
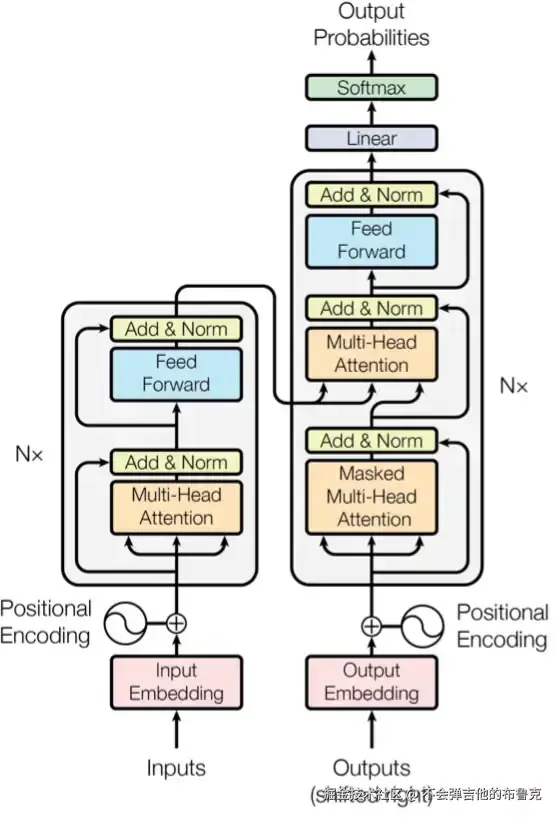
背景&创新点
在深度学习的世界里,归一化层(如BatchNorm、LayerNorm)就像一位兢兢业业的“管家”。它们每天忙着给数据做按摩 (减均值、除方差),再涂点护肤品(γ、β scale 和 shift参数调整),确保神经网络不“爆血管”(梯度爆炸)或“饿晕”(梯度消失)。自从2015年BatchNorm横空出世,归一化层就成了所有模型的标配,Transformer更是对其死心塌地,甚至有人放话:“没有归一化,AI活不过三集!”
这位“管家”有个毛病——计算成本高,搞得Transformer训练时像在开人口普查大会。更气人的是,管家还特爱刷存在感,几乎每层网络它都出场,关键是脱离了他,事情还会不好收场,作为资本家的主人葛朗台已经脸上挤着笑容,内心滴着血的忍这个老管家好多年了
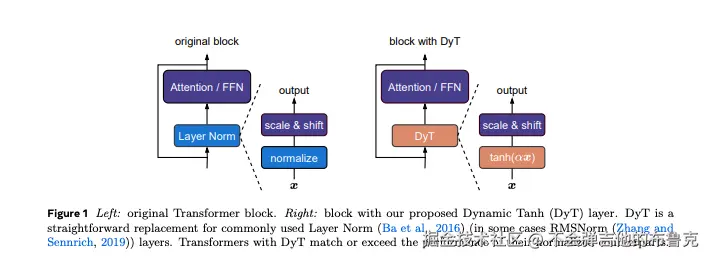
这篇论文提出了Dynamic Tanh(DyT) ,一个自称“我不需要统计,照样能管好数据”的酷炫方案。它的核心思想简单到离谱:用tanh函数直接压缩数据,再配一个动态缩放参数α。就像给数据戴了一副“自适应墨镜”,太亮的地方自动调暗,太暗的地方调亮,全程不查户口(无需计算统计量),它的亮点:
- 不搞标准化:拒绝“减均值除方差”的繁琐流程
- 单枪匹马:仅需一个可学习参数α,比归一化层的γ、β还省内存
- 速度狂魔:计算开销直降50%,训练时仿佛开了氮气加速!
下面我们从机制原理和数据公式几个维度说明一下二者之间的区别
机制原理和数据公式
LayerNorm的机制与发展:从“数据按摩师”到“甩手掌柜”
LayerNorm(层归一化)是Transformer的御用管家,他不仅改善了梯度流,还能适应深层网络中激活值的分布变化,尤其在对极端值进行非线性压缩方面起到了重要作用
它的工作流程如下:
- 按摩手法:对每个token的数据单独处理,减去均值、除以标准差。
- 护肤品配方:用γ和β参数调整输出范围,让数据“容光焕发”。
公式长这样:
(翻译成人话:先给数据搓澡,再涂大宝SOD蜜。)
异卵孪生兄弟,下面这样,
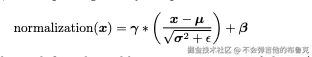
核心功能
-
局部线性和全局非线性特性: 对训练好的网络进行采样分析后发现,虽然每个 token 内的归一化操作保持了局部的线性特性,但当把所有 token 的输出数据画在一张图中时,整体映射呈现出明显的 tanh 型 S 曲线。
-
极值的压缩效果: 绝大部分数据位于线性区间,但对于那些极端值,归一化层通过除以较大的标准差,起到了明显的“压扁”作用,这种非线性处理对于稳定训练和防止激活爆炸是非常重要的
归一化层本质分析
领域几位大佬基于现象看本质发现,基于三个网络的样本采样返现:在训练好的 Transformer 中,LayerNorm 层输出的非线性映射呈现出类似 tanh 函数的 S 形曲线特征。大部分输入值处于线性区间,但对于极值输入则进行了明显的压缩处理,
通过input与output 关系大部分是线性的,类似于 x-y 图中的直线。然而,更深的 LN 层是我们进行更有趣的观察的地方。
从这些更深的层中,一个惊人的观察结果是,这些曲线的形状中的大多数都与 tanh 函数表示的全部或部分 S 形曲线高度相似(见图 3)。
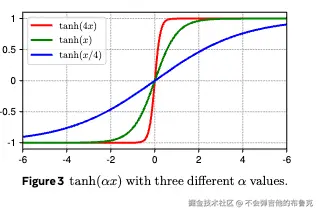
既然整体映射呈现出明显的 tanh 型 S 曲线,于是作者一拍大腿: “直接上tanh不就完事了?还统计个毛线!”,毕竟新函数不需要计算均值,减去方差.
Dynamic Tanh (DyT) 层(Dynamic Tanh)
-
实现思路: 直接将原有归一化层替换为 DyT 层,不需要额外的归一化统计量计算,只需对每个输入元素应用 tanh(αx) 操作,然后再进行缩放和平移。
-
直观解释: 该方法利用 tanh 函数在中间区域近似线性、在极值区域压缩输出的特性,模拟了 LN 对极端激活值的处理效果,同时降低了计算复杂度
- α:动态缩放参数:自学成才,根据数据范围调整tanh的“拉伸程度”。
- tanh:灵魂压缩师:把极端值按头压进[-1,1],防止网络“高血压

为什么它能成功?
- 以假乱真:tanh的S型曲线完美模仿LayerNorm的非线性压缩。
- 轻装上阵:没有统计计算,GPU感动到哭:“终于不用加班算方差了!”
DyT vs LayerNorm——一场“速度与激情”的较量
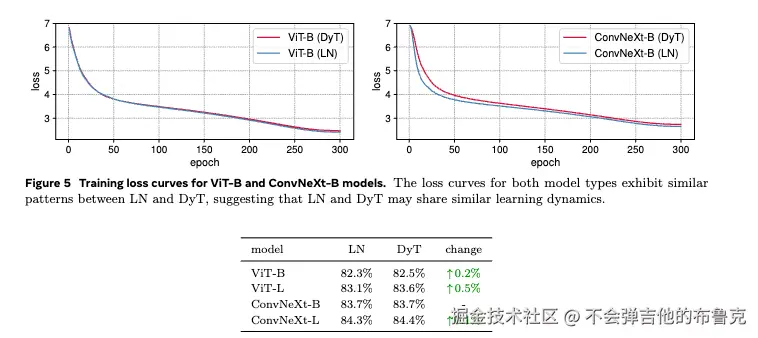
Supervised learning in vision.实验效果如下:
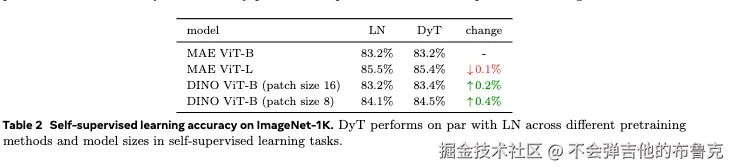
Self-supervised learning in vision实验效果如下:
Diffusion models.(DiT)

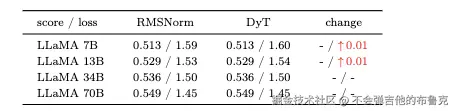
Large Language Models实验效果如下:
这篇论文告诉我们:有时候,简单粗暴才是王道。
- 扔掉统计计算,AI照样能跑得欢。
- 一个tanh加一个α,直接让Transformer实现“管理自由”。
未来,或许会有更多“叛逆方案”挑战传统智慧。毕竟,AI的世界里, “没有什么是不可替代的,除了创新本身。”
(小声BB:不过DyT在ConvNet里还是翻车了,ResNet表示:“年轻人,路还长着呢!”)
引用资料: arxiv.org/pdf/2503.10…
评论记录:
回复评论: