1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 对模型的输出结果去除批量维度。 获取每个检测框的置信度最高的类别,并根据置信度阈值进行筛选,过滤掉低置信度的目标检测框 。 坐标转换,将预测框还原到原始图像尺寸,并将边界框的表示从中心点坐标 (x_center, y_center) 和宽高 (w, h) 格式转换为左上角和右下角坐标 (x1, y1, x2, y2) 格式。 进行非极大值抑制(NMS),去除重叠度过高的检测框,得到最终的目标检测结果。 def xywh2xyxy ( x) :
y = np. copy( x)
y[ . . . , 0 ] = x[ . . . , 0 ] - x[ . . . , 2 ] / 2
y[ . . . , 1 ] = x[ . . . , 1 ] - x[ . . . , 3 ] / 2
y[ . . . , 2 ] = x[ . . . , 0 ] + x[ . . . , 2 ] / 2
y[ . . . , 3 ] = x[ . . . , 1 ] + x[ . . . , 3 ] / 2
return y
def multiclass_nms ( boxes, scores, class_ids, iou_threshold) :
unique_class_ids = np. unique( class_ids)
keep_boxes = [ ]
for class_id in unique_class_ids:
class_indices = np. where( class_ids == class_id) [ 0 ]
class_boxes = boxes[ class_indices, : ]
class_scores = scores[ class_indices]
class_keep_boxes = nms( class_boxes, class_scores, iou_threshold)
keep_boxes. extend( class_indices[ class_keep_boxes] )
return keep_boxes
def nms ( boxes, scores, iou_threshold) :
sorted_indices = np. argsort( scores) [ : : - 1 ]
keep_boxes = [ ]
while sorted_indices. size > 0 :
box_id = sorted_indices[ 0 ]
keep_boxes. append( box_id)
ious = compute_iou( boxes[ box_id, : ] , boxes[ sorted_indices[ 1 : ] , : ] )
keep_indices = np. where( ious < iou_threshold) [ 0 ]
sorted_indices = sorted_indices[ keep_indices + 1 ]
return keep_boxes
def compute_iou ( box, boxes) :
xmin = np. maximum( box[ 0 ] , boxes[ : , 0 ] )
ymin = np. maximum( box[ 1 ] , boxes[ : , 1 ] )
xmax = np. minimum( box[ 2 ] , boxes[ : , 2 ] )
ymax = np. minimum( box[ 3 ] , boxes[ : , 3 ] )
intersection_area = np. maximum( 0 , xmax - xmin) * np. maximum( 0 , ymax - ymin)
box_area = ( box[ 2 ] - box[ 0 ] ) * ( box[ 3 ] - box[ 1 ] )
boxes_area = ( boxes[ : , 2 ] - boxes[ : , 0 ] ) * ( boxes[ : , 3 ] - boxes[ : , 1 ] )
union_area = box_area + boxes_area - intersection_area
iou = intersection_area / union_area
return iou
def process_output ( outputs, conf_threshold, iou_threshold, input_width, input_height, img_width, img_height) :
predictions = np. squeeze( outputs[ 0 ] ) . T
scores = np. max ( predictions[ : , 4 : ] , axis= 1 )
predictions = predictions[ scores > conf_threshold, : ]
scores = scores[ scores > conf_threshold]
if len ( scores) == 0 :
return [ ] , [ ] , [ ]
class_ids = np. argmax( predictions[ : , 4 : ] , axis= 1 )
boxes = predictions[ : , : 4 ]
input_shape = np. array( [ input_width, input_height, input_width, input_height] )
boxes = np. divide( boxes, input_shape, dtype= np. float32)
boxes *= np. array( [ img_width, img_height, img_width, img_height] )
boxes = xywh2xyxy( boxes)
indices = multiclass_nms( boxes, scores, class_ids, iou_threshold)
return boxes[ indices] , scores[ indices] , class_ids[ indices]
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"> 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 utils.py
import numpy as np
import cv2
class_names = [ 'person' , 'head' , 'helmet' ]
rng = np. random. default_rng( 3 )
colors = rng. uniform( 0 , 255 , size= ( len ( class_names) , 3 ) )
def nms ( boxes, scores, iou_threshold) :
sorted_indices = np. argsort( scores) [ : : - 1 ]
keep_boxes = [ ]
while sorted_indices. size > 0 :
box_id = sorted_indices[ 0 ]
keep_boxes. append( box_id)
ious = compute_iou( boxes[ box_id, : ] , boxes[ sorted_indices[ 1 : ] , : ] )
keep_indices = np. where( ious < iou_threshold) [ 0 ]
sorted_indices = sorted_indices[ keep_indices + 1 ]
return keep_boxes
def multiclass_nms ( boxes, scores, class_ids, iou_threshold) :
unique_class_ids = np. unique( class_ids)
keep_boxes = [ ]
for class_id in unique_class_ids:
class_indices = np. where( class_ids == class_id) [ 0 ]
class_boxes = boxes[ class_indices, : ]
class_scores = scores[ class_indices]
class_keep_boxes = nms( class_boxes, class_scores, iou_threshold)
keep_boxes. extend( class_indices[ class_keep_boxes] )
return keep_boxes
def compute_iou ( box, boxes) :
xmin = np. maximum( box[ 0 ] , boxes[ : , 0 ] )
ymin = np. maximum( box[ 1 ] , boxes[ : , 1 ] )
xmax = np. minimum( box[ 2 ] , boxes[ : , 2 ] )
ymax = np. minimum( box[ 3 ] , boxes[ : , 3 ] )
intersection_area = np. maximum( 0 , xmax - xmin) * np. maximum( 0 , ymax - ymin)
box_area = ( box[ 2 ] - box[ 0 ] ) * ( box[ 3 ] - box[ 1 ] )
boxes_area = ( boxes[ : , 2 ] - boxes[ : , 0 ] ) * ( boxes[ : , 3 ] - boxes[ : , 1 ] )
union_area = box_area + boxes_area - intersection_area
iou = intersection_area / union_area
return iou
def xywh2xyxy ( x) :
y = np. copy( x)
y[ . . . , 0 ] = x[ . . . , 0 ] - x[ . . . , 2 ] / 2
y[ . . . , 1 ] = x[ . . . , 1 ] - x[ . . . , 3 ] / 2
y[ . . . , 2 ] = x[ . . . , 0 ] + x[ . . . , 2 ] / 2
y[ . . . , 3 ] = x[ . . . , 1 ] + x[ . . . , 3 ] / 2
return y
def draw_detections ( image, boxes, scores, class_ids, mask_alpha= 0.3 ) :
det_img = image. copy( )
img_height, img_width = image. shape[ : 2 ]
font_size = min ( [ img_height, img_width] ) * 0.0006
text_thickness = int ( min ( [ img_height, img_width] ) * 0.001 )
det_img = draw_masks( det_img, boxes, class_ids, mask_alpha)
for class_id, box, score in zip ( class_ids, boxes, scores) :
color = colors[ class_id]
draw_box( det_img, box, color)
label = class_names[ class_id]
caption = f' { label} { int ( score * 100 ) } %' ( det_img, caption, box, color, font_size, text_thickness)
return det_img
def draw_box ( image: np. ndarray, box: np. ndarray, color: tuple [ int , int , int ] = ( 0 , 0 , 255 ) ,
thickness: int = 2 ) - > np. ndarray:
x1, y1, x2, y2 = box. astype( int )
return cv2. rectangle( image, ( x1, y1) , ( x2, y2) , color, thickness)
def draw_text ( image: np. ndarray, text: str , box: np. ndarray, color: tuple [ int , int , int ] = ( 0 , 0 , 255 ) ,
font_size: float = 0.001 , text_thickness: int = 2 ) - > np. ndarray:
x1, y1, x2, y2 = box. astype( int )
( tw, th) , _ = cv2. getTextSize( text= text, fontFace= cv2. FONT_HERSHEY_SIMPLEX,
fontScale= font_size, thickness= text_thickness)
th = int ( th * 1.2 )
cv2. rectangle( image, ( x1, y1) ,
( x1 + tw, y1 - th) , color, - 1 )
return cv2. putText( image, text, ( x1, y1) , cv2. FONT_HERSHEY_SIMPLEX, font_size, ( 255 , 255 , 255 ) , text_thickness, cv2. LINE_AA)
def draw_masks ( image: np. ndarray, boxes: np. ndarray, classes: np. ndarray, mask_alpha: float = 0.3 ) - > np. ndarray:
mask_img = image. copy( )
for box, class_id in zip ( boxes, classes) :
color = colors[ class_id]
x1, y1, x2, y2 = box. astype( int )
cv2. rectangle( mask_img, ( x1, y1) , ( x2, y2) , color, - 1 )
return cv2. addWeighted( mask_img, mask_alpha, image, 1 - mask_alpha, 0 )
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 target_detection.py
import time
import cv2
import numpy as np
import onnxruntime
from detection. utils import xywh2xyxy, draw_detections, multiclass_nms
class TargetDetection :
def __init__ ( self, path, conf_thres= 0.7 , iou_thres= 0.5 ) :
self. conf_threshold = conf_thres
self. iou_threshold = iou_thres
self. initialize_model( path)
def __call__ ( self, image) :
return self. detect_objects( image)
def initialize_model ( self, path) :
self. session = onnxruntime. InferenceSession( path, providers= onnxruntime. get_available_providers( ) )
self. get_input_details( )
self. get_output_details( )
def detect_objects ( self, image) :
input_tensor = self. prepare_input( image)
outputs = self. inference( input_tensor)
self. boxes, self. scores, self. class_ids = self. process_output( outputs)
return self. boxes, self. scores, self. class_ids
def prepare_input ( self, image) :
self. img_height, self. img_width = image. shape[ : 2 ]
input_img = cv2. cvtColor( image, cv2. COLOR_BGR2RGB)
input_img = cv2. resize( input_img, ( self. input_width, self. input_height) )
input_img = input_img / 255.0
input_img = input_img. transpose( 2 , 0 , 1 )
input_tensor = input_img[ np. newaxis, : , : , : ] . astype( np. float32)
return input_tensor
def inference ( self, input_tensor) :
start = time. perf_counter( )
outputs = self. session. run( self. output_names, { self. input_names[ 0 ] : input_tensor} )
return outputs
def process_output ( self, output) :
predictions = np. squeeze( output[ 0 ] ) . T
scores = np. max ( predictions[ : , 4 : ] , axis= 1 )
predictions = predictions[ scores > self. conf_threshold, : ]
scores = scores[ scores > self. conf_threshold]
if len ( scores) == 0 :
return [ ] , [ ] , [ ]
class_ids = np. argmax( predictions[ : , 4 : ] , axis= 1 )
boxes = self. extract_boxes( predictions)
indices = multiclass_nms( boxes, scores, class_ids, self. iou_threshold)
return boxes[ indices] , scores[ indices] , class_ids[ indices]
def extract_boxes ( self, predictions) :
boxes = predictions[ : , : 4 ]
boxes = self. rescale_boxes( boxes)
boxes = xywh2xyxy( boxes)
return boxes
def rescale_boxes ( self, boxes) :
input_shape = np. array( [ self. input_width, self. input_height, self. input_width, self. input_height] )
boxes = np. divide( boxes, input_shape, dtype= np. float32)
boxes *= np. array( [ self. img_width, self. img_height, self. img_width, self. img_height] )
return boxes
def draw_detections ( self, image, draw_scores= True , mask_alpha= 0.4 ) :
return draw_detections( image, self. boxes, self. scores,
self. class_ids, mask_alpha)
def get_input_details ( self) :
model_inputs = self. session. get_inputs( )
self. input_names = [ model_inputs[ i] . name for i in range ( len ( model_inputs) ) ]
self. input_shape = model_inputs[ 0 ] . shape
self. input_height = self. input_shape[ 2 ]
self. input_width = self. input_shape[ 3 ]
print ( self. input_width, self. input_height)
def get_output_details ( self) :
model_outputs = self. session. get_outputs( )
self. output_names = [ model_outputs[ i] . name for i in range ( len ( model_outputs) ) ]
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 ATDetector.py
import cv2
from detection. target_detection import TargetDetection
from detection. utils import draw_detections
class ATDetector ( ) :
def __init__ ( self) :
super ( ATDetector, self) . __init__( )
self. model_path = "../yolov8s_best.onnx"
self. detector = TargetDetection( self. model_path, conf_thres= 0.5 , iou_thres= 0.3 )
def detect_image ( self, input_image, output_image) :
cv_img = cv2. imread( input_image)
boxes, scores, class_ids = self. detector. detect_objects( cv_img)
cv_img = draw_detections( cv_img, boxes, scores, class_ids)
cv2. namedWindow( "output" , cv2. WINDOW_NORMAL)
cv2. imwrite( output_image, cv_img)
cv2. imshow( 'output' , cv_img)
cv2. waitKey( 0 )
def detect_video ( self, input_video, output_video) :
cap = cv2. VideoCapture( input_video)
fps = int ( cap. get( 5 ) )
videoWriter = None
while True :
_, cv_img = cap. read( )
if cv_img is None :
break
boxes, scores, class_ids = self. detector. detect_objects( cv_img)
cv_img = draw_detections( cv_img, boxes, scores, class_ids)
if videoWriter is None :
fourcc = cv2. VideoWriter_fourcc( 'm' , 'p' , '4' , 'v' )
videoWriter = cv2. VideoWriter( output_video, fourcc, fps, ( cv_img. shape[ 1 ] , cv_img. shape[ 0 ] ) )
videoWriter. write( cv_img)
cv2. imshow( "aod" , cv_img)
cv2. waitKey( 5 )
if cv2. getWindowProperty( "aod" , cv2. WND_PROP_AUTOSIZE) < 1 :
break
cap. release( )
videoWriter. release( )
cv2. destroyAllWindows( )
if __name__ == '__main__' :
det = ATDetector( )
input_video= r"E:\dataset\MOT\video\A13.mp4"
output_video= "../data/output.mp4"
det. detect_video( input_video, output_video)
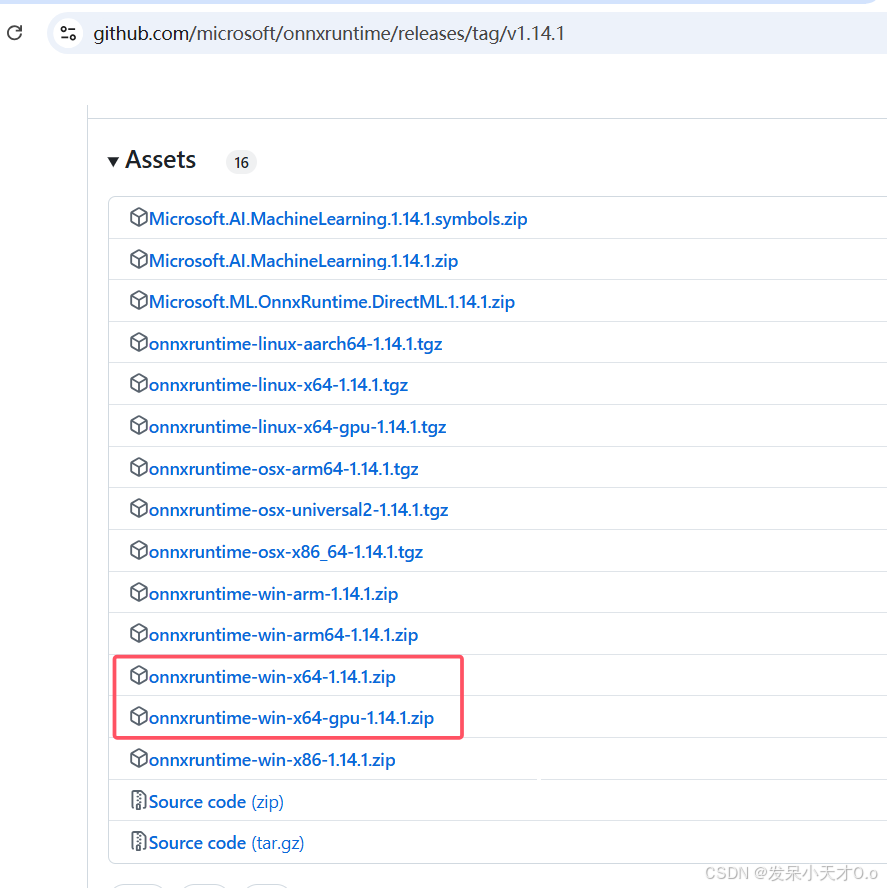
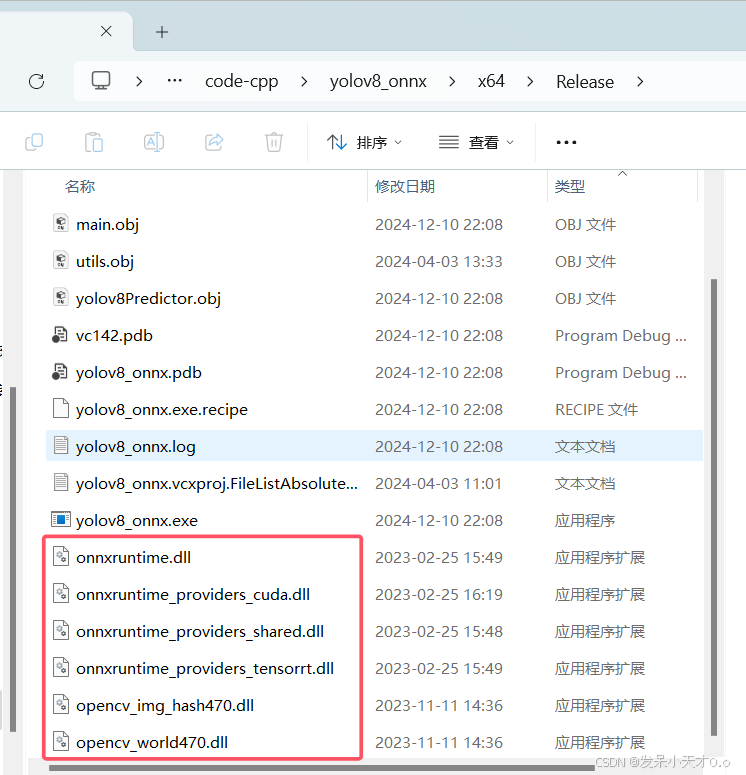
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 Python 是解释型语言,代码在运行时逐行解释执行。在进行模型推理时,每次执行模型的计算操作(如卷积、池化等)都需要解释器介入,这会带来一定的性能开销。而C++ 是编译型语言,代码直接编译为机器码,计算机可以直接执行。在处理 YOLOv8 推理等这种计算密集型任务时,C++ 没有解释器的开销,执行速度更快。 Python 代码的跨平台性较好,但在一些特殊的硬件平台或者嵌入式系统中,可能会受到限制。例如,在资源非常有限的嵌入式设备中,安装 Python 解释器以及相关的依赖库(如 NumPy、ONNX Runtime for Python 等)可能会占用过多的存储空间,并且 Python 解释器的运行也需要一定的资源支持。而且 Python 程序在不同的操作系统上可能会因为依赖库版本等问题出现兼容性问题。C++ 的跨平台性非常出色,并且可以通过编译器选项和特定的平台相关代码,更好地适应不同的硬件环境。对于 YOLOv8 等模型推理,如果要部署到嵌入式设备、工业控制设备等特殊平台,C++ 可以更方便地进行优化和定制。例如,在一些对性能和体积要求苛刻的嵌入式视觉系统中,C++ 可以直接编译成高效的机器码,并且可以根据设备的硬件特性进行针对性的优化,如利用硬件加速指令集等。 总之, 使用C++ 编写可以提供更快的实时性能。 笔者的环境是Windows11,CUDA 11.7,cuDNN 8.5,IDE是 vs2019。下载的ONNX Runtime的CPU和GPU版本为1.14.1。下载链接为https://github.com/microsoft/onnxruntime/releases/tag/v1.14.1
笔者下载的opencv 版本为 4.7.0 ,下载链接为 https://opencv.org/releases/
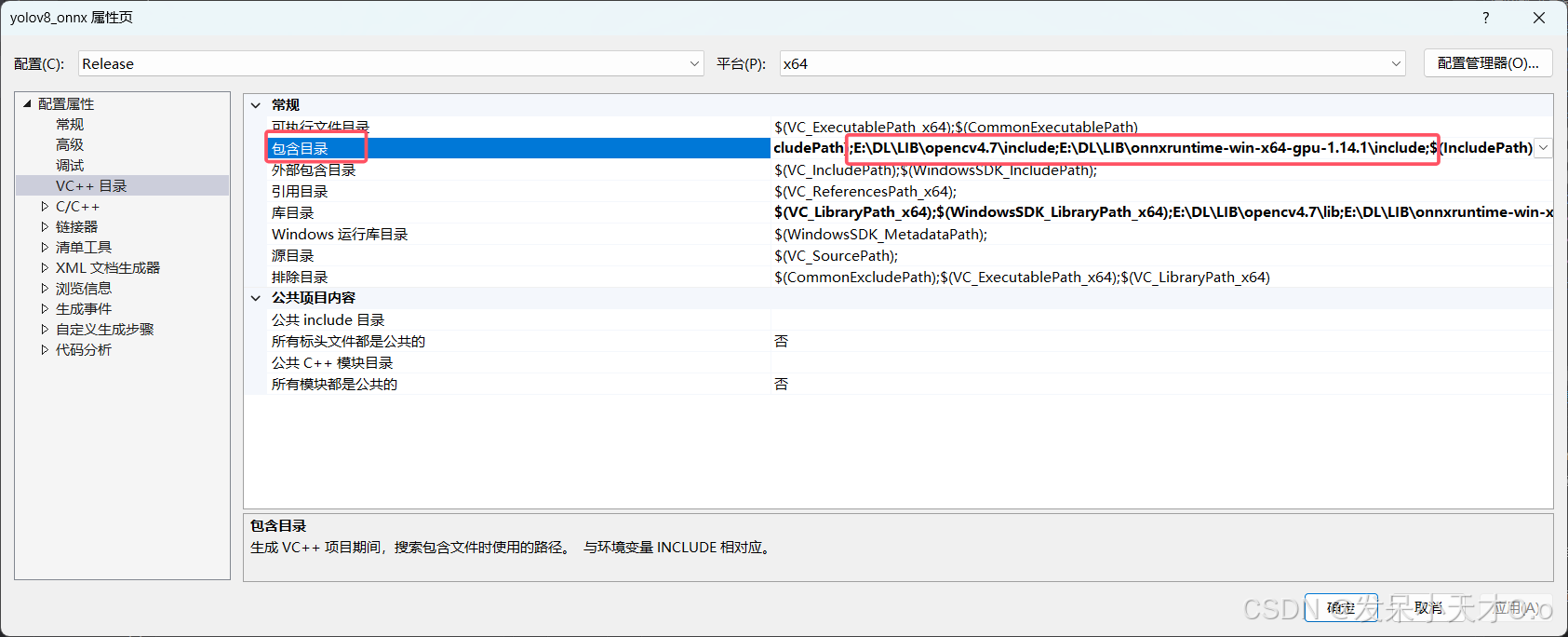
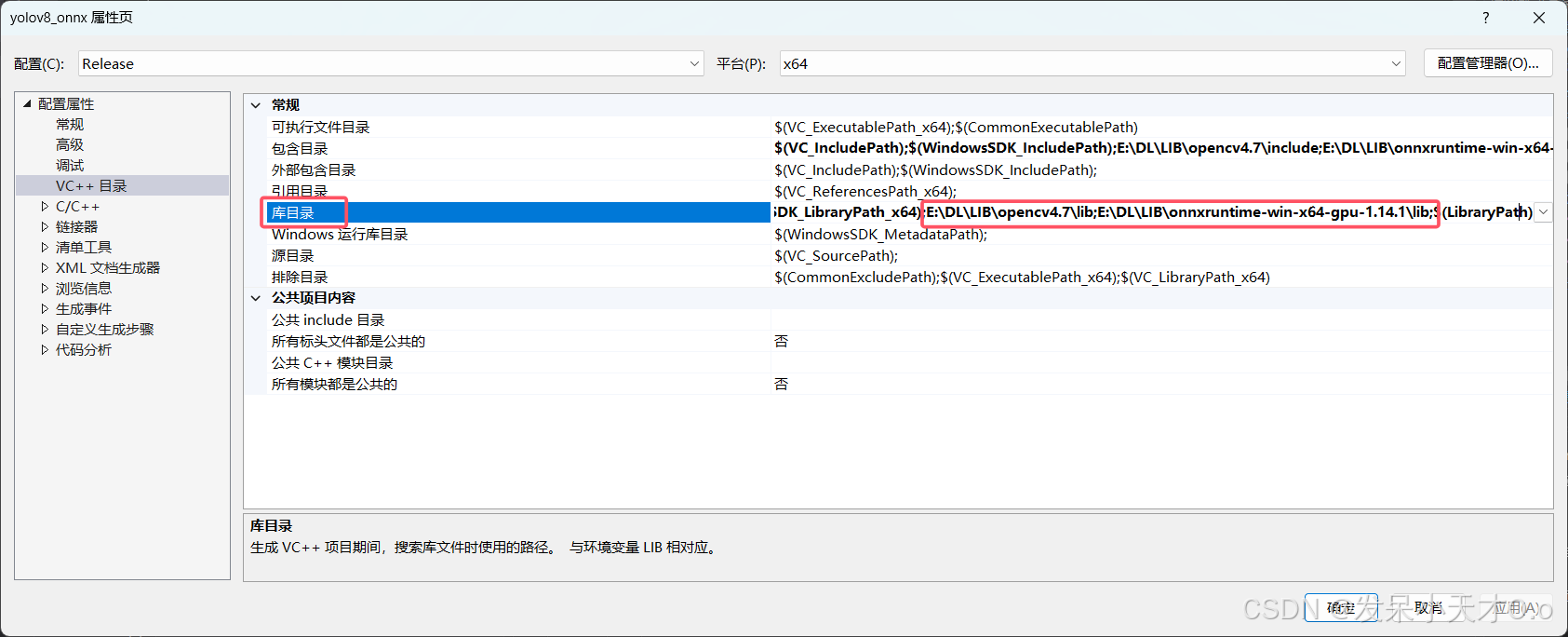
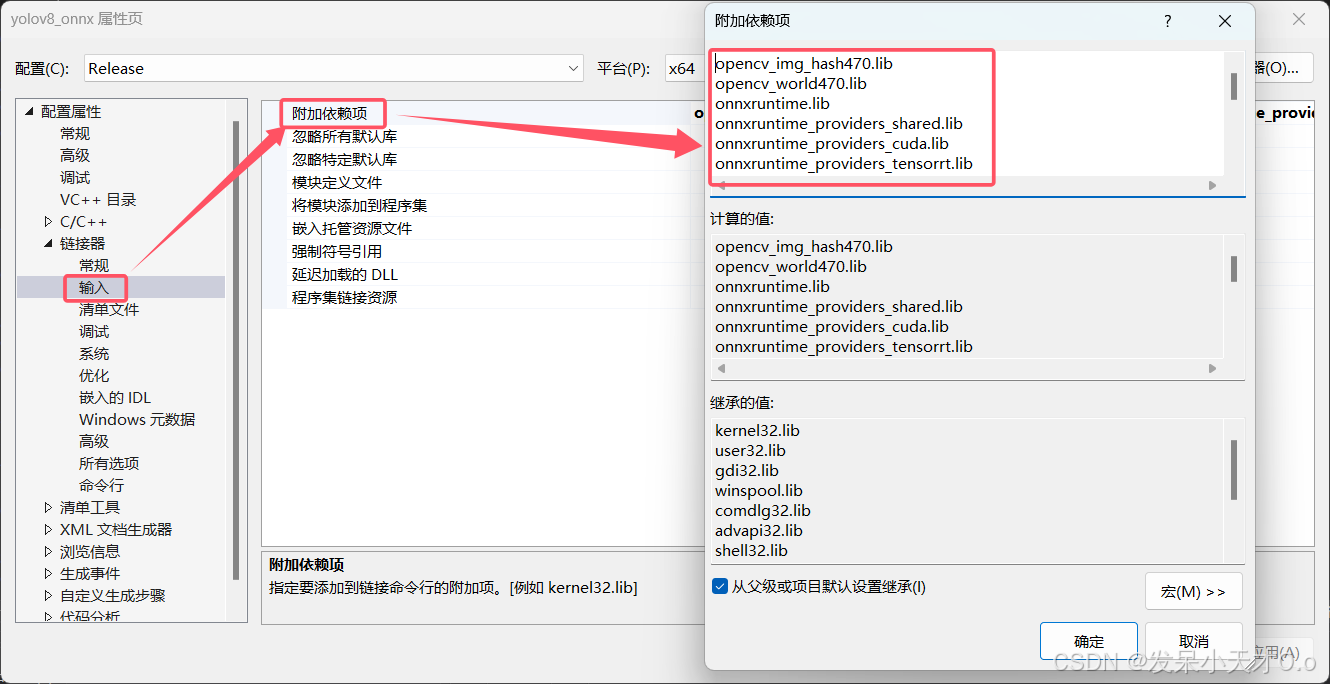
下载完成后解压,在项目属性配置ONNX Runtime和OpenCV。
同Python语言实现一样,模型推理部署需要三大步骤:预处理、模型推理、后处理。在这里,笔者重点介绍 使用C++实现模型推理的流程。
颜色空间转换,OpenCV 默认读取的图像是 BGR 格式,YOLO 模型通常要求输入 RGB 格式图像。 将图像调整为网络输入所需的固定尺寸(保持原始图像的宽高比在图像周围添加填充)。 归一化(将像素值缩放到 [0, 1] 区间)。 数据格式转换(HWC -> CHW)。 # include env = Ort :: Env ( OrtLoggingLevel:: ORT_LOGGING_LEVEL_WARNING, "YOLOV8" ) ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">Ort::Env 是 ONNX Runtime 中的环境对象,它是一个全局性的对象,用于初始化和管理 ONNX Runtime 运行时环境。功能:
初始化 ONNX Runtime 库。 控制日志记录级别和日志输出。 提供名称标识符,方便调试和跟踪。 ONNX Runtime 支持的日志级别:
ORT_LOGGING_LEVEL_VERBOSE:记录所有信息(详细级别)。 ORT_LOGGING_LEVEL_INFO:记录一般信息。 ORT_LOGGING_LEVEL_WARNING:记录警告信息。 ORT_LOGGING_LEVEL_ERROR:仅记录错误信息。 ORT_LOGGING_LEVEL_FATAL:仅记录致命错误信息。 设置 ONNX Runtime 会话的选项。这可能包括配置 GPU 使用、优化器级别、执行模式等。
sessionOptions = Ort :: SessionOptions ( ) ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">它控制 ONNX 模型在推理时的行为,包括:线程数(并行计算能力);优化级别(对模型进行图优化);CUDA 使用(GPU 加速);内存分配器;会话日志设置 等。
sessionOptions. SetIntraOpNumThreads ( 1 ) ;
OrtCUDAProviderOptions cudaOption;
sessionOptions. AppendExecutionProvider_CUDA ( cudaOption) ;
sessionOptions. SetGraphOptimizationLevel ( GraphOptimizationLevel:: ORT_ENABLE_ALL) ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">在 ONNX Runtime 中,SetGraphOptimizationLevel 用于设置图优化的级别,影响模型执行时的效率和性能。图优化有助于提高推理速度和减少内存消耗。不同的优化级别会对模型执行过程中的节点、计算图进行不同程度的优化。
常见的图优化级别
ORT_ENABLE_BASIC:
这是基本优化级别。 启用对计算图的基本优化,例如节点合并、常量折叠、去除无用的操作等。 相比于未启用优化,这个级别能带来一定程度的性能提升。 ORT_ENABLE_EXTENDED:
启用更高级的优化策略,例如通过对操作进行更复杂的优化来加速推理。 优化程度更高,可能会进一步减少内存占用和计算量。 ORT_ENABLE_ALL:
启用所有可能的优化策略,包括最激进的优化。 这是最大优化级别,会尝试最大限度地提升推理性能。 包括节点的合并、常量折叠、冗余节点移除、图的精简等多个优化过程。 适合追求最高性能的场景,但可能会增加模型加载时间,尤其是在某些复杂的模型中。 为什么使用 ORT_ENABLE_ALL?
性能提升: ORT_ENABLE_ALL 可以对计算图执行更多的优化,极大地提升推理速度。 内存优化:优化后的图通常会更小,内存占用也会减少。 适用场景:对于生产环境中的高性能需求,或者需要进行大量推理的场景,启用所有优化可以显著减少执行时间和内存消耗。 加载预训练的 ONNX 模型文件。
const wchar_t * modelPath = "yolov8.onnx" ;
Ort:: Session session ( env, modelPath, sessionOptions) ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">其中,第二个参数modelPath,模型的路径需要以宽字符(wchar_t*)格式传递。因为Windows 系统中的文件路径通常使用宽字符编码(wchar_t)。
可以使用c_str() 方法,它返回 std::wstring 对象的指针,确保符合 Ort::Session 构造函数 所需的格式。方便与需要const char或const wchar_t 类型的 C 风格函数或库(如 OpenCV、ONNX Runtime 等)兼容。
OpenCV:cv::imread() 接收 const char*。 ONNX Runtime(Windows 平台):Ort::Session 需要 const wchar_t* 。 对于 std::string:返回 const char*。 对于 std::wstring:返回 const wchar_t*。 如果你的模型路径原本是 std::string 类型,可以通过一个转换函数 将其转换为 std::wstring,例如:
std:: wstring w_modelPath = utils:: charToWstring ( modelPath. c_str ( ) ) ;
std:: wstring utils:: charToWstring ( const char * str)
{
typedef std:: codecvt_utf8< wchar_t > convert_type;
std:: wstring_convert< convert_type, wchar_t > converter;
return converter. from_bytes ( str) ;
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">从 Ort::Session 对象中获取模型输入和输出的详细信息,包括数量、名称、类型和形状。
在 ONNX Runtime 中,Ort::Session 提供了两种方法来获取模型输入/输出名称:
GetInputName
GetInputNameAllocated 内存管理 更为安全,因为返回的 Ort::AllocatedStringPtr 是 RAII 风格的对象,自动释放内存。
Ort:: AllocatorWithDefaultOptions allocator;
std:: vector< const char * > inputNames;
std:: vector< Ort:: AllocatedStringPtr> input_names_ptr;
std:: vector< std:: vector< int64_t >> inputShapes;
bool isDynamicInputShape{ } ;
size_t numInputNodes = session. GetInputCount ( ) ;
for ( size_t i = 0 ; i < numInputNodes; ++ i)
{
auto input_name= session. GetInputNameAllocated ( i, allocator) ;
inputNames. push_back ( input_name. get ( ) ) ;
input_names_ptr. push_back ( std:: move ( input_name) ) ;
Ort:: TypeInfo inputTypeInfo = session. GetInputTypeInfo ( i) ;
std:: vector< int64_t > inputTensorShape = inputTypeInfo. GetTensorTypeAndShapeInfo ( ) . GetShape ( ) ;
inputShapes. push_back ( inputTensorShape) ;
isDynamicInputShape = false ;
if ( inputTensorShape[ 2 ] == - 1 && inputTensorShape[ 3 ] == - 1 )
{
std:: cout << "Dynamic input shape" << std:: endl;
this -> isDynamicInputShape = true ;
}
}
std:: vector< const char * > outputNames;
std:: vector< Ort:: AllocatedStringPtr> output_names_ptr;
std:: vector< std:: vector< int64_t >> outputShapes;
int classNums = 3 ;
size_t numOutputNodes = session. GetOutputCount ( ) ;
if ( num_output_nodes > 1 )
{
hasMask = true ;
std:: cout << "Instance Segmentation" << std:: endl;
}
else
std:: cout << "Object Detection" << std:: endl;
for ( size_t i = 0 ; i < numOutputNodes; ++ i)
{
auto output_name = session. GetOutputNameAllocated ( i, allocator) ;
outputNames. push_back ( output_name. get ( ) ) ;
output_names_ptr. push_back ( std:: move ( output_name) ) ;
Ort:: TypeInfo outputTypeInfo = session. GetOutputTypeInfo ( i) ;
std:: vector< int64_t > outputTensorShape = outputTypeInfo. GetTensorTypeAndShapeInfo ( ) . GetShape ( ) ;
outputShapes. push_back ( outputTensorShape) ;
if ( i == 0 )
{
if ( ! this -> hasMask)
classNums = outputTensorShape[ 1 ] - 4 ;
else
classNums = outputTensorShape[ 1 ] - 4 - 32 ;
}
}
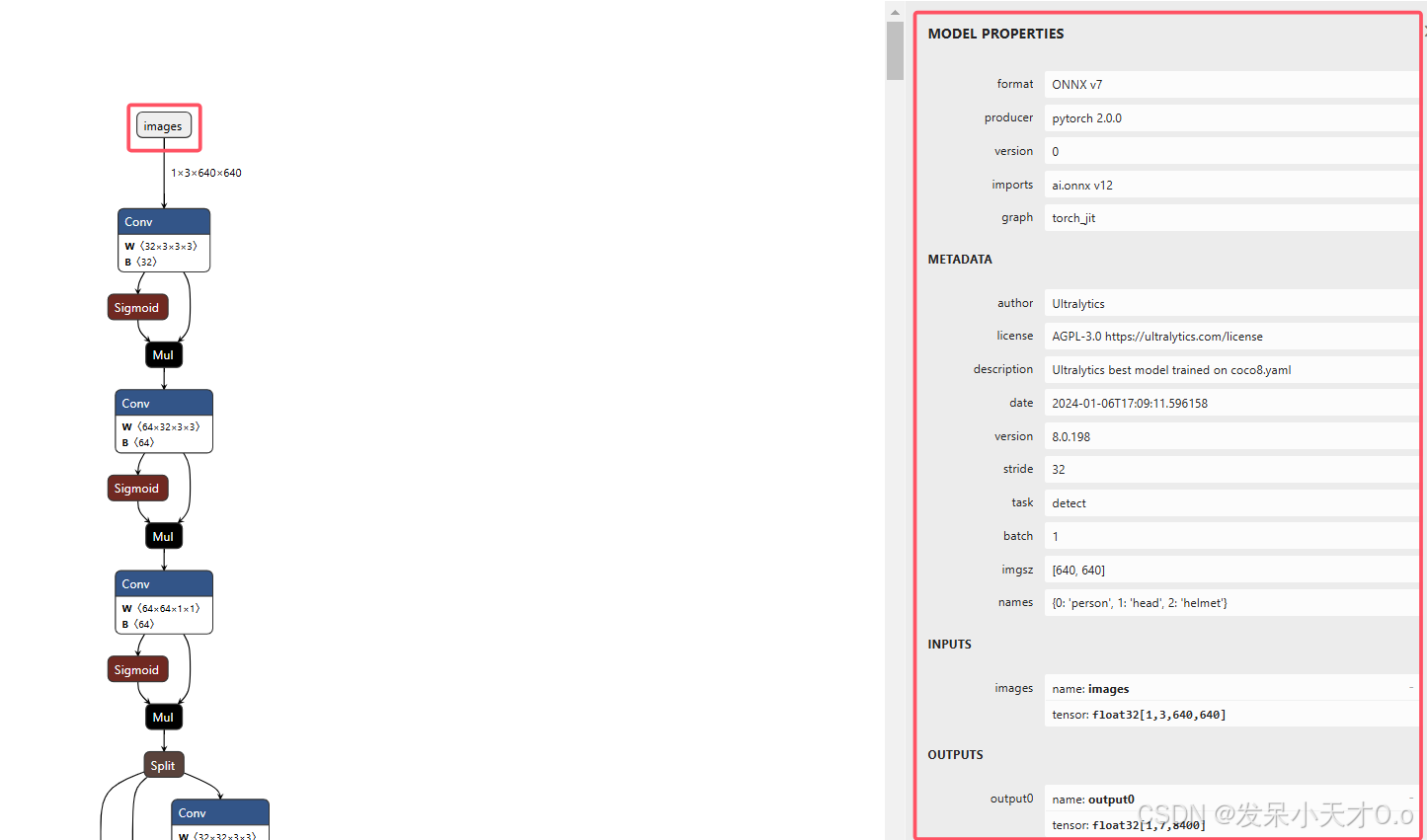
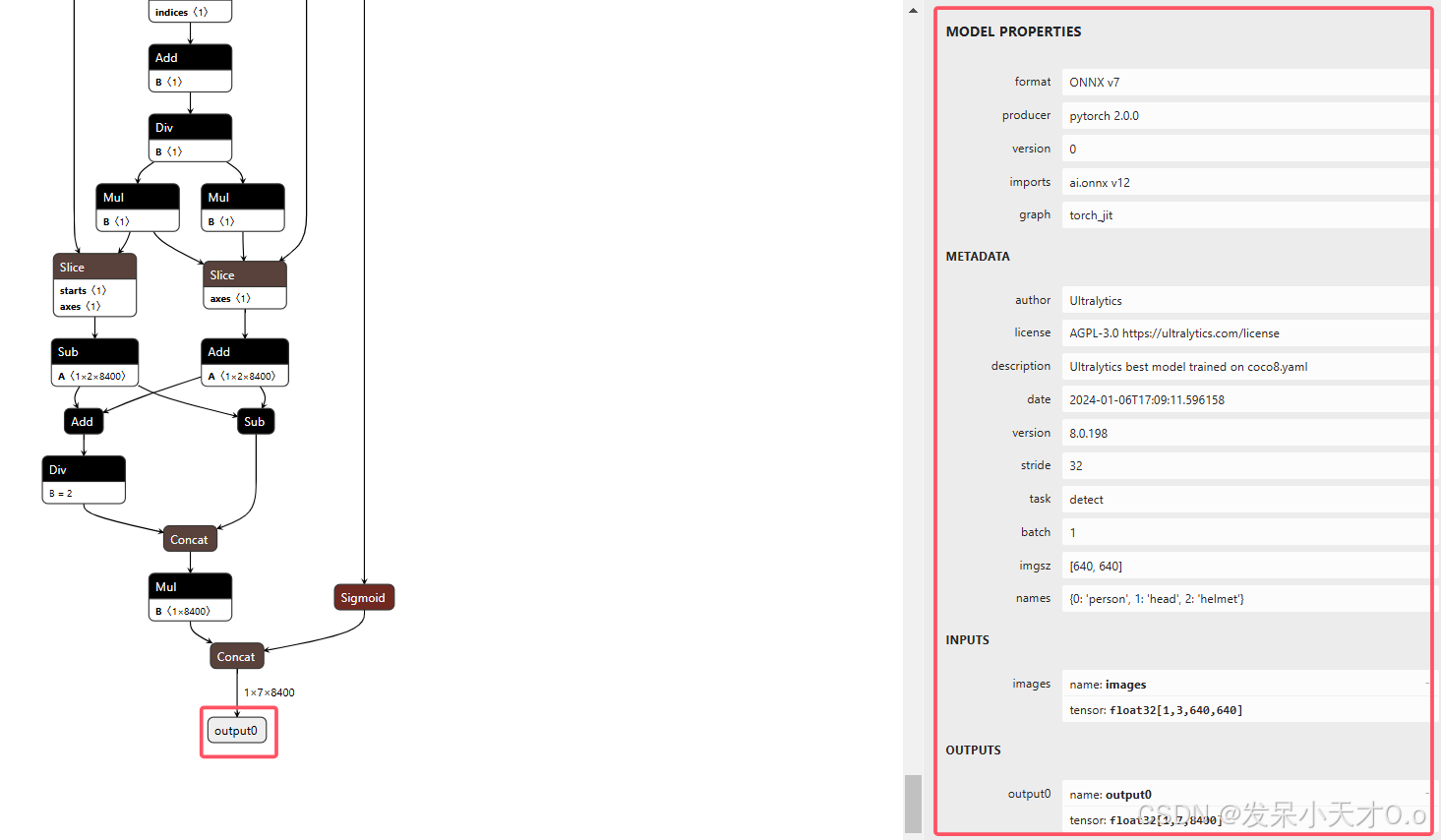
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 查看模型的输入和输出层可以使用netron 这个网站可视化,直接导入onnx模型即可。
输入层:
std:: vector< Ort:: Value> inputTensors;
Ort:: MemoryInfo memoryInfo = Ort:: MemoryInfo :: CreateCpu ( OrtAllocatorType:: OrtArenaAllocator, OrtMemType:: OrtMemTypeDefault) ;
inputTensors. push_back ( Ort:: Value:: CreateTensor < float > (
memoryInfo, inputTensorValues. data ( ) , inputTensorSize,
inputTensorShape. data ( ) , inputTensorShape. size ( ) ) ) ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">CreateTensor参数解释:
std:: vector< Ort:: Value> outputTensors = session. Run ( Ort:: RunOptions{ nullptr } ,
inputNames. data ( ) , inputTensors. data ( ) , 1 ,
outputNames. data ( ) , outputNames. size ( ) ) ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">run 参数解释:
Run 返回一个包含 输出 Tensor 的向量 std::vectorOrt::Value,每个 Ort::Value 包含模型的一个输出。
从输出张量获取数据,并通过 cv::Mat 转换为矩阵格式(CHW → HWC)。 提取最高置信度的类别和对应的分数,过滤低置信度目标。 将中心坐标 (cx, cy) 和宽高 (w, h) 转换为左上角坐标 (x, y) 和尺寸格式。 去除重叠度高的冗余检测框,保留置信度最高的框。 将检测框从网络输入尺寸映射回原图尺寸。 utils.cpp
# include "utils.h" :: vectorProduct ( const std:: vector< int64_t > & vector)
{
if ( vector. empty ( ) )
return 0 ;
size_t product = 1 ;
for ( const auto & element : vector)
product *= element;
return product;
}
std:: wstring utils:: charToWstring ( const char * str)
{
typedef std:: codecvt_utf8< wchar_t > convert_type;
std:: wstring_convert< convert_type, wchar_t > converter;
return converter. from_bytes ( str) ;
}
std:: vector< std:: string> utils:: loadNames ( const std:: string & path)
{
std:: vector< std:: string> classNames;
std:: ifstream infile ( path) ;
if ( infile. good ( ) )
{
std:: string line;
while ( getline ( infile, line) )
{
if ( line. back ( ) == '\r' )
line. pop_back ( ) ;
classNames. emplace_back ( line) ;
}
infile. close ( ) ;
}
else
{
std:: cerr << "ERROR: Failed to access class name path: " << path << std:: endl;
}
srand ( time ( 0 ) ) ;
for ( int i = 0 ; i < 2 * classNames. size ( ) ; i++ )
{
int b = rand ( ) % 256 ;
int g = rand ( ) % 256 ;
int r = rand ( ) % 256 ;
colors. push_back ( cv:: Scalar ( b, g, r) ) ;
}
return classNames;
}
void utils:: visualizeDetection ( cv:: Mat & im, std:: vector< Yolov8Result> & results,
const std:: vector< std:: string> & classNames)
{
cv:: Mat image = im. clone ( ) ;
for ( const Yolov8Result & result : results)
{
int x = result. box. x;
int y = result. box. y;
int conf = ( int ) std:: round ( result. conf * 100 ) ;
int classId = result. classId;
std:: string label = classNames[ classId] + " 0." + std:: to_string ( conf) ;
int baseline = 0 ;
cv:: Size size = cv:: getTextSize ( label, cv:: FONT_ITALIC, 0.4 , 1 , & baseline) ;
image ( result. box) . setTo ( colors[ classId + classNames. size ( ) ] , result. boxMask) ;
cv:: rectangle ( image, result. box, colors[ classId] , 2 ) ;
cv:: rectangle ( image,
cv:: Point ( x, y) , cv:: Point ( x + size. width, y + 12 ) ,
colors[ classId] , - 1 ) ;
cv:: putText ( image, label,
cv:: Point ( x, y - 3 + 12 ) , cv:: FONT_ITALIC,
0.4 , cv:: Scalar ( 0 , 0 , 0 ) , 1 ) ;
}
cv:: addWeighted ( im, 0.4 , image, 0.6 , 0 , im) ;
}
void utils:: letterbox ( const cv:: Mat & image, cv:: Mat & outImage,
const cv:: Size & newShape = cv:: Size ( 640 , 640 ) ,
const cv:: Scalar & color = cv:: Scalar ( 114 , 114 , 114 ) ,
bool auto_ = true ,
bool scaleFill = false ,
bool scaleUp = true ,
int stride = 32 )
{
cv:: Size shape = image. size ( ) ;
float r = std:: min ( ( float ) newShape. height / ( float ) shape. height,
( float ) newShape. width / ( float ) shape. width) ;
if ( ! scaleUp)
r = std:: min ( r, 1.0f ) ;
float ratio[ 2 ] { r, r} ;
int newUnpad[ 2 ] { ( int ) std:: round ( ( float ) shape. width * r) ,
( int ) std:: round ( ( float ) shape. height * r) } ;
auto dw = ( float ) ( newShape. width - newUnpad[ 0 ] ) ;
auto dh = ( float ) ( newShape. height - newUnpad[ 1 ] ) ;
if ( auto_)
{
dw = ( float ) ( ( int ) dw % stride) ;
dh = ( float ) ( ( int ) dh % stride) ;
}
else if ( scaleFill)
{
dw = 0.0f ;
dh = 0.0f ;
newUnpad[ 0 ] = newShape. width;
newUnpad[ 1 ] = newShape. height;
ratio[ 0 ] = ( float ) newShape. width / ( float ) shape. width;
ratio[ 1 ] = ( float ) newShape. height / ( float ) shape. height;
}
dw /= 2.0f ;
dh /= 2.0f ;
if ( shape. width != newUnpad[ 0 ] && shape. height != newUnpad[ 1 ] )
{
cv:: resize ( image, outImage, cv:: Size ( newUnpad[ 0 ] , newUnpad[ 1 ] ) ) ;
}
int top = int ( std:: round ( dh - 0.1f ) ) ;
int bottom = int ( std:: round ( dh + 0.1f ) ) ;
int left = int ( std:: round ( dw - 0.1f ) ) ;
int right = int ( std:: round ( dw + 0.1f ) ) ;
cv:: copyMakeBorder ( outImage, outImage, top, bottom, left, right, cv:: BORDER_CONSTANT, color) ;
}
void utils:: scaleCoords ( cv:: Rect & coords,
cv:: Mat & mask,
const float maskThreshold,
const cv:: Size & imageShape,
const cv:: Size & imageOriginalShape)
{
float gain = std:: min ( ( float ) imageShape. height / ( float ) imageOriginalShape. height,
( float ) imageShape. width / ( float ) imageOriginalShape. width) ;
int pad[ 2 ] = { ( int ) ( ( ( float ) imageShape. width - ( float ) imageOriginalShape. width * gain) / 2.0f ) ,
( int ) ( ( ( float ) imageShape. height - ( float ) imageOriginalShape. height * gain) / 2.0f ) } ;
coords. x = ( int ) std:: round ( ( ( float ) ( coords. x - pad[ 0 ] ) / gain) ) ;
coords. x = std:: max ( 0 , coords. x) ;
coords. y = ( int ) std:: round ( ( ( float ) ( coords. y - pad[ 1 ] ) / gain) ) ;
coords. y = std:: max ( 0 , coords. y) ;
coords. width = ( int ) std:: round ( ( ( float ) coords. width / gain) ) ;
coords. width = std:: min ( coords. width, imageOriginalShape. width - coords. x) ;
coords. height = ( int ) std:: round ( ( ( float ) coords. height / gain) ) ;
coords. height = std:: min ( coords. height, imageOriginalShape. height - coords. y) ;
mask = mask ( cv:: Rect ( pad[ 0 ] , pad[ 1 ] , imageShape. width - 2 * pad[ 0 ] , imageShape. height - 2 * pad[ 1 ] ) ) ;
cv:: resize ( mask, mask, imageOriginalShape, cv:: INTER_LINEAR) ;
mask = mask ( coords) > maskThreshold;
}
template < typename T >
T utils:: clip ( const T & n, const T & lower, const T & upper)
{
return std:: max ( lower, std:: min ( n, upper) ) ;
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 predictor.cpp
# include "yolov8Predictor.h" YOLOPredictor :: YOLOPredictor ( const std:: string & modelPath,
const bool & isGPU,
float confThreshold,
float iouThreshold,
float maskThreshold)
{
this -> confThreshold = confThreshold;
this -> iouThreshold = iouThreshold;
this -> maskThreshold = maskThreshold;
env = Ort :: Env ( OrtLoggingLevel:: ORT_LOGGING_LEVEL_WARNING, "YOLOV8" ) ;
sessionOptions = Ort :: SessionOptions ( ) ;
std:: vector< std:: string> availableProviders = Ort :: GetAvailableProviders ( ) ;
std:: cout << "--------------------" << std:: endl;
for ( int i = 0 ; i < availableProviders. size ( ) ; ++ i)
{
std:: cout << availableProviders. at ( i) << std:: endl;
}
auto cudaAvailable = std:: find ( availableProviders. begin ( ) , availableProviders. end ( ) , "CUDAExecutionProvider" ) ;
OrtCUDAProviderOptions cudaOption;
if ( isGPU && ( cudaAvailable == availableProviders. end ( ) ) )
{
std:: cout << "GPU is not supported by your ONNXRuntime build. Fallback to CPU." << std:: endl;
std:: cout << "Inference device: CPU" << std:: endl;
}
else if ( isGPU && ( cudaAvailable != availableProviders. end ( ) ) )
{
std:: cout << "Inference device: GPU" << std:: endl;
sessionOptions. AppendExecutionProvider_CUDA ( cudaOption) ;
}
else
{
std:: cout << "Inference device: CPU" << std:: endl;
}
# ifdef _WIN32 :: wstring w_modelPath = utils:: charToWstring ( modelPath. c_str ( ) ) ;
session = Ort :: Session ( env, w_modelPath. c_str ( ) , sessionOptions) ;
# else = Ort :: Session ( env, modelPath. c_str ( ) , sessionOptions) ;
# endif const size_t num_input_nodes = session. GetInputCount ( ) ;
const size_t num_output_nodes = session. GetOutputCount ( ) ;
if ( num_output_nodes > 1 )
{
this -> hasMask = true ;
std:: cout << "Instance Segmentation" << std:: endl;
}
else
std:: cout << "Object Detection" << std:: endl;
Ort:: AllocatorWithDefaultOptions allocator;
for ( int i = 0 ; i < num_input_nodes; i++ )
{
auto input_name = session. GetInputNameAllocated ( i, allocator) ;
this -> inputNames. push_back ( input_name. get ( ) ) ;
input_names_ptr. push_back ( std:: move ( input_name) ) ;
Ort:: TypeInfo inputTypeInfo = session. GetInputTypeInfo ( i) ;
std:: vector< int64_t > inputTensorShape = inputTypeInfo. GetTensorTypeAndShapeInfo ( ) . GetShape ( ) ;
this -> inputShapes. push_back ( inputTensorShape) ;
this -> isDynamicInputShape = false ;
if ( inputTensorShape[ 2 ] == - 1 && inputTensorShape[ 3 ] == - 1 )
{
std:: cout << "Dynamic input shape" << std:: endl;
this -> isDynamicInputShape = true ;
}
}
for ( int i = 0 ; i < num_output_nodes; i++ )
{
auto output_name = session. GetOutputNameAllocated ( i, allocator) ;
this -> outputNames. push_back ( output_name. get ( ) ) ;
output_names_ptr. push_back ( std:: move ( output_name) ) ;
Ort:: TypeInfo outputTypeInfo = session. GetOutputTypeInfo ( i) ;
std:: vector< int64_t > outputTensorShape = outputTypeInfo. GetTensorTypeAndShapeInfo ( ) . GetShape ( ) ;
this -> outputShapes. push_back ( outputTensorShape) ;
if ( i == 0 )
{
if ( ! this -> hasMask)
classNums = outputTensorShape[ 1 ] - 4 ;
else
classNums = outputTensorShape[ 1 ] - 4 - 32 ;
}
}
}
void YOLOPredictor :: getBestClassInfo ( std:: vector< float > :: iterator it,
float & bestConf,
int & bestClassId,
const int _classNums)
{
bestClassId = 4 ;
bestConf = 0 ;
for ( int i = 4 ; i < _classNums + 4 ; i++ )
{
if ( it[ i] > bestConf)
{
bestConf = it[ i] ;
bestClassId = i - 4 ;
}
}
}
cv:: Mat YOLOPredictor :: getMask ( const cv:: Mat & maskProposals,
const cv:: Mat & maskProtos)
{
cv:: Mat protos = maskProtos. reshape ( 0 , { ( int ) this -> outputShapes[ 1 ] [ 1 ] , ( int ) this -> outputShapes[ 1 ] [ 2 ] * ( int ) this -> outputShapes[ 1 ] [ 3 ] } ) ;
cv:: Mat matmul_res = ( maskProposals * protos) . t ( ) ;
cv:: Mat masks = matmul_res. reshape ( 1 , { ( int ) this -> outputShapes[ 1 ] [ 2 ] , ( int ) this -> outputShapes[ 1 ] [ 3 ] } ) ;
cv:: Mat dest;
cv:: exp ( - masks, dest) ;
dest = 1.0 / ( 1.0 + dest) ;
cv:: resize ( dest, dest, cv:: Size ( ( int ) this -> inputShapes[ 0 ] [ 2 ] , ( int ) this -> inputShapes[ 0 ] [ 3 ] ) , cv:: INTER_LINEAR) ;
return dest;
}
void YOLOPredictor :: preprocessing ( cv:: Mat & image, float * & blob, std:: vector< int64_t > & inputTensorShape)
{
cv:: Mat resizedImage, floatImage;
cv:: cvtColor ( image, resizedImage, cv:: COLOR_BGR2RGB) ;
utils:: letterbox ( resizedImage, resizedImage, cv:: Size ( ( int ) this -> inputShapes[ 0 ] [ 2 ] , ( int ) this -> inputShapes[ 0 ] [ 3 ] ) ,
cv:: Scalar ( 114 , 114 , 114 ) , this -> isDynamicInputShape,
false , true , 32 ) ;
inputTensorShape[ 2 ] = resizedImage. rows;
inputTensorShape[ 3 ] = resizedImage. cols;
resizedImage. convertTo ( floatImage, CV_32FC3, 1 / 255.0 ) ;
blob = new float [ floatImage. cols * floatImage. rows * floatImage. channels ( ) ] ;
cv:: Size floatImageSize{ floatImage. cols, floatImage. rows} ;
std:: vector< cv:: Mat> chw ( floatImage. channels ( ) ) ;
for ( int i = 0 ; i < floatImage. channels ( ) ; ++ i)
{
chw[ i] = cv:: Mat ( floatImageSize, CV_32FC1, blob + i * floatImageSize. width * floatImageSize. height) ;
}
cv:: split ( floatImage, chw) ;
}
std:: vector< Yolov8Result> YOLOPredictor :: postprocessing ( const cv:: Size & resizedImageShape,
const cv:: Size & originalImageShape,
std:: vector< Ort:: Value> & outputTensors)
{
std:: vector< cv:: Rect> boxes;
std:: vector< float > confs;
std:: vector< int > classIds;
float * boxOutput = outputTensors[ 0 ] . GetTensorMutableData < float > ( ) ;
cv:: Mat output0 = cv:: Mat ( cv:: Size ( ( int ) this -> outputShapes[ 0 ] [ 2 ] , ( int ) this -> outputShapes[ 0 ] [ 1 ] ) , CV_32F, boxOutput) . t ( ) ;
float * output0ptr = ( float * ) output0. data;
int rows = ( int ) this -> outputShapes[ 0 ] [ 2 ] ;
int cols = ( int ) this -> outputShapes[ 0 ] [ 1 ] ;
std:: vector< std:: vector< float >> picked_proposals;
cv:: Mat mask_protos;
for ( int i = 0 ; i < rows; i++ )
{
std:: vector< float > it ( output0ptr + i * cols, output0ptr + ( i + 1 ) * cols) ;
float confidence;
int classId;
this -> getBestClassInfo ( it. begin ( ) , confidence, classId, classNums) ;
if ( confidence > this -> confThreshold)
{
if ( this -> hasMask)
{
std:: vector< float > temp ( it. begin ( ) + 4 + classNums, it. end ( ) ) ;
picked_proposals. push_back ( temp) ;
}
int centerX = ( int ) ( it[ 0 ] ) ;
int centerY = ( int ) ( it[ 1 ] ) ;
int width = ( int ) ( it[ 2 ] ) ;
int height = ( int ) ( it[ 3 ] ) ;
int left = centerX - width / 2 ;
int top = centerY - height / 2 ;
boxes. emplace_back ( left, top, width, height) ;
confs. emplace_back ( confidence) ;
classIds. emplace_back ( classId) ;
}
}
std:: vector< int > indices;
cv:: dnn:: NMSBoxes ( boxes, confs, this -> confThreshold, this -> iouThreshold, indices) ;
if ( this -> hasMask)
{
float * maskOutput = outputTensors[ 1 ] . GetTensorMutableData < float > ( ) ;
std:: vector< int > mask_protos_shape = { 1 , ( int ) this -> outputShapes[ 1 ] [ 1 ] , ( int ) this -> outputShapes[ 1 ] [ 2 ] , ( int ) this -> outputShapes[ 1 ] [ 3 ] } ;
mask_protos = cv:: Mat ( mask_protos_shape, CV_32F, maskOutput) ;
}
std:: vector< Yolov8Result> results;
for ( int idx : indices)
{
Yolov8Result res;
res. box = cv:: Rect ( boxes[ idx] ) ;
if ( this -> hasMask)
res. boxMask = this -> getMask ( cv:: Mat ( picked_proposals[ idx] ) . t ( ) , mask_protos) ;
else
res. boxMask = cv:: Mat :: zeros ( ( int ) this -> inputShapes[ 0 ] [ 2 ] , ( int ) this -> inputShapes[ 0 ] [ 3 ] , CV_8U) ;
utils:: scaleCoords ( res. box, res. boxMask, this -> maskThreshold, resizedImageShape, originalImageShape) ;
res. conf = confs[ idx] ;
res. classId = classIds[ idx] ;
results. emplace_back ( res) ;
}
return results;
}
std:: vector< Yolov8Result> YOLOPredictor :: predict ( cv:: Mat & image)
{
float * blob = nullptr ;
std:: vector< int64_t > inputTensorShape{ 1 , 3 , - 1 , - 1 } ;
this -> preprocessing ( image, blob, inputTensorShape) ;
size_t inputTensorSize = utils:: vectorProduct ( inputTensorShape) ;
std:: vector< float > inputTensorValues ( blob, blob + inputTensorSize) ;
std:: vector< Ort:: Value> inputTensors;
Ort:: MemoryInfo memoryInfo = Ort:: MemoryInfo :: CreateCpu (
OrtAllocatorType:: OrtArenaAllocator, OrtMemType:: OrtMemTypeDefault) ;
inputTensors. push_back ( Ort:: Value:: CreateTensor < float > (
memoryInfo, inputTensorValues. data ( ) , inputTensorSize,
inputTensorShape. data ( ) , inputTensorShape. size ( ) ) ) ;
std:: vector< Ort:: Value> outputTensors = this -> session. Run ( Ort:: RunOptions{ nullptr } ,
this -> inputNames. data ( ) ,
inputTensors. data ( ) ,
1 ,
this -> outputNames. data ( ) ,
this -> outputNames. size ( ) ) ;
cv:: Size resizedShape = cv:: Size ( ( int ) inputTensorShape[ 3 ] , ( int ) inputTensorShape[ 2 ] ) ;
std:: vector< Yolov8Result> result = this -> postprocessing ( resizedShape,
image. size ( ) ,
outputTensors) ;
delete [ ] blob;
return result;
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 图片测试:



评论记录:
回复评论: