
本文研究Simulink中的原子子系统生成的代码。
1 问题引入
在手写嵌入式C代码的时候,如果遇到反复使用的同一个代码片段,一个基本操作就是把他提炼为一个函数,然后反复调用。这样做不仅能使代码更具有可读性,也能有效的减少代码量,降低了Flash资源使用。
同理,假如有如下Simulink模型,大量使用了具有相同逻辑的模块。
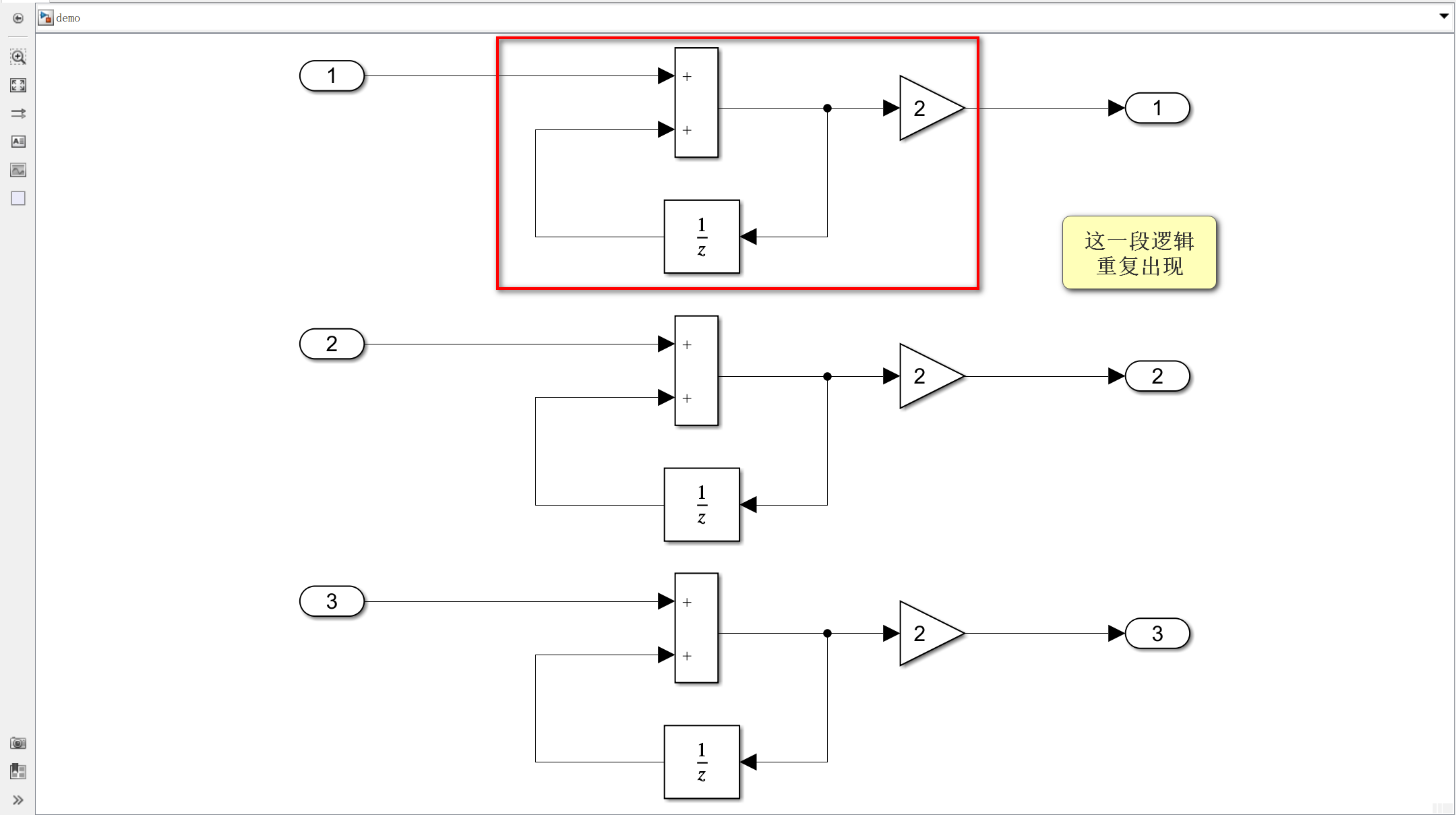
生成的代码中就会出现重复功能的C代码。
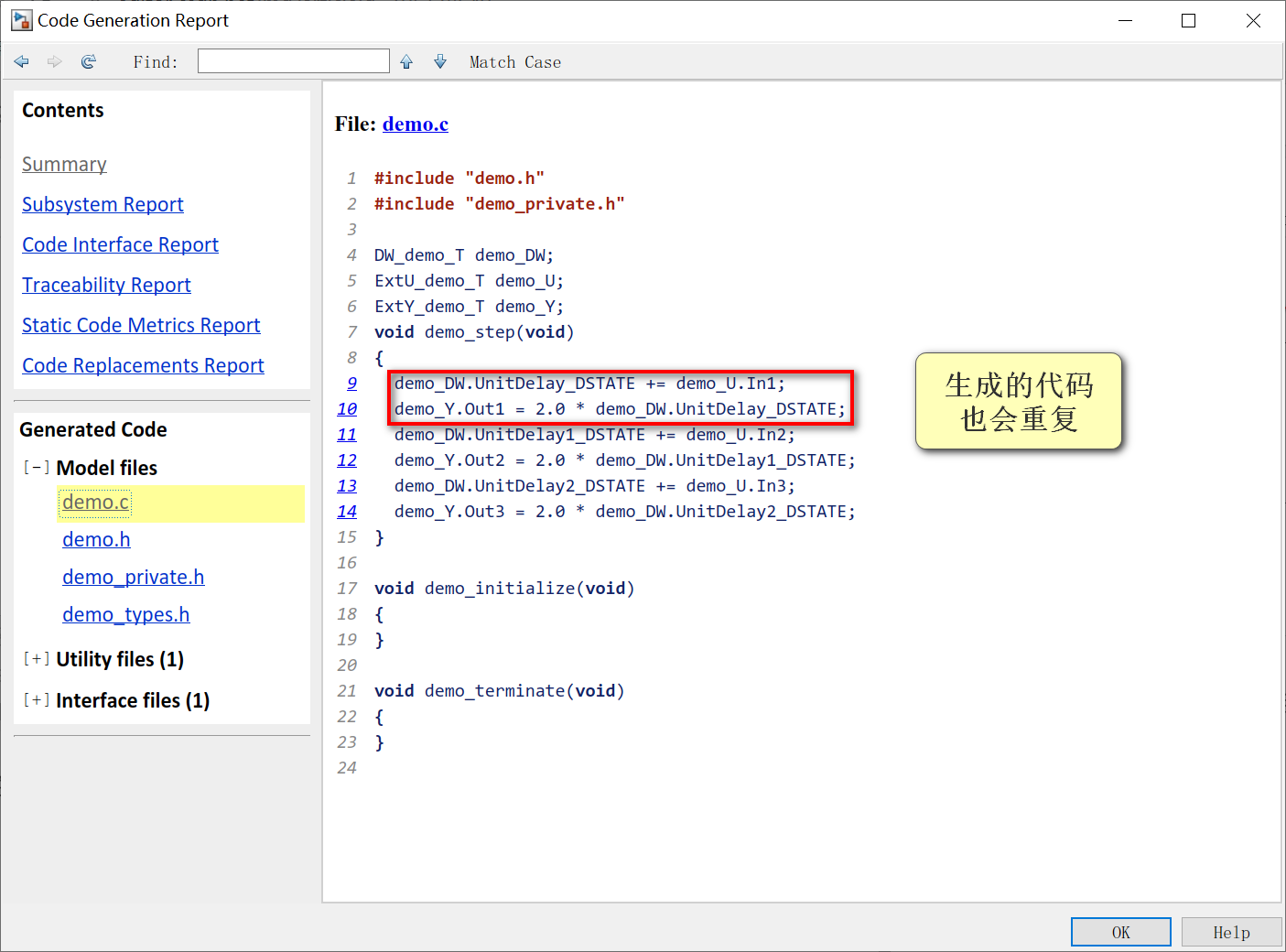
在项目中的模块一般都比demo中的更加复杂,也就产生了更多的冗余代码。一个好的解决办法就是将重复的模块配置成原子子系统。
2 原子子系统配置
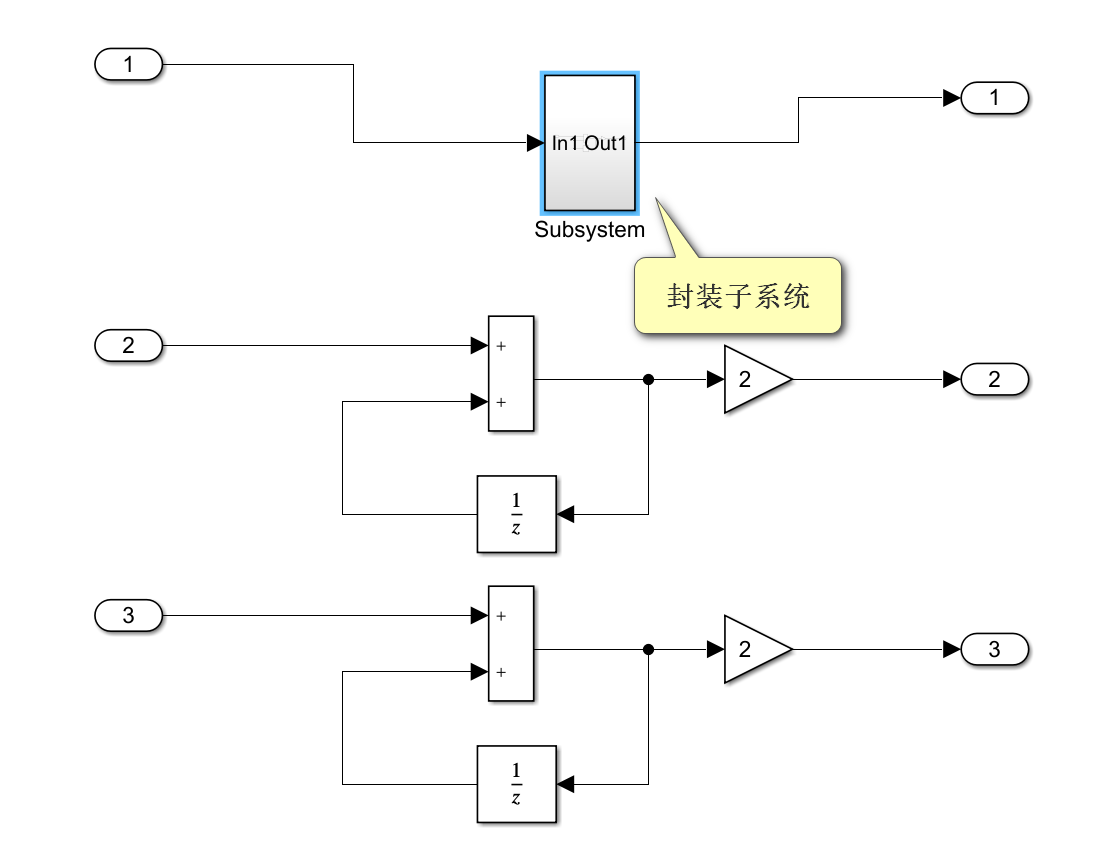
1.框选其中一个模块,然后Ctrl+G将其封装为子系统。
2.右键子系统,选择Block Parameters,打开模块参数配置窗口。
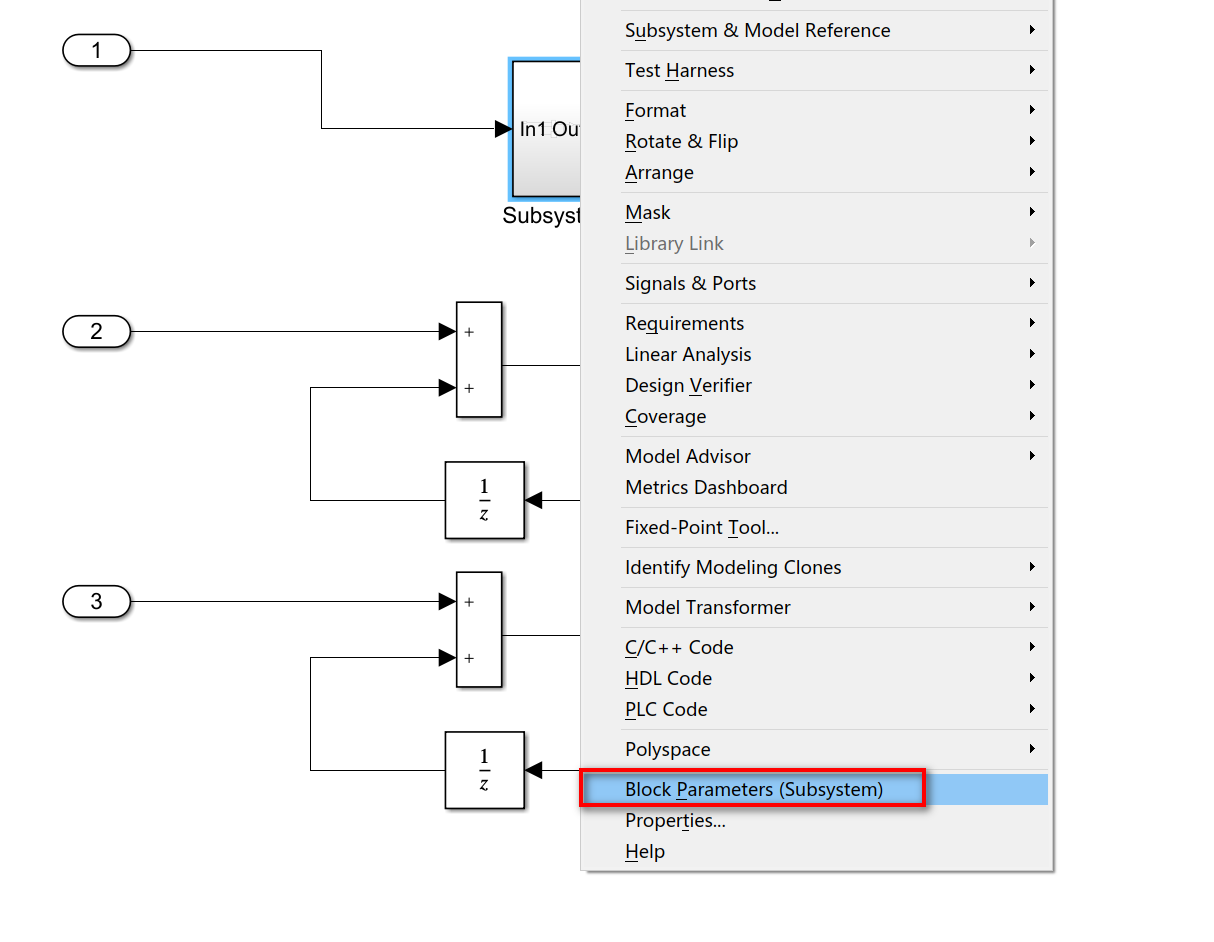
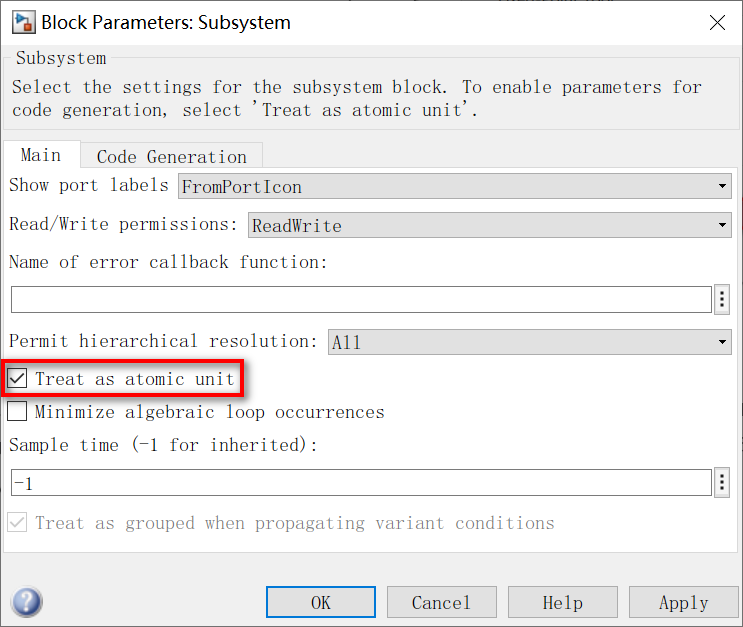
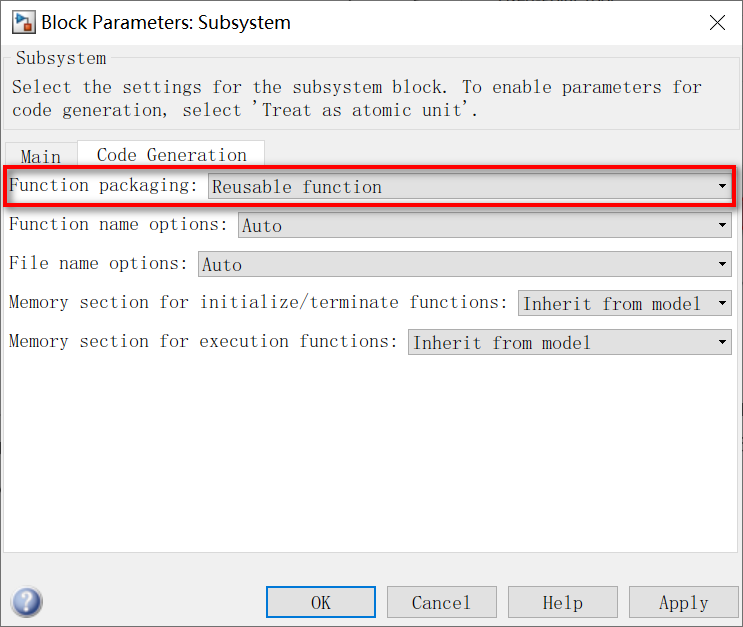
3.在Main这一栏中,勾上Treat as atomic unit。然后在Code Generation这一栏中,将Function packaging选为Reusable Function。下面的函数名和文件名可以自定义,也可以默认。
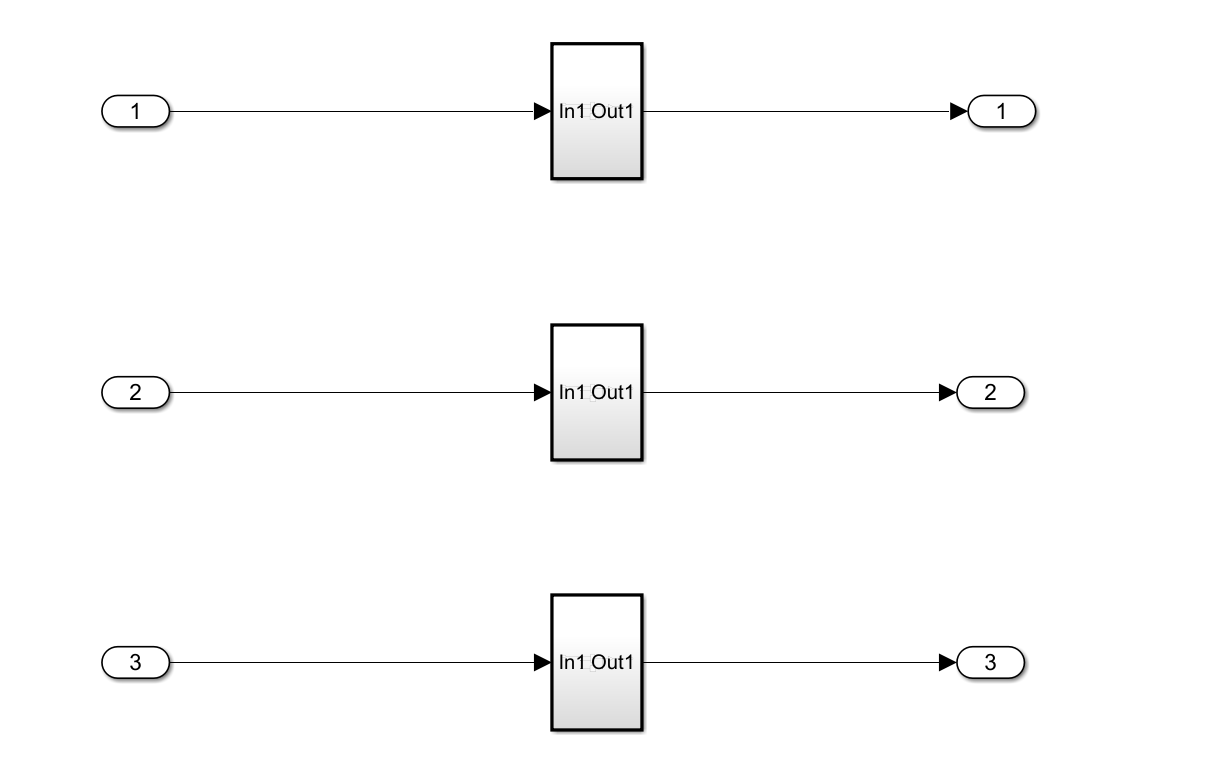
4.把其余两个模块替换成原子子系统的复制。
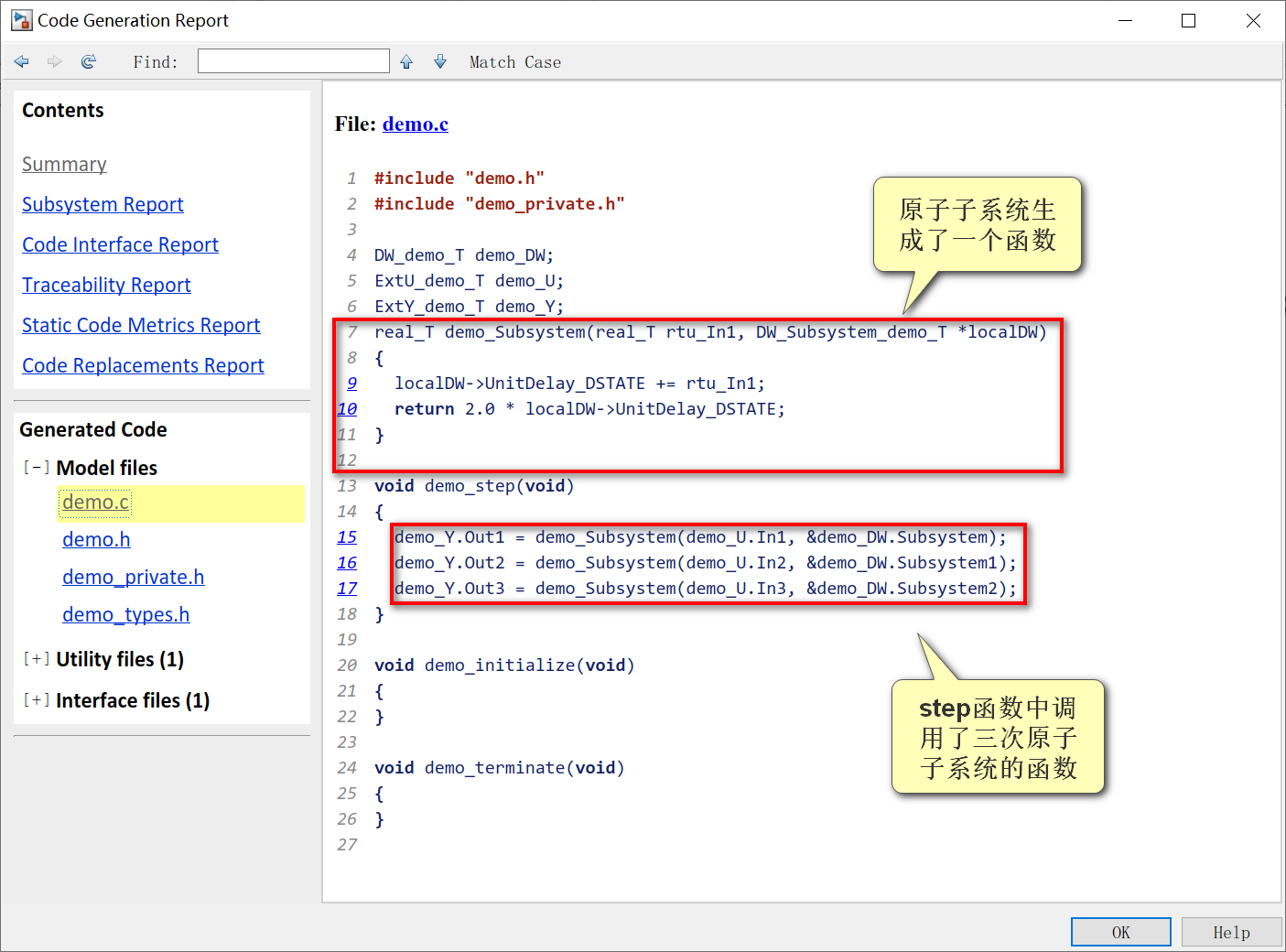
5.保存模型,生成代码。可以看出Simulink为原子子系统生成了一个函数,然后在step函数中调用了三次。
3 将原子子系统单独生成文件
通过配置也可以将原子子系统生成一个单独的文件,供step函数调用。
1.首先,在Block Parameters窗口中配置文件名。通过自定义文件名称和函数名称,可以将原子子系统的代码生成到一个C文件中。
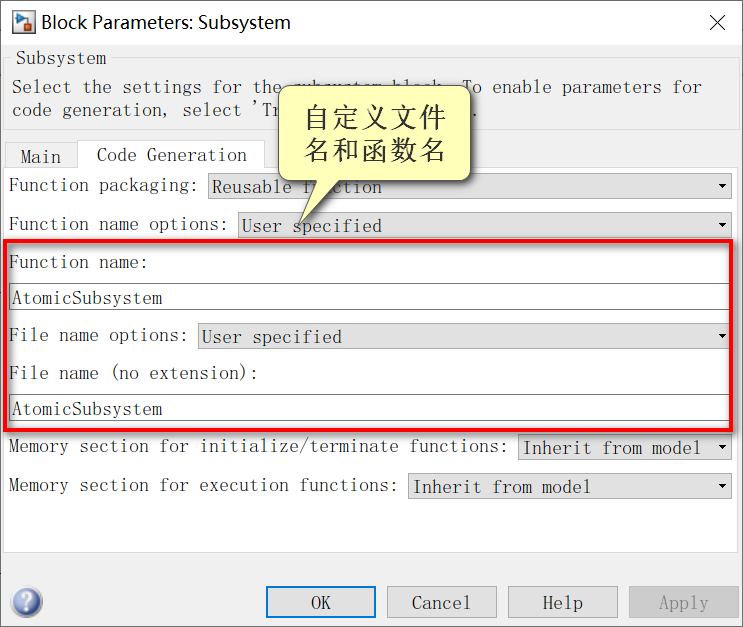
对应的代码:
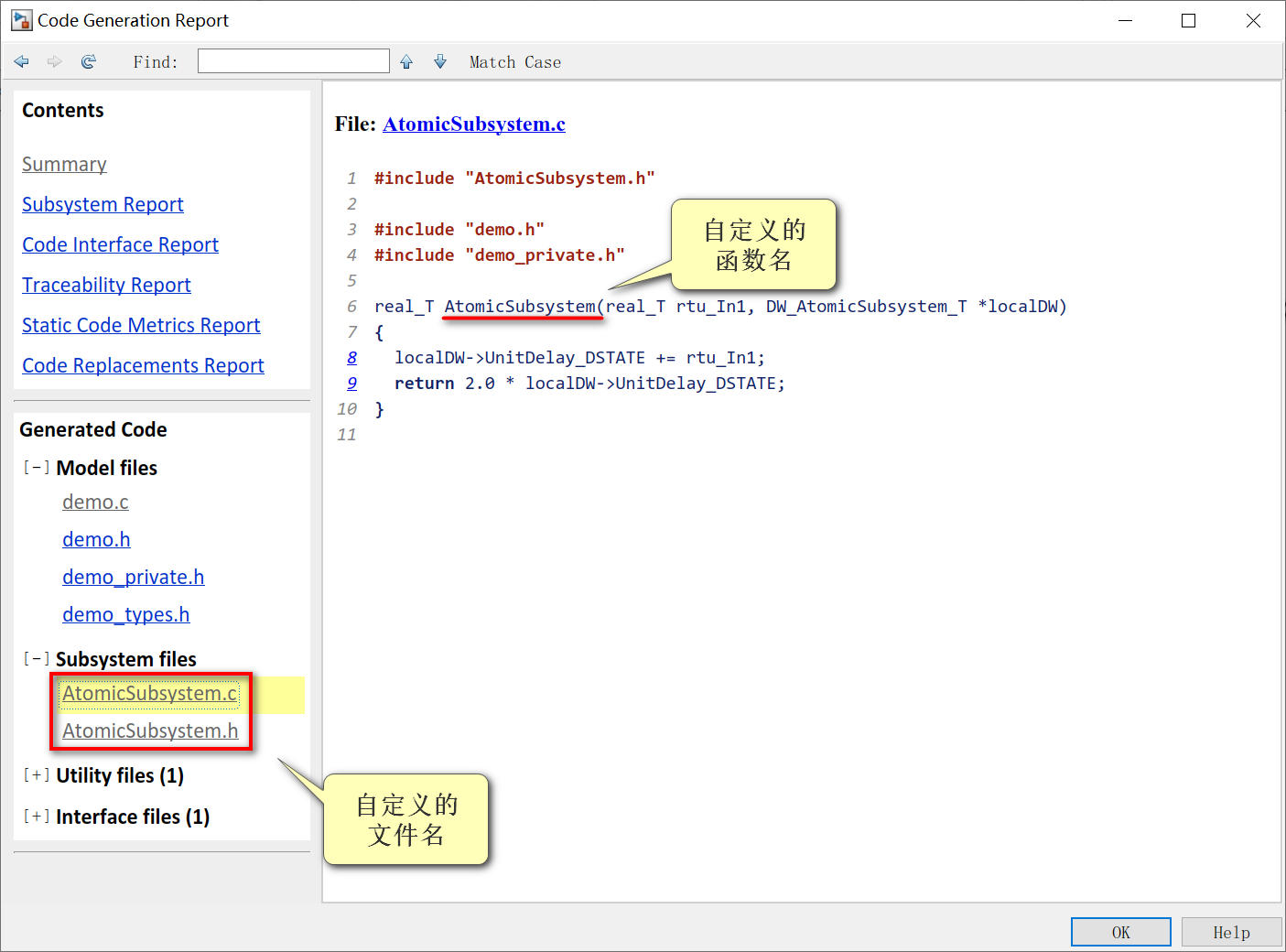
另外,还可以将原子子系统配置成库,就可以供多个模型调用,也更加便于修改。
4 原子子系统的数据类型
最近博主在工作中发现,原子子系统的输入输出的数据类型,也会对代码生成有一定的影响。
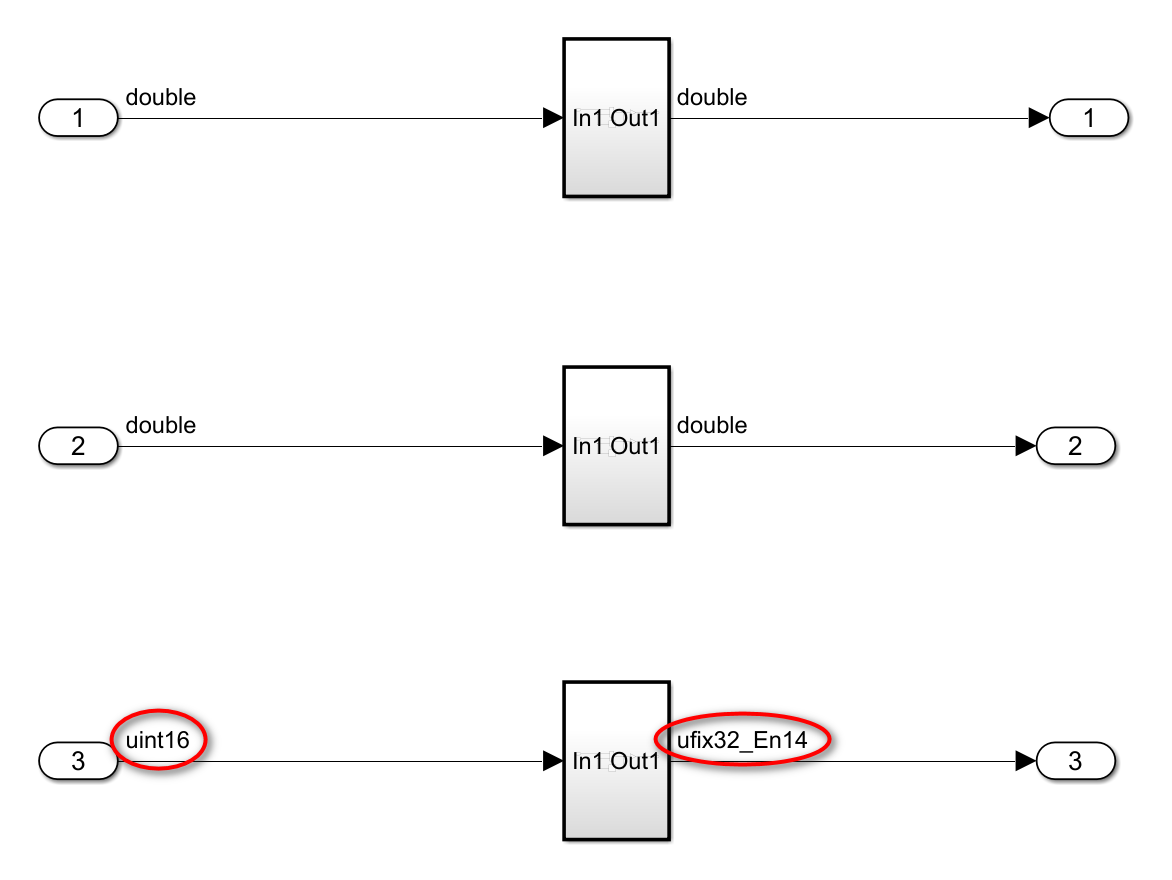
1)将原模型的第3个Import的输出类型修改为uint16,仿真后,输入输出类型就不再是像上面的两个double型了。
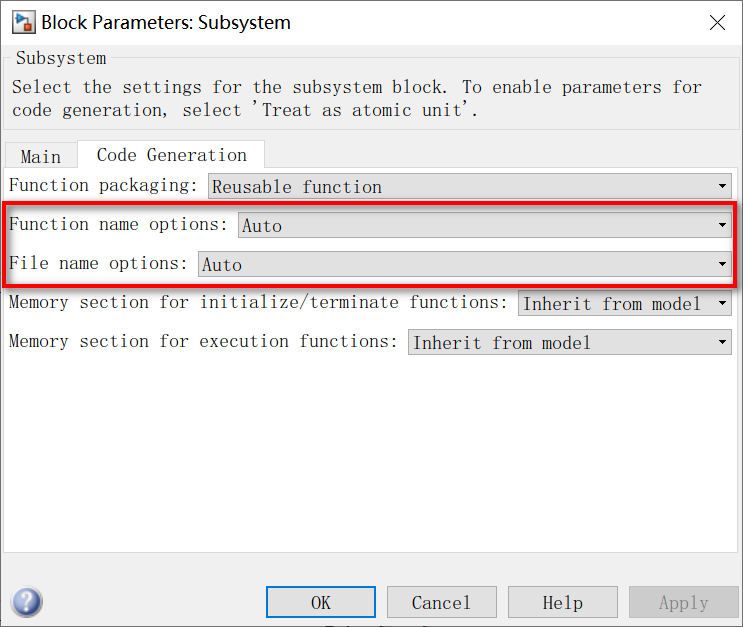
2)将原子子系统的代码生成配置都改成Auto。
3)Ctrl + B生成代码。
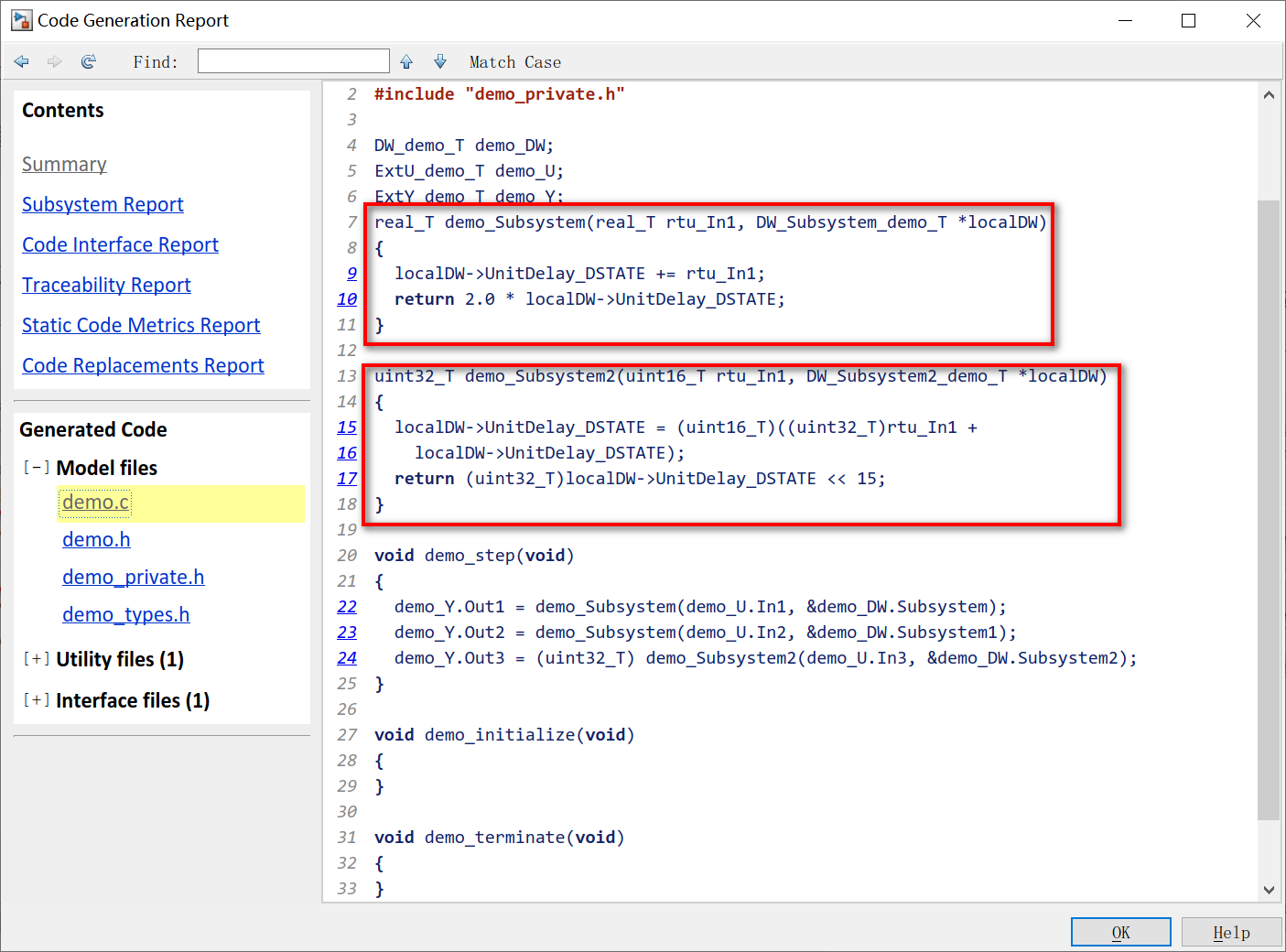
观察生成的代码会发现,三个内容相同的原子子系统生成了不同的两个函数。前两个输入输出调用的是同一个demo_Subsystem()函数,后一个输入输出调用的是另一个demo_Subsystem2()函数。
导致这种情况的原因就是因为原子子系统的输入类型不一样,导致了必须生成类型不用的形参,才能和模型的类型相对应。博主认为,在建模过程中应该尽量使同样的原子子系统的输入输出类型相同,这样才能够比较有效地降低代码量。
如果接口类型不同的情况向,像是第3章中强制指定原子子系统对应函数的名称,则生成代码会报错。
5 总结
通过定义原子子系统,实现将同种功能的代码复用,减少了代码量,提高了可读性。
评论记录:
回复评论: