
讲解视频:www.bilibili.com/video/BV1Tg…
SpringBatch是目前Java生态中最常用的批处理框架,银行业务中经常使用SpringBatch来实现日终结算和报表输出等功能。SpringBatch的起源是2006年埃森哲(Accenture)将自己的私有批处理框架开源,与SpringSource(Spring Framework 的背后公司)合作发布了Spring Batch 1.0。 后续SpringBatch的设计也经过多次重构,但是在今天看来已经存在严重的设计问题,对于性能优化、代码复用都极为不友好。本文将分析SpringBatch的设计问题,并结合NopBatch这一新的批处理框架的实现方案来介绍下一代批处理框架的设计思想。
一. SpringBatch简介
以下是智谱清言AI对于SpringBatch的简介:
Spring Batch 是一个用于批量处理的轻量级、全面的框架。它旨在支持开发对企业级系统的批量处理需求,如大规模数据导入、转换和迁移。Spring Batch 建立在 Spring 框架之上,允许开发者利用 Spring 的核心特性,如依赖注入和声明式事务管理,来创建健壮的批处理应用程序。
以下是 Spring Batch 的一些关键特性:
-
可重用性:Spring Batch 提供了许多可重用的组件,如作业读取器(ItemReaders)、作业写入器(ItemWriters)和处理者(ItemProcessors),这些组件可以很容易地被定制和扩展。
-
可扩展性:框架设计考虑到了扩展性,允许开发者通过插件机制添加自定义的组件。
-
健壮性:Spring Batch 支持事务管理,确保批量作业的原子性和一致性。它还提供了跳过和重试机制,以处理数据错误和故障。
-
声明式开发:通过配置和少量的代码,开发者可以定义复杂的批处理作业流程。
-
并行处理:Spring Batch 支持并行处理,可以通过分区来加速大量数据的处理。
-
启动和调度:Spring Batch 作业可以很容易地被集成到 Spring 的任务调度框架(如 Quartz)中,或者通过命令行启动。
-
监控和管理:框架提供了监控和管理作业执行的工具,包括作业状态追踪和统计信息收集。
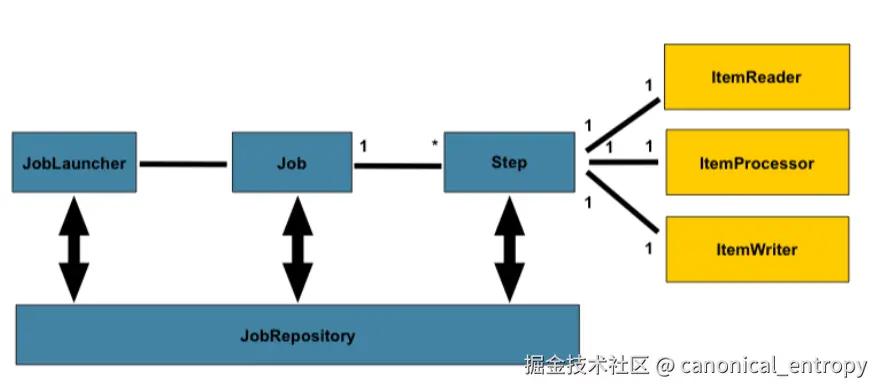
主要组件包括:
- JobRepository:用于存储作业执行期间的数据,包括作业的执行状态。
- JobLauncher:用于启动作业的运行。
- Job:表示一个完整的批处理作业,由一系列的步骤(Step)组成。
- Step:作业中的单个步骤,可以包含读、处理、写等操作。
- ItemReader:负责读取数据。
- ItemProcessor:负责处理读取到的数据。
- ItemWriter:负责将处理后的数据写入到目的地。
Spring Batch 的使用场景非常广泛,包括但不限于:
- 数据同步
- 财务和报表生成
- 数据转换和迁移
- 文件处理
通过使用 Spring Batch,企业可以有效地处理批量操作,提高数据处理效率,同时确保系统的稳定性和数据的准确性。 ==========智谱清言AI创作完毕=====================
SpringBatch的核心接口
SpringBatch内置的核心逻辑是标准的读取-处理-写出三个步骤,对应的接口如下:
java 代码解读复制代码interface ItemReader {
T read();
}
interface ItemProcessor {
O process(@NonNull I item);
}
interface ItemWriter {
void write(Chunk chunk);
}
为了控制处理过程中的资源消耗,SpringBatch引入了Chunk的概念,Chunk是一次性处理的数据量,可以通过配置commit-interval来控制。 比如以下的配置表示每100条数据作为一个chunk来处理,每个chunk都对应一个read-process-write的过程,
xml 代码解读复制代码<batch:job id="firstBatchJob">
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="itemReader" processor="itemProcessor"
writer="itemWriter" commit-interval="100">
batch:chunk>
batch:tasklet>
batch:step>
batch:job>
Chunk的处理逻辑
Chunk的处理逻辑用伪代码表示,大致上是逐个读取并处理,然后收集所有返回结果,一次性写入。
scss 代码解读复制代码doInTransaction:
beforeChunk() // 在事务内执行
repeat:
item = reader.read();
result = processor.process(item);
if(result != null)
outputs.add(result);
try{
beforeWrite()
writer.write(outputs);
afterWrite()
}catch(e){
onWriteError(e,outputs);
}
afterChunk() // 在事务外执行
Writer负责写入一组对象在架构层面便于实现写入优化,比如使用JDBC的batch insert比单条insert要快很多。
二. SpringBatch的设计问题
2.1 Reader的每次调用不应该只返回一条记录
SpringBatch的设计中ItemReader的read调用每次只返回一条记录,这样的设计导致了难以进行批量读取优化。大量的reader内部实现时是按照某个pageSize批量读取,然后再逐条返回。
常见的实现方式如下:
java 代码解读复制代码class JdbcPagingItemReader implements ItemReader {
public T read() {
if (this.results == null || current >= pageSize) {
this.results = doReadPage();
page++;
if (current >= pageSize) {
current = 0;
}
}
int next = this.current++;
if (next < results.size()) {
return results.get(next);
} else {
return null;
}
}
}
这种设计不仅使得Reader必须持有临时状态变量,而且也使得批量优化难以在外部进行。如果Reader读取的不是简单的平面结构记录,而是一个复杂的业务对象,那么如果要实现属性的批量加载,就必须修改Reader的实现代码,导致了代码的耦合性增加。
NopBatch中使用IBatchLoader接口来实现批量加载,可以更好的支持批量读取优化。
java 代码解读复制代码public interface IBatchLoader {
/**
* 加载数据
*
* @param batchSize 最多装载多少条数据
* @return 返回空集合表示所有数据已经加载完毕
*/
List load(int batchSize, IBatchChunkContext context);
}
- 增加了batchSize参数,明确告知加载器当前需要多少数据,便于底层实现优化
- 将context作为参数传递。SpringBatch中要获取context需要实现
ChunkListener.beforeChunk(ChunkContext context)这种接口函数, 将context保存为类的成员变量,然后才可以在load函数中使用,这样的设计过于繁琐。而IBatchLoader接口函数的参数信息完整,便于直接通过lambda函数来实现。 - 一次性返回一个Chunk所需的数据,而不是逐条返回,这样Reader内部就不需要维护复杂的状态变量
基于Loader返回的列表数据,我们可以使用很自然、很简单的方式批量加载相关数据
javascript 代码解读复制代码List data = loader.load(batchSize, context);
// 批量加载其他相关数据,加载的数据可以放到context中,也可以作为data中元素的扩展字段
batchLoadRelatedData(data, context);
当处理数据需要获取互斥锁的时候,SpringBatch的设计也显得非常不友好。因为SpringBatch的ItemReader是逐条读取的,导致获取锁的时候无法进行批量优化,并且获取锁的顺序也难以控制,存在死锁风险。 而NopBatch的设计可以先按照某种规则对记录进行排序(不要求reader读取时整体排序),然后一次性获取所有需要的锁,这样就可以避免死锁风险。
总而言之,SpringBatch的设计体现出Item Oriented的遗迹,导致Chunk级别的处理很不自然。
Chunk的概念是在Spring2.0中引入的,最早的时候SpringBatch只有Item的概念。
SpringBatch 1.0中的ItemWriter接口定义如下:
java 代码解读复制代码public interface ItemWriter {
public void write(Object item) throws Exception;
public void flush() throws FlushFailedException;
public void clear() throws ClearFailedException;
}
2.2 Processor的每次调用不应该只返回一条记录
SpringBatch中Processor的处理逻辑类似于函数式编程中的map函数,data.map(a->b),对每一条输入记录进行处理,返回一个输出记录。 这里很自然的就会产生一个疑问,为什么一次处理最多只会产生一个输出?不能一次处理产生多个输出吗?
现代的流处理框架的语义更接近于函数式编程中的flatMap函数, data.flatMap(a->[b])。也就是说,一次处理,可以有三种结果:A. 没有输出 B. 产生一个输出 C. 产生多个输出。
流式处理模式:如果一次处理可以产生多个输出,那么能不能每产生一个输出就交给下游进行处理,不用等待当前所有输出都产生之后再传递到下游?
NopBatch仿照流处理框架,定义了如下处理接口
java 代码解读复制代码public interface IBatchProcessor {
/**
* 执行类似flatMap的操作
*
* @param item 输入数据对象
* @param consumer 接收返回结果,可能为一条或者多条。也可能不产生数据导致consumer不会被调用
* @param context 上下文信息
*/
void process(S item, Consumer consumer, IBatchChunkContext context) ;
/**
* 两个processor合成为一个processor
*
* @param processor
* @param IBatchProcessor then(IBatchProcessor processor) {
return new CompositeBatchProcessor<>(this, processor);
}
}
-
IBatchProcessor采用回调函数consumer来接收处理结果,内部产生输出元素之后就可以立刻消费
-
IBatchProcessor接口还提供了一个then函数,可以将两个IBatchProcessor组合为一个整体的Processor,形成一种链式调用。这其实是类似函数式编程中Monad概念的一种应用。
2.3 Writer接收Collection类型数据即可
首先SpringBatch中ItemWriter的命名不太合适。ItemWriter从命名上看是用于消费Processor产生的结果数据,这样就导致在概念层面上固化了Read-Process-Write的处理流程。但有很多情况下我们并不需要写出结果,只需要消费输入的数据而已。
NopBatch引入了通用的BatchConsumer概念,使得BatchConsumer和BatchLoader构成一对对偶的接口,BatchLoader加载的数据直接传递给BatchConsumer进行消费。
java 代码解读复制代码public interface IBatchConsumer {
/**
* @param items 待处理的对象集合
* @param context 上下文对象
*/
void consume(Collection items, IBatchChunkContext context) ;
}
基于Consumer接口,Chunk的处理流程变得非常简单
javascript 代码解读复制代码List items = loader.load(batchSize,context);
if(items == null || items.isEmpty())
return ProcessingResult.STOP;
consumer.consume(items,context);
Processor可以看作是一种可选的Consumer实现方案
java 代码解读复制代码public class BatchProcessorConsumer {
@Override
public void consume(Collection items, IBatchChunkContext context) {
Collection outputs = new ArrayList<>();
for(S item: items){
processor.process(item, outputs::add, context);
}
consumer.consume(outputs, context);
}
}
当异步执行Processor的情况下,会使用ConcurrentLinkedQueue来保存outputs。
与NopBatch中Consumer直接接收Collection类型数据不同,SpringBatch中的Witer接收Chunk类型的数据,它的结构定义如下:
java 代码解读复制代码class Chunk implements Iterable, Serializable {
private List items = new ArrayList<>();
private List> skips = new ArrayList<>();
private final List errors = new ArrayList<>();
private Object userData;
private boolean end;
private boolean busy;
}
Chunk结构中包含多种信息,但是在Processor和Reader中却不能直接访问Chunk结构,造成不必要的复杂性。
在NopBatch的架构中,Loader/Processor/Consumer接口都接受同样的IBatchChunkContext参数,通过它可以实现相互协调。同时在IBatchConsumer接口中,items以Collection类型传递即可,没有必要强制要求使用List类型。
对比一下NopBatch中的核心接口
java 代码解读复制代码interface IBatchLoader{
List load(int batchSize, IBatchChunkContext chunkCtx);
}
interface IBatchProcessor{
void process(S item, Consumer consumer,
IBatchChunkContext chunkCtx);
}
interface IBatchConsumer{
void consume(Collection items, IBatchChunkContext chunkCtx) ;
}
显然,NopBatch的三个核心接口更加直观,loader取出的类型可以直接匹配consumer的入参类型,而且三者共享IBatchChunkContext上下文环境,可以利用它实现协调。
一个良好的架构设计应该可以通过它的函数签名(类型定义)看出它的内在组织方式。
2.4 事务处理机制不灵活
SpringBatch强制限定了一个Chunk的Read-Process-Write在一个事务中执行。但是在Nop平台中,业务实体一般都具有乐观锁版本字段,而且在OrmSession中会缓存所有实体对象,这使得我们可以选择仅在Write阶段打开事务,从而缩小事务影响范围,减少数据库连接池的占用时间。
比如说,Processor可以在事务之外运行,当业务处理失败时不会产生数据库层面的回滚,从而降低了数据库的压力,也减少了数据库层面的锁竞争。在OrmSession.flush()调用的时候才会实际将内存中的修改数据更新到数据库中,此时如果发现乐观锁版本发生变化,则可以触发数据库回滚,避免多线程并发访问同一个业务数据出现冲突。
在NopBatch中,我们根据transactionScope配置的不同,可以创建支持不同的事务范围的Consumer。
javascript 代码解读复制代码 if (batchTransactionScope == BatchTransactionScope.consume
&& transactionalInvoker != null) {
// 仅在consume阶段打开事务。process可以是纯逻辑处理过程,不涉及到修改数据库,而读数据一般不需要打开事务。
consumer = new InvokerBatchConsumer(transactionalInvoker, consumer);
}
if (this.processor != null) {
// 如果设置了processor,则先执行processor再调用consumer,否则直接调用consumer
IBatchProcessor processor = this.processor.setup(context);
consumer = new BatchProcessorConsumer<>(processor, (IBatchConsumer) consumer);
}
// 在process和consume阶段打开事务
if (batchTransactionScope == BatchTransactionScope.process && transactionalInvoker != null) {
consumer = new InvokerBatchConsumer(transactionalInvoker, consumer);
}
2.5 失败重试逻辑不灵活
SpringBatch内置了失败重试逻辑:当Processor执行失败时,可以自动按照RetryPolicy的设置重试多次。但是很多时候Processor内部并没有完成所有涉及到单条记录的业务逻辑。比如说,Processor中可能并没有实际保存数据,而是将保存延迟到整个chunk处理完毕,统一使用Jdbc Batch机制来保存。这种情况下,针对单条记录的Retry就无法起到作用。
在NopBatch中,我们提供了一种针对整个chunk的重试机制。当chunk执行失败时,我们会自动重试整个chunk,而且重试的时候可以选择逐条重试,也就是将每个条目作为单独的chunk去重试,这样虽然损失了批量保存的优化,但是可以隔离出那些有错误的单条记录。
java 代码解读复制代码public class RetryBatchConsumer {
public void consume(List items, IBatchChunkContext context) {
IBatchRecordSnapshotBuilder.ISnapshot snapshot =
snapshotBuilder.buildSnapshot(items);
try {
consumer.consume(items, context);
} catch (BatchCancelException e) {
throw e;
} catch (Exception e) {
// 有可能部分记录已经被处理,不需要被重试
if (context.getCompletedItemCount() > 0) {
items = new ArrayList<>(items);
items.removeAll(context.getCompletedItems());
}
retryConsume(e, items, snapshot, context);
}
}
RetryOnceResult retryConsumeOneByOne(int retryCount, List items,
IBatchChunkContext context) {
context.setSingleMode(true);
List retryItems = new ArrayList<>();
Throwable retryException = null;
Throwable fatalError = null;
for (R item : items) {
List single = Collections.singletonList(item);
Throwable consumeError = null;
try {
// 将每条输入数据做成一个小的批次单独执行一次
consumer.consume(single, context);
context.addCompletedItem(item);
} catch (BatchCancelException e) {
consumeError = e;
throw e;
} catch (Exception e) {
consumeError = e;
if (retryPolicy.getRetryDelay(e, retryCount + 1, context) >= 0) {
// 如果item可重试
retryItems.add(item);
retryException = e;
}
}
}
...
}
}
-
之所以能够实现整个chunk的retry,是因为Loader可以一次性获取到一个Chunk的所有输入数据,所以只要把这些数据缓存下来,就可以多次调用Consumer。Processor的处理逻辑已经被封装到BatchProcessorConsumer中,因此重试时只需要重复consume就可以。
-
如果有些已经成功完成的记录不需要被重复处理,则可以在consumer中成功处理之后,将它们加入到BatchChunkContext上下文对象中的completedItems集合中。重试整个chunk时,已经被完成的记录会被自动跳过。
三. NopBatch的架构变化
3.1 通过context实现动态注册Listener
SpringBatch中的reader/writer/processor如果需要监听步骤开始、步骤结束等事件,标准的方法是实现StepExecutionListener这种接口。
java 代码解读复制代码class MyProcessor implements ItemProcessor, StepExecutionListener{
@Override
public void beforeStep(StepExecution stepExecution) {
System.out.println("Before Step: " + stepExecution.getStepName());
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
System.out.println("After Step: " + stepExecution.getStepName());
return stepExecution.getExitStatus();
}
....
}
这种做法造成两个问题
-
如果使用Spring容器来管理这些bean,则考虑到并发执行的情况,这些bean需要设置
scope=step而不能是全局Singleton单例。SpringBatch的StepScope实现非常tricky,导致要求开启全局开关spring.main.allow-bean-definition-overriding。而另一方面Spring在缺省情况下已经禁止Bean重定义,并且强烈建议关闭这个开关。参见@StepScope not working when XML namespace activated。 -
如果我们对Reader/Processor/Writer进行了包装,则会导致这些Listener无法自动被SpringBatch框架所发现。我们必须额外注册listener才可以。理想情况下,应该是注册Writer的时候就自动注册它所需要的Listener,而不需要在配置文件中额外配置Listener。
xml 代码解读复制代码 <step id="step1">
<tasklet>
<chunk reader="itemReader" writer="compositeWriter" commit-interval="2">
<streams>
<stream ref="fileItemWriter1"/>
<stream ref="fileItemWriter2"/>
streams>
chunk>
tasklet>
step>
<beans:bean id="compositeWriter"
class="org.springframework.batch.item.support.CompositeItemWriter">
<beans:property name="delegates">
<beans:list>
<beans:ref bean="fileItemWriter1" />
<beans:ref bean="fileItemWriter2" />
beans:list>
beans:property>
beans:bean>
比如上面的示例配置中,我们使用了一个CompositeWriter,它内部使用了两个Writer来实现功能。但是SpringBatch并不知道这件事情,它所接收到的compositeWriter上并没有实现ItemStream这种回调事件接口。为了要正确调用,我们需要额外增加streams配置,指定那些Writer实现了ItemStream回调接口,需要在适当的时候被调用。
如果和前端框架的变革做一个对比,可以发现一件非常有趣的事情:SpringBatch的这个做法与传统的前端Class Component如出一辙。
javascript 代码解读复制代码class MyComponent extends Vue {
// 组件挂载后执行的逻辑
mounted() {
console.log('Component mounted');
}
// 组件更新后执行的逻辑
updated() {
console.log('Component updated');
}
// 组件卸载前执行的逻辑
beforeDestroy() {
console.log('Component will be destroyed');
}
// 渲染函数
render(h) {
return (
<div>
{/* 组件的渲染逻辑 */}
Hello, Vue Class Component!
div>
);
}
}
核心的设计思想都是在组件上实现生命周期监听函数,框架在创建这些组件的时候注册对应的事件监听器,然后利用组件对象的成员变量来实现多个回调函数之间的信息传递和组织。
前端领域后来出现了一个革命性的进展,就是引入了所谓的Hooks机制,抛弃了Class Based的组件方案。参见我的公众号文章从React Hooks看React的本质
在Hooks方案下,前端组件退化为一个响应式的render函数,考虑到一次性的初始化过程,Vue选择将组件抽象为render函数的构造器。
javascript 代码解读复制代码defineComponent({
setup() {
onMounted(() => {
console.log('Component mounted');
});
onUpdated(() => {
console.log('Component updated');
});
onBeforeUnmount(() => {
console.log('Component will be destroyed');
});
return () => (
<div>
{/* 组件的渲染逻辑 */}
Hello, Vue Composition API!
div>
);
}
Hooks方案相比于传统的类组件方案有如下优点:
-
事件监听函数可以独立于类结构被定义,可以很容易的实现二次封装。比如将上面的onMounted+onUpdated调用封装为一个可复用的useXXX的函数。
-
多个事件监听函数之间可以通过闭包传递信息,而不需要再通过this指针迂回。
-
可以根据传入的参数动态决定是否注册事件监听器。
这里的关键性的架构变化是提供了一种全局的、动态事件注册机制,而不是将事件监听函数与某个对象指针绑定,必须是某个对象的成员函数。
类似于Hooks方案,NopBatch将核心抽象从IBatchLoader这种运行组件变更为IBatchLoaderProvider这种工厂组件,它提供一个setup方法来创建IBatchLoader。
java 代码解读复制代码public interface IBatchLoaderProvider {
IBatchLoader setup(IBatchTaskContext context);
interface IBatchLoader {
List load(int batchSize, IBatchChunkContext context);
}
}
这里的setup函数返回Loader类似于Vue组件的setup函数返回renderer。Vue组件调用一次setup返回的renderer函数,然后renderer函数会被调用多次。 同样的,IBatchLoaderProvider的setup函数被调用一次返回IBatchLoader,然后loader会被调用多次。
上下文对象context提供了onTaskBegin/onTaskEnd等回调函数注册方法。
java 代码解读复制代码class ResourceRecordLoaderProvider extends AbstractBatchResourceHandler
implements IBatchLoaderProvider {
public IBatchLoader setup(IBatchTaskContext context) {
LoaderState state = newLoaderState(context);
return (batchSize, batchChunkCtx) ->{
// 在一个chunk处理完毕后执行回调函数
batchChunkCtx.onAfterComplete(err -> onChunkEnd(err, batchChunkCtx, state));
return load(batchSize, state);
};
}
LoaderState newLoaderState(IBatchTaskContext context) {
LoaderState state = new LoaderState<>();
state.context = context;
IResource resource = getResource(context);
IRecordInput input = recordIO.openInput(resource, encoding);
if (recordRowNumber) {
input = new RowNumberRecordInput<>(input);
}
state.input = input;
// 注册回调函数,当task执行完毕时关闭资源
context.onAfterComplete(err -> {
IoHelper.safeCloseObject(state.input);
});
return state;
}
}
在上面的示例中,我们通过显式传递的上下文对象上的onAfterComplete等函数来注册回调函数。如果做进一步的封装,使用ThreadLocal来存放context对象,则可以使得调用形式更加接近Hooks。
java 代码解读复制代码public class BatchTaskGlobals {
static final ThreadLocal s_taskContext = new NamedThreadLocal<>("batch-task-context");
public static IBatchTaskContext useTaskContext() {
return s_taskContext.get();
}
public static void provideTaskContext(IBatchTaskContext taskContext) {
s_taskContext.set(taskContext);
}
public static void onTaskEnd(BiConsumer action) {
IBatchTaskContext ctx = useTaskContext();
ctx.onAfterComplete(error -> action.accept(ctx, error));
}
public static void onBeforeTaskEnd(Consumer action) {
IBatchTaskContext ctx = useTaskContext();
ctx.onBeforeComplete(()-> action(ctx));
}
}
导入BatchTaskGlobals上的静态方法后,就可以使用如下调用形式
java 代码解读复制代码IBatchLoader setup(ITaskContext context){
init();
...
}
void init(){
onBeforeTaskEnd(taskCtx ->{
...
});
onChunkBegin(batchChunkCtx ->{
...
});
}
类似的,IBatchProcessor和IBatchConsumer等对象都变更为IBatchProcessorProvider和IBatchConsumerProvider的setup函数的返回结果。
Provider现在成为单例对象,可以使用IoC容器进行配置,不需要动态Scope支持。同时,无论封装多少层,都可以直接访问到上下文对象IBatchTaskContext,通过它动态注册各类事件监听函数。
有趣的是,虽然Hooks是React的发明,但是Vue选择将逻辑分解为setup和render两个阶段是一种更加自然的实现。否则就必然需要在每个细节调用处都区分是否是第一次调用需要执行初始化动作。 这对于性能优化而言是非常不利的,在概念层面上上也很容易引入混淆。
3.2 使用通用的TaskFlow来组织逻辑流
SpringBatch提供了一种简易的逻辑流模型,在XML中可以配置多个步骤以及步骤之间的转移关系,还支持并行执行和条件跳转。
比如下面这个由智谱清言AI生成的例子,它通过split启动两个并行执行的子流程,然后每个子流程内部再串行执行步骤。
xml 代码解读复制代码<job id="exampleJob" xmlns="http://www.springframework.org/schema/batch">
<split id="split1" task-executor="taskExecutor">
<flow>
<step id="step1">
<tasklet ref="tasklet1" />
<next on="COMPLETED" to="step2" />
<next on="FAILED" to="step4" />
step>
<step id="step2">
<tasklet ref="tasklet2" />
<next on="COMPLETED" to="step4" />
step>
flow>
<flow>
<step id="step3">
<tasklet ref="tasklet3" />
<next on="COMPLETED" to="step4" />
step>
flow>
split>
<step id="step4">
<tasklet ref="tasklet4" />
step>
job>
SpringBatch中调度的步骤单元对应于Tasklet接口,chunk处理是Tasklet的一种具体实现。
java 代码解读复制代码public class ChunkOrientedTasklet implements Tasklet{
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Chunk inputs = (Chunk) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
inputs = chunkProvider.provide(contribution);
if (buffering) {
chunkContext.setAttribute(INPUTS_KEY, inputs);
}
}
chunkProcessor.process(contribution, inputs);
chunkProvider.postProcess(contribution, inputs);
chunkContext.removeAttribute(INPUTS_KEY);
chunkContext.setComplete();
return RepeatStatus.continueIf(!inputs.isEnd());
}
}
有趣的是SpringBatch早期的设计中只有chunk处理,并没有引入通用的Tasklet接口,这反映出SpringBatch整体设计的抽象程度是先天不足的。
Tasklet接口由SpringBatch 2.0引入 ,参见Spring Batch 2.0 Highlights
java 代码解读复制代码public interface Tasklet {
/**
* Given the current context in the form of a step contribution, do whatever is
* necessary to process this unit inside a transaction. Implementations return
* {@link RepeatStatus#FINISHED} if finished. If not they return
* {@link RepeatStatus#CONTINUABLE}. On failure throws an exception.
* @param contribution mutable state to be passed back to update the current step
* execution
* @param chunkContext attributes shared between invocations but not between restarts
* @return an {@link RepeatStatus} indicating whether processing is continuable.
* Returning {@code null} is interpreted as {@link RepeatStatus#FINISHED}
* @throws Exception thrown if error occurs during execution.
*/
RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception;
}
Tasklet接口本质上就是一个通用的函数接口,只是为了支持失败后重试,它需要通过StepContribution来实现持久化存储。
SpringBatch的关键特性描述中强调了可重用性和可扩展性,但是实际情况是它的可重用性和可扩展性都很差。典型的,SpringBatch中所提供的核心接口也好,流程编排也好,都是特定于SpringBatch自身实现的,不能用于更广泛的场景。比如说,我们如果扩展了SpringBatch内置的FlatFileItemReader实现了某种数据文件格式的解析,则这个扩展类只能用于SpringBatch批处理这一个特定的场景,而且只能通过SpringBatch框架来使用。当我们想在SpringBatch框架之外复用任何SpringBatch相关的内容的时候都会发现困难重重。
SpringBatch的job配置可以看作是一种非常简易且不通用的逻辑流编排机制,它只能编排批处理任务,不能作为一个通用的逻辑流编排引擎来使用。在NopBatch框架中我们明确将逻辑流编排从批处理引擎中剥离出来,使用通用的NopTaskFlow来编排逻辑,而NopBatch只负责一个流程步骤中的Chunk处理。这使得NopTaskFlow和NopBatch的设计都变得非常简单直接,它们的实现代码远比SpringBatch要简单(只有几千行代码),且具有非常强大的扩展能力。在NopTaskFlow和NopBatch中做的工作都可以应用到更加通用的场景中。
NopTaskFlow是根据可逆计算原理从零开始构建的下一代逻辑流编排框架,它的核心抽象是支持Decorator和状态持久化的RichFunction。它的性能很高并且非常轻量级(核心只有3000行左右代码),可以用在所有需要进行函数配置化分解的地方。详细介绍参见从零开始编写的下一代逻辑编排引擎 NopTaskFlow
在NopTaskFlow中实现与上面SpringBatch Job等价的配置
xml 代码解读复制代码<task x:schema="/nop/schema/task/task.xdef" xmlns:x="/nop/schema/xdsl.xdef">
<steps>
<parallel nextOnError="step4">
<steps>
<sequential timeout="3000">
<steps>
<simple name="step1" bean="tasklet1"/>
<simple name="step2" bean="tasklet2"/>
steps>
sequential>
<simple name="step3" bean="tasklet3"/>
steps>
parallel>
<simple name="step4" bean="tasklet4"/>
steps>
task>
NopTaskFlow提供了parallel、sequential、loop、choose、fork等丰富的逻辑步骤类型,并且每个步骤都支持timeout、retry、decorator、catch、when、validator等通用的增强配置。比如,下面的配置表示在3秒内没有执行完毕则抛出超时异常,在未超时的情况下如果执行失败则重试5次,每次执行都在一个事务中执行。
xml 代码解读复制代码 <sequential timeout="3000">
<retry maxRetryCount="5" />
<decorator name="transaction" />
<steps>
<simple name="step1" bean="tasklet1" />
<simple name="step2" bean="tasklet2" />
steps>
sequential>
sequential表示按顺序执行,因此不需要在每个步骤上指定它的下一步是什么。当step1执行完毕没有报错时,它会自动执行到step2。这种执行模式非常类似于一般的程序语言,可以更容易的和程序语言对应起来。特别是,在SpringBatch中所有步骤是共享要一个全局变量空间,每个步骤再有一个自己的持久化变量空间,而在NopTaskFlow中,步骤之间嵌套调用可以形成一个堆栈,整个逻辑流执行过程中变量的可见范围可以类比于一般的函数调用;嵌套在内部的函数可以看到父函数作用域中的变量。
NopTaskFlow还支持直接嵌套执行Xpl模板语言和XScript脚本。
xml 代码解读复制代码<steps>
<xpl name="step1">
<source>
<c:script>
const isAdmin = svcCtx.userContext.hasRole('admin');
c:script>
<c:choose>
<when test="${isAdmin}">
<app:AdminService arg1="3" />
when>
<otherwise>
<app:UserService arg1="4" />
otherwise>
c:choose>
source>
xpl>
<script name="step2" lang="java">
NopTaskFlow中核心的步骤抽象对应于如下接口
java 代码解读复制代码public interface ITaskStep extends ISourceLocationGetter {
/**
* 步骤类型
*/
String getStepType();
Set getPersistVars();
boolean isConcurrent();
/**
* 步骤执行所需要的输入变量
*/
Listextends ITaskInputModel> getInputs();
/**
* 步骤执行会返回Map,这里对应Map中的数据类型
*/
Listextends ITaskOutputModel> getOutputs();
/**
* 具体的执行动作
*
* @param stepRt 步骤执行过程中所有内部状态都保存到stepState中,基于它可以实现断点重启
* @return 可以返回同步或者异步对象,并动态决定下一个执行步骤。如果返回的结果值是CompletionStage,则外部调用者会自动等待异步执行完毕,
* 在此过程中可以通过cancelToken来取消异步执行。
*/
TaskStepReturn execute(ITaskStepRuntime stepRt);
}
ITaskStep提供了远比SpringBatch的Tasklet更加完善的抽象支持。比如说ITaskStep内置了cancel能力,可以随时调用taskRuntime.cancel或者stepRt.cancel来取消当前逻辑流的执行。每个step的inputs配置描述了输入参数的名称和类型,而output配置描述了产生的输出结果参数的名称和类型,这使得TaskStep可以直接映射到一般程序语言中的函数声明。
xml 代码解读复制代码<xpl name="step1">
<input name="a" type="int">
<source>x + 1source>
input>
<input name="b" type="int">
<source>y + 2source>
input>
<output name="RESULT" type="int"/>
<source>
return a + b
source>
xpl>
以上代码等价于如下函数调用
javascript 代码解读复制代码function step1(a:int, b:int){
return { RESULT: a + b};
}
const {RESULT} = step1(x+1,y+2)
3.3 支持工作共享的分区并行处理
SpringBatch提供了将数据拆分成多个分区,并分配给多个从属步骤(slave steps)来实现并行处理的机制。以下是分区并行处理的主要步骤和组件:
-
定义分区器(Partitioner):
- 分区器负责将数据分成多个分区。每个分区包含一部分数据,并将这些分区信息存储在
ExecutionContext中。
- 分区器负责将数据分成多个分区。每个分区包含一部分数据,并将这些分区信息存储在
-
配置主步骤(Master Step):
- 主步骤负责管理分区和分配任务。它使用分区器生成分区,并将每个分区分配给从属步骤进行处理。
-
配置从属步骤(Slave Step):
- 从属步骤负责处理分配给它的分区数据。每个从属步骤可以并行执行,从而提高处理效率。
-
任务执行器(Task Executor):
- 任务执行器用于并行执行从属步骤。可以配置不同类型的任务执行器,如
SimpleAsyncTaskExecutor或ThreadPoolTaskExecutor,以实现并行处理。
- 任务执行器用于并行执行从属步骤。可以配置不同类型的任务执行器,如
通过以上步骤,Spring Batch可以有效地将大任务分解为多个小任务并行处理,从而提高处理效率和性能。
xml 代码解读复制代码<batch:job id="partitionedJob">
<batch:step id="masterStep">
<batch:partition step="slaveStep" partitioner="rangePartitioner">
<batch:handler grid-size="4" task-executor="taskExecutor"/>
batch:partition>
batch:step>
batch:job>
<batch:step id="slaveStep">
<batch:tasklet>
<batch:chunk reader="itemReader" processor="itemProcessor"
writer="itemWriter" commit-interval="10"/>
batch:tasklet>
batch:step>
SpringBatch的这种分区并行设计相当于是从Reader开始就实现分区读取,然后每个Slave步骤都使用专属于自己的Reader去读取数据,然后再做处理。如果某一个分区的数据特别多,其他分区的线程全部处理完毕空闲下来之后也无法帮助它。 在实际业务中,往往存在更细粒度的分区可能性。比如说,银行业务中往往只需要保证单个账户的数据按照顺序处理,不同账户的数据可以并行处理。NopBatch提供了更加灵活的分区并行处理策略。
首先,NopBatch中的BatchTask具有concurrency参数,通过它可以指定使用多少个并行线程去处理。同时,在IBatchChunkContext中保存concurrency参数和当前线程索引参数,这样在处理的时候,我们就可以直接知道总共有多少个处理线程,当前线程是其中的第几个线程,便于内部执行分区操作。
java 代码解读复制代码interface IBatchChunkContext{
int getConcurrency();
int getThreadIndex();
...
}
class BatchTask implements IBatchTask{
public CompletableFuture executeAsync(IBatchTaskContext context){
CompletableFuture future = new CompletableFuture<>();
context.fireTaskBegin();
// 多个线程可以并发执行。loader/processor/consumer都需要是线程安全的
CompletableFuture[] futures = new CompletableFuture[concurrency];
for (int i = 0; i < concurrency; i++) {
futures[i] = executeChunkLoop(context, i);
}
CompletableFuture.allOf(futures).whenComplete((ret, err) -> {
onTaskComplete(future, meter, err, context);
});
return future;
}
CompletableFuture executeChunkLoop(IBatchTaskContext context,
int threadIndex) {
CompletableFuture future = new CompletableFuture<>();
executor.execute(() -> {
BatchTaskGlobals.provideTaskContext(context);
try {
do {
if (context.isCancelled())
throw new BatchCancelException(ERR_BATCH_CANCEL_PROCESS);
IBatchChunkContext chunkContext = context.newChunkContext();
chunkContext.setConcurrency(concurrency);
chunkContext.setThreadIndex(threadIndex);
if (processChunk(chunkContext)!= ProcessResult.CONTINUE)
break;
} while (true);
future.complete(null);
} catch (Exception e) {
future.completeExceptionally(e);
} finally {
BatchTaskGlobals.removeTaskContext();
}
});
return future;
}
}
与SpringBatch的grid分区不同,NopBatch的步骤级别并行处理时是共享Loader、Processor和Consumer的,只是通过IBatchChunkContext传入了concurrency和threadIndex参数。
NopBatch内置了一个PartitionDispatchLoaderProvider,它提供了一种灵活的分区加载能力。PartitionDispatchLoaderProvider在setup的时候会启动几个加载线程去实际加载数据,然后在内存中通过散列函数根据业务关键信息计算得到一个0到32767之间的Hash值,每个Hash值对应于一个微队列,每个队列中的记录都必须按顺序进行处理。所有的微队列放到PartitionDispatchQueue中统一管理。
每个处理线程去加载chunk数据的时候,可以从PartitionDispatchQueue中的微队列中获取数据,每次获取到数据后就标记对应的微队列已经被使用,阻止其他线程去处理同样的微队列。当chunk处理完毕之后,会在onChunkEnd回调函数中释放对应的微队列。
xml 代码解读复制代码<batch>
<loader>
<orm-reader entityName="DemoIncomingTxn">
orm-reader>
<afterLoad>
for(let item of items){
item.make_t().partitionIndex = ...; // 动态计算得到partitionIndex
}
afterLoad>
<dispatcher loadBatchSize="100" partitionIndexField="_t.partitionIndex">
dispatcher>
loader>
batch>
Nop平台中的所有实体都提供了make_t()函数,它返回一个Map,可以用于保存自定义临时属性。这一设计也符合可逆计算每个局部都具有扩展能力的设计理念。
上面是NopBatch DSL的一个配置片段,它采用OrmReader读取DemoIncomingTxn表中的数据,然后按照实体上_t.partitionIndex的配置投递到不同的队列。
在SpringBatch中每个线程对应一个分区,分区的个数等于线程的个数。而在NopBatch中实际分区的个数最大为32768,它远大于批处理任务的并行线程数,同时又远小于实际业务实体数,可以保证分区比较均衡同时又不需要在内存中维护太多的队列。
如果确实需要类似SpringBatch的步骤级别的并行处理能力,可以直接使用NopTaskFlow中的fork或者fork-n步骤配置。
xml 代码解读复制代码<fork name="processFile" var="fileName" aggregateVarName="results"
executor="nop-global-worker">
<producer>
return ["a.dat","b.dat"]
producer>
<steps>
steps>
<aggregator>
aggregator>
fork>
fork步骤的producer可以动态计算得到一个列表,然后针对其中的每个元素会启动一个单独的步骤实例。
NopBatch DSL中的OrmReader和JdbcReader都支持partitionIndexField配置,如果指定了这个分区字段,且传入partitionRange参数,则会自动生成分区过滤条件。
xml 代码解读复制代码<batch>
<loader>
<orm-reader entityName="MyEntity" partitionIndexField="partitionIndex">
<filter>
<eq name="status" value="1" />
filter>
orm-reader>
loader>
batch>
调用批处理任务时传入partitionRange配置
javascript 代码解读复制代码batchTaskContext.setPartitionRange(IntRangeBean.of(1000,100));
上面的配置会导致自动追加分区过滤条件,在执行时会生成如下SQL语句。
sql 代码解读复制代码select o from MyEntity o
where o.status = '1'
and o.partitionIndex between 1000 and (1000 + 100 - 1)
三. DSL森林: NopTaskFlow + NopBatch + NopRecord + NopORM
SpringBatch虽然号称是声明式开发,但是它的声明式是利用Spring IoC有限的Bean组装描述,大量的业务相关内容仍然是需要写在Java代码中,并没有建立一个完整的能够实现细粒度的声明式开发的批处理模型。另外一方面,如果SpringBatch真的提出一个专用于批处理的领域特定模型,似乎又难以保证它的可扩展性,有可能会限制它的应用范围。
NopBatch所提供的解决方案是一个非常具有Nop平台特色的解决方案,也就是所谓的DSL森林:通过复用一组无缝嵌套在一起的、适用于不同局部领域的DSL来解决问题,而不是依靠一个单一的、大而全的、专门针对批处理设计的DSL。针对批处理,我们只建立一个最小化的NopBatch批处理模型,它负责抽象Batch领域特定的Chunk处理逻辑,并提供一系列的辅助实现类,比如PartitionDispatcherQueue。在更宏观的任务编排层面上,我们复用已有的NopTaskFlow来实现。NopTaskFlow完全不具备批处理相关的知识,也不需要为了与NopBatch集成在一起在引擎内部做任何适应性改造,而是通过元编程抹平两者之间融合所产生的一切沟沟坎坎。
举例来说,在文件解析层面,SpringBatch提供了一个FlatFileItemReader,通过它可以进行一系列的配置来实现对简单结构的数据文件实现解析。
xml 代码解读复制代码<bean id="flatFileItemReader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="classpath:data/input.dat" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.FixedLengthTokenizer">
<property name="names" value="length,name,price,quantity" />
<property name="columns">
<list>
<bean class="org.springframework.batch.item.file.transform.Range">
<constructor-arg value="1" />
<constructor-arg value="4" />
bean>
<bean class="org.springframework.batch.item.file.transform.Range">
<constructor-arg value="5" />
<constructor-arg value="24" />
bean>
<bean class="org.springframework.batch.item.file.transform.Range">
<constructor-arg value="25" />
<constructor-arg value="30" />
bean>
<bean class="org.springframework.batch.item.file.transform.Range">
<constructor-arg value="31" />
<constructor-arg value="36" />
bean>
list>
property>
bean>
property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<property name="targetType" value="com.example.MyRecord" />
bean>
property>
bean>
property>
bean>
显然这种配置是非常臃肿的,而且这种配置是专用于SpringBatch的文件Reader。在SpringBatch之外如果我们想解析同样的数据文件,一般很难直接复用SpringBatch中的配置信息。
在Nop平台中,我们定义了一种专用于数据消息格式解析和生成的Record模型,但它并不是为批处理文件解析专门设计,而是可以用于所有需要消息解析和生成的地方,是一种通用的声明式开发机制,而且能力远比SpringBatch中的FlatFile配置强大。
xml 代码解读复制代码<task x:schema="/nop/schema/task/task.xdef" xmlns:x="/nop/schema/xdsl.xdef"
x:extends="/nop/task/lib/common.task.xml,/nop/task/lib/batch-common.task.xml"
xmlns:record="record" xmlns:task="task" x:dump="true">
<input name="bizDate" type="LocalDate" />
<record:file-model name="SimpleFile" binary="true">
<body>
<fields>
<field name="name" type="String" length="10" codec="FLS"/>
<field name="product" type="String" length="5" codec="FLS"/>
<field name="price" type="double" codec="f8be"/>
<field name="quantity" type="int" codec="s4be"/>
fields>
body>
record:file-model>
<steps>
<custom name="test" customType="batch:Execute" useParentScope="true"
xmlns:batch="/nop/batch/xlib/batch.xlib">
<batch:task taskName="test.loadData" batchSize="100" saveState="true">
<taskKeyExpr>bizDatetaskKeyExpr>
<loader>
<file-reader filePath="dev:/target/input/${bizDate}.dat"
fileModelPath="simple.record-file.xlsx" />
loader>
<processor name="processor1">
<source>
consume(item);
source>
processor>
<processor name="processor2" task:taskModelPath="process-item.task.xml">
processor>
<consumer name="all">
<file-writer filePath="dev:/target/output/${bizDate}-all.dat"
record:file-model="SimpleFile"/>
consumer>
<consumer name="selected">
<filter>
return item.quantity > 500;
filter>
<file-writer filePath="dev:/target/output/${bizDate}-selected.dat"
fileModelPath="simple.record-file.xml"/>
consumer>
batch:task>
custom>
steps>
task>
在上面的示例中,演示了在NopTaskFlow中如何无缝嵌入Batch批处理模型和Record消息格式定义。
- NopTaskFlow逻辑编排引擎在设计的时候并没有任何关于批处理任务的知识,也没有内置Record模型。
- 扩展NopTaskFlow并不需要实现某个NopTaskFlow引擎内部的扩展接口,也不需要使用NopTaskFlow内部的某种注册机制注册扩展步骤。这与一般的框架设计形成鲜明对比。
- 只需要查看
task.xdef元模型,了解NopTaskFlow逻辑编排模型的节点结构,就可以使用XLang语言内置的元编程机制实现扩展。 x:extends="/nop/task/lib/common.task.xml,/nop/task/lib/batch-common.task.xml"引入了基础模型支持,这些基础模型通过x:post-extends等元编程机制在XNode结构层对当前模型进行结构变换。我们可以按需引入编译期结构变换规则。
xml 代码解读复制代码<custom customType="ns:TagName" xmlns:ns="libPath" ns:argName="argValue">
<ns:slotName>...ns:slotName>
custom>
会被自动变换为
<xpl>
<source>
<ns:TagName xpl:lib="libPath" argName="argValue">
<slotName>...ns:slotName>
ns:TagName>
source>
xpl>
也就是说,customType是具有名字空间的标签函数名。所有具有相同名字空间的属性和子节点都会作为该标签的属性和子节点。虽然直接使用xpl步骤也不是很复杂,但是基于customType进行元编程变换可以进一步压缩信息表达量,确保只需要表达最少量的信息,所有能推导得到的表达都自动推导得到。
- 所有的XDSL都自动支持扩展属性和扩展节点,缺省情况下带名字空间的属性和节点不会参与XDef元模型检查。所以在task节点下可以引入自定义的
batch-common.task.xml引入的元编程处理器自动解析为RecordFileMeta模型对象,并保存为编译期的一个变量。 file-reader和file-writer节点上的record:file-model属性会被识别,并自动转换。
xml 代码解读复制代码<file-writer record:file-model="SimpleFile">
file-writer>
被变换为
<file-writer>
<newRecordOutputProvider>
<batch-record:BuildRecordOutputProviderFromFileModel
fileModel="#{SimpleFile}"
xpl:lib="/nop/batch/xlib/batch-record.xlib"/>
newRecordOutputProvider>
file-writer>
#{}是XLang语言中所定义的编译期表达式语法,通过它可以获取到编译期设置的变量。
- NopTaskFlow在某个步骤中调用BatchTask,在BatchTask的Processor中我们可以使用同样的方式来调用NopTaskFlow来实现针对单条记录的处理逻辑。
xml 代码解读复制代码<processor name="processor2" task:taskModelPath="process-item.task.xml">
processor>
会被变换为
<processor name="processor2">
<source>
<task:Execute taskModelPath="process-item.task.xml"
inputs="${{item,consume,batchChunkCtx}}"
xpl:lib="/nop/task/xlib/task.xlib"/>
source>
processor>
- task模型通过
customType="batch:Execute"可以嵌入batch模型,在batch模型的processor配置中可以通过task:taskModelPath嵌入另外一个task模型。
- 在数据库存取方面,NopORM提供了完整的ORM模型支持,内置多租户、逻辑删除、字段加解密、柔性事务处理、数据关联查询、批量加载和批量保存优化等完善的数据访问层能力。通过orm-reader和orm-writer可以实现数据库读写。
xml 代码解读复制代码<batch>
<loader>
<orm-reader entityName="DemoIncomingTxn">
<query>...查询条件...query>
orm-reader>
loader>
<consumer name="saveToDb">
<orm-writer entityName="DemoTransaction" allowUpdate="false">
<keyFields>唯一键字段keyFields>
orm-writer>
consumer>
batch>
结合NopTaskFlow、NopBatch、NopRecord和NopORM等多个领域模型,Nop平台就可以做到在一般业务开发时完全通过声明式的方式实现批处理任务,而不需要编写Java代码。
可以停在这里仔细想一下,在一个DSL中同时包含task定义,batch task定义和record定义等多种领域模型定义,同时它们又无缝融合在一起,看起来是一个完整的单一DSL。
- 如果不使用Nop平台要怎么实现?
- 这种定义DSL并将多个DSL粘结在一起的能力能够被抽象出来成为一种通用能力吗?
- 这种抽象能力会影响运行时性能吗?
- 多个DSL混合在一起如何进行断点调试?报错时能准确定位到DSL的源码吗?
- 如何为这种混合的DSL快速开发可视化设计器?能用Excel来做DSL配置吗?
命令行执行
Nop平台所提供的nop-cli工具可以直接执行逻辑编排任务。
- 在_vfs目录下引入
app.orm.xml,batch-demo.task.xml等DSL文件,nop-cli工具会自动加载工作目录下的虚拟文件系统中的所有模型文件。 - 通过
java -Dnop.config.location=application.yaml -jar nop-cli.jar run-task v:/batch/batch-demo.task.xml -i="{bizDate:'2024-12-08'}"执行逻辑编排任务。
- run-task指定的第一个参数为逻辑编排模型文件的路径。
v:表示是_vfs虚拟文件系统下的路径。也可以直接送操作系统中的文件路径。 -i参数指定了逻辑编排任务中的输入参数,采用json格式。也可以通过-if=filePath来指定输入数据文件,文件内为一个JSON数据。- 通过
-Dnop.config.location来指定配置文件,在其中可以配置数据库连接密码等。
TestNopCli单元测试用例中提供了testBatchGenDemo等单元测试函数,可以通过调试这些测试用例来熟悉NopBatch引擎。
四. DSL的多重表象
Nop平台与其他平台的一个本质性区别是Nop平台并不只是内置了一些常用的DSL,而是提供了一整套的面向语言编程(Language Oriented Programming)的基础技术设施,可以用于快速开发或者扩展已有的DSL。而且每一个DSL都不仅仅是具有唯一的表达形式,而是具有Excel、可视化编辑、JSON、XML等多种表达形式,在这几种形式之间自由转换。
举例来说,在record-file.register-model.xml中定义了消息模型具有多种加载器
xml 代码解读复制代码<model x:schema="/nop/schema/register-model.xdef" xmlns:x="/nop/schema/xdsl.xdef"
name="record-file">
<loaders>
<xdsl-loader fileType="record-file.xml" schemaPath="/nop/schema/record/record-file.xdef"/>
<xlsx-loader fileType="record-file.xlsx" impPath="/nop/record/imp/record-file.imp.xml" />
loaders>
model>
上面的配置表示 xxx.record-file.xml这种类型的文件可以被解析为RecordFileMeta对象,解析时按照record-file.xdef元模型进行解析。同时xxx.record-file.xlsx这种类型的文件需要使用XlsxObjectLoader来解析,解析时按照record-file.imp.xml中定义的结构规则。
在txn.record-file.xlsx中定义了一个定长数据文件的格式,包含文件头、文件体和文件尾。
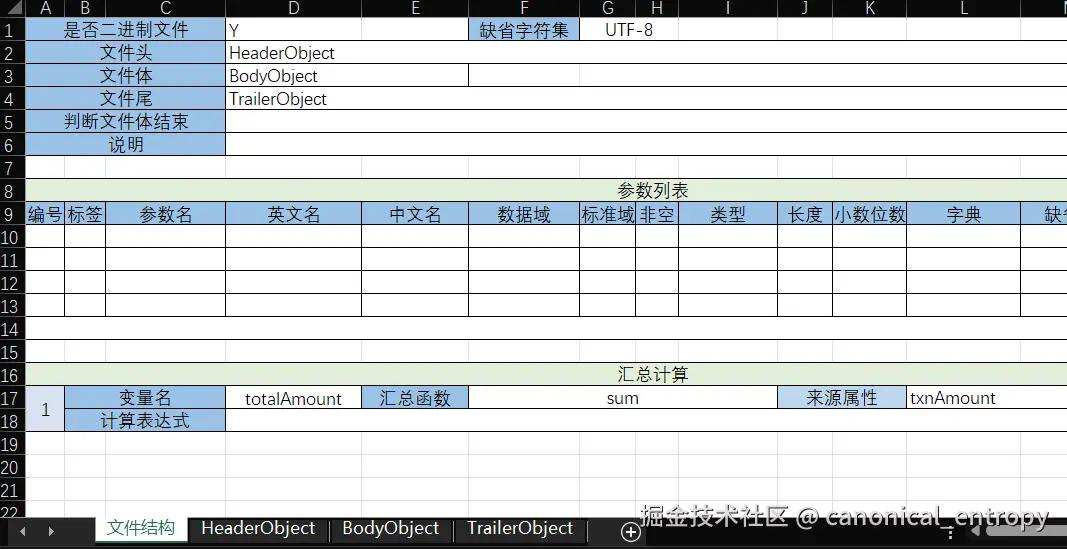
它等价于如下配置
xml 代码解读复制代码<file x:schema="/nop/schema/record/record-file.xdef" xmlns:x="/nop/schema/xdsl.xdef" binary="true">
<header typeRef="HeaderOObject"/>
<body typeRef="BodyObject" />
<trailer typeRef="TrailerObject" />
<aggregates>
<aggregate name="totalAmount" aggFunc="sum" prop="txnAmount" />
aggregates>
<types>
<type name="HeaderObject">
<fields>...fields>
type>
<type name="BodyObject">
<fields>...fields>
type>
<type name="TrailerObject">
<fields>...fields>
type>
types>
file>
ORM模型
在/nop-cli/demo/_vfs/app/demo/orm目录下提供了一个演示用的app.orm.xml模型文件,它演示了非常有趣的NopORM模型配置。
xml 代码解读复制代码<orm x:schema="/nop/schema/orm/orm.xdef" xmlns:x="/nop/schema/xdsl.xdef"
orm:forceDynamicEntity="true" x:dump="true"
xmlns:orm-gen="orm-gen" xmlns:xpl="xpl" xmlns:orm="orm">
<x:gen-extends>
<orm-gen:GenModelFromExcel path="demo.orm.xlsx" xpl:lib="/nop/orm/xlib/orm-gen.xlib"/>
<orm-gen:GenModelFromExcel path="demo-delta.orm.xlsx" xpl:lib="/nop/orm/xlib/orm-gen.xlib" />
x:gen-extends>
orm>
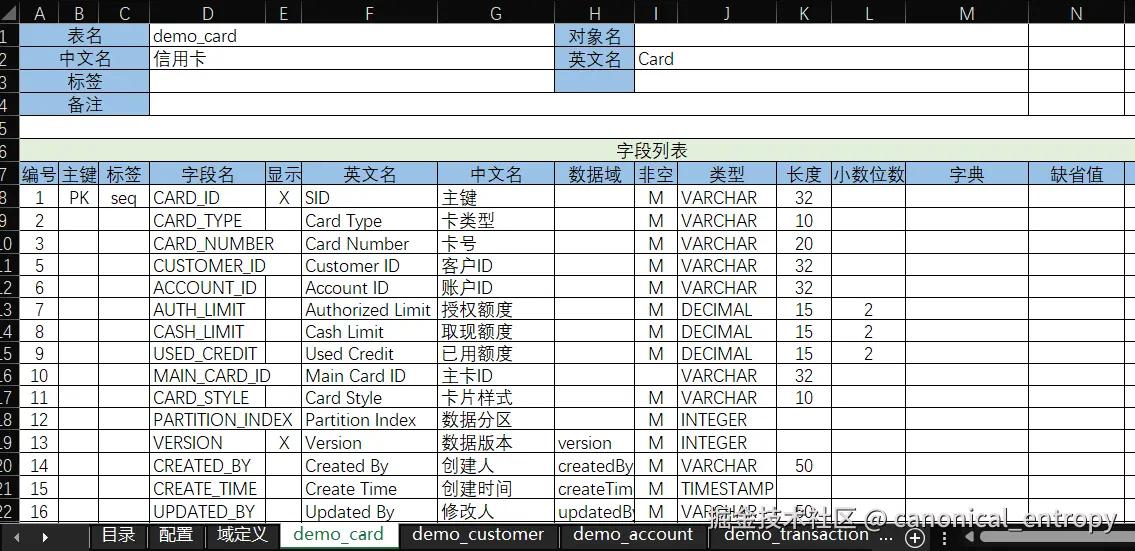
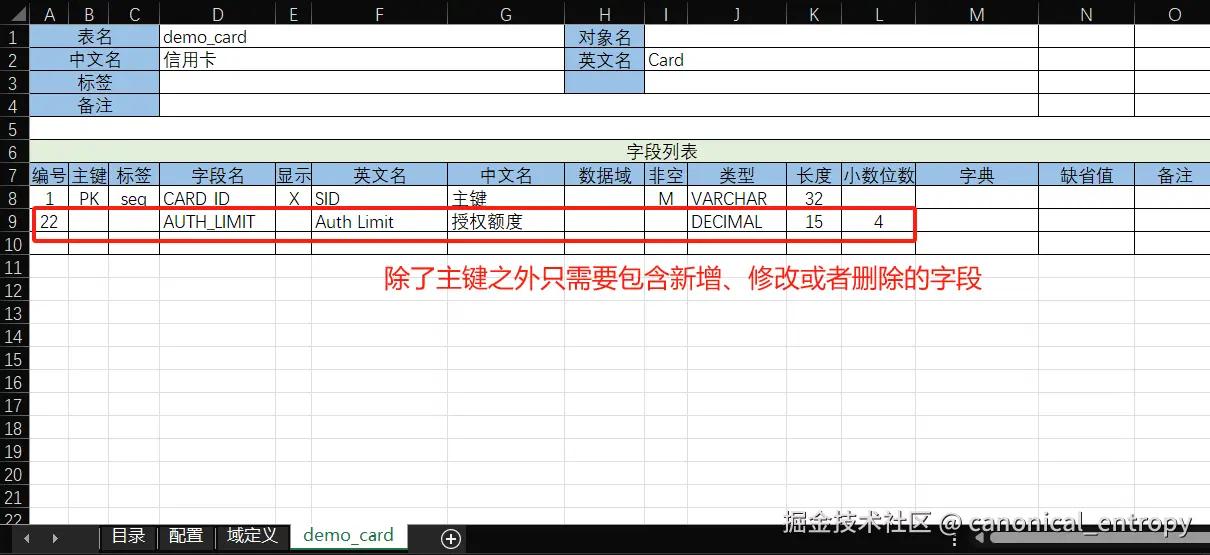
- 首先这里设置了
orm:forceDynamicEntity=true表示无需生成实体类代码,直接用动态实体来实现ORM映射。这样在batch模型中就可以直接使用ORM实体的关联查询,而无需事先生成代码。在XLang语言中,动态实体和普通Java类一样可以直接使用属性访问语法,完全和普通实体一样使用。 - 第二个有趣的地方是
x:gen-extends段演示了元编程模型生成,以及差量模型合并的一种实现方式。这种方式是一种完全通用的做法,而且无需任何额外的努力,它本身就是Nop平台底层能力的一部分。orm-gen:GenModelFromExcel会读取Excel格式的orm.xlsx模型文件,根据orm.imp.xml导入配置自动将它解析为OrmModel对象,然后再利用orm.xdef元模型定义将OrmModel模型对象转换为XNode节点。demo-delta.orm.xlsx中定义了差量模型。当我们希望定制demo.orm.xlsx这个模型文件的时候,可以不修改原始模型文件,直接增加一个新的Delta模型文件,它的结构与原始模型文件完全一致(全量是差量的一个特例,无需为差量表达专门做设计)。- 两个
orm-gen:GenModelFromExcel标签调用会生成两个XNode节点,按照XLang语言规范,x:gen-extends段生成的多个节点会自动执行差量合并,从而合并成一个完整的XNode节点。x:dump=true会导致运行时在日志文件中打印出详细合并过程以及最后合并的结果。
借助于以上配置,我们就可以在Excel中进行数据模型以及数据模型差量的定义,对Excel模型的修改会立刻应用到系统中。如果是在线运行的系统,修改Excel模型后直接刷新页面就会重新加载ORM模型。这是因为Nop平台底层实现了模型资源文件的依赖追踪,模型解析结果依赖于它在编译期所访问的所有资源文件,任何一个资源文件变化都会导致模型缓存失效。
在这里也可以仔细思考一下,如果不使用Nop平台,要实现类似的可视化模型设计和差量化模型定义,需要怎么做?
- 这里并不一定要使用Excel来做可视化设计器,比如我们可以使用PDManer可视化设计工具或者PowerDesigner设计工具来做ORM模型设计,只需要写一个标签函数实现模型转换即可。Nop平台内置了
pdman.xlib和PdmModelParser实现这两种模型的适配。
评论记录:
回复评论: