
本书的第三部分重点介绍 Cube 管理器组件。工作节点负责在节点池中单个节点上运行各个任务,而管理器则负责管理整个系统。管理器的职责包括:
-
响应用户的请求;
-
在工作节点上调度任务;
-
定期收集系统中任务和工作节点的状态信息;
-
检查正在运行的任务的健康状况,并在出现问题时尝试使它们恢复到正常状态。
在第 7 章中,我们将详细阐述 Manager 对象的实现细节。这一实现将包括一个简单的调度器,我们会在后续章节中对其进行改进。
在第 8 章中,我们将为 Manager 对象构建一个 API。这个 API 将成为用户与 Cube 进行交互的机制。
在第 9 章中,我们将探讨一些常见的故障场景,并考虑处理这些场景的方案。然后我们将实现一个处理任务故障的解决方案。
7 管理器登场
本章涵盖以下内容:
-
回顾管理器的作用
-
设计一个简单的调度算法
-
实现管理器用于调度和更新任务的方法
在第 4、5 和 6 章中,我们实现了编排系统 Cube 的工作节点组件。在第 4 章中,我们专注于工作节点的核心功能,使其能够启动和停止任务。第 5 章中,我们为工作节点添加了一个 API。这个 API 封装了我们在第 4 章中构建的功能,并使得标准 HTTP 客户端(例如 curl)能够使用这些功能。最后,在第 6 章中,我们让工作节点具备了收集自身相关指标的能力,并通过同一个 API 将这些指标公开出来。通过这些工作,我们可以运行多个工作节点,每个工作节点又能运行多个任务。
现在,我们将注意力转移到 Cube 的管理器组件上。正如我们在第 1 章中提到的,管理器是编排器的核心。虽然我们有多个工作节点,但我们并不希望让编排系统的用户直接将任务提交给某个工作节点。为什么呢?这会给用户带来不必要的负担,迫使他们了解系统中存在多少个工作节点,这些节点已经运行了多少任务,然后再从中选择一个。相反,我们将所有这些管理工作封装到管理器中。用户将任务提交给管理器,然后由管理器来确定系统中的哪个工作节点最适合处理该任务。
与工作节点不同,Cube 编排器只有一个管理器。这是一个实用的设计决策,旨在简化我们在实现管理器时需要考虑的问题数量。
在本章结束时,我们将实现一个管理器,它能够使用一种简单的轮询调度算法将任务提交给工作节点。
7.1 Cube 管理器
管理器组件使我们能够将管理方面的事务与执行方面的事务分离开来。这是一种被称为 “关注点分离” 的设计原则。在编排系统中(图 7.1),管理方面的事务包括以下内容:
- 处理来自用户的请求;
- 将任务分配给最有能力执行它们的工作节点(即调度);
- 跟踪任务和工作节点的状态;
- 重启失败的任务。
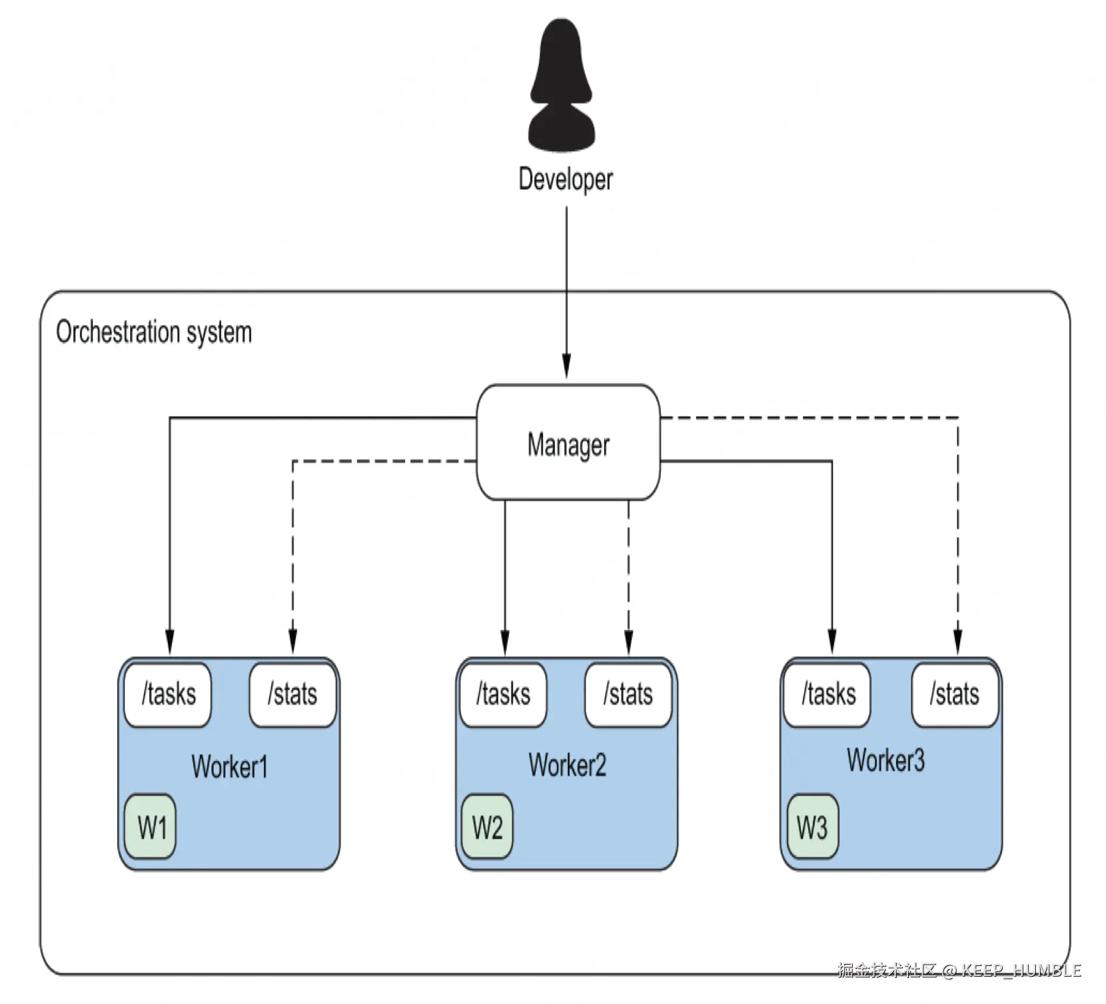
图 7.1 管理器负责管理任务,这就好比餐厅领座员安排顾客座位的职能。它将利用工作节点的 /tasks 和 /stats API 端点来履行其管理职责。
每个编排系统都有一个管理器组件。谷歌的 Borg 系统将其称为 “BorgMaster”。HashiCorp 的 Nomad 使用了一个虽然缺乏想象力但很实用的术语 “server(服务器)” 来指代它。Kubernetes 并没有为这个组件起一个单一的名称,而是专门标识出了其各个子组件(如 API 服务器、控制器管理器、etcd、调度器等)。
控制平面与数据平面
理解关注点分离的另一种方式是控制平面与数据平面的概念。在网络领域中,你会经常看到这些术语,它们指的是不同的存在层面。
在一个网络中,控制平面控制数据如何从 A 点移动到 B 点。这个平面负责诸如创建路由表之类的工作,而路由表是由不同的协议来确定的,比如边界网关协议(BGP)和开放式最短路径优先协议(OSPF)。这个平面所执行的功能类似于我们管理器的管理职责。
与控制平面不同,数据平面承担着实际的数据传输工作。这个平面所执行的功能类似于我们工作节点的执行职责。
7.1.1 组成管理器的组件
和我们的工作节点一样,我们的管理器将由几个子组件构成,如图 7.2 所示。管理器将有一个任务数据库(Task DB),和工作节点一样,它将用于存储任务。然而,与工作节点的任务数据库不同的是,管理器的任务数据库将包含系统中的所有任务。
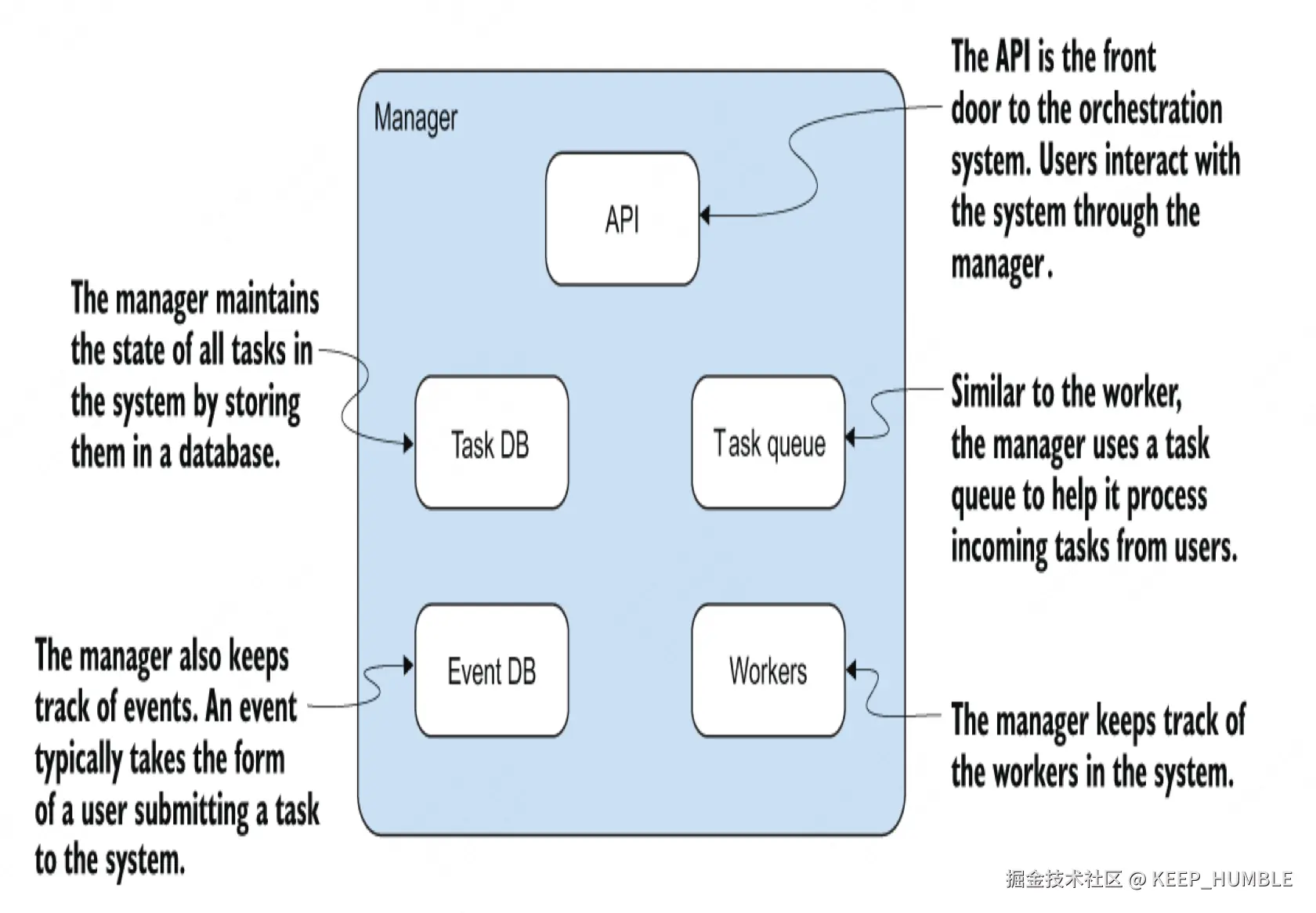
图 7.2 管理器的组件与工作节点的组件类似,只是额外增加了一个事件数据库(Event DB)和一个工作节点列表。
管理器还将有一个事件数据库(Event DB),用于存储事件(即 task.TaskEvent)。这个子组件主要是为了方便我们将元数据与特定于任务的数据分开。元数据包括诸如用户向系统提交任务的时间戳等信息。在第 12 章为管理器实现命令行界面(CLI)时,我们会用到这些元数据。
和工作节点一样,对于管理器的初始实现,我们将使用内存中的映射(in-memory map)来存储任务和事件。管理器的 Workers 子组件是它所管理的工作节点的列表。和工作节点一样,它也将有一个任务队列(Task Queue)。最后,管理器将有一个类似于工作节点的 API(图 7.2)。(就像我们处理工作节点的 API 那样,我们将在单独的一章中讨论管理器的 API,所以在此之前我们暂不深入探讨它。)
有了这个基础,我们就可以继续进行实现工作了。
7.2 管理器结构体
和工作节点一样,我们在第 2 章中创建了管理器实现的框架。这个管理器框架的核心是 Manager 结构体,它将包含一些字段,这些字段代表了我们之前确定的各个子组件。你可以在清单 7.1 中看到这个结构体,它应该和我们在第 2 章留下的状态相同。
由于已经过去了一段时间,让我们来回顾一下对管理器的要求。在第 1 章中,我们确定了这些要求:
-
接受用户启动和停止任务的请求;
-
将任务调度到工作节点机器上;
-
跟踪任务、任务的状态以及任务运行所在的机器。
如果你需要更多关于 Manager 结构体及其字段的提示,请回顾 2.3 节的内容。
code 7.1 The Manager struct
go 代码解读复制代码package manager
type Manager struct {
Pending queue.Queue
TaskDb map[uuid.UUID]*task.Task
EventDb map[uuid.UUID]*task.TaskEvent
Workers []string
WorkerTaskMap map[string][]uuid.UUID
TaskWorkerMap map[uuid.UUID]string
}
我们将按以下顺序实现这些方法:
- SelectWorker
- SendWork
- UpdateTasks
7.3.1 实现 SelectWorker 方法
在实现我们管理器的早期阶段,SelectWorker 方法将充当调度器。它的唯一目的是从管理器的工作节点列表(即 Workers 字段,它是一个字符串切片)中选择一个工作节点。我们将从一个简单的轮询调度算法开始,该算法首先简单地从 Workers 列表中选择第一个工作节点,并将其存储在一个变量中。从这一点开始,该算法如下:
-
检查我们是否处于
Workers列表的末尾。 -
如果不是,选择列表中的下一个工作节点。
-
否则,返回到开头并选择列表中的第一个工作节点。
为了实现这个算法,我们需要对 Manager 结构体进行一个小的改动。正如你在下面的清单中看到的,我们添加了 LastWorker 字段。我们将使用这个字段来存储一个整数,该整数将作为 Workers 切片的索引,从而让我们得到一个工作节点。
code 7.3 Adding the LastWorker field to the Manager struct
go 代码解读复制代码type Manager struct {
...
LastWorker int
}
现在让我们来看一下实际的调度算法。正如你在清单 7.4 中所看到的,它只有九行代码(不包括方法签名)。我们首先声明变量 newWorker,它代表被选中来运行任务的幸运工作节点。然后我们使用一个 if/else 代码块来选择工作节点。在这个代码块中,我们首先检查在上一次运行时选择的工作节点是否是我们工作节点列表中的最后一个。如果不是,我们就将 newWorker 设置为工作节点列表中的下一个工作节点,并将 LastWorker 的值加 1。如果之前选择的工作节点是列表中的最后一个,我们就从头开始,选择列表中的第一个工作节点,并相应地设置 LastWorker 的值。最后,我们将选择的工作节点返回给调用者。
code 7.4 Implementing a naive scheduling algorithm
go 代码解读复制代码func (m *Manger) SelectWorker() string {
var newWorker int
if m.LastWorker+1 < len(m.Workers) {
newWorker = m.LastWorker+1
m.LastWorker++
} else {
newWorker = 0
m.LastWorker = 0
}
return m.Workers[newWorker]
}
有必要花点时间来谈谈存储在管理器 Workers 字段中的字符串格式。该字段本身是 []string 类型,从技术上讲,这些字符串的值可以是任何内容。然而在实际应用中,它们将采用 <主机名>:<端口> 的形式。如果你还记得在第 5 章和第 6 章中,当我们启动工作节点的 API 时,我们指定了 CUBE_HOST 和 CUBE_PORT 环境变量。我们将前者设置为 localhost,后者设置为 5555。所以管理器的 Workers 字段包含一个 <主机名>:<端口> 值的列表,这些值指定了工作节点 API 运行的地址。
code 7.5 The manager's SendWork method
go 代码解读复制代码func (m *Manager) SendWork() {
if m.Pending().Len() > 0 {
w := m.SelectWorker()
e := m.Pending.Dequeue()
te := e.(task.TaskEvent)
t := te.Task
log.Printf("Pulled %v off pending queue\n", t)
m.EventDb[te.ID] = &te
m.WorkerTaskMap[w] = append(m.WorkerTaskMap[w], te.Task.ID)
m.TaskWorkerMap[t.ID] = w
t.State = task.Scheduled
m.TaskDb[t.ID] = &t
data, err := json.Marshal(te)
if err != nil {
log.Printf("Unable to marshal task object: %v.\n", t)
}
...
}
}
一旦 SendWork 方法从 Pending 队列中取出一个任务并将其编码为 JSON 格式,剩下要做的就是将该任务发送给选定的工作节点。这最后两个步骤在清单 7.6 中实现。将任务发送给工作节点需要使用工作节点的主机名和端口来构建 URL,这些信息是我们之前调用管理器的 SelectWorker 方法时获取到的。从这开始,我们使用标准库 net/http 包中的 Post 函数。然后我们对响应体进行解码并打印出来。请注意,我们在这个过程中也会检查是否有错误。
code 7.6 The final two steps of the SendWork method
go 代码解读复制代码 url := fmt.Sprintf("http://%s/tasks", w)
resp, err := http.Post(url, "application/json", bytes.NewBuffer(data))
if err != nil {
log.Printf("Error connection to %v: %v\n", w, err)
m.Pending.Enqueue(te)
return
}
d := json.NewDecoder(resp.Body)
if resp.StatusCode != http.StatusCreated {
e := worker.ErrResponse{}
err := d.Decode(&e)
if err != nil {
fmt.Printf("Error decoding response: %s\n", err.Error())
return
}
log.Printf("Response error (%d): %s", e.HTTPStatusCode, e.Message)
return
}
t = task.Task{}
err = d.Decode(&t)
if err != nil {
fmt.Printf("Error decoding response: %s\n", err.Error())
return
}
log.Printf("%#v\n", t)
} else {
log.Println("No work in the queue")
}
}
从这段代码中你可以看到,管理器正通过我们在第 5 章中实现的工作节点 API 与工作节点进行交互。
7.3.3 实现 UpdateTasks 方法
目前,我们的管理器能够选择一个工作节点来运行任务,然后将该任务发送给选定的工作节点。它还将任务存储在了其任务数据库(TaskDB)和事件数据库(EventsDB)中。但管理器对任务的了解仅基于自身视角。诚然,它把任务发送给了工作节点,并且如果一切顺利,工作节点会返回 http.StatusCreated(即 201)状态码。然而,即便我们收到了 http.StatusCreated 响应,这也仅仅表明工作节点接收到了任务并将其添加到了自己的队列中。这个响应并不能说明任务已成功启动且正在运行。你可能会问,任务怎么会失败呢?以下是几种可能的情况:
-
用户指定了一个不存在的 Docker 镜像,这样当工作节点尝试启动任务时,Docker 会报错称找不到该镜像。
-
工作节点的磁盘已满,没有足够空间下载 Docker 镜像。
-
Docker 容器内运行的应用程序存在 bug,导致其无法正确启动(也许容器镜像的创建者遗漏了应用程序正常启动所需的某个重要环境变量)。
这些只是任务可能失败的几种情况。虽然管理器不一定需要了解任务可能失败的每一种情况,但它需要做的是定期与工作节点沟通,获取正在运行任务的状态更新。此外,管理器需要获取集群中每个工作节点的状态更新。考虑到这些,我们来实现管理器的 UpdateTasks 方法。
从每个工作节点更新任务状态的大致流程很简单。对于每个工作节点,我们执行以下步骤:
-
向工作节点查询其任务列表。
-
对于每个任务,更新管理器数据库中该任务的状态,使其与工作节点中的状态一致。
第一步可以参考清单 7.7。到这时候你应该对其感到熟悉了。管理器首先使用 net/http 包中的 Get 方法向工作节点发送一个 GET /tasks 的 HTTP 请求。它会检查是否有错误,比如连接问题(也许工作节点出于某种原因停机了)。如果管理器能够连接到工作节点,它会检查响应状态码,确保收到的是 http.StatusOK(即 200)状态码。最后,它会对响应体中的 JSON 数据进行解码,这应该会得到工作节点的任务列表。
code 7.7 Step 1 of the process to update the manager's tasks
go 代码解读复制代码func (m *Manager) UpdateTasks() {
for _, worker := range m.Workers {
log.Printf("Checking worker %v for task updates", worker)
url := fmt.Sprintf("http://%s/tasks", worker)
resp, err := http.Get(url)
if err != nil {
log.Printf("Error connection to %v: %v\n", worker, err)
}
if resp.StatusCode != http.StatusOK {
log.Printf("Error sending request: %v\n", err)
}
d := json.NewDecoder(resp.Body)
var tasks []*task.Task
err = d.Decode(&tasks)
if err != nil {
log.Printf("Error unmarshalling tasks: %s\n", err.Error())
}
}
}
第二步如清单 7.8 所示,它在清单 7.7 的主 for 循环中执行。我们更新任务的方式并没有什么特别复杂或巧妙之处。首先,我们会检查管理器中任务的状态是否与工作节点中的状态相同;如果不同,我们就将管理器中任务的状态设置为工作节点所报告的状态(通过这种方式,管理器将工作节点视为 “全局状态” 的权威来源,也就是系统中任务的当前状态)。一旦更新了任务的状态,我们接着会更新其开始时间(StartTime)和结束时间(FinishTime)。最后,我们会更新任务的容器 ID(ContainerID)。
code 7.8 Step 2 of the process to update the manager's tasks
go 代码解读复制代码 for _, t := range tasks {
_, ok := m.TaskDb[t.ID]
if !ok {
log.Printf("Task with ID %s not found\n", t.ID)
return
}
if m.TaskDb[t.ID].State != t.State {
m.TaskDb[t.ID].State = t.State
}
m.TaskDb[t.ID].StartTime = t.StartTime
m.TaskDb[t.ID].FinishTime = t.FinishTime
m.TaskDb[t.ID].ContainerID = t.ContainerID
}
随着 UpdateTasks 方法的实现,我们现在已经完成了管理器的核心功能。在继续之前,让我们快速总结一下到目前为止所取得的成果:
-
通过
SelectWorker方法,我们实现了一个简单但较为初级的调度算法,用于将任务分配给工作节点。 -
通过
SendWork方法,我们实现了一个流程,该流程使用SelectWorker方法,并通过工作节点的 API 将单个任务发送给已分配的工作节点。 -
通过
UpdateTasks方法,我们实现了一个流程,使得管理器能够更新其对系统中所有任务状态的认知。
我们刚刚完成了大量的工作。在进入下一部分之前,花点时间庆祝一下你的成就吧!
7.3.4 向管理器添加任务
虽然我们已经实现了管理器的核心功能,但仍有几个方法需要实现。其中第一个方法是 AddTask 方法,如清单 7.9 所示。这个方法看起来应该很眼熟,因为它和我们为工作节点创建的 AddTask 方法类似。它的用途也相似:该方法用于将任务添加到管理器的队列中。
code 7.9 The manager's AddTask method
go 代码解读复制代码func (m *Manager) AddTask(te task.TaskEvent) {
m.Pending.Enqueue(te)
}
7.3.5 创建管理器
最后,让我们来创建 New 函数,如清单 7.10 所示。这是一个辅助函数,它接收一个工作节点列表,创建一个管理器实例,并返回指向该实例的指针。此函数的主要工作是初始化管理器所需的各个子组件。它会设置 taskDB 和 eventDb 数据库。接着,它会初始化 workerTaskMap 和 taskWorkerMap 这两个映射,这些映射能帮助管理器更轻松地确定任务的运行位置。虽然从技术上来说,这个函数不叫构造函数(不像其他一些面向对象语言里的构造函数),但它起到了类似的作用,并且会在启动管理器的过程中被使用。
code 7.10 Initializing a new manager with the New() function
go 代码解读复制代码func New(workers []string) *Manager {
taskDb := make(map[uuid.UUID]*task.Task)
eventDb := make(map[uuid.UUID]*task.TaskEvent)
workerTaskMap := make(map[string][]uuid.UUID)
taskWorkerMap := make(map[uuid.UUID]string)
for worker := range workers {
workerTaskMap[workers[worker]] = []uuid.UUID{}
}
return &Manager{
Pending: *queue.New(),
Workers: workers,
TaskDb: taskDb,
EventDb: eventDb,
WorkerTaskMap: workerTaskMap,
TaskWorkerMap: taskWorkerMap,
}
}
随着 AddTask 方法和 New 函数的添加,我们已经完成了 Cube 管理器的初始实现。现在剩下要做的就是测试运行一下它了!
7.4 关于故障和弹性的插曲
在这里值得停下来思考一下我们实现方案中的一个弱点。虽然管理器能够从一组工作节点中选择一个,并向其发送任务来运行,但它并没有处理故障的机制。管理器只是在其任务数据库中记录系统的状态。
然而,我们要构建的是一个声明式系统,在这个系统中用户声明任务的期望状态。管理器的工作是通过合理的努力使任务达到声明的状态。目前,合理的努力意味着只进行一次尝试让任务达到期望状态。我们将在第 9 章再次探讨这个话题,届时会考虑管理器在面对故障时可以采取的额外措施,以构建一个更具弹性的系统。
7.5 整合所有内容
到目前为止,我们构建 Cube 所采用的模式应该已经很清晰了。我们在本章的大部分时间里编写所需的核心代码;然后在本章末尾,我们在项目的 main.go 文件中编写或更新 main() 函数来使用我们编写的代码。接下来的几章我们也会继续沿用这个模式。
在本章中,我们将以第 6 章的 main.go 文件作为起点。在过去的章节中,我们只专注于运行工作节点,而现在我们既想运行工作节点,也想运行管理器。我们要同时运行它们,因为单独运行管理器是没有意义的:只有在有一个或多个工作节点的情况下,管理器才有存在的必要。
让我们复制第 6 章的 main.go 文件。如前所述,这是我们运行工作节点和管理器的起点。我们之前的代码已经知道如何启动一个工作节点实例。从清单 7.11 中可以看到,我们创建了一个工作节点实例 w,然后创建了一个工作节点 API 实例 api。接下来,我们调用同样在 main.go 中定义的 runTasks 函数,并将指向工作节点 w 的指针传递给它。我们使用一个协程(goroutine)来调用 runTasks 函数,通过在函数调用前加上 go 关键字来实现。同样,我们使用第二个协程来调用工作节点的 CollectStats() 方法,该方法会定期收集工作节点所在机器的统计信息(就像我们在第 6 章看到的那样)。最后,我们调用 API 的 Start() 方法,该方法会启动 API 服务器并监听请求。这是我们要做的第一个改动。我们不再在主协程中调用 api.Start(),而是使用第三个协程来调用它,这样就可以同时运行工作节点的所有必要组件。我们将复用前一章的 main() 函数,并做一个小改动,让工作节点的所有组件在不同的协程中运行。
code 7.11 Running all the worker's components in separate goroutines
go 代码解读复制代码func main() {
...
go api.Start()
}
code 7.12 Calling the manager.New() function
go 代码解读复制代码 workers := []string{fmt.Sprintf("%s:%d", host, port)}
m := manager.New(workers)
在一个工作节点实例正在运行且已经创建了一个管理器实例的情况下,接下来的步骤是向管理器添加一些任务。在清单 7.13 中,我们创建了三个任务。这只是随意决定的数量,你可以根据需要选择多一些或少一些任务。创建 Task 和 TaskEvent 应该看起来很熟悉,因为这和我们在前面章节中处理工作节点时所做的事情是一样的。不过,现在我们不是直接将 TaskEvent 添加到工作节点,而是通过在管理器 m 上调用 AddTask 方法,并将任务事件 te 传递给它,从而将其添加到管理器中。这个循环中的最后一步是在管理器 m 上调用 SendWork 方法,该方法将选择我们目前仅有的一个工作节点,并通过工作节点的 API 将任务事件发送给该工作节点。
code 7.13 Adding tasks to the manager
go 代码解读复制代码 for i := 0; i < 3; i++ {
t := task.Task{
ID: uuid.New(),
Name: fmt.Sprintf("test-container-%d", i),
State: task.Scheduled,
Image: "docker.io/strm/helloworld-http",
}
te := task.TaskEvent{
ID: uuid.New(),
State: task.Running,
Task: t,
}
m.AddTask(te)
m.SendWork()
}
到了这一步,让我们停下来思考一下都发生了什么:
我们创建了一个工作节点实例,它正在运行并监听 API 请求。
我们创建了一个管理器实例,它的工作节点列表中包含了我们之前创建的那个唯一的工作节点。我们创建了三个任务,并将这些任务添加到了管理器中。
管理器选择了一个工作节点(在这种情况下,是唯一存在的那个),并将三个任务发送给了它。
工作节点接收到了这些任务,并且至少尝试启动它们。
从上述流程可以明显看出,对于系统中任务的状态,存在两个视角:一个是管理器的视角,另一个是工作节点的视角。从管理器的视角来看,它已经将任务发送给了工作节点。除非向工作节点 API 发送请求时返回了错误,否则管理器在这个过程中的工作可以认为已经完成。
从工作节点的视角来看,情况要复杂得多。工作节点收到了来自管理器的请求。但我们要记住工作节点的构建方式。当工作节点 API 的请求处理程序接收到请求后,并不会直接执行任何操作;相反,处理程序会将请求放入工作节点的队列中。在一个单独的协程里,工作节点会执行启动和停止任务的实际操作。正如在第 5 章提到的,这种设计决策让我们能够将处理 API 请求的关注点和执行启动、停止任务实际操作的关注点分离开来。
一旦工作节点从其队列中取出一个任务并尝试执行必要的操作,可能会出现各种各样的问题。就像我们之前列举的,出现问题的例子可能包括用户错误(例如,用户在任务规范中指定了一个不存在的 Docker 镜像)或者机器错误(例如,机器没有足够的磁盘空间来下载任务的 Docker 镜像)。
由此可见,为了让管理器在我们的编排系统中发挥有效作用,不能采用 “一发送就不管” 的任务管理方式。它必须不断地与所管理的工作节点进行沟通,以协调自己和工作节点对于任务状态的认知。
我们在本章前面已经讨论过这个问题,这也是我们实现管理器 UpdateTasks 方法的动机。所以,现在让我们利用之前的设想。一旦管理器将任务发送给工作节点,我们就调用管理器的 UpdateTasks 方法。
为了实现这个目标,我们将使用另一个协程来调用一个匿名函数。和其他编程语言一样,Go 中的匿名函数就是在调用处定义的函数。在这个匿名函数内部,我们使用一个无限循环。在这个循环里,我们打印一条信息性的日志消息,告知我们管理器正在从其工作节点更新任务信息。然后调用管理器的 UpdateTasks 方法,以更新它对系统中任务状态的认知。最后,让程序休眠 15 秒。和之前一样,这里使用休眠仅仅是为了减慢系统运行速度,以便我们能够观察和理解程序的运行情况。既然提到了观察程序运行情况,我们再添加一个无限循环,遍历系统中的任务并打印出每个任务的 ID 和状态。这样,当 UpdateTasks 方法执行时,我们就可以观察到任务状态的变化。在 Go 生态系统中,使用匿名函数在单独的协程中运行一段代码是一种常见的模式。
code 7.14 Using an anonymous function
go 代码解读复制代码 go func() {
for {
fmt.Printf("[Manager] Updating tasks from %d workers\n", len(m.Workers))
m.UpdateTasks()
time.Sleep(15 * time.Second)
}
}()
for {
for _, t := range m.TaskDb {
fmt.Printf("[Manager] Task: id: %s, state: %d\n", t.ID, t.State)
time.Sleep(15 * time.Second)
}
}
此时,我们已经编写好了将工作节点和管理器一起运行所需的所有代码。那么,让我们从编写代码切换到运行代码。要运行我们的 main.go 程序,使用 go run main.go 命令来调用它。另外,在命令中定义 CUBE_HOST 和 CUBE_PORT 环境变量是很重要的,因为这会告诉工作节点 API 要监听哪个端口。这些环境变量也将被管理器用来填充其 Workers 字段。当我们启动程序时,初始输出应该看起来很熟悉。我们应该会看到以下内容:
go 代码解读复制代码$ CUBE_HOST=localhost CUBE_PORT=5555 go run main.go
Starting Cube Worker
...
2025/03/12 19:53:39 Pulled {b44db1a2-c623-49c6-abc0-1fff5acb3e8b test-container-0 0 0 0 0 docker.io/strm/helloworld-http map[] map[] map[] 0001-01-01 00:00:00 +0000 UTC 0001-01-01 00:00:00 +0000 UTC 0} off pending queue
2025/03/12 19:53:39 Added task {b44db1a2-c623-49c6-abc0-1fff5acb3e8b test-container-0 1 0 0 0 docker.io/strm/helloworld-http map[] map[] map[] 0001-01-01 00:00:00 +0000 UTC 0001-01-01 00:00:00 +0000 UTC 0}
2025/03/12 19:53:39 Pulled {36988c39-6747-42a4-9bd8-29009899df94 test-container-1 0 0 0 0 docker.io/strm/helloworld-http map[] map[] map[] 0001-01-01 00:00:00 +0000 UTC 0001-01-01 00:00:00 +0000 UTC 0} off pending queue
2025/03/12 19:53:39 Added task {36988c39-6747-42a4-9bd8-29009899df94 test-container-1 1 0 0 0 docker.io/strm/helloworld-http map[] map[] map[] 0001-01-01 00:00:00 +0000 UTC 0001-01-01 00:00:00 +0000 UTC 0}
2025/03/12 19:53:39 Pulled {935af4a2-8144-4059-b61b-6f201a64fadd test-container-2 0 0 0 0 docker.io/strm/helloworld-http map[] map[] map[] 0001-01-01 00:00:00 +0000 UTC 0001-01-01 00:00:00 +0000 UTC 0} off pending queue
2025/03/12 19:53:39 Added task {935af4a2-8144-4059-b61b-6f201a64fadd test-container-2 1 0 0 0 docker.io/strm/helloworld-http map[] map[] map[] 0001-01-01 00:00:00 +0000 UTC 0001-01-01 00:00:00 +0000 UTC 0}
在看到这个初始输出之后,我们应该会看到工作节点开始执行任务。然后,一旦三个任务都开始执行,你应该就会开始看到 main.go 程序的输出。我们的代码在一个 for 循环中调用管理器的 UpdateTasks 方法,遍历管理器的任务,并在另一个单独的 for 循环中打印出每个任务的 ID 和状态:
yaml 代码解读复制代码[Manager] Task: id: b44db1a2-c623-49c6-abc0-1fff5acb3e8b, state: 1
[Manager] Updating tasks from 1 workers
[Manager] Task: id: 36988c39-6747-42a4-9bd8-29009899df94, state: 1
[Manager] Task: id: 935af4a2-8144-4059-b61b-6f201a64fadd, state: 1
在输出中,您还会看到类似下面的输出。该输出来自我们的管理器本身:
arduino 代码解读复制代码2025/03/12 19:53:54 Attempting to update task b44db1a2-c623-49c6-abc0-1fff5acb3e8b
{"status":"Pulling from strm/helloworld-http","id":"latest"}
{"status":"Digest: sha256:bd44b0ca80c26b5eba984bf498a9c3bab0eb1c59d30d8df3cb2c073937ee4e45"}
{"status":"Status: Image is up to date for strm/helloworld-http:latest"}
[Manager] Task: id: b44db1a2-c623-49c6-abc0-1fff5acb3e8b, state: 2
[Manager] Task: id: 36988c39-6747-42a4-9bd8-29009899df94, state: 2
[Manager] Task: id: 935af4a2-8144-4059-b61b-6f201a64fadd, state: 2
当我们的 main.go 程序在一个终端中运行时,打开第二个终端并查询工作节点 API。根据你在启动 main.go 程序后多快运行 curl 命令的情况,你可能不会立即看到全部三个任务。不过,最终你应该会看到它们:
php 代码解读复制代码$curl http://localhost:5555/tasks |jq .
[
{
"ID": "935af4a2-8144-4059-b61b-6f201a64fadd",
"ContainerID": "0bbdfd3a0cb901e79b0cd5823e02cacbda242bae9394f8762d8771a2813627bd",
"Name": "test-container-2",
"State": 2,
"CPU": 0,
"Memory": 0,
"Disk": 0,
"Image": "docker.io/strm/helloworld-http",
"RestartPolicy": "",
"ExposedPorts": null,
"HostPorts": null,
"PortBindings": null,
"StartTime": "2025-03-12T11:54:21.35478Z",
"FinishTime": "0001-01-01T00:00:00Z",
"HealthCheck": "",
"RestartCount": 0
},
{
"ID": "b44db1a2-c623-49c6-abc0-1fff5acb3e8b",
"ContainerID": "7f82b5992fac0a0c15cf62b5cba382ee17363f11929fc22cfa9316be61e306e5",
"Name": "test-container-0",
"State": 2,
"CPU": 0,
"Memory": 0,
"Disk": 0,
"Image": "docker.io/strm/helloworld-http",
"RestartPolicy": "",
"ExposedPorts": null,
"HostPorts": null,
"PortBindings": null,
"StartTime": "2025-03-12T11:53:49.126328Z",
"FinishTime": "0001-01-01T00:00:00Z",
"HealthCheck": "",
"RestartCount": 0
},
{
"ID": "36988c39-6747-42a4-9bd8-29009899df94",
"ContainerID": "40bfd4d9059a8acc243f61ab1d0c622d54d375081f0395fb42270ba9d6cb8254",
"Name": "test-container-1",
"State": 2,
"CPU": 0,
"Memory": 0,
"Disk": 0,
"Image": "docker.io/strm/helloworld-http",
"RestartPolicy": "",
"ExposedPorts": null,
"HostPorts": null,
"PortBindings": null,
"StartTime": "2025-03-12T11:54:05.715971Z",
"FinishTime": "0001-01-01T00:00:00Z",
"HealthCheck": "",
"RestartCount": 0
}
]
除了查询 Worker API 之外,我们还可以使用 docker 命令来验证任务是否正在运行。请注意,为了便于阅读,我删除了 docker ps 输出中的一些列:
bash 代码解读复制代码$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0bbdfd3a0cb9 strm/helloworld-http "/main.sh" 32 minutes ago Up 32 minutes 0.0.0.0:55016->80/tcp test-container-2
40bfd4d9059a strm/helloworld-http "/main.sh" 32 minutes ago Up 32 minutes 0.0.0.0:55015->80/tcp test-container-1
7f82b5992fac strm/helloworld-http "/main.sh" 32 minutes ago Up 32 minutes 0.0.0.0:55014->80/tcp test-container-0
总结
- 任务事件记录:管理器以
task.TaskEvent项的形式记录用户请求,并将它们存储在其EventDB中。这个任务事件,其中包含task.Task本身,代表了用户对任务的期望状态。 - 任务状态记录:管理器在其
TaskDB中记录 “世界状态”(即从工作节点角度来看任务的实际状态)。对于管理器的这个初始实现,我们不会尝试重试失败的任务,而只是简单地记录状态。我们将在第 9 章中重新讨论这个问题。 - 管理器的职能:管理器仅履行管理职能。它接受来自用户的请求,在其内部数据库中记录这些请求,选择一个工作节点来运行任务,并将任务传递给该工作节点。它通过查询工作节点的 API 定期更新其内部状态。它并不直接参与实际运行任务的任何操作。
- 任务分配算法:我们使用了一种简单且非常初级的算法来将任务分配给工作节点。这一决定使我们能够用相对较少的代码行数编写一个可工作的管理器实现。我们将在第 10 章中重新审视这一决定。
评论记录:
回复评论: