
内存是什么
想象你需要频繁查阅一本参考书,为了方便你会将它放在家中的书架上,而不是家里的书堆里。这样每次需要时你都能迅速找到它。计算机内存(Memory)就像这个书架,为程序提供一个快速访问数据和指令的地方

内存是计算机中的一种高速存储设备,用于存储程序运行时所需的数据和指令,它是 CPU 可以直接访问的数据储存区,是程序执行的基础。内存的大小和速度直接影响程序的运行效率和系统的响应速度,充足的内存可以避免频繁的磁盘交换(Swapping),提高多任务处理能力
计算机设计初衷是高效运行程序,因此虽然硬盘的容量更大,反而被称为辅助存储器,CPU 可以直接读取的内存被称为主存储器
内存地址
程序执行有几个基本步骤
- 编写源代码:使用文本编辑器编写 C 语言代码
- 编译:使用编译器(如
gcc)将源代码编译成机器码,生成可执行文件 - 加载:操作系统将可执行文件加载到内存中,分配内存空间
- 执行:CPU读取内存中的指令,逐条执行程序
- 终止:程序执行完毕,操作系统回收内存资源
程序的源代码存储在磁盘,而 CPU 无法直接读取磁盘,因此需要将程序从磁盘加载到内存才能被 CPU 读取。一段看起简单的程序可能由多条指令组成,在程序是怎么执行的(一):基础流程里面介绍过,CPU 一次只能执行一条指令
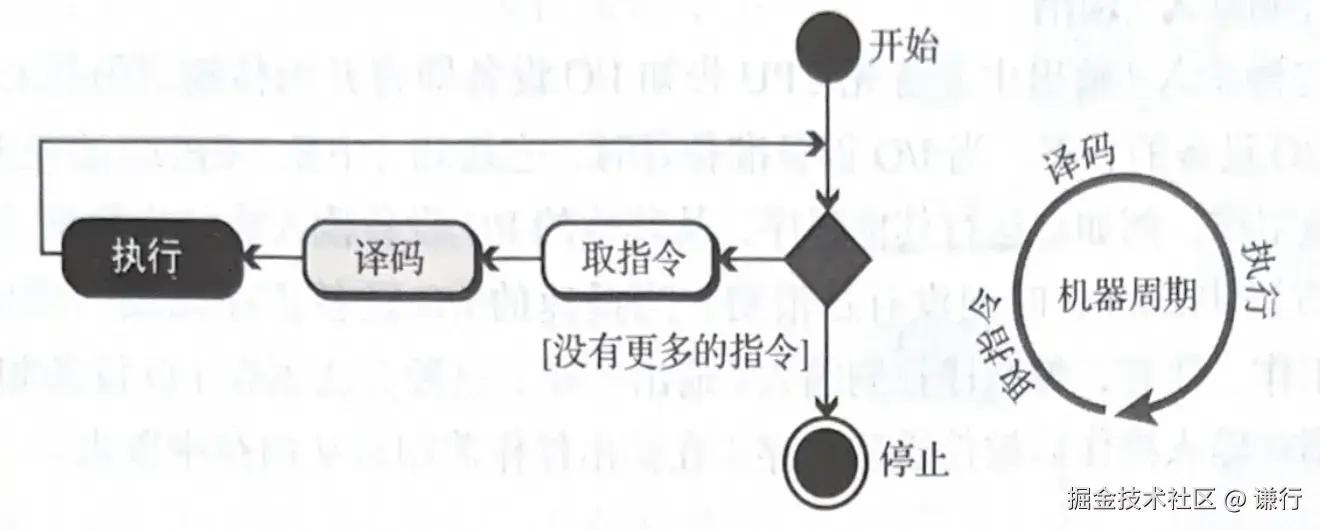
因此在将程序编译后的指令列表载入内存之前需要为其编号,存入到指定的位置供 CPU 读取,这个指定方式就是内存地址
内存地址是内存中每个存储单元的唯一标识符,它告诉计算机系统数据存储在哪里,以便在需要时能迅速定位和访问这些数据。每个内存单元都有一个独特的地址对应一个字节(字节是计算机基本存储单位,由 8 bit 组成,也就是 8 个二进制数字)的信息存储量,通常以十六进制(Hexadecimal)形式表示,便于人类阅读和处理,一个内存地址通常由以下部分组成:
- 基地址(Base Address) :内存的起始点,决定了内存区域的起始位置
- 偏移量(Offset) :相对于基地址的位移量,用于访问特定的数据单元
c 代码解读复制代码#include
运行结果示例
plain代码解读复制代码变量 var 的地址是: 0x7ffc1a2b3c4d
0x:表示十六进制数,7ffc1a2b3c4d表示具体的地址值。内存地址的长度取决于系统的位数:
- 32位系统:地址长度为32位,表示范围为0到2³²-1(约4GB)
- 64位系统:地址长度为64位,表示范围为0到2⁶⁴-1(约18EB)
接下来了解一下编译、链接和载入过程,就能明白每个指令的内存地址最终是怎么确定下来的
编辑确定程序相对地址
编译过程将高层次的源代码(如C语言)转换为低层次的目标代码(机器码)。在这个过程中编译器会为程序中的变量、函数等分配符号地址,这些地址是相对于程序模块自身的,不是最终的内存地址。
c 代码解读复制代码#include
使用 gcc 编译
plain代码解读复制代码gcc -c example.c -o example.o
生成的目标文件 example.o 包含了几个部分
- 代码段(Text Segment) :存储可执行的机器指令
- 数据段(Data Segment) :存储已初始化的全局变量(
global_var) - 符号表(Symbol Table) :包含变量和函数的符号及其相对地址
- 符号地址:
global_var和main函数在目标文件中的相对地址,例如:
plain代码解读复制代码global_var:0x1000 main:0x1050
C 语言在编译之后还需要链接,把多个目标文件以及 stdio 等 library 合并成一个完整可执行文件
plain代码解读复制代码gcc example.o -o example
在此过程中,链接器会为程序分配基地址,比如0x400000,然后将目标文件中的符号地址与基地址相加
plain代码解读复制代码global_var:0x400000 + 0x1000 = 0x401000 main: 0x400000 + 0x1050 = 0x401050
而这个地址仍旧只是一个相对地址,程序的最终的地址需要在加载到内存时候确认
程序加载确定物理地址
程序加载过程由操作系统负责,将可执行文件加载到内存中,为程序分配实际的内存地址。加载器(Loader)根据系统的内存分配策略和程序的需求,将程序的各个部分放置在内存中的不同区域
- 代码段(Text Segment) :存储程序的机器指令
- 数据段(Data Segment) :存储已初始化的全局变量和静态变量
- BSS段(Block Started by Symbol) :存储未初始化的全局变量和静态变量,运行时被初始化为0
- 堆(Heap) :用于动态内存分配,如
malloc,起始于高地址,向高地址增长 - 栈(Stack) :用于函数调用和局部变量,起始于高地址,向低地址增长
c 代码解读复制代码#include
程序加载到内存后布局大概是这样的
plain代码解读复制代码+---------------------+ | Text Segment | <- 程序指令 |Machine Instructions | +---------------------+ | Data Segment | <- 已初始化的全局变量 | global_var = 100 | +---------------------+ | BSS Segment | <- 未初始化的全局变量 | uninit_global = 0 | +---------------------+ | Heap | <- 动态分配的内存 | *heap_var = 300 | +---------------------+ | Stack | <- 局部变量和函数调用 | local_var = 200 | +---------------------+
逻辑地址与物理地址
对程序而言可以访问的地址实际是操作系统提供的逻辑地址(也称之为虚拟地址),而不是内存实际的物理地址,逻辑地址是程序在执行过程中生成的地址,它是程序员在编写代码时所使用的地址
在实际读写内存时候,操作系统负责逻辑地址到物理地址的映射,之所以这样操作是出于几个方面的考虑
- 进程隔离: 每个进程拥有自己独立的虚拟地址空间,确保进程间的数据隔离与安全。即使多个进程使用相同的虚拟地址,操作系统会将其映射到不同的物理地址,防止数据泄漏与冲突
- 内存保护:通过权限控制,防止非法内存访问,提高系统安全性
- 简化编程模型:为程序提供连续的地址空间,减少内存管理的复杂性
- 支持虚拟内存:通过将部分数据存储到磁盘,允许程序使用超出物理内存容量的地址空间,通过分页和交换机制提升内存利用率
逻辑地址到物理地址的映射是操作系统课程中内存管理的核心,这个过程主要依赖于内存管理单元(MMU)和页表(Page Table)
- 程序生成逻辑地址:在程序执行过程中,CPU生成逻辑地址用于数据访问
- 地址分割:
-
- 页号(Page Number) :逻辑地址的高位部分,表示所在页的编号
- 页内偏移量(Offset) :逻辑地址的低位部分,表示页内具体的位置
- 页表查找:
-
- MMU通过页号在页表中查找对应的物理页帧地址
- 页表由操作系统维护,记录虚拟页与物理页帧的映射关系
- 生成物理地址:将物理页帧地址与页内偏移量组合,得到最终的物理地址
- 访问物理内存:根据物理地址,CPU在内存中读取或写入数据
变量与类型的本质
c 代码解读复制代码int num = 5;
我们知道这个语句的含义是定义一个 int 类型的变量,并赋值为 5,但对编译和载入内存而言其实有几个过程
- 内存分配:分配一块大小为
sizeof(int)的内存来存储变量num。在大多数现代系统中int通常占用 4 个字节,但具体大小可能会因系统架构和编译器而异 - 符号表记录:在编译过程中,编译器会通过符号表将变量名
num与其对应的内存地址相关联,在后续代码中对num的任何操作都通过符号表找到其在内存中的实际地址 - 内存区划分:如果
num是全局变量,编译器通常将它存储在全局数据区(Data Segment),如果是局部变量,它会被分配在栈(Stack)中 - 值初始化:将值
5存储到分配给num的内存区域
变量名只是内存地址的一个别名,类型决定了变量在内存中的大小和表示方式,来看一下令 C 语言的拦路虎——指针
c 代码解读复制代码#include
根据上面的理论我们知道 arr 本质上是一块 sizeof(int) * 5内存空间地址,前面提到过计算机的存储基本单位是字节,而一般 int 占用了 4 个字节,arr 里面有 5 个 int,那么需要 20 个字节,每个字节都有一个地址,arr 怎么表示 20 个地址呢?
答案就是 arr 是第一个 int 的第一个字节的地址,所以访问数组第一个元素是 arr[0]。这时候有同学可能问:按照这个理论,每个 int 占用四个字节,数组第二个元素应该是 arr[4],为什么实际使用时候是 arr[1] 呢?
这是因为数组给做了快捷操作,当使用数组下标访问元素时,所使用的下标实际上是以元素为单位的,而不是以字节为单位的。编译器根据数据类型自动处理每个元素的大小,所以当访问 arr[1] 时,实际上访问的是“从数组头部开始偏移一个 int 大小单位的位置”,即它指向了第二个元素
arr 本身其实就是个指针,所以我们才能定义一个指针,直接使用 arr 赋值int *ptr = arr;,同时也可以使用指针创建数组
c 代码解读复制代码int *ptr = malloc(5 * sizeof(int));
而在 C 语言中数组下标访问 ptr[i] 本质上是指针操作的一种语法糖,在底层等价于 *(ptr + i)
c 代码解读复制代码*(ptr + 0) = 10; // 等价于 ptr[0] = 10;
*(ptr + 1) = 20; // 等价于 ptr[1] = 20;
*(ptr + 2) = 30; // 等价于 ptr[2] = 30;
*(ptr + 3) = 40; // 等价于 ptr[3] = 40;
*(ptr + 4) = 50; // 等价于 ptr[4] = 50;
毫无疑问, 移动下标是 ptr + 1 而不是 ptr + 4,指针只是代表内存地址,而如果想获取指针指向地址的值需要使用*做解引用,arr[1] 中[]自带了解引用操作,相当于一种快捷的写法
从中可以看出操作系统引入逻辑地址的概念具有重要意义,逻辑地址允许数组使用下标进行随机访问,因为其建立在逻辑地址的连续性基础上,而不强求物理内存的连续性。过多依赖连续的物理内存会加剧内存碎片的问题,从而降低内存使用效率。而逻辑地址通过抽象层有效地满足了程序的连续性需求,同时更优化地利用了物理内存资源
数据类型不只是决定了变量在内存中的大小,编译器还会利用类型检测一下语法错误,几个特别容易混淆的概念
- 静态类型:类型在编译时确定,类型错误在编译阶段被发现
- 动态类型:类型在运行时确定,类型错误在运行阶段被发现
- 强类型:严格遵守类型规则,类型不匹配会导致错误
- 弱类型:允许隐式类型转换,可能导致意外的行为
Python 和 JavaScript 都是动态类型 语言,而 Python 是强类型语言,JavaScript 是弱类型语言
函数与栈
当函数调用时候,CPU 会使用栈存储函数调用时的临时变量和函数调用信息
- 栈帧创建:每次函数被调用时,会在栈上为该函数分配一个新的栈帧。栈帧包含函数的局部变量、参数、返回地址等,其中返回地址指示函数返回后继续执行的程序位置
- 入栈操作:函数执行时,参数值、返回地址和局部变量依次被压入栈,这使得每次函数调用之间的变量是相互独立的,避免数据污染
- 函数执行:函数体内的代码开始执行,使用栈帧中的参数和局部变量
- 出栈操作:函数执行完或者遇到 return 语句时,程序会从栈中弹出当前栈帧,弹出操作会释放栈帧中局部变量所占用的内存空间。程序使用栈帧中的返回地址来恢复执行流,继续执行调用函数的位置后的代码
- 递归与栈:递归函数每调用一次都会增加一个新的栈帧,这解释了为什么过深的递归调用会引发栈溢出错误,每个递归调用返回时,程序继续上一个递归帧的返回地址
factorial(5) 的执行过程大概是这样的
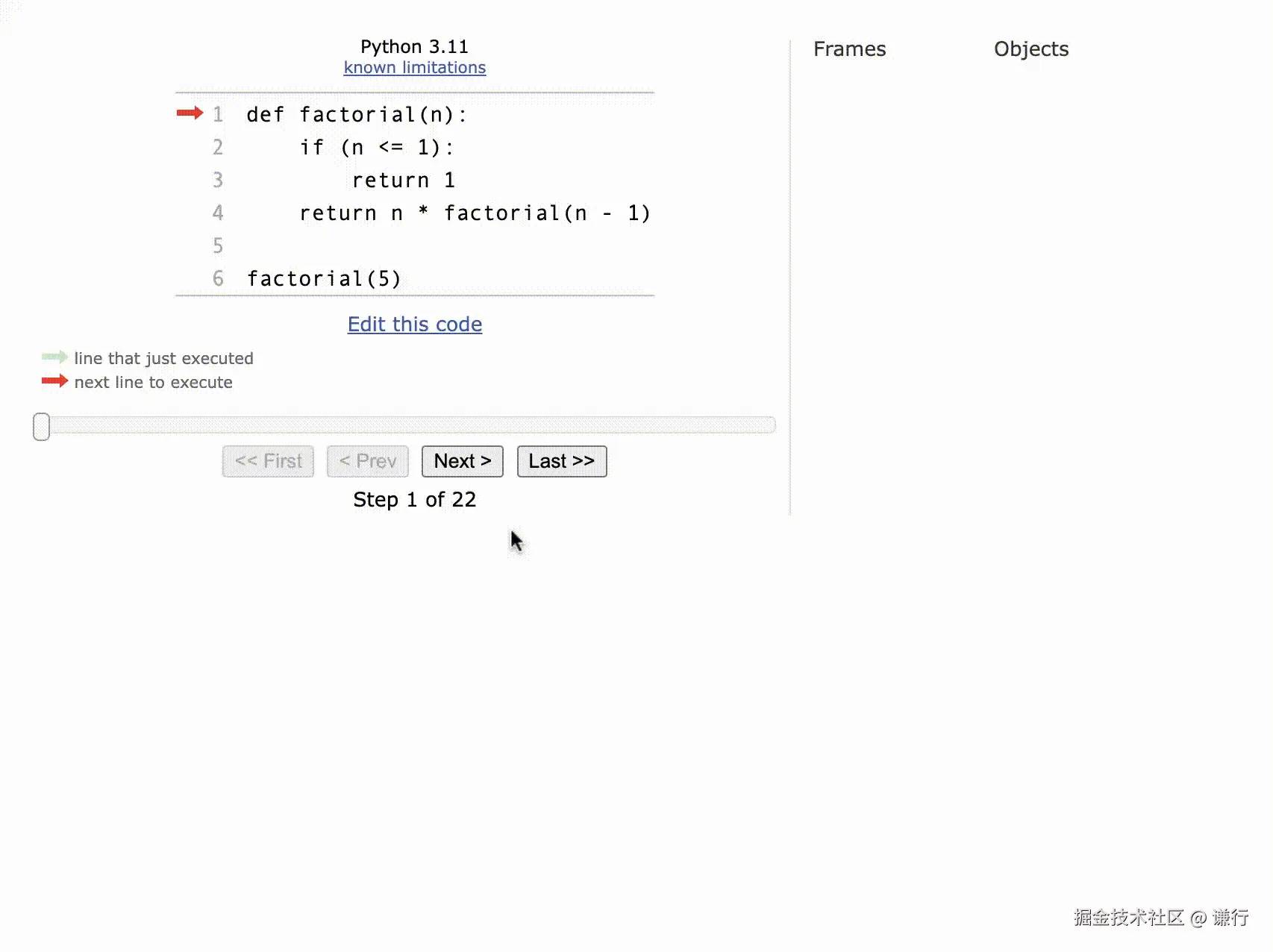
程序计数器(Program Counter,PC)是计算机系统中一个关键的寄存器,用于存放下一条指令所在单元的地址的地方。 当执行一条指令时,首先需要根据 PC 中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为“取指令”。与此同时 PC 中的地址自动加 1,如此往复直到程序所有指令执行完成
函数调用时操作系统会做两步操作
- 保存返回地址: 把当前程序计数器的值(即调用指令的下一条指令的地址)压入调用栈来保存,在函数执行完成后可以跳转回该内存地址继续执行
- 跳转到被调函数: 调用指令将程序计数器设置为被调函数的起始地址,这样程序就开始执行被调函数的指令
函数返回时
- 恢复返回地址: 函数执行完成后,执行返回指令(如
RET指令),此时程序访问调用栈,弹出先前保存的返回地址 - 继续执行调用者的程序: 将程序计数器设置为该返回地址,程序控制流返回到调用函数的下一条指令,继续正常的执行流程
其实 C 语言的goto也是做的类似操作
c 代码解读复制代码#include
-
标记和跳转:
- 编译器在编译时会记录每个标签的位置(即标签在代码中的地址)
- 当遇到
goto语句时,程序会立即跳转到由goto指定的标签所指向的代码行
-
修改程序计数器 (PC) :
- 在执行
goto语句时,程序计数器会被更新为目标标签的内存地址 - 这程时序的下一条指令不再是按顺序执行的,而是开始执行从标签定义的地址开始的指令
- 在执行
致敬
指针理解可以看一下 C 语言指针,读一下视频作者 Harsha Suryanarayana 的生平可能会更有感慨 ,另外作者的数据结构教程也超赞
评论记录:
回复评论: