
一. 背景
大数据集群通常由多种组件协同工作来支撑业务需求,由HDFS存储数据,使用yarn进行资源调度,使用hive、spark等计算引擎进行数据处理。
为了保证HDFS中的数据安全,控制Yarn任务提交和资源分配,限制Yarn任务非法终止,规范计算引擎(如Hive、Spark)的数据访问权限,因此需要对HDFS、Yarn、Hive、Spark等组件进行权限管控,权限管控分为用户认证和授权两步。
不同组件的用户认证方式各不相同,但是大多数都支持两种用户认证方式:linux用户认证和kerberos认证,linux用户认证比较简单,但是比较容易绕过。kerberos认证能保证很高的安全性,但是配置复杂,尤其是多个组件之间的用户认证,考虑到目前大数据集群处于安全的网络环境,所以大数据这边采用了第一种用户认证方式。
不同组件的授权方式差别很大,例如HDFS就和linux文件系统授权类似,而Yarn要通过修改配置文件的方式管理权限,Hive提供了使用sql授权的授权方式,而Spark直接不支持权限管控。为了统一这些组件的授权方式,以及实现本身不支持权限管控的组件的权限管控,大数据这边引入Ranger实现了对各个组件授权的统一管理。
此外Ranger还支持审计日志,开启后,能记录用户访问组件的资源、资源类型、访问方式和授权结果等记录。
下面首先简单介绍下大数据常用组件和组件的权限管控方式。
1.1 常用组件介绍
1.1.1 Hadoop
Hadoop是一个开源的分布式计算框架,主要用于大规模数据的存储和处理,主要组件包括HDFS和YARN
HDFS :一个分布式文件系统,负责存储大规模数据文件。
YARN :Hadoop集群中的资源管理系统,负责管理集群中的计算资源并调度作业。
1.1.2 Hive
Hive 是一个基于Hadoop构建的数据仓库工具,用于大规模数据的存储、查询和分析, 主要组件包括metastore和hiveserver2。
Metastore : Hive的核心组件,提供元数据的集中管理,所有hive sql的执行都需要Metastore的参与。
HiveServer2 : Hive的核心服务组件,可以接受来自各种客户端的查询请求。
1.1.3 Spark
Spark 是一个快速、通用的大数据处理引擎,能够高效地进行大规模数据处理和分析,支持批处理和流处理。
1.2 常用组件权限管控方式
各个常用组件权限管控方式如下表:
| 组件 | 认证 | 授权 | 审计日志 |
|---|---|---|---|
| HDFS | 支持两种认证方式 1.支持Kerberos协议进行用户身份认证 2.支持使用当前服务器用户进行身份认证 | 采用类Unix的权限模型,支持文件和目录级别的读、写、执行权限。它使用用户-组模型,每个文件和目录都有所有者、组和其他用户的权限设置。 HDFS还支持访问控制列表(ACL),提供更细粒度的权限控制 | 不支持 |
| Yarn | 支持两种认证方式 1.支持Kerberos协议进行用户身份认证 2.支持使用当前服务器用户进行身份认证 | 通过修改配置文件的方式实现授权 | 不支持 |
| Hive | 只支持对Hiveserver2进行权限管控,支持多种认证方式,下面是其中3种: 1.支持Kerberos协议进行用户身份认证 2.支持LDAP方式进行身份认证 3.自定义身份认证 | Hive提供了类似关系数据库的权限模型,支持GRANT和REVOKE命令来控制数据库、表、列级别的访问权限。 Hive还支持基于角色的访问控制(RBAC),允许创建角色并为角色分配权限,简化权限管理 | 不支持 |
| Spark | 本身不支持权限管控 | 本身不支持权限管控,但是HDFS权限管控对Spark也生效 | 不支持 |
1.3 单一组件权限管控的不足
通过上表可以看到,各组件通常都有自己的权限管理机制,如果每个组件都单独进行权限管控,会带来以下问题:
- 分散管理 : 每个组件需要单独配置,增加了管理复杂度,且有些组件本身不支持权限管控。
- 一致性难保证 : 跨组件的权限策略难以保持一致。
- 有限的细粒度控制 : 某些组件的原生权限控制粒度较粗。
- 缺乏中央化审计 : 难以全面审计整个集群的访问情况。
- 可扩展性差 : 随着集群规模增长,单组件权限管理变得越发困难。
因此需要引入统一的权限管控组件来实现对所有组件权限的统一管理,并借助统一权限管控组件实现对本身不支持权限管控的组件的进行权限管控。
二、常用的权限管控组件介绍与对比
在大数据生态系统中,Apache Sentry、Apache Ranger 是最常用的统一权限管控组件,可以对大多数组件实现细粒度的权限管控。
Apache Knox是只针对服务层面授权的权限管控组件,可以对少部分组件实现简单的权限管控,下面是具体信息:
| 特性 | Apache Sentry | Apache Ranger | Apache Knox |
|---|---|---|---|
| 授权原理 | 1.统一的授权管理框架,通过Hook具体后台服务的流程框架,深度侵入代码,添加授权验证逻辑的方式来实现权限管控的2.对不同的大数据组件提供不同的权限管控插件,依次实现权限管控 3.通过sql-like的方式实现授权 | 1.统一的授权管理框架,通过Hook具体后台服务的流程框架,深度侵入代码,添加授权验证逻辑的方式来实现权限管控的2.对不同的大数据组件提供不同的权限管控插件,依次实现权限管控 3.通过web ui的方式实现授权 | 1.提供基于网关的 API 代理控制 2.用户通过网关访问大数据集群的服务,Knox 负责认证和路由请求 |
| 优点 | 1. 细粒度权限控制 2. 简单易用,适合小型集群 | 1.支持基于标签的授权策略,可以跨多个组件对某一资源进行授权 2.支持组件较多 3.提供数据脱敏 4.支持行、列级别的过滤功能 | 1.增强了集群的安全性,将所有请求集中到网关 2.提供统一的认证入口,简化客户端配置 |
| 缺点 | 1.支持组件较少 2.社区维护减少,逐步被 Ranger 取代 3.缺乏灵活的标签或动态授权机制 | 实时性稍差,需要定期同步策略 | 1.主要用于服务层面的访问控制,不支持细粒度数据访问权限 |
可以看到,Sentry即将被淘汰,Knox不支持细粒度权限管控,Ranger支持细粒度的权限管控,而且社区活跃度高,因此选择Ranger来实现大数据集群权限管控,此外,Ranger还有一些第三方插件可以给那些原本不支持权限管控的组件授权。
上面提到权限管控分为用户认证和授权两步,但是Ranger不负责用户认证,只负责授权,因此组件进行权限管控时,需要自己实现用户认证,然后再利用Ranger实现授权。
三、用户认证
目前大数据多数组件支持的认证方式有两种,一种是Kerberos,需要手动配置,另一种是默认的使用inux用户的方式实现用户认证。
下面简单介绍下这两种用户认证方式。
3.1 Kerberos
Kerberos 是一种网络安全协议,主要用于在不安全的网络环境中保证身份的安全认证,这是大数据组件基本都支持的一种身份认证方式。
原理:Kerberos使用基于票据的认证机制,用户通过KDC(Key Distribution Center)获取票据后才能访问资源,如图所示:
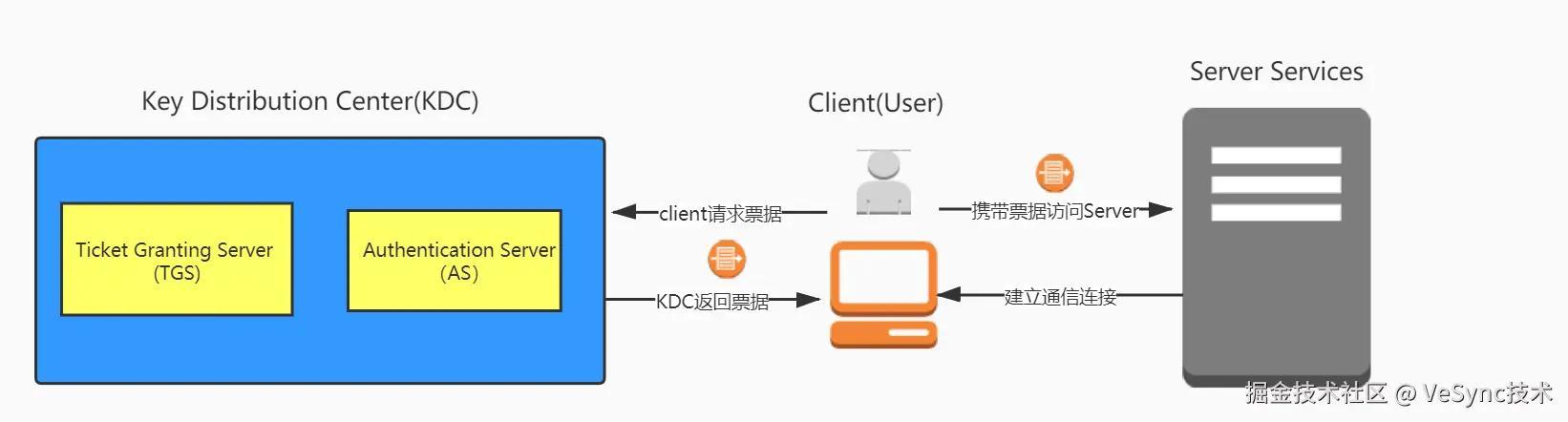
第一步是客户端向KDC请求获取想要访问的目标服务的服务授予票据(Ticket);
第二步是客户端拿着从KDC获取的服务授予票据(Ticket)访问相应的网络服务;
更加详细的认证过程可参考:seevae.github.io/2020/09/12/…
优势:高安全性,防止中间人攻击和重放攻击。适用于大规模集群环境,广泛集成于 Hadoop 生态系统。
不足:配置复杂,需部署KDC和维护密钥表。当鉴权涉及到多个组件时,配置kerberos非常复杂、难度非常大。
3.2 linux用户
这是大多数组件默认的用户认证方式,即默认只要用户能登录部署大数据组件的服务器,那么用户就完成了认证。
优点是这种用户认证方式十分简单,缺点是这种用户认证方式很容易被绕开。
由于目前大数据集群处于安全的网络环境,且会通过jumpserver的方式限制用户登录大数据集群所在服务器,大数据集群本身已处于一个很安全的环境,因此大数据这边选择使用linux用户这种简单的方式来进行用户认证。
四、授权
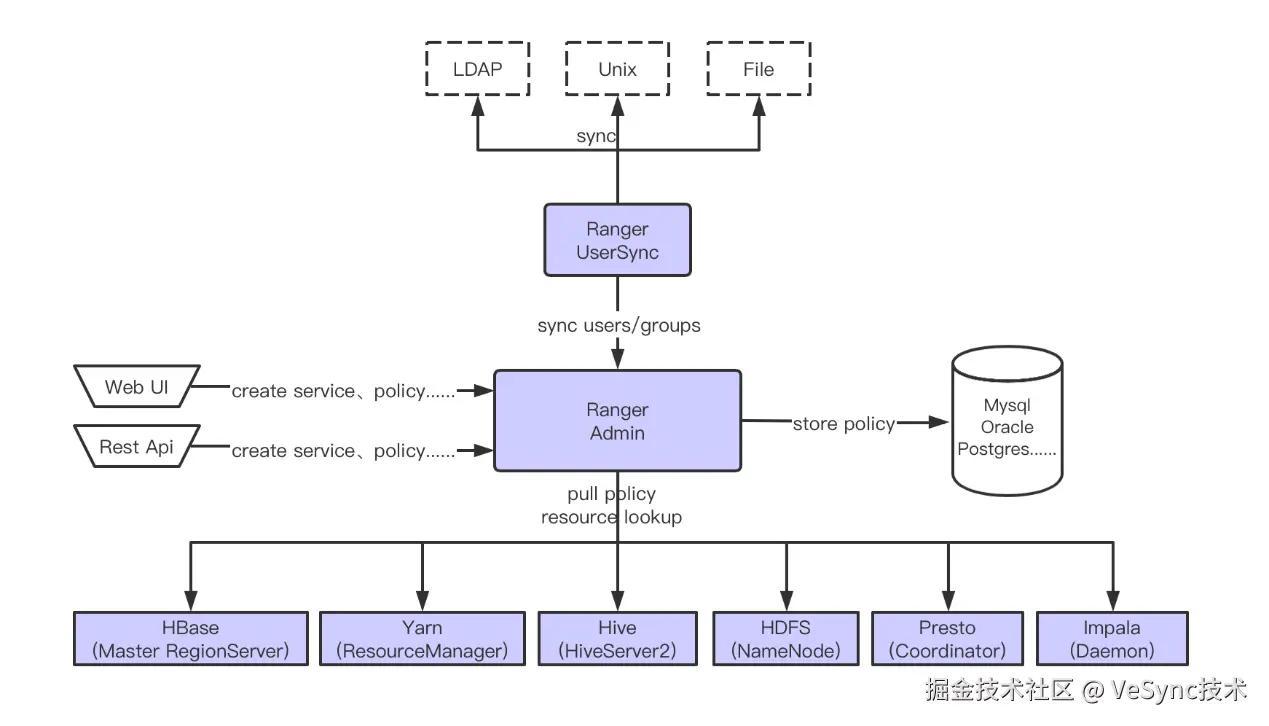
授权主要由Ranger完成,ranger整体架构如下:
1.Ranger可以通过Ranger UserSync插件同步LDAP、UNIX、FILE中的用户到Ranger Admin,然后由Ranger Admin将数据保存到Mysql中。
2.用户可以通过WebUI或者Rest Api发出创建、修改、删除权限的命令,Ranger Admin接收命令后会将权限策略保存到Mysql。
3.Hive、Yarn等组件需要安装权限管控插件来实现授权,权限管控插件会定期从Ranger Admin拉取权限策略,Ranger Admin会从Mysql拉取权限策略并返回给插件,插件会缓存权限策略到本地,组件根据权限策略判断用户是否有权限执行相关操作。
Ranger的授权方式主要分为两种:基于资源的授权方式和基于标签的授权方式。除此之外,Ranger还支持审计日志,审计日志由权限管控插件开启。
下面详细介绍下这两种授权方式和审计日志。
4.1 基于资源的授权方式
这是一种传统的授权方法,直接针对特定的资源定义访问控制策略,资源可以是数据库、表、列、文件、文件夹等。
管理员需要为每个资源单独定义权限,指定哪些用户、组、角色可以执行哪些操作(如读、写、执行等)。
这种授权方式是每个组件作为一个独立的授权单位授权,当不同组件对同一资源授予不同权限时,可能会有权限冲突。
4.1.1 Ranger支持的组件介绍
Ranger目前支持这些下面组件的授权,组件安装权限管控插件并在这个页面进行配置后,就可以从这个页面点击进入组件的授权页面,对组件的资源进行授权了,部分组件还支持数据脱敏和数据过滤。
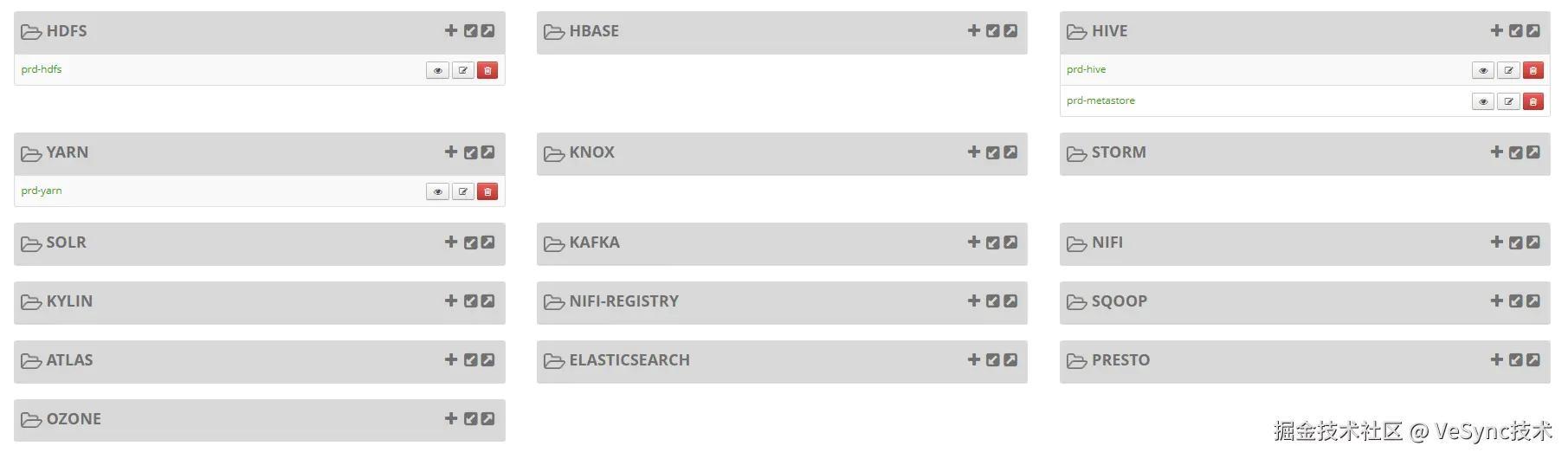 因为不同组件的授权方式差别非常大,这里只讲一些常用组件的授权。
因为不同组件的授权方式差别非常大,这里只讲一些常用组件的授权。
HDFS:支持对路径及其子路径的授权,权限总共有三种,读、写、执行
Yarn:支持对队列的授权,权限总共有两种:提交任务、管理队列(kill掉别人的任务,执行特定命令等)
Hive:支持对数据库、表、列级别的授权,支持很多种权限,例如select, update, create, drop, alter等权限:
4.1.2 授权
在对组件的资源进行授权时,Ranger提供的授权对象有三个:
- 用户(User):系统中的个人账号,是授权的基本主体。
- 组(Group):多个用户的集合,可以批量管理和授权,简化权限分配。
- 角色(Role):定义一组特定的权限集合,可以灵活地将权限捆绑并分配给用户或组。
Ranger中的用户和组可以通过Ranger的UserSync插件同步过来,管理员也可以自己创建。而角色一般都是管理员手动创建。
Ranger对用户、组、角色的实际授权页面是这样的:
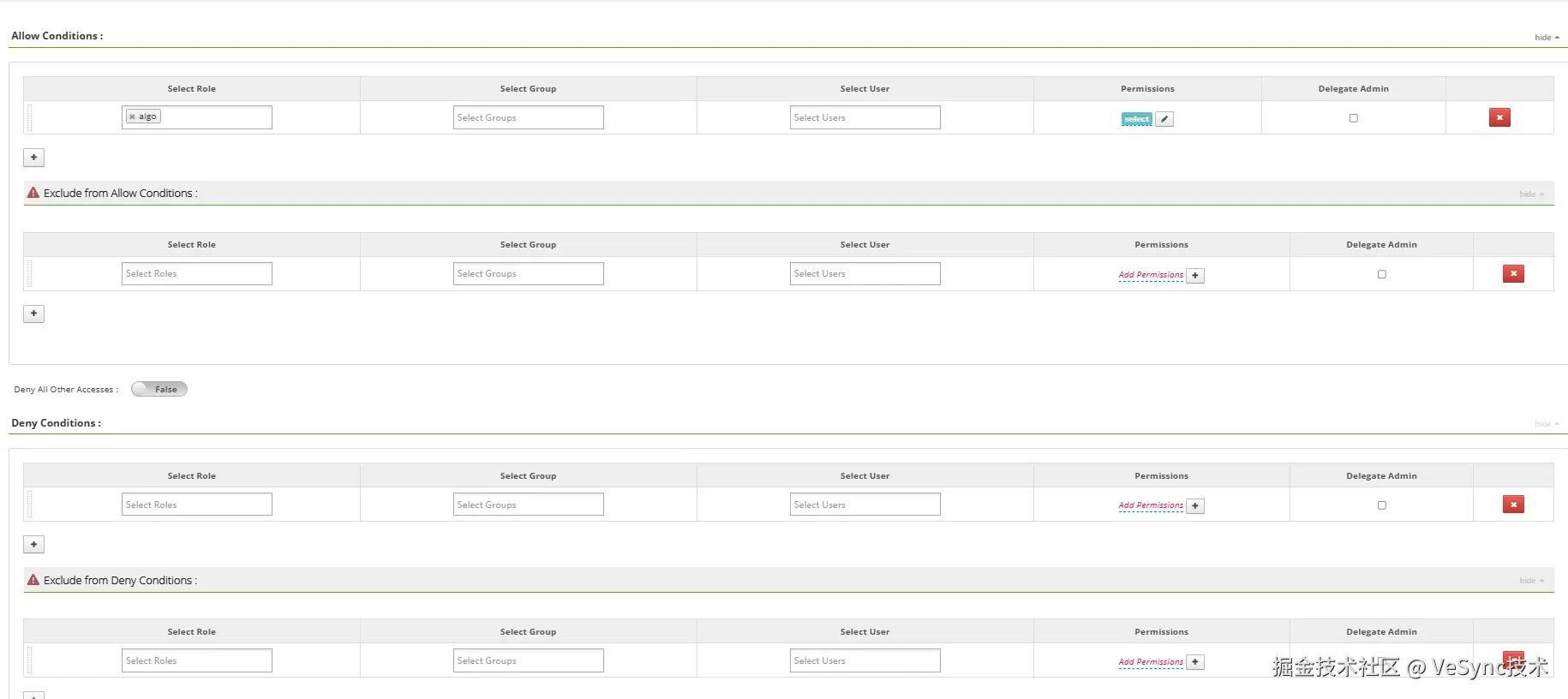
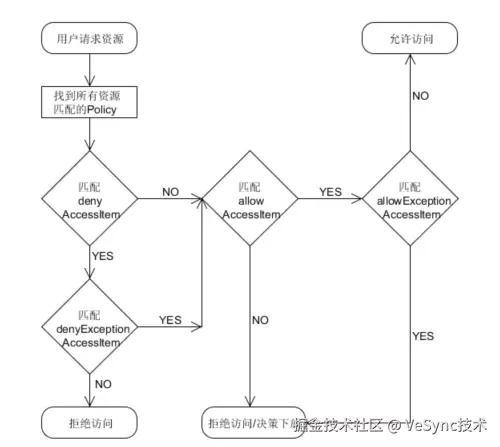
可以看到,Ranger对用户、组、角色的授权主要有以下四种方式:
- allow conditions 设置的是那些角色、组或者用户可以使用该策略
- exclude from allow conditions 从可以使用策略的角色、组和用户中限定某些角色、组或者用户不可以使用该策略。
- deny conditions 设置哪些角色、组和用户不可以使用该策略。
- exclude from deny conditions 从禁止使用该策略的角色、组中排除某些角色、组和用户。
这四种授权方式的整体流程和优先级如图所示:
4.1.2 数据脱敏
Ranger支持Hive等数据库相关组件列级别的数据脱敏,可以针对某些用户对某些字段脱敏处理,脱敏的方式共有以下几种:
- Redact – 用x屏蔽所有字母字符,用n屏蔽所有数字字符.
- Partial mask: show last 4 – 仅显示最后四个字符,其他用x代替
- Partial mask: show first 4 – 仅显示前四个字符,其他用x代替
- Hash – 用值的哈希值替换原值。
- Nullify – 用NULL值替换原值。
- Unmasked (retain original value) – 原样显示
- Date: show only year – 仅显示日期字符串的年份部分,并将月份和日期默认为01/01。
- Custom – 可使用任何有效Hive UDF(返回与被屏蔽的列中的数据类型相同的数据类型)来自定义策略。
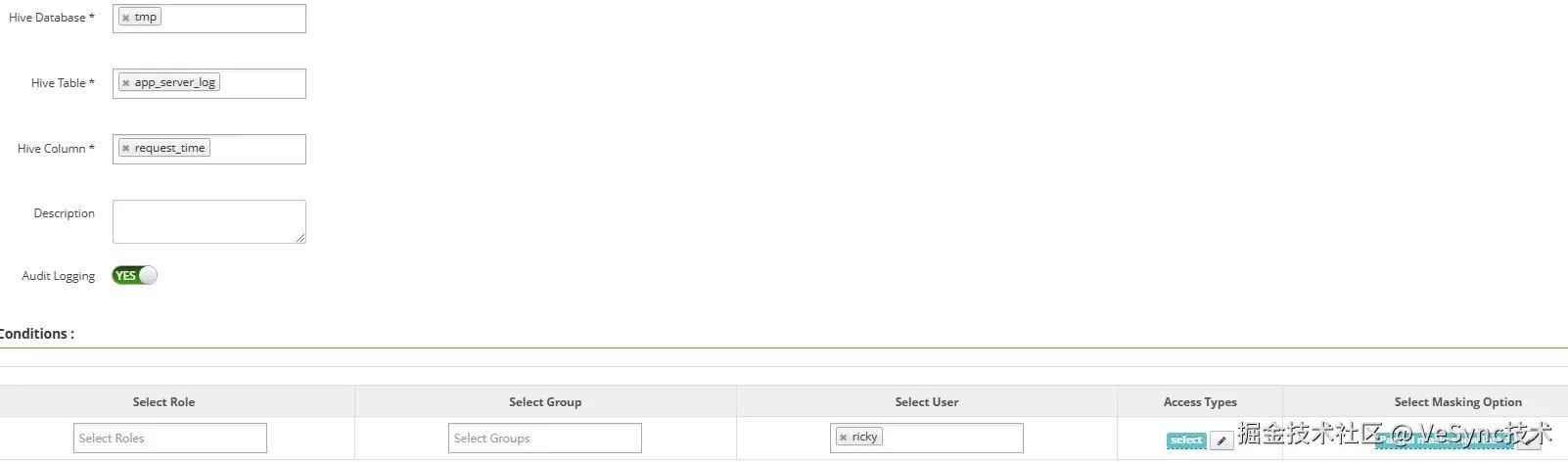
如下图所示,针对ricky用户设置了tmp.app_server_log表的request_time字段的脱敏,这样当ricky用户查询tmp.app_server_log表request_time字段时,只会显示后四位字符。
4.1.3 数据过滤
Ranger支持Hive等数据库相关组件的行级别的数据过滤,可以针对某些用户过滤掉满足特定条件的数据。
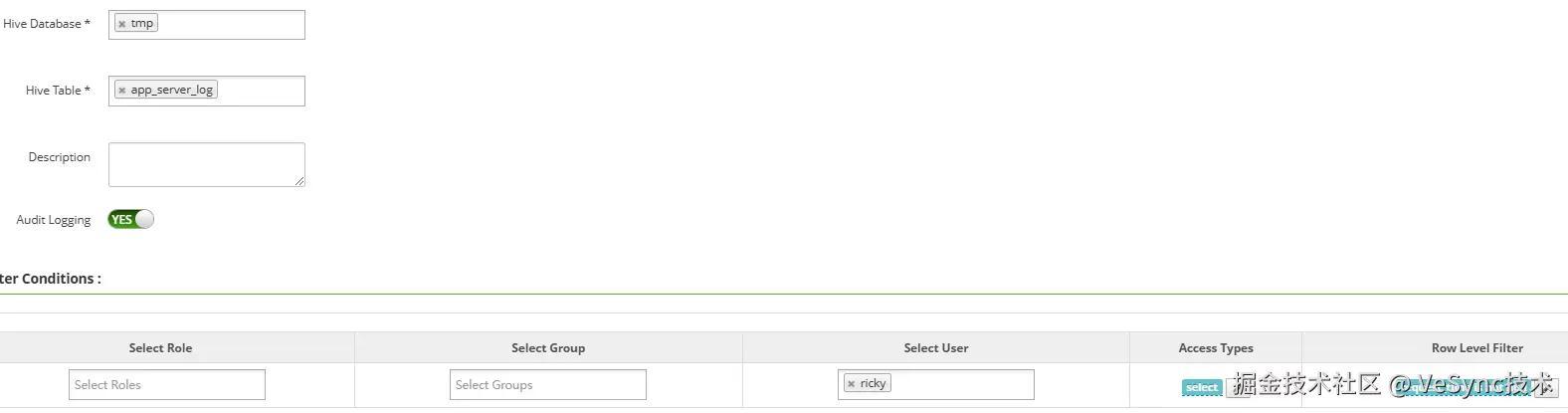
如图所示,针对ricky用户根据request_time字段设置了tmp.app_server_log表的数据过滤方式,这样ricky用户查询tmp.app_server_log表数据时,只能查询到符合request_time is not null条件的数据
4.2 基于标签的权限管控
这是一种更灵活的授权方法,基于给资源分配的标签来定义访问控制策略。管理员首先给资源分配标签(如"敏感"、"公开"、"财务"等),然后基于这些标签定义策略。一个策略可以应用到所有带有特定标签的资源,无需为每个资源单独设置,但是这种授权方式无法仅依靠Ranger实现,需要借助Atlas(一种可以给资源标签的组件)等组件实现。
有以下优点:
1.更易于管理,特别是在大型和动态环境中。
2.提供了更好的抽象层,使策略管理更加灵活。
3.可以跨组件授权。
4.3 审计日志
Ranger支持审计日志,并提供一个专门查看审计日志的页面,可以查看所有组件的授权记录。审计日志由Ranger的权限管控插件开启,每个组件都拥有一个Ranger的权限管控插件,因此可以独立打开或关闭组件的审计日志。审计日志可以存储在本地文件、HDFS和Solr中。
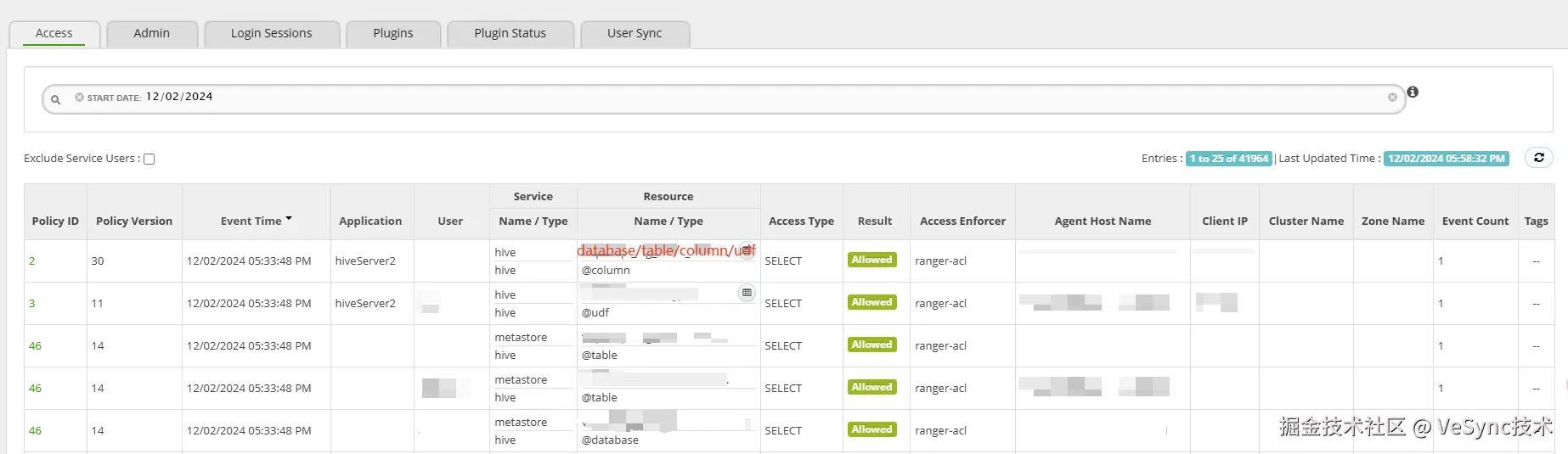
针对当前业务需求,大数据这边选择只使用Ranger基于资源的权限管控方式实现大数据集群的权限管控,并开启了HDFS、metastore、hiveserver2和spark的审计日志。
五、应用场景
目前业务需求下,大数据这边只需要对HDFS的部分目录做权限管控、对Hive中的表做权限管控、对Yarn任务提交和Yarn任务管理做权限管控,只涉及简单的具体资源的权限管控,因此大数据这边选择只使用Ranger基于资源的权限管控方式实现大数据集群的权限管控。
审计日志这边,大数据配置了HDFS、metastore、hiveserver2和spark的审计日志,因为这些组件都能操作和删除数据,因此需要配置审计日志重点监控。
至于Yarn,大数据这边则没有配置审计日志,不配置有两个原因,一个是因为Yarn的审计日志太多,二是因为Yarn只涉及任务的管理,它的审计日志不太重要。
下面是具体的应用场景:
| 组件 | 没有权限管控之前的痛点 | 权限管控实现方式 |
|---|---|---|
| HDFS | HDFS上存放了大数据这边绝大部分重要数据,但是每个可以登录Hadoop安装服务器的用户都能以最高权限随意访问。 虽然通过jumpserver对登录服务器的人员做了限制,但是不能保证这些人不会对HDFS做一些误操作导致HDFS上的数据被清空。 | 用户认证 :采用linux用户的方式实现了用户认证 授权 : 1.使用Ranger实现了HDFS上重要数据的权限管控 2.使用HDFS自带的权限管控系统实现了公共目录的权限管控 3.修改hdfs权限掩码为077,保证后续创建的文件或文件夹只有创建者才拥有权限 |
| Yarn | 大数据这边大部分任务都在Yarn上运行,包括实时任务,每个可以登录Hadoop安装服务器的用户都可以向所有Yarn队列提交任务,随意kill掉其他人提交到Yarn队列上的任务。 例如算法组就可以随意提交任务到大数据这边的Yarn队列。 | 用户认证 :采用linux用户的方式实现了用户认证 授权 : 1.修改配置文件,关闭了Yarn自带的权限管控系统 2.修改配置文件,开启了Yarn命令的权限管控 3.使用Ranger实现了Yarn的权限管控,实现了对提交任务和kill任务的权限控制,保证了用户只能kill掉自己提交的任务,保证了用户提交任务时只能向授权队列提交任务。 |
| hiveserver2 | Hive这边存储了大数据这边大部分的重要数据,每个人都可以通过ip和端口直接连接hiveserver2,并且是最高权限,可以随意操作Hive中的数据,甚至可以删除Hive中所有的数据。 | 用户认证 :采用自定义的方式实现了用户认证,即手动编写代码实现hiveserver2用户认证方法,阻止陌生用户登录hiveserver2。 授权 :使用Ranger实现了hiveserver2的权限管控,根据业务对Hive的数据库、表、字段、UDF函数都做了权限管控 |
| metastore | 其他人可以通过api的方式连接metastore,从而用最高权限操作hive数据 | 用户认证 :采用linux用户的方式实现了用户认证 授权 :Ranger没有管控metastore权限的插件,于是大数据这边使用了第三方插件实现了metastore的权限管控,根据业务对Hive的数据库、表、字段都做了权限管控。 |
| Spark | spark可以随意访问HDFS上的数据和hive数据库中的数据,虽然可以通过控制HDFS的权限和metastore的权限实现spark的权限管控,但是这种管控方式太过繁琐。 | 用户认证 :采用linux用户的方式实现了用户认证 授权 :Ranger没有管控Spark权限的插件,于是大数据这边使用了第三方插件实现了Spark的权限管控,使得Spark的授权方式和Hive保持一致,既能实现数据库、表、列级别的权限管控,还能实现数据脱敏和数据过滤。 |
| 审计日志 | 在HDFS、Yarn、Hive、Spark等组件没有开启审计日志之前,定位一些误操作的问题就很困难,例如去定位HDFS上某一文件被删除,Hive中某一表分区被删除。 | 大数据这边开启了除了Yarn以外所有通过Ranger插件实现权限管控的组件的审计日志,监控这些组件上所有的增删改查操作,同时将审计日志存入Solr,方便审计日志的检索。 |
六、权限管控插件的具体安装方式
Ranger每种权限管控插件的安装要求都不一样,下面是具体要求:
hdfs插件:需要安装在NameNode所在服务器
yarn插件:需要安装在ResourceManager所在服务器
hiveserver2插件:需要安装在hiveserver2所在服务器
metastore插件(主要管控metastore、hivecli的权限):管控metastore权限就需要安装在metastore所在服务器、管控hive cli权限就需要安装在所有安装hive组件的服务器
spark插件:需要安装在每一个安装过spark组件的服务器
6.1 hdfs插件
1.解压hdfs插件后,修改install.properties文件内容
ini 代码解读复制代码POLICY_MGR_URL=http://hadoop-1:6080(ranger-admin地址)
REPOSITORY_NAME=prd-hdfs(填从ranger admin拉取策略的名称)
COMPONENT_INSTALL_DIR_NAME=/data/apps/hadoop-3.2.2(hadoop安装地址)
XAAUDIT.SOLR.ENABLE=true (是否启用审计日志)
XAAUDIT.SOLR.URL=http://hadoop-1:6083/solr/ranger_audits (solr索引位置)
XAAUDIT.SOLR.ZOOKEEPER=hadoop-1:2181,hadoop-2:2181,hadoop-3:2181/ranger_audits (zookeeper集群地址)
XAAUDIT.SOLR.IS_ENABLED=true
XAAUDIT.SOLR.SOLR_URL=http://hadoop-1:6083/solr/ranger_audits
CUSTOM_USER=hadoop(安装hdoop的用户)
CUSTOM_GROUP=hadoop (安装hdoop的组)
2.启动插件
bash代码解读复制代码/data/apps/ranger-2.0.0/ranger-hdfs/enable-hdfs-plugin.sh
3.修改所有服务器上hadoop的hdfs-site.xml文件,新增配置设置hdfs权限掩码为077,保证后续创建的文件或文件夹只有创建者才拥有权限
xml 代码解读复制代码<property>
<name>fs.permissions.umask-modename>
<value>077value>
property>
4.执行命令重启NameNode,高可用集群需要注意重启顺序,保证NameNode的active和standby状态不变
css 代码解读复制代码hdfs --daemon stop namenode
hdfs --daemon start namenode
5 Ranger配置hdfs插件.
sql 代码解读复制代码Service Name:prd-hdfs
Description:hdfs
Username:hadoop
Password:自定义
Namenode URL:hdfs://hadoop-1:8020,hdfs://hadoop-2:8020
Authorization Enabled:Yes
Authentication Type:Simple
RPC Protection Type:Authentication
Add New Configurations:
dfs.client.failover.proxy.provider.ns1:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
ranger.service.https.attrib.clientAuth:false
dfs.namenode.acls.enabled:false
ranger.service.https.attrib.client.auth:false
tag.download.auth.users:hadoop
policy.download.auth.users:hadoop
policy.grantrevoke.auth.users:hadoop
dfs.nameservices:ns1
dfs.ha.namenodes.ns1:nn1,nn2
dfs.namenode.rpc-address.ns1.nn2:hadoop-1:8020
dfs.namenode.rpc-address.ns1.nn1:hadoop-2:8020
6.测试组件是否安装成功
在hdfs上新建/test目录,设置该目录权限为000,切换用户为test,执行hdfs dfs ls /test命令访问目录会被拒绝
在ranger上对test用户授予 /test目录的所有权限,再次访问目录,若是可以访问目录、在此目录创建文件、读取此目录文件,则说明组件安装成功
7.注意事项
安装了Ranger插件后,HDFS会同时遵守两套授权策略,一种是HDFS自带的Hadoop acl(关闭不了),另一种是Ranger的Ranger acl,具体的授权流程如下:
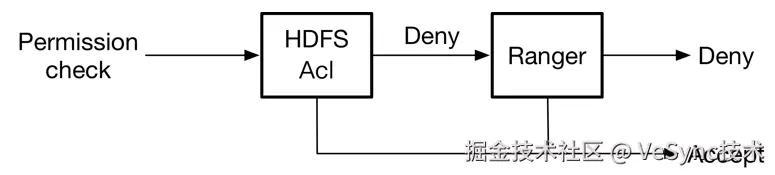
可以在Ranger的审计日志中看到是哪种授权策略生效,若是Access Enforcer是ranger-acl,则表示权限由Ranger控制。若是Access Enforcer是hadoop-acl,则表示权限由HDFS本身权限管控系统控制。
6.2 yarn插件
1.解压yarn插件,修改install.properties文件内容,具体内容和hdfs插件基本一致
2.修改ResourceManager所在服务器的hadoop的yarn.xml文件, 添加以下配置
xml 代码解读复制代码
<property>
<name>yarn.admin.aclname>
<value>hadoopvalue>
property>
3. 修改ResourceManager所在服务器上hadoop配置目录下的capacity-scheduler.xml文件
删除包含以下acl_submit_applications或acl_administer_queue的配置项,取消之前设置的队列权限,新增以下配置项,禁用yarn的本身授权方式:
xml 代码解读复制代码<property>
<name>yarn.scheduler.capacity.root.acl_submit_applicationsname>
<value> value>
property>
<property>
<name>yarn.scheduler.capacity.root.acl_administer_queuename>
<value> value>
property>
4.启动ranger的yarn插件
bash代码解读复制代码/data/apps/ranger-2.0.0/ranger-yarn/enable-yarn-plugin.sh
5.重启ResourceManager,高可用集群需要注意重启顺序,保证ResourceManager的active和standby状态不变,重启NameNode的时候一定要在Ranger上配置好权限再重启
css 代码解读复制代码yarn --daemon stop resourcemanager
yarn --daemon start resourcemanager
6 Ranger配置hdfs插件.
bash代码解读复制代码Service Name:prd-yarn Description:yarn Username:hadoop Password: YARN REST URL:hdfs://hadoop-1:8020,hdfs://hadoop-2:8020 Authentication Type:Simple
6.3 hiveserver2插件
1.安装hiveserver2插件方式和上面hdfs插件、yarn插件方式一致,从ranger自带的插件中解析出来hive插件,这就是hiveserver2插件,然后安装即可。
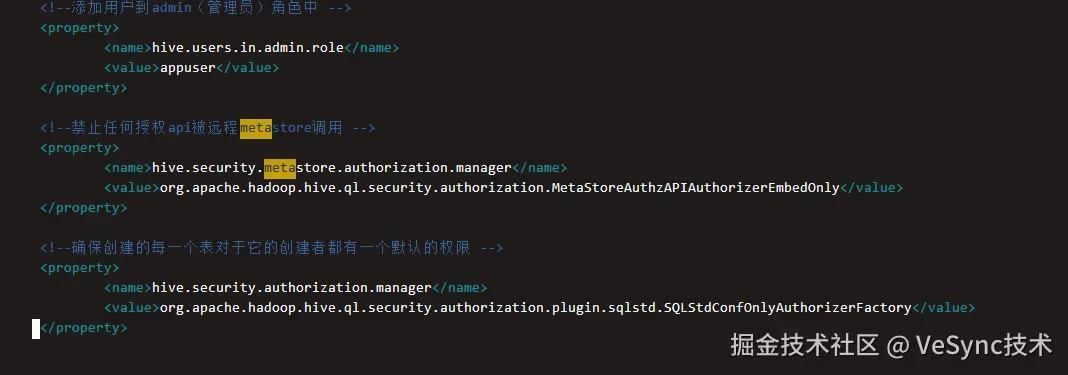
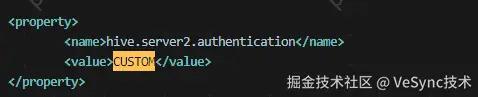
2.值得注意的点是,若是hive-site.xml文件中存在以下关于授权的内容,在启动hiveserver2插件之前需要删掉:

6.4 metastore插件
1.下载开源ranger插件源码,地址为:github.com/insightlake…,可下载zip文件,然后通过远程桌面上传到服务器
2.解压缩zip包,并编译源码
vbnet 代码解读复制代码mvn clean compile package install assembly:assembly -DskipTests
3.编译后源码所在文件夹内会生成一个target目录,解压缩target里面的ranger-metastore-plugin-2.1.0-metastore-plugin.tar.gz文件到/data/apps/ranger-2.0.0文件夹,然后重命名为ranger-metastore
4.修改ranger-metastore文件夹里的install.properties文件,其他内容可以和hiveserver2插件基本一致,REPOSITORY_NAME需要注意一下:1.可以和hiveserver2不保持一致,2.如果插件要安装多个机器,每个机器都可以不一样。这里填的是你想要拉取ranger admin的策略的名字。
5.启动插件,重启metastore,测试下hive cli的权限管控是否生效,因为hive cli直接连接metastore。
注意事项:
metastore和hive cli的权限管控会由metastore插件开启,hiveserver2的权限管控会由hiveserver2插件开启,插件安装之后都会在hive的配置目录下生成ranger-hive-security.xml文件,后面安装插件生成的文件会覆盖掉前面安装插件生成的文件。
metastore、hive cli和hiveserver2都会按照ranger-hive-security.xml文件中配置的情况去从ranger admin拉取权限策略,并遵从此策略进行权限管控。
6.5 spark插件
1.下载开源组件代码,地址:github.com/apache/subm…
2.解压缩zip包,然后编译源码
ruby 代码解读复制代码mvn clean package -Pspark-3.0 -Pranger-2.0 -Dmaven.javadoc.skip=true -DskipTests -pl :submarine-spark-security
3.编译后,源码的submarine-security/spark-security目录下会生成一个target目录,复制target目录中的submarine-spark-security-0.6.0.jar包到SPARK_HOME是spark的安装目录。
4.在$SPARK_HOME/conf目录下创建ranger-spark-security.xml文件,文件内容如下:
xml 代码解读复制代码<configuration>
<property>
<name>ranger.plugin.spark.policy.rest.urlname>
<value>http://hadoop-1:6080value>
property>
<property>
<name>ranger.plugin.spark.service.namename>
<value>prd-hivevalue>
property>
<property>
<name>ranger.plugin.spark.policy.cache.dirname>
<value>/etc/ranger/hive/policycachevalue>
property>
<property>
<name>ranger.plugin.spark.policy.pollIntervalMsname>
<value>5000value>
property>
<property>
<name>ranger.plugin.spark.policy.source.implname>
<value>org.apache.ranger.admin.client.RangerAdminRESTClientvalue>
property>
configuration>
5.复制文件$HIVE_HOME/conf/ranger-hive-audit.xml到$SPARK_HOME/conf目录下,并改名为ranger-spark-audit.xml
6.在spark-defaults.conf文件中新增以下配置
ini 代码解读复制代码spark.sql.extensions=org.apache.submarine.spark.security.api.RangerSparkSQLExtension
7.测试权限管控是否生效,测试成功后,上传新增jar包到HDFS,如果需要上传的话。
七 未来展望
1.建立统一的权限管控中心,将其他需要进行权限管控的组件也放到Ranger中,进行统一的权限管控
2.目前Ranger存在一些问题,例如审计日志检索功能不好用,导致有时候检索不到一些数据,需要解决这些问题,对Ranger做进一步优化。
3.对于metastore这种提供api访问方式且存放重要数据的组件,实现更为严格的用户认证方式。
评论记录:
回复评论: