
最近在边缘部署的单机 K8s 环境中出现了间歇性的 DNS 解析失败,服务跑一段时间就出现了。问题的原因之前没有出现过,因此做了一个记录。
部署架构
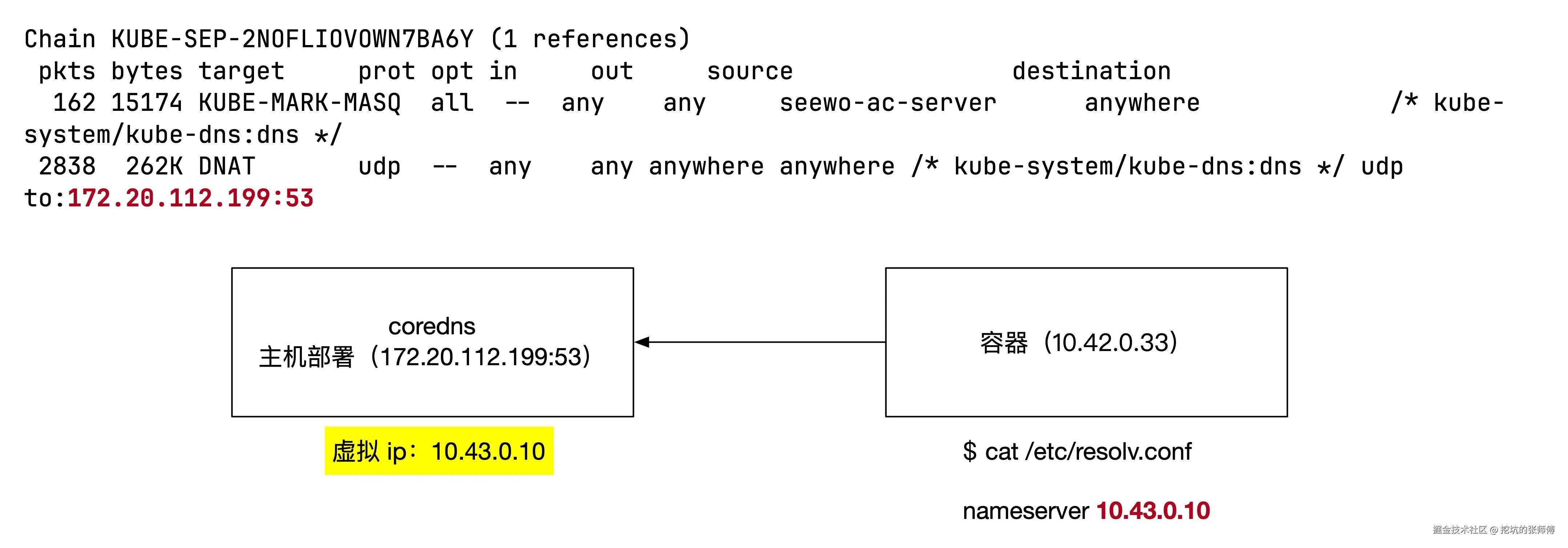
- 单节点 Kubernetes 集群
- CoreDNS 以主机网络模式运行
- 通过 iptables 规则将 DNS 查询请求转发至虚拟 IP (10.43.0.10:53)
问题现象
在排查过程中发现了一个有趣的现象:
- 正常解析场景:使用 dig 命令手动发送 DNS 查询包均能获得正确响应
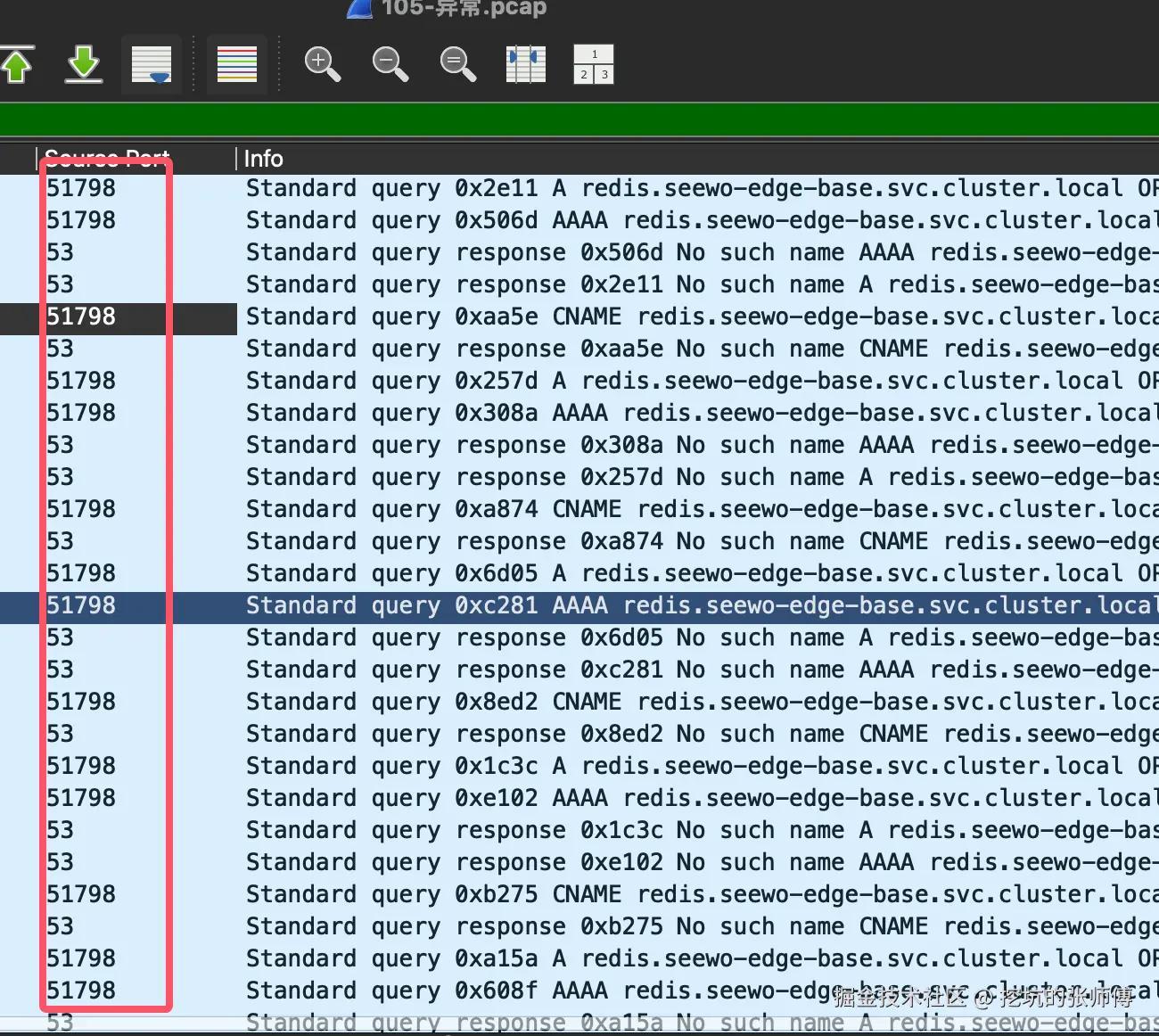
- 异常解析场景:Redisson 客户端的 DNSMonitor 代码(基于 Netty 实现)每 5 秒进行的域名解析会出现失败(用来判断 DNS 解析是否失效)

将 Netty 发送的 DNS 数据包保存下来,使用 nc 工具重放相同的 payload 能够成功获得响应。测试命令如下:
代码解读复制代码nc -u 10.43.0.10 53 < dns_pkt
这就有点奇怪了,几乎所有的条件都一致。后面发现一个奇怪的地方,出问题的时候,在 DNS 解析失败的情况下,Netty 客户端始终使用同一个源端口进行 DNS 查询。这个特征与正常情况下应该随机选择源端口的行为不符。
通过检查 conntrack NAT 表项,conntrack 表项的反向 SRC 和 DST 地址都是不符合预期的(后面会分析),又由于 Redisson 的 DNSMonitor 组件配置了 5 秒的监控间隔,这导致:DNS 查询请求每 5 秒发送一次 UDP,conntrack 表项的默认过期时间为 30 秒,频繁的 DNS 查询导致 conntrack 表项无法正常老化和更新。
css 代码解读复制代码udp 17 173 src=10.42.0.129 dst=10.43.0.10 sport=52421 dport=53 src=10.43.0.10 dst=172.20.112.199 sport=53 dport=52421 [ASSURED] mark=0 use=1
当我手动把这个记录删除时,解析立马可以恢复正常。
为什么 conntrack 记录会跑着跑着就不对了。我写了一个脚本监控 conntrack 异常记录出现的时间,
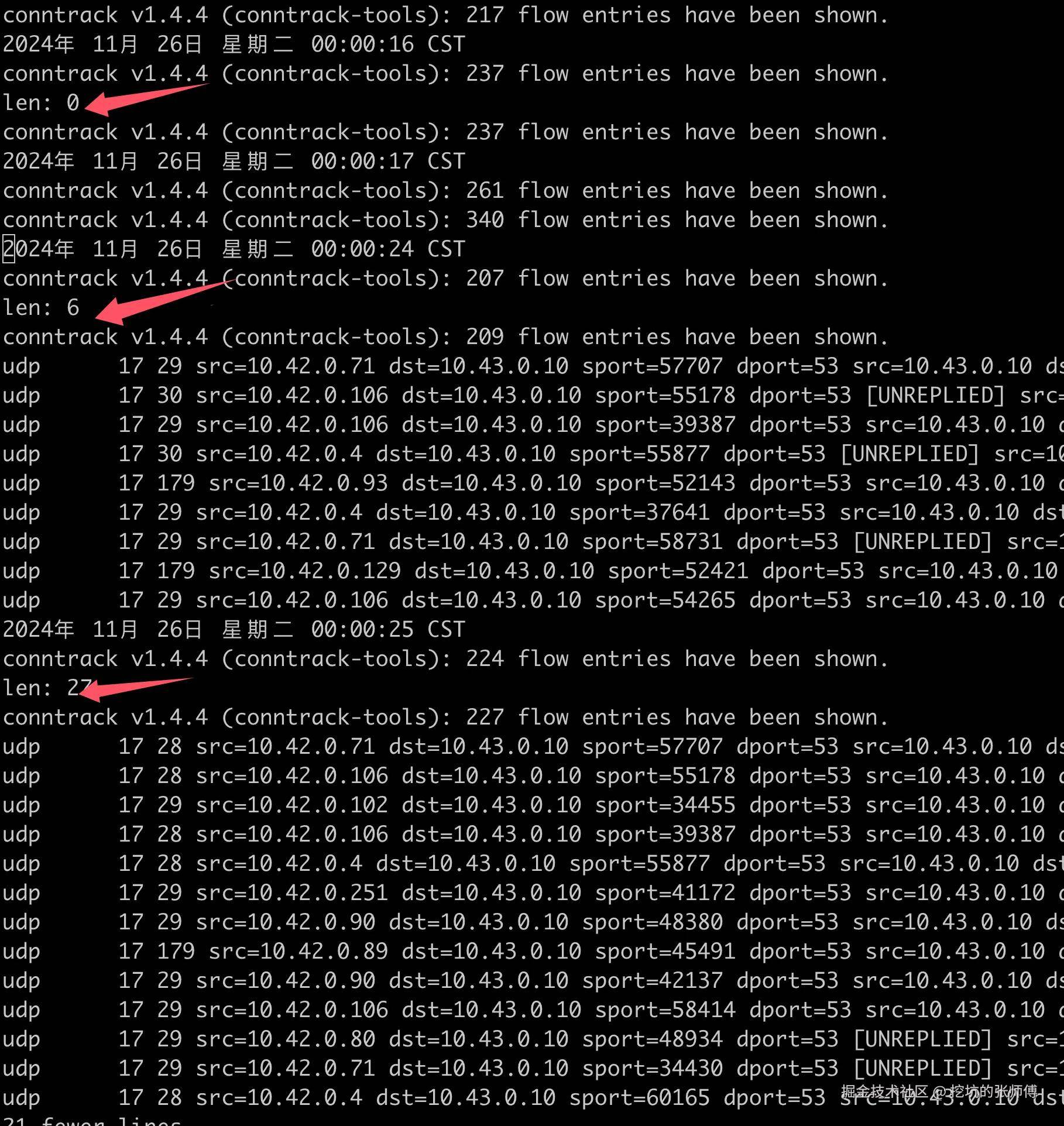
DNS 解析异常与凌晨的定时任务存在关联。运维定时任务导致 CoreDNS 发生非预期的每日重启。
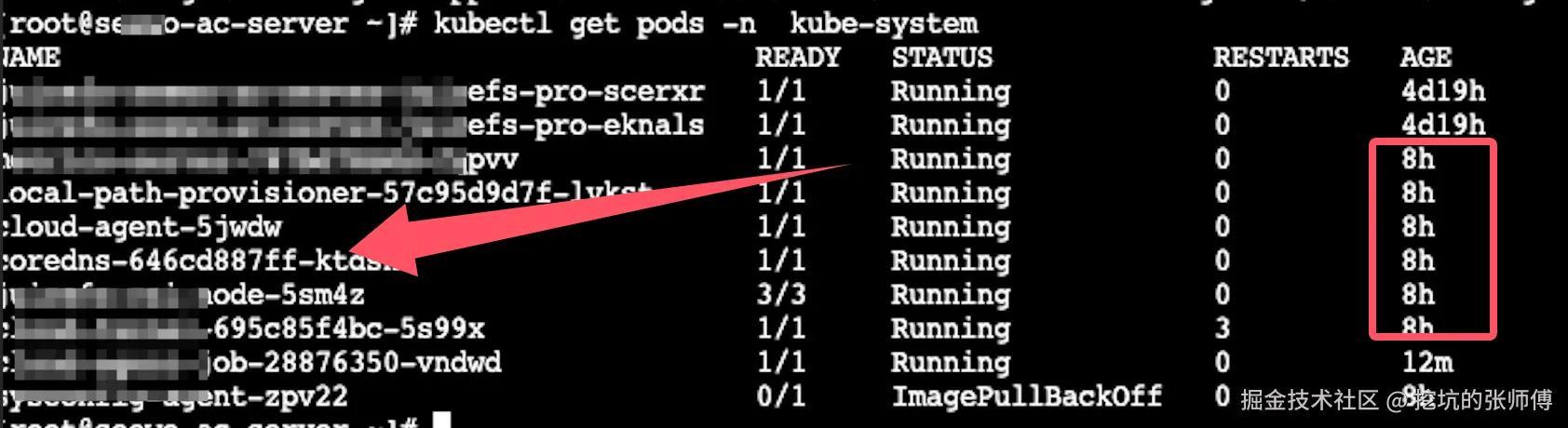
为什么 coredns 重启会导致 conntrack 异常
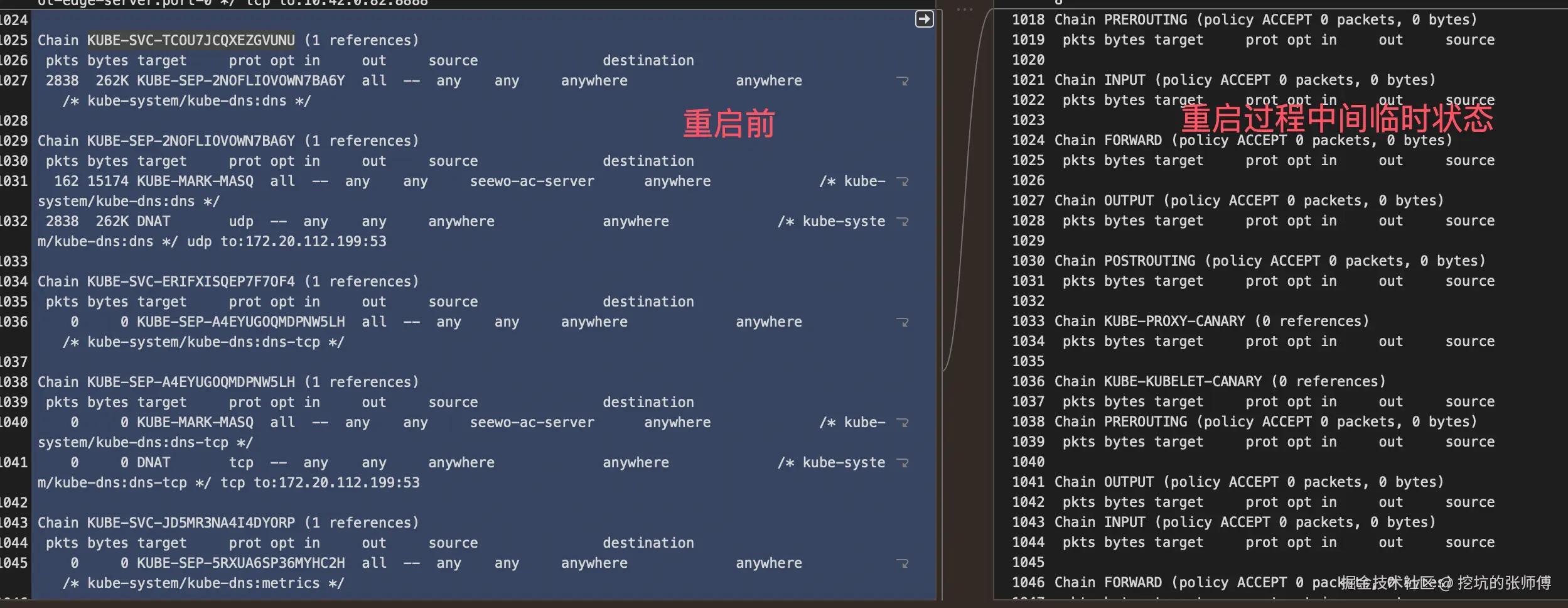
在 CoreDNS 重启过程中会出现一个临时状态,NAT 规则变更:
- CoreDNS Pod 终止时,相关的 NAT 规则会被删除
- 新的 CoreDNS Pod 启动后,会重新添加 NAT 规则
在 NAT 规则被删除到重新添加的这段时间内,如果容器与 CoreDNS(10.43.0.10)发生通信,由于特定的 NAT 规则缺失,流量会被错误地导向默认 NAT 规则处理。
我做了一个重启期间的 iptable 的 NAT 表变化记录,重启操作前的 iptables 的 NAT 表规则:
sql 代码解读复制代码Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
2838 262K KUBE-SVC-TCOU7JCQXEZGVUNU udp -- any any anywhere 10.43.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain
0 0 KUBE-NODEPORTS all -- any any anywhere anywhere /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
Chain KUBE-SVC-TCOU7JCQXEZGVUNU (1 references)
pkts bytes target prot opt in out source destination
2838 262K KUBE-SEP-2NOFLIOVOWN7BA6Y all -- any any anywhere anywhere /* kube-system/kube-dns:dns */
Chain KUBE-SEP-2NOFLIOVOWN7BA6Y (1 references)
pkts bytes target prot opt in out source destination
162 15174 KUBE-MARK-MASQ all -- any any seewo-ac-server anywhere /* kube-system/kube-dns:dns */
2838 262K DNAT udp -- any any anywhere anywhere /* kube-system/kube-dns:dns */ udp to:172.20.112.199:53
在重启过程中,这几条规则被删除了。
conntrack 前后对比如下:
css 代码解读复制代码$ conntrack -L
# 异常
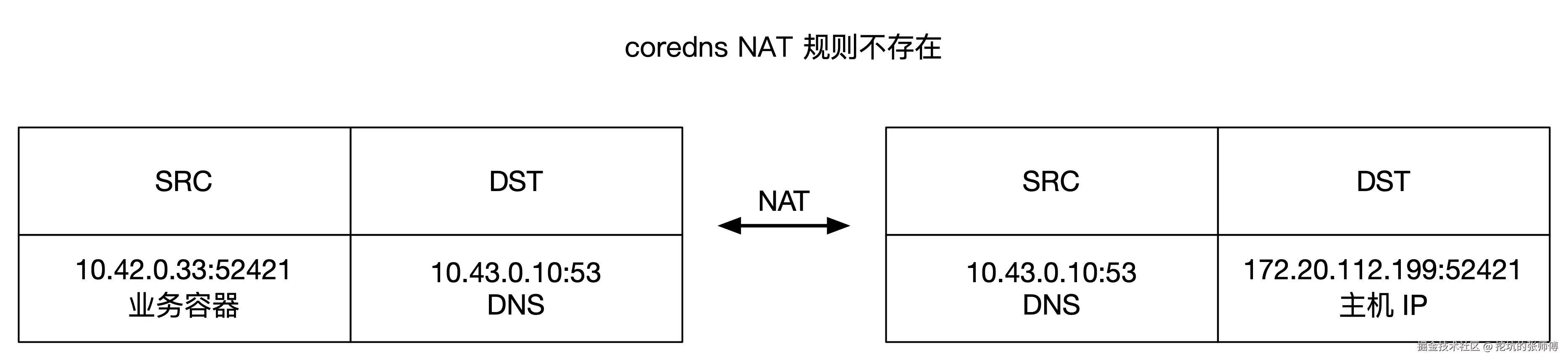
udp 17 177 src=10.42.0.33 dst=10.43.0.10 sport=52421 dport=53 src=10.43.0.10 dst=172.20.112.199 sport=53 dport=52421 [ASSURED] mark=0 use=1
# 正常
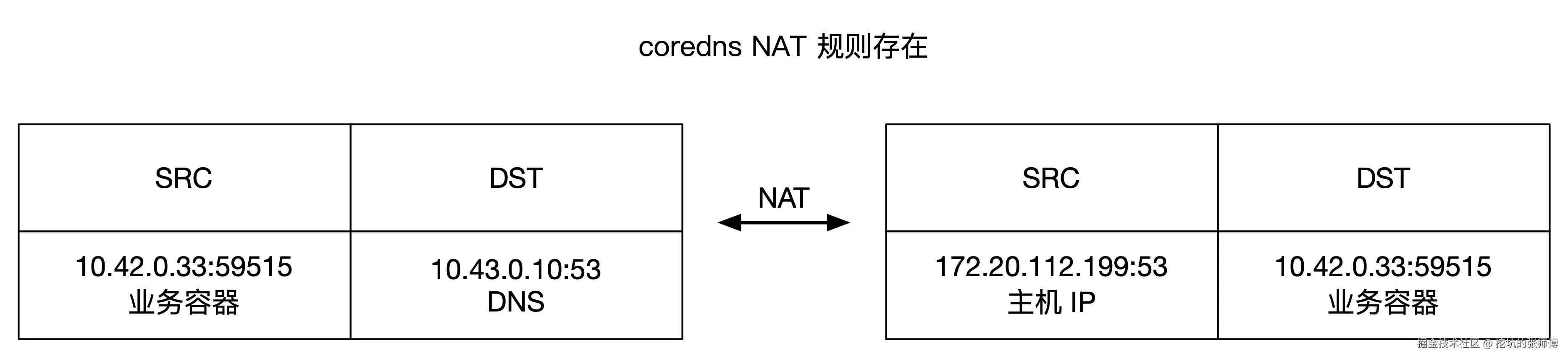
udp 17 28 src=10.42.0.33 dst=10.43.0.10 sport=59515 dport=53 src=172.20.112.199 dst=10.42.0.33 sport=53 dport=59515 mark=0 use=1
NAT 规则不存在时:
当 NAT 规则存在时:
错误的 NAT 规则会导致 conntrack 表项记录异常,这些异常的 conntrack 记录会持续存在,直到 UDP conntrack 表项自然过期(默认 30 秒),影响后续的 DNS 查询请求的正常处理。
如何复现
写一段 Go 程序,使用同一个端口,不停的与 10.43.0.10 的 53 端口通信
go 代码解读复制代码package main
import (
"fmt"
"github.com/miekg/dns"
"net"
"os"
"strconv"
"time"
)
const DnsAddr = "10.43.0.10:53"
func main() {
if len(os.Args) < 2 {
fmt.Println("Please provide domain name")
return
}
domain := os.Args[1]
sleepTime := 1000
if len(os.Args) > 2 {
if t, err := strconv.Atoi(os.Args[2]); err == nil {
sleepTime = t
}
}
fmt.Printf("dns_fk!, dns: %s, domain: %s, sleep: %dms\n", DnsAddr, domain, sleepTime)
conn, err := net.ListenUDP("udp", &net.UDPAddr{IP: net.IPv4zero, Port: 52001})
if err != nil {
fmt.Printf("Failed to bind: %v\n", err)
return
}
defer conn.Close()
dnsAddr, err := net.ResolveUDPAddr("udp", DnsAddr)
if err != nil {
fmt.Printf("Failed to resolve DNS address: %v\n", err)
return
}
packet := buildDNSPacket(domain)
count := 0
lastPrint := time.Now()
for {
count++
if time.Since(lastPrint) > 3*time.Second {
fmt.Printf("send count: %d\n", count)
lastPrint = time.Now()
}
_, err := conn.WriteToUDP(packet, dnsAddr)
if err != nil {
fmt.Printf("Failed to send packet: %v\n", err)
continue
}
if sleepTime > 0 {
time.Sleep(time.Duration(sleepTime) * time.Millisecond)
}
}
}
func buildDNSPacket(domain string) []byte {
m := new(dns.Msg)
m.SetQuestion(dns.Fqdn(domain), dns.TypeA)
m.RecursionDesired = false
m.Id = dns.Id()
data, _ := m.Pack()
return data
}
bash代码解读复制代码./udp_fk rocketmq-nameserver.xeewo-edge-base.svc.cluster.local 10
此时会创建一条 conntrack 记录
css 代码解读复制代码$ conntrack -E -s 10.42.0.33 -p udp
[NEW] udp 17 30 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 [UNREPLIED] src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001
[UPDATE] udp 17 30 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001
[UPDATE] udp 17 120 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001 [ASSURED]
然后重启 coredns
perl 代码解读复制代码kubectl delete pod coredns-65b5854f7-lkwlf -n kube-system
观察 conntrack 变化过程:
scss 代码解读复制代码$ conntrack -E -s 10.42.0.33 -p udp
// 重启前
[NEW] udp 17 30 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53
[UNREPLIED] src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001
[UPDATE] udp 17 30 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001
[UPDATE] udp 17 120 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001 [ASSURED]
// 重启后
// 旧的 conntrack 记录被删除
[DESTROY] udp 17 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 src=172.20.112.199 dst=10.42.0.33 sport=53 dport=52001 [ASSURED]
// 新增了一条新的 conntrack 记录(异常)
[NEW] udp 17 30 src=10.42.0.33 dst=10.43.0.10 sport=52001 dport=53 [UNREPLIED] src=10.43.0.10 dst=172.20.112.199 sport=53 dport=42285
通过抓包就可以发现,此时的 DNS 通信就是失败的。
k8s 的问题?
事后,经过查看 k8s 的 issue,还真这是一个老 bug 了(kube-proxy/iptables, client continuous to send packets, udp server pod restart cause UDP conntrack entry error )链接地址 github.com/kubernetes/…
k8s 的新版本可以缓解这一问题。
修复
k8s 版本是升不动的,改业务代码倒是比较容易,本质问题是 redisson 的 DNSMonitor 特性,目前看是使用同一个 UDP 端口去查询 DNS,解决一下就可以了,具体的措施就不展开。
小结
这次问题出现有两个条件:
- coredns 每天定期重启,加速了问题的出现
- redisson 使用固定的端口,持续的请求 coredns,导致错误的 conntrack 记录无法过期清理
正经人谁用 redisson。。。
评论记录:
回复评论: