
之前,我们已经完成了工作流的基本流程和整体框架设计,接下来的任务就是进入实际操作和实现阶段。如果有同学对工作流的整体结构还不够熟悉,可以先参考一下这篇文章,帮助你更好地理解和掌握工作流的各个部分:juejin.cn/post/744399…
本篇文章是我关于Spring AI搭建Agent系列的第三篇实战教程,虽然Spring AI目前仍处于快照版本,还未发布正式版本,但这并不妨碍我们了解其最新的功能和发展动态。毕竟,人工智能是未来发展的核心方向之一。接下来,我将直接进入主题,废话不多说,我们开始吧!
今天我们将主要使用Spring AI Alibaba进行开发演示,展示如何通过这个框架构建AI助理。在最后,我还会附上整个AI助理的演示视频,供大家参考。通过这个演示,大家可以看到,当前的Java开发者不再需要转向Python,依然可以参与到AI Agent开发的潮流中,抓住这一全新的技术趋势!
简单回顾
好的,回顾一下之前的工作,我们已经成功搭建了一个个人 AI 助理 Agent 示例,该示例已经具备了多项实用功能,接下来我将简单回顾一下这些功能的实现及其特点:
- 旅游攻略:通过直接调用第三方工作流工具 Coze 来完成旅游攻略的生成,整个过程既快速又高效,无需复杂的配置,能够快速响应用户的需求,提供精准的旅行推荐。
- 天气查询:该功能通过从数据库中查询当前地址的编码,然后调用天气API接口进行实时天气查询,能够准确地提供用户所在地的天气预报,确保用户获取到最新的天气信息。
- 个人待办:系统可以根据用户的指令,自动生成SQL查询并执行相关操作,直接访问数据库,方便用户添加、删除或更新个人待办事项,极大地提高了任务管理的效率。
这些功能在整个AI助理Agent中已经得到了有效的整合和应用,极大提升了用户体验和操作便捷性。接下来,整个系统的架构设计如下所示:
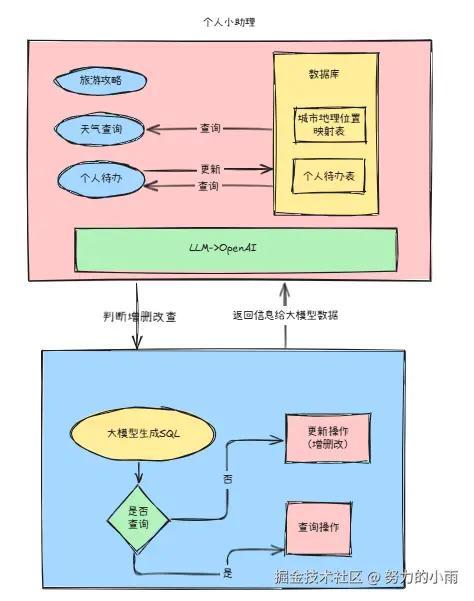
之前,我们一直使用的是hunyun兼容OpenAI接口进行测试和联调,今天我们继续进行Spring AI的应用开发,不过这次使用的是国内的Spring AI版本——Spring AI Alibaba。与之前的OpenAI接口不同,Spring AI Alibaba更贴合国内的技术环境和需求。如果你希望使用原生的兼容接口,目前可以考虑阿里巴巴的通义千问模型,它提供了较为成熟和稳定的API支持。
需要特别说明的是,关于Spring AI中第三方聊天模型接口的情况,在我目前了解的基础上,只有Alibaba是官方开发并支持的,稳定性方面也有了更高的保证。而其他一些例如智普的接口,虽然功能上能够满足基本需求,但它们更多的是由个人开发者和爱好者维护,稳定性和技术支持相对有所差异,使用时需要特别留意其可用性。
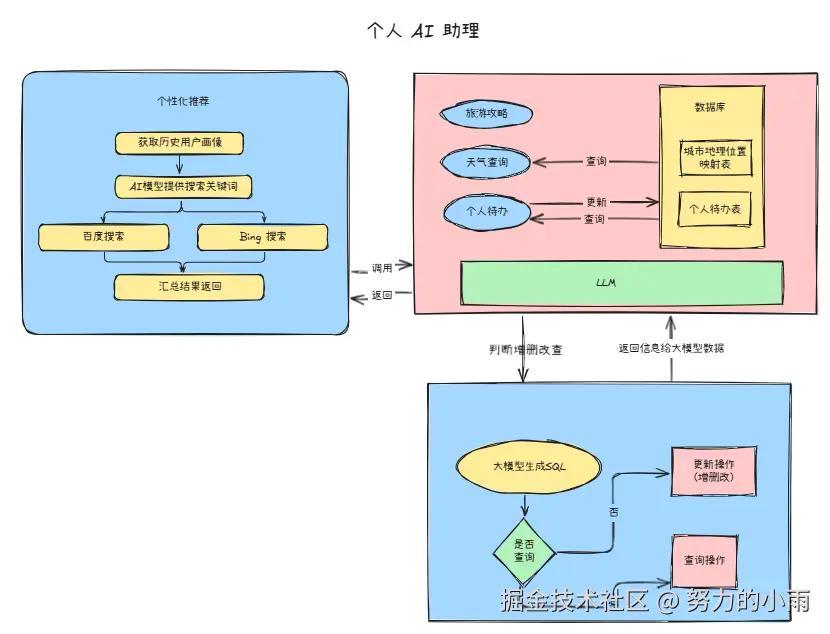
个性化推荐
在这个功能模块中,我们主要依托用户的历史画像,通过分析其过往的行为数据、兴趣偏好等信息,利用AI模型总结出相关的搜索关键词,进而推荐一些用户可能会感兴趣的电影、新闻等内容。
我已经大致画出了一个简单的设计图,展示了这一推荐流程的架构。大家可以看一下这个设计图:
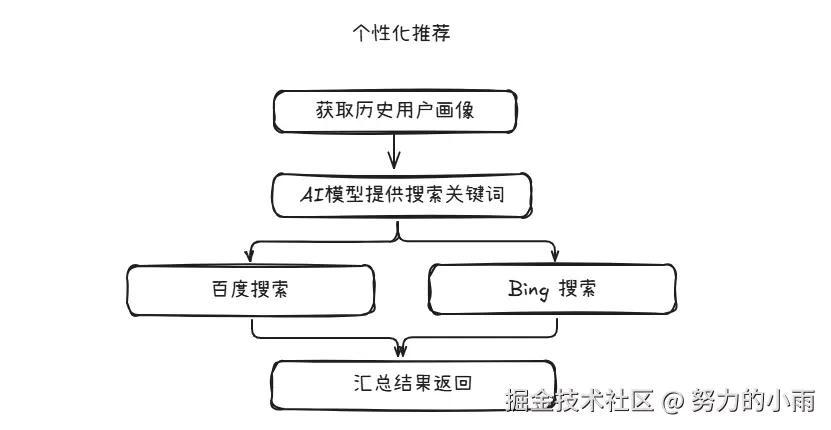
为了更好地展示我工作流的并行处理能力,我特意选择了百度和Bing两个搜索插件进行演示。
此外,Spring AI Alibaba框架内部已经开始着手开发插件商店,目前虽仅有4个插件,但这只是一个起点,未来框架将会不断扩展和丰富插件的种类和功能,支持更多第三方插件的集成和应用。如图所示,当前框架的插件商店界面已经初具雏形:

好的,接下来我们继续深入讨论。在这一部分,百度搜索是实时进行的,即系统会直接调用百度的搜索接口。相比之下,Bing搜索则需要使用个人API密钥进行调用。由于目前尚未配置好API密钥,为了便于展示和测试,我暂时将Bing搜索的返回值写死为固定的结果,而没有进行实际的API调用。这样做的目的是为了简化演示流程,确保其他部分能够正常工作。
需要特别注意的是,目前Spring AI Alibaba框架本身并不支持完整的工作流功能。虽然框架在不断迭代和优化,但目前如果想要实现工作流编排的功能,开发者需要自行开发相关的功能模块,或者选择等待框架官方在未来版本中加入工作流支持。因此,在当前的工作流编排中,我们将依赖手动编码来实现任务的顺序执行和逻辑控制。
工作流实现
我们之前提供的仅仅是一些大致的框架和思路,但具体的内部实现并没有详细展开。在此,我将分享一些关键的代码实现。每个人在实现时可能会采用不同的方式,如果你有更为高效或更合适的解决方案,当然可以根据自己的理解进行调整和优化。
接下来,我将简要展示整体框架的示意图,以帮助大家更清晰地理解整体结构,避免后续讨论时产生混淆。如图所示:
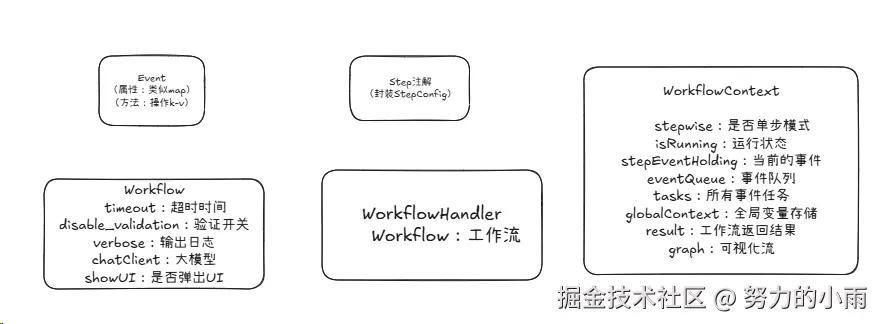
好的,接下来我们将深入探讨主要的核心部分。首先,我们需要将扫描步骤中的step方法进行封装,转化为任务(task),并将其交由工作流进行管理和保存。
initialContext
我在这部分的设计上参考了LlamaIndex的工作流,将扫描类中的step方法集成到初始化上下文中,以实现更加高效和灵活的任务管理。通过这种方式,我们能够确保每个步骤都能被系统有效地捕获并按照预期的流程执行。接下来,我们来看一下核心代码的实现,具体如下所示:
java 代码解读复制代码private WorkflowContext initialContext() {
WorkflowContext context = new WorkflowContext(false);
// 获取当前子类的类对象
Class clazz = this.getClass();
// 获取子类的所有方法
Method[] methods = clazz.getDeclaredMethods();
Graph graph = context.getGraph();
// 遍历所有方法,检查是否有 StepConfig 注解
for (Method method : methods) {
if (method.isAnnotationPresent(Step.class)) {
Step annotation = method.getAnnotation(Step.class);
String name = method.getName();
log.info("Method: {}", name);
if (!context.getEventQueue().containsKey(name)){
context.getEventQueue().put(name, new ArrayBlockingQueue<>(10));
}
// 获取方法的参数类型
Class[] parameterTypes = method.getParameterTypes();
Listextends ToolEvent>> acceptedEventList = List.of(annotation.acceptedEvents());
String eventName = name;
StepConfig stepConfig = StepConfig.builder().acceptedEvents(acceptedEventList).eventName(eventName)
.returnTypes(method.getReturnType()).build();
log.info("Adding node: {}", name);
// 添加节点并设置节点标签和样式
Node nodeA = graph.addNode(name);
nodeA.setAttribute("ui.style", "text-size: 20;size-mode:fit;fill-color:yellow;size:25px;");
// 创建线程对象但不启动
Thread thread = new Thread(() -> {
log.info("Thread started for method: {}", name);
//可能有多个事件,需要处理
ArrayListextends ToolEvent>> events = new ArrayList<>(acceptedEventList);
// 获取队列对象
ArrayBlockingQueue queue = context.getEventQueue().get(name);
while (true) {
try {
ToolEvent event = queue.take(); // 从队列中取出事件
if(!StringUtils.isEmpty(context.getResult())){
break;
}
if (isAcceptedEvent(event, acceptedEventList,events,context,name)) {
//开始执行时间
long startTime = System.currentTimeMillis();
context.setStepEventHolding(event);
Object returnValue = method.invoke(this, context); // 执行方法
//继续发布事件
continueSendEvent(context,returnValue,name);
// 执行时间
long endTime = System.currentTimeMillis();
graph.getNode(name).setAttribute("ui.label", name + "耗时:" + (endTime - startTime) + "ms");
} else {
continue;
}
} catch (InterruptedException e) {
log.error("Thread interrupted for method: {}", name, e);
Thread.currentThread().interrupt();
break;
} catch (Exception e) {
log.error("Error executing method: {}", name, e);
//继续发布事件
continueSendEvent(context,new StopEvent(e.getMessage()),name);
}
}
});
context.addThread(thread);
}
}
return context;
}
注释写的基本很清楚了,我再来简单解释一下这段代码的含义,帮助你理解。
- 创建一个 WorkflowContext 对象,传入 false 参数,表示并行处理。
- 获取当前类的信息:获取当前子类的类对象以及其声明的方法列表。
- 遍历方法并寻找 Step 注解:遍历子类中的所有方法,检查每个方法是否被 @Step 注解标记。
- 设置事件队列:对每个被 @Step 注解的方法,首先获得其名称,然后检查上下文中的事件队列。若不存在,则为该方法名创建一个 ArrayBlockingQueue。
- 添加图形节点(Node):在图形 (Graph) 中为每个步骤添加一个节点,并设置其视觉样式(如文本大小和填充颜色)。
- 创建并配置线程:
- 为每个步骤创建一个新的线程。这个线程负责从事件队列中读取事件并根据事件处理逻辑执行步骤方法。
- 在该线程中,通过无限循环持续读取队列中的事件,处理符合条件的事件。处理时会记录方法的执行时间并更新节点标签信息,处理异常情况并继续发布事件。
- 处理事件和执行方法:
- 在每次取出事件后,首先检查当前状态是否应继续执行(例如检查是否有结果返回)。
- 如果取到的事件被该步骤接受,则调用相应的方法执行处理,并根据返回值继续发布后续事件。如果方法执行时抛出异常,也会捕获并处理,同时继续发布一个停止事件。
run方法
在完成了任务的封装后,接下来要做的就是如何启动并执行所有的任务。这一部分的逻辑主要集中在run方法中,负责协调和控制所有任务的执行流程。接下来,让我们简单查看一下run方法中的核心代码实现:
java 代码解读复制代码public String run(String jsonString) throws IOException {
WorkflowContext context = initialContext();
if (!StringUtils.isEmpty(jsonString)) {
//初始参数
context.getGlobalContext().putAll(JSONObject.parseObject(jsonString));
}
WorkflowHandler handler = new WorkflowHandler(context);
handler.handleTask(timeout);
if (showUI) {
//todo 本地测试时,会将springboot程序一起杀掉,后期优化
context.getGraph().display();
try {
System.out.println("Press any key to exit...");
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
} else {
// 导出图形为文件
FileSinkImages pic = new FileSinkImages(FileSinkImages.OutputType.PNG, FileSinkImages.Resolutions.HD1080);
pic.setLayoutPolicy(FileSinkImages.LayoutPolicy.COMPUTED_FULLY_AT_NEW_IMAGE);
pic.writeAll(context.getGraph(), "sample.png");
}
return context.getResult();
}
我来简单的说下这部分代码的含义。
- 初始化工作流上下文,就是上面刚说的部分代码。
- 处理输入的JSON字符串:这里主要考虑的是工作流是可以有输入参数的,而我将输入参数全都当做json处理,以后也好做对象封装。
- 执行工作流任务:这里就是简单的启动一下所有task线程任务。
- UI显示或文件导出:因为我不是前端,技术有限,并没有使用前端生成HTML代码的输出,而是使用的graphstream类快速生成的图片或弹窗UI。并简单记录了一下每个事件的执行时间。
- 返回结果:最后我会将工作流的结果全都放到result中返回给调用方。整个工作流算是完成了。
剩下的部分基本上没有太多复杂的代码了。通过参考LlamaIndex的工作流核心代码,我自定义了这一工作流封装,并将其进行了适当的优化。接下来,我们进入真正的测试阶段,重点检验它的稳定性和完整性。
虽然目前实现的版本仍然有许多优化空间和改进之处,但至少它已经能够顺利运行,具备了初步的可用性。现在,让我们开始实际的运行测试,看看效果如何。
准备工作
申请api-key
连接地址如下:bailian.console.aliyun.com/?spm=a2c4g.…
进入后,请根据个人需求选择任意一个千问模型。然后,查看并保存您的个人API密钥(key)。如果没有密钥,您可以按照指引自行创建一个新的密钥,具体操作步骤如图所示。

保存好后,我们需要用到这个api-key。
创建项目
我们可以直接复制一个官方提供的 demo,保留所有依赖项不变,其他部分可以根据我们的需求进行修改和调整。项目的整体结构如图所示:
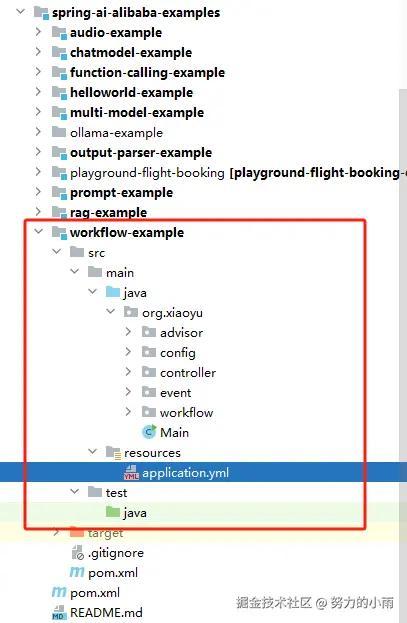
好的,接下来我们继续进行。首先,由于我们需要集成百度搜索和 Bing 搜索插件,因此我们可以直接将它们添加到 pom.xml 的依赖中。经过整合之后,最终的依赖配置如下所示:
xml 代码解读复制代码"1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>3.3.3version>
<relativePath/>
parent>
<groupId>com.alibaba.cloud.aigroupId>
<artifactId>workflow-exampleartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>workflow-examplename>
<description>Demo project for Spring AI Alibabadescription>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<maven.compiler.source>17maven.compiler.source>
<maven.compiler.target>17maven.compiler.target>
<maven-deploy-plugin.version>3.1.1maven-deploy-plugin.version>
<spring-ai-alibaba.version>1.0.0-M3.2spring-ai-alibaba.version>
properties>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.aigroupId>
<artifactId>spring-ai-alibaba-starterartifactId>
<version>${spring-ai-alibaba.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>com.alibaba.cloud.aigroupId>
<artifactId>spring-ai-alibaba-starter-plugin-baidusearchartifactId>
<version>1.0.0-M3.2version>
<scope>compilescope>
dependency>
<dependency>
<groupId>com.alibaba.cloud.aigroupId>
<artifactId>spring-ai-alibaba-starter-plugin-bingsearchartifactId>
<version>1.0.0-M3.2version>
<scope>compilescope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-deploy-pluginartifactId>
<version>${maven-deploy-plugin.version}version>
<configuration>
<skip>trueskip>
configuration>
plugin>
plugins>
build>
project>
接着,我们再去填写一个配置文件信息,如下所示:
yaml 代码解读复制代码spring:
application:
name: workflow-example
ai:
dashscope:
api-key: 自己的key,如:sk-
chat:
options:
model: qwen-plus
在这里,我使用的是 qwen-plus 模型,但你完全可以根据实际需求选择其他可用的模型。根据目前的选项,你有以下几种选择:qwen-turbo、bailian-v1、dolly-12b-v2、qwen-plus 以及 qwen-max。
Event封装优化
接下来,我们将开始使用自己创建的 ToolEvent 类。在最近的优化中,我对该类进行了一些改进,主要加入了一个抽象逻辑,旨在更好地处理工作流事件的逻辑。不仅提升了代码的可扩展性和可维护性,还增加了一个 事件输出参数名,该参数名的引入使得获取其他节点的参数信息变得更加简便和高效。以下是更新后的代码示例:
java 代码解读复制代码public abstract class ToolEvent {
//此处省略部分代码
public String getOutputName() {
if (this.outputName == null) {
this.outputName = this.getClass().getSimpleName();
}
return this.outputName;
}
public abstract void handleEvent(Map globalContext) ;
}
接下来,我们需要对时间处理相关的节点进行封装。考虑到这个方法不应该暴露给用户直接调用,而是应该在我们内部进行控制和执行,因此,我将其封装到了发布事件之前的时间节点。以下是相关代码的实现:
java 代码解读复制代码public class WorkflowContext {
//此处省略部分代码
public void sendEvent(ToolEvent value) {
//这里执行
value.handleEvent(globalContext);
eventQueue.entrySet().stream().forEach(entry -> {
String key = entry.getKey();
log.info("send event to {},event:{}", key, value.getEventName());
entry.getValue().add(value);
});
}
}
剩下的部分已经没有明显需要进一步优化的地方了,我们可以直接开始使用抽象出来的事件类来创建所需的节点信息,并将其集成到系统中以实现具体功能。
工作流节点创建
HistoryInfoEvent
为了方便演示,出于简化的考虑,我们并没有实际进行用户历史画像的提取操作,而是简单地写了一句说明文字。在实际的应用场景中,完全可以将相关信息从用户数据中提取出来,进行进一步的分析和处理。以下是相关代码示例:
java 代码解读复制代码public class HistoryInfoEvent extends ToolEvent {
private String HISTORY_INFO = "{\n" +
" \"name\": \"努力的小雨\",\n" +
" \"age\": \"28岁\",\n" +
" \"hobbies\": {\n" +
" \"sports\": [\"打篮球\"],\n" +
" \"movies\": [\"变形金刚\", \"钢铁侠\", \"复仇者联盟\"],\n" +
" \"news\": [\"AI实时新闻\"]\n" +
" },\n" +
" \"occupation\": \"软件工程师\",\n" +
" \"location\": \"北京\"\n" +
"}";
@Override
public void handleEvent(Map globalContext) {
//假设从用户画像中获取信息
ThreadUtils.sleep(1342);
//存入输出值,给其他人使用
globalContext.put(getOutputName()+":output", HISTORY_INFO);
}
}
AIChatEvent
在这里,我们需要为程序添加一个 chatClient 属性对象,并确保在初始化时将其注入到相关的事件中,以便在后续的操作中能够正常使用。为了更好地展示如何使用,我简单地编写了一些提示词,用于规划输出格式。这些提示词的作用是限定输出内容的样式和结构。通常情况下,Spring AI 是可以在调用时通过传入相应的类,自动将预设的提示词传递给类中的方法,从而对输出结果进行有效的限制和格式化。
然而,为了方便本次演示,我采取了一种简化的处理方式,以便更直观地展示相关流程和功能。
java 代码解读复制代码public class AIChatEvent extends ToolEvent {
private String systemprompt = """
- Role: 个性化信息检索专家
- Background: 用户希望根据自己的兴趣爱好等个人信息,获取定制化的推荐内容,包括电影、新闻。
- Profile: 你是一位专业的个性化信息检索专家,擅长根据用户的个人信息和偏好,高效地检索和推荐相关内容。
- Skills: 你具备强大的信息筛选能力、对各类信息源的深入了解,以及快速响应用户需求的能力。
- Goals: 根据用户的兴趣爱好等信息,提供两个关键词,帮助用户在搜索引擎中快速找到今日电影推荐、今日实时新闻。
- Constrains: 关键词需要简洁、相关性强,并且能够直接用于搜索引擎查询。
- OutputFormat: 返回两个数组元素,每个元素包含一个关键词。
- Workflow:
1. 分析用户的兴趣爱好和个人信息。
2. 根据分析结果,确定与电影、新闻相关的关键词。
3. 将关键词以数组形式返回给用户。
- Examples:
- 例子1:用户喜欢科幻电影、国际新闻
- ['今日科幻电影推荐', '今日国际新闻头条']
- 例子2:用户喜欢历史纪录片、财经新闻
- ['今日历史纪录片推荐', '今日财经新闻头条']
- 例子3:用户喜欢动作电影、体育新闻
- ['今日动作电影推荐', '今日体育新闻快讯']
""";
private ChatClient chatClient;
public AIChatEvent(ChatClient chatClient) {
this.chatClient = chatClient;
}
@Override
public void handleEvent(Map globalContext) {
String prompt = """
请根据提供的用户画像返回给我数组,数组中包含两个关键词,每个关键词都需要简洁、相关性强,并且能够直接用于搜索引擎查询。
---
""" + globalContext.get(HistoryInfoEvent.class.getSimpleName()+":output");
String content = chatClient.prompt().system(systemprompt).user(prompt).advisors(new MyLoggerAdvisor()).call().content();
log.info("content->{}",content);
globalContext.put(getOutputName()+":output", content);
}
}
SearchEvent
为了演示工作流的并行处理能力,我在“搜索事件”部分创建了两个独立的节点。这些节点是为了展示在多个任务同时执行。由于Bing插件需要使用API密钥,而该密钥在当前环境中没有配置,因此我暂时将其写死,导致无法获取实际的搜索结果。以下是相关的代码示例:
java 代码解读复制代码public class BingSearchEvnet extends ToolEvent {
// private BingSearchService bingSearchService = new BingSearchService();
private String searchWord;
public BingSearchEvnet(String searchWord) {
this.searchWord = searchWord;
}
@Override
public void handleEvent(Map globalContext) {
//仿制搜索
ThreadUtils.sleep(2000);
globalContext.put(getOutputName()+":output", searchWord+",并无搜索到");
}
}
public class BaiDuSearchEvent extends ToolEvent {
private BaiduSearchService baiduSearchService = new BaiduSearchService();
private String searchWord;
public BaiDuSearchEvent(String searchWord) {
this.searchWord = searchWord;
}
@Override
public void handleEvent(Map globalContext) {
BaiduSearchService.Request request = new BaiduSearchService.Request(searchWord, 10);
BaiduSearchService.Response response = baiduSearchService.apply(request);
if (response == null || response.results().isEmpty()){
return;
}
StringBuilder stringBuilder = new StringBuilder();
for (BaiduSearchService.SearchResult result : response.results()) {
stringBuilder.append("---------");
stringBuilder.append("title:");
stringBuilder.append(result.title());
stringBuilder.append("text:");
stringBuilder.append(result.abstractText());
log.info("result.title:{}",result.title());
log.info("result.abstractText:{}",result.abstractText());
}
globalContext.put(getOutputName()+":output", stringBuilder.toString());
}
}
请注意,上面提供的代码包含了两个类。为了减少代码的篇幅,我将它们合并在了一起。需要特别注意的是,官方插件的百度搜索结果对象并没有提供 get 方法。因此,在处理结果时,我将其解析出来并存储到一个字符串变量中,而没有直接使用 toJsonString 方法。因为如果直接调用该方法进行转换,最终会得到一个空的结果。
工作流规划
剩下的部分就是将工作流的各个节点进行规划和连接。具体来说,这一步是确保所有节点之间的逻辑关系和执行顺序能够正确地衔接在一起,从而形成一个完整的工作流。接下来,我们可以通过以下代码来实现这一目标:
java 代码解读复制代码public class RecommendWorkflow extends Workflow {
private ChatClient chatClient;
public RecommendWorkflow(ChatClient chatClient) {
this.chatClient = chatClient;
}
@Step(acceptedEvents = {StartEvent.class})
public ToolEvent toHistoryInfoEvent(WorkflowContext context) {
return new HistoryInfoEvent();
}
@Step(acceptedEvents = {HistoryInfoEvent.class})
public ToolEvent toAIChatEvent(WorkflowContext context) {
return new AIChatEvent(chatClient);
}
/**
演示并行效果
*/
@Step(acceptedEvents = {AIChatEvent.class})
public ToolEvent toBaiduSearchEvent(WorkflowContext context) {
Object array = context.getGlobalContext().get(AIChatEvent.class.getSimpleName() + ":output");
//转string数组
JSONArray jsonArray = JSONArray.parseArray((String) array);
return new BaiDuSearchEvent(jsonArray.getString(0));
}
/**
演示并行效果
*/
@Step(acceptedEvents = {AIChatEvent.class})
public ToolEvent toBingSearchEvent(WorkflowContext context) {
Object array = context.getGlobalContext().get(AIChatEvent.class.getSimpleName() + ":output");
//转string数组
JSONArray jsonArray = JSONArray.parseArray((String) array);
return new BingSearchEvnet(jsonArray.getString(1));
}
@Step(acceptedEvents = {BaiDuSearchEvent.class,BingSearchEvnet.class})
public ToolEvent toStopEvent(WorkflowContext context) {
//获取搜索结果
JSONObject result = new JSONObject();
result.put("百度搜索结果:",context.getGlobalContext().get(BaiDuSearchEvent.class.getSimpleName() + ":output"));
result.put("bing搜索结果:",context.getGlobalContext().get(BingSearchEvnet.class.getSimpleName() + ":output"));
return new StopEvent(result.toJSONString());
}
}
在这部分代码中,我们可以清晰地看到,经过工作流优化后的处理逻辑变得非常简洁。除了需要为事件封装必要的参数外,几乎没有其他复杂的处理逻辑。接下来,我们需要进一步配置和注入所需的聊天大模型,以确保系统能够顺利地与其进行交互并完成相应的任务。
模型配置
在这段配置中,我对工作流的可视化和超时时间进行了调整。特别需要注意的是,如果是在生产环境中,请避免启用 showui 选项,这样就会让工作流的流程转化成图片保存了。
除了这一点,我还对大模型的超时时间进行了配置,因为默认的超时时间较短,如果与模型的沟通时间过长,就容易触发超时错误并导致报错。
最后,我还添加了日志打印的配置,这样可以在测试过程中方便地查看大模型的调用日志,以便更好地调试和排查问题。
java 代码解读复制代码@Configuration
class ChatConfig {
@Bean
RecommendWorkflow recommendWorkflow(ChatClient.Builder builder) {
RecommendWorkflow recommendWorkflow = new RecommendWorkflow(builder.build());
recommendWorkflow.setTimeout(20);
recommendWorkflow.setShowUI(true);
return recommendWorkflow;
}
@Bean
RestClient.Builder restClientBuilder(RestClientBuilderConfigurer restClientBuilderConfigurer) {
ClientHttpRequestFactorySettings defaultConfigurer = ClientHttpRequestFactorySettings.DEFAULTS
.withReadTimeout(Duration.ofMinutes(5))
.withConnectTimeout(Duration.ofSeconds(30));
RestClient.Builder builder = RestClient.builder()
.requestFactory(ClientHttpRequestFactories.get(defaultConfigurer));
return restClientBuilderConfigurer.configure(builder);
}
@Bean
MyLoggerAdvisor myLoggerAdvisor() {
return new MyLoggerAdvisor();
}
}
日志类
日志的写法其实非常简单,大家可以参考一下。
java 代码解读复制代码@Slf4j
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
public static final Function DEFAULT_REQUEST_TO_STRING = (request) -> {
return request.toString();
};
public static final Function DEFAULT_RESPONSE_TO_STRING = (response) -> {
return ModelOptionsUtils.toJsonString(response);
};
private final Function requestToString;
private final Function responseToString;
public MyLoggerAdvisor() {
this(DEFAULT_REQUEST_TO_STRING, DEFAULT_RESPONSE_TO_STRING);
}
public MyLoggerAdvisor(Function requestToString,
Function responseToString) {
this.requestToString = requestToString;
this.responseToString = responseToString;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
private AdvisedRequest before(AdvisedRequest request) {
log.info("request: {}", this.requestToString.apply(request));
return request;
}
private void observeAfter(AdvisedResponse advisedResponse) {
log.info("response: {}", this.responseToString.apply(advisedResponse.response()));
}
@Override
public String toString() {
return SimpleLoggerAdvisor.class.getSimpleName();
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
advisedRequest = before(advisedRequest);
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
observeAfter(advisedResponse);
return advisedResponse;
}
@Override
public Flux aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
advisedRequest = before(advisedRequest);
Flux advisedResponses = chain.nextAroundStream(advisedRequest);
return new MessageAggregator().aggregateAdvisedResponse(advisedResponses, this::observeAfter);
}
}
这里包含了我们需要实现的所有增强器方法,代码量较大,但实际上它们的核心逻辑并不复杂,主要就是在不同的地方打印当前对象的内容,并记录相关的日志信息。目的是确保在系统运行过程中能够及时获取到足够的调试信息,方便后续的调试与优化。
访问入口
最终,为了简化对我们工作流的访问过程,我直接编写一个控制器(Controller)来接收和处理外部请求。以下是实现该控制器的代码示例:
java 代码解读复制代码@RestController
@RequestMapping("/hello")
public class HelloWordController {
@Autowired
private RecommendWorkflow recommendWorkflow;
@RequestMapping("/word")
public String hello() throws IOException {
return recommendWorkflow.run("");
}
}
为了便于演示和简化示例的复杂度,我在这里并没有引入任何输入参数。事实上,您完全可以根据实际需求,将一些必要的标识信息(例如用户ID、会话ID或其他工作流所需要的上下文数据)作为输入参数传递给控制器。
工作流演示效果
接下来,我们将进行工作流功能的演示。在启动项目之后,只需在浏览器中输入以下地址:http://localhost:8080/hello/word,即可直接访问该功能。具体内容将如下图所示。

最终返回结果如图所示:
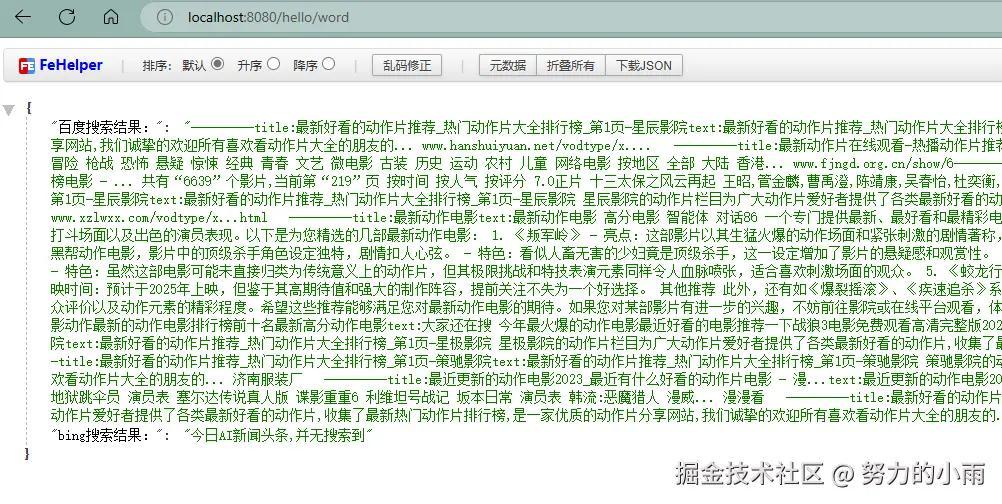
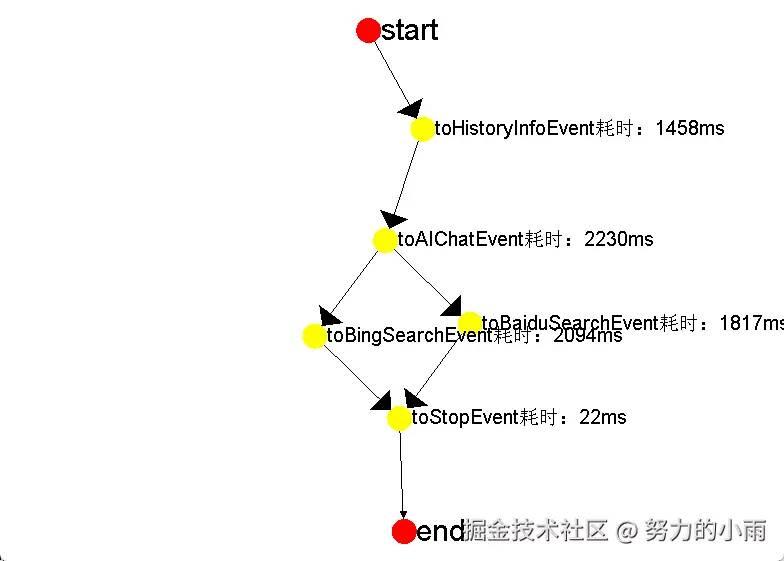
在正常情况下,我们的项目会自动生成并输出一张图片,你可以在系统中看到该图片的展示效果。如图所示:
为了更好地展示效果,我已将UI开关功能开启。以下是启用开关后的界面效果图:
嵌入AI助理
正如目前市面上许多智能体平台的设计模式,工作流通常是一个可以单独调用的模块。因此,我们可以将工作流作为微服务的一部分进行部署,并通过暴露相应的接口,便于我们的AI Agent进行调用。这个接口通常以函数(function)的形式呈现。需要特别注意的是,AI聊天问答项目与工作流项目是两个独立的模块,尽管如此,你也完全可以将这两个模块合并成一个整体,视项目需求而定。为了保持与其他智能体平台的一致性,在本示范中我们选择将它们分别作为两个独立的项目进行演示。
为了帮助大家更清晰地理解整个架构,我简单绘制了一张框架图,大家可以参考一下,避免在后续的讲解中感到困惑。
好的,接下来,我们需要对现有的系统进行一些调整,具体来说,就是将原本使用的OpenAI依赖替换成我们的千问模型。
大模型接入
在这里,需要特别注意的是,目前千问模型并没有直接集成在官方的Spring AI框架中,因此无法像其他常见模型那样直接通过Spring AI的依赖引入进行使用。
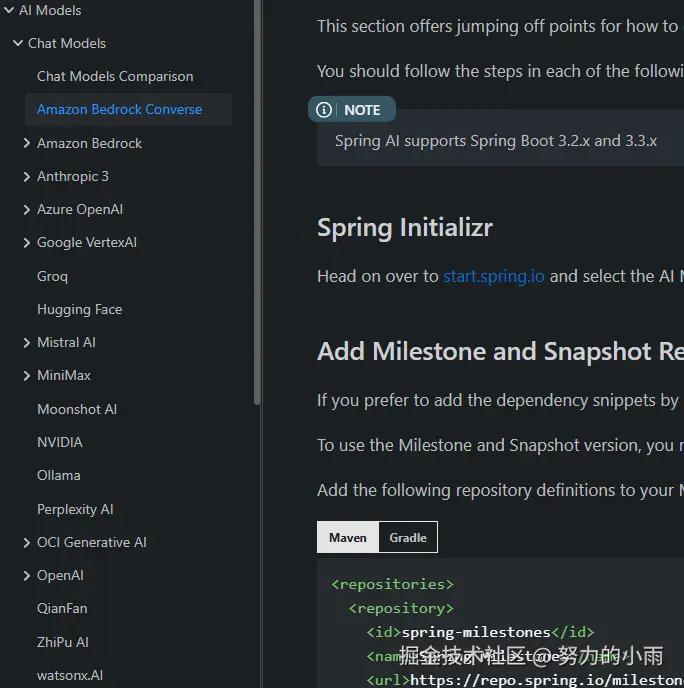
因此,如果我们希望在项目中使用千问模型作为依赖,必须遵循Spring AI Alibaba的集成方式,按照其官方Demo的指导,将spring-ai-alibaba-starter依赖引入到我们的项目中。以下是该依赖的引入方式和配置示例,供大家参考:
xml 代码解读复制代码<dependency>
<groupId>com.alibaba.cloud.aigroupId>
<artifactId>spring-ai-alibaba-starterartifactId>
<version>1.0.0-M3.2version>
dependency>
紧接着,接下来的步骤是,务必将之前添加的OpenAI依赖在项目中进行注释或者直接删除掉,否则在运行时可能会导致依赖冲突和报错问题。由于我的Spring AI问答项目是基于properties配置文件来管理配置信息的,因此我们需要在application.properties文件中添加与千问模型集成所需的相关配置信息。
xml代码解读复制代码spring.ai.dashscope.api-key= sk-63eb29c7f4dd4de489fa64382d94a797 spring.ai.dashscope.chat.options.model= qwen-plus
这样我们就能够顺利启动并成功运行系统。如图所示,基本的问答流程已经正常工作,所有的功能都按预期进行。
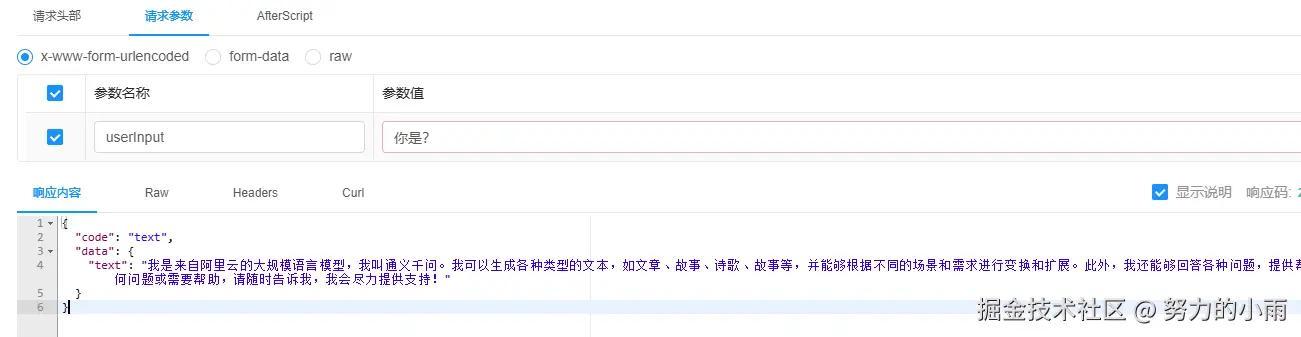
项目已经成功启动并正常运行,接下来我们可以继续编写一个函数调用。在这一阶段,我们将直接通过 HTTP 调用进行通信,而暂时不涉及服务发现和注册机制。这样做的目的是为了简化演示。
FunctionCall
需要注意的是,在进行这次变更后,我们发现出现了许多兼容性问题,之前运行良好的流程也开始出现错误。因此,我对整个系统进行了全面优化。经过一番调整和修复后,最终保留下来的插件调用配置就是当前的版本。
java 代码解读复制代码@Bean
public FunctionCallbackWrapper weatherFunctionInfo(AreaInfoPOMapper areaInfoPOMapper) {
return FunctionCallbackWrapper.builder(new BaiDuWeatherService(areaInfoPOMapper))
.withName("CurrentWeather") // (1) function name
.withDescription("获取指定地点的天气情况") // (2) function description
.build();
}
@Bean
@Description("旅游规划")
public FunctionCallbackWrapper travelPlanningFunctionInfo() {
return FunctionCallbackWrapper.builder(new TravelPlanningService())
.withName("TravelPlanning") // (1) function name
.withDescription("根据用户的旅游目的地推荐景点、酒店以及给出实时机票、高铁票信息") // (2) function description
.build();
}
@Bean
@Description("待办管理")
public FunctionCallbackWrapper toDoListFunctionWithContext(ToDoListInfoPOMapper toDoListInfoPOMapper, JdbcTemplate jdbcTemplate) {
return FunctionCallbackWrapper.builder(new ToDoListInfoService(toDoListInfoPOMapper,jdbcTemplate))
.withName("toDoListFunctionWithContext") // (1) function name
.withDescription("添加待办,crud:c 代表增加;r:代表查询,u:代表更新,d:代表删除") // (2) function description
.build();
}
@Bean
@Description("用户查询今日推荐内容")
public FunctionCallbackWrapper myWorkFlowServiceCall() {
return FunctionCallbackWrapper.builder(new MyWorkFlowService())
.withName("myWorkFlowServiceCall") // (1) function name
.withDescription("用户查询今日推荐内容,参数:username为用户名") // (2) function description
.build();
}
接下来,我们将讨论工作流中插件的调用部分。这里涉及到一个 HTTP 调用功能。下面是该部分的代码示例:
java 代码解读复制代码@Slf4j
@Description("今日推荐")
public class MyWorkFlowService implements Function {
@JsonClassDescription("username:用户名字")
public record WorkFlowRequest(String username) {}
public record WorkFlowResponse(String result) {}
public WorkFlowResponse apply(WorkFlowRequest request) {
MyWorkFlowRun myWorkFlowRun = new MyWorkFlowRun();
String result = myWorkFlowRun.getResult(request.username);
return new WorkFlowResponse(result);
}
}
@Slf4j
public class MyWorkFlowRun {
RestTemplate restTemplate = new RestTemplate();
/**
* 这里也可以优化成一个公用的插件,比如传入一个工作流id,然后工作流项目那边根据id运行,这样就可以复用
* @param username 入参
* @return 返回的结果
*/
public String getResult(String username) {
log.info("打印输入参数-username:{}", username);
//我们不使用入参作为搜索词,而是直接写死,这里只是演示下
String result = restTemplate.getForObject("http://localhost:8080/hello/word", String.class);
return result;
}
}
在这里,我只是进行了一个简化的操作,即简单调用了本地的工作流接口,并打印了输入参数。由于当前的实现中并不需要这些参数,因此我只是将其输出做了展示。然而,如果在实际应用中你需要使用这些参数,完全可以将其传递给工作流接口进行相应的处理。
接下来,一切准备就绪,我们只需将这个插件集成到我们的问答模型中。具体的代码实现如下:
java 代码解读复制代码@PostMapping("/ai-function")
ChatDataPO functionGenerationByText(@RequestParam("userInput") String userInput) {
//此处省略重复代码
String content = this.chatClient
.prompt(systemPrompt)
.user(userInput)
.advisors(messageChatMemoryAdvisor,myLoggerAdvisor)
//用来区分不同会话的参数conversation_id
.advisors(advisor -> advisor.param("chat_memory_conversation_id", conversation_id)
.param("chat_memory_response_size", 100))
.functions("CurrentWeather","TravelPlanning","toDoListFunctionWithContext","myWorkFlowServiceCall")
//此处省略重复代码
在这里,我们只需简单地将刚才使用的名称直接添加到 functions 中,操作非常简便。实际上,这一步骤无需过多复杂的配置,一旦添加完成,接下来的工作就交给大模型自动处理了。
助理效果
这里简要介绍一下前端UI部分的实现。我主要使用的是ChatSDK,并将其集成到项目中。整个过程相对简单,配置项也比较基础,开发人员只需参考官方提供的文档,按照指导步骤进行操作即可顺利完成集成。这里就不多说了。

接下来,我们将启动两个项目:一个是 Spring AI 项目,另一个是 Spring AI Alibaba 项目(负责工作流部分)。启动这两个项目后,我们可以直观地观察它们在实际运行中的表现。
现在不支持西瓜视频链接了,请去B站观看吧:www.bilibili.com/video/BV1WP…
总结
在本系列教程中,我们深入探讨了Spring AI及其在国内版本Spring AI Alibaba的实战应用,重点关注了如何构建一个功能丰富、智能高效的AI助理。通过详细讲解从工作流的基本流程设计到实际操作实现的全过程,我们逐步揭开了AI助理开发的神秘面纱,使得Java开发者能够轻松上手并应用最新的AI技术。
首先,我们回顾了构建个人AI助理Agent的全过程,涵盖了诸如旅游攻略、天气查询和个人待办事项等多个实用功能模块。在这一部分,我们不仅介绍了相关功能的设计和实现,还探讨了如何将这些功能模块无缝集成到一个综合性的AI助理中,确保用户体验的流畅与智能。此外,我们深入分析了工作流的实现细节,重点讨论了事件封装优化、工作流节点的创建与组织、以及如何高效规划和管理复杂的工作流。
在教程的最后,我们通过一个实际的项目启动与运行测试环节,生动展示了AI助理的实际效果。通过这些实际测试,我们不仅验证了系统的稳定性与可扩展性,还为后续的优化和功能拓展打下了坚实的基础。最终,我们的目标是让开发者不仅理解Spring AI的核心技术和应用框架,更能通过实际操作掌握AI助理开发的精髓。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
评论记录:
回复评论: