
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~

「2019 Python开发者日」7折优惠最后3天,请扫码咨询 ↑↑↑
作者 | Lin-Zhuo Chen
转载自博客
链接:https://linzhuo.xyz/posts/DUpsample/
今天为大家推荐一篇 CVPR2019 关于语义分割的文章 Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation,该文章提出了一种不同于双线性插值的上采样方法,能够更好的建立每个像素之间预测的相关性。得益于这个强大的上采样方法,模型能够减少对特征图分辨率的依赖,能极大的减少运算量。该工作在 PASCAL VOC 数据集上达到了 88.1% 的 mIOU,超过了 DeeplabV3 + 的同时只有其 30% 的计算量。
论文传送门:https://arxiv.org/abs/1903.02120
1. Introduction
在之前的语义分割方法中,双线性插值通常作为其最后一步来还原特征图的分辨率,由于非线性差值不能建立起每个像素的预测之间的关系,因此为了得到精细的结果,对特征图的分辨率要求较高,同时带来了巨额的计算量。
为了解决这个问题,本工作提出了 Data-dependent Up-sampling (DUpsample),能够减少上采样操作对特征图分辨率的依赖,大量的减少计算量。同时得益于 DUpsample, Encoder 中的 low-level feature 能够以更小的运算量与 Decoder 中的 high-level feature 进行融合,模型结构如下所示:
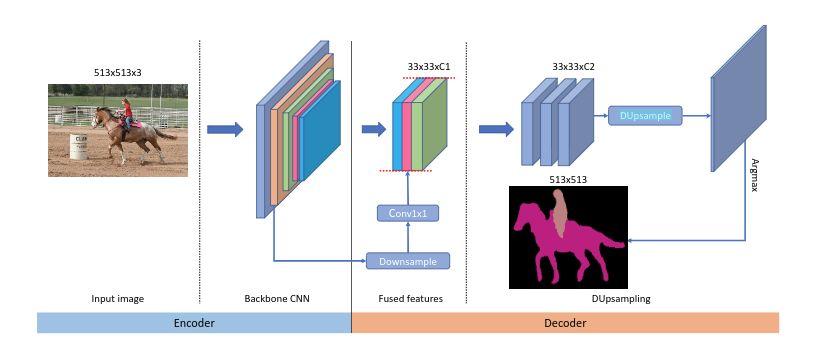
我们可以看到,该网络将传统的非线性插值替换成 DUpsample,同时在 feature fuse 方面,不同于之前方法将 Decoder 中的特征上采样与 Encoder 特征融合,本工作将 Encoder 中的特征下采样与 Decoder 融合,大大减少了计算量 ,这都得益于 DUpsample。
2. Our Approach
之前的语义分割方法使用下列公式来得到最终的损失:
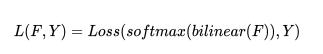
其中 Loss 通常为交叉熵损失,F 为特征图,Y 为 ground truth,由于双线性插值过于简单,对特征图 F 的分辨率较高,因此引入了大量的计算。一个重要的发现是语义分割输入图像的 label Y 并不是 i.i.d 的,所以 Y 可以被压缩成 Y′,我们令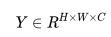 , 并将 Y 划分成
, 并将 Y 划分成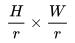 的子窗口,每个子窗口的大小为 r×r,接着我们将每个子窗口
的子窗口,每个子窗口的大小为 r×r,接着我们将每个子窗口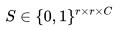 拉伸成向量
拉伸成向量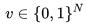 ,其中
,其中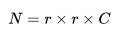 ,随即我们将向量 v 压缩成低维向量 x,我们使用线性投影来完成,最后,我们有:
,随即我们将向量 v 压缩成低维向量 x,我们使用线性投影来完成,最后,我们有: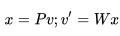 ,其中
,其中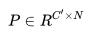 ,用来将 v 压缩成 x,
,用来将 v 压缩成 x,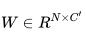 为 reconstruction matrix, v′为重建后的 v,我们可以用压缩后的向量 x 组合成 Y′.
为 reconstruction matrix, v′为重建后的 v,我们可以用压缩后的向量 x 组合成 Y′.
矩阵 P 和矩阵 W 可以通过最小化下列式子得到:
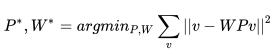
我们可以使用梯度下降,或者在正交约束的条件下使用 PCA 求解。
使用压缩后的 Y′为目标,我们可以使用下列损失函数来预训练网络:
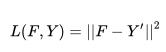
另一种直接的方法是在 Y 空间计算 loss,也就是并非将 Y 压缩到 Y′, 我们可以将 F 使用 W(上面预训练得到的)上采样然后计算损失,公式如下:
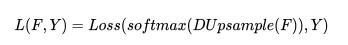
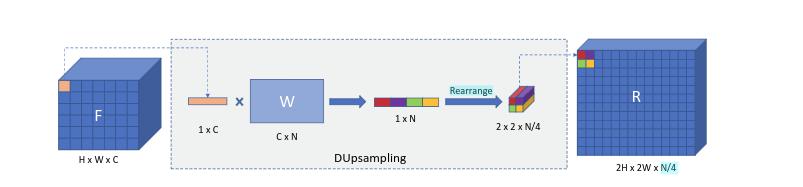
其中以两倍为例,DUpsample 的操作如下图所示:
我们可以用 1X1 卷积来完成上述的权重与特征相乘的过程。但是当我们将这个模块嵌入到网络时会遇到优化问题。因此我们使用 softmax with temperature 函数来解决这个问题: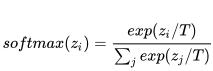 。
。
我们发现 T 可以使用梯度下降学习得到,这样减少了调试的麻烦。
有大量的工作说明,与 low-level features 结合可以显著的提升分割的精度,其做法如下: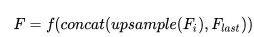 ,
,
f 是在上采样之后的卷积操作,其计算量依赖于特征图的空间大小,这样做会显著增加计算量。得益于 DUpsample,我们可以使用下列操作来减少计算量:
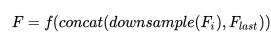 ,
,
这样做不仅保证了在低分辨率下的有效性,而且减少了计算量,同时允许任意 level feature 的融合。
只有使用了 DUpsample,上述操作才变得可行,否则语义分割的精度会被双线性插值限制。
3. Experiments
本次实验使用以下两种数据集:PASCAL VOC 2012 和 PASCAL Context benchmark。我们使用 ResNet-50 或 Xception-50 作为我们的 backbone,具体训练细节详见论文。
首先我们设计实验说明双线性插值的上限远远低于 DUpsample。首先我们搭建一个简易网络实现 auto-encoder,其中上采样方式分别使用双线性插值与 DUpsample, 输入分别为 ground_truth,得到下表中的 mIOU*,这个指标代表上采样方法的上限。同时我们使用 ResNet50 作为主干网络,输入为 raw image 去实现语义分割,得到下表中的 mIOU:
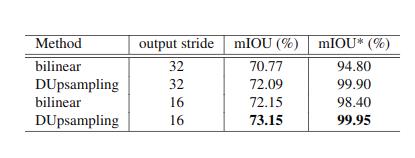
通过上表我们可以发现:
1) 在相同条件下,DUpsampling 效果优于 bilinear。
2)DUpsampling 在 output_stride=32 的情况下效果与 bilinear 在 output_stride=16 的情况下结果相当。
接下来我们设计实验说明融合不同的 low-level 特征对结果的影响,如下表所示:
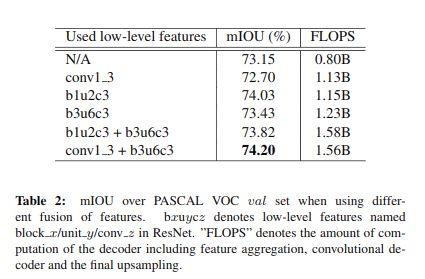
值得说明的是,并不是所有与 low-level feature 的融合都会提升结果,例如 conv1_3,因为其结果不够鲁棒。因此和什么 low-level feature 相结合对语义分割的结果有很大的影响。
接下来我们设计实验与双线性插值进行比较:
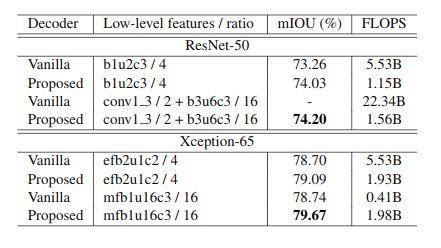
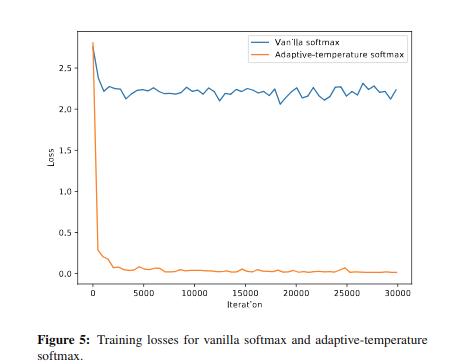
可以看到我们的方法优于传统的双线性插值上采样方法。同时我们验证了不同的 softmax 对结果的影响,在没有使用 softmax with tenperature 的情况下只有 69.81 的 mIOU(这里没设置消融实验有些疑惑,感觉不同的 softmax 对实验结果影响挺大的)。
最后将我们的方法与最新的模型进行比较,结果如下(分别为 PASCAL VOC 与 PASCAL context):
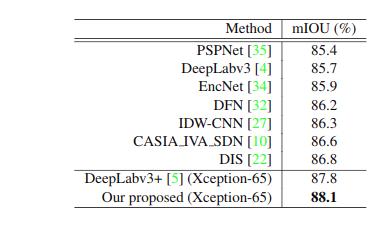
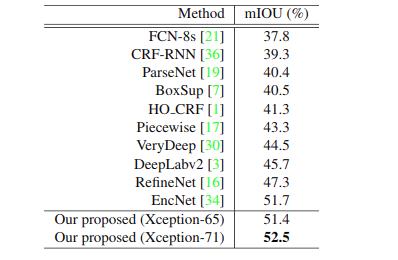
我们的方法在只用 deeplabv3+ 30% 的计算量的情况下,超越了当前所有的方法。
总的来说,我觉得这个论文提出的想法很有趣,是一篇很有 insight 的论文。
由于论文现在还没有开源,笔者尝试实现了一下 DUpsample 的操作和网络:
https://github.com/LinZhuoChen/DUpsampling。
目前还在建设中,欢迎大家关注和 star。
(*本文是AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆

推荐阅读:

❤点击“阅读原文”,查看历史精彩文章。
评论记录:
回复评论: