
基于反向扩散过程的高分辨率图像生成优化
近年来,图像生成技术在人工智能领域取得了显著进展,尤其是在深度生成模型中,反向扩散过程(denoising diffusion probabilistic models, DDPM)因其在高质量图像生成方面的优越性能而受到广泛关注。与传统的生成对抗网络(GANs)不同,反向扩散模型通过逐步还原图像噪声的过程,能够生成高分辨率、细节丰富的图像。
本文将探讨基于反向扩散过程的高分辨率图像生成优化方法,重点分析其原理、挑战与优化策略,并通过代码实例演示如何实现一个简单的反向扩散模型。
反向扩散模型简介
反向扩散过程原理
反向扩散模型的核心思想是通过逐步将噪声添加到图像中,然后通过反向扩散过程将噪声去除,从而生成图像。该过程通常分为两步:
- 正向扩散过程:从真实图像开始,逐步添加噪声,直到最终变成纯噪声图像。
- 反向扩散过程:从噪声图像开始,逐步去除噪声,以恢复出清晰的图像。
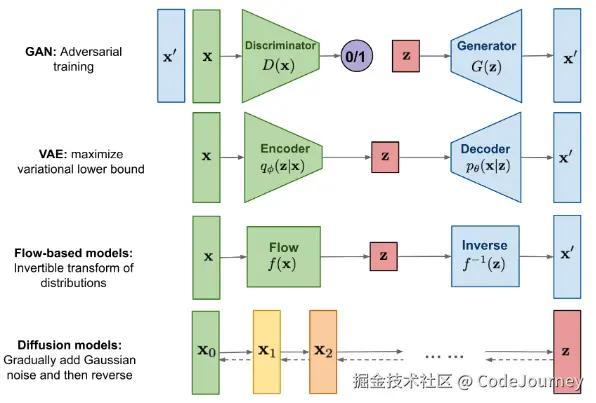
模型训练与生成
反向扩散模型的训练目标是通过最大化数据似然估计来优化去噪网络,即训练一个神经网络模型来预测图像在每个时间步的噪声分布。生成过程则从纯噪声开始,逐步去噪直至获得清晰图像。
高分辨率图像生成的挑战
尽管反向扩散模型在生成高质量图像方面表现出色,但在生成高分辨率图像时,仍面临着一些挑战:
- 计算开销大:高分辨率图像需要更多的扩散步骤和更大的模型容量,这使得训练和生成过程的计算量大大增加。
- 噪声去除精度要求高:随着图像分辨率的增加,反向扩散过程中的噪声去除精度变得至关重要。任何微小的噪声误差都可能影响图像的质量。
- 时间复杂度:为了获得更高的生成质量,通常需要更多的时间步(扩散步骤)。这对于高分辨率图像生成来说可能会导致长时间的生成过程。
高分辨率图像生成优化方法
1. 增强模型架构
为了处理高分辨率图像生成中的计算复杂度,通常需要通过增强模型的能力来提高生成效率。例如,可以使用更深的神经网络、更大的卷积核和更高效的神经网络架构。
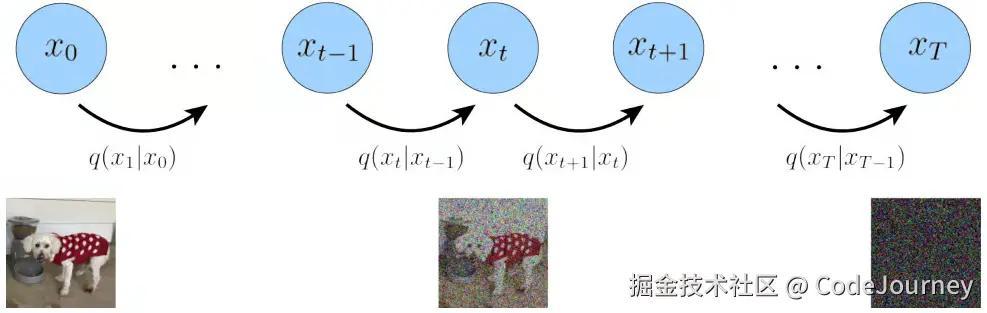
示例:改进的UNet架构
反向扩散模型中的生成网络通常采用类似于UNet的结构。为了优化高分辨率生成过程,我们可以通过增加网络深度、引入跳跃连接(skip connections)和注意力机制(attention mechanisms)来增强模型能力。
ini 代码解读复制代码import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3, base_channels=64):
super(UNet, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, base_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(base_channels, base_channels * 2, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(base_channels * 2, base_channels, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(base_channels, out_channels, kernel_size=3, stride=1, padding=1)
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
2. 多尺度扩散策略
在高分辨率图像生成中,使用多尺度扩散策略可以有效降低计算复杂度。通过在不同分辨率的图像上分别进行扩散,可以减少计算负担。通常在低分辨率图像上进行扩散训练,再逐渐将扩散过程扩展到更高分辨率的图像。
3. 利用预训练模型
利用在低分辨率图像生成任务中预训练的反向扩散模型,再进行高分辨率图像生成的微调,能够显著加快训练速度,并且提升高分辨率图像生成的质量。
4. 使用自适应噪声调度
自适应噪声调度算法可以根据图像的不同区域调整噪声添加和去除的策略。对于高分辨率图像而言,这种方法能够根据图像细节的复杂度动态调整扩散步骤,以便更高效地去噪。
代码实现:基于反向扩散的高分辨率图像生成
以下代码展示了如何实现一个简单的反向扩散生成模型,利用上述UNet结构生成高分辨率图像。
ini 代码解读复制代码import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 设置超参数
learning_rate = 1e-4
batch_size = 16
epochs = 10
# 定义图像预处理
transform = transforms.Compose([
transforms.Resize(128),
transforms.ToTensor(),
])
# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 初始化UNet模型
model = UNet(in_channels=3, out_channels=3, base_channels=64).cuda()
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
# 训练过程
for epoch in range(epochs):
model.train()
for i, (images, _) in enumerate(train_loader):
images = images.cuda()
# 随机生成噪声
noise = torch.randn_like(images).cuda()
# 生成图像
generated_images = model(noise)
# 计算损失
loss = criterion(generated_images, images)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Step [{i}/{len(train_loader)}], Loss: {loss.item():.4f}')
# 保存模型
torch.save(model.state_dict(), 'high_res_diffusion_model.pth')
代码解析
- 数据加载与预处理:使用
CIFAR-10数据集进行训练,图像大小被统一调整为128x128。 - 模型构建:基于UNet架构构建了一个简单的图像生成网络。
- 训练过程:使用MSELoss作为损失函数,随机生成噪声并通过UNet生成图像,计算损失并进行反向传播。
高分辨率图像生成中的性能提升方法
1. 高效的噪声去除策略
在高分辨率图像生成中,噪声的去除是至关重要的一步。由于高分辨率图像通常包含更多的细节,微小的噪声误差可能导致图像质量的大幅下降。因此,精确的噪声去除过程对生成结果的影响极大。为此,研究者们提出了几种噪声去除的优化策略。
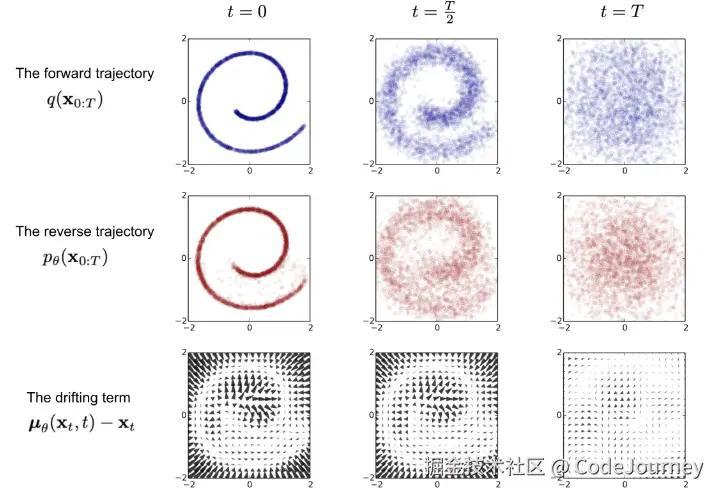
自适应噪声去除
传统的扩散模型通常在每个时间步中使用相同的噪声去除策略,而自适应噪声去除方法则根据每个区域的特征和噪声级别动态调整去噪的强度。自适应去噪网络可以根据不同区域的噪声水平对去噪网络进行调整,从而实现更细致的图像恢复。
例如,使用卷积神经网络(CNN)作为噪声去除模型时,可以在每个时间步中引入自适应卷积核,从而提高去噪效果。
代码示例:自适应噪声去除
以下是一个自适应噪声去除的代码示例,通过动态调整卷积核大小来增强图像的去噪能力。
ini 代码解读复制代码class AdaptiveNoiseRemoval(nn.Module):
def __init__(self, in_channels=3, base_channels=64):
super(AdaptiveNoiseRemoval, self).__init__()
self.conv1 = nn.Conv2d(in_channels, base_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(base_channels, base_channels * 2, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(base_channels * 2, in_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = self.conv1(x)
x = torch.relu(x)
x = self.conv2(x)
x = torch.relu(x)
x = self.conv3(x)
return x
# 动态调整卷积核大小(根据噪声水平)
def adaptive_conv_kernel(input_img, noise_level):
kernel_size = int(noise_level * 3) # 根据噪声水平调整卷积核大小
conv_layer = nn.Conv2d(3, 3, kernel_size=kernel_size, padding=kernel_size//2)
return conv_layer(input_img)
在这个例子中,通过自适应地调整卷积核大小,我们能够根据噪声水平动态优化去噪操作,从而提高生成图像的质量。
2. 使用多模态学习提升生成效果
生成高分辨率图像时,如何捕捉图像的多模态特征是一个重要的问题。图像生成往往不仅仅是图像重建的问题,还涉及到对图像语义和内容的理解。为此,研究者们提出了多模态学习的方法,它通过将不同模态的特征(如文本描述、标签信息等)融合到生成过程中,来提升图像的生成质量。
文本条件的反向扩散生成
通过引入条件信息(如文本描述)来辅助图像生成,可以帮助模型更好地理解图像的内容,从而生成更符合目标需求的高分辨率图像。将文本信息作为条件输入反向扩散模型,可以实现基于文本的高分辨率图像生成。
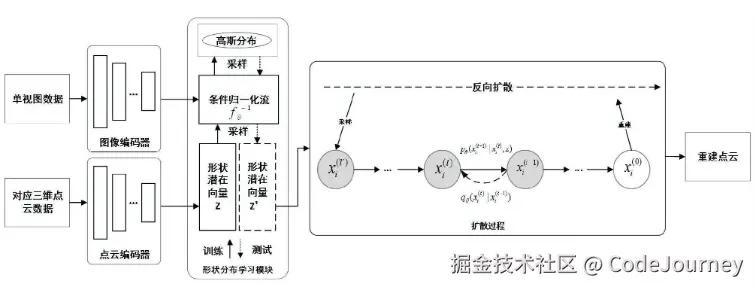
示例:文本条件的图像生成模型
下面是一个简单的代码示例,展示如何通过条件信息(例如文本)来生成图像。
ini 代码解读复制代码from transformers import CLIPTextModel, CLIPTokenizer
# 加载预训练的CLIP模型,用于将文本转换为条件向量
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch16")
text_model = CLIPTextModel.from_pretrained("openai/clip-vit-base-patch16")
def text_to_embedding(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
text_embeddings = text_model.get_input_embeddings()(inputs.input_ids)
return text_embeddings
# 将文本条件作为输入传入生成网络
class TextConditionedDiffusion(nn.Module):
def __init__(self, in_channels=3, text_embedding_dim=512):
super(TextConditionedDiffusion, self).__init__()
self.unet = UNet(in_channels=in_channels, out_channels=in_channels)
self.text_fc = nn.Linear(text_embedding_dim, in_channels * 128 * 128)
def forward(self, x, text_embeddings):
# 将文本嵌入向量转化为网络输入
text_features = self.text_fc(text_embeddings).view(-1, 3, 128, 128)
# 将图像与文本条件进行结合
x = x + text_features
return self.unet(x)
# 示例文本描述
text_description = "A scenic view of a mountain range during sunset"
text_embeddings = text_to_embedding(text_description)
# 使用文本条件进行图像生成
model = TextConditionedDiffusion()
generated_image = model(torch.randn(1, 3, 128, 128), text_embeddings)
3. 结合GAN优化反向扩散
尽管反向扩散模型在图像质量上有着很大的优势,但生成的图像往往缺乏清晰的结构或边缘,导致生成图像看起来较为模糊。为了克服这一缺点,许多研究者提出了将生成对抗网络(GAN)与反向扩散模型相结合的思路。通过将GAN作为判别器来优化反向扩散生成的图像,可以有效提高生成图像的细节和清晰度。
GAN增强的反向扩散模型
在这种方法中,反向扩散模型和GAN判别器协同工作:反向扩散模型生成图像,而GAN的判别器则用来评估生成图像的质量,并引导反向扩散模型在生成过程中更好地去除噪声。
示例:结合GAN与反向扩散
scss 代码解读复制代码class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.fc = nn.Linear(128 * 32 * 32, 1)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = x.view(x.size(0), -1) # Flatten the tensor
x = torch.sigmoid(self.fc(x)) # Return a probability
return x
class DiffusionWithGAN(nn.Module):
def __init__(self):
super(DiffusionWithGAN, self).__init__()
self.unet = UNet()
self.discriminator = Discriminator()
def forward(self, x):
generated_image = self.unet(x)
real_or_fake = self.discriminator(generated_image)
return generated_image, real_or_fake
# 训练循环
def train(model, dataloader, optimizer, discriminator_optimizer):
for images, _ in dataloader:
images = images.cuda()
# 生成图像
generated_images = model.unet(images)
# 判别器训练
real_labels = torch.ones(images.size(0), 1).cuda()
fake_labels = torch.zeros(images.size(0), 1).cuda()
discriminator_optimizer.zero_grad()
real_loss = nn.BCELoss()(model.discriminator(images), real_labels)
fake_loss = nn.BCELoss()(model.discriminator(generated_images.detach()), fake_labels)
d_loss = real_loss + fake_loss
d_loss.backward()
discriminator_optimizer.step()
# 生成器训练
optimizer.zero_grad()
g_loss = nn.BCELoss()(model.discriminator(generated_images), real_labels)
g_loss.backward()
optimizer.step()
return d_loss.item(), g_loss.item()
# 实例化模型与优化器
model = DiffusionWithGAN()
optimizer = optim.Adam(model.unet.parameters(), lr=1e-4)
discriminator_optimizer = optim.Adam(model.discriminator.parameters(), lr=1e-4)
4. 对抗性训练与超分辨率
生成高分辨率图像的另一个方向是超分辨率技术。反向扩散模型可以与超分辨率技术结合,通过对抗性训练,提升图像的分辨率和细节。通过训练模型生成低分辨率图像,并将其与高分辨率图像进行对比,利用对抗性损失提高生成图像的质量。
结论
反向扩散模型为高分辨率图像生成提供了一种新颖且强大的方法,但在实践中,我们仍面临着计算复杂度高、生成过程缓慢等问题。通过多种优化策略,如增强模型架构、引入多模
态信息、结合生成对抗网络等,可以有效提升图像生成的效果。随着技术的不断进步,未来的反向扩散生成模型将在更多应用场景中发挥重要作用。
评论记录:
回复评论: