
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~

「2019 Python开发者日」,购票请扫码咨询 ↑↑↑
作者 | Olga Liakhovich
译者 | AI科技大本营编译志愿者团队
编辑 | Jane
出品 | AI科技大本营(id:rgznai100)
【导语】最近,AI科技大本营陆续为大家介绍了多篇 2019 CVPR 的精彩、优质论文解读!为了方便大家集中学习,营长特此为大家做了近期的汇总整理!不仅如此,作为清明小长假的第一天,营长精心准备了更精彩的福利内容:回顾 2018 年 CVPR 的 3 天大会,并对主要内容进行了整理与总结,也谈及了一些研究趋势,正好可以与今年的成果进行对比!这份大礼包全网只在 AI科技大本营!收藏指数爆表!
回顾 CVPR 2018,三天会议主要包括以下九大部分内容:
特别版块:专题研讨会及比赛
目标识别和场景理解问题
对图像中人的分析研究
3D视觉问题
计算机视觉中的机器学习问题
视频分析问题
计算摄影问题
图像运动及跟踪问题
应用
下面是去年总结的一些未来值得研究的趋势和话题,随着 CVPR 2019 的成果不断跟踪与积累,后续还可以继续做对比与分析:
视频分析:如视频字幕,动作分类,预测人 (行人) 移动的方向等问题
视觉情感分析
空间 (房间) 中智能体的方向,虚拟房间数据集,这些话题都跟机器学习的应用有关
视频中的行人重识别问题
图像的风格转移 (GAaaaNs) 仍然是一个研究热点
对抗性攻击问题的分析
图像增强问题,包括消除图像脱落、阴影等问题
自然语言处理与计算机视觉领域的结合话题
图像和视频的显著性分析
边缘设备 (edge device) 上的计算效率问题
弱监督学习下的计算机视觉问题
域自适应问题
机器学习的可解释性
强化学习在计算机视觉领域中的应用:包括网络优化,数据,神经网络的学习过程等
有关数据标记领域的话题
接下来,AI科技大本营把 2018 CVPR 会议上的主要内容划分了八大类别为大家做进一步的分析:
1. 场景的分析与问答
2. 图像增强及操作
3. 计算机视觉领域中的各种神经网络架构
4. 基于目标驱动的导航系统及室内 3D 场景
5. 人物相关性分析
6. 高效的深度神经网络
7. 文本与计算机视觉
8. 数据与计算机视觉
一、场景分析及问答
模块主题一:Embodied Question Answering (具体的问答问题)
亮点:走向具体化的智能体,能够听说看,还能采取行动和进行推理。
架构和技术细节:
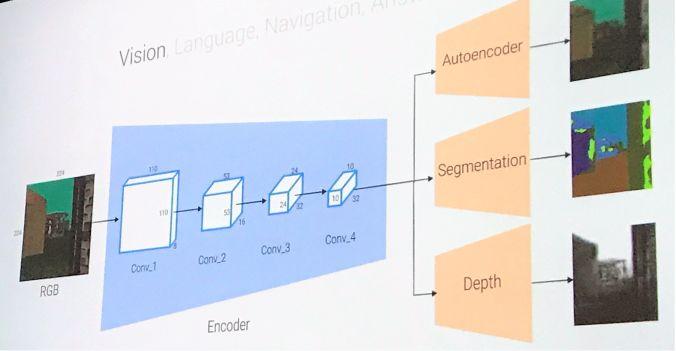
视觉模型:结构示意图如下,以 CNN 结构作为编码,进行多任务的、像素到像素的预测。
语言模型:两层的 LSTMs 结构。
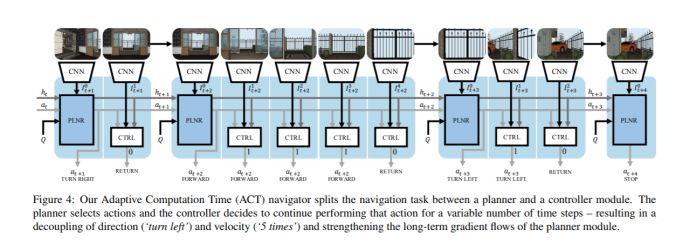
操纵模型:结构示意图如下,这是一个多层次的 RL 结构。Planner 选择动作 (向前,向左,向右),而控制器 (controller) 将这些原始动作作为多次使用的变量,并将 controller 执行的结果返回给 planner。
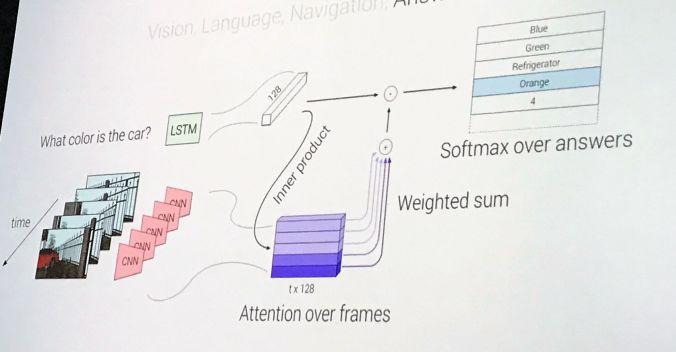
回答模型:结构示意图如下,检查最后5帧,并根据图像--问题的相似度来计算一个基于注意池化的视觉编码,然后将这些与问题的 LSTM 编码相结合,并在 172 个可能的答案空间上输出 softmax 结果。
数据集:使用EQA 数据集 (环境中的问题):该数据集含有 rgb 图像,语义分割掩码,深度映射图,自上而下的映射图。此外,数据集共包含12种房型 (厨房,生活区等) 和50种对象类型,并以编程方式生成的问题,这与 CLEVR 数据集的方式类似。
应用场景:智能体能够在自然环境中采取行动并跟人类以自然语言的方式交流。
论文与项目地址:
https://arxiv.org/abs/1711.11543
https://embodiedqa.org/
https://github.com/facebookresearch/EmbodiedQA
模块主题二:Learning by Asking Questions (LBA) (通过问答进行学习)
亮点:LBA \ Interactive Agents,决定它们需要什么样的信息以及如何获取这些信息。这种方式更优于被动的监督式学习。
架构和技术细节:给定一组图像提出问题,以监督学习的方式得到问题的答案。其流程如下图所示:
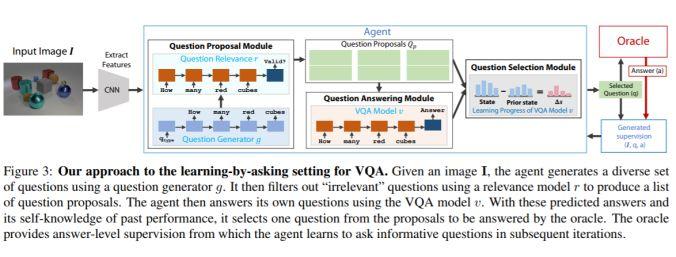
问题生成模型:是一种图像字幕生成模型,它使用以图像特征 (第一隐藏输入) 为条件的 LSTM 模型来生成一个问题。而问答模块是标准的 VQA 模型。
数据集:使用 CLEVR 数据集,包含 70K 张图片和 700 张 QA 图片。
参考:
https://research.fb.com/publications/learning-by-asking-questions/
模块主题三:Im2Flow: Motion Hallucination from Static Images for Action Recognition (基于静态图幻觉的动作识别研究)
亮点:将静态图像转换为精准的映射流图,并通过 single snapshot 的方式预测隐含的、未观察到的未来的运动情况。这有助于静态图像的动作识别研究。
架构和技术细节:通过编码--解码的 CNN 结构和一种新颖的光流编码结构,来将静态图像转换为映射流图。其结构示意图如下:
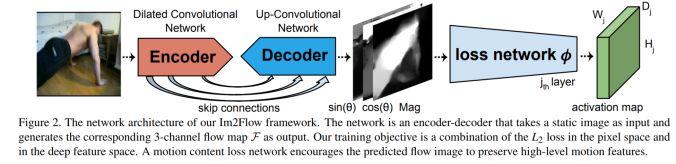
数据集:UCF-101 HMDB-51 的视频数据集上训练,该数据集含 700K 帧。
应用场景:图像\视频分析,字幕生成,动作识别和动态场景识别。
其他观点:除了人类的运动,该模型还可以用于预测场景的运动情况,如海洋中波浪的起落等。此外,该模型也可以推断出新图像的运动潜在性 (得分),即准备发生的运动和运动的强度等。
论文与项目地址:
https://arxiv.org/abs/1712.04109
http://vision.cs.utexas.edu/projects/im2flow/
模块主题四:Actor and Action Video Segmentation from a Sentence (基于语句的视频动作、动作者分割研究)
亮点:动作由自然语句所指定 (vs 预定义好的动作词汇表)。任何动作者 (vs 与人类接近的动作者)。
架构和技术细节:来自于自然语句的 RGB 模型,该模型用于动作者和视频动作的分割任务,包括三个组成,其结构示意图如下:
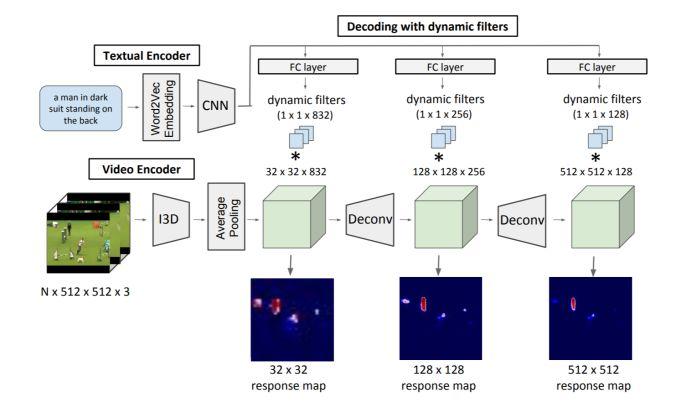
用 CNN 结构来编码表达式
用 3D CNN 结构来对视频进行编码
解码器:通过对已编码好的文本表征和视频表征进行进行动态的卷积过程,实现逐像素的分割。此外,相同的模型也应用于输入流。
数据集:两个流行的动作者和动作数据集,包含超过7500条的自然语言描述。
应用场景:视频分析,索引,字幕生成等。
其他观点:
IoU (Intersectionction-union) 用于衡量分割结果的质量。
句子感知 (sentence awareness) 对动作者和动作描述是有帮助的。
视频感知 (video awareness) 有助于得到更准确的分割结果。
好的效果图如下:

论文与项目地址:
https://arxiv.org/abs/1803.07485
https://kgavrilyuk.github.io/publication/actor_action/
模块主题五:Egocentric Activity Recognition (EAR) on a Budget (以自我为中心的动作识别研究)
亮点:基于不同的能量模型,利用 RL 学习策略。
架构和技术细节:智能眼镜的功能受限于电池及其自身的处理能力。
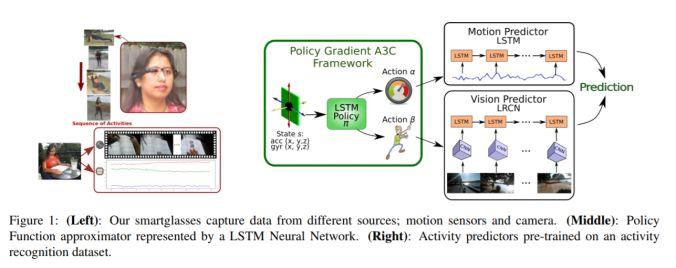
数据集:基准数据集采用 Multimodal 数据库。
应用场景:使用 AI 来帮助进行生活助理和护理服务工作 (使用智能眼镜得到的数据进行动作的跟踪和识别)。此外,EAR 还可以提供自动提醒/警告的功能,帮助认知障碍以避免危险情况。
其他观点:学习用户环境是利用能量运动和视觉方法的关键。
论文地址,数据集链接:
http://sheilacaceres.com/dataego/
http://www-personal.usyd.edu.au/~framos/Publications_files/egocentric-activity-recognition%20(2).pdf
模块主题六:Emotional Attention: A Study of Image Sentiment and Visual Attention (情感注意力:图像情感与视觉注意力研究)
亮点:这是第一项侧重于图像情感属性与视觉注意力之间关系的研究。此外,该研究另一贡献是创建 EMOtional 注意数据集 (EMOd 数据集)。
架构和技术细节:设计一个深度神经网络结构用于显著性预测,结构包括一个学习图像场景中空间和语义上下文信息的子网络,结构示意图如下。CASNet:一个对通道进行加权操作的子网络 (下图中在虚线橙色矩形内部分),用于计算每个图像中一组1024维特征的权重,以捕获特定图像语义特征信息的相对重要性。
灰色虚线箭头表示的是通过子网络修正后,图像中不同区域的相对显著性。
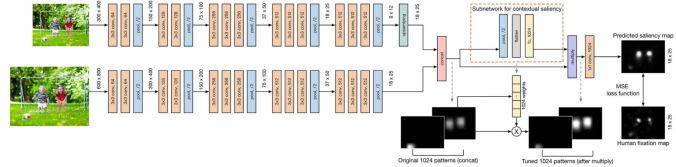
数据集:三种包含情感内容的数据库:EMOd 数据集包含1019张图片,NUSEF数据集包含751张图片,CAT 数据集包含2000张图片。
应用场景:用于视频监督,字幕生成等。
其他观点:情感目标会吸引简短而强烈的注意力。与人类相关的目标的情感优先级要大于那些与人类无关的目标。
论文地址:
https://nus-sesame.top/emotionalattention/
模块主题七:Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation (基于角定位和区域分割的多导向场景文本检测研究)
亮点:通过定位文本边界框的角点并在相对位置上分割文本区域来检测场景中的文本。
架构和技术细节:结合目标检测和语义分割的思想,并以另一种方式应用二者。基于给定的图像,网络通过角点检测和位置敏感性分割输出角点和分割映射图。然后通过对角点进行采样和分组来进一步生成候选框。最后,通过分割映射图和 NMS 抑制来得到这些候选框的分数。其结构示意图如下:
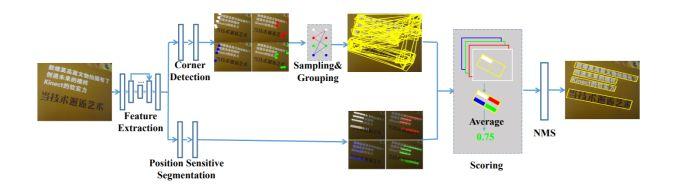
数据集:ICDAR2013 数据集,ICDAR2015 数据集,MSRA-TD500 数据集, MLT 和 COCO-Text 数据集。
应用场景:一些从自然场景图像中提取文本信息的任务:如产品搜索,图像检索,自动驾驶等。
其他观点:与一般物体检测相比,场景中的文本检测更加复杂,因为:
场景文本可能存在于任意方向的自然图像中,因此边界框的形状可以是旋转的矩形或四边形。
场景文本的边界框的宽高比变化很大。
由于场景文本的形式可以是字符,单词或文本行等,因此算法在定位边界时可能会产生混淆。
论文地址:
https://arxiv.org/abs/1802.08948
模块主题八:Neural baby talk (神经网络之间的对话)
亮点:Neural baby talk:这是一种新颖的框架,用于准确地定位图中的目标,同时生成自然语言描述字幕。首先,生成指数量级的模板,再将检测过程与字幕生成过程分离,并以不同类型的监督方式进行处理。该研究使用神经网络的方法协调经典的“槽填充”方法 (slot filling),同时在听觉上和视觉上实现神经网络的应用。
架构和技术细节:其结构示意图如下:
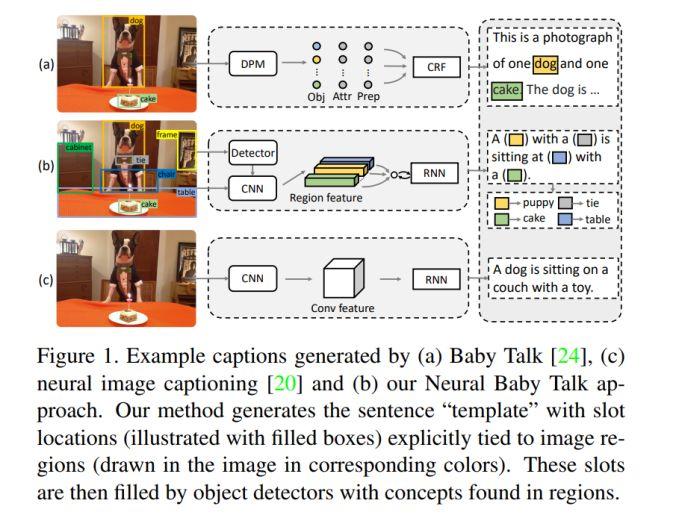
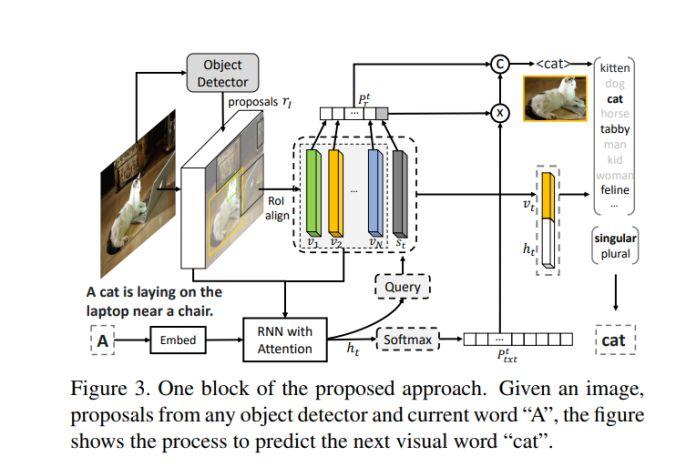
数据集:COCO 数据集。
应用场景:图像字幕生成任务。
其他观点:该研究使目标检测的升级版--在目标检测的基础上结合了自然语言的处理。
论文和 github 链接:
https://arxiv.org/pdf/1803.09845.pdf
https://github.com/jiasenlu/NeuralBabyTalk
二、计算机视觉领域中的各种神经网络架构
模块主题一:Deep Layer Aggregation (深度层聚合)
亮点:深度层聚合的方式使得模型具有更准确的性能表现和更少的参数量,同时这也为深层可视化架构的泛化和有效扩展应用提供了一种方式。
架构和技术细节:模型通过学习任意模块的聚合层输出,表现出更有表现力的层输入和更快速的层聚合性能。其结构示意图如下:
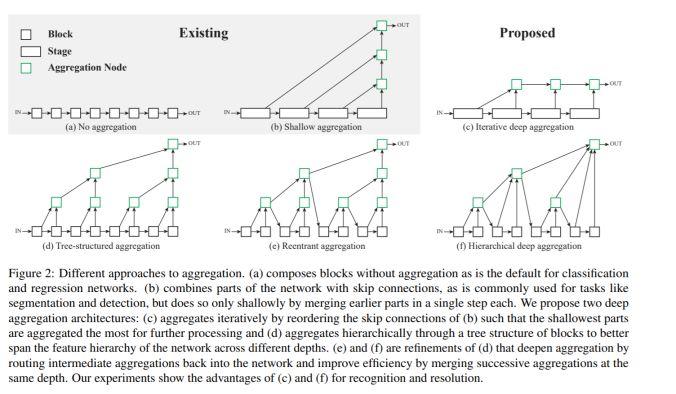
应用场景:图像识别,图像分割任务。
其他观点:该研究涉及到未来图像识别领域的两个趋势:
更好的构建模块。
跳跃连接。
我们要考虑的是如何才能使二者更好得兼容,以及如何通过有效的跳跃连接来提高 DRN (扩张性的残差神经网络) 的准确性?
论文和 github 链接:
https://arxiv.org/abs/1707.06484
https://github.com/ucbdrive/dla
此外,作者开源了这个数据标签工具 (含 BSD 许可证):
http://www.scalabel.ai/
模块主题二:Practical Block-wise Neural Network Architecture Generation (逐模块地神经网络结构生成)
亮点:该研究提出了一个名为 BlockQNN 的逐模块神经网络生成管道 (pipeline)
架构和技术细节:神经网络生成管道(pipeline)模块能够通过带 epsilon-greedy 探索策略的 Q-Learning 范式来自动构建高性能的神经网络结构。此外,它还是个分布式的异步网络框架,这能大大提高网络的运行速度。其结构示意图如下:
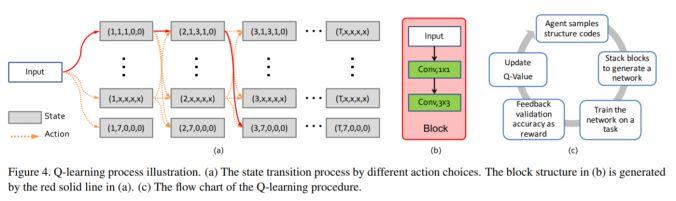
数据集:CIFAR,ImageNet
其他观点:在 CIFAR 数据集上的图像分类任务:使用32个 GPU只需花费3天的时间就能自动生成网络结构,这比 NASv1-Google (800GPU,28天) 所需的时间和资源要少的多。
论文链接:
https://arxiv.org/abs/1708.05552
模块主题三:Relation Networks for Object Detection (用于目标检测的推理网络)
亮点:目标关系的建议模块 (ORM) 可以嵌入到现有的目标检测体系中 (如 Faster RCNN),并提高了目标检测的 mAP 值 (+ 0.5-2)。此外,该模块能够通过目标的外观特征和几何关系间的交互来同时处理一组目标。
架构和技术细节:其结构示意图如下
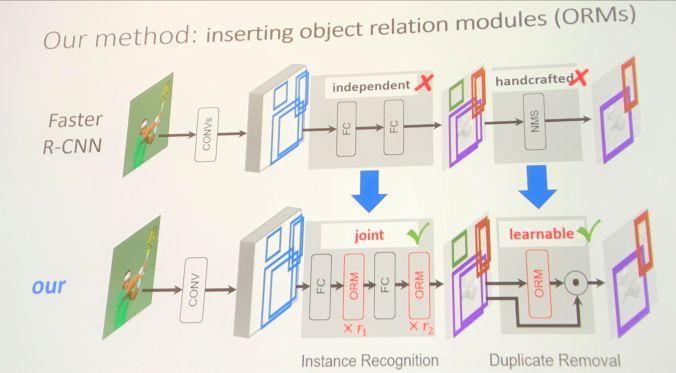
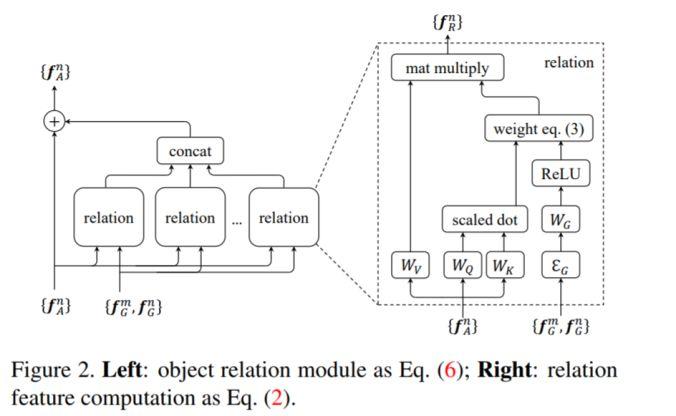
其他观点:该研究作者声称,在 Faster RCNN 中插入2个建议模块 (ORM),可以提高 2.3 mAP。此外,这种关系网络的学习不仅能够适用于具有高关系权重的目标对,还能在不同类之间实现信息的共享。
论文和 github 链接:
https://arxiv.org/abs/1711.11575
https://github.com/msracver/Relation-Networks-for-Object-Detection
模块主题四:DeepGlobe: A Challenge for Parsing the Earth through Satellite Images (DeepGlobe:通过卫星图像解析地球)
亮点:该研究包含三个部分:用于路面特征提取的 D-LinkNet,用于地面覆盖物分类的 Dense Fusion,以及用于建筑物检测的 Multi-task U-net。
架构和技术细节:
1、D-LinkNet:
结构:网络采用 LinkNet 结构构建,并在其中心部分引入了扩张卷积层 (dilated convolution layer)。Linknet 结构在计算和存储方面都非常高效。扩张卷积是一种强大的工具,可以在不降低特征映射图分辨率的情况下扩大特征点的感受野。
损失函数和优化器:以 BCE (二进制交叉熵) 和 dice coefficient loss 作为损失函数,以 Adam 作为优化器。
数据增强:在测试阶段的图像增强 (TTA),包括图像水平翻转,图像垂直翻转,图像对角线翻转 (每张预测图像将被增强 2×2×2 = 8次),然后还原输出图像以匹配原始图像。
2、Dense Fusion:密集融合网络(DFCNet),其结构示意图如下:
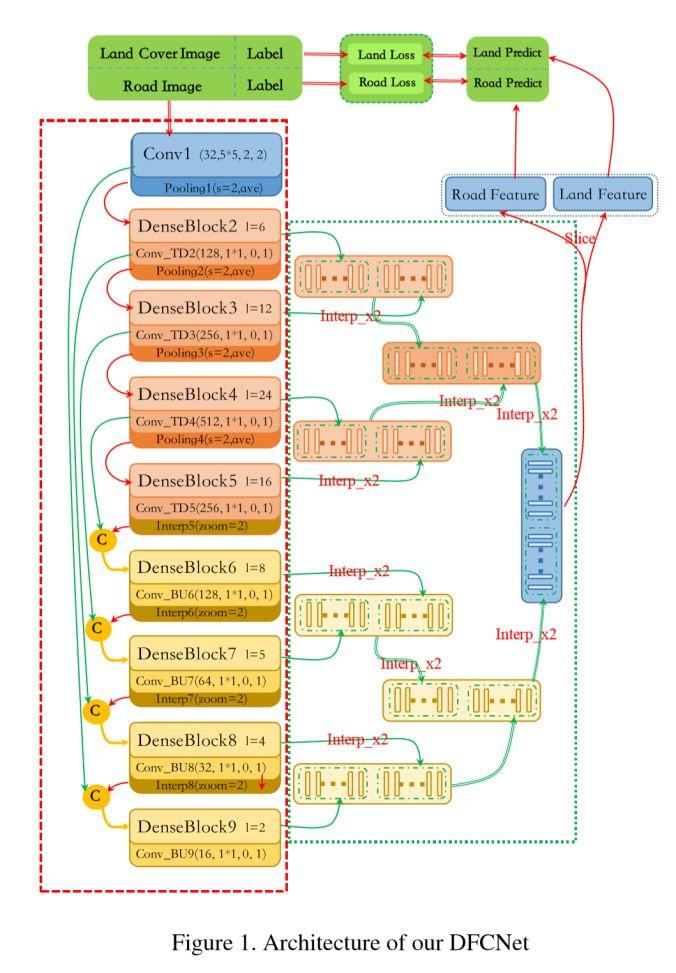
Multi-task U-net:其结构示意图如下:
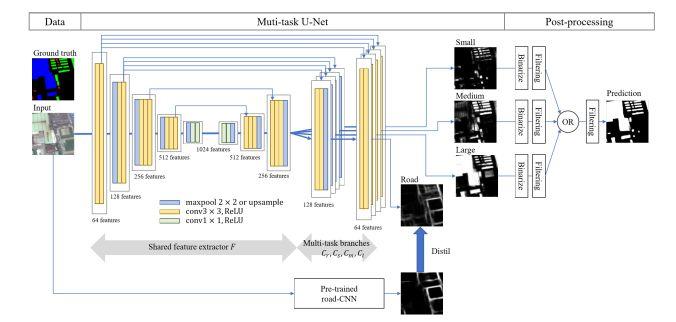
数据集:高分辨率的卫星图像数据集及其相应的训练数据。
应用场景:可用于三种任务挑战--道路特征提取,建筑物检测及地面覆盖物分类。
其他观点:对于实例分割任务,除了少数一两个研究中使用到 maskRCNN 结构,其他的研究都是基于 Unet 网络展开的,如 stacked Unet,NU-net,multi-task Unet等。
项目主页链接:
http://deepglobe.org/
模块主题五:Interpretable Machine Learning for Computer Vision (计算机视觉中可解释性的机器学习)
亮点:可解释性并不是要理解模型中所有数据点的所有细节。
架构和技术细节:详细介绍在下面的链接中
应用场景:当你向别人展示一个 AI 项目时,大多数人仍然认为 AI 是一个黑盒子。而该研究能够为这一切提供不错的解释。
其他观点:
何时需要可解释性:当我们无法将想法形式化时,可解释性可以帮助我们实现。
何时不需要可解释性:你只需要预测的情况;已被充分研究的问题;不匹配的目标问题等。
可解释性的例子:EDA;规则解读;例子;稀疏性和单调性;消融测试 (ablation test);输入特征的重要性;概念的重要性等。
如何评估:通过实验 (human experiment and ground-truth experiment)。
关于 t-sne可视化 (google 有一篇关于 t-sne 可视化的文章):使用 T-SNE 可视化模型的思考方式。
参考链接:
http://deeplearning.csail.mit.edu/slide_cvpr2018/been_cvpr18tutorial.pdf
https://interpretablevision.github.io/
模块主题六:What do deep networks like to see? (深度神经网络喜欢看什么?)
亮点:对分类器进行交叉式重建。
架构和技术细节:其结构示意图如下:
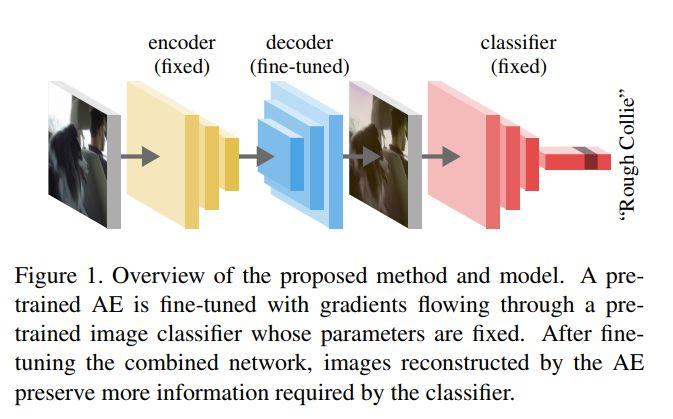
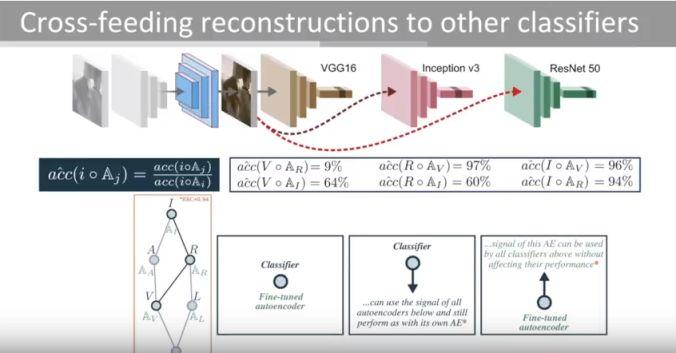
数据集:YFCC100m,Imagenet
应用场景:解释或理解 CNNs。
其他观点:该研究深入了解深度神经网络的每一层,这可能有助于选择所要切割的层,提取图像特征以及使用这些特征来训练新模型。
项目主页链接:
https://spalaciob.github.io/s2snets.html
模块主题七:Context Encoding for Semantic Segmentation (用于语义分割的上下文编码)
亮点:相比于 FCN,上下文编码模块在略微增加计算成本的情况下,能够显著地改善语义分割的结果。总的说来,该研究的主要贡献包括:提出语义编码丢失 (SE-loss):这是一个利用全局场景的上下文信息的单元。实现了一个新的语义分割框架:上下文编码网络 EncNet,增强了一个预训练好的深度残差网络。
架构和技术细节:该模块能够选择性地突出与类别相关的特征映射,并简化了网络的问题。该模型在 ADE20K 测试集上取得了0.5567的最终得分,超过了 COCO Challenge 2017 的获胜者的表现。此外,它还改进了相对阴影网络的特征表示,这是在 CIFAR-10 数据集上用于图像分类任务的模型。其结构示意图如下:
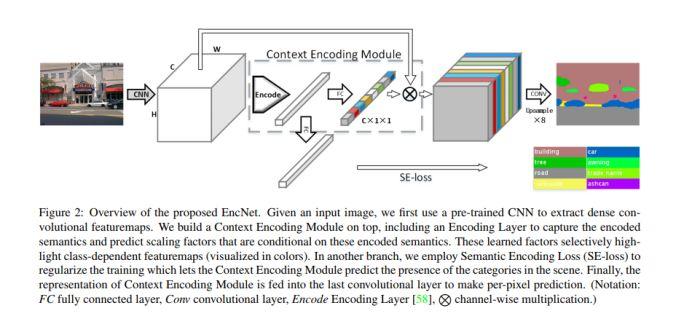
数据集:PSCAL-Context 数据集,PASCAL VOC 2012 数据集,ADE20K 数据集,CIFAR-10 数据集
应用场景:语音分割任务
论文及 github 链接:
https://arxiv.org/pdf/1803.08904.pdf
http://hangzh.com/PyTorch-Encoding/experiments/segmentation.html
https://github.com/zhanghang1989/PyTorch-Encoding
模块主题八:Learn to See in the dark (“暗夜之眼”:学会在黑暗中观察)
亮点:训练一个端到端的全卷积神经网络,用于处理低光图像。
架构和技术细节:其结构示意图如下:
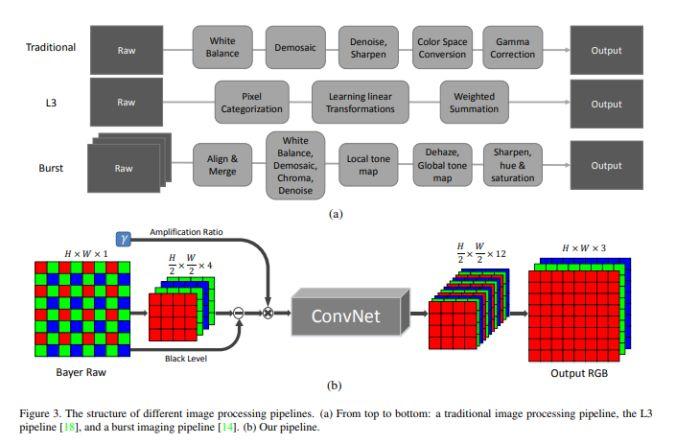
数据集:研究中使用的数据集由作者收集的,包括夜间的室内和室外图像,共5094个原始短曝光图像。
应用场景:图像处理
其他观点:未来我们要思考的是这项研究能否封装成一个 API,以方便使用。
论文及 github 链接:
https://arxiv.org/pdf/1805.01934.pdf
https://github.com/cchen156/Learning-to-See-in-the-Dark
三、 图像增强及操作
模块主题一:xUnit: Learning a Spatial Activation Function for Efficient Image Restoration (xUit:用于图像还原的高效空间激活函数)
亮点:该研究提出的方法能够显著地减少模型学习过程的参数量,特别是对用于图像超分辨率和图像去噪的神经网络,其参数量减少了一半以上。
架构和技术细节:与逐像素的激活单元 (如 ReLU 和 sigmoids) 相比,该研究提出的函数单元是一个具有空间连接性的可学习的非线性函数,这使得网络能够捕获更复杂的特征。因此,网络以更少的层数就能达到相同的性能。其结构示意图如下。
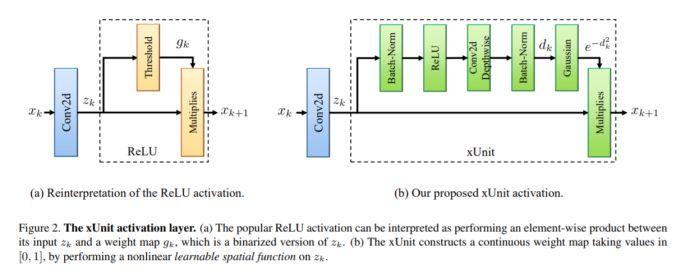
数据集:BSD68 数据集和Rain12 数据集
应用场景:图像超分辨率和图像去燥
论文及 github 链接:
https://arxiv.org/abs/1711.06445
https://github.com/kligvasser/xUnit
模块主题二:Deformation Aware Image Compression (变形可感知的图像压缩技术)
亮点:该研究中编码器无需过多地描述精细结构的几何形状,而只需要着重描述一些重要部分的几何结构,这将大大提高了细节保存的效果 (研究结果已经验证)。
架构和技术细节:该研究很容易与其他的 CODEC 相结合。由于人类观察者对部件轻微的局部平移性并不重视,受此启发作者提出了 SSD 的变形不敏感版本 (以平方差的和作为度量):变形可感知的 SSD 结构 (DASSD)。
数据集:Berkley 的图像分割数据集和Kodak 数据集
应用场景:图像压缩
其他观点:该研究所展现的视觉效果令人震撼。
论文链接:
https://arxiv.org/abs/1804.04593
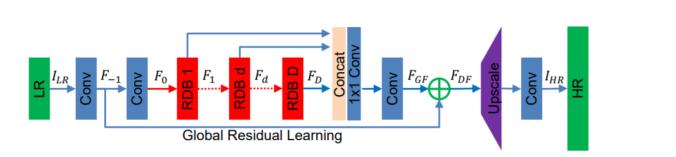
模块主题三:Residual Dense Network for Image Super-Resolution (用于图像超分辨率的残差密集型网络)
亮点:该研究的目标是充分利用原始低分辨率 (LR) 图像的分层特征。
架构和技术细节:其结构示意图如下:
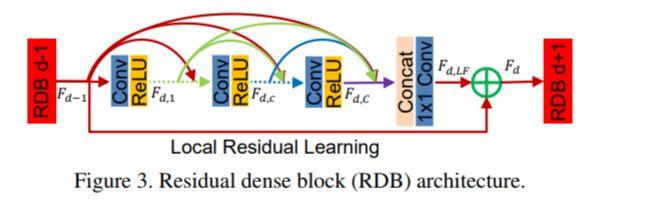
RGB 模块的结构示意图如下:
数据集:DIV2K 数据集,Set5 数据集,Set14 数据集,B100 数据集,Urban100 数据集,Manga109 数据集
应用场景:图像增强
论文和 github 链接:
https://arxiv.org/abs/1802.08797
https://github.com/yulunzhang/RDN
模块主题四:Attentive Generative Adversarial Network for Raindrop Removal from a Single Image (用于单幅图像雨滴去除的注意力生成对抗网络)
亮点:该研究将视觉注意力机制引入生成对抗网络,在这里的注意力主要是针对特定的雨滴区域。
架构和技术细节:该研究的模型混合了带 LSTMs 的 GANs 和 Unet 网络,其结构示意图如下:
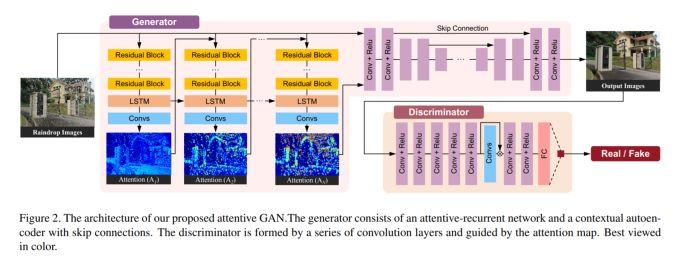
数据集:该研究使用的数据集含有 1K 图像对。为了准备数据集,研究中作者在拍照时使用了两块完全相同的玻璃:一块玻璃上带水滴,而另一块保持清洁,以便形成对比。
应用场景:图像编辑处理
其他观点:该研究使用预训练好的 VGG-16 模型所展现的视觉效果令人震撼,如下图所示。

论文链接:
https://arxiv.org/abs/1711.10098
模块主题五:Burst Denoising with Kernel Prediction Networks (用于图像去燥的核预测网络)
亮点:该研究中采用 CNN 结构预测空间变化核,它可以用于图像对齐和去燥。此外,研究中采用的一种有意思的数据生成方式,用于模型训练。
架构和技术细节:模型的结构示意图如下:
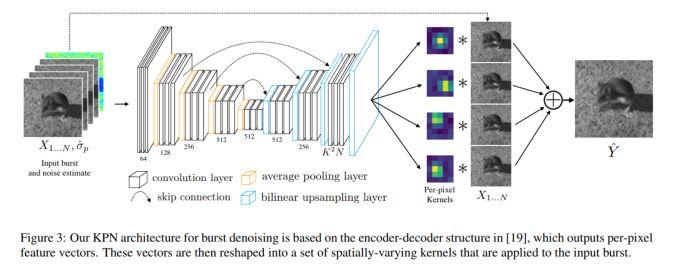
数据集:使用开放图像数据集的图像数据来合成训练数据:修改图像以引入合成的训练数据,这些数据是未对齐的和近似噪声的图像。为了生成 N 帧的合成数据,作者采用单张图像并生成 N 张未对齐的、裁剪后的图像补丁 (cropped patches)。
应用场景:图像相关的应用
其他观点:在真实的数据集上 (昏暗条件下用 Nexus 6P手机拍摄),作者声称了该研究具有良好的表现:模型是在合成数据集上进行训练的,经一些图像预处理后在真实数据集进行基准测试,其中图像预处理操作包括:去除黑暗度,抑制热点像素 (hot pixels),交替帧的全像素对齐等。
论文和 github 链接:
https://arxiv.org/abs/1712.02327
https://github.com/google/burst-denoising
模块主题六:Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning (利用深度强化学习精心设计的 Toolchain 用于图像还原)
亮点:Toolbox 由专门处理小规模不同任务的 CNN 结构和 RL 组成:通过学习策略来选择最合适的工具以便恢复受损图像。
架构和技术细节:模型的结构示意图如下:
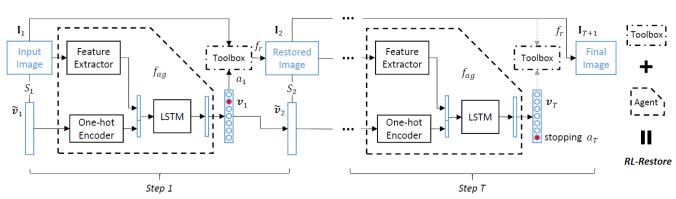
数据集:DIV2K 数据集,一个受损图像的数据集并添加部分合成的数据。
应用场景:图像相关的应用
其他观点:该研究在真实数据集上表现得相当良好。智能代理能够自主决定何时停止图像恢复。此外,该框架也能处理并恢复真实图像的扭曲。
项目主页和 github 链接:
http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/
http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/
四、基于目标驱动的导航系统及室内 3D 场景
模块主题一:Density Adaptive Point Set Registration (基于密度自适应机制的点集配准研究)
亮点:该研究能够成功解决地面激光雷达应用中常见的密度严重变化问题。
架构和技术细节:将场景的潜在结构视为一个潜在的概率分布模型,以保证点集密度变化的不变性。然后,基于期望最大化的框架,通过最小化 Kullback-Leibler 散度来推断场景的概率模型及其配准参数。该研究中还引入了观察的权重函数。
数据集:合成数据集:通过在室内3D场景的多边形网格上模拟点采样过程来构建合成点云数据。此外,研究中还使用到 Virtual Photo 数据集和 ETH TLS 数据集。
应用场景:激光相关的应用,3D 地图,场景理解等。
其他观点:该研究的作者在几个具有挑战性的、来自真实世界的激光雷达数据集上进行了大量实验,并对3D 场景的基础结构和采集过程进行建模,以获得对密度变化的鲁棒性。
论文链接:
https://arxiv.org/abs/1804.01495
模块主题二:Im2Pano3D: Extrapolating 360 Structure and Semantics Beyond the Field of View (通过外推法获取360度的结构及视野外的语义信息)
亮点:为了简化 3D 结构的预测,我们提出一种平面方程来对3D 表面进行参数化,并训练模型对这些参数进行直接预测。
架构和技术细节:
该研究的核心思想:利用室内环境的高度结构化,通过学习许多典型场景的统计数据,模型能够利用强大的上下文信息来预测超出视野范围 (Field of View,FoV) 的内容。
使用多个损失函数:逐像素精度损失,使用 Patch-GAN 获取的 mid-level 上下文一致性的对抗损失,以及通过场景类别和目标分布的全局场景一致性测量。最终,每个通道的损失是这三个损失的加权和。
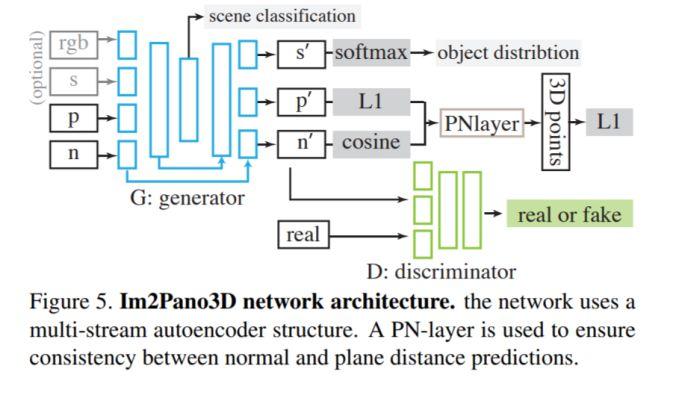
数据集:3D House 数据,其中包含合成的房间 (SUNCG) 和真实的房间(Matterplot3D)。
应用场景:机器人应用,基于目标驱动的导航,下一最佳视角的估计等。
其他观点:Im2Pano3D 能够预测未知场景的 3D 结构和语义信息,实现超过56%的像素精度和小于 0.52m 的平均距离误差。研究还表明经合成数据 SUNCG预训练,能够显著地提高了模型的性能。此外,论文进一步介绍了人类应对场景补全任务的研究结果:虽然目前神经网络的效果并不是很好,但却是非常有前途的一个方向。
项目主页和 github 链接:
http://im2pano3d.cs.princeton.edu/
https://github.com/shurans/im2pano3d
模块主题三:Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments (视觉到语言:在真实环境中解释视觉的指示信息)
亮点:真实环境中平均的指示信息长度:29个由自然语言构成的单词。该研究提出第一个用于真实建筑物导航的基准数据集。
架构和技术细节:研究中采用 RNN (Seq2Seq LSTM) 结构。
数据集:Matterport3D 数据集,Room-to-Room (R2R) 数据集,测试数据集采用的是未知的建筑物数据。
应用场景:机器人应用
其他观点:这是一项成功的研究:作者介绍了 Matterport3D 模拟器,这是一个基于 Matterport3D 数据集的智能代理研究,并开发了新型大规模 RL 可视化的模拟环境。
项目主页链接:
https://bringmeaspoon.org/
模块主题四:Sim2Real View Invariant Visual Servoing by Recurrent Control (通过循环控制的 Sim2Real 视觉视角不变形研究)
亮点:视觉服务系统利用其对过去运动的记忆来理解动作如何在当前的视觉点影响机器人运动,纠正错误并逐渐靠近目标。研究中使用模拟数据和一个强化学习目标来学习该循环控制器。
架构和技术细节:视觉服务系统主要使用视觉反馈机制将工具或终点移动到所需位置。该研究的目标是由要查询的目标图像所指示,并且网络必须都找出该目标在图像中的位置。模型的结构示意图如下:
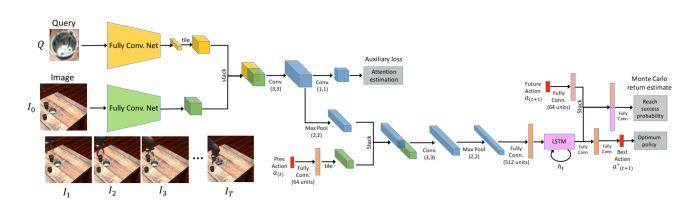
数据集:通过大量生成具有不同相机位置,对象和纹理数据来合成强监督的训练数据。
应用场景:机器人应用
其他观点:这是一项有趣,但无法马上投入生产应用的研究。
论文和项目主页链接:
https://arxiv.org/pdf/1712.07642
https://fsadeghi.github.io/Sim2RealViewInvariantServo/
五、人物相关性分析
模块主题一:Divide and Grow: Capturing Huge Diversity in Crowd Images With Incrementally Growing CNN (用递增式 CNN 结构来捕捉图像中人群的多样性)
亮点:该研究采用递归式的 CNN 结构来估计人群数量。
架构和技术细节:在预训练基础 CNN 模型后,逐步构建 CNN 树模型,其中每个节点表示在子数据集上微调的回归量。回归量的计算是通过复制树叶节点每个回归量并经差分训练专门化子网络来实现的。模型的结构示意图如下:
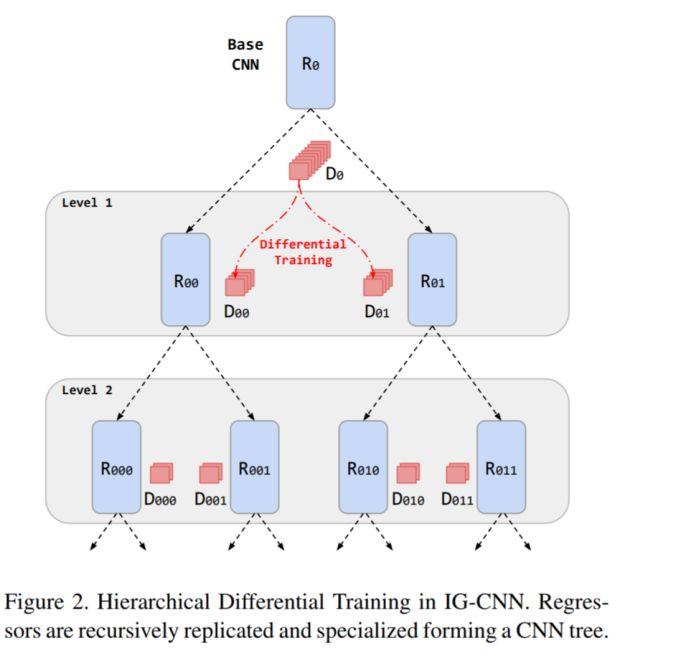
数据集:Shanghaitech 数据集,UCF CC 50 数据集,World Expo10 数据集。
应用场景:与监视有关的应用
其他观点:该研究的一大亮点是其度量标准:采用平均绝对误差和均方误差结合。此外,CNN 树结构的叶节点处的回归量是在没有任何手动指定标准的情况下才记得到的,无需任何的专家干预。
论文链接:
http://openaccess.thecvf.com/content_cvpr_2018/html/2726.html
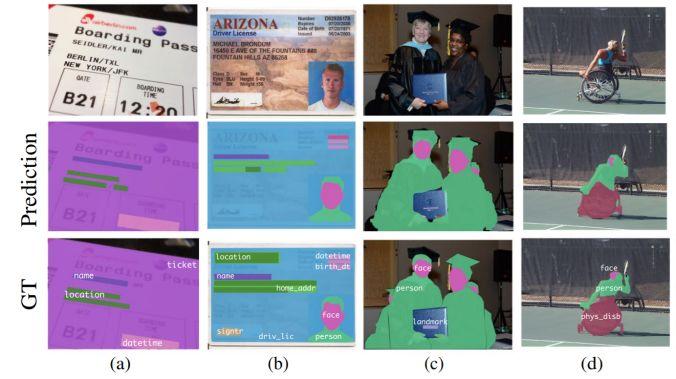
模块主题二:Connecting Pixels to Privacy and Utility: Automatic Redaction of Private Information in Images (将像素与个人隐私和实用程序相连接:自动编辑图像中的私人信息)
亮点:这是第一个能够自动编辑各种私人信息的研究。也是第一个提出大型的私人图像数据集,这些数据都是在真实环境中采集得到的,研究中对各种隐私类别进行像素和实例级别的标签注释。
架构和技术细节:该研究的主要挑战是要对多种形式的私人信息 (Textual,Visual,Multimodal) 进行跨形式、多属性的整体编辑。模型的结构示意图如下:
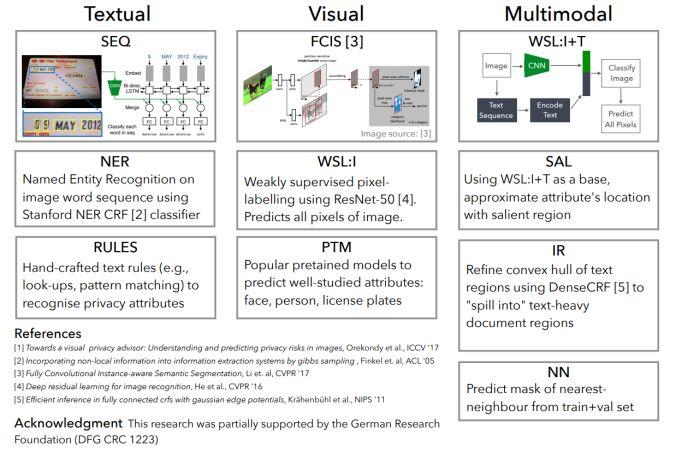
数据集:该研究采用新的数据集,扩展了原始的 Visual Privacy (VISPR) 数据集,增加了高质量的像素和实例级标签注释。最终,作者提出了一个包含 8.5k 张图像的数据集,这些图像对24种隐私属性进行了 47.6k 个实例注释。
应用场景:隐私数据的清洗
其他观点:该研究所提出的方法在手动编辑的情况下能够有效地实现对多种隐私信息与实用程序的权衡,取得83%的性能表现。
项目主页和 github 链接:
https://resources.mpi-inf.mpg.de/d2/orekondy/redactions/
https://github.com/tribhuvanesh/visual_redactions
模块主题三:Fashion AI (时尚界的 AI)
亮点:这是来自阿里巴巴团队提出的 Fashion AI 研究。
架构和技术细节:该研究能够根据时尚的衣服图片自动创建属于你自己的衣柜。

数据集:数据来源主要包括两个方面:首先是来自淘宝上的很多衣服图片。此外,在 Google 上使用属性名称进行关键词搜索以获取大量的衣服图像数据。总的来说,最终每个属性有 100-300 张图片,共由 12K 张图片数据构成。
应用场景:阿里巴巴提出的 Fashion AI 应用能够为造型师自动化地探索服装的搭配。首先,探索多张图像并尝试识别不同风格的衣服。接着,在网站上基于给定的一件 T 恤,Fashion AI 能够为你推荐相匹配的裤子或裙子。
论文链接在:
https://arxiv.org/pdf/1712.02662.pdf
六、高效的深度神经网络
模块主题一:Efficient and accurate CNN Models at Edge compute platforms (用于Edge 计算平台的高效而精准的 CNN 模型)
亮点:该研究提出的 CNN 模型在 DeepLens 上以 CPU 运行实时的目标检测的速度比在 GPU 上更快。
架构和技术细节:该研究由 XNOR.AI 团队提出。随着对 Edge 设备隐私性、安全性及带宽的需求不断增长,该研究团队提出了自己的解决方案:
精度较低 (量化):固定点,二进制 (XNOR-Net)
稀疏模型:基于 CNN 的查找和分解
紧凑型网络设计:移动网络 (Mobile Net)
如何提高准确性:标签精炼。
应用场景:用于 Edge 设备
其他观点:图像标签应该是富含类别的信息的一种软标识。当前图像标签所面临的挑战 (以 Imagenet 为例):
标签具有误导性:如下图“波斯猫”的例子:
在无需任何背景的情况下,随机裁剪可以制作训练数据。
如果 chihuahua 被错误分类为猫或汽车,则会受到同等量级的惩罚。

模块主题二:Co-Design of Deep Neural Nets and Neural Net Accelerators for Embedded Vision Applications (为嵌入式视觉应用联合设计深度神经网络及其加速器)
亮点:该研究提出的观点是深度神经网络及其加速器需要联合设计。
架构和技术细节:流行的神经网络及其进行目标检测的计算要求如下图所示(源于 MobileNetV2 论文):
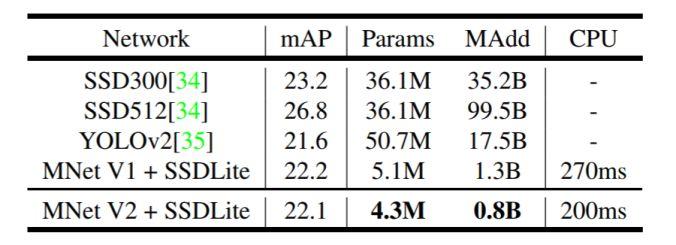

与操作相比,速度与内存访问的相关性更高更相关;与计算相比,能量消耗与存储器访问更相关。
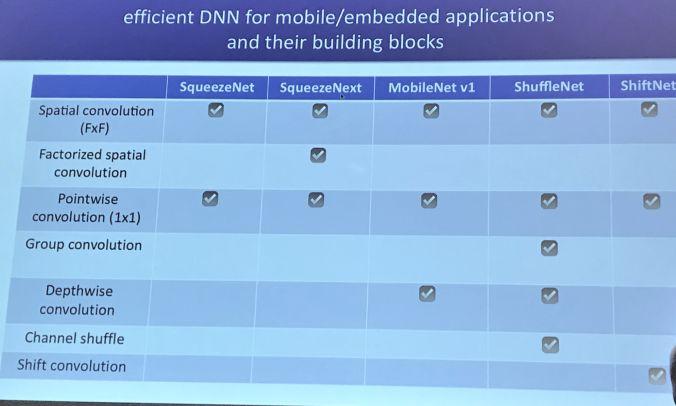
SqueezeNet 网络:基于硬件可感知的神经网络,其结构示意图如下:
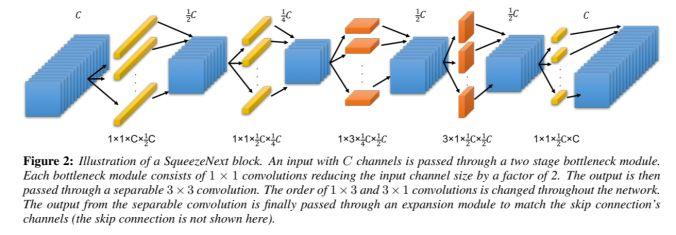
应用场景:用于 Edge 设备
其他观点:
高效的 DNN 计算的关键在于数据重用性。
不同的 CNN 层具有数据重用的不同模式。
不同的神经网络加速器架构支持不同数据类型的重用 (输出 vs 权重)
论文链接:
https://arxiv.org/abs/1804.10642
模块主题三:Intel deployment tutorial (Intel 的部署教程)
亮点:OpenCV 是计算机视觉领域最广泛使用的库。
架构和技术细节:“OpenVINO”(开源的视觉推理和神经网络优化工具包):这是被 Intel 内部广泛使用的计算机视觉工具包,包括跨 CPU,GPU,FPGA,VPU,IPU 等传统计算机视觉库 OpenCV 和深度学习工具包。
允许在 Edge 设备上进行基于 CNN 的深度学习推理。
在 Intel CV 加速器上支持跨平台的异构执行,使用支持 CPU ,Intel 集成显卡,Intel Movidius™ Neural Compute Stick 和 FPGA 的一个通用 API。
通过一个易于使用的 CV 函数库和预优化的内核,加快产品上市速度。
优化 CV 标准的调用,包括OpenCV *,OpenCL™和OpenVX *。
应用场景:本教程涉及到 OpenCV,在未来的 CV 项目可能还会更多地考虑关于 OpenCV的内容。
其他观点:这是一个用于高性能 CV 和 DL 推理的开发工具包,能够解决 CV 和 DL 部署的相关问题。
参考链接:
https://software.intel.com/en-us/openvino-toolkit
https://opencv.org/CVPR-2018-tutorial.html
七、文本与计算机视觉
模块主题一:DocUnet: Document Image Unwarping via A stacked U-Net (DocUnet:通过一个堆叠的 U-Net 展开文档图像)
亮点:本研究实现了一个具有中间层监督机制的堆叠 U-Net,以从失真图像直接预测其修正版本的前向映射图。
架构和技术细节:研究中提出的数据增强操作来提高模型的泛化能力:利用可描述的纹理数据集(DTD),产生各种背景纹理数据;在原始数据的 HSV 色彩空间中添加抖动处理以放大图像亮度和纸张颜色变化;通过一个投射变换来解决视角变化问题。模型的结构示意图如下图所示:
数据集:合成数据集,如下图所示:

应用场景:文本分析。
其他观点:该研究中使用合成数据集来训练模型,而在真实数据集上进行评估测试。

论文链接:
http://www.juew.org/publication/DocUNet.pdf
模块主题二:Document enhancement using visibility detection (基于视觉检测的文本增强研究)
亮点:本研究主要是基于计算机视觉检测技术,来实现文本的增强,其实验效果如下图所示。


架构和技术细节:
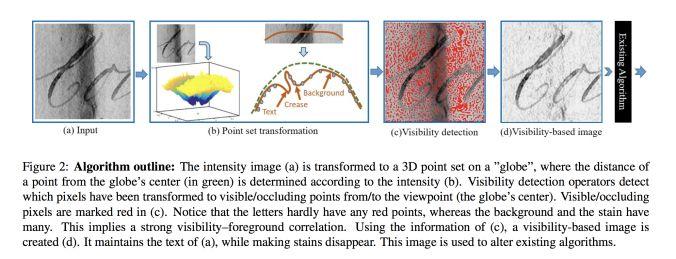
应用场景:文本图像的二值化,文本去阴影等应用。
其他观点:该研究可用于预处理文档,然后将图像传递给 OCR,实现在恶劣的光线条件下处理扭曲的文档图像。
论文链接:
http://webee.technion.ac.il/~ayellet/Ps/18-KKT.pdf
八、数据与计算机视觉
模块主题一:Generate To Adapt: Aligning Domains using Generative Adversarial Network (生成自适应:利用生成对抗网络实现域对齐)
亮点:本研究利用无监督数据,通过 GAN 拉近源分布和目标分布,使二者更接近联合的特征空间。
架构和技术细节:模型的结构示意图如下图所示:
源域的更新:使用监督分类丢失来更新 F 和 CNNs;F 和 G.D 使用对抗性损失来更新,以产生类别一致的源图像。
目标域更新:更新FNN,以便目标嵌入 (当通过 GAN 传递时) 产生类似的图像源;这里的损失将源特征表征和目标特征表征对齐。
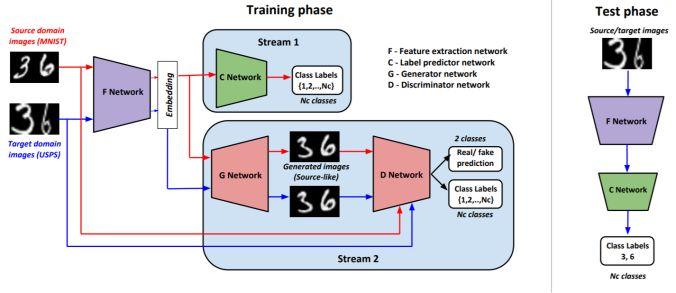
数据集:DIGITS 和 OFFICE 数据集。此外,从合成数据到真实数据的域自适应过程的数据集;从 CAD 数据集到 Pascal,VISDA 数据集。
应用场景:用于在未知数据上改善 CNN 的性能。
其他观点:
与 Office 实验相比,该研究中数字实验的图像生成质量更佳。
该研究中生成器能够以类别一致的方式为源输入和目标输入生成类似的源图像。
该研究中,Office 实验会出现模式崩溃 (mode collaspe) 现象。
该研究的 Office 实验表明,GAN 模型由合成图像生成逼真图像的困难使得以跨域图像生成的方法作为数据增强操作也变得非常困难。值得注意的是,研究中提出的方法依赖于图像生成,并将其作为特征提取网络导出丰富梯度模式,因此即使存在严重的模式崩溃现象和较差的生成质量,该方法也能很好地工作。
论文和 github 链接:
https://arxiv.org/abs/1704.01705
https://github.com/yogeshbalaji/Generate_To_Adapt
模块主题二:COCO-Stuff: Thing and Stuff Classes in Context (COCO-Stuff:上下文中的物体和填充物类别)
亮点:众所周知的是,COCO 数据集缺少数据标注。本项研究通过密集的、逐像素填充注释的方式来增强 COCO 数据集。
架构和技术细节:由于 COCO 数据是复杂的、含有大量物体的自然场景图像,因此 COCO-Stuff 这项研究能够探索不同物体之间的丰富关系,也能为完整的场景理解研究奠定基础。
数据集:COCO 2017 数据集,其中包含 164K 张图像,带有91个类别的像素标注。COCO-Stuff 包含172个类别:其中有 80个类别与 COCO 数据集中的相同。另外的91个类别是由专家标注的。还有1个未标注的类别只在两种情况下使用:如果标签不属于上述171个预定义类中的任何一个,或者标注工具无法推断像素的标签时才使用这个未标注类别。
应用场景:用于改善语义分割的性能。
论文链接:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Caesar_COCO-Stuff_Thing_and_CVPR_2018_paper.pdf
模块主题三:Workshop session: vision with sparse and scarce data (研讨会专题:稀疏数据和少量数据情况下的视觉研究)
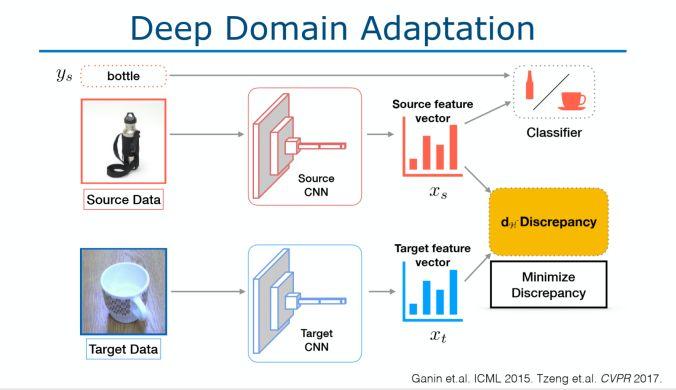
亮点:由 Judy Hoffman 演讲的关于 Make your data count 的报告。Imagenet 数据集有偏见的,因为它主要来自社交媒体的数据,例如人们喜欢将狗的正脸看作狗图片等等。在现实生活中,如果我们的数据是低分辨率的,运动模糊的或姿势变化的短视频,那么模型将无法很好地运行。
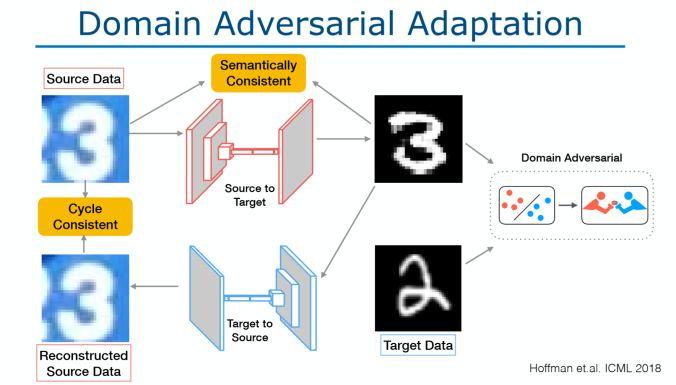
架构和技术细节:我们该如何改善模型的泛化能力呢?当视觉环境发生变化或出现偏差时,我们要让模型学习无法区分域的表示,可以通过下面两种方法实现:
深度域自适应:如下图所示。
域对抗自适应:如下图所示。
数据集:研究中采用 ImageNet 数据集和 SYNTHIA 数据集。
应用场景:
跨城市的自适应:以德国的数据进行训练,但是以旧金山的数据进行测试 (标志,隧道,道路大小)。
跨季节的自适应:采用 SYNTHIA数据集。
跨季节的像素自适应,以秋天的数据生成冬天的数据
合成真实像素的自适应:以合成的 GTA 数据进行训练,以德国的数据进行测试。
其他观点:从 Judy hoffman的演讲中可以发现:该研究涉及到 GANs 的知识,同时这也是计算机视觉中的常见问题。以往,我们通常都是使用转移学习来处理这些问题,但是 Judy hoffman 这次的演讲为我们提供了一些解决交叉自适应问题的新见解。
More and More
CVPR 2018 open access
http://openaccess.thecvf.com/CVPR2018.py
CVPR 2018 视频
https://www.youtube.com/results?search_query=CVPR18
此文链接:
https://olgalitech.wordpress.com/2018/06/30/cvpr-2018-recap-notes-and-trends/
技术头条 | CVPR 2019 系列论文:
CVPR 2019审稿满分论文:中国博士提出融合CV与NLP的视觉语言导航新方法
CVPR 2019 | 惊艳的SiamMask:开源快速同时进行目标跟踪与分割算法
CVPR 2019 | 微软、中科大开源基于深度高分辨表示学习的姿态估计算法
CVPR 2019 | 西工大开源拥挤人群数据集生成工具,大幅提升算法精度
CVPR 2019 | 斯坦福学者提出GIoU,目标检测任务的新Loss
微软亚研院提出用于语义分割的结构化知识蒸馏 | CVPR 2019
这么多优秀的论文解读,离不开 AI科技大本营的志愿者团队,在此对团队中的每一位小伙伴表示感谢!同时打个有品质的招募广告,团队一直有招新计划,在此向大家发出诚挚的邀请,希望爱刷 Paper、爱分享、爱钻研代码的你加入我们的团队!还有稿费可拿哦!(加入志愿者团队可微信联系 1092722531)
(本文为 AI大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。更多详细信息请咨询13581782348(微信同号)。

推荐阅读:

❤点击“阅读原文”,查看历史精彩文章。
一、力扣
1、最长连续序列

注意是遍历集合!!!否则会超时
java 代码解读复制代码class Solution {
public int longestConsecutive(int[] nums) {
int ans = 0;
Set st = new HashSet<>();
for (int num : nums) {
st.add(num); // 把 nums 转成哈希集合
}
for (int x : st) { // 遍历哈希集合
if (st.contains(x - 1)) {
continue;
}
// x 是序列的起点
int y = x + 1;
while (st.contains(y)) { // 不断查找下一个数是否在哈希集合中
y++;
}
// 循环结束后,y-1 是最后一个在哈希集合中的数
ans = Math.max(ans, y - x); // 从 x 到 y-1 一共 y-x 个数
}
return ans;
}
}
2、分发饼干

java 代码解读复制代码class Solution {
public int findContentChildren(int[] g, int[] s) {
Arrays.sort(s);
Arrays.sort(g);
int point=0,traget=0;
for(int i=0;i
if(s[i]>=g[traget]){
traget++;
point++;
}
}
return point;
}
}
3、买卖股票的最佳时机 II

贪心做法,相邻两天只要有利润,就进行交易
java 代码解读复制代码class Solution {
public int maxProfit(int[] prices) {
int ans = 0;
int n = prices.length;
for (int i = 1; i < n; ++i) {
ans += Math.max(0, prices[i] - prices[i - 1]);
}
return ans;
}
}
4、摆动序列

1. 贪心

java 代码解读复制代码class Solution {
public int wiggleMaxLength(int[] nums) {
// 处理特殊情况:数组长度为0或1时,直接返回长度
if (nums.length <= 1) {
return nums.length;
}
// 当前差值(当前元素与前一个元素的差)
int curDiff = 0;
// 上一个有效差值(记录波峰或波谷的变化方向)
int preDiff = 0;
// 计数器,初始为1,因为至少有一个元素
int count = 1;
for (int i = 1; i < nums.length; i++) {
curDiff = nums[i] - nums[i - 1];
// 当当前差值与上一个有效差值符号相反时,说明出现摆动
// 注意:当preDiff为0时(初始状态或连续相等情况),只要当前差值非0即视为有效摆动
if ((curDiff > 0 && preDiff <= 0) || (curDiff < 0 && preDiff >= 0)) {
count++;
preDiff = curDiff; // 更新上一个有效差值
}
}
return count;
}
}
2. 动态规划

java 代码解读复制代码class Solution {
public int wiggleMaxLength(int[] nums) {
// dp[i][0]表示以nums[i]为波峰时的最长摆动子序列长度
// dp[i][1]表示以nums[i]为波谷时的最长摆动子序列长度
int[][] dp = new int[nums.length][2];
// 初始化:每个元素自身至少可以构成长度为1的子序列
for(int i=0;i
Arrays.fill(dp[i],1);
}
for (int i = 1; i < nums.length; i++) {
// 遍历所有可能的j < i,更新状态
for (int j = 0; j < i; j++) {
if (nums[j] > nums[i]) {
// 当前元素nums[i]比nums[j]小,可作为波谷
// 取nums[j]作为波峰时的最长长度,并加上当前元素
dp[i][1] = Math.max(dp[i][1], dp[j][0] + 1);
} else if (nums[j] < nums[i]) {
// 当前元素nums[i]比nums[j]大,可作为波峰
// 取nums[j]作为波谷时的最长长度,并加上当前元素
dp[i][0] = Math.max(dp[i][0], dp[j][1] + 1);
}
// 若nums[j] == nums[i],不影响状态,无需处理
}
}
// 最终结果取最后一个元素作为波峰或波谷的最大值
return Math.max(dp[nums.length - 1][0], dp[nums.length - 1][1]);
}
}
5、最大子数组和

dp[i]为以nums[i]结尾的最大子数组和。
java 代码解读复制代码class Solution {
public int maxSubArray(int[] nums) {
int res=nums[0];
int n=nums.length;
int[] dp=new int[n];
dp[0]=res;
for(int i=1;i
dp[i]=nums[i]+Math.max(0,dp[i-1]);
res=Math.max(dp[i],res);
}
return res;
}
}
java 代码解读复制代码class Solution {
public int maxSubArray(int[] nums) {
if (nums.length == 1){
return nums[0];
}
int sum = Integer.MIN_VALUE;
int count = 0;
for (int i = 0; i < nums.length; i++){
count += nums[i];
sum = Math.max(sum, count); // 取区间累计的最大值(相当于不断确定最大子序终止位置)
if (count <= 0){
count = 0; // 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
}
}
return sum;
}
}
6、跳跃游戏

java 代码解读复制代码class Solution {
public boolean canJump(int[] nums) {
int n=nums.length;
int nexright=0;
for(int i=0;i
if(i<=nexright){
nexright=Math.max(nexright,i+nums[i]);
}else{
return false;
}
}
return true;
}
}
评论记录:
回复评论: