

尽管一再否认进入汽车制造行业,但作为科技领域的巨头,华为在自动驾驶领域的研究动作颇受外界关注。

作者 | 李娜 胡婳溦
本文经授权转自第一财经(ID:cbn-yicai)
四大项目,挑战Python全栈工程师?
https://edu.csdn.net/topic/python115?utm_source=csdn_bw
2018 年,华为相继与一汽、北汽、上汽、东风、广汽、长安、奥迪、奔驰等车企进行合作,其中和北汽的合作得到北汽集团董事长徐和谊的高度评价,双方还进行了第二次战略签约,并且成立了 1873 戴维森创新实验室。
此外,在一份疑似来自于华为内部高管的讲话中提到,华为目前已经掌握了自动驾驶的核心技术。该名高管称,“未来自动驾驶能力的电动汽车,除了底盘,4 个轮子,外壳和座椅外剩下的都是华为拥有的技术。”
换句话说,华为已经具备了“造车”的能力。
可以看到,这几年随着人工智能、大数据、云计算技术的快速发展,汽车的工业生态、产品形状和商业模式都进入了新的变革中,以无人驾驭、车联网为代表的智能化已成为未来汽车工业差异化竞赛的制高点。而科技企业的加入,更是将“造车新势力”的声量一路推高,汽车跑道上出现了不少新的面孔。
但相比于传统汽车巨头所掌握的整车技术以及搭建的完整的供应链和销售体系,科技企业的加入能够为这个行业带来什么样的影响?像华为、苹果、百度这样的科技公司又对于自动驾驶有着什么样变革,传统汽车企业和互联网企业谁能主宰未来的“自动驾驶”市场?显然,现在还没有一个统一的答案。

造不造车?
在外界看来,华为这几年在“造车”上动作频频。
两年前,华为与清华大学进行无人驾驶汽车深度技术合作的消息被广泛传播,一张看似简陋的无人车的“雏形”也被曝光。而后,华为又高调宣布与奥迪等车企联手开发 5G 汽车。华为消费者者 BG 手机产品线总裁何刚甚至在社交媒体上表示,5G 联网汽车在 2020 年前有望问世。“此次奥迪与华为的合作,将在两年内推出实体化的汽车产品,提供在实现完全自动驾驶之前的辅助驾驶系统。”
而去年发布的 OceanConnect 车联网平台更是把华为的“汽车梦”推至高潮,喊出的口号“数字化每一辆车”背后似乎隐藏着这家企业在汽车领域的野心。
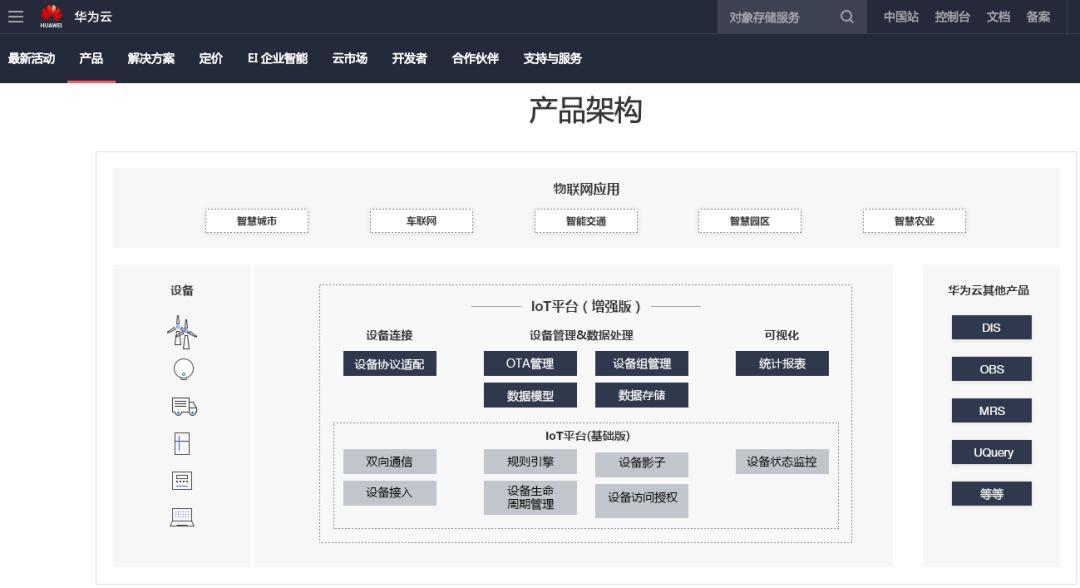
华为 OceanConnect IoT 平台:
https://www.huaweicloud.com/product/iot.html
但无论是内部还是外部,去年还是今年,华为的官方态度一如既往:华为将专注于 ICT 领域,主张与汽车制造企业广泛合作。“公司没有进入汽车制造业的计划,也没有推出华为品牌汽车的计划。”华为内部人士对记者如是说。
在今年 1 月 17 日的采访中,华为创始人兼 CEO 任正非更是对记者明确表示,华为永远不会造汽车。

“我们是做车联网的模块,汽车中的电子部分,边缘计算是我们做的,我们可能会是全世界做得最好的。但是它不是车,我们要和车配合起来,车用我们的模块进入自动驾驶。决不会造车的。因此,我们不会跨界,我们是有边界的,以电子流为中心的领域,非这个领域的都要砍掉。”任正非说。
对于外界关于华为“造车”的噪音,一位华为内部人士对记者表示,华为拥有自己的业务边界,在汽车领域,一是不做上层应用,二是不做整车。他强调,外界理解的“造车”其实是华为在车联网上的布局,但这并不等同于要抢汽车企业的生意。更重要的是,华为也并不是从这几年才开始对车联网进行投资,出于产业空间和自身业务延伸,华为早已开始了布局。
据记者了解,在 2013 年,华为就正式推出了车载模块 ME909T,也同时推出了针对该领域的持续性投资计划,当时宣称的金额达到每年上亿元人民币。同年,华为还发布了前装车载移动热点、汽车在线诊断系统以及符合车规标准的 3G、4G 通信模块等产品。
而在之前的一场行业论坛上,华为中央研究院副院长袁庭球就提到,“现在一些高档汽车的总代码大概有 1 亿行,这是什么概念?汽车内的代码量超过了 Facebook、微软 Office。”袁庭球认为,汽车今后将集数据中心、计算中心、控制中心于一身,成为我们人类不可分割的一部分。
换言之,从汽车的整体趋势来看,软件正在吞噬并占领整个行业,电子化、软件化、信息化正在代替以前机械动力部分成为价值中枢,汽车将回归交通工具的本质,无人驾驶是必然趋势。
而这正是华为所看到的机会。
无人汽车将带来千倍的流量挑战、计算挑战和数据挑战,未来自动驾驶汽车能达到十倍甚至千倍于人类的驾驶能力,海量数据的加工和处理正是华为所擅长的部分。某种程度上看,汽车领域传统机械制造模块并不是华为最看重的。在汽车行业,以无人驾驶为核心的互联网软件模块以及以动力电池为核心的驱动模块才是最能产生价值的模块。
“走向智能社会的路程中,每一步都充满挑战,但不可否认这其中诞生的种种,会成为新一轮增长的机会与拐点。任何企业要抓住机会,必须成为数字化的组织,也唯有如此才能不掉队。”在一场行业大会上,华为轮值董事长徐直军表示,在智能社会中任何企业都无法独善其身。他甚至表示,“希望厂商之间的竞争来得更加猛烈些,倒逼行业加快数字化的同时,华为才越有可能实现自身业务数字化转型需求,而在那之前,华为只有不计回报地投入。”

谁能颠覆“汽车业”?
汽车产业正处在传统车到智能网联汽车、交通工具到出行服务、单车智能到智慧城市大变革的拐点期,对于这一点,显然不仅仅只有华为看到,中国以及全球的科技巨头都在加大在该领域的投资。
以国际厂商苹果为例,2014 年 Apple Titan(泰坦)项目正式获批,苹果汽车业务开始,并设立专门的汽车研究实验室,开始大规模招募软件工程师、汽车工程师甚至火箭科学家等。
苹果最初希望通过发布 CarPlay 车载系统,抢占传统汽车智能化的市场,进军车联网行业。CarPlay 车载系统能够实现把 iPhone 上的信息转移到汽车前置屏幕上,苹果在车载系统和地图领域布局,为其自动驾驶车提供了更多的可能,使其能够进行更加精确的测验。
2017 年,苹果获得了美国加州测试自动驾驶汽车的许可,并发布了首份自动驾驶汽车研究成果,一套能更轻松探知路上行人的软件系统。苹果 CEO 库克甚至称无人驾驶系统为“苹果一切 AI 项目的母体”,对其注重程度可见一斑。
而拥有 Android 系统的 Google 在 2009 年就开始了无人驾驶汽车项目。现在,谷歌的测验车现已开展到第三代,预计从 2021 年开始,项全球数百万新车提供基于 Android 操作系统的车载信息娱乐系统。
而国内科技企业也早已嗅到了这一领域的商机。
2017 年 4 月 29 日,百度重磅发布了 Apollo 计划,该计划是百度推出的向汽车行业及自动驾驶领域的合作伙伴提供的软件平台。阿里的 YunOS 操作系统则在 2010 年就立项,2011 年正式推出。2016 年 7 月 6 日,阿里与上汽发布了一款名为 RX5 的荣威牌 SUV 与其搭载的阿里 YunOS 操作系统,定位是全球首款互联网汽车。而腾讯则投资了包括蔚来汽车、FMC 以及成爱驰企业。目前,腾讯已经与一汽、宝马、广汽、长安、吉利、东风柳汽等企业签订了战略合作,搭载“AI in car”腾讯车联方案的多款车型已经上市销售。
在 2018 年 11 月 1 日,腾讯全球合作伙伴大会上,腾讯副总裁钟翔平发布了“四横两纵一中台”的业务战略规划。所谓“四横”,指的是腾讯车联、腾讯自动驾驶、腾讯位置服务,腾讯乘车码“两纵”是指腾讯内容平台和安全保障系统。“一中台”指的是腾讯 AI 和腾讯云。
据美国波士顿咨询集团测算,自动驾驶汽车创造的市场价值将达到 420 亿美元;2035 年前,全球将有 1800 万辆汽车拥有部分自动驾驶功能,1200 万辆汽车成为完全自动驾驶汽车,这是一个巨大的市场机会。
但从目前来看,自动驾驶的理想与现实之间距离仍大。
自动驾驶技术主要分为 L0 至 L5 级,现阶段不少试验型汽车能够达到 L4 级别,许多互联网、初创企业正在从 L4 级别开始研发。而中国交通场景复杂多变,目前地图导航系统精准度较低,消费者对于自动驾驶汽车可靠程度还存在质疑。自动驾驶除了技术上不断面临新挑战,在法律、标准等方面皆存在诸多有待解决的问题。
一名学者告诉记者,“以自动驾驶为例,虽然自动驾驶是人工智能极为重要的运用领域,但如何将自动驾驶与最先进的人工智能研究成果相关联,乃至如何将自动驾驶运用到实际的生活中,每一关都是一个门槛;而政府的支持,企业的投资,学界的研究,以及消费者的接受程度,都有着息息相关的联系,少了一环,都将面临的是一个产业的退步,乃至夭折。”
而在分析师看来,未来在自动驾驶领域有两种类型的公司有机会跑出:
一种是有强大技术实力的整车公司,借助于国外成熟的技术、生产设施以及销售渠道,结合自己的低成本和高效的管理模式,消化吸收国外领先技术;
第二种如同华为这样的公司,凭借着在车联网和无人驾驶这些关键技术上的突破,成为全球各大 OEM 合作的首选合作伙伴。这两者都有一个共同点,就是要有核心技术和体系竞争力,而这个,也是目前很多互联网造车公司的短板所在。
好学,高效的Python,薪资也这么高:
https://edu.csdn.net/topic/python115?utm_source=csdn_bw
免责声明:作者独立观点,不代表 CSDN 立场。
【END】

热 文 推 荐
☞ 被V神点赞, 我是如何用五子棋打败以太坊排名最高的应用的? |人物志
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

1、什么是分库分表?
1.1、当前遇到的问题
随着订单数据的增加,当MySQL单表存储数据达到一定量时其存储及查询性能会下降,在阿里的《Java 开发手册》中提到MySQL单表行数超过 500 万行或者单表容量超过 2GB时建议进行分库分表,分库分表可以简单理解为原来一个表存储数据现在改为通过多个数据库及多个表去存储,这就相当于原来一台服务器提供服务现在改成多台服务器组成集群共同提供服务,从而增加了服务能力。
这里说的500 万行或单表容量超过 2GB并不是定律,只是根据生产经验而言,为什么MySQL单表当达到一定数量时性能会下降呢?我们知道为了提高表的查询性能会增加索引,MySQL在使用索引时会将索引加入内存,如果数据量非常大内存肯定装不下,此时就会从磁盘去查询索引就会产生很多的磁盘IO,从而影响性能,这些和表的设计及服务器的硬件配置都有关,所以如果当表的数据量达到一定程度并且还在不断的增加就需要考虑进行分库分表了。
1.2、什么是分库分表?
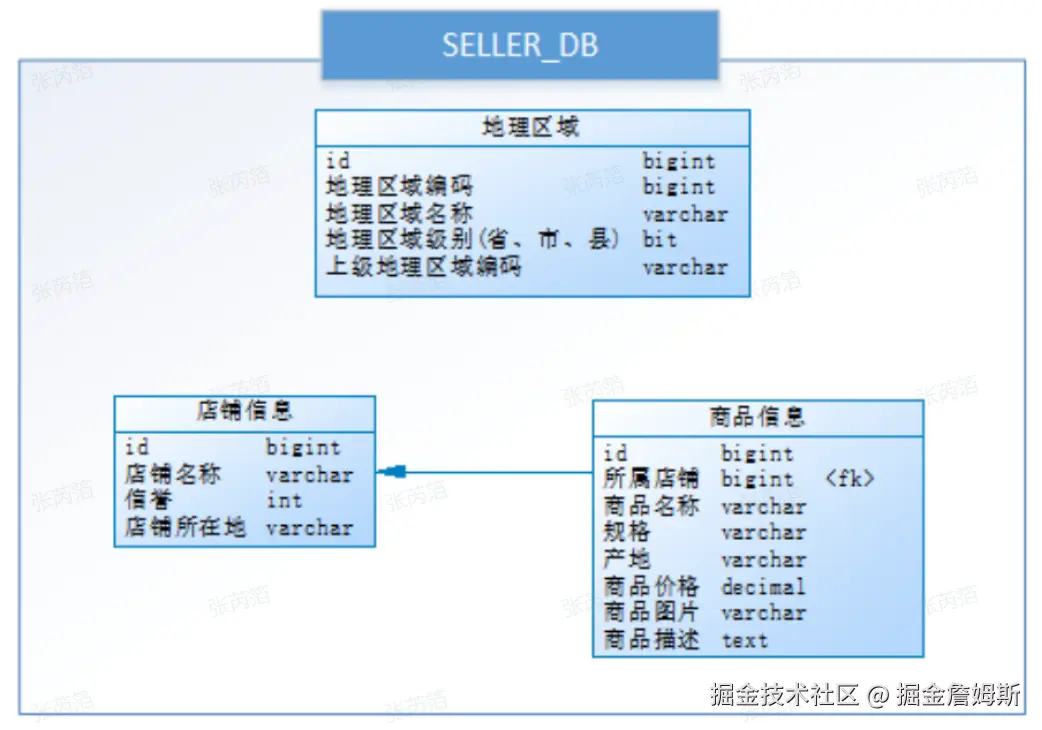
下边是一个电商系统的数据库,涉及了店铺、商品的相关业务。
随着公司业务快速发展,数据库中的数据量猛增,访问性能也变慢了,如何优化呢?
我们可以把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的,如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库 拆分的方法来解决数据库的性能问题
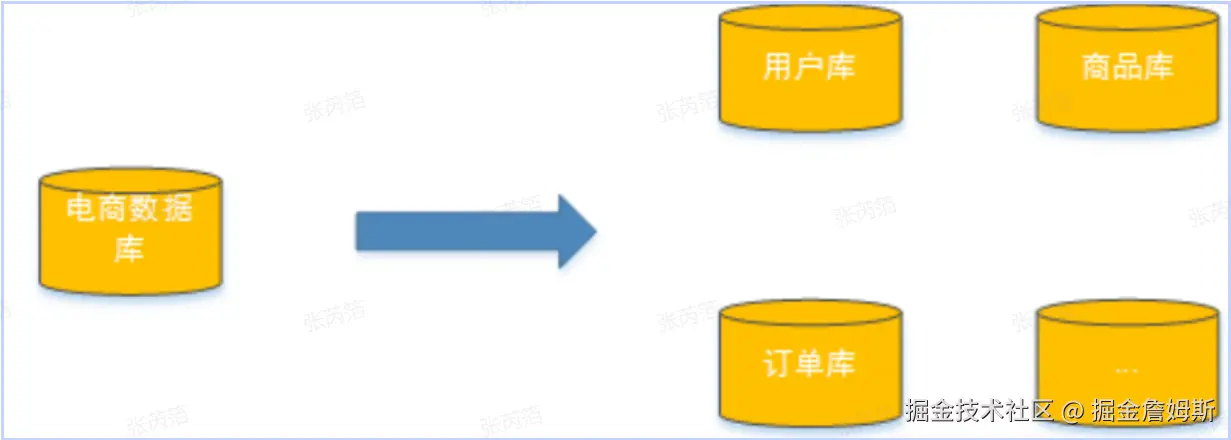
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
1.3、分库分表的四种方式
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表种方式。
1.3.1、垂直分表
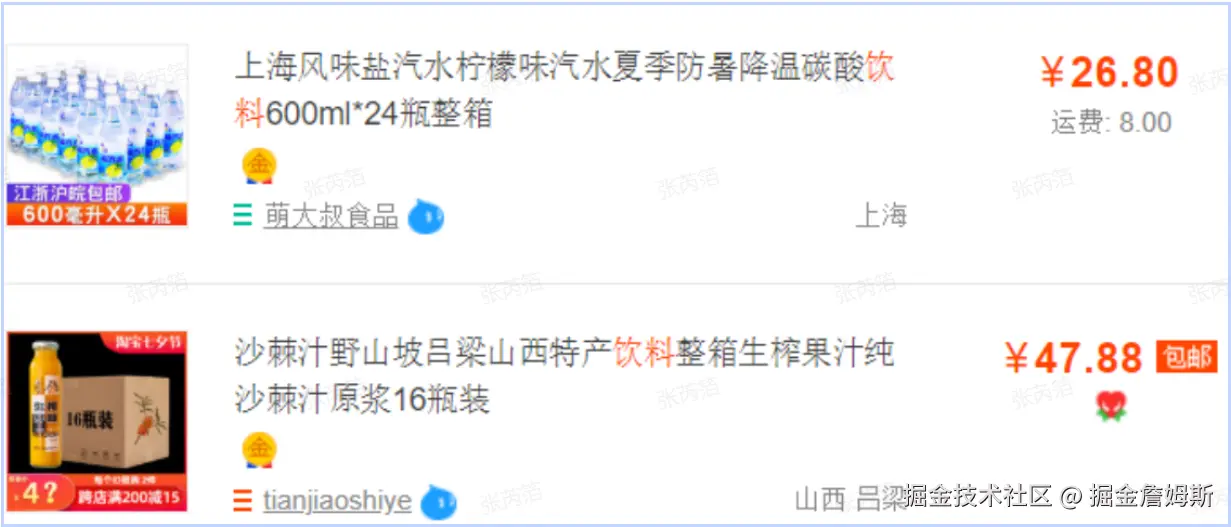
用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品信息中商品描述字段访问
频次较低,且该字段存储占用空间较大,访问单个数据IO时间较长;商品信息中商品名称、商品图片、商品价格等 其他字段数据访问频次较高。
由于这两种数据的特性不一样,因此考虑将商品信息表拆分如下:
将访问频次低的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中。
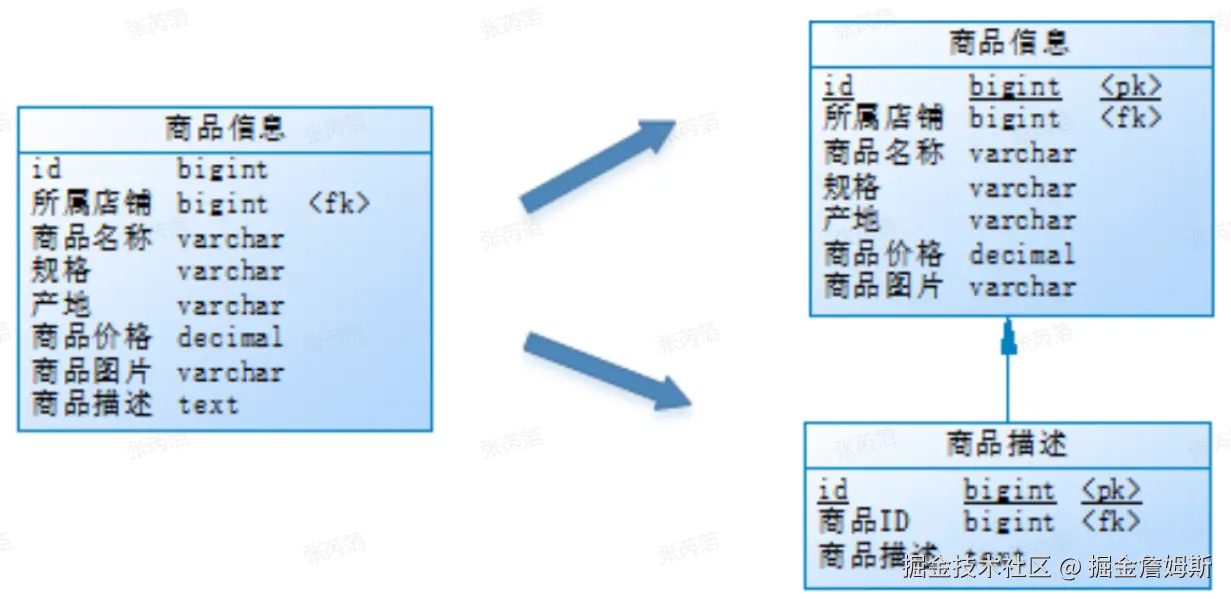
垂直分表是将一个表按照字段分成多表,每个表存储其中一部分字段,比如按冷热字段进行拆分。
垂直分表带来的好处是:充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
通常我们按以下原则进行垂直拆分:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
1.3.2、垂直分裤
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
经过思考,他把原有的SELLER_DB(卖家库),分为了PRODUCT_DB(商品库)和STORE_DB(店铺库),并把这两个库分 散到不同服务器
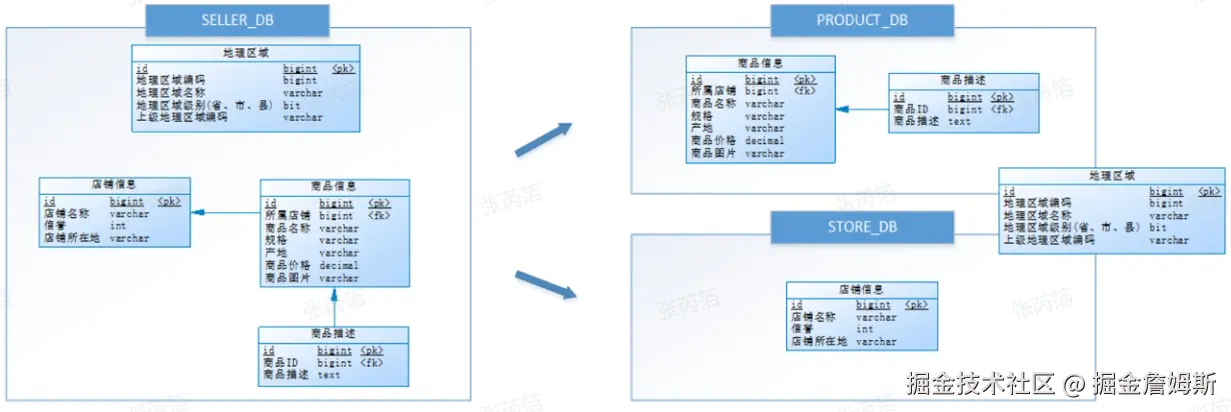 由于商品信息与商品描述业务耦合度较高,因此一起被存放在PRODUCT_DB(商品库);而店铺信息相对独立,因此 单独被存放在STORE_DB(店铺库)。
由于商品信息与商品描述业务耦合度较高,因此一起被存放在PRODUCT_DB(商品库);而店铺信息相对独立,因此 单独被存放在STORE_DB(店铺库)。
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用,微服务架构下通常会对数据库进行垂直分类,不同业务数据放在单独的数据库中,比如:客户信息数据库、订单数据库等。
它带来的提升是:
1、解决业务层面的耦合,业务清晰
2、能对不同业务的数据进行分级管理、维护、监控、扩展等
3、高并发场景下,垂直分库一定程度的提升IO、降低单机硬件资源的瓶颈。
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的题。
1.3.3、水平分库
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,PRODUCT_DB(商品库)单库存储数据已经超出预估。粗略估计,目前有8w店铺,每个店铺平均150个不同规格的商品,再算上增长,那商品数量得往1500w+上预估,并且PRODUCT_DB(商品库)属于访问非常频繁的资源,单台服务器已经无法支撑。此时该如何优化?
再次分库?但是从业务角度分析,目前情况已经无法再次垂直分库。
尝试水平分库,将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中。
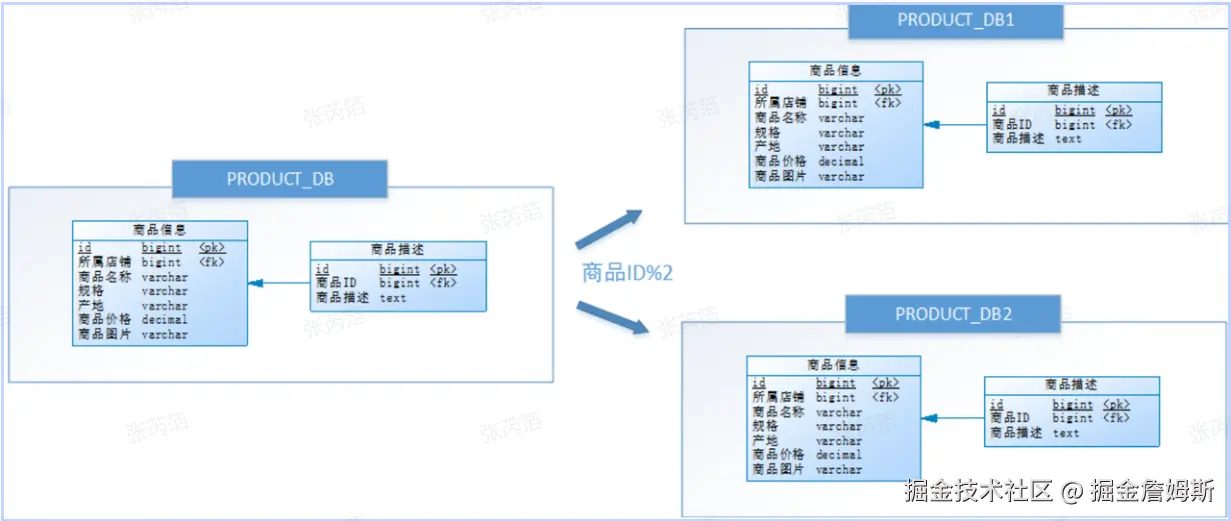
也就是说,要操作某条数据,先分析这条数据所属的店铺ID。如果店铺ID为双数,将此操作映射至RRODUCT_DB1(商品库1);如果店铺ID为单数,将操作映射至RRODUCT_DB2(商品库2)。
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上,比如:单数订单在db_orders_0数据库,偶数订单在db_orders_1数据库。
它带来的提升是:
1、解决了单库大数据,高并发的性能瓶颈。
2、提高了系统的稳定性及可用性。
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
1.3.4、水平分表
按照水平分库的思路把PRODUCT_DB_X(商品库)内的表也可以进行水平拆分,其目的也是为解决单表数据量大 的问题,如下图:
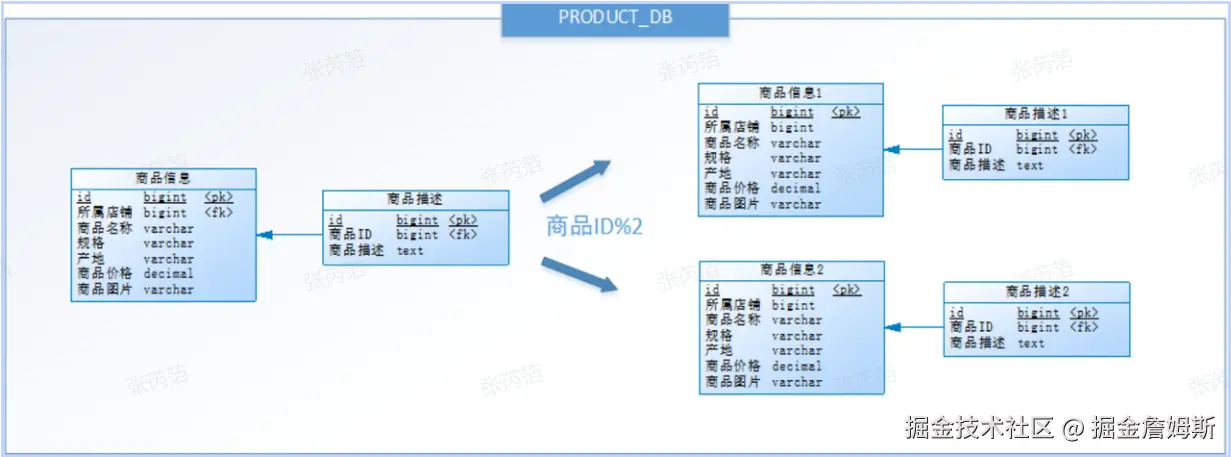
与水平分库的思路类似,不过这次操作的目标是表,商品信息及商品描述被分成了两套表。如果商品ID为双数,将 此操作映射至商品信息1表;如果商品ID为单数,将操作映射至商品信息2表。此操作要访问表名称的表达式为商品 信息[商品ID%2 + 1]
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中,比如:0到500万的订单在orders_0数据、500万到1000万的订单在orders_1数据表。
水平分表优化了单一表数据量过大而产生的性能问题
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
2、订单分库分表方案
2.1、搭建分库分表环境
2.1.1、分库分表方案
对订单数据进行分库分表
2.1.1.1、Hash方式
拿分库举例:将订单号除以数据库个数求余数,假如有3台数据库,计算表达式为:db_订单号%3, 比如:10号订单会存入到db_1数据库,11号订单存储到db_2数据库。
此方式的优点是:数据均匀。
缺点:扩容时需要迁移数据。比如:3台数据库改为4台数据库,此时计算表达式为:db_订单号%4,10号订单存储到db_2数据库,11号订单存储到db_3数据库,此时就需要进行数据迁移,将10号订单由db_1迁移到db_2。
2.1.1.2、rang方式
比如:0到500万到db_1数据库,500万到1000万到db_2数据库,依次类推。
此方式的优点:扩容时不需要迁移数据。
缺点:存在数据热点问题,因为订单号是从0开始依次往上累加,前期所有的数据都是访问db_1数据库,db_1的压力较大。
2.1.1.2、综合方案
综合1、2方案的优缺点制定综合方案。
分库方案:设计三个数据库,根据用户id哈希,分库表达式为:db_用户id % 3
参考历史经验,前期设计三个数据库,每个数据库使用主从结构部署,可以支撑项目几年左右的运行,虽然哈希存在数据迁移问题,在很长一段时间也不用考虑这个问题。
分表方案:根据订单范围分表,0---1500万落到table_0,1500万---3000万落到table_1,依次类推。
根据范围分表不存在数据库迁移问题,方便系统扩容。
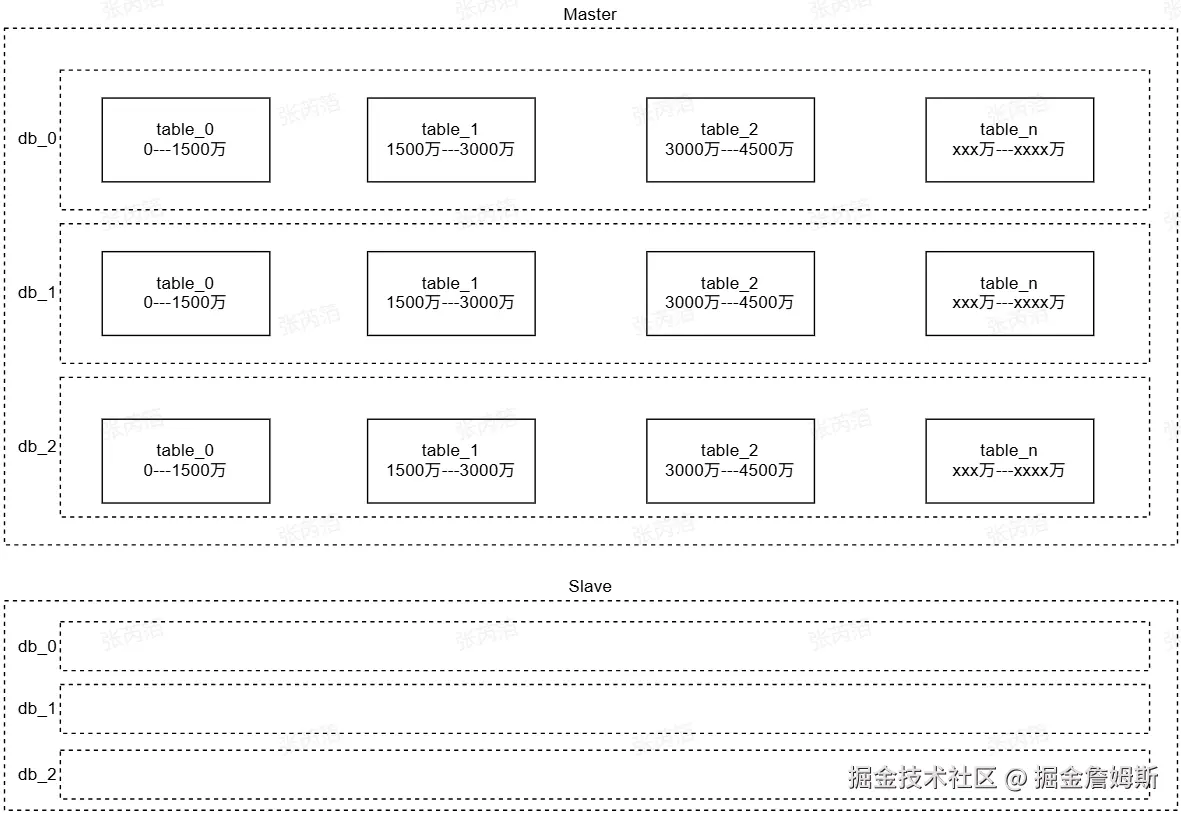
2.1.2、ShardingSphere介绍
Apache ShardingSphere 是一款分布式的数据库生态系统,可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
所以数据分片是应对海量数据存储与计算的有效手段。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储。使用ShardingSphere 的数据分片功能即可实现分库分表。
2.1.3、创建数据库
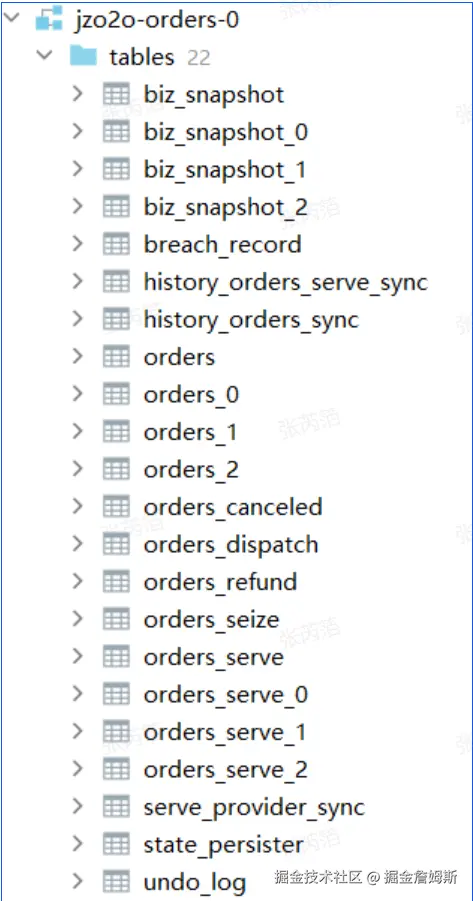
订单数据库分为三个库 :jzo2o-orders-0、jzo2o-orders-1、jzo2o-orders-2

下边分别向三个数据库导入测试数据
每个数据库对orders、biz_snapshot、orders_serve进行分表(暂分3个表),其它表为广播表(即在每个数据库都存在且数据是完整的),如下图:
2.1.3、添加依赖
yml 代码解读复制代码com.jzo2o
jzo2o-shardingsphere-jdbc
2.1.3、配置shardingsphere-jdbc-dev.yml
配置文件如下:
jzo2o-orders-0、jzo2o-orders-1、jzo2o-orders-2表示三个数据源对应三个订单数据库。
每个数据库中对orders、orders_serve、biz_snapshot进行分表。
详细如下:
yml 代码解读复制代码dataSources:
jzo2o-orders-0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/jzo2o-orders-0?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
jzo2o-orders-1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/jzo2o-orders-1?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
jzo2o-orders-2:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/jzo2o-orders-2?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
rules:
- !TRANSACTION
defaultType: BASE
- !SHARDING
tables:
orders:
actualDataNodes: jzo2o-orders-${0..2}.orders_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orders_table_inline
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: orders_database_inline
orders_serve:
actualDataNodes: jzo2o-orders-${0..2}.orders_serve_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orders_serve_table_inline
databaseStrategy:
standard:
shardingColumn: serve_provider_id
shardingAlgorithmName: orders_serve_database_inline
biz_snapshot:
actualDataNodes: jzo2o-orders-${0..2}.biz_snapshot_${0..2}
tableStrategy:
standard:
shardingColumn: biz_id
shardingAlgorithmName: biz_snapshot_table_inline
databaseStrategy:
standard:
shardingColumn: db_shard_id
shardingAlgorithmName: biz_snapshot_database_inline
shardingAlgorithms:
# 订单-分库算法
orders_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${user_id % 3}
# 分库支持范围查询
allow-range-query-with-inline-sharding: true
# 订单-分表算法
orders_table_inline:
type: INLINE
props:
# 分表算法表达式
algorithm-expression: orders_${(int)Math.floor(id % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 服务单-分库算法
orders_serve_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${serve_provider_id % 3}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 服务单-分表算法
orders_serve_table_inline:
type: INLINE
props:
# 允许范围查询
algorithm-expression: orders_serve_${(int)Math.floor(id % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 快照-分库算法
biz_snapshot_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${db_shard_id % 3}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 快照-分表算法
biz_snapshot_table_inline:
type: INLINE
props:
# 允许范围查询
algorithm-expression: biz_snapshot_${(int)Math.floor((Long.valueOf(biz_id)) % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# id生成器
keyGenerators:
snowflake:
type: SNOWFLAKE
- !BROADCAST
tables:
- breach_record
- orders_canceled
- orders_refund
- orders_dispatch
- orders_seize
- serve_provider_sync
- state_persister
- orders_dispatch_receive
- undo_log
- history_orders_sync
- history_orders_serve_sync
props:
sql-show: true
配置项说明参考官方文档 shardingsphere.apache.org/document/cu…
dataSources:数据源
jzo2o-orders-x:与actualDataNodes对应。
下边以orders表为例说明分库分表策略:
-
分库键:user_id
-
分库表达式:jzo2o-orders-${user_id % 3}
根据用户id计算落到哪个数据库
-
分表键:id
-
分表表达式:orders_${(int)Math.floor(id % 10000000000 / 15000000)}
按1500万为单位进行分表,比如:订单号2311020000000000019,为19位,表达式的值为19,匹配表orders_0,如果表达式的值大于1500万小于3000万匹配表orders_1。
- !BROADCAST:指定广播表
广播表在jzo2o-orders-0、jzo2o-orders-1、jzo2o-orders-2每个数据库的数据一致。
yml 代码解读复制代码 tables:
orders:
#由数据源名 + 表名组成(参考 Inline 语法规则)
actualDataNodes: jzo2o-orders-${0..2}.orders_${0..2}
tableStrategy:#分表策略
standard:
shardingColumn: id #分片列名称
shardingAlgorithmName: orders_table_inline # 分片算法名称
databaseStrategy:#分库策略
standard:
shardingColumn: user_id
shardingAlgorithmName: orders_database_inline
shardingAlgorithms:
# 订单-分库算法
orders_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${user_id % 3}
# 分库支持范围查询
allow-range-query-with-inline-sharding: true
# 订单-分表算法
orders_table_inline:
type: INLINE
props:
# 分表算法表达式
algorithm-expression: orders_${(int)Math.floor(id % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
评论记录:
回复评论: