
1.引子
早上好!今天我要跟你分享的是ConcurrentHashMap。
尽管你说你们的项目业务复杂度不高,没有多少用户量,不需要考虑并发情况,你从来都只用到了HashMap,不关心ConcurrentHashMap。那也没有关系,ConcurrentHashMap与HashMap师出同门,有着千丝万缕的关系,它们二者的武功路数是一样的,只不过ConcurrentHashMap的修为要更高(它是并发安全的HashMap)。
因此借助上一篇我们刚分享完HashMap,趁热打铁一块儿把ConcurrentHashMap一起收拾了。那么这一篇我们就接着上一篇,主要搞清楚这么几个问题:
- 上一篇我们分析了HashMap的底层实现原理,比如说底层数据结构是数组,通过拉链法解决hash冲突等。那你能告诉我,在实际项目中该如何更好的使用HashMap吗?
- 上一篇我们分析了HashMap在解决hash冲突的时候,有两种方案:开放寻址法、拉链法。那你能告诉我,它们之间有什么区别吗?
- 你说ConcurrentHashMap是线程安全版本的HashMap。那么你能告诉我,它是如何实现线程安全的?在jdk8与jdk8以前版本中,有什么差异吗?以及jdk8中改变线程安全实现方式的背后逻辑吗?(灵魂三拷问......)
好了,带上以上几个问题,让我们开始吧
2.案例
2.1.HashMap最佳实践
现在我们知道了,在实际项目中,我们是把HashMap作为容器来使用的。既然是容器,那就需要考虑这么几个问题:
- 容器的容量大小,能够支持存放多少个元素,一开始给多少合适呢?(初始容量问题)
- 指定了容器初始容量大小后,万一元素太多,容器放不下了如何处理呢?(容器扩容、装载因子问题)
针对上面的问题,我们来分析一下:
- 在HashMap中,默认的初始容量大小是16, 在实际项目中,我们可以考虑预估要存入的元素个数,根据元素个数设置合适的初始容量。减少HashMap动态扩容,减少重建哈希表,从而提升性能
arduino 代码解读复制代码/**
* The default initial capacity - MUST be a power of two.
* 默认初始容量,HashMap的容量最好是保持 2的n次方
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- HashMap装载因子,默认是0.75。表示在HashMap中,当元素的个数超过:capacity * 0.75的时候,就会启动动态扩容,每次扩容后容量大小都是之前的两倍
- 装载因子越大,表示空闲空间越小,对应的HashMap冲突的概率就会越大。在实际项目中,我们可以设置合适的装载因子,提升HashMap性能
arduino 代码解读复制代码/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
2.2.hash冲突详解
现在你已经知道了在项目中用好HashMap,需要考虑的一些问题:初始容量、装载因子等。
接下来我们一起来看另外一个问题:如何解决hash冲突。关于hash冲突,单从应用HashMap来说,我们并不需要关心,毕竟大多数时候,我们都仅仅是使用HashMap,并不会考虑从0到1写一个HashMap。但是我还是想建议你了解一下,关于整个世界的认知,我们都应该知其然,且知其所以然。
上一篇我们提到关于hash冲突,主要有两种解决方案:开放寻址法,拉连法。但是当时我并没有详细说明,我们跳过了,现在我们一起来看一下,什么是开放寻址法?什么是拉链法?
我们知道HashMap的底层数据结构是数组,数组的容量是有限的(我们暂时不考虑扩容,因为扩容后容量也还是有限的,只是比起扩容前大一倍)。
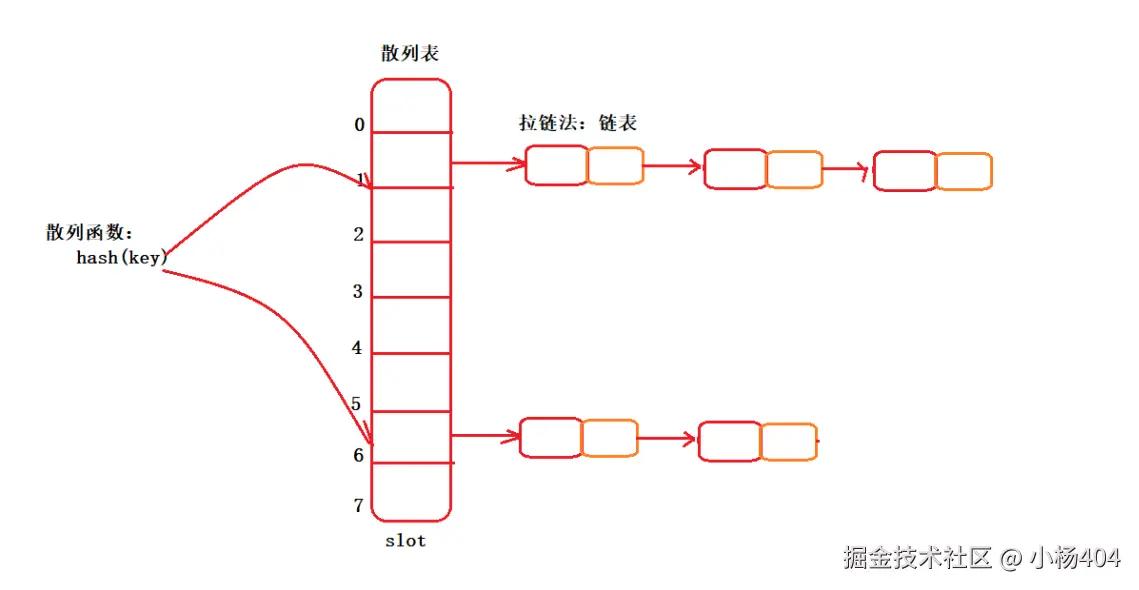
我们也知道HashMap的存储是key/value键值对,需要将任意类型的key,通过散列函数hash(key),转换成数组下标,与数组联系起来,实现在O(1)时间复杂度下,查找目标元素。我们直观的看一个图:
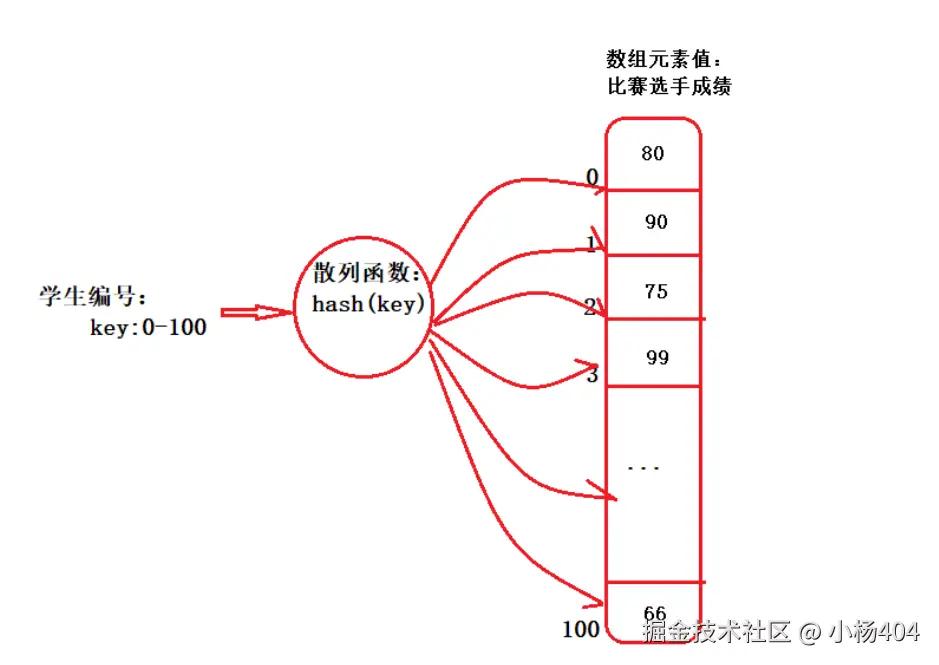
另外你还记得我们上一篇举的示例吗?hash(0+5)=5,hash(1+4)=5,hash(2+3)=5。假设当前目标数组下标是:5,那你也看到了,左右key:0+5,1+4,2+3并不相同,但是通过hash函数后,却都指向了数组下标:5的位置。这就是hash冲突的由来。
好了,我又带着你回顾了一遍hash冲突,现在我们重新回到解决hash冲突:开放寻址法、拉链法。
2.2.1.关于开放寻址法
开放寻址法,是指当发生hash冲突后,比如说某个key,通过哈希函数hash(key),指向了数组下标5的位置。此时不巧下标5的位置已经存放了元素,即发生了hash冲突。
那么开放寻址法的做法,是从数组下标5的位置开始向后搜索,寻找到第一个空的,还未存放任何元素的下标位置,比如:8,作为当前key元素存放的位置。
我们来直观的看一个图:
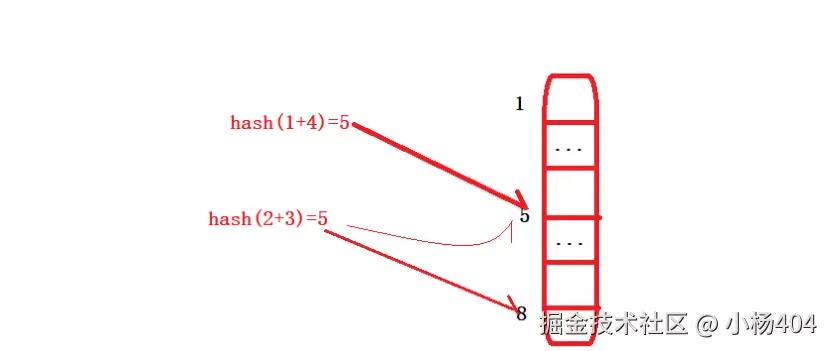
前一个元素hash(1+4)=5,占用了数组下标5的位置;
后一个元素hash(2+3)=5,虽然指向了数组下标5位置,但是此时下标5的位置已经被hash(1+4)元素占用,所以hash(2+3)元素只能继续向后搜索,直到搜索到下标8的位置,发现下标8位置未使用,即作为元素hash(2+3)的位置。
你看,这就是开放寻址法。
2.2.2.关于拉链法
拉链法,是指当发生hash冲突后,比如说某个key,通过哈希函数hash(key),指向了数组下标5的位置。此时不巧下标5的位置已经存放了元素,即发生了hash冲突。
那么拉链法的做法,不同于开放寻址法。它不需要从下标5的位置向后搜索,它是直接定位到下标5的位置,在此处通过链表,将发生hash冲突的多个元素连接起来,形成一个链表。
我们直观的看一个图:
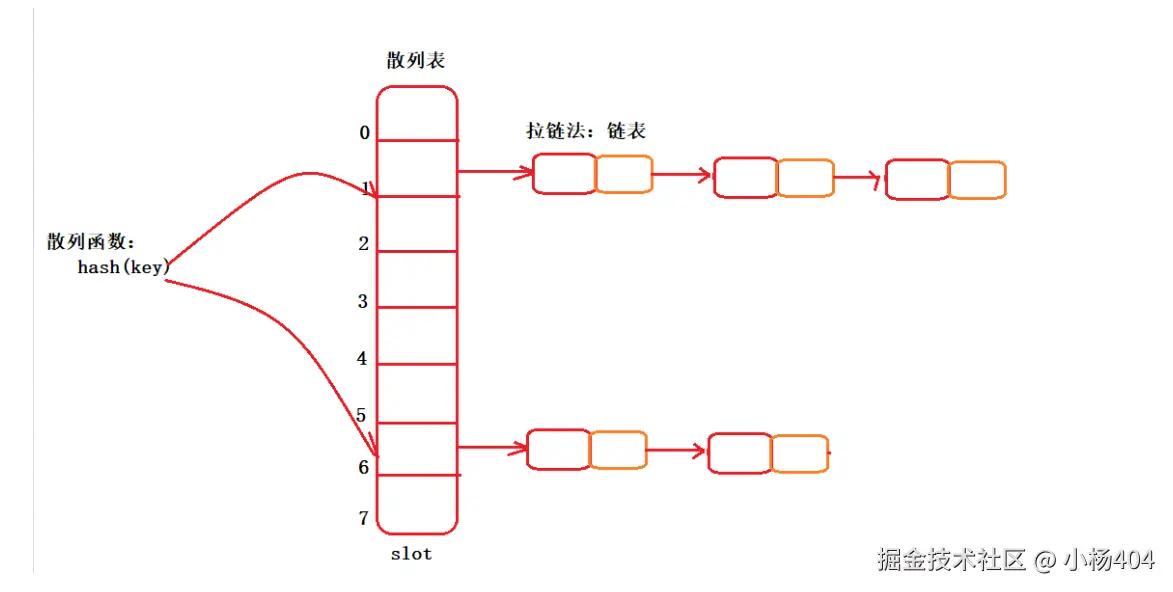
你看,这就是拉链法。
2.2.3.关于二者适用场景
现在你已经知道了什么是hash冲突,以及hash冲突的两种主要解决方案:开放寻址法、拉链法。
我们再来探讨一个问题,什么场景下适合用开放寻址法?什么场景下适合用拉链法呢?
我们知道开放寻址法,最大的特点就是当发生hash冲突的时候,有向后搜索的操作。那么假设在存放大量目标元素对象的场景下,发生冲突的概率会非常大,每次发生冲突,都要向后搜索操作,会比较影响性能。
因此,开放寻址法适合在容器容量需求不大(即目标元素不多),hash冲突发生概率小的场景下,我建议你可以看一下ThreadLocalMap源码,ThreadLocalMap即使用了开放寻址法解决hash冲突。
知道了开放寻址法的适用场景后,我们通过反向思考,即不难理解拉链法的使用场景了。拉链法适合在目标元素多,容器容量需求大、hash冲突发生概率大的业务场景。不用说,你已经知道了,我们一直的主角HashMap,ConcurrentHashMap都使用了拉链法解决hash冲突。
2.3.ConcurrentHashMap详解
为了方便你理解ConcurrentHashMap,我们前面做了非常长的铺垫,上一篇文章以及这篇文章的上半部分。
现在相信你已经理解了HashMap,那我们就开始进入ConcurrentHashMap的内容了。关于ConcurrentHashMap,大方向上你先有一个印象:ConcurrentHashMap它是HashMap的线程安全版本,它与HashMap一脉相传,是师兄弟关系,只不过它是关门弟子,得了师傅的真传,能力要更加强大一些。
上面这段话的意思,大致是想要告诉你,ConcurrentHashMap的底层实现原理,用了什么数据结构,如何解决hash冲突等都与HashMap一样。我们只需要关心它是如何实现线程安全的就可以了。
那就让我们开始吧,你需要注意一下,ConcurrentHashMap线程安全的实现,在jdk8版本,与jdk8以前的版本区别比较大,我们分开来说。
2.3.1.jdk7版本的ConcurrentHashMap
我们先来看ConcurrentHashMap在jdk8以前版本的实现,以下我的分析,和涉及到的源码都是参考jdk7,你先留意一下。
谈到线程安全,你肯定想到了,除了加锁没有别的手段,并且你还进一步想到了我们在锁小节分享的:synchronized、或者Lock对象。
这里我们初步的想法是没有任何问题的,想要实现线程安全:加锁。但是我们还需要稍微往前思考一个问题:如果只是简单的加锁,那不就是Hashtable了吗?java设计者的大神们,你们是不是闲着没事干,顺便多写了一个ConcurrentHashMap呢?
答案肯定不是的,大神之所以称之为大神,其中有一个区别于常人的特质,就是从来不做无用功!
那要这么说,我们就需要搞清楚有了Hashtable,为什么还需要一个ConcurrentHashMap?
我们先回顾一下,Hashtable是如何实现线程安全的,以及它存在什么问题?你还记得吗,前面我们在高级并发编程系列十四(并发集合基础) 一篇,分享了Hashtable实现线程安全的方式,它是直接在每个操作方法上加了synchronized关键字。比如下图,是我们熟悉的get方法:
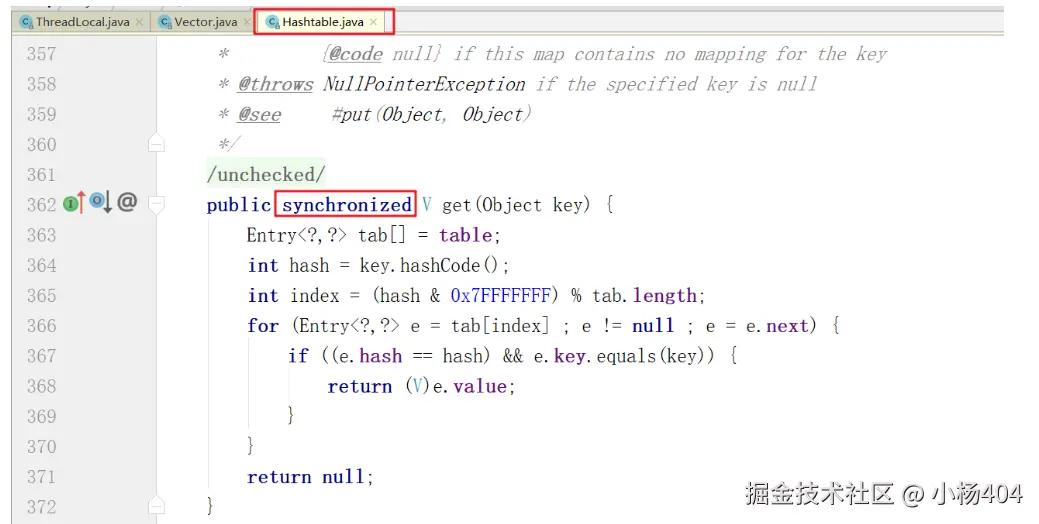
我们说直接在方法上加synchronized关键字,实现线程安全有什么问题呢?最大的问题就是锁粒度太大,导致并发性能低,不足以应用在高并发业务场景。这也是为什么Hashtable出身以来,从未受宠的原因,你也不喜欢它对吧!千万别说喜欢,非要喜欢的话怎么不见在你的项目中使用Hashtable呢?
说了这么多别人的不是,其目的都是为了衬托ConcurrentHashMap的主角光环。那你说说看吧,ConcurrentHashMap到底是如何实现线程安全,又是如何支持高并发的?我们从两个方面来看。
既然要线程安全,那么锁,肯定是要锁的,基础原理不变
另外要支持高并发业务场景,都加锁了,还怎么实现高并发呢?这个地方你需要特别留意了,这里我将给你分享一个解决大、且复杂问题的通用思想,我们说:面对大的,复杂的业务问题,要想实现化繁为简,唯一的手段即是拆分。今天我们说分布式,微服务化其核心都是拆字决!
那具体到ConcurrentHashMap中,它到底是如何拆的呢?它是这么拆的:通过分段锁,即保障了线程安全,又提升了并发能力。
关于分段锁,你可以这么去理解:原来是一个大锁,限制了并发能力,因为只有一把锁;现在我们把大锁分成多把小锁(ConcurrentHashMap默认是16个分段锁),可以同时支持16个并发。
好了,文字分析我们差不多讲明白了,接下来我通过源码,以及画一个图,让你更好的理解ConcurrentHashMap(你需要注意,我当前的jdk版本是7)。
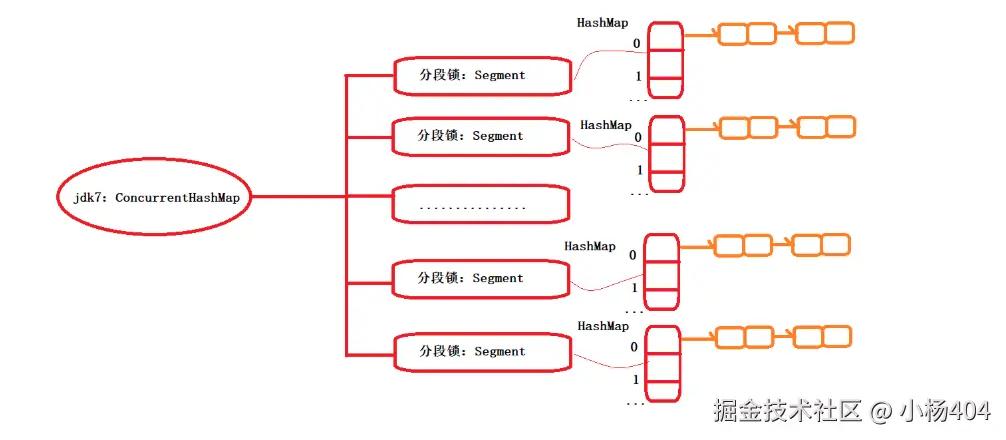
ConcurrentHashMap图示:
ConcurrentHashMap源码代表:
通过上图我们直观看到在jdk7中,ConcurrentHashMap它是通过分段锁实现支持高并发,默认情况下,有16个分段锁,其中每一个分段锁中,即是一个HashMap。
接下来我们一起通过源码,辅助理解上图。
- 底层数据结构,数组
swift 代码解读复制代码/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;
- 分段锁Segment定义
scala 代码解读复制代码/**
* Segments are specialized versions of hash tables. This
* subclasses from ReentrantLock opportunistically, just to
* simplify some locking and avoid separate construction.
* 每个Segment,原来就是一个ReentrantLock,好熟悉有没有
*/
static final class Segment,V> extends ReentrantLock implements Serializable {
......
}
- 分段锁内部定义
css 代码解读复制代码/*
*每个Segment,都是一个HashMap
*/
transient volatile HashEntry[] table;
2.3.2.jdk8版本的ConcurrentHashMap
现在你已经知道了jdk7中的ConcurrentHashMap,我们说在jdk8中,它不再是分段锁的设计思想了,它变了!
变成什么了呢?变成了cas + synchronized组合来保障线程安全,同时实现支持高并发。这里你还记得什么是cas吗,如果不记得了,我推荐你看我这个系列的另外一篇文章:高级并发编程系列十二(一文搞懂cas) 。
这里限于篇幅和侧重关注点,我就不再详细跟你说cas了,我只简单带你回顾一下cas的核心原理: cas本质上是不到黄河心不死,即不释放cpu,循环操作,直到操作成功为止。
它的操作原理是三个值:内存值A、期望值B、更新值C。每次操作都会比较内存值A,是否等于期望值B、如果等于则将内存值更新成值C,操作成功;如果内存值A,不等于期望值B,则操作失败,进行下一次循环操作 。
给你回顾完cas,我们主要再来关注为什么在jdk8中,ConcurrentHashMap会通过cas +synchronized组合,来替换jdk7中的分段锁Segment呢?难道分段锁它不香吗?
我带着你一起分享一下我的个人理解:
- 我们知道cas是一种无锁化机制,大家都可以并行来抢占cpu(因为不加锁嘛),自然是你可以抢,我也可以抢
- 那要这么说,cas就非常适合并发冲突小,加锁临界点(范围)小的应用场景。
- 请说人话:什么是并发冲突小?简单说就是读多写少的业务场景,即读不需要加锁,写才需要加锁
- 嗯,你这么说我就明白了,我们在项目中使用HashMap,正好都是读多写少,一次写入,多次读取的业务场景。比如本地缓存实现方案
- 因此cas+synchronized组合实现ConcurrentHashMap的方案,在实际应用中,会比分段锁的实现方案,带来更高的并发支持,性能会更好!
你看,这么说,你是不是也能理解jdk8中的ConcurrentHashMap了。最后我们还是看一个图吧。
这个图你见过了,就是我们上一篇中HashMap的图。在jdk8中ConcurrentHashMap的底层数据结构上,与HashMap完全一样,它只是增加了cas+synchronized操作。话不多说,我们看图:
评论记录:
回复评论: