
上一篇完成DPO的训练,但是模型的输出效果不好,因此在找原因,于是将理论重新过一遍,以发现每个环节需要优化的地方,本文就是理论知识:《Transformer模型中的位置编码》。
1、什么是位置编码
在语言中,一句话是由词组成的,词与词之间是有顺序的,如果顺序乱了或者重排,其实整个句子的意思就变了,所以词与词之间是有顺序的。
在循环神经网络中,序列与序列之间也是有顺序的,所以循环神经网络中,序列与序列之间也是有顺序的,不需要处理这种问题。
但是在Transformer中,每个词是独立的,所以需要将词的位置信息添加到模型中,让模型维护顺序关系。
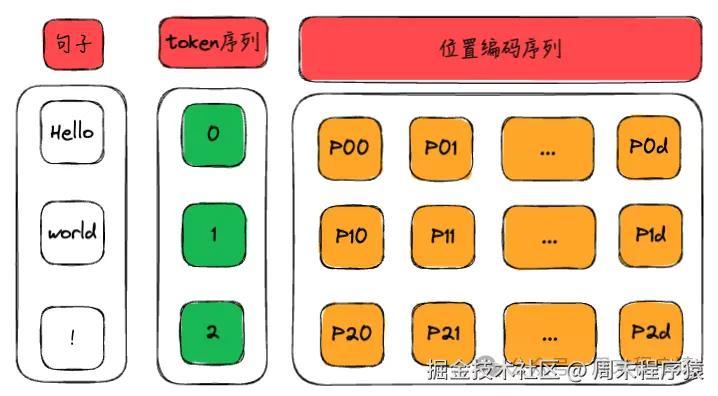
位置编码就是将hello world! 的token和位置关系通过向量表示出来,作为训练的输入数据,如上图,位置编码最终会变成:
csharp 代码解读复制代码[
[P00, P01, P02 ... P0d],
[P10, P11, P12 ... P1d],
[P20, P21, P22 ... P2d],
]
2、计算位置编码
计算位置编码有多种方式:固定位置编码,相对位置编码,绝对位置编码,其中Transformer的作者设计了一种三角函数位置编码方式,通过三角函数计算输出位置编码向量。
为什么三角函数可以作为计算位置编码的函数?
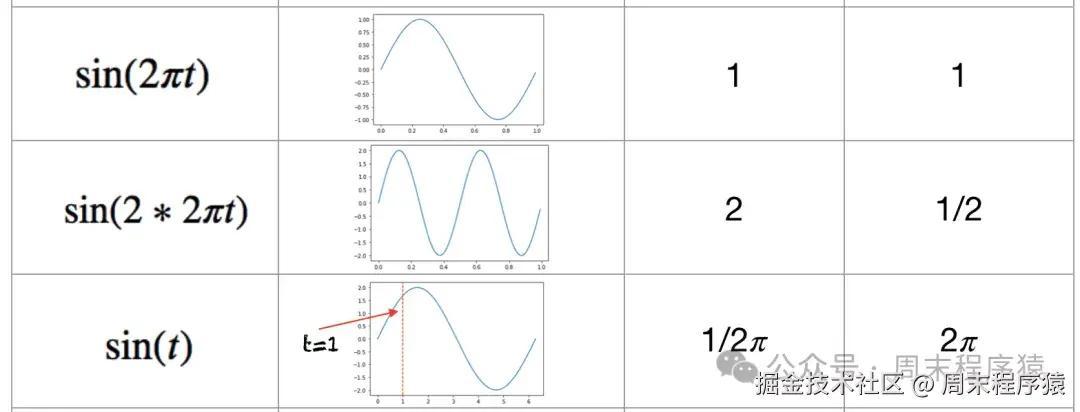
- 首先我们来回顾一下三角函数的基本性质:函数具有周期性,取值范围是[-1, 1]。
- 其次,如果用绝对位置编码计算最大序列为3的位置(0-7),二进制表示如下:
csharp 代码解读复制代码[
[0, 0, 0],
[0, 0, 1],
[0, 1, 0],
[0, 1, 1],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0],
[1, 1, 1]
]
从上可以表示看出,较高比特位的交替频率低于较低比特位,存在周期性bit位变化,符合三角函数的周期性,而且三角函数的取值范围是[-1, 1],输出浮点数,并且数据连续,比直接使用二进制更节省空间。
3、Transformer中的位置编码层
假设你有一个长度为L的输入序列,要计算第K个元素的位置编码,位置编码由不同频率的正弦和余弦函数给出:
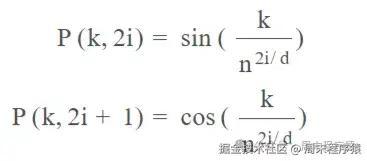
- k:词序列中的第K个元素
- d:词向量维度,比如512,1024,8K等
- P(k, i):位置函数,输出位置编码向量
- n:定义的标量,Attention Is All You Need 的作者设置为 10,000
- i:映射到列索引,范围是0
d/2(由于输入是2i表示,如果用i表示,范围可以是0d)
按照上述Hello world!的例子,计算位置编码结果如下:
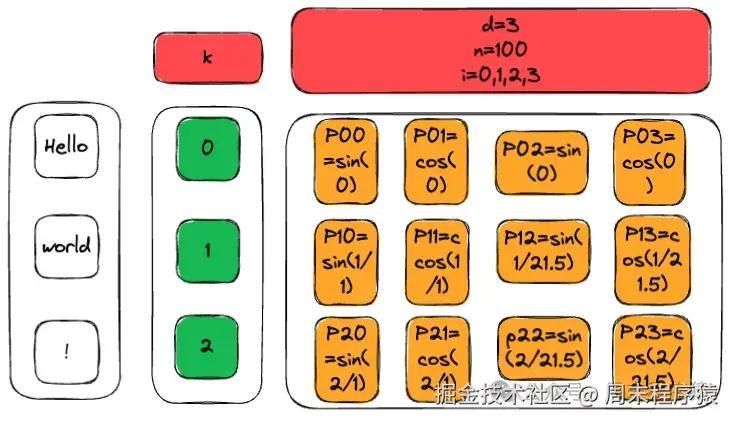
那么用代码实现一个简化版本的位置编码:
ini 代码解读复制代码import numpy as np
def getPositionEncoding(seq_len, d, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=3, d=3, n=100)
print(P)
# 输出结果:
[[ 0. 1. 0. ]
[ 0.84147098 0.54030231 0. ]
[ 0.90929743 -0.41614684 0. ]]
4、大模型训练中的位置编码代码
在我们从0训练大模型中,其位置编码的实现如下:
python 代码解读复制代码def precompute_pos_cis(dim: int, seq_len: int, theta: float = 10000.0):
"""预计算相对位置编码的复数形式,用于旋转位置编码(RoPE)。"""
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)) # 计算频率
t = torch.arange(seq_len, device=freqs.device) # 创建时间步长
freqs = torch.outer(t, freqs).float() # 计算频率的外积
pos_cis = torch.polar(torch.ones_like(freqs), freqs) # 生成复数形式的频率
return pos_cis # 返回预计算的复数位置编码
def apply_rotary_emb(xq, xk, pos_cis):
"""应用旋转位置编码到查询和键。"""
def unite_shape(pos_cis, x):
"""调整位置编码的形状以匹配输入张量的形状。"""
ndim = x.ndim # 获取输入的维度
assert 0 <= 1 < ndim # 确保维度有效
assert pos_cis.shape == (x.shape[1], x.shape[-1]) # 确保位置编码形状匹配
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)] # 生成新形状
return pos_cis.reshape(*shape) # 调整位置编码的形状
# 将查询和键转换为复数形式
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
pos_cis = unite_shape(pos_cis, xq_) # 调整位置编码形状
xq_out = torch.view_as_real(xq_ * pos_cis).flatten(3) # 应用位置编码并转换回实数
xk_out = torch.view_as_real(xk_ * pos_cis).flatten(3) # 同上
return xq_out.type_as(xq), xk_out.type_as(xk) # 返回与输入类型一致的输出
这里使用的是RoPE旋转位置编码,和相对位置编码相比,RoPE 具有更好的外推性,Meta 的 LLAMA 和 清华的 ChatGLM 都使用该编码,目前是大模型相对位置编码中应用最广的方式之一,具体原理由于篇幅原因就不讲了,可以看看这篇文章:cloud.tencent.com/developer/a…
评论记录:
回复评论: