
之前给大家展示了如何部署Pro-GigaPath。 接下来就讲解一下该模型的基础用法。
这里以官方的demo文件为演示实例。
官方示例文件代码解读复制代码1_slide_mpp_check.py :检查图像是否符合要求 2_tiling_demo.py :将ndpi文件,切割为多个块 3_load_tile_encoder.py :检查模型的输出是否符合预期 4_load_slide_encoder.py :加载和打印一个预训练的病理学图像编码器模(slide_encoder)的参数数量。以下是代码的详细步骤和功能 gigapath_pac_visualization.ipynb :可视化模型特征提取的中间层 run_gigapath.ipynb :模型加载使用的全流程
1_slide_mpp_check.py
文件内容代码解读复制代码''' 该文件 用于检测图像是否符合要求 ''' import huggingface_hub import os from gigapath.preprocessing.data.slide_utils import find_level_for_target_mpp os.environ["HF_TOKEN"] = "令牌" assert "HF_TOKEN" in os.environ, "Please set the HF_TOKEN environment variable to your Hugging Face API token" local_dir = os.path.join(os.path.expanduser("~"), ".cache/") huggingface_hub.hf_hub_download("prov-gigapath/prov-gigapath", filename="sample_data/PROV-000-000001.ndpi", local_dir=local_dir, force_download=False) slide_path = os.path.join(local_dir, "sample_data/PROV-000-000001.ndpi") print("NOTE: Prov-GigaPath is trained with 0.5 mpp preprocessed slides") target_mpp = 0.5 level = find_level_for_target_mpp(slide_path, target_mpp) if level is not None: print(f"Found level: {level}") else: print("No suitable level found.")
注: 令牌为hugging face的令牌。不知道如何添加令牌的可以去看我的第一期教程。
Prov-GigaPath:病理基础模型 本地部署 及 使用 (一) 本地部署#Prov-GigaPath 代码的下载 - 掘金
关键部分:
python 代码解读复制代码target_mpp = 0.5
level = find_level_for_target_mpp(slide_path, target_mpp)
if level is not None:
print(f"Found level: {level}")
else:
print("No suitable level found.")
这段代码用于检查目标ndpi文件是否存在 像素微米量为0.5的层 。因为该模型训练时是用像素微米量为0.5进行训练的,因此预测图像最好也采用这个像素密度。
该代码可用于使用模型前的数据检查。
这段代码可以用于后面的使用。
2_tiling_demo.py
文件内容代码解读复制代码''' 该文件用于切割ndpi,为多个小块 ''' from gigapath.pipeline import tile_one_slide import huggingface_hub import os os.environ["HF_TOKEN"] = "令牌" assert "HF_TOKEN" in os.environ, "Please set the HF_TOKEN environment variable to your Hugging Face API token" local_dir = os.path.join(os.path.expanduser("~"), ".cache/") huggingface_hub.hf_hub_download("prov-gigapath/prov-gigapath", filename="sample_data/PROV-000-000001.ndpi", local_dir=local_dir, force_download=False) slide_path = os.path.join(local_dir, "sample_data/PROV-000-000001.ndpi") save_dir = os.path.join('./', 'outputs/preprocessing/') print("NOTE: Prov-GigaPath is trained with 0.5 mpp preprocessed slides. Please make sure to use the appropriate level for the 0.5 MPP") tile_one_slide(slide_path, save_dir=save_dir, level=1) print("NOTE: tiling dependency libraries can be tricky to set up. Please double check the generated tile images.")
本文件用于将一个ndpi文件切割为多个小块。
关键代码:
python 代码解读复制代码tile_one_slide(slide_path, save_dir=save_dir, level=1)
'''
slide_path: 目标文件的路径
save_dir: 要保存的文件夹
level: 图像金字塔的层数,level越大,单张照片越模糊,照片数量越多
'''
根据level将图像拆分成小块,并保存到本地。
3_load_tile_encoder.py
python 代码解读复制代码'''
用于检查输出与预期是否一致
'''
import timm
from PIL import Image
from torchvision import transforms
import torch
import os
os.environ["HF_TOKEN"] = "令牌"
assert "HF_TOKEN" in os.environ, "Please set the HF_TOKEN environment variable to your Hugging Face API token"
tile_encoder = timm.create_model("hf_hub:prov-gigapath/prov-gigapath", pretrained=True)
print("param #", sum(p.numel() for p in tile_encoder.parameters()))
transform = transforms.Compose(
[
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
]
)
img_path = "images/prov_normal_000_1.png"
sample_input = transform(Image.open(img_path).convert("RGB")).unsqueeze(0)
with torch.no_grad():
output = tile_encoder(sample_input).squeeze()
print("Model output:", output.shape)
print(output)
expected_output = torch.load("images/prov_normal_000_1.pt")
print("Expected output:", expected_output.shape)
print(expected_output)
assert torch.allclose(output, expected_output, atol=1e-2)
这个文件主要用于检查您的模型是否符合预期,只需要运行一遍,观察两个输出值是否相同即可。如果相同就说明没有问题。如果不相同,我也没办法😢
4_load_slide_encoder.py
python 代码解读复制代码'''
这段代码的主要功能是加载和打印一个预训练的病理学图像编码器模型(slide_encoder)的参数数量。以下是代码的详细步骤和功能
'''
import os
import gigapath.slide_encoder as slide_encoder
os.environ["HF_TOKEN"] = "令牌"
assert "HF_TOKEN" in os.environ, "Please set the HF_TOKEN environment variable to your Hugging Face API token"
# load from HuggingFace
# NOTE: CLS token is not trained during the pretraining
model_cls = slide_encoder.create_model("hf_hub:prov-gigapath/prov-gigapath", "gigapath_slide_enc12l768d", 1536, global_pool=False)
# load from HuggingFace with global pooling
model_global_pool = slide_encoder.create_model("hf_hub:prov-gigapath/prov-gigapath", "gigapath_slide_enc12l768d", 1536, global_pool=True)
print("param #", sum(p.numel() for p in model_global_pool.parameters()))
这段代码是教你如何加载模型的。
run_gigapath.ipynb
因为我的ipynb内核出现了问题,因此我将ipynb文件改为了py文件, 并对代码的一些细节进行了修改。该文件的代码可以看作是完整加载模型并进行预测的教程文档
这个文件里面的代码十分重要
文件内容代码解读复制代码''' 加载 和 使用模型。可以看成完整的教程 ''' import os import huggingface_hub from gigapath.pipeline import tile_one_slide from gigapath.preprocessing.data.slide_utils import find_level_for_target_mpp from gigapath.pipeline import load_tile_slide_encoder from gigapath.pipeline import run_inference_with_tile_encoder from gigapath.pipeline import run_inference_with_slide_encoder os.environ["HF_TOKEN"] = "令牌" assert "HF_TOKEN" in os.environ, "Please set the HF_TOKEN environment variable to your Hugging Face API token" # 下载演示图像,并进行切割 local_dir = os.path.join(os.path.expanduser("~"), ".cache/") huggingface_hub.hf_hub_download("prov-gigapath/prov-gigapath", filename="sample_data/PROV-000-000001.ndpi", local_dir=local_dir, force_download=False) slide_path = os.path.join(local_dir, "PROV-000-000001.ndpi") # 如果想预测自己的图像可以更改下面的值 slide_path = slide_path # 注:Prov-GigaPath 使用以 0.5 MPP 预处理的载玻片进行训练。确保为 0.5 MPP 使用适当的级别。 # 这里使用 1_slide_mpp_check.py 的方法检查图像 # 检查图像 mpp = 0.5 的层数 tmp_dir = './outputs/preprocessing/' # 分割后的图像保存的路径 target_mpp = 0.5 level = find_level_for_target_mpp(slide_path, target_mpp) if level is not None: print(f"mpp为0.5的层数是: {level}") else: raise EOFError('没有找到mpp为0.5的层数') tile_one_slide(slide_path, save_dir=tmp_dir, level=level) # 加载图片 slide_dir = "outputs/preprocessing/output/" + os.path.basename(slide_path) + "/" image_paths = [os.path.join(slide_dir, img) for img in os.listdir(slide_dir) if img.endswith('.png')] print(f"找到 {len(image_paths)} 个图像") # 模型加载 tile_encoder, slide_encoder_model = load_tile_slide_encoder(global_pool=True) # 运行平铺级别推理 tile_encoder_outputs = run_inference_with_tile_encoder(image_paths, tile_encoder) for k in tile_encoder_outputs.keys(): print(f"tile_encoder_outputs[{k}].shape: {tile_encoder_outputs[k].shape}") # run inference with the slide encoder slide_embeds = run_inference_with_slide_encoder(slide_encoder_model=slide_encoder_model, **tile_encoder_outputs) print(slide_embeds.keys()) for i in slide_embeds: print(i) print(slide_embeds[i].shape)
这里简单修改了一下文件内容,并添加了中文注释方便大家学习。
下面是对代码的拆解
文件加载
文件加载代码解读复制代码# 下载演示图像,并进行切割 local_dir = os.path.join(os.path.expanduser("~"), ".cache/") huggingface_hub.hf_hub_download("prov-gigapath/prov-gigapath", filename="sample_data/PROV-000-000001.ndpi", local_dir=local_dir, force_download=False) slide_path = os.path.join(local_dir, "sample_data/PROV-000-000001.ndpi") # 如果想预测自己的图像可以更改下面的值 slide_path = slide_path
官方给出的代码是从互联网上拉取的。
注:force_download 记得改为 False, 官方默认为 True 。当此参数为True 时,每次运行该代码都会对图像进行一次下载并覆盖掉本地文件。为False 时,但本地存在该文件时,就不再进行拉取。
如果我们不使用官方提供的demo文件,只想预测自己的图像,那么定义下面的变量就可。
slide_path = '目标图像的路径'
图像分割
由于ndpi文件太大,人类目前发明的模型都不能一次性读取如此庞大的图像,因此需要对图像进行分割,依次传入。(prov-gigapath 模型之所以厉害,就是它可以全局把握图像。因此你不需要担心分割后的图像会影响性能。当然,如果有个模型可以一次性读取ndpi文件当然比这个效果好,这只是一种妥协😭,人类加油!!)
先看代码:
图像分割代码解读复制代码tmp_dir = './outputs/preprocessing/' # 分割后的图像保存的路径 target_mpp = 0.5 level = find_level_for_target_mpp(slide_path, target_mpp) if level is not None: print(f"mpp为0.5的层数是: {level}") else: raise EOFError('没有找到mpp为0.5的层数') tile_one_slide(slide_path, save_dir=tmp_dir, level=level)
注: Prov-GigaPath 使用以 0.5 MPP 预处理的载玻片进行训练。确保为 0.5 MPP 使用适当的级别。
这里我参考了 2_tiling_demo.py 中的代码,加入自动识别level的机制。
python 代码解读复制代码target_mpp = 0.5
level = find_level_for_target_mpp(slide_path, target_mpp)
if level is not None:
print(f"mpp为0.5的层数是: {level}")
else:
raise EOFError('没有找到mpp为0.5的层数')
这里可以自动提取mpp = 0.5 的level
图片的加载与模型的加载
ini 代码解读复制代码# 加载图片
slide_dir = "outputs/preprocessing/output/" + os.path.basename(slide_path) + "/"
image_paths = [os.path.join(slide_dir, img) for img in os.listdir(slide_dir) if img.endswith('.png')]
print(f"找到 {len(image_paths)} 个图像")
# 模型加载
tile_encoder, slide_encoder_model = load_tile_slide_encoder(global_pool=True)
这个没什么好说的就是提前将模型 与 图像加载到内存中,为下一步做准备。
模型使用
scss 代码解读复制代码# 运行平铺级别推理
tile_encoder_outputs = run_inference_with_tile_encoder(image_paths, tile_encoder)
for k in tile_encoder_outputs.keys():
print(f"tile_encoder_outputs[{k}].shape: {tile_encoder_outputs[k].shape}")
# 运行滑动编码器推理
slide_embeds = run_inference_with_slide_encoder(slide_encoder_model=slide_encoder_model, **tile_encoder_outputs)
print(slide_embeds.keys())
for i in slide_embeds:
print(i)
print(slide_embeds[i].shape)
结果
结果代码解读复制代码dict_keys(['layer_0_embed', 'layer_1_embed', 'layer_2_embed', 'layer_3_embed', 'layer_4_embed', 'layer_5_embed', 'layer_6_embed', 'layer_7_embed', 'layer_8_embed', 'layer_9_embed', 'layer_10_embed', 'layer_11_embed', 'layer_12_embed', 'last_layer_embed']) layer_0_embed torch.Size([1, 768]) layer_1_embed torch.Size([1, 768]) layer_2_embed torch.Size([1, 768]) layer_3_embed torch.Size([1, 768]) layer_4_embed torch.Size([1, 768]) layer_5_embed torch.Size([1, 768]) layer_6_embed torch.Size([1, 768]) layer_7_embed torch.Size([1, 768]) layer_8_embed torch.Size([1, 768]) layer_9_embed torch.Size([1, 768]) layer_10_embed torch.Size([1, 768]) layer_11_embed torch.Size([1, 768]) layer_12_embed torch.Size([1, 768]) last_layer_embed torch.Size([1, 768])
这里根据可以提取需要的layer,越往后提取出的特征越抽象,越往前越接近人类的视觉。如果要进行分类,可以直接使用last_layer_embed的数据。然后,连接一个分类器使用即可。
gigpath_pac_visualization.py
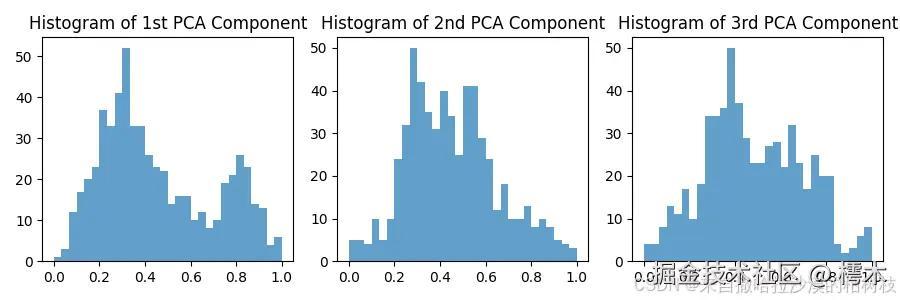
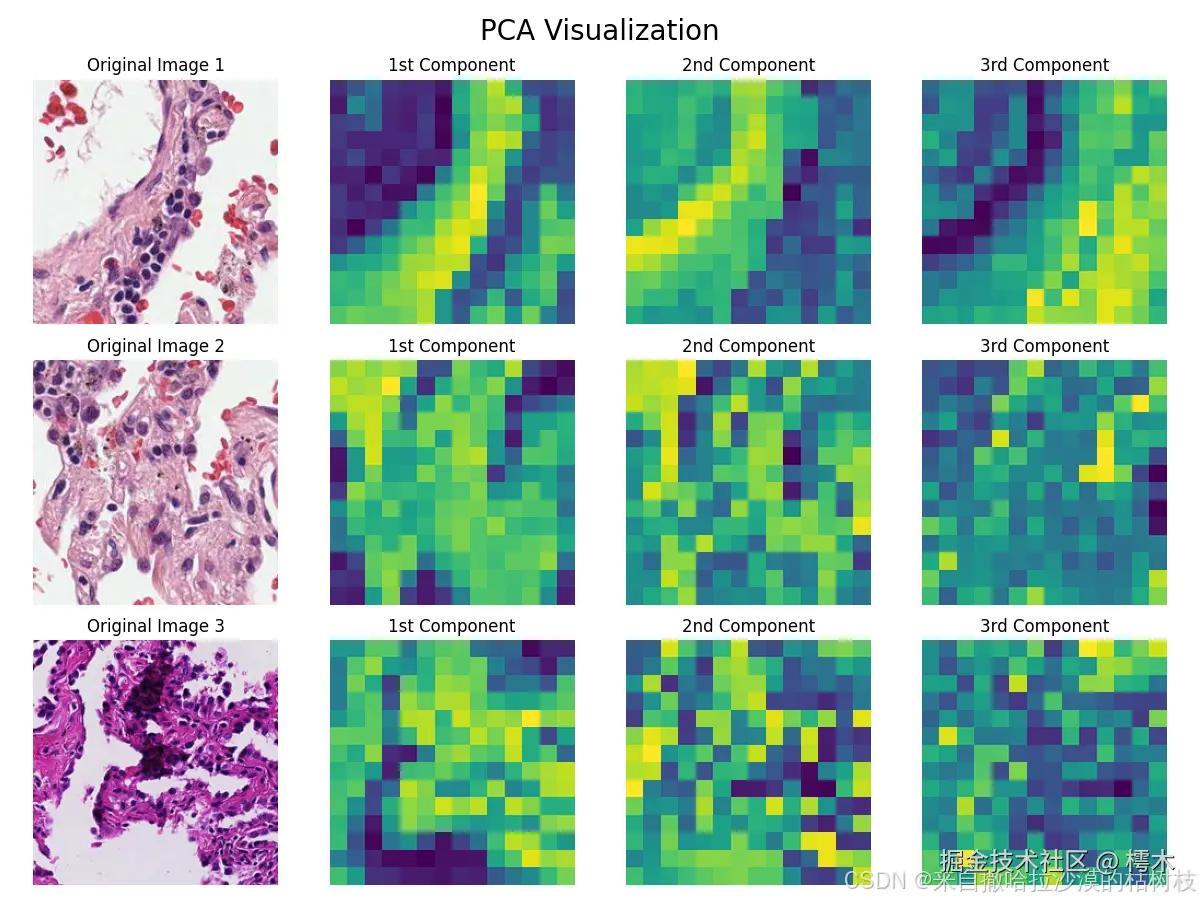
该文件主要演示了,模型主成分提取的功能,并与原图进行了融合。
和上一个文件一样,这里将ipynb文件转化为了py文件
ini 代码解读复制代码import os
import timm
import torch
import numpy as np
from PIL import Image
import torchvision.transforms as transforms
from sklearn.decomposition import PCA
from sklearn.preprocessing import MinMaxScaler
from typing import List
import cv2
import matplotlib.pyplot as plt
# 令牌设置
os.environ["HF_TOKEN"] = "令牌"
assert "HF_TOKEN" in os.environ, "Please set the HF_TOKEN environment variable to your Hugging Face API token"
# 常量配置
DEVICE = 'cuda'
NUMBER_COMPONENTS = 3
image_paths = [
"./images/01581x_25327y.png",
"./images/01581x_25583y.png",
'images/P301503_53248_50176_11264_23552_11776_24064.jpg'
]
output_path = './outputs'
# 模型创建
model = timm.create_model("hf_hub:prov-gigapath/prov-gigapath", pretrained=True)
device = DEVICE
model.to(device)
# 用于对图像进行归一化
# 统一图像大小
transform = transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
def load_and_preprocess_image(image_path: str) -> Image.Image:
'''
用于打开图像
'''
with open(image_path, 'rb') as f:
img = Image.open(f).convert('RGB')
return img
pca = PCA(n_components=3) # 设置主成分降维的数量
scaler = MinMaxScaler(clip=True)
def process_images(images: List[Image.Image], background_threshold: float = 0.5, larger_pca_as_fg: bool = False) -> List[np.ndarray]:
imgs_tensor = torch.stack([transform(img).to(device) for img in images])
with torch.no_grad():
# 获取模型中间特征,intermediates_only=True 表示只获取中间特征
intermediate_features = model.forward_intermediates(imgs_tensor, intermediates_only=True)
# 将最后一层的特征转换为合适的形状
features = intermediate_features[-1].permute(0, 2, 3, 1).reshape(-1, 1536).cpu()
# 对特征进行 PCA 降维,并使用缩放器进行缩放
pca_features = scaler.fit_transform(pca.fit_transform(features))
# 根据 larger_pca_as_fg 标志判断前景索引
if larger_pca_as_fg:
# 如果 larger_pca_as_fg 为 True,则前景是大于背景阈值的
fg_indices = pca_features[:, 0] > background_threshold
else:
# 否则,前景是小于背景阈值的
fg_indices = pca_features[:, 0] < background_threshold
# 使用前景索引提取前景特征
fg_features = pca.fit_transform(features[fg_indices])
# 对前景特征进行缩放
scaler.fit(fg_features)
normalized_features = scaler.transform(fg_features)
# 准备结果图像,假设每张图像被划分为 14x14 的小块
result_img = np.zeros((imgs_tensor.size(0) * 196, 3))
# 将归一化的前景特征填入结果图像
result_img[fg_indices] = normalized_features
# 将 imgs_tensor 移动到 CPU 以便后续处理
imgs_tensor = imgs_tensor.cpu()
transformed_imgs = []
# 对每张图像进行处理,将张量转换为 NumPy 数组并反归一化
for i, img in enumerate(imgs_tensor):
img_np = img.permute(1, 2, 0).numpy() # 转换维度为 (高, 宽, 通道)
img_np = (img_np * np.array([0.229, 0.224, 0.225])) + np.array([0.485, 0.456, 0.406]) # 反归一化
img_np = (img_np * 255).astype(np.uint8) # 转换为 8 位无符号整数
transformed_imgs.append(img_np) # 添加到结果列表
# 将结果图像重塑为每张输入图像的形状
results = [result_img.reshape(imgs_tensor.size(0), 14, 14, 3)[i] for i in range(len(images))]
# 返回结果,包含处理后的图像、变换后的图像和 PCA 特征
return results, transformed_imgs, pca_features
images = [load_and_preprocess_image(path) for path in image_paths]
results, transformed_imgs, pca_features = process_images(images, larger_pca_as_fg=False)
# 查看主成分分析的结果
def create_overlay_image(original, result, alpha=0.3):
# Resize result to match the original image size
result_resized = cv2.resize(result, (original.shape[1], original.shape[0]))
overlay = (alpha * original + (1 - alpha) * result_resized * 255).astype(np.uint8)
return overlay
num_images = len(transformed_imgs)
fig, axes = plt.subplots(num_images, 3, figsize=(9, 3 * num_images))
for i, (image, result) in enumerate(zip(transformed_imgs, results)):
overlay = create_overlay_image(image, result)
# Original image
axes[i, 0].imshow(image)
axes[i, 0].set_title(f"Original Image {i+1}")
axes[i, 0].axis('off')
# PCA result image
axes[i, 1].imshow(result)
axes[i, 1].set_title(f"Foreground-Only PCA for Image {i+1}")
axes[i, 1].axis('off')
# Overlay image
axes[i, 2].imshow(overlay)
axes[i, 2].set_title(f"Overlay for Image {i+1}")
axes[i, 2].axis('off')
#fig.suptitle('PCA Visualizations', fontsize=20)
plt.tight_layout()
plt.savefig(os.path.join(output_path,'PCA.png'))
plt.close()
plt.figure(figsize=(9, 3))
plt.subplot(1, 3, 1)
plt.hist(pca_features[:, 0], bins=30, alpha=0.7)
plt.title('Histogram of 1st PCA Component')
plt.subplot(1, 3, 2)
plt.hist(pca_features[:, 1], bins=30, alpha=0.7)
plt.title('Histogram of 2nd PCA Component')
plt.subplot(1, 3, 3)
plt.hist(pca_features[:, 2], bins=30, alpha=0.7)
plt.title('Histogram of 3rd PCA Component')
plt.tight_layout()
plt.savefig(os.path.join(output_path,'histogram_of_PCA.png'))
plt.close()
patch_h, patch_w = 14, 14
fig, axes = plt.subplots(num_images, 4, figsize=(12, 3 * num_images))
for i in range(num_images):
# Original image
axes[i, 0].imshow(transformed_imgs[i])
axes[i, 0].set_title(f"Original Image {i+1}")
axes[i, 0].axis('off')
# First component
component1 = pca_features[i * patch_h * patch_w : (i + 1) * patch_h * patch_w, 0].reshape(patch_h, patch_w)
axes[i, 1].imshow(component1, cmap='viridis_r')
axes[i, 1].set_title(f'1st Component')
axes[i, 1].axis('off')
# Second component
component2 = pca_features[i * patch_h * patch_w : (i + 1) * patch_h * patch_w, 1].reshape(patch_h, patch_w)
axes[i, 2].imshow(component2, cmap='viridis_r')
axes[i, 2].set_title(f'2nd Component')
axes[i, 2].axis('off')
# Third component
component3 = pca_features[i * patch_h * patch_w : (i + 1) * patch_h * patch_w, 2].reshape(patch_h, patch_w)
axes[i, 3].imshow(component3, cmap='viridis_r')
axes[i, 3].set_title(f'3rd Component')
axes[i, 3].axis('off')
# RGB visualization
# rgb_image = np.stack((component3, component2, component1), axis=-1)
# axes[i, 4].imshow(rgb_image)
# axes[i, 4].set_title(f'RGB Visualization')
# axes[i, 4].axis('off')
fig.suptitle('PCA Visualization', fontsize=20)
plt.tight_layout()
plt.savefig(os.path.join(output_path,'PCA_Visualization.png'))
plt.close()
这个我就不详细解释了,想了解模型使用细节的可以看run_gigapath.ipynb文件的拆解。
这里,我使用了两张官方自带的图像,和一张我自己的图像。下面是效果展示
结论
因为,prov-gigapath 为基础模型,只能进行进行特征提取,还不能进行预测,需要配合上游模型使用。我阅读了好几次官方论文也没有找到官方使用的上游模型是什么。这里怀疑官方就是简单的加了一个输出层。附上官方论文的地址:基于真实世界数据的数字病理学全玻片基础模型 |自然界
如果,有人发现了什么,欢迎私信我,也欢迎有人找我交流。
评论记录:
回复评论: