
Hammer模型提出了一种创新的Function Calling模型训练方法,其中核心思想之一是通过函数和参数命名的调整来增强模型的鲁棒性,减少因命名模糊性或不一致性引发的错误。
 你好啊,我是小智,今天我将详细解析Hammer模型如何通过函数名和参数名的修改,数倍提升模型在Function Calling任务中的准确性。
你好啊,我是小智,今天我将详细解析Hammer模型如何通过函数名和参数名的修改,数倍提升模型在Function Calling任务中的准确性。
改名提升模型性能,看似玄学也有依据
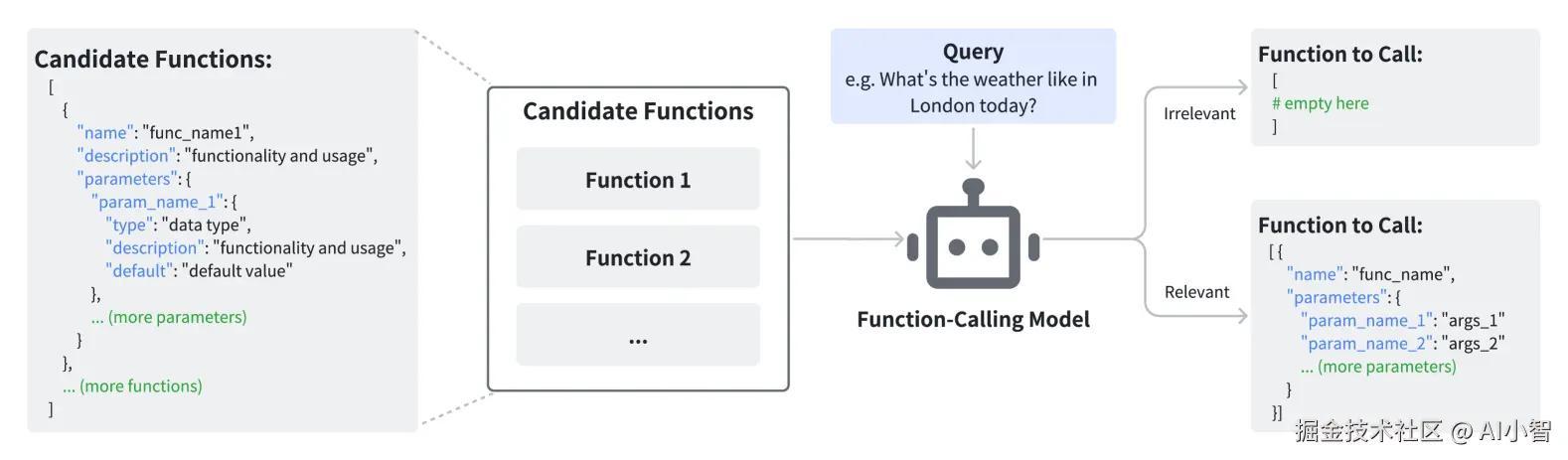
简洁命名的模糊性
在大多数编程语言中,函数名和参数名都是对功能的抽象表达。通常情况下,简洁的命名规则便于代码阅读与理解,但当这些简洁的命名被直接作为模型输入时,可能会导致一定程度的模糊性。例如,假设我们有一个名为get_data的函数,该函数可能用于从数据库、文件或网络获取数据,但不同的上下文可能会让模型难以判断其真正用途。
特别是在存在复杂功能的情况下,简洁的命名约定可能导致误导。例如,save可能表示保存文件、保存数据,甚至是提交数据库事务。此时,模型仅依赖函数名推断函数目的时,简洁命名反而可能降低准确性。
同名参数的误导性
同样,函数参数名的命名惯例也可能影响模型的判断。在数据集中,不同的函数可能使用相同或类似的参数名,导致模型在推断过程中受到历史数据的干扰。比如,data或input等参数名可能在不同的函数中具有完全不同的含义,但如果模型只依据参数名来推断其用途,可能会引发错误推断。
命名约定的不一致性
在实际开发中,命名约定常常因团队、项目或语言的不同而存在差异。例如,驼峰式命名(CamelCase)和下划线式命名(snake_case)在同一数据集中可能并存。如果训练数据集中的命名方式与测试环境中的不一致,模型的表现可能会受到负面影响。在这种情况下,模型可能无法准确理解不同命名方式的函数或参数,影响其调用的准确性。
Schema描述更加准确有力
Schema描述提供了更灵活的自然语言解释,往往更准确和详细,并通常包含函数和参数名称旨在传达的信息"。
函数和参数名称的简洁和简洁格式可能会导致歧义,并误导模型的理解,特别是在存在复杂功能的情况下。相比之下,描述提供了对函数作用和预期行为的更全面的视角,超越了函数和参数名称所能传达的内容。通过关注描述而不是名称,模型可以更准确地把握函数的意图,并避免训练数据中特定命名模式引入的陷阱。
如何实现改名后的模型训练
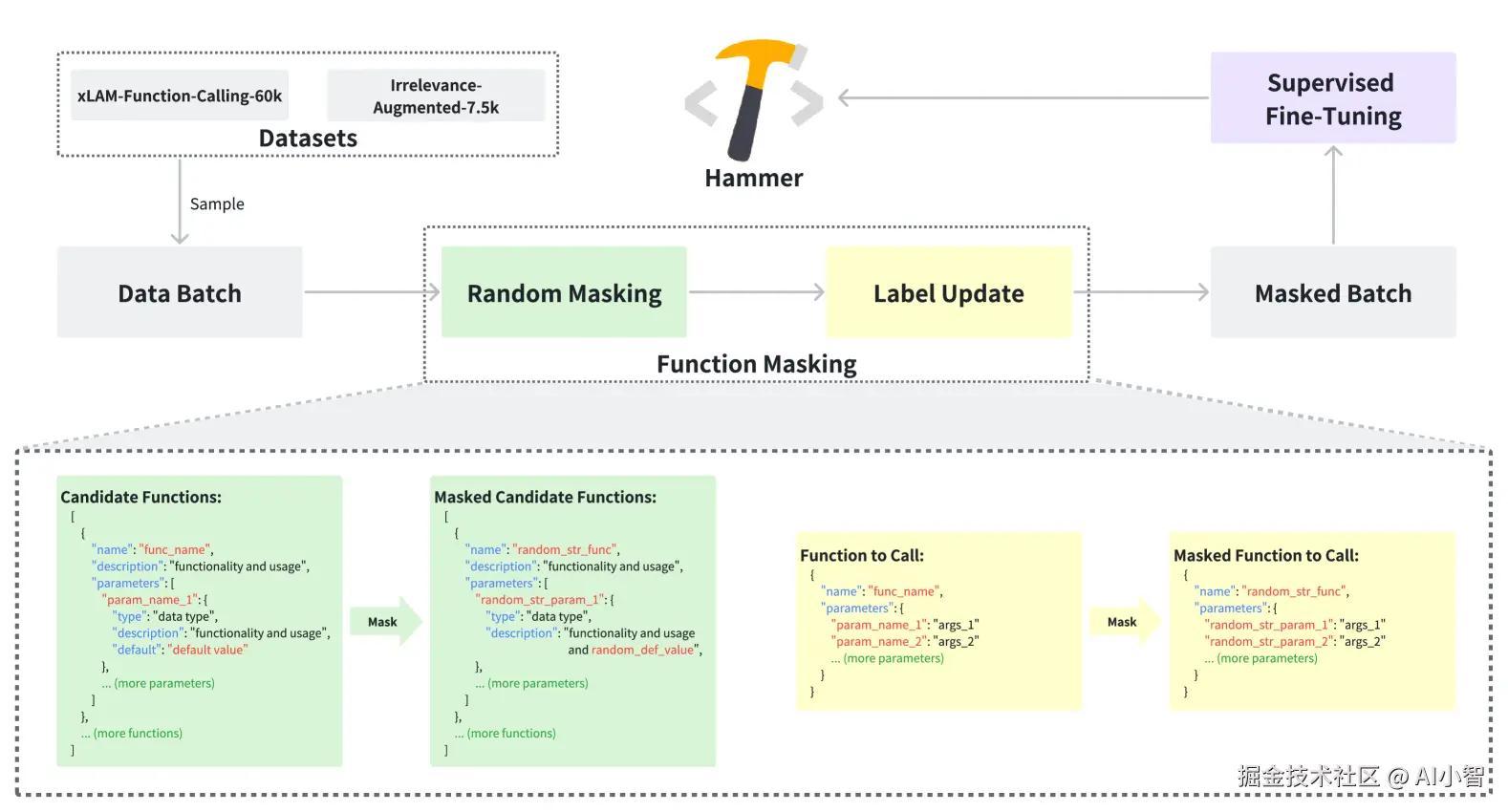
增强数据集:微调与多样性提升
为了提升函数调用准确率,Hammer模型采用了增强数据集的策略。在此方法中,模型通过对数据集进行扩展,尤其是在xLAM-function-calling-60k数据集上增加了7,500个实例,这些实例专注于检测无关性,从而使得模型能够更好地区分相关和无关的函数调用。
通过这种增强方式,模型能够更好地处理在训练集和测试集之间存在的命名不一致性。对数据集的微调不仅提高了模型对函数名的敏感度,也让模型学会了如何忽略无关的参数和函数。
函数屏蔽:减少对名称的依赖
Hammer模型采用了函数屏蔽技术,在训练过程中随机将候选函数名称替换为随机字符串。这一策略的核心思想是使得模型更关注函数的功能描述,而非函数名称。这种方式迫使模型理解函数的功能,而不仅仅是通过名称来推测其目的。
具体来说,模型通过仅仅理解函数的输入输出及其描述来进行函数调用,而非依赖可能模糊或误导的名称信息。例如,在训练过程中,模型可能会遇到如下两种情况:
- 原始命名:
get_user_data(user_id) - 屏蔽后的命名:
function_1234(arg1)
在屏蔽后的训练过程中,模型不会通过get_user_data来猜测其功能,而是通过函数描述或参数来推断其功能。
函数描述的优化
除去函数名本身,函数描述也是模型理解函数目的的重要线索。通过增强训练集中的函数描述,并将这些描述与输入输出匹配,模型能够更好地学习到函数的实际功能。这一过程涉及到对数据集的精细化处理,使得每个函数都附带一个尽可能详细的描述。
这种优化策略,结合函数屏蔽和增强数据集的手段,能有效提升模型对函数调用的准确性和鲁棒性。
启发
高质量数据是金矿
在任何机器学习任务中,高质量数据都至关重要。而数据的质量不仅仅体现在标注的准确性,还包括数据的多样性和丰富性。Hammer模型的成功不仅仅在于使用了大规模的数据集,更在于对已有数据进行了精细化的改造和优化。作为AI工程师,我们应该从数据源的多样性和质量上投入更多精力,而不仅仅关注模型的复杂度。
从人的角度出发
大多数工程师在设计函数时,往往是从功能描述出发,而非仅依赖函数名称。这一思维模式实际上与模型的思维方式存在类似性。通过从人的角度理解模型如何处理函数调用,我们可以发现许多潜在的优化空间。例如,考虑到工程师在编写函数时会根据其功能来定义参数,而不仅仅依赖参数名本身,模型也应该更多地关注函数的功能描述。
评论记录:
回复评论: