
先赞后看,Java进阶一大半
小明(化名)坐在密不透风的会议室里,手握着笔,放在桌面上的是满满的两页面试题。
其中一道系统设计题是这样。。。
微博或者短信都有单条发送字数的限制,如果需要分享一个长网址,很容易越出限制,短链服务可以将长网址变成短网址,方便传播。
请设计一个短链服务,要求短网址尽可能短,且保证系统安全和并发能力。
各位hao,我是南哥,相信对你通关面试、拿下Offer有所帮助。
⭐⭐⭐一份南哥编写的《Java学习/进阶/面试指南》:https://github/JavaSouth
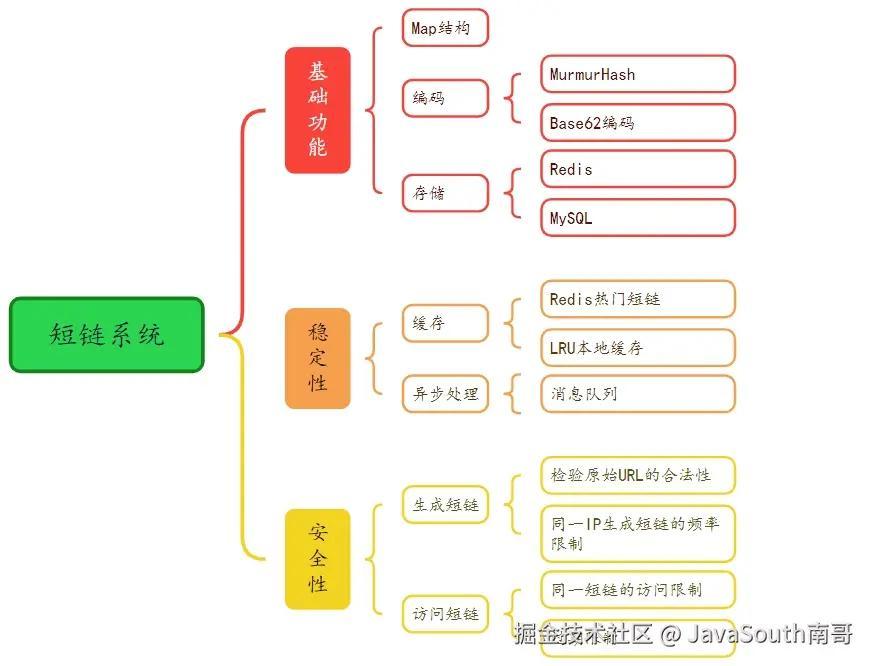
1. 短链系统设计
1.1 基础功能
如何设计短链服务最基础、最核心的功能?短链系统把一条长链转换为一条短链,它们之间是一个一对一的关系。这样我们使用Map结构来存储这个对应关系,这里我们用到高性能内存服务器Redis。
这个对应关系同样需要进行物理存储,暂定使用MySQL,先做出一个表设计。
sql 代码解读复制代码# 短链数据库表
CREATE TABLE `short_link` (
`distributed_id` BIGINT UNSIGNED NOT NULL COMMENT '分布式ID',
`long_url` VARCHAR(2048) NOT NULL,
`short_code` VARCHAR(10) NOT NULL UNIQUE,
`created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
`expires_at` TIMESTAMP NULL,
`user_id` BIGINT UNSIGNED,
`effective_days` INT UNSIGNED COMMENT '有效天数',
PRIMARY KEY (`distributed_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
上面数据库表的分布式ID有什么用?别急是这样的,每条长链的长短不同、格式不同、组成不同,我们很难保证所有短链生成出来的短链长度、格式一致!
可以这样取巧,每条唯一的长链在进行数据库物理存储时,都会被分配一个唯一的分布式ID。咱们不是根据长链来生成短链,而是根据这个分布式ID来生成短链。
分布式ID由数字组成,把长数字转换为短链,这个技术我们使用MurmurHash非加密型哈希函数算法,当然可选的技术有Base62编码。
南哥给出它们之间的区别。
| 特性 | MurmurHash | Base62 |
|---|---|---|
| 用途 | 数据映射到固定长度的哈希值 | 数据编码为短字符串 |
| 是否可逆 | 不可逆 | 可逆 |
| 输出格式 | 固定长度的整数或字节 | 可变长度的字符串 |
| 字符集 | 无特定字符集限制 | 0-9, a-z, A-Z |
| 分布性 | 分布均匀,减少哈希冲突 | 无分布均匀性,字符分布取决于输入 |
| 安全性 | 无安全性,非加密 | 无安全性,非加密 |
| 典型应用 | 哈希表、数据分片、数据校验 | URL 短链接、UUID 编码、序列号生成 |
我们需要保证生成的短链具有唯一性,基于这样的需求,咱们采用第一种MurmurHash来确保生成的hash分布均匀且哈希冲突更少,同时会把该结果进行编码转换为链接字符串。
java 代码解读复制代码// 使用MurmurHash转换长链
public class ShortLinkService {
private static final String BASE_URL = "http://short.url/";
public String generateShortLink(String longUrl) {
// 生成分布式ID
long id = saveLongUrl(longUrl);
// 使用MurmurHash生成短链
int hash = MurmurHash3.hash32(id);
String shortCode = Integer.toString(hash, 36); // Base36编码以生成短链
return BASE_URL + shortCode;
}
}
但是!!如果你只回答了上面这一步,那我认为这道题你只能得35分,一个系统不仅仅只要保证基础功能。。。
1.2 稳定性设计
(1)缓存加速读取
稳定性在这套系统设计题的体现是流量高峰期间的一个并发能力,
相对通用且常见的缓存方案,实际上来来去去就那么一套,但各个公司使用的基础架构不同、服务器架构不同,最稳妥是要基于公司实际的架构情况做出最合适当前需求的方案。
南哥在上文有提到把短链、长链的一对一关系存储到Redis,通过Redis缓存技术可以提高访问短链的速度,另外只有热门的短链才有这个待遇,其他非热门短链走下面的流程。
短链系统有 N 个微服务节点,我们在每隔微服务节点都设置了本地缓存,那本地缓存的目标对象是哪些?
我们无需像热门短链一样配置在Redis,这里使用 LRU 算法,下面介绍下。
LRU 算法即最近最少使用算法,为本地缓存设置最大容量,当缓存容量达到阈值时,该算法会把最久没有访问的内容作为替换对象从缓存中删除。保证本地缓存的对象是相对访问量高的短链。
如果一个短链、长链的对应关系需要100字节存储,那 10 MB 本地缓存可以存储 10 w 个长短链对应关系。
java 代码解读复制代码// LRU算法使用
public class LRU {
public static void main(String[] args) {
LRUMap map = new LRUMap(3);
map.put(0, 0);
map.put(1, 1);
map.put(2, 2);
System.out.println(map);
map.get(0);
System.out.println(map);
map.put(3, 3);
System.out.println(map);
}
private static class LRUMap extends LinkedHashMap {
private int max;
public LRUMap(int max) {
// accessOrder设置true时,把该get的元素放到队尾
super((int) (max * 1.4f), 1.75f, true);
this.max = max;
}
// 容量满时,删除队首元素
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > max;
}
}
}
shell 代码解读复制代码# 执行结果
{0=0, 1=1, 2=2}
{1=1, 2=2, 0=0}
{2=2, 0=0, 3=3} // 删除了最近最少使用的队首元素1
(2)异步消息实现削峰
短链系统对于用户来说,主要就两个请求。一个是把长链生成短链,另一个是访问短链重定向到长链地址。上文的缓存方案服务的是第二种用户请求,下面我们针对第一种用户请求加上并发支持。
南哥先画出这部分的抽象图。
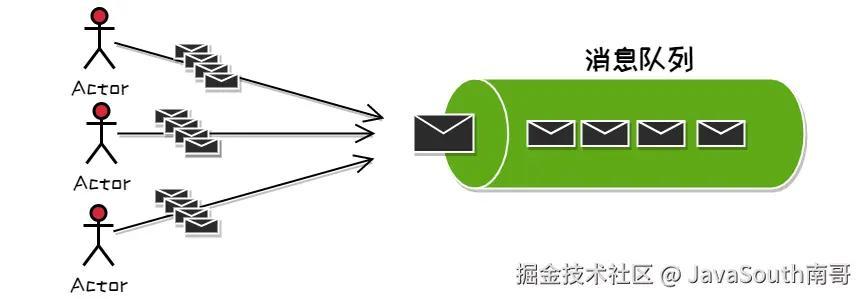
用户把长链转换请求到短链系统,我们把每一次请求看成一个个消息队列消息,上传到消息队列Kafka中。这里消息队列起到一个流量削峰的作用。
大家可以思考下,如果没有消息队列把一个个任务先缓存起来,而是任由每秒几千 / 上万个请求直接冲击服务器,这很有可能造成服务器崩溃。而队列任务一个个执行则减少了一瞬间需要处理的 N 个任务个数,减少服务器瞬时压力。
但是!!如果你只回答了上面两步,那我认为这道题你只能得70分,一个系统要完善不仅仅需要完成基础功能、保证系统稳定性,还需要保证系统的安全性!
1.3 安全性设计
我们从两方面来考虑安全性的问题:生成短链如何保证安全?访问短链如何保证安全?
一、生成短链
(1)防止用户上传带有敏感性、不合法的链接,我们需要对长链的原始URL进行合法性的检测,如果是非法的链接直接拒绝服务。
java 代码解读复制代码// 原始URL合法性检测
public class UrlValidator {
public boolean isValidUrl(String url) {
...
}
}
(2)防止用户滥用短链生成服务,我们需要对用户每天的可用次数进行限制。
可以根据用户ID查询用户每天生成短链的次数,限制用户生成短链次数;当然用户很聪明,会制造多个小号,我们对同一IP生成短链的频率也加上限制。
使用Nginx对同一IP生成短链的频率进行限制。
shell 代码解读复制代码# Nginx对同一IP生成短链的频率限制
http {
limit_req_zone $binary_remote_addr zone=shortlink_limit:10m rate=1r/s;
server {
listen 80;
location /generate {
limit_req zone=shortlink_limit burst=5 nodelay;
proxy_pass http://your_backend_service;
}
}
}
二、访问短链
为了防止短链访问被滥用,我们可以为每条短链设置每小时可访问的次数;同时每一条短链与长链的对应关系具有时效性,过期了需要重新生成短链。
我是南哥,南就南在Get到你的点赞点赞点赞。

看了就赞,Java进阶一大半。点赞 | 收藏 | 关注,各位的支持就是我创作的最大动力❤️
评论记录:
回复评论: