
导语
- 标题:ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
- 链接:arxiv.org/pdf/2504.11…
摘要
尽管强化学习训练的推理模型在纯文本推理任务中表现突出,但在需要精确计算或符号操作的结构化问题上仍显不足。为此,本文提出 ReTool 框架,通过将实时代码执行与自然语言推理交叉集成,并采用结果驱动的强化学习策略,让模型自主学习何时、如何调用计算工具。训练过程分为两阶段:一是利用合成数据进行代码增强的监督微调,二是在沙箱环境中以任务正确性为奖励,迭代优化工具使用策略。在国际数学竞赛基准 AIME 上的实验显示,ReTool 在训练效率和最终准确率上均大幅领先于纯文本强化学习和多种竞争基线,并在模型中观察到诸如代码自我修正等新兴行为,表明该方法在复杂数学推理场景中具有显著潜力。
引言
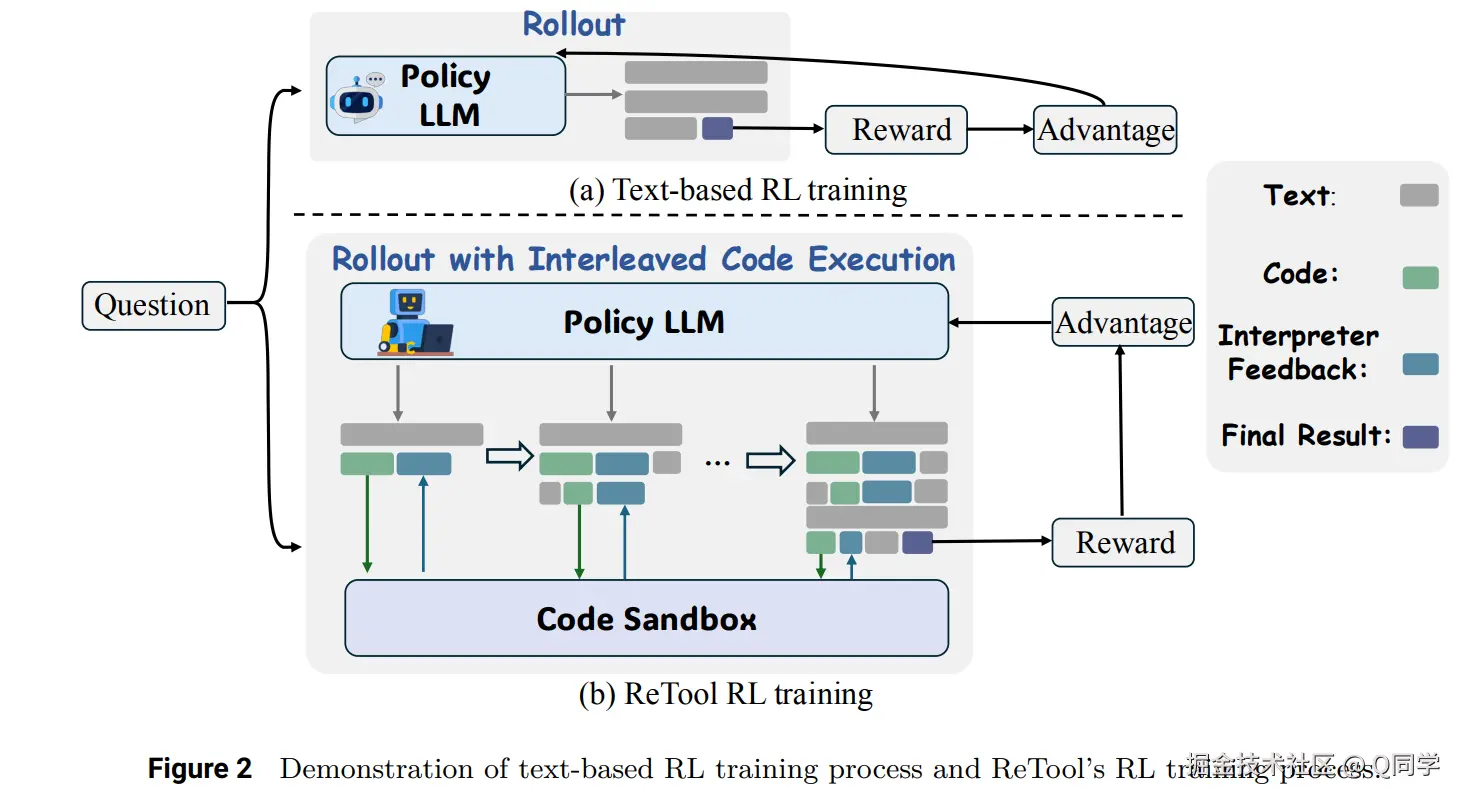
本文探讨如何将工具调用集成到大型语言模型(LLM)中,通过强化学习(RL)训练让模型在推理过程中能灵活调用外部工具,从而弥补传统文本推理方法的不足。具体来说,ReTool是一个新型的强化学习框架,通过集成代码解释器,能够提升模型在处理复杂数学推理任务时的表现,尤其是在那些需要精确计算和符号操作的任务中。
核心创新点
ReTool的核心创新点在于其通过强化学习,训练大型语言模型在推理过程中智能地调用外部工具(如代码解释器)。传统的语言模型依赖文本推理来解题,但在面对需要高度精确计算或复杂方程求解时,纯文本推理往往会产生错误或无法覆盖所有解空间。而通过ReTool,模型能够实时生成代码并与外部计算工具交互,帮助其验证中间步骤或进行精确计算,从而弥补传统方法的不足。
具体来说,ReTool有两个关键特性:
- 动态交错的实时代码执行:模型在推理过程中可以实时生成并执行代码,通过反馈结果来调整推理方向。
- 自动化的RL训练范式:模型通过强化学习的反馈机制,学习何时以及如何调用外部工具,并在多轮推理中优化工具的使用策略。
这种设计使得模型能够逐步掌握何时调用工具、如何选择合适的工具,并且在推理过程中进行自我修正,最终实现更高效、更精确的推理过程。
研究方法和思路
ReTool的设计分为两个主要阶段:
- 冷启动SFT阶段:通过构建一个高质量的数据集,训练模型理解何时和如何调用工具。这个数据集由多来源的数学推理任务组成,经过专家审核和筛选,确保每个示例都能提供准确的推理路径和工具调用信息。
- 强化学习阶段:在此阶段,模型通过与代码解释器的交互进行强化学习,探索最佳的推理策略。模型通过动态生成代码、调用外部工具、获取执行结果,并根据反馈优化策略。这一过程帮助模型逐渐学会在复杂任务中应用工具。
训练过程
- 训练算法:PPO算法
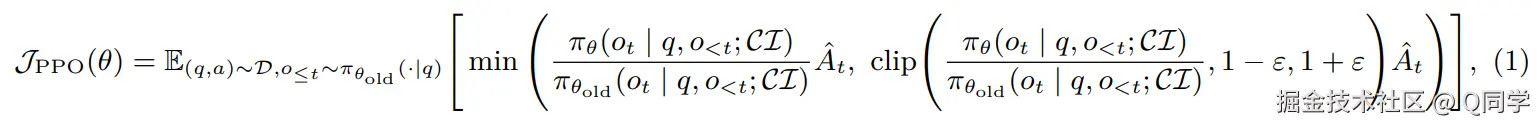
- 奖励设置:使用正确性评估奖励,从指定格式
\boxed{}中提取最终答案
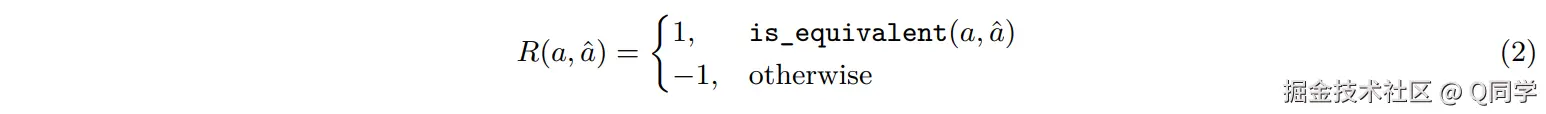
实验结果
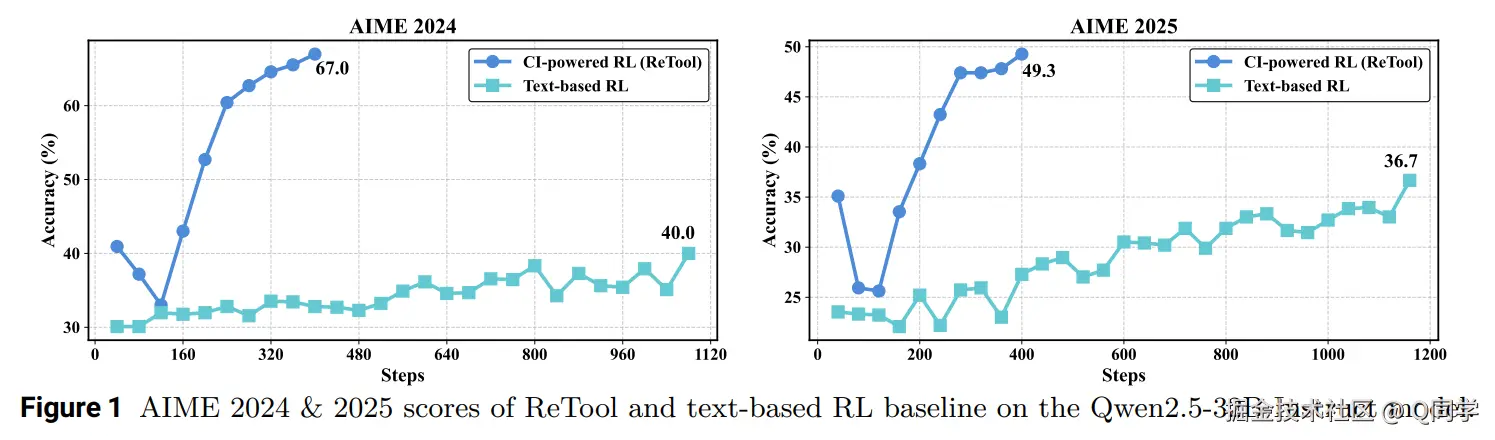
在挑战性的AIME奥赛基准上,ReTool的表现令人惊艳。经过仅400步训练,ReTool在AIME2024测试集上达到了67%的准确率,这一结果大大超过了传统文本型RL方法(仅40%的准确率,训练步数超过1000步)。此外,ReTool在AIME2025上也展现了出色的性能,达到了49.3%的准确率,远超其他模型。
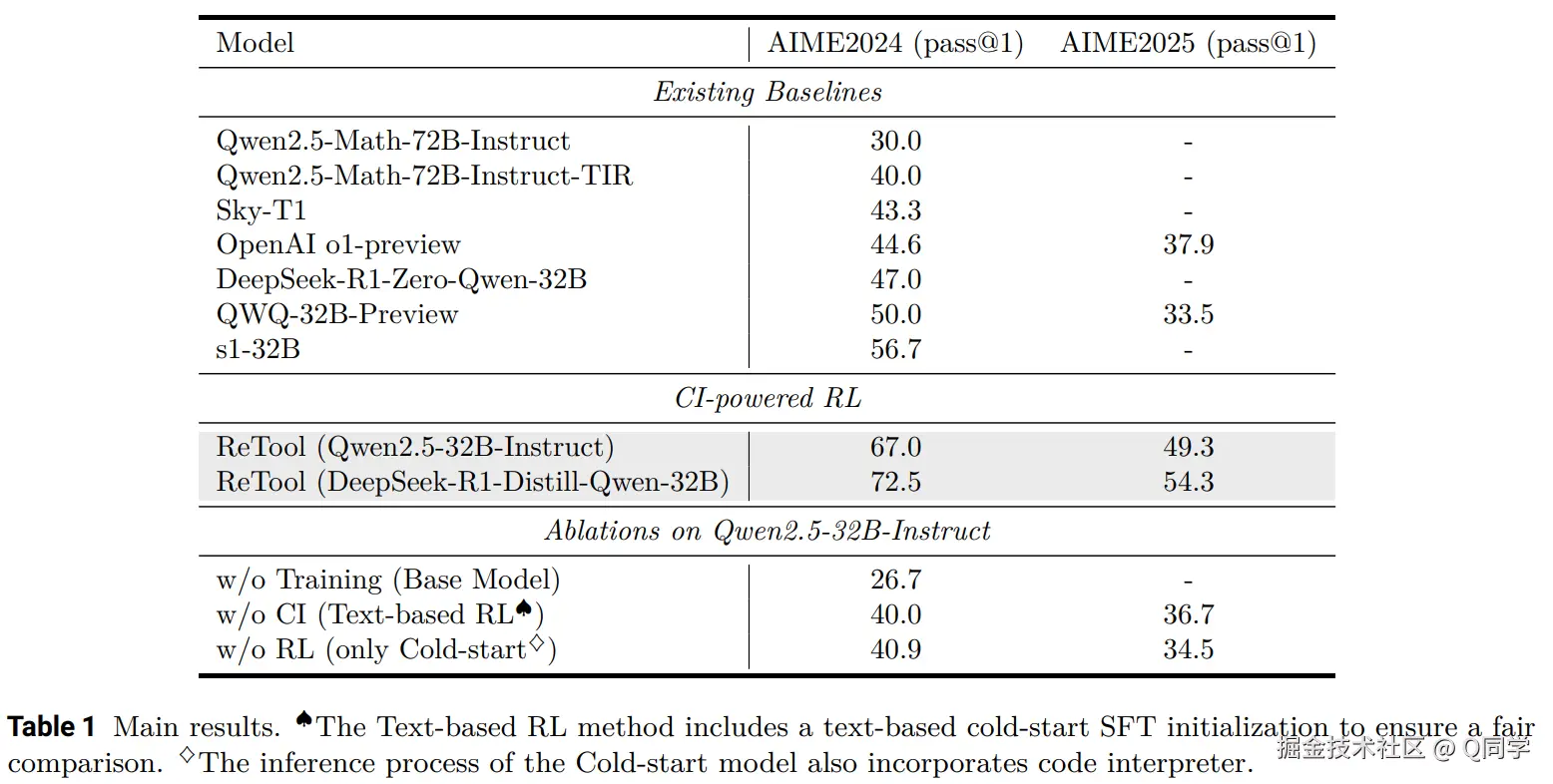
更重要的是,ReTool在训练过程中展示了新的行为模式。例如,模型能够自我修正代码错误并通过迭代优化推理过程。这种自适应的工具使用和修正能力,为未来更高效的推理模式奠定了基础。
对比与分析
ReTool的最大优势在于其灵活的工具使用策略。在传统的文本型RL方法中,模型只能依赖于静态的文本推理,很难应对需要精确计算或复杂符号操作的任务。而ReTool通过引入工具集成,能够动态生成代码、与外部计算工具交互,极大地提高了推理的准确性和效率。
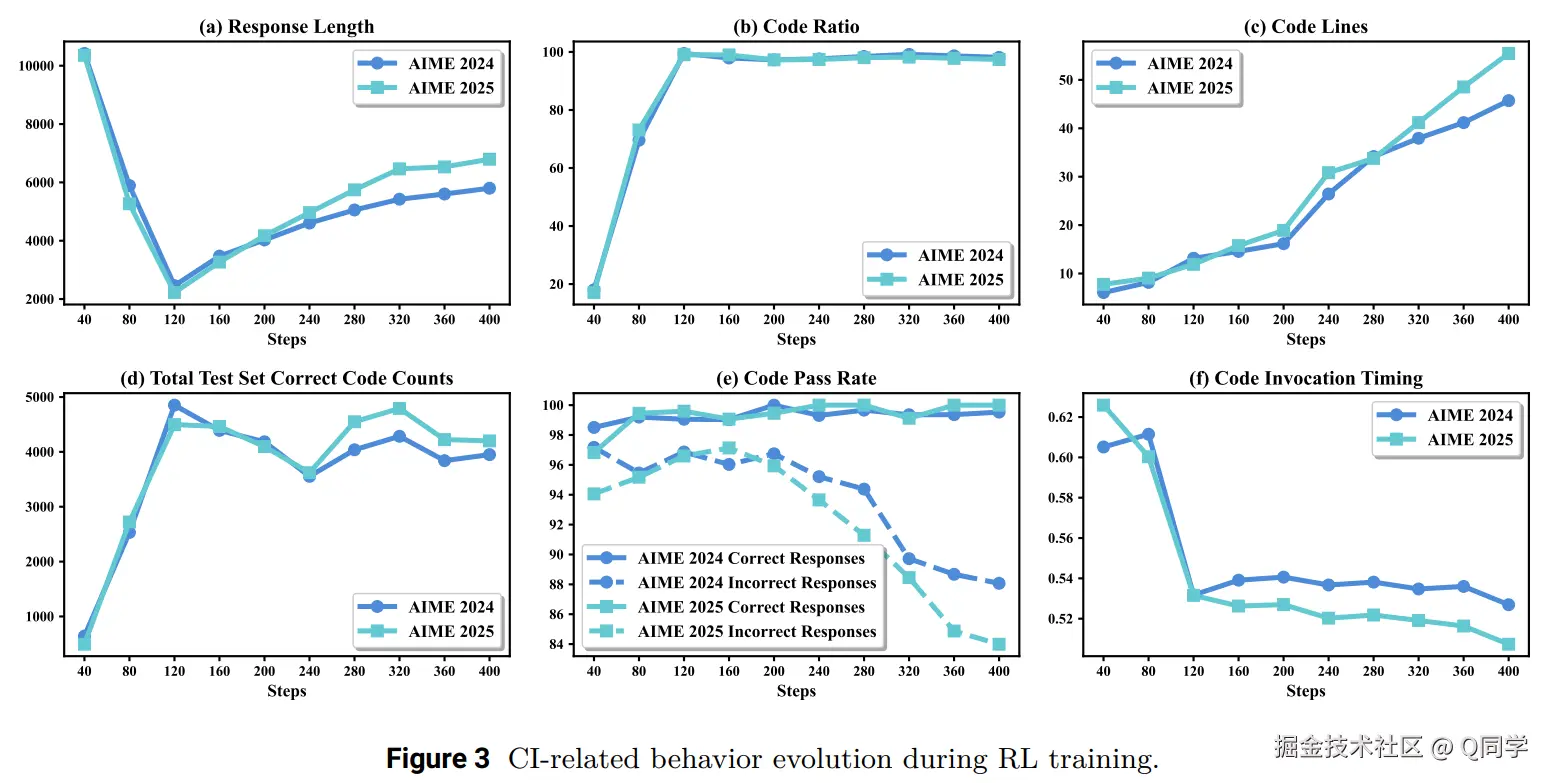
本文对训练过程中的一些指标进行了详细分析,具体如下:
- Token效率(图3a):训练后平均响应长度减少约 40%,表明代码介入可精简冗长计算。
- 代码使用趋势(图3b):随着训练推进,代码调用比例和代码行数持续上升,且调用时机逐渐提前。

- 自我修正能力(图4):在遇到执行错误时,模型能够根据反馈识别问题并迭代生成正确代码。
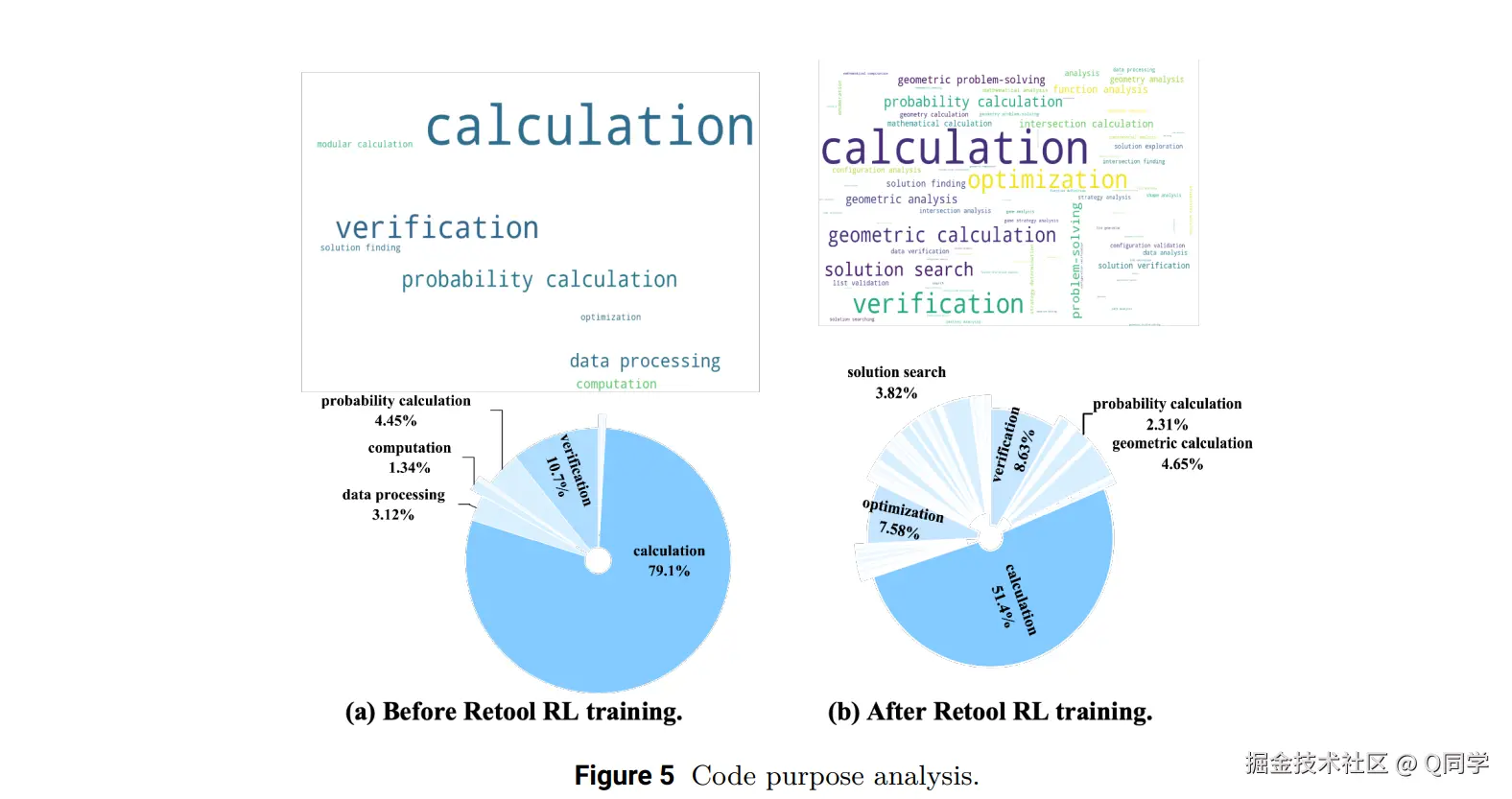
- 用途演化(图5):最初代码主要用于简单计算与验证,后期用途更趋多样,涵盖复杂逻辑与自适应工具选择。
- 案例对比(图6):典型题目展示了纯文本推理易出错、过程冗长,而代码驱动推理则以简洁且精确的方式完成计算,进一步支持整体策略判断。

总结
ReTool通过创新性地将代码执行与强化学习结合,为大型语言模型的推理能力提供了新的提升路径。通过将计算工具集成到推理过程中,ReTool显著提高了模型在数学推理任务中的表现,并为未来更高效的工具增强型推理开辟了新的方向。随着研究的深入,ReTool可能会在更广泛的应用领域中展现其强大的潜力,为解决复杂问题提供更多的智能解决方案。
评论记录:
回复评论: