
一、KAN网络介绍
1.1 Kolmogorov-Arnold Network (KAN)网络结构的提出
2024年4月,来自MIT、加州理工学院、东北大学等团队的研究,引爆了一整个科技圈:Yes We KAN! 这种创新方法挑战了多层感知器(Multilayer Perceptron,MLP) 的传统观点,为神经网络架构提供了全新的视角,GitHub上收获15k stars。

1.2 Kolmogorov-Arnold Network(KAN)名称由来
为了纪念两位伟大的已故数学家Andrey Kolmogorov和Vladimir Arnold,称其为科尔莫格罗夫-阿诺德网络(KAN) 。
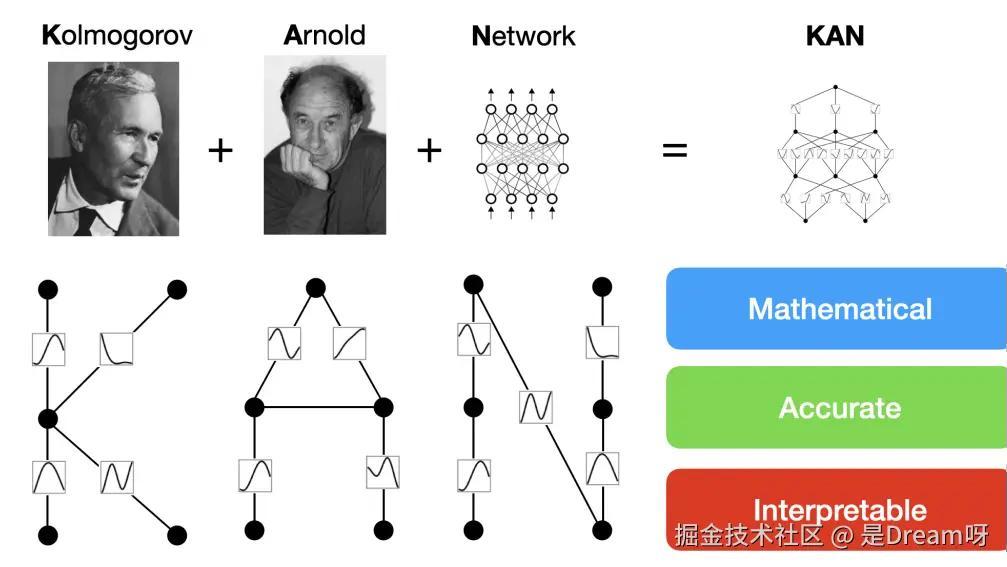
作者特别强调其有三个非常重要的特点:
- 在数学上是合理的
- 准确的
- 可解释的
1.3 从结构上对比
多层感知器(MLP): 全连接前馈神经网络,重要性怎么强调都不为过;神经元之间的连接是一个实数值,代表权重,而神经元本身配有一个非线性的激活函数;
KAN: 它没有将权重参数表示为一个实数,而是表示为一种B样条函数,这个样条函数直接连接两个神经元,代替了MLP中的线性权重;

与MLP类似,KAN具有全连接结构:
MLP在节点——「神经元」上具有固定的激活函数,
而KAN在边——「权重」上具有可学习的激活函数。
KAN的网络结构可以表示为:

其中,Φi表示第i层的变换,这些变换由可学习的激活函数组成,而不是传统的线性权重参数。这种设计允许KAN在网络的边缘采用可学习的激活函数,这些函数通常以样条函数形式参数化,从而提供了极高的灵活性,并能够用更少的参数来模拟复杂的函数,增强了模型的可解释性;
MLP的网络结构则可以表示为:

在MLP中,Wi表示线性权重参数,而σ表示非线性激活函数。MLP通过线性变换后跟非线性激活函数来处理数据,这种结构在深度学习中非常常见,因为它能够学习数据中的复杂模式。
KAN的公式强调了可学习的激活函数,这些函数在网络的边缘采用,与传统MLP中的固定激活函数形成对比。MLP的公式则侧重于线性权重参数和非线性激活函数的组合,这是其处理数据的基础。
B-样条: KAN的核心, KAN中的样条函数是其学习机制的核心,它们取代了神经网络中通常使用的传统权重参数。样条的灵活性使其能够通过调整其形状来适应性地建模数据中的复杂关系,从而最小化近似误差,增强了网络从高维数据集中学习细微模式的能力。
1.4 B样条函数介绍
样条函数(Spline Function) 是一种用于逼近或插值数据的平滑函数,它由分段多项式拼接而成,并且这些多项式在连接处具有一定的连续性(相当于通过分段多项式的组合,以在不牺牲光滑性的前提下精确地逼近或插值数据)。
样条函数分类:
1.线性样条:每个子区间上使用一阶多项式,即直线段它们在节点处具有零阶连续性,函数值连续,导数不连续;
2.二次样条:在每个子区间上使用二阶多项式,在节点处通常要求函数值和一阶导数连续;
3.三次样条:在每个子区间上使用三阶多项式;
4.B样条(B-spline):使用一组基函数来表示样条,每个基函数只在少数几个子区间非零。
B样条(B-spline)应用:
1.插值(Interpolation):即通过已知数据点来构造一条平滑曲线,以便在数据点之间进行估计;
2.数据拟合(Data Fitting):可以对大量噪声数据进行平滑处理,从而得到一个逼近数据的光滑函数;
3.计算机图形学(Computer Graphics):广泛用于图形和动画中,用于表示和控制复杂的曲线和曲面。
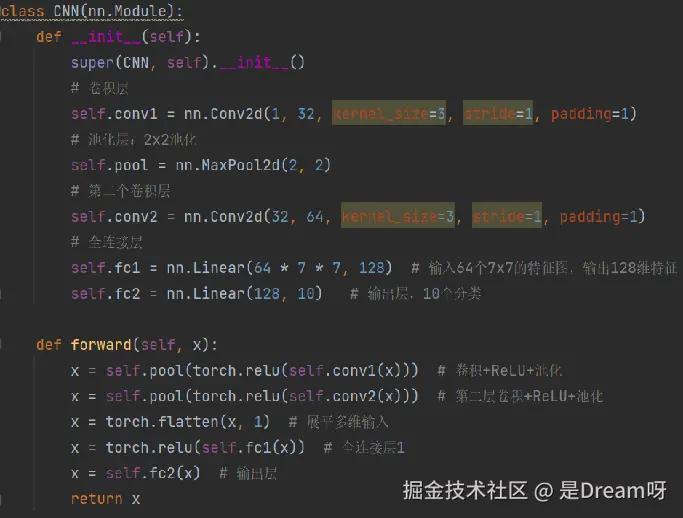
1.5 从代码上对比
CNN:
不需要展平,直接输入
组成:
卷积层+池化层+全连接层
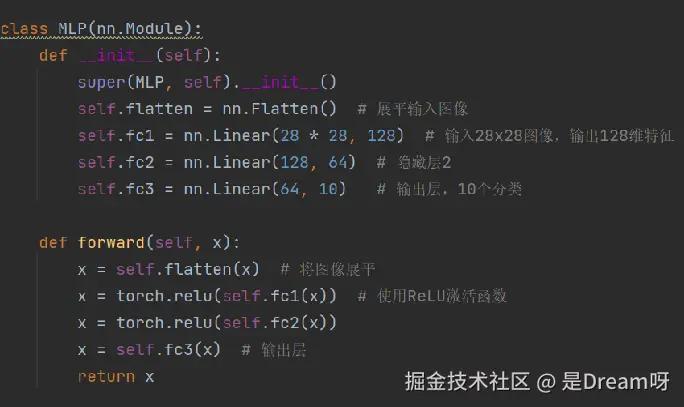
MLP:
需将图像展平为长向量
组成:
完全由全连接层组成
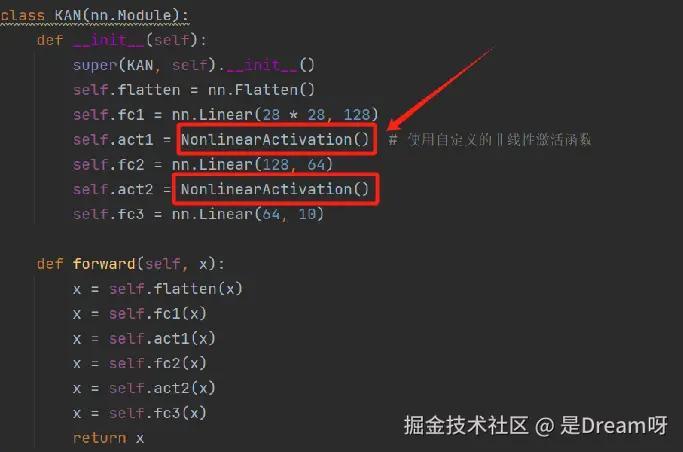
MLP 和 KAN 的实现是非常相似的:
都是由全连接层(Linear)和激活函数组成的网络;
MLP 网络使用传统的ReLU激活函数,KAN 网络使用了一个自定义的非线性激活函数。
1.6 从数学上对比
MLP的灵感来自于通用近似定理,即对于任意一个连续函数,都可以用一个足够深的神经网络来近似。
KAN则是来自于Kolmogorov-Arnold表示定理,每个多元连续函数都可以表示为单变量连续函数的两层嵌套叠加。表明任何复杂的“配方”都可以简化为基本的单一成分配方,然后以特定方式组合,如图所示:
其证明公式:
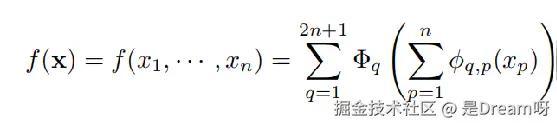
ϕqp(Xp)是单变量函数(简单的单成分配方),Φq采用单变量函数并将它们组合在一起。
定理指出,可以用2n+1个这样的外部函数——每个外部函数是一个一元函数(它作用于由内部一元函数组成的求和),来表示任何多变量函数;
进而,每个函数都可以用一元函数和求和来表示。
二、KAN网络仿真实验
2.1 仿真实验软硬件环境和参数配置
本次仿真实验要用到模型:CNN、MLP、MLP_KAN、KAN、 FastKAN、FasterKAN、ConvKAN。
重点模型解释:
MLP_KAN:是在MLP的基础上修改了激活函数;
FastKAN:通过径向基函数实现非常快的Kolmogorov-Arnold网络,用径向基函数(Radial basis function network)替换原始 KAN 中的 3 阶 B 样条基, RBF 函数很好地近似于 B 样条基,并且非常易于计算;
FasterKAN:使用 Fast-KAN 中的代码作为其基础,使用反射SWitch激活函数,这些 RSWAF 函数可以近似于 B 样条基,它们易于计算,同时具有均匀的网格;
ConvKAN:KAN卷积与卷积非常相似,但不是在内核和图像中的相应像素之间应用点积,而是对每个元素应用可学习非线性激活函数,然后相加。
实验首先在MNIST数据集和CIFAR-10数据集上进行了测试,然后在四种人体行为数据集上进行了测试,得到实验数据及可视化维度图。
以下是实验软硬件环境及参数配置:


2.2 模型在MNIST数据集上进行实验
MNIST数据集上不同模型准确率对比:
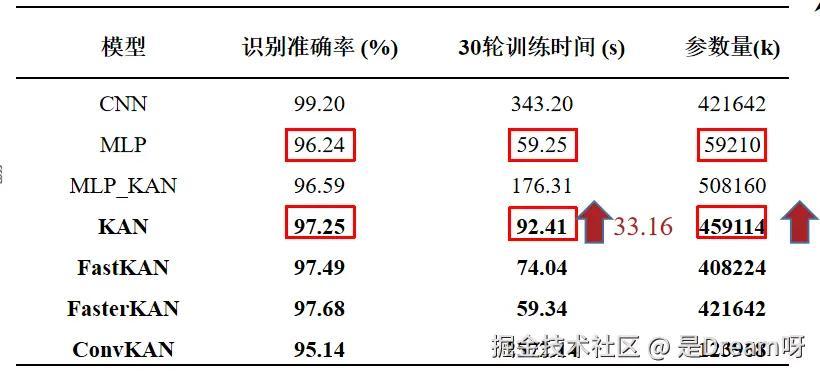
在使用不同的模型在MNIST数据集上的识别准确率以及参数量和训练时间,可以发现KAN与MLP相比准确率并没有很大的不同,但是训练时间和参数量KAN比MLP大得多。
2.3 模型在CIFAR-10数据集上进行实验
CIFAR-10数据集上不同模型准确率对比:
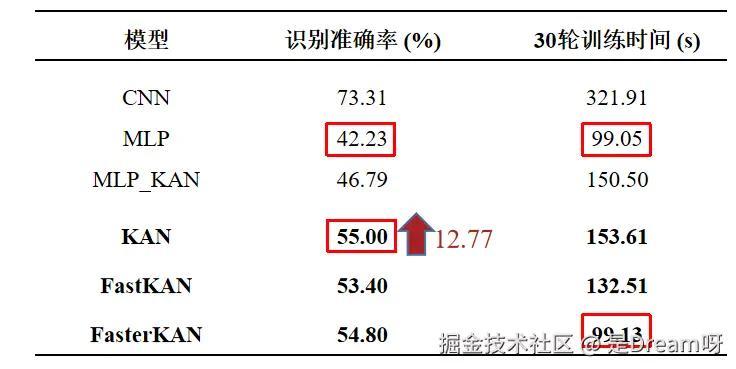
发现KAN比MLP在CIFAR-10数据集上的准确率高12.77%,表明其在复杂数据集上准确率要占优。
而对KAN进行优化过后的FasterKAN的训练时间达到了和MLP一样的效果。
2.4 KAN在MNIST数据集和CIFAR-10数据集的实验分析
质性分析:
- 模型复杂性:KAN模型可能在结构上更为复杂,因为它需要学习激活函数,这可能增加了模型的表达能力,但同时也增加了训练的难度和成本。
- 适用性:在简单数据集(如MNIST)上,KAN模型并没有显示出明显的优势,这可能是因为简单数据集的特征较为直观,传统模型如MLP已经足够有效。然而,在更复杂的数据集上,KAN模型的潜力得以展现,这表明更适合处理复杂任务。
- 训练速度:KAN模型的训练速度慢是一个明显的瓶颈,这与其结构复杂性有关。
- 参数量:KAN模型的参数量相对较多,这意味着它在某些任务上能够以较少的层数实现高精度,但小任务上不如MLP。
量化分析:
- 识别准确率:在MNIST数据集上,CNN模型的准确率最高(99.20%),而KAN模型的准确率为97.25%,略低于CNN,但高于MLP(96.24%)。在CIFAR-10数据集上,CNN模型的准确率(73.31%)高于KAN(55.00%),显示出在图像识别任务上,传统的CNN模型仍然具有优势。
- 训练时间:在MNIST数据集上,MLP模型的训练时间最短(59.25秒),而KAN模型的训练时间为92.41秒,显示出KAN模型在训练效率上的不足。在CIFAR-10数据集上,MLP模型的训练时间同样最短(99.05秒),而KAN模型的训练时间为153.61秒,进一步证实了KAN模型训练速度慢的问题。
- 参数量:在MNIST数据集上,MLP_KAN模型的参数量最大(508160),而KAN模型的参数量为459114,这表明KAN模型在参数量上相对较大,需要更多的计算资源。
2.5 KAN在WISDM数据集进行实验
WISDM数据集上不同模型准确率对比:
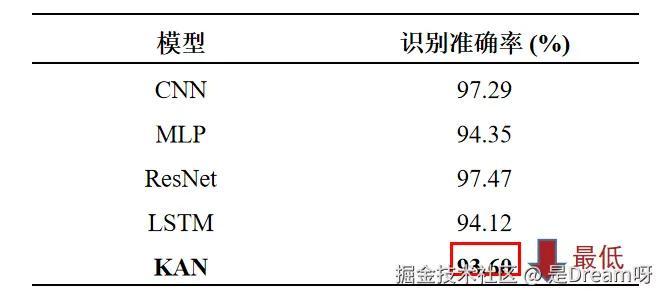
在使用不同的模型在WISDM数据集上的识别准确率,可以发现KAN与其他模型相比,识别准确率是最低的。
2.6 KAN在UCI-HAR数据集进行实验
UCI-HAR数据集上不同模型准确率对比:

在使用不同的模型在UCI-HAR数据集上的识别准确率,KAN与除MLP之外的模型相比,识别准确率不如其他模型,但是相较于MLP,KAN的识别准确率提高了0.92% 。
2.7 KAN在PAMAP2数据集进行实验
PAMAP2数据集上不同模型准确率对比:
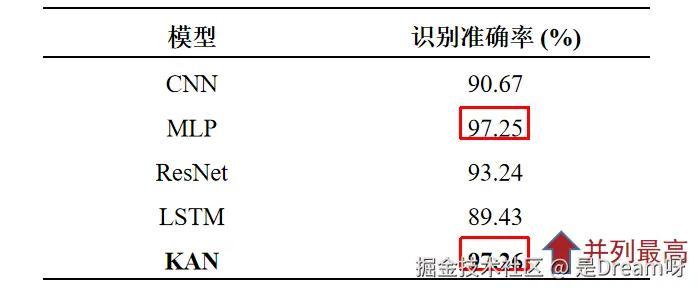
在使用不同的模型在PAMAP2数据集上的识别准确率,此时的识别准确率与其他模型相比相比,KAN和MLP都达到了最高。
2.8 KAN在OPPORTUNITY数据集进行实验
OPPORTUNITY数据集上不同模型准确率对比:
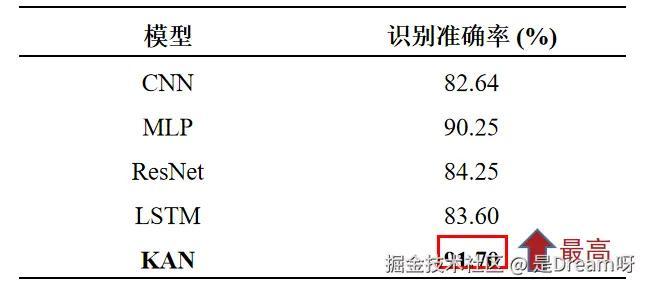
在使用不同的模型在OPPORTUNITY数据集上的识别准确率,KAN此时的识别准确率达到了最高,而且识别准确率比第二高的MLP都要多出1.45% 。
2.9 KAN在四种人体行为数据集上的实验分析
质性分析:
- 模型复杂性:KAN模型的复杂性源于其设计中包含的知识感知机制,这涉及到学习激活函数或其他高级特征。这种复杂性提高了模型的表达能力,但也可能增加了训练的难度和成本。
- 适用性:在人体行为识别任务中,KAN模型在PAMAP2数据集上的表现尤为突出,这表明它在处理复杂和多样化的行为模式时具有优势。这是因为人体行为数据通常包含丰富的时序信息和复杂的动态变化,KAN模型能够更好地捕捉这些特征。
- 训练速度:KAN模型的训练速度较慢,在实际应用中,这需要更多的计算资源和时间,尤其是在处理大规模数据集时。
- 参数量:KAN模型具有较多的参数,这有助于它在复杂任务上实现高精度。然而,在参数量和模型性能之间需要找到平衡,以避免过拟合和不必要的计算开销。
量化分析:
- 识别准确率:在提供的四个数据集中,KAN模型在PAMAP2数据集上达到了最高的准确率(97.26%),这表明它在处理该数据集的特定任务时非常有效。在其他数据集上,KAN的表现也相对稳定,平均准确率为94.115%。
- 参数量:KAN模型的复杂性暗示它具有较多的参数,这有助于提高模型的准确性,但也增加计算资源的需求。
2.10 KAN实验总结
1.模型复杂性与表达能力: KAN模型由于其知识感知机制和学习激活函数的设计,具有较高的模型复杂性。这种复杂性赋予了模型强大的表达能力,使其能够捕捉和学习数据中的复杂特征。然而,这也带来了训练难度的增加和对计算资源的更高需求。
2.适用性与任务匹配: KAN模型在处理复杂数据集,如PAMAP2人体行为数据集时,展现出了显著的优势,这表明它更适合于复杂任务。在简单数据集如MNIST上,KAN模型并未显示出明显优势,说明在简单任务上,传统模型可能更为合适。这提示我们在选择模型时需要考虑任务的复杂性和数据集的特性。
3.训练效率与资源需求: KAN模型的训练速度较慢,这在MNIST和CIFAR-10数据集的实验中得到了体现。较长的训练时间意味着在实际应用中可能需要更多的计算资源和时间投入。这一点在资源有限或对训练速度有要求的场景下需要特别考虑。
4.准确率与参数量的权衡: KAN模型在人体行为数据集上的平均准确率为94.115%,显示出良好的性能。同时,其较大的参数量有助于提高模型在复杂任务上的准确性,但也可能增加过拟合的风险和计算资源的需求。在实际应用中,需要在模型的准确性和参数量之间找到平衡点,以避免不必要的计算开销和过拟合问题。
综上所述,KAN模型在处理复杂任务时具有潜力,但在选择使用时需要考虑其对计算资源的需求、训练效率以及与任务特性的匹配度。在资源充足且任务复杂性高的情况下,KAN模型是一个值得考虑的选择。
三、为什么选择KAN网络模型
3.1 更小的参数和规模
在数据拟合任务上研究者发现:
一个中等规模的KAN(如256个隐藏单元)就可以达到或超过一个大规模MLP(如1024个隐藏单元)的性能,
而参数量仅为后者的六分之一左右。这表明,KAN能够用更紧凑的模型取得与大模型相当甚至更优的效果。
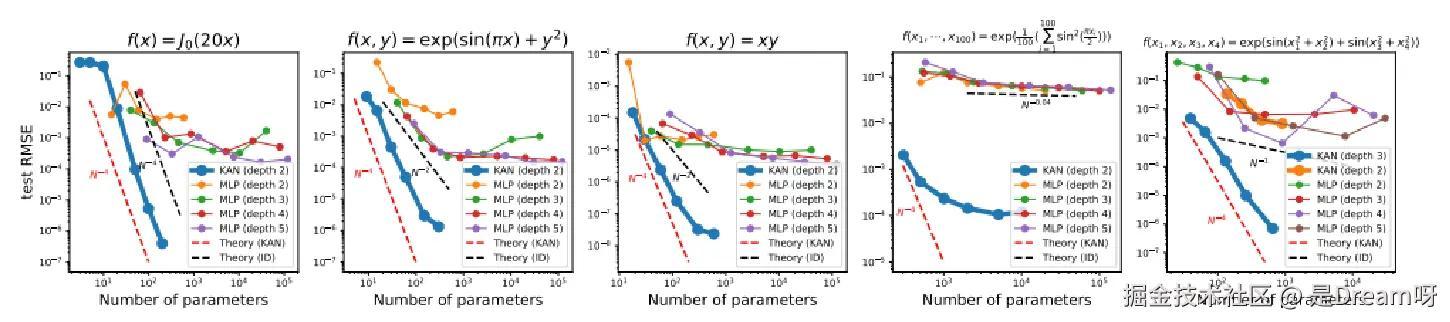
理论分析和实证结果均表明:
KAN具有比MLP更优越的神经缩放定律。随着模型规模的增大,KAN的性能提升速度显著快于MLP。当任务复杂度足够高时,要达到相同的准确率,所需的KAN规模远小于MLP,如下图作者得到的实验室数据 。
3.2 可解释性方面的优势
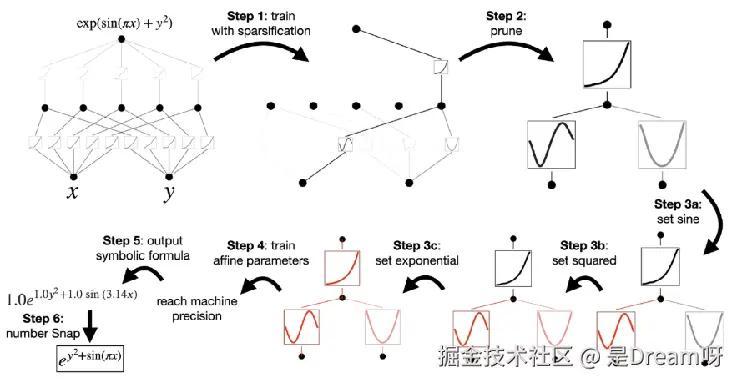
可解释性是KAN的另一大亮点。得益于简洁的结构和直观的权重函数,KAN非常容易可视化和解释。在解释之前,先通过稀疏正则化对KAN进行训练,然后剪枝,剪枝后的 KAN更容易解释。
3.2.1 稀疏化
线性权重被可学习的激活函数取代,因此需定义这些激活函数的 L1范数,激活函数的 L1 范数定义为其 Np个输入的平均幅度;单独L1范 数不足以实现 KAN 的稀疏化,还需要额外的熵正则化。
3.2.2 可视化
将激活函数 Φl,i,j的透明度设置为与 tanh(βAl,i,j) 成正比,β = 3 。
3.2.3 剪枝
经过稀疏化惩罚训练后,一般还需要将网络修剪成更小的子网。在节点级别对 KAN 进行稀疏化,所有不重要的神经元都被修剪。
3.2.4 符号化
如果猜测某些激活函数实际上是符号函数(例如cos或log),则提供一个接口将其设置为指定的符号形式,例如fix_symbolic(l,i,j,f) 可以设置 (l , i, j) 激活为 f。从样本中获得预激活x 和后激活y,并拟合仿射参数(a, b, c, d),使得 y ≈ cf (ax + b) + d。
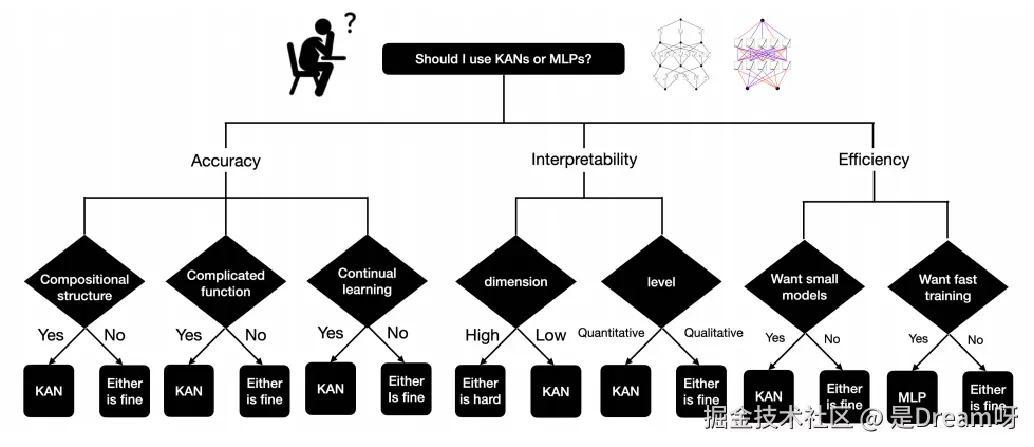
3.3 KAN提供新思路
KAN为神经网络的设计和应用开辟了一条全新道路。重新思考MLP的局限性,引入了革命性的改进——可学习的边激活函数。KAN提供了一种更简单高效的神经网络,在准确性和可解释性方面展现出巨大优势[5] 。
当前,以transformer为代表的大模型在众多领域一统江湖,但它们大都基于MLP构建,并未从根本上突破 MLP的桎梏,KAN为改进这些模型提供了新思路。KAN所特有的可解释性,带来更透明、更易理解的深度学习技术,提高人工智能的可信度,其潜力在未来有机会得到进一步的发掘。
3.4 KAN的争议与肯定
关于KAN的争议也没有停止,例如七月底新加坡国立大学的论文《KAN or MLP: A Fairer Comparison》发现KAN仅在符号公式表示方面优于MLP,但在机器学习、计算机视觉、NLP和音频处理等其他任务上仍低于 MLP。
但无论怎样,在通过堆砌越来越大的网络来提升 AI 性能的当下,KAN 探索深度学习底层新路线的精神是值得肯定的。

评论记录:
回复评论: