1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81
• 查看⽂档我们会发现unordered_map的⽀持增删查改且跟map的使⽤⼀模⼀样,关于使⽤我们这⾥就不再赘述和演⽰了。
•unordered_map和map的第⼀个差异是对key的要求不同,map要求Key⽀持⼩于⽐较,⽽unordered_map要求Key⽀持转成整形且⽀持等于⽐较,要理解unordered_map的这个两点要求得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求。
•unordered_map和map的第⼆个差异是迭代器的差异,map的iterator是双向迭代器,unordered_map是单向迭代器,其次map底层是红⿊树,红⿊树是⼆叉搜索树,⾛中序遍历是有序的,所以map迭代器遍历是Key有序+去重。⽽unordered_map底层是哈希表,迭代器遍历是Key⽆序+去重。
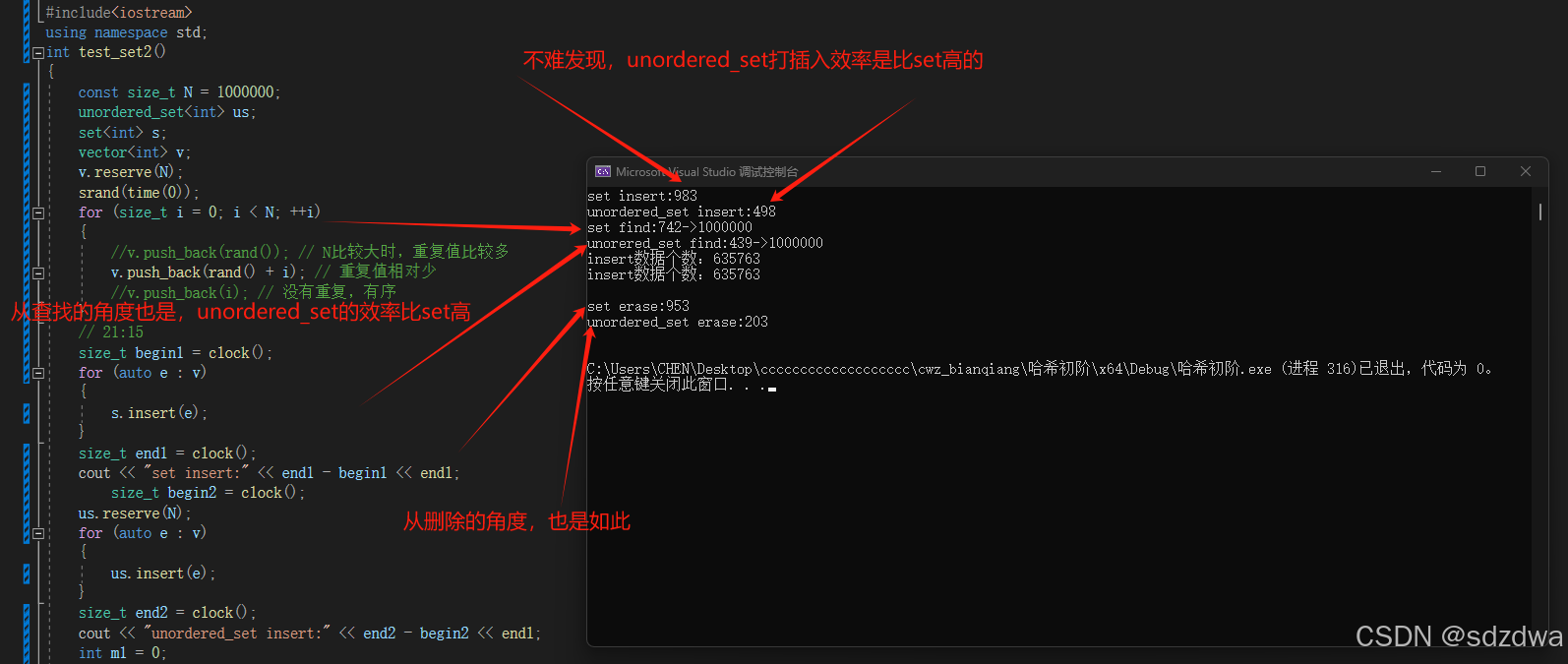
•unordered_map和map的第三个差异是性能的差异,整体⽽⾔⼤多数场景下,unordered_map的增删查改更快⼀些,因为红⿊树增删查改效率是,⽽哈希表增删查平均效率是 ,具体可以参看下⾯代码的演⽰的对⽐差异。
有上面可以得知,unordered_set、unordered_map底层是哈希表实现的,我们不禁好奇,哈希表是怎么样的呢?哈希表是怎么样实现O(1)的效率的呢?为什么会无序呢?
哈希(hash)⼜称散列,是⼀种组织数据的⽅式。从译名来看,有散乱排列的意思。本质就是通过哈希函数把关键字Key跟存储位置建⽴⼀个映射关系,查找时通过这个哈希函数计算出Key存储的位置,进⾏快速查找。
当关键字的范围⽐较集中时,直接定址法就是⾮常简单⾼效的⽅法,⽐如⼀组关键字都在[0,99]之间,那么我们开⼀个100个数的数组,每个关键字的值直接就是存储位置的下标。再⽐如⼀组关键字值都在[a,z]的⼩写字⺟,那么我们开⼀个26个数的数组,每个关键字acsii码-a ascii码就是存储位置的下标。也就是说直接定址法本质就是⽤关键字计算出⼀个绝对位置或者相对位置。这个⽅法我们在计数排序部分已经⽤过了,其次在string章节的下⾯OJ也⽤过了。
直接定址法:
这种方法高效,简单
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
字符串中的第一个唯一字符
class Solution {
public :
int firstUniqChar ( string s) {
int count[ 26 ] = { 0 } ;
for ( auto ch : s)
{
count[ ch- 'a' ] ++ ;
}
for ( size_t i = 0 ; i < s. size ( ) ; ++ i)
{
if ( count[ s[ i] - 'a' ] == 1 )
return i;
}
return - 1 ;
}
} ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 总结:直接定地址法:是最简洁、最高效的哈希,但是也有限制条件:数据要集中。 如果数据离散那么就会导致空间利用率低、关键字范围限制、机动性差
哈希冲突体现了直接定址法的弊端:
直接定址法的缺点也⾮常明显,当关键字的范围⽐较分散时,就很浪费内存甚⾄内存不够⽤。假设我们只有数据范围是[0, 9999]的N个值,我们要映射到⼀个M个空间的数组中(⼀般情况下M >= N),那么就要借助哈希函数(hashfunction)hf,关键字key被放到数组的h(key)位置,这⾥要注意的是h(key)计算出的值必须在[0, M)之间。这⾥存在的⼀个问题就是,两个不同的key可能会映射到同⼀个位置去,这种问题我们叫做哈希冲突,或者哈希碰撞。理想情况是找出⼀个好的哈希函数避免冲突,但是实际场景中,冲突是不可避免的,所以我们尽可能设计出优秀的哈希函数,减少冲突的次数,同时也要去设计出决冲突的⽅案。
总结:在哈希表中避免不了哈希映射,为了解决或适应哈希冲突,人们要去设计出减缓哈希冲突或适应哈希冲突的方案。
假设哈希表中已经映射存储了N个值,哈希表的⼤⼩为M,那么 ,负载因⼦有些地⽅也翻译为载荷因⼦/装载因⼦等,他的英⽂为load factor。负载因⼦越⼤,哈希冲突的概率越⾼,空间利⽤率越⾼;负载因⼦越⼩,哈希冲突的概率越低,空间利⽤率越低;
我们将关键字映射到数组中位置,⼀般是整数好做映射计算,如果不是整数,我们要想办法转换成整数,这个细节我们后⾯代码实现中再进⾏细节展⽰。下⾯哈希函数部分我们讨论时,如果关键字不是整数,那么我们讨论的Key是关键字转换成的整数。
【注意】这是对哈希的数据类型Key值的要求如下:
⼀个好的哈希函数应该让N个关键字被等概率的均匀的散列分布到哈希表的M个空间中,但是实际中却很难做到,但是我们要尽量往这个⽅向去考量设计.
【说明】 哈希函数功能:
• 除法散列法也叫做除留余数法,顾名思义,假设哈希表的⼤⼩为M,那么通过key除以M的余数作为映射位置的下标,也就是哈希函数为:h(key) = key % M。
•当使⽤除法散列法时,要尽量避免M为某些值,如2的冥,10的冥等。如果是 ,那么key %2^x本质相当于保留key的后X位,那么后x位相同的值,计算出的哈希值都是⼀样的,就冲突了。如:{63 , 31}看起来没有关联的值,如果M是16,也就是 ,那么计算出的哈希值都是15,因为63的⼆进制后8位是 00111111,31的⼆进制后8位是 00011111。如果是 ,就更明显了,保留的都是10进值的后x位,如:{112, 12312},如果M是100,也就是 ,那么计算出的哈希值都是12
•当使⽤除法散列法时,建议M取不太接近2的整数次冥的⼀个质数(素数)。
出了除法散列之外还有许多的哈希函数,这提一下:乘法散列法
• 乘法散列法对哈希表⼤⼩M没有要求,他的⼤思路第⼀步:⽤关键字 K 乘上常数 A (0A 的⼩数部分。第⼆步:后再⽤M乘以kA 的⼩数部分,再向下取整。
• h(key) = floor(M × ((A × key)%1.0)),其中floor表⽰对表达式进⾏下取整,A∈(0,1),这⾥ 最重要的是A的值应该如何设定,Knuth认为 (⻩⾦分割点]) ⽐较好。 h(key) = floor(M × ((A ×key)%1.0)) A = ( 5 − 1)/2 = 0.6180339887…
• 乘法散列法对哈希表⼤⼩M是没有要求的,假设M为1024,key为1234,A = 0.6180339887, Akey = 762.6539420558,取⼩数部分为0.6539420558, M×((A×key)%1.0) = 0.6539420558 1024 =669.6366651392,那么h(1234) = 669。
全域散列法
• 如果存在⼀个恶意的对⼿,他针对我们提供的散列函数,特意构造出⼀个发⽣严重冲突的数据集,⽐如,让所有关键字全部落⼊同⼀个位置中。这种情况是可以存在的,只要散列函数是公开且确定的,就可以实现此攻击。解决⽅法⾃然是⻅招拆招,给散列函数增加随机性,攻击者就⽆法找出确定可以导致最坏情况的数据。这种⽅法叫做全域散列。
解决方案
• h (key) = ((a × key + b)%P )%M (P-1)组全域散列函数组。
• 需要注意的是每次初始化哈希表时,随机选取全域散列函数组中的⼀个散列函数使⽤,后续增删查改都固定使⽤这个散列函数,否则每次哈希都是随机选⼀个散列函数,那么插⼊是⼀个散列函数,查找⼜是另⼀个散列函数,就会导致找不到插⼊的key了。
在开放定址法中所有的元素都放到哈希表⾥,当⼀个关键字key⽤哈希函数计算出的位置冲突了,则按照某种规则找到⼀个没有存储数据的位置进⾏存储,开放定址法中负载因⼦⼀定是⼩于的。这⾥的规则有三种:线性探测、⼆次探测、双重探测。
线性探测
• 从发⽣冲突的位置开始,依次线性向后探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果⾛到哈希表尾,则回绕到哈希表头的位置。
•h(key) = hash0 = key % M, hash0位置冲突了,则线性探测公式为: hc(key,i) = hashi =(hash0 + i) % M, i = {1, 2, 3, …, M −1},因为负载因⼦⼩于1,则最多探测M-1次,⼀定能找到⼀个存储key的位置。
•线性探测的⽐较简单且容易实现,线性探测的问题假设,hash0位置连续冲突,hash0,hash1,hash2位置已经存储数据了,后续映射到hash0,hash1,hash2,hash3的值都会争夺hash3位置,这种现象叫做群集/堆积。下⾯的⼆次探测可以⼀定程度改善这个问题。
• 下⾯演⽰ {19,30,5,36,13,20,21,12} 等这⼀组值映射到M=11的表中。
h(19) = 8,h(30) = 8,h(5) = 5,h(36) = 3,h(13) = 2,h(20) = 9,h(21) =10,h(12) = 1
⼆次探测
• 从发⽣冲突的位置开始,依次左右按⼆次⽅跳跃式探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果往右⾛到哈希表尾,则回绕到哈希表头的位置;如果往左⾛到哈希表头,则回绕到哈希表 尾的位置;
• h(key) = hash0 = key % M , hash0位置冲突了,则⼆次探测公式为: hc(key,i) = hashi = (hash0 ± i2 ) % M,i = {1, 2, 3, …, 2/M}
• ⼆次探测当 hashi = (hash0 − i2)%M时,当hashi<0时,需要hashi += M • 下⾯演⽰ {19,30,52,63,11,22} 等这⼀组值映射到M=11的表中。
开放定址法在实践中,不如下⾯讲的链地址法,因为开放定址法解决冲突不管使⽤哪种⽅法,占⽤的
开放定址法的哈希表结构
enum State
{
EXIST,
EMPTY,
DELETE
} ;
template < class K , class V >
struct HashData
{
pair< K, V> _kv;
State _state = EMPTY;
} ;
template < class K , class V >
class HashTable
{
private :
vector< HashData< K, V>> _tables;
size_t _n = 0 ;
} ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 要注意的是这⾥需要给每个存储值的位置加⼀个状态标识,否则删除⼀些值以后,会影响后⾯冲突的
扩容 这⾥我们哈希表负载因⼦控制在0.7,当负载因⼦到0.7以后我们就需要扩容了,我们还是按照2倍扩
inline unsigned long __stl_next_prime ( unsigned long n)
{
static const int __stl_num_primes = 28 ;
static const unsigned long __stl_prime_list[ __stl_num_primes] =
{
53 , 97 , 193 , 389 , 769 ,
1543 , 3079 , 6151 , 12289 , 24593 ,
49157 , 98317 , 196613 , 393241 , 786433 ,
1572869 , 3145739 , 6291469 , 12582917 , 25165843 ,
50331653 , 100663319 , 201326611 , 402653189 , 805306457 ,
1610612741 , 3221225473 , 4294967291
} ;
const unsigned long * first = __stl_prime_list;
const unsigned long * last = __stl_prime_list + __stl_num_primes;
const unsigned long * pos = lower_bound ( first, last, n) ;
return pos == last ? * ( last - 1 ) : * pos;
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Key不能取模的问题
当key是string/Date等类型时,key不能取模,那么我们需要给HashTable增加⼀个仿函数,这个仿函
template < class K >
struct Hashturn
{
size_t operator ( ) ( const K& key)
{
return ( size_t) key;
}
} ;
template < >
struct Hashturn < string>
{
size_t operator ( ) ( const string& key)
{
size_t m = 0 ;
for ( auto & e : key)
{
m += e;
}
return m;
}
} ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"> class="hide-preCode-box">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 完整代码:
enum State
{
EXIST,
EMPTY,
DELETE
} ;
template < class K , class V >
struct HashData
{
pair< K, V> _kv;
State _state= EMPTY;
} ;
template < class K >
struct Hashturn
{
size_t operator ( ) ( const K& key)
{
return ( size_t) key;
}
} ;
template < >
struct Hashturn < string>
{
size_t operator ( ) ( const string& key)
{
size_t m = 0 ;
for ( auto & e : key)
{
m += e;
}
return m;
}
} ;
inline unsigned long __stl_next_prime ( unsigned long n)
{
static const int __stl_num_primes = 28 ;
static const unsigned long __stl_prime_list[ __stl_num_primes] = {
53 , 97 , 193 , 389 , 769 ,
1543 , 3079 , 6151 , 12289 , 24593 ,
49157 , 98317 , 196613 , 393241 , 786433 ,
1572869 , 3145739 , 6291469 , 12582917 , 25165843 ,
50331653 , 100663319 , 201326611 , 402653189 , 805306457 ,
1610612741 , 3221225473 , 4294967291
} ;
const unsigned long * first = __stl_prime_list;
const unsigned long * last = __stl_prime_list + __stl_num_primes;
const unsigned long * pos = lower_bound ( first, last, n) ;
return pos == last ? * ( last - 1 ) : * pos;
}
template < class K , class V , class Hashturn = Hashturn< K>>
class HashTable
{
public :
HashTable ( )
: _tables ( __stl_next_prime ( 0 ) )
, _n ( 0 )
{ }
Hashturn con;
bool insert ( const pair< K, V> & kv)
{
if ( Find ( kv. first) )
{
return false ;
}
if ( _n * 10 / _tables. size ( ) >= 7 )
{
HashTable< K, V, Hashturn> newht;
newht. _tables. resize ( __stl_next_prime ( _tables. size ( ) + 1 ) ) ;
for ( auto & e : _tables)
{
if ( e. _state == EXIST)
{
newht. insert ( e. _kv) ;
}
}
_tables. swap ( newht. _tables) ;
}
size_t Hash0 = con ( kv. first) % _tables. size ( ) ;
size_t Hashi = Hash0;
size_t i = 1 ;
while ( _tables[ Hashi] . _state == EXIST)
{
Hashi = ( Hash0 + i) % _tables. size ( ) ;
i++ ;
}
_tables[ Hashi] . _kv = kv;
_tables[ Hashi] . _state = EXIST;
++ _n;
return true ;
}
HashData< K, V> * Find ( const K& key)
{
size_t Hash0 = con ( key) % _tables. size ( ) ;
size_t Hashi = Hash0;
size_t i = 1 ;
while ( _tables[ Hashi] . _state != EMPTY)
{
if ( _tables[ Hashi] . _state!= DELETE && _tables[ Hashi] . _kv. first == key)
{
return & _tables[ Hashi] ;
}
Hashi = ( Hash0 + i) % _tables. size ( ) ;
i++ ;
}
return nullptr ;
}
bool erase ( const K& key)
{
HashData< K, V> * ret = Find ( key) ;
if ( ret == nullptr )
{
return false ;
}
else
{
ret-> _state = DELETE;
return true ;
}
}
private :
vector< HashData< K, V>> _tables;
size_t _n;
} ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 开放定址法中所有的元素都放到哈希表⾥,链地址法中所有的数据不再直接存储在哈希表中,哈希表
链地址法代码实现
inline unsigned long __stl_next_prime ( unsigned long n)
{
static const int __stl_num_primes = 28 ;
static const unsigned long __stl_prime_list[ __stl_num_primes] =
{
53 , 97 , 193 , 389 , 769 ,
1543 , 3079 , 6151 , 12289 , 24593 ,
49157 , 98317 , 196613 , 393241 , 786433 ,
1572869 , 3145739 , 6291469 , 12582917 , 25165843 ,
50331653 , 100663319 , 201326611 , 402653189 , 805306457 ,
1610612741 , 3221225473 , 4294967291
} ;
const unsigned long * first = __stl_prime_list;
const unsigned long * last = __stl_prime_list +
__stl_num_primes;
const unsigned long * pos = lower_bound ( first, last, n) ;
return pos == last ? * ( last - 1 ) : * pos;
}
template < class T >
struct Buket_Node
{
T _data;
Buket_Node< T> * _next;
Buket_Node ( const T& data)
: _data ( data)
, _next ( nullptr )
{ }
} ;
template < class K >
struct Hashturn
{
size_t operator ( ) ( const K& key)
{
return ( size_t) key;
}
} ;
template < >
struct Hashturn < string>
{
size_t operator ( ) ( const string& key)
{
size_t m = 0 ;
for ( auto & e : key)
{
m += e;
}
return m;
}
} ;
template < class K , class T , class KeyofT , class Hashturn >
class hash_bucket ;
template < class K , class T , class Ref , class Ptr , class KeyOfT , class Hash >
struct Hash_Iterator
{
typedef Buket_Node< T> Node;
typedef hash_bucket< K, T, KeyOfT, Hash> HT;
typedef Hash_Iterator< K, T, Ref, Ptr, KeyOfT, Hash> Self;
Node* _node;
const HT* _ht;
Hash_Iterator ( Node* node, const HT* ht)
: _node ( node)
, _ht ( ht)
{ }
Ref operator * ( )
{
return _node-> _data;
}
Ptr operator -> ( )
{
return & _node-> _data;
}
bool operator != ( const Self& s)
{
return _node != s. _node;
}
Self& operator ++ ( )
{
if ( _node-> _next)
{
_node = _node-> _next;
}
else
{
KeyOfT kot;
Hash hash;
size_t hashi = hash ( kot ( _node-> _data) ) % _ht-> _tables. size ( ) ;
++ hashi;
while ( hashi < _ht-> _tables. size ( ) )
{
_node = _ht-> _tables[ hashi] ;
if ( _node)
break ;
else
++ hashi;
}
if ( hashi == _ht-> _tables. size ( ) )
{
_node = nullptr ;
}
}
return * this ;
}
} ;
template < class K , class T , class KeyofT , class Hashturn >
class hash_bucket
{
template < class K , class T , class ref , class ptr , class KeyofT , class Hashturn >
friend struct Hash_Iterator ;
typedef Buket_Node< T> Node;
public :
typedef Hash_Iterator< K, T, T& , T* , KeyofT, Hashturn> Iterator;
typedef Hash_Iterator< K, T, const T& , const T* , KeyofT, Hashturn> Const_Iterator;
hash_bucket ( )
: _n ( 0 )
, _tables ( __stl_next_prime ( 0 ) )
{ }
~ HashTable ( )
{
for ( size_t i = 0 ; i < _tables. size ( ) ; i++ )
{
Node* cur = _tables[ i] ;
while ( cur)
{
Node* next = cur-> _next;
delete cur;
cur = next;
}
_tables[ i] = nullptr ;
}
}
Iterator begin ( )
{
if ( _n == 0 )
{
return Iterator ( nullptr , this ) ;
}
for ( int i = 0 ; i < _tables. size ( ) ; i++ )
{
Node* cur = _tables[ i] ;
if ( cur)
{
return Iterator ( cur, this ) ;
}
}
}
Iterator end ( )
{
return Iterator ( nullptr , this ) ;
}
Const_Iterator end ( ) const
{
return Const_Iterator ( nullptr , this ) ;
}
Const_Iterator begin ( ) const
{
if ( _n == 0 )
{
return Const_Iterator ( nullptr , this ) ;
}
for ( int i = 0 ; i < _tables. size ( ) ; i++ )
{
Node* cur = _tables[ i] ;
if ( cur)
return Const_Iterator ( cur, this ) ;
}
}
pair< Iterator, bool > insert ( const T& data)
{
KeyofT kot;
Hashturn hash;
if ( 1 == ( _n / _tables. size ( ) ) )
{
Iterator it = Find ( kot ( data) ) ;
if ( it != end ( ) )
return { it, false } ;
vector< Node* > newtables ( __stl_next_prime ( _tables. size ( ) + 1 ) ) ;
for ( int i = 0 ; i < _tables. size ( ) ; i++ )
{
Node* cur = _tables[ i] ;
while ( cur)
{
Node* next = cur-> _next;
size_t hashi = hash ( kot ( cur-> _data) ) % newtables. size ( ) ;
cur-> _next = newtables[ hashi] ;
newtables[ hashi] = cur;
cur = next;
}
_tables[ i] = nullptr ;
}
_tables. swap ( newtables) ;
}
size_t hashi = hash ( kot ( data) ) % _tables. size ( ) ;
Node* newnode = new Node ( data) ;
newnode-> _next = _tables[ hashi] ;
_tables[ hashi] = newnode;
++ _n;
return { Iterator ( newnode, this ) , false } ;
}
Iterator Find ( const K& key)
{
KeyofT kot;
Hashturn hash;
size_t hashi = hash ( key) % _tables. size ( ) ;
Node* cur = _tables[ hashi] ;
while ( cur)
{
if ( kot ( cur-> _data) == key)
{
return Iterator ( cur, this ) ;
}
}
return Iterator ( nullptr , this ) ;
}
bool erase ( const K& key)
{
KeyofT kot;
Hashturn hash;
Node* prev = nullptr ;
size_t hashi = hash ( key) % _tables. size ( ) ;
Node* cur = _tables[ hashi] ;
while ( cur)
{
if ( kot ( cur-> _data) == key)
{
if ( prev)
{
prev-> _next = cur-> _next;
}
else
{
_tables[ hashi] = prev;
}
delete cur;
_n-- ;
return true ;
}
else
{
prev = cur;
cur = cur-> _next;
}
}
return false ;
}
private :
size_t _n = 0 ;
vector< Node* > _tables;
} ;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 再见,并非终点,而是另一段旅程的起点。愿我们在各自的旅途中,都能遇见更美的风景,书写更加精彩的人生篇章!!!
data-report-view="{"mod":"1585297308_001","spm":"1001.2101.3001.6548","dest":"https://blog.csdn.net/2301_80109683/article/details/145352601","extend1":"pc","ab":"new"}">>





评论记录:
回复评论: