
在字符串处理中,正则表达式堪称神器。本文简单介绍笔者在工作中运用正则表达式的一些经验,以及踩过的许多坑。
1 正则表达式概念及语法
正则表达式是一串用于定义某种模式的字符。在Matlab脚本编程中,通常使用正则表达式在一段文本中匹配出某种固定格式的字符串。
更多正则表达式的概念及其语法可以参照Matlab帮助文档——正则表达式,其中有很多通俗易懂的例子助于理解。不过笔者认为,没必要一次性把所有的语法规则背下来,只要在有用到正则表达式的时候查阅即可。
2 正则表达式的方法、技巧
本节举一些使用正则表达式的例子。
2.1 使用match、tokens、names参数
在使用regexp()函数的时候,需要加上match参数才能返回符合表达式的字符串,否则返回的是该表达式在文本中的位置。
2.1.1 match参数
1.在Matlab中运行如下代码,考察不用match参数时的返回值。
>> text = 'I am Jackson,he is Jack.';
>> regexp(text,'Jaw+')
ans =
6 20
- 1
- 2
- 3
- 4
- 5
- 6
其中,表达式 Jaw+ 表示我们想匹配出Ja开头的单词。返回的6和20这两个数字表明以Ja开头的Jackson和Jack单词在text文本的第6和第20个字符。
2.在Matlab中运行如下代码,考察使用match参数时的返回值。
>> text = 'I am Jackson,he is Jack.';
>> regexp(text,'Jaw+','match')
ans =
1×2 cell 数组
{'Jackson'} {'Jack'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用了match参数后会把符合表达式的字符串返回。
2.1.2 tokens参数
1.在Matlab中运行如下代码,考察用match而不用tokens参数时的返回值。
>> text = 'I am Jackson,he is Jack.';
>> result = regexp(text,'Isams(Jaw+)','match')
result =
1×1 cell 数组
{'I am Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
返回的是符合正则表达式的一整句话’I am Jackson’。
2.在Matlab中运行如下代码,考察使用tokens参数时的返回值。
>> result = regexp(text,'Isams(Jaw+)','tokens')
result =
1×1 cell 数组
{1×1 cell}
>> result{1}
ans =
1×1 cell 数组
{'Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
返回的是一个单元数组嵌套一个单元数组。进一步打开单元数组,发现里面把’Jackson’这个名字匹配出来了,正是正则表达式’Isams(Jaw+)'的括号中的内容。所以tokens参数可以匹配出正则表达式的部分内容。
2.1.3 names参数
1.在Matlab中运行如下代码,考察用match而不用names参数时的返回值。
>> text = 'I am Jackson,he is Jack.';
>> result = regexp(text,'Isams(Jaw+)','match')
result =
1×1 cell 数组
{'I am Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
返回的是符合正则表达式的一整句话’I am Jackson’。
2.在Matlab中运行如下代码,考察使用names参数时的返回值。
>> result = regexp(text,'Isams(?Jaw+)','names')
result =
包含以下字段的 struct:
MyName: 'Jackson'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
除了参数改成了names,括号里也增加了一个标签MyName。返回的是一个结构体,结构体的标签是MyName,这个标签对应的内容是匹配的Jackson。
2.2 文本中的空格符
空格符可谓时正则表达式应用中的一个常见的坑。还是上面那个例子,假如想把am后面的单词提取出来,正则表达式应该用上下文匹配的方式这么写:
>> regexp(text,'(?<=ams)Jaw+','match')
ans =
1×1 cell 数组
{'Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中,(?<=ams) 指的是想匹配的文字前面是am这个单词加一个空白符,这样就顺利匹配出来了。
但是,坑点在于处理很多不同的文本的时候,空白符不一定是一个。假如原文字的单词之间有多个空格符,肉眼一眼看不出来,就会被我们的脚本漏掉而什么都匹配不出来,如下所示:
>> text = 'I am Jackson,he is Jack.';
>> regexp(text,'(?<=ams)Jaw+','match')
ans =
空的 0×0 cell 数组
- 1
- 2
- 3
- 4
- 5
- 6
为了避免这种情况,需要把正则表达式改成regexp(text,’(?<=ams+)Jaw+’,‘match’),告诉计算机这里的s可能有很多个,这样就能顺利匹配出来了:
>> text = 'I am Jackson,he is Jack.';
>> regexp(text,'(?<=ams+)Jaw+','match')
ans =
1×1 cell 数组
{'Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.3 文本中的换行符
如果我们的表达式横跨两行的话,就一定要把换行符考虑进去,譬如:
>> text1 = ['I am Jack',newline,'son,he is Jack.']
text1 =
'I am Jack
son,he is Jack.'
>> regexp(text1,'(?<=ams+)Jaw+','match')
ans =
1×1 cell 数组
{'Jack'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在text1中Jackson这个单词被换行符分割成了两段,所以在换行的地方就不会继续匹配了。笔者认为,在实际工作中可以把换行符写进正则表达式中,如下所示:
>> regexp(text1,'(?<=ams+)Ja[w
]+','match')
ans =
1×1 cell 数组
{'Jack↵son'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样的话,就都匹配出来了,不过中间会有一个↵的符号代表换行符,可以再加一层strrep函数把换行符替换掉:
>> strrep(regexp(text1,'(?<=ams+)Ja[w
]+','match'),newline,'')
ans =
1×1 cell 数组
{'Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
有的时候,换行符不是’ ’,而是’ ’,即回车符+换行符。
2.4 注意中英文字符差异
很多文本中,有可能是因为粗心而混用了中英文字符,导致匹配正则表达式的失败。例如在text = ‘I am Jackson,he is Jack.’;这段原文字中,逗号的使用如果为中文,就有可能匹配失败。如
>> text = 'I am Jackson,he is Jack.';
>> regexp(text,'Jaw+(?=,)','match')
ans =
空的 0×0 cell 数组
- 1
- 2
- 3
- 4
- 5
- 6
代码中用了个中文逗号,而正则表达式中用了英文逗号,所以导致匹配失败。笔者认为,解决这种问题要么就从源头上保证原文本没写错,要么就在正则表达式里面考虑进去。可以将表达式改一下,把中英文逗号都包含进去:
>> regexp(text,'Jaw+(?=[,,])','match')
ans =
1×1 cell 数组
{'Jackson'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
同类的问题还有中英文括号、中英文双引号等,这些都非常容易引起错误,但又不容易发现。
2.5 RegExp参数
在Matlab中有很多搜索类的函数,其中往往有RegExp参数可以打开,通过正则表达式搜索。譬如在笔者以前的博客Matlab技巧(二) 通过脚本获取/修改Simulink模块参数,使用了find_system函数搜索出Simulink中的模块。在这个函数中,就可以用正则表达式来搜索。
为了验证这个参数,首先在Simulink中新建如下模型:
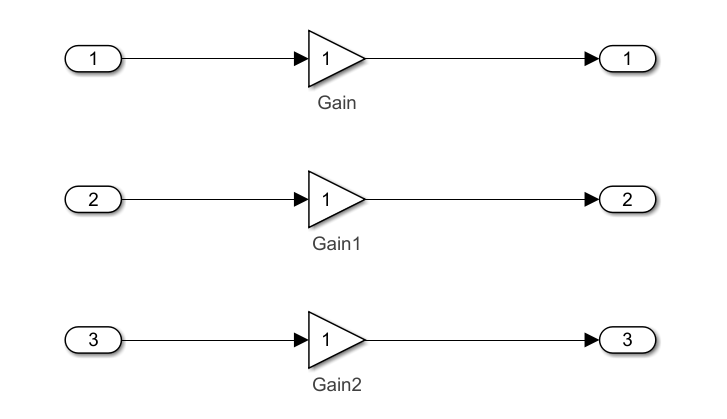
图中的Gain1和Gain2都是由第一个Gain复制过来的,系统将其Name属性自动命名,加上了数字。
接着在Matlab命令行输入:
>> find_system(gcs,'RegExp','on','Name','Gaind*')
ans =
3×1 cell 数组
{'untitled/Gain' }
{'untitled/Gain1'}
{'untitled/Gain2'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通过 ‘Gaind*’ 这个正则表达式,就把名为Gain带一个数字的模块搜索出来了。如果用 'Gaind+'这个表达式,就不会把’Gain’匹配出来了。要注意*和+的区别。
>> find_system(gcs,'RegExp','on','Name','Gaind+')
ans =
2×1 cell 数组
{'untitled/Gain1'}
{'untitled/Gain2'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3 总结
正则表达式并不难,但是应用的过程中总是有一些小问题,需要边摸索边解决。笔者一时也没法完全回忆起工作中所遇到的各类问题,等再次遇到的时候再回来补充。
评论记录:
回复评论: