
《Flink 架构》系列(已完结),共包含以下 6 篇文章:
- Flink 架构(一):系统架构
- Flink 架构(二):数据传输
- Flink 架构(三):事件时间处理
- Flink 架构(四):状态管理
- Flink 架构(五):检查点 Checkpoint(看完即懂)
- Flink 架构(六):保存点 Savepoint
? 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 ??? 吧 (点赞 ?、关注 ?、收藏 ?)!!!您的支持 ??? 将激励 ? 博主输出更多优质内容!!!
在运行过程中,应用的任务会持续进行数据交换。TaskManager 负责将数据从发送任务传输至接收任务。它的网络模块在记录传输前会先将它们收集到 缓冲区 中。换言之,记录并非逐个发送的,而是在缓冲区中以批次形式发送。该技术是有效利用网络资源、实现高吞吐的基础。它的机制类似于网络以及磁盘 I/O 协议中的缓冲技术。
❗ 请注意,将记录放入缓冲区并不意味着 Flink 的处理模型是基于微批次的。
每个 TaskManager 都有一个用于收发数据的网络缓冲池(每个缓冲默认 32 KB 大小)。如果发送端和接收端的任务运行在不同的 TaskManager 进程中,它们就要用到 操作系统的网络栈 进行通信。流式应用需要以流水线方式交换数据,因此每对 TaskManager 之间都要维护一个或多个永久的 TCP 连接来执行数据交换。 在 Shuffle 连接模式下,每个发送端任务都需要向任意一个接收任务传输数据。对于每一个接收任务,TaskManager 都要提供一个专用的网络缓冲区、用于接收其他任务发来的数据。下图展示了这一架构。
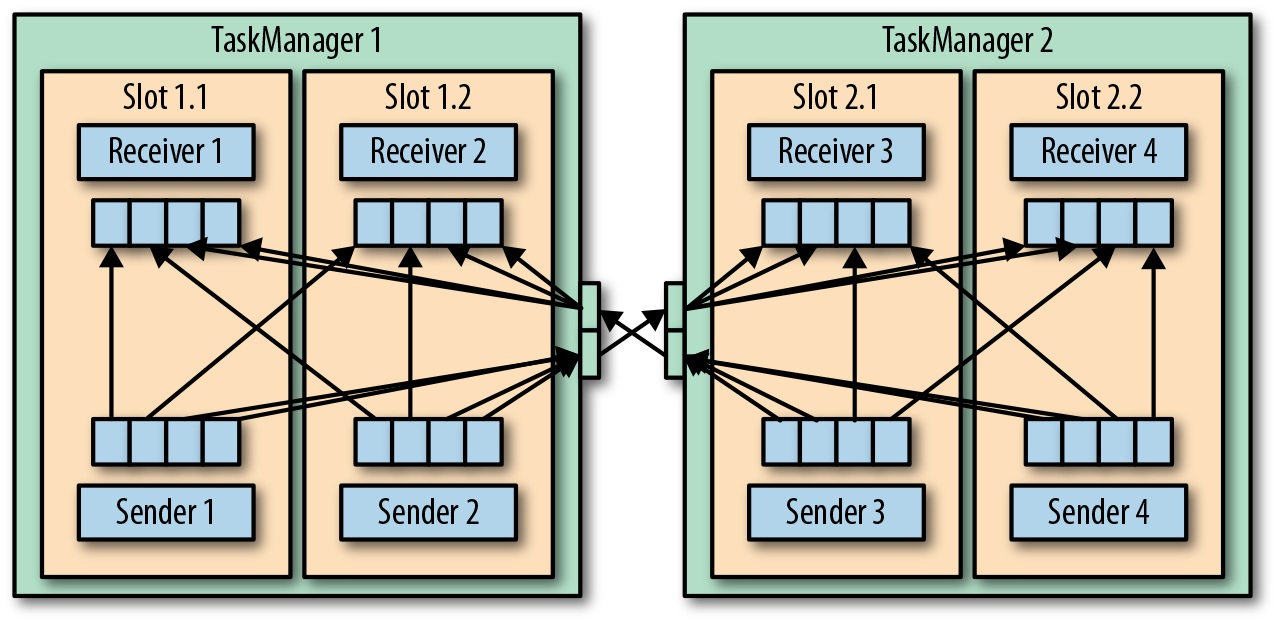
如上图所示,由于接收端的并行度为 4,所以每个发送端任务至少需要 4 个网络缓冲区来向任一接收端任务发送数据。同理,每个接收端任务也需要至少 4 个缓冲区来接收数据。缓冲区内的数据在向对方 TaskManager 传输时会共享网络连接。为了使流水线式的数据交换平滑进行,TaskManager 必须提供足够多的缓冲区来同时服务所有进出连接。在 Shuffle 或广播连接的情况下,每个发送任务都需要为每个接收任务提供一个缓冲区,因此所需的缓冲区数量可达到相关算子任务数的平方级别。Flink 默认的网络缓冲区配置足以应对中小型使用场景。而对于大型使用场景,后续将会介绍其内容调整配置。
批处理应用除了流水线式通信之外,还可以在发送端收集需要发出的数据。一旦发送端任务完成。所有数据会经由一个到接收端的临时 TCP 连接批量发出。
当发送任务和接收任务处于同一个 TaskManager 进程时,发送任务会将要发送的记录序列化到一个字节缓冲区中。一且该缓冲区占满就会被放到一个队列里。接收任务会从这个队列里获取缓冲区并将其中的记录反序列化。这意味着 同一个 TaskManager 内不同任务之间的数据传输不会涉及网络通信。
Flink 采用多种技术来降低任务之间的通信开销。接下来,我们简要讨论一下 基于信用值(credit-based)的流量控制以及 任务链接(task chaining)。
1.基于信用值的流量控制
通过网络连接逐条发送记录不但低效,还会导致很多额外开销。若想充分利用网络连接带宽,就需要对数据进行缓冲。在流处理环境下,缓冲的一个明显缺点是会增加延迟,因为记录首先要收集到缓冲区中而不会立即发送。
Flink 实现了一个基于信用值的流量控制机制,它的工作原理如下:接收任务会给发送任务授予一定的信用值,其实就是保留一些用来接收它数据的网络缓冲。一旦发送端收到信用通知,就会在 信用值所限定的范围内 尽可能多地传输缓冲数据,并会附带上 积压量(已经填满准备传输的网络缓冲数目)大小。
接收端使用保留的缓冲来处理收到的数据,同时依据各 发送端的积压量信息 来计算所有相连的发送端在下一轮的信用优先级。由于发送端可以在接收端有足够资源时立即传输数据,所以基于信用值的流量控制可以有效降低延迟。此外,信用值的授予是根据各发送端的数据积压量来完成的,因此该机制还能在出现数据倾斜(data skew)时有效地分配网络资源。不难看出,基于信用值的流量控制是 Flink 实现高吞吐低延迟的重要一环。
2.任务链接
Flink 采用一种名为 任务链接 的优化技术来降低某些情况下的 本地通信开销。任务链接的前提条件是,多个算子必须有相同的并行度且通过本地转发通道(local forward channel)相连。下图中算子所组成的流水线就满足上述条件。它包含了 3 个算子,每个算子的任务并行度都为 2 且通过本地转发方式连接。
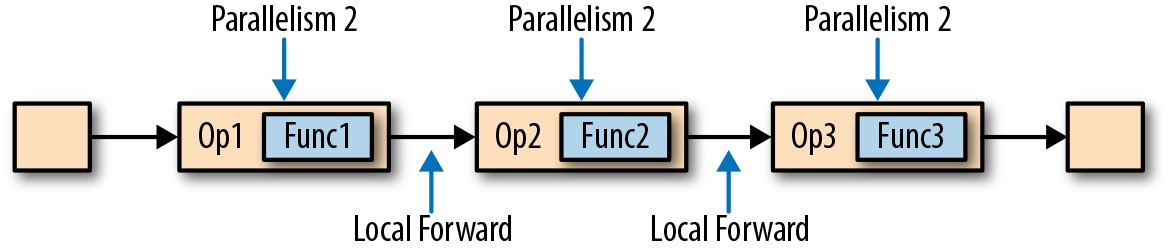
下图展示了流水线如何在任务链接模式下执行。多个算子的函数被 “融合” 到同一个任务中,在同一个线程内执行。函数生成的记录只需通过简单的方法调用就可以分别发往各自的下游函数。因此函数之间的记录传输基本上不存在序列化及通信开销。
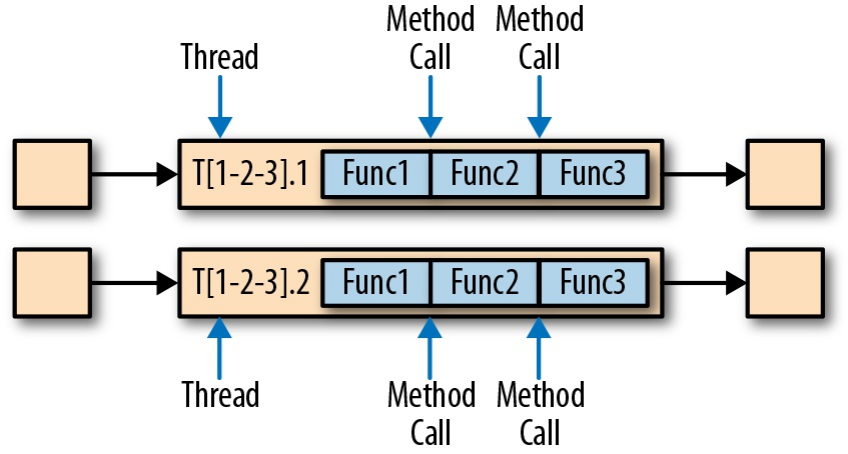
单线程执行的链接任务 “融合” 了多个函数,并通过方法调用进行数据传输。
虽然任务链接可以有效地降低本地任务之间的通信开销,但有的流水线应用反而不希望用到它。举例而言,有时候我们需要对过长任务链接进行切分或者将两个计算量大的函数分配到不同的处理槽中。下图展示了相同的流水线在非任务链接模式下执行。其中每个函数都交由单独的任务、在特定线程内处理。
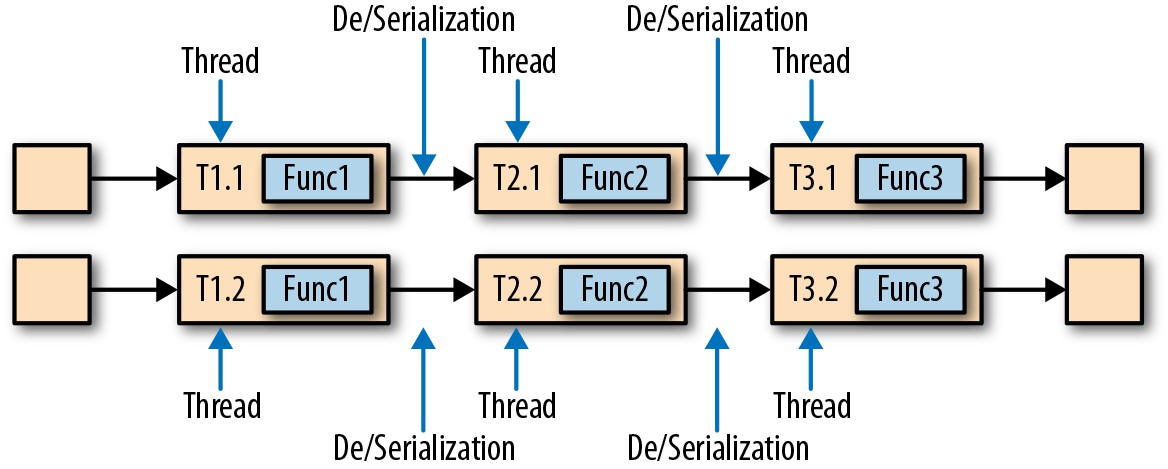
利用专用线程执行非链接任务并通过缓冲通道及序列化进行数据传输。
Flink 在默认情况下会开启任务链接。后续,我们会展示如何针对某一应用禁用任务链接以及如何单独控制单个算子的行为。
评论记录:
回复评论: