
这是我的第395篇原创文章。
一、引言
在dify中预置了很多模型供应商和众多主流模型,但是现今AI发展迅速,新的模型不停的涌现,如何在dify中使用这些新的模型?
(1)如果你的平台不是dify已有的供应商但是兼容openai API接口规范,比如OneApi。可以通过在dify的模型供应商选项中选择“OpenAI-API-compatible”。这是因为OneApi平台提供的接口与OpenAI的接口兼容,dify通过这种方式能够识别并正确地与OneApi平台进行交互。
(2)如果你的平台是dify已有的供应商但是不兼容openai API接口规范且你的平台是目前不支持你想调用的模型类型如rerank模型或SST模型(比如triton,一个可以自定义扩展模型的部署平台,如果你需要多个模型组合可能需要在triton平台进行编排扩展部署)。可以通过接口转发实现或对 Dify 进行二次开发实现。
(3)如果你的平台不是dify已有的供应商且不兼容openai API接口规范,则要添加一个全新的模型供应商,会稍微更复杂一点,但是其实原理差不多,其实就是实现模型的请求。
二、实现过程
2.1 接口转发
这里以文心中的rerank模型为例。文心提供了一款rerank模型:bce-reranker-base,它是网易有道的。在dify当前(0.9.2版本)版本中文心这个模型提供商下并没有rerank这个类型,所以无法直接添加。
但是看了一遍所有供应商,发现LocalAI是支持rerank模型的,那么就可以自己实现一个服务,实现对bce-reranker-base这个模型的调用,并且将输入和输出进行重新格式化,以符合LocalAI的rerank接口格式即可。
经过比对发现输入格式是一致的,只不过输出有一点不一样,只要简单处理一下就可以了。简单的实例代码如下:
- import json
- import requests
- from http.server import BaseHTTPRequestHandler, HTTPServer
-
- class PostHandler(BaseHTTPRequestHandler):
- def do_POST(self):
- if self.path == '/rerank':
- content_length = int(self.headers['Content-Length'])
- post_data = self.rfile.read(content_length)
-
- result = rerank(post_data)
-
- resultJson = json.loads(result)
- results = resultJson['results']
-
- for item in results:
- doc = item['document']
- del item['document']
- item['document'] = {'text':doc}
-
- result = json.dumps(resultJson)
- print(resultJson)
- self.send_response(200)
- self.send_header("Content-type", "application/json")
- self.end_headers()
- self.wfile.write(bytes(result, encoding='utf-8'))
-
-
- def get_access_token():
- #获取百度的token
-
- def rerank(payload):
- url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/reranker/bce_reranker_base?access_token=" + get_access_token()
-
- headers = {
- 'Content-Type': 'application/json'
- }
-
- response = requests.request("POST", url, headers=headers, data=payload)
-
- return response.text
-
- if __name__ == '__main__':
- host = "0.0.0.0"
- port = 8899
- server = HTTPServer((host, port), PostHandler)
- print(f"Server is running on http://{host}:{port}")
- server.serve_forever()

然后在dify中添加LocalAi模型,注意模型名称是rerank。注意上面的代码只是简单的示例,实用中要考虑并发性,所以最好通过aiohttp和线程池搭配来实现服务。
2.2 dify二次开发
这里以部署在triton的SeACoParaformer模型为例。模型供应商的源码在项目的api/core/model_runtime/model_providers/目录下,在这里可以看到每个供应商有一个目录,其中triton的目录是triton_inference_server。同时,在这个目录下面,我们可以看到,只有一个子目录llm。因为目前dify只支持LLM接入。
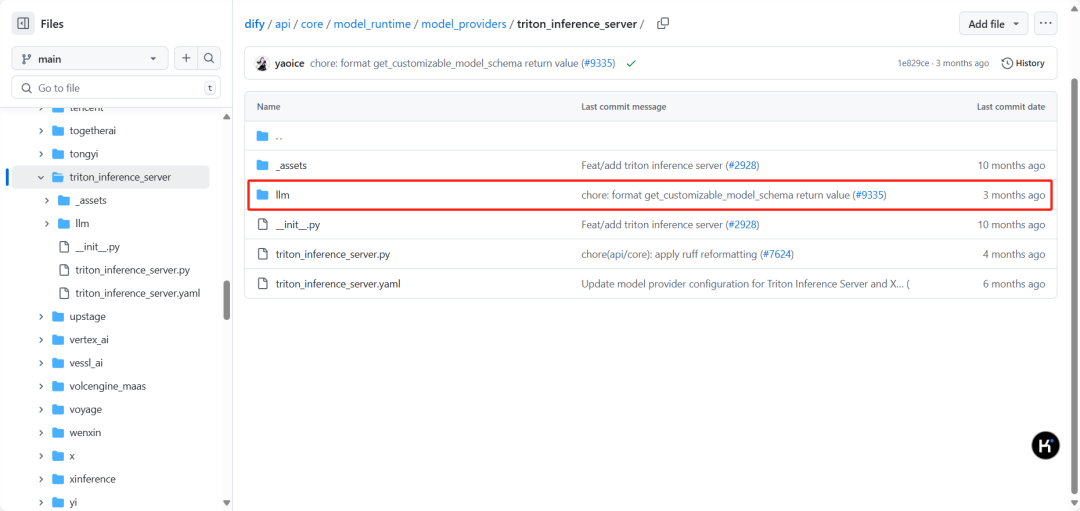
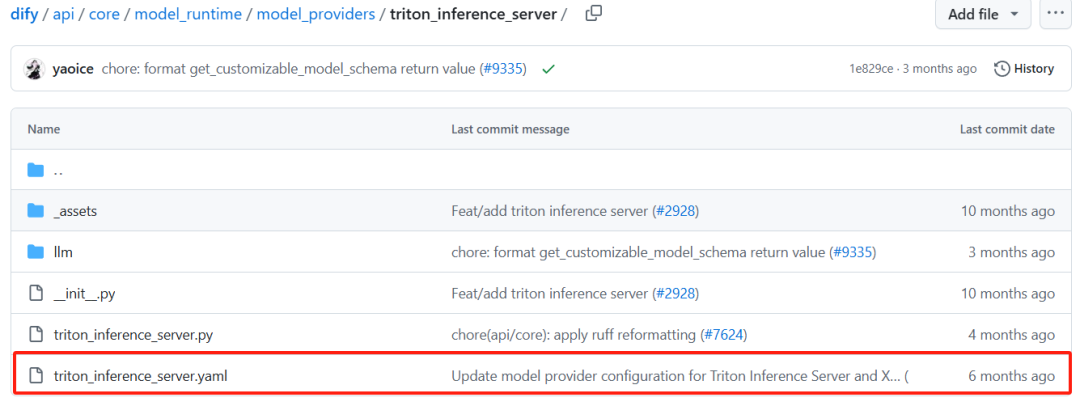
我们首先需要修改triton_inference_server这个目录下的triton_inference_server.yaml,这是trion模型配置文件。
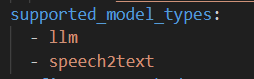
在supported_model_types加上speech2text,如下:
在configurate_methods这里我们可以看到triton支持自定义模型的配置:
![]()
供应商支持三种模型配置方式:
-
预定义模型(predefined-model):表示用户只需要配置统一的供应商凭据即可使用供应商下的预定义模型。
-
自定义模型(customizable-model):用户需要新增每个模型的凭据配置,如 Xinference,它同时支持 LLM 和 Text Embedding,但是每个模型都有唯一的 model_uid,如果想要将两者同时接入,就需要为每个模型配置一个 model_uid。
-
从远程获取(fetch-from-remote):与
predefined-model配置方式一致,只需要配置统一的供应商凭据即可,模型通过凭据信息从供应商获取。 -
如OpenAI,我们可以基于 gpt-turbo-3.5 来 Fine Tune 多个模型,而他们都位于同一个 api_key 下,当配置为
fetch-from-remote时,开发者只需要配置统一的 api_key 即可让 Dify Runtime 获取到开发者所有的微调模型并接入 Dify。 -
这三种配置方式支持共存,即存在供应商支持
predefined-model+customizable-model或predefined-model+fetch-from-remote等,也就是配置了供应商统一凭据可以使用预定义模型和从远程获取的模型,若新增了模型,则可以在此基础上额外使用自定义的模型。
接着,我们首先要添加speech2text这个类型,创建一个名字为speech2text的目录。在speech2text目录下创建一个空的__init__.py文件和一个speech2text.py文件,我们需要在speech2text.py文件中来实现对SeACoParaformer模型的调用。
在speech2text.py中新建一个class:TritonSpeech2TextModel,

它继承Speech2TextModel(继承的AIModel),并实现它的几个函数。
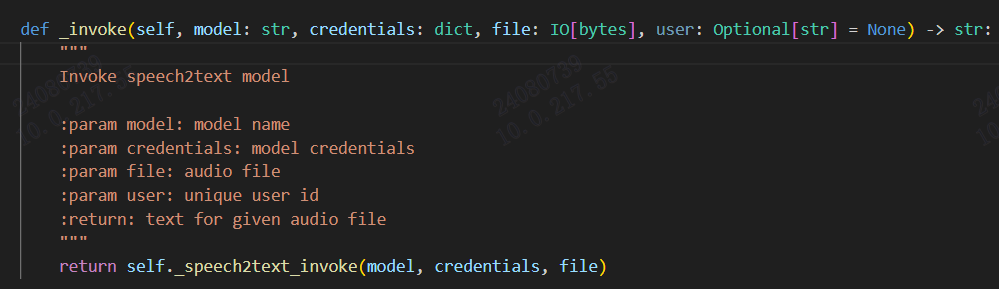
_invoke:实现对模型的请求和返回
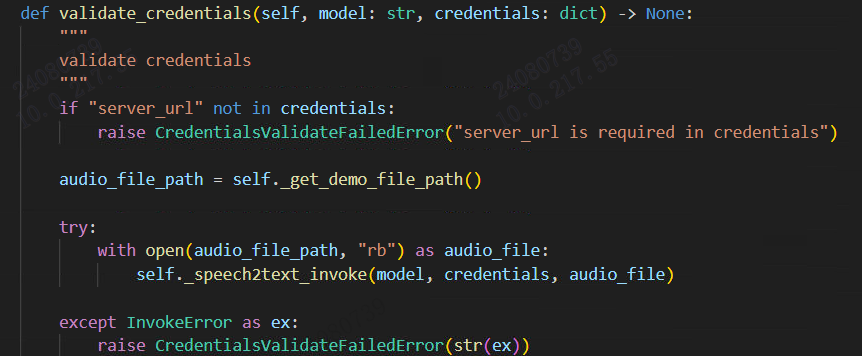
validate_credentials:验证模型供应商,可以做一次模型请求,也可以验证密钥(比如文心就验证通过密钥获取token)。当添加模型后会自动执行这一步来验证,验证成功才添加成功。
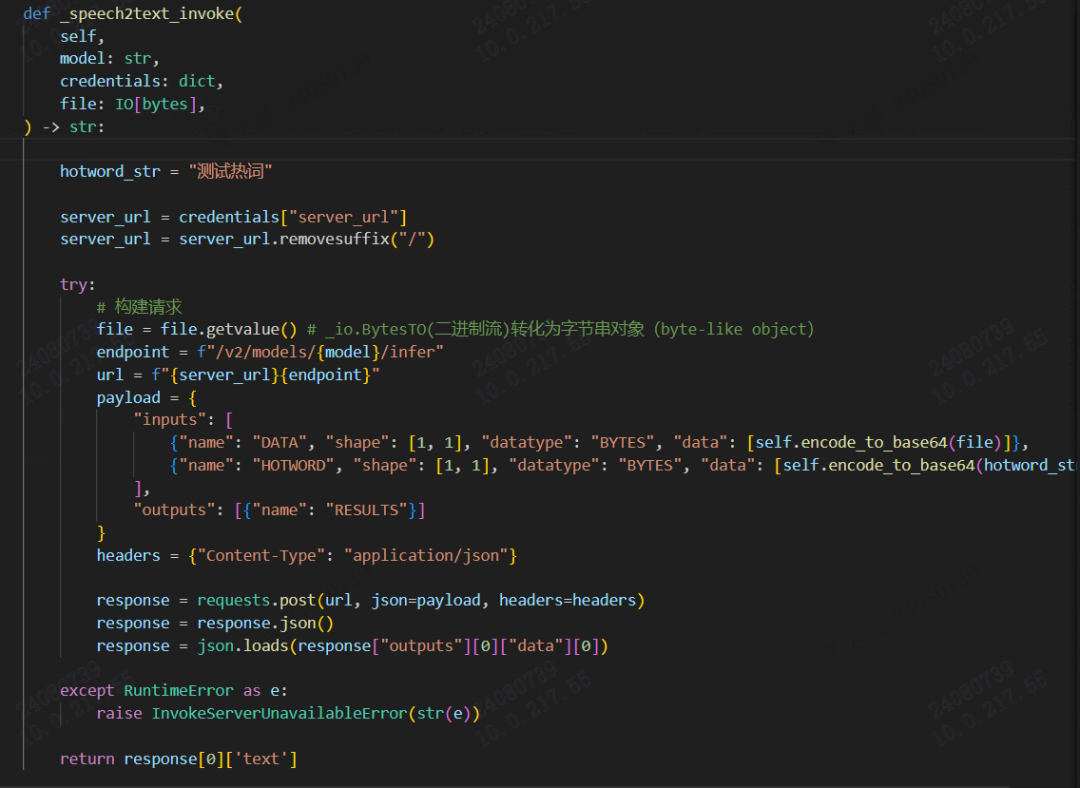
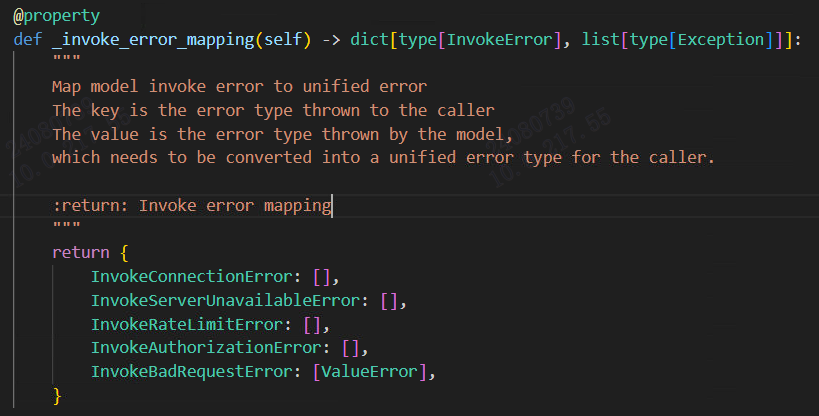
_invoke_error_mapping:枚举各种错误所以最主要的就是_invoke函数,这里实现了请求,不同供应商不一样,代码如下:
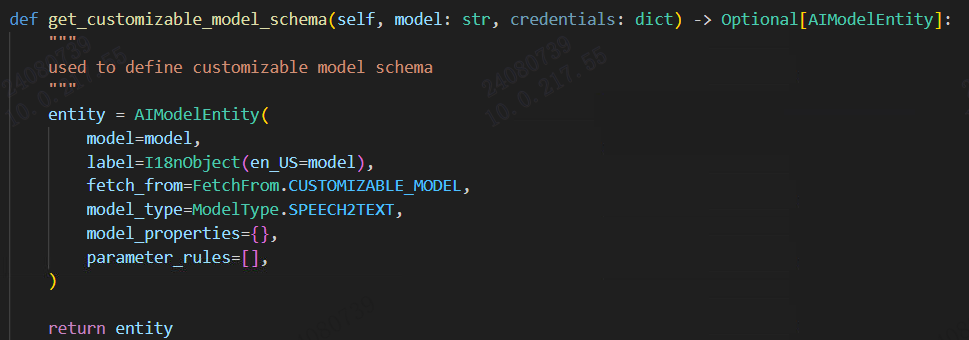
get_customizable_model_schema:用于定义定制化模型的概要,比如模型标签、类型、来源、属性。
完成上述步骤之后,进入模型供应商,可见Triton这个模型供应商已经支持speech2text:
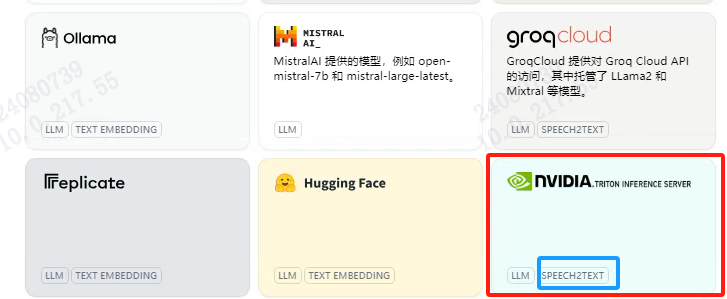
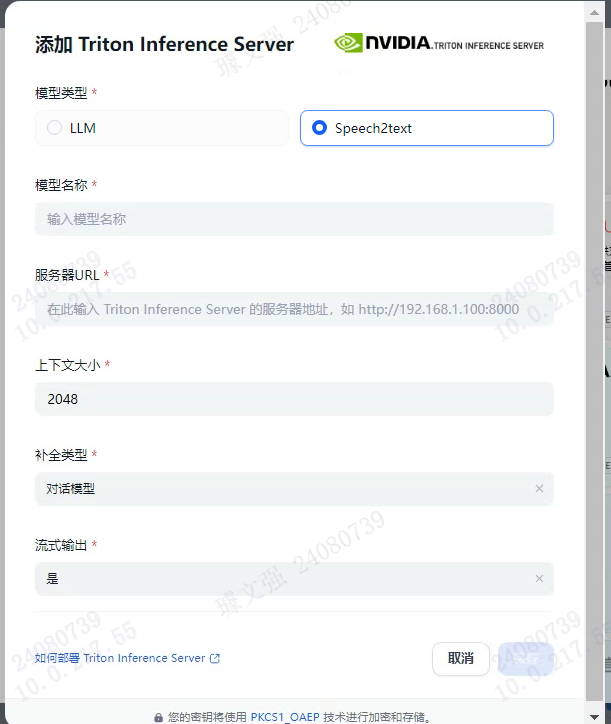
配置模型名称和服务器URL即可完成接入:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。

 微信公众号
微信公众号

评论记录:
回复评论: