

【CSDN 编者按】程序员刷豆瓣也要刷出技术感,本文爬取豆瓣 TOP250 告诉你这些书“热门”在哪里!案例分析之外,重在梳理编写爬虫的逻辑和链路关键点,手把手教你形成自己编写爬虫的方法论。
Are you ready? Let's go!

作者 | 周志鹏
责编 | 郭 芮
本文以爬取豆瓣TOP250图书为例,但重点并不在案例本身,而在于梳理编写爬虫的逻辑和链路关键点,帮助感兴趣的童鞋逐渐形成自己编写爬虫的方法论(这个是最最最关键的),并在实战中体验requests+xpath绝妙的感觉。没错,这一招requests+xpath(json)真的可以吃遍天。
马克思曾经没有说过——当你浏览网页时,看到的只是浏览器想让你看到的。这句话道出了一个真谛——我们看到的网页只一个结果,而这个网页总是由众多小的“网页(或者说部分)”构成。
就像拼图,我们看到的网页其实是最终拼好的成品,当我们输入一个网址,浏览器会"自动"帮我们向远方的服务器发送构成这个大拼图的一众请求,服务器验证身份后,返回相关的小拼图(请求结果),而浏览器很智能的帮助我们把小拼图拼成大拼图。
我们需要的,就是找到网页中存储我们数据的那个小拼图的网址,并进一步解析相关内容。以豆瓣TOP250图书为例,爬虫的第一步,就是“审查元素”,找到我们想要爬取的目标数据及其所在网址。
豆瓣TOP250图书网址:https://book.douban.com/top250

审查元素,找到目标数据所在的URL
审查元素,就是看构成网页的小拼图具体是怎么拼的,操作起来很简单,进入网页后,右键——审查元素,默认会自动定位到我们所需要的元素位置。
比如我们鼠标移动到“追风筝的人”标题上,右键后审查元素:
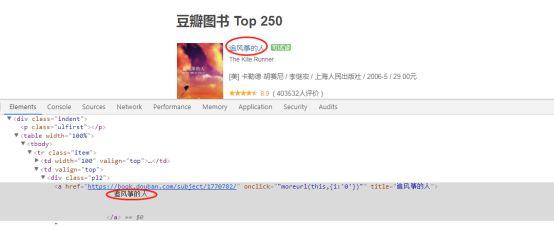
其实,我们需要的数据(图书名称、评价人数、评分等等)都在一个个网页标签中。爬虫这玩意儿就是刚开始看着绕但用起来很简单,极简主义友情提示,不要被复杂的结构迷惑。
在彻底定位目标数据之前,我们先简单明确两个概念。
网页分为静态和动态,我们可以粗暴理解为,直接右键——查看源代码,这里显示的是静态网址的内容,如果里面包含我们需要的数据,那直接访问最初的网址(浏览器网址栏的网址)即可。
而有的数据是在我们浏览的过程中默默新加载(浏览过程中向服务器发送的请求)的,这部分网页的数据一般藏在JS/XHR模块里面。
是这样操作的:审查元素——刷新网址——NETWORK——JS或者XHR。
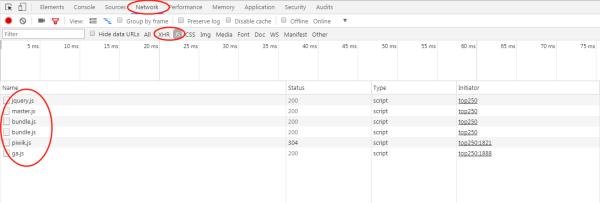
概念讲解到此为止,下面是操作详解,即我们如何找到我们需要的网址。
一般来说,静态网页中的数据比较容易获取,爬取之前我们养成先查看源代码的方式检查所需要的数据是否在静态网页中的习惯。
右键——查看源代码:

验证一下需要的数据在静态网址中是否出现,CTRL+F快捷查找,然后输入我们刚才看到的图书榜第一的“追风筝的人”。
成功找到!得来全不费工夫,朝下拉,发现需要的所有数据都在静态网址中,完全不需要去动态网页中一步步排查了。

尝试请求,报错中前行
我们刚才发现目标数据是在静态网址中,直接访问https://book.douban.com/top250就可以拿到。下一步,借助PYTHON中requests的get方法很高效的实现网页访问。
import requestshtml = requests.get('https://book.douban.com/top250')requests.get函数第一个参数默认是请求的网址,后面还有headers,cookeis等关键字参数,稍后会讲。
OK,一个访问请求完成了,是不是超级简单?访问完成后,我们可以看一下返回的内容:

一般都会讲返回的状态码以及对应的意义,但个人觉得直接暴力抽看返回内容也很方便。
很尴尬,没伪装都访问成功了,之前验证headers的豆瓣现在连headers都不验证了。小豆,你堕落了......但关于爬虫模拟用户行为必须敲黑板讲重点!!!
当我们用PYTHON对目标网址进行访问,本质上是用PYTHON对目标服务器发送了一个请求,而这种机器(Python)并不是真实的用户(通过浏览器请求的),这种“虚假”访问是服务器深恶痛绝的(爬虫会对网站服务器造成负荷,而且绝大多数网站并不希望数据被批量获取)。所以,如果想要万无一失,访问行为必须模拟,要尽可能的让你的爬虫像正常的用户。最常规的方法就是通过伪装headers和cookies来让我们的爬虫看起来更像人。
继续举个例子:
你住在高档小区,小P这个坏小伙想伪装你进小区做不可描述的事情。
他知道,门卫会根据身份象征来模糊判断是否是小区业主,所以小P先租了一套上档次的衣服和一辆称得上身份的豪车(可以理解为伪装headers),果然混过了门卫。但是呢,小P进进出出太频繁,而且每次停车区域都不一样,引起了门卫的严重怀疑,在一个星期后,门卫升级检验系统,通过人脸识别来验证,小P被拒绝在外,但很快,小P就通过毁容级别的化妆术(伪装cookies),完全伪装成你,竟然混过了人脸识别系统,随意出入,为所欲为。
此处主要是形象化科普,其实还有IP等更复杂的伪装方式,感兴趣的同学可以自己研究。
所以,为了保险起见,我们还是构造伪装成正常浏览器的请求头。
找到静态网址和其关键参数(请求头headers相关参数都在Request Headers下):
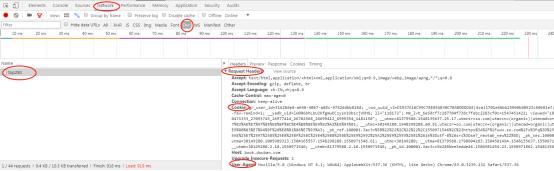
requests库会有默认的headers,关键参数都是字典格式,这里我们把浏览器的参数赋值给headers,从请求头的角度伪装成正常浏览器。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}#再来请求一次html = requests.get('https://book.douban.com/top250',headers = headers)html.text[:200]#成功返回结果
请求成功,解析并定位到我们需要的数据
刚才我们拿到了正确的返回结果html,所有的内容都包在html.text里,我们需要对这一大包内容进行解析和定位,xpath就登场了。
操作如下:
from lxml import etreebs = etree.xpath(html.text) #这一步把HTML的内容解析成xpath方法可以很容易定位的对象,其实就是为定位数据做好准备的必要一步,记住这步必要的操作。
先举个例子讲解用法:

注:xpath的索引都是从1开始的,谨记谨记!
这里缩进代表从属关系,我们想要的作者信息被包裹在 的标签内,从下到上又从属于上一级的div标签——td标签——tr标签。
怎么用xpath获取?
bs.xpath('//tr[@class = "item"]/td[2]/p')[0].text//代表从根目录(从上到下)开始定位(初始定位都需要这样),tr[@class = "item"]表示找到class等于item标签,因为可能会有很多个tr标签,我们通过class属性来区分,tr后面的/代表下一级,td[2]表示定位到第二个td标签,然后再下一级的p标签,并获取他的内容text。
如果是要获取p里面class的值:
bs.xpath('//tr[@class = "item"]/td[2]/p/@class'))[0]还没完全理解?不要紧,用一下就会了,Let's do it!
鼠标移动到"追风筝的人”作者名上,右键——审查元素:
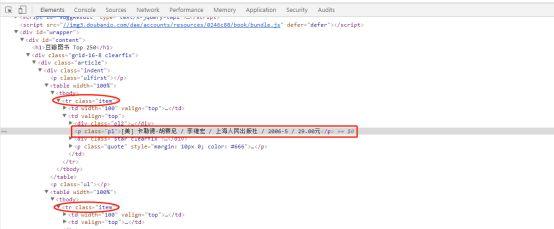
关于书籍作者相关的信息都被包裹在p标签中,而p标签又从属于td-tr-tbody-table。
再进一步点击,书名、评价数、评分等相关信息也都是在类似的链路,所有的信息都被包裹在tr[@class = "item"]这一级,虽然再往上一级的tbody和table也可以,但只要定位到tr就够了。
我们来定位一下:
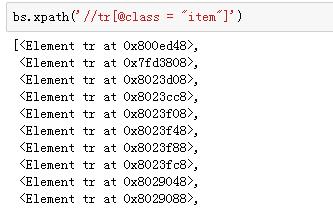
返回了一系列对象,数一数(这个地方没截全),正好25个,对应着我们在浏览器中看到的25本书的相关信息。我们先用第一个对象,来尝试定位需要的关键信息。

注:我们定位了第一个元素,书籍相关信息都被包裹着(从属于他),我们想要进一步定位,很简单,直接调用xpath方法,而且开头不需要加//:
书籍名:

作者、出版社信息:

细心的同学一定发现了,定位返回的值是一个列表,我们通过索引[0]来提取里面的内容,至于定位元素,我们既可以通过序号(td[2]/div[1]这样),也可以通过对属性进行赋值(p[@class = "pl"])来判断。
Emmm,有一个疑惑点非常容易对人造成困扰,就是定位了之后,我们怎么提取我们需要的信息,举个例子:

大家会发现,作者相关信息是被包裹在 和
下面,继续提取关键信息:
评分:

评价人数:

一句话概括:

OKAY,我们把定位提取操作汇总一下:
#这里创建一个DATAFRAME来存储最终结果result = pd.DataFrame()for i in bs.xpath('//tr[@class = "item"]'): #书籍中文名 book_ch_name = i.xpath('td[2]/div[1]/a[1]/@title')[0] #评分 score = i.xpath('td[2]/div[2]/span[2]')[0].text #书籍信息 book_info = i.xpath('td[2]/p[@class = "pl"]')[0].text #评价数量由于数据不规整,这里用PYTHON字符串方法对数据进行了处理 comment_num = i.xpath('td[2]/div[2]/span[3]')[0].text.replace(' ','').strip('(\n').strip('\n)') #一句话概括 brief = i.xpath('td[2]/p[@class = "quote"]/span')[0].text #这里的cache是存储每一次循环的结果,然后通过下一步操作循环更新result里面的数据 cache = pd.DataFrame({'中文名':[book_ch_name],'评分':[score],\ '书籍信息':[book_info],'评价数量':[comment_num],'一句话概括':[brief]}) #把新循环中的cache添加到result下面 result = pd.concat([result,cache])
结果像酱紫(截取了部分):
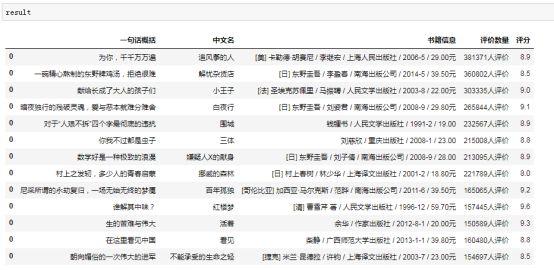
呼~最关键的数据定位,数据获取已经完成了。

翻页爬取,尽收囊中
俗话说的好,拿一血者拿天下。我们已经拿到了第一页的数据,其他页面数据都是一样的结构,最后只需要我们找到网页变化的规律,实现翻页爬取。
我们在浏览器中翻到下一页(第二页)。当当当当!浏览器网址栏的网址的变化你一定发现了!

再下一页(第三页):

我们有理由进行推断,网址前面的结构都是不变的,决定页数的关键参数是start后面的数字,25代表第二页,50代表第三页,那一页就是0,第四页就是75,以此类推。
来来回回翻页,不出所料,翻页的关键就是start参数的变化。所以,我们只需要设置一个循环,就能够构造出所有的网址。
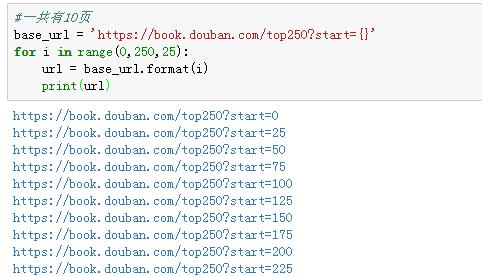
至此,各个模块的代码可谓大功告成!
最后,先来一个TOP50词云版书单,再附上完整代码来抛砖引玉:

import pandas as pdimport requestsfrom lxml import etreeimport time#循环构造网址def format_url(base_url,pages = 10): urls = [] for num in range(0,pages * 25,25): urls.append(base_url.format(num)) return urls#解析单个页面def parse_page(url,headers): #创建一个存储结果的容器 result = pd.DataFrame() html = requests.get(url,headers = headers) bs = etree.HTML(html.text) for i in bs.xpath('//tr[@class = "item"]'): #书籍中文名 book_ch_name = i.xpath('td[2]/div[1]/a[1]/@title')[0] #评分 score = i.xpath('td[2]/div[2]/span[2]')[0].text #书籍信息 book_info = i.xpath('td[2]/p[@class = "pl"]')[0].text #评价数量由于数据不规整,这里用PYTHON字符串方法对数据进行了处理 comment_num = i.xpath('td[2]/div[2]/span[3]')[0].text.replace(' ','').strip('(\n').strip('\n)') try: #后面有许多书籍没有一句话概括 #一句话概括 brief = i.xpath('td[2]/p[@class = "quote"]/span')[0].text except: brief = None #这里的cache是存储每一次循环的结果,然后通过下一步操作循环更新result里面的数据 cache = pd.DataFrame({'中文名':[book_ch_name],'评分':[score],\ '书籍信息':[book_info],'评价数量':[comment_num],'一句话概括':[brief]}) #把新循环中的cache添加到result下面 result = pd.concat([result,cache]) return resultdef main(): final_result = pd.DataFrame() base_url = 'https://book.douban.com/top250?start={}' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} urls = format_url(base_url,pages = 10) for url in urls: res = parse_page(url,headers = headers) final_result = pd.concat([final_result,res]) #爬虫要文明,这里设置了一个爱心520时间 time.sleep(5.2) return final_resultif __name__ == "__main__": final_result = main()作者:周志鹏,2年数据分析,深切感受到数据分析的有趣和学习过程中缺少案例的无奈,遂新开公众号「数据不吹牛」,定期更新数据分析相关技巧和有趣案例(含实战数据集),欢迎大家关注交流。
声明:本文为作者原创投稿,未经允许请勿转载,欢迎大家通过以下方式联系投稿。

热 文 推 荐
☞ 云评测 | OpenStack智能运维解决方案 @文末有福利!
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

前言
我比较喜欢写教程,但是纯手写的话,一方面太麻烦了,另一方面就是觉得自己写的不太好,很多时候都喜欢直接贴代码算了。但直接贴代码对有编程基础的人而言可能很有帮助,但是对想入门的小白而言,一上来就是一大堆代码就很容易劝退。
怎么把教程写好,是我一直都在探索的事情。
昨天在GitHub上偶然刷到了一个项目,说是基于代码仓库直接就能生成教程文档,我抱着试一试的心态去尝试了一下,结果确实被惊艳到了,今天就来分享给大家,我也会带大家实践一下。
这个项目叫Tutorial-Codebase-Knowledge。
GitHub地址:github.com/The-Pocket/…
Tutorial-Codebase-Knowledge介绍
这是一个 Pocket Flow 的教程项目,一个仅100行代码的LLM框架。它爬取 GitHub 仓库,并从代码中构建知识库。它分析整个代码库以识别核心抽象及其交互方式,并将复杂的代码转化为带有清晰可视化内容的初学者友好教程。
实践
创建一个python虚拟环境,安装包:
代码解读复制代码pip install -r requirements.txt
需要修改一下call_llm.py:
使用谷歌的模型可以这样写:
ini 代码解读复制代码def call_llm(prompt, use_cache: bool = True):
client = genai.Client(
api_key=os.getenv("GEMINI_API_KEY", "你的api key"),
)
model = os.getenv("GEMINI_MODEL", "gemini-2.5-pro-exp-03-25")
response = client.models.generate_content(
model=model,
contents=[prompt]
)
response_text = response.text
return response_text
使用兼容OpenAI格式的模型可以这样写:
ini 代码解读复制代码# Use OpenAI o1
def call_llm(prompt, use_cache: bool = True):
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "你的api key"),
base_url="https://api.siliconflow.cn/v1")
r = client.chat.completions.create(
model="Qwen/QwQ-32B",
messages=[{"role": "user", "content": prompt}],
response_format={
"type": "text"
},
reasoning_effort="medium",
store=False
)
return r.choices[0].message.content
使用这个命令用于测试:
bash代码解读复制代码python utils/call_llm.py
参考README的使用方法:
bash 代码解读复制代码# Analyze a GitHub repository
python main.py --repo https://github.com/username/repo --include "*.py" "*.js" --exclude "tests/*" --max-size 50000
# Or, analyze a local directory
python main.py --dir /path/to/your/codebase --include "*.py" --exclude "*test*"
# Or, generate a tutorial in Chinese
python main.py --repo https://github.com/username/repo --language "Chinese"
--repo 或 --dir - 指定 GitHub 仓库 URL 或本地目录路径(必需,互斥) -n, --name - 项目名称(可选,如果省略则从 URL/目录派生) -t, --token - GitHub 令牌(或设置 GITHUB_TOKEN 环境变量) -o, --output - 输出目录(默认:./output) -i, --include - 要包含的文件(例如,".py" ".js") -e, --exclude - 要排除的文件(例如,"tests/" "docs/") -s, --max-size - 文件最大大小(以字节为单位,默认:100KB) --language - 生成教程的语言(默认:"english")
正常运行如下图所示:
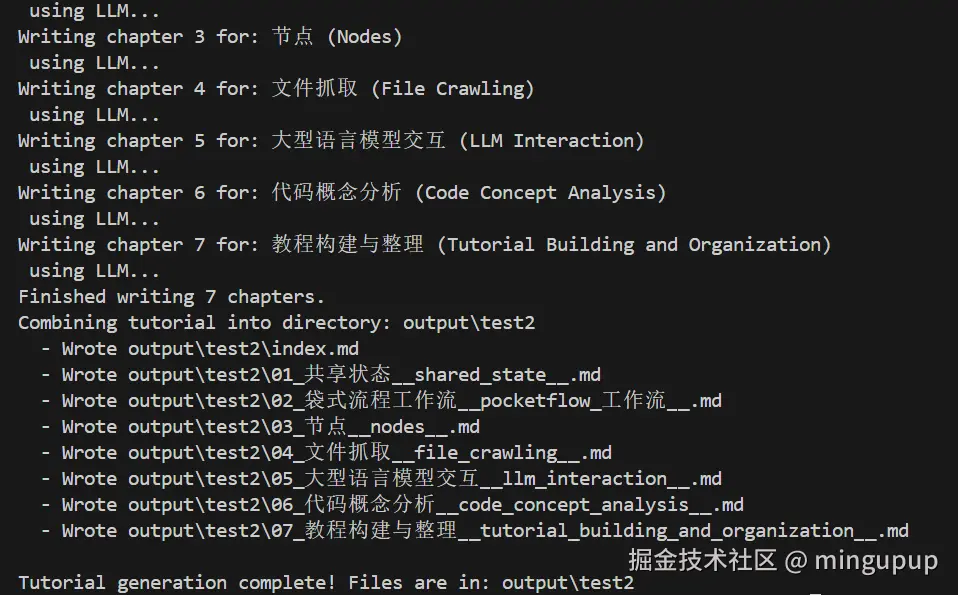
会开始分析章节然后开始写章节的内容。
以自己的一个教程仓库为例,我使用了不同的模型创建教程,把生成的教程我上传到GitHub了。
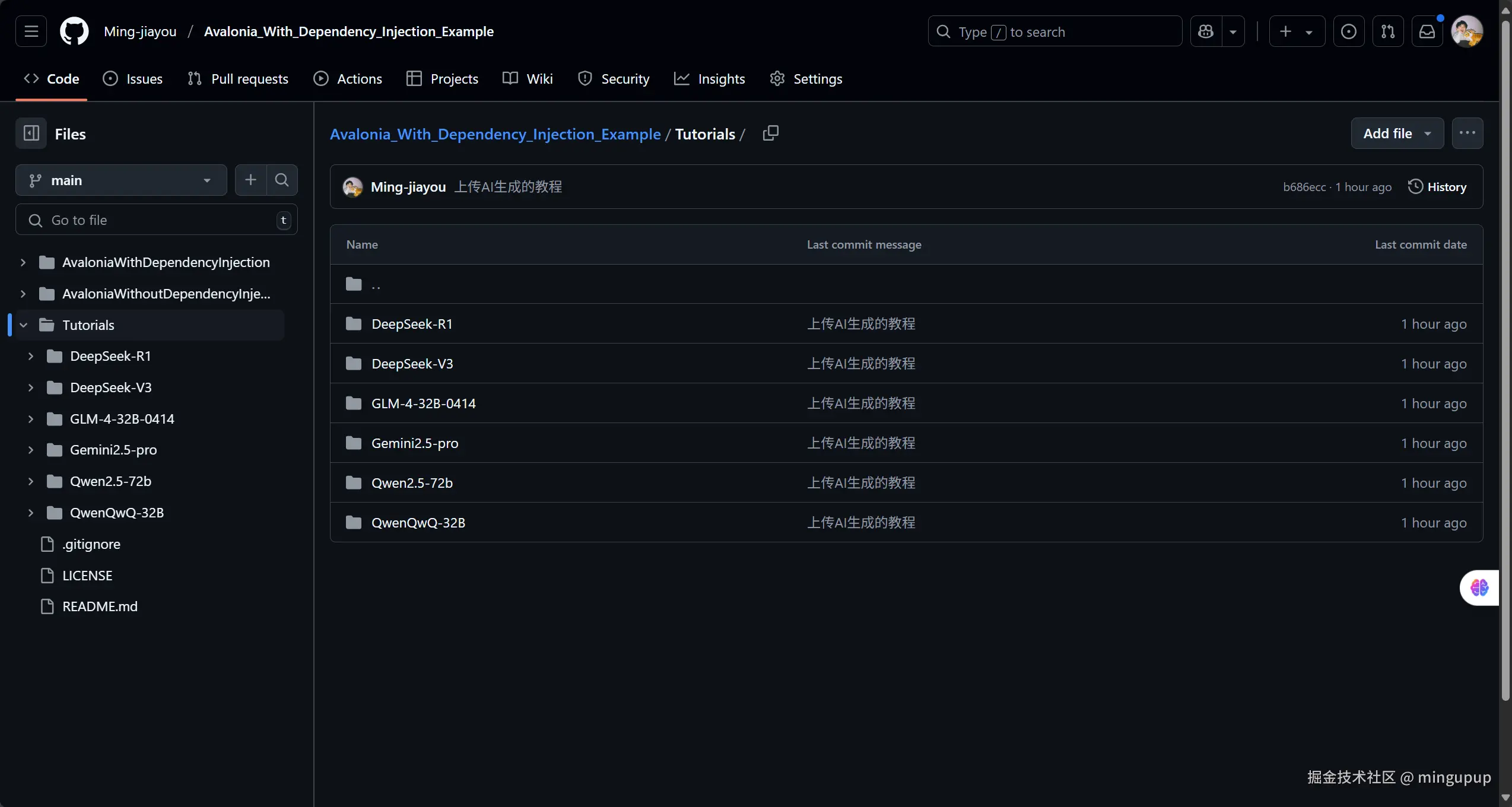
在我使用的模型中,我觉得效果最好的是gemini-2.5-pro-exp-03-25。
感兴趣的朋友可以自己看看对比一下。
我现在把gemini-2.5-pro-exp-03-25生成的贴出来看看。
Tutorial: Avalonia_With_Dependency_Injection_Example
本项目 Avalonia_With_Dependency_Injection_Example 是一个使用 Avalonia UI 与 依赖注入 技术构建的示例应用。它展示了如何通过依赖注入管理应用的 组件和服务,并通过 导航服务 实现不同视图之间的切换。通过视图模型与视图的分离设计,项目实现了模块化开发,提高了代码的复用性和可维护性。
Source Repository: github.com/Ming-jiayou…
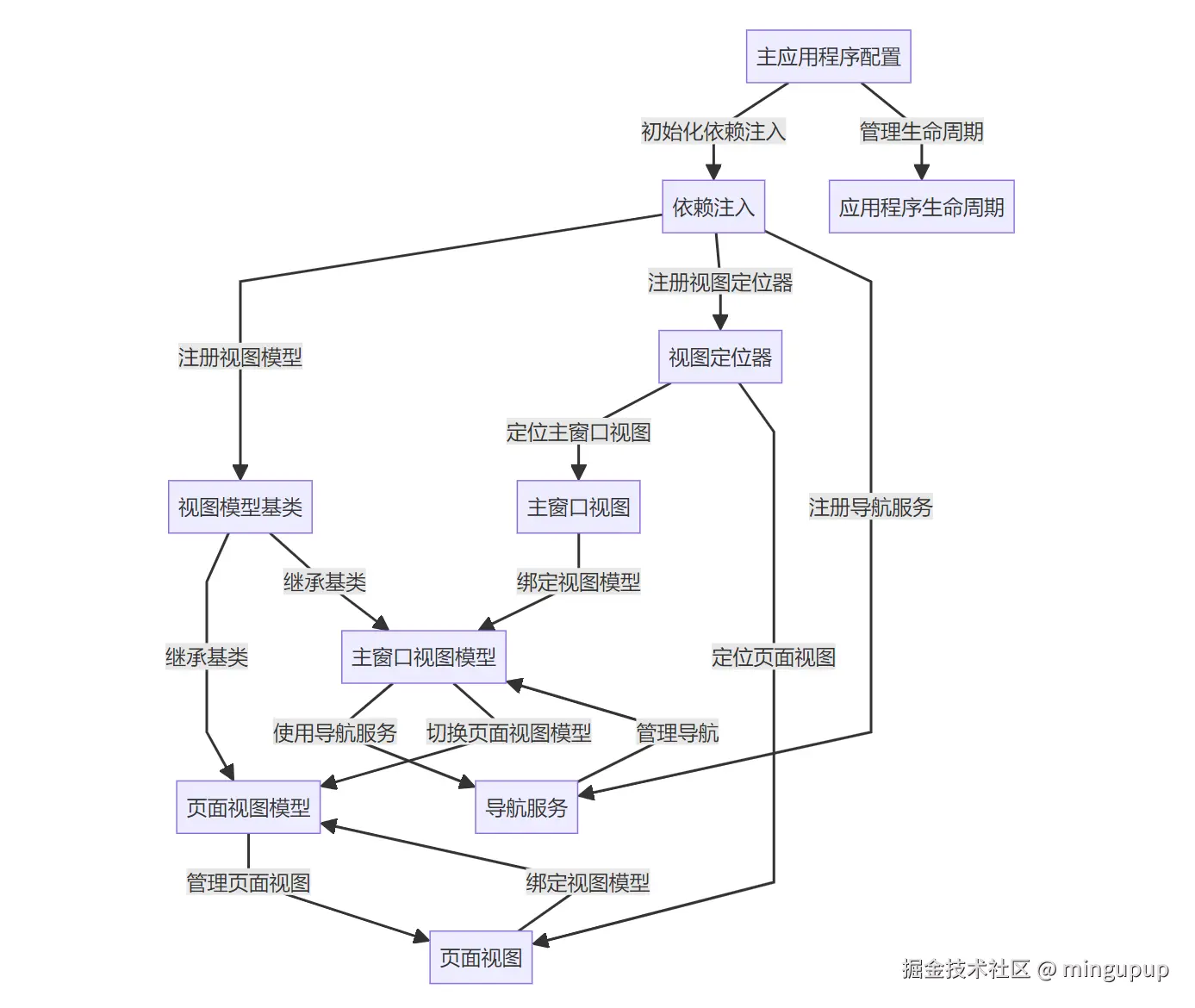
Chapter 1: 主应用程序配置
欢迎初学者!
欢迎来到我们的第一个章节!在这个章节中,我们将学习如何配置和启动Avalonia应用程序。如果你是第一次接触Avalonia或者依赖注入(Dependency Injection, DI),请不要担心,我们将通过具体的例子来一步步引导你。
为什么要配置主应用程序?
在开发任何应用程序时,首先需要做的一件事情就是配置和启动它。在Avalonia中,主应用程序配置类似于一家公司的前台,负责接待访客并引导他们进入正确的房间。在这个例子中,我们的“前台”会做一些必要的初始化工作,比如设置主窗口和初始化依赖注入。这样的配置能确保应用程序能够顺利启动,用户可以使用所有的功能。
具体实现
1. 创建应用程序类
我们从创建应用程序类开始。在Avalonia中,应用程序类继承自Application,并重写一些方法来配置应用程序。我们来看一下App.axaml.cs文件中的代码:
csharp 代码解读复制代码using System.Linq;
using Avalonia;
using Avalonia.Controls.ApplicationLifetimes;
using Avalonia.Data.Core;
using Avalonia.Data.Core.Plugins;
using Avalonia.Markup.Xaml;
using AvaloniaWithDependencyInjection.ViewModels;
using AvaloniaWithDependencyInjection.Views;
using Microsoft.Extensions.DependencyInjection;
namespace AvaloniaWithDependencyInjection
{
public partial class App : Application
{
public override void Initialize()
{
AvaloniaXamlLoader.Load(this);
}
public override void OnFrameworkInitializationCompleted()
{
if (ApplicationLifetime is IClassicDesktopStyleApplicationLifetime desktop)
{
DisableAvaloniaDataAnnotationValidation();
var mainWindow = Program.ServiceProvider?.GetRequiredService();
var mainViewModel = Program.ServiceProvider?.GetRequiredService();
if (mainWindow != null && mainViewModel != null)
{
mainWindow.DataContext = mainViewModel;
desktop.MainWindow = mainWindow;
}
}
base.OnFrameworkInitializationCompleted();
}
private void DisableAvaloniaDataAnnotationValidation()
{
var dataValidationPluginsToRemove =
BindingPlugins.DataValidators.OfType().ToArray();
foreach (var plugin in dataValidationPluginsToRemove)
{
BindingPlugins.DataValidators.Remove(plugin);
}
}
}
}
代码解释
-
Initialize 方法:
AvaloniaXamlLoader.Load(this);:加载XAML资源,初始化用户界面。
-
OnFrameworkInitializationCompleted 方法:
ApplicationLifetime:检查应用程序是否在传统的桌面环境中运行。DisableAvaloniaDataAnnotationValidation():禁用Avalonia的数据注释验证,避免与CommunityToolkit重复验证。Program.ServiceProvider.GetRequiredService和() Program.ServiceProvider.GetRequiredService:从依赖注入服务中获取主窗口和主窗口视图模型。() mainWindow.DataContext = mainViewModel;:将主窗口的 DataContext 设置为主窗口视图模型。desktop.MainWindow = mainWindow;:设置应用程序的主窗口。
-
DisableAvaloniaDataAnnotationValidation 方法:
- 从数据验证插件中移除Avalonia的数据注释验证插件,避免重复验证。
2. 配置依赖注入
接下来,我们来看看如何配置依赖注入。在Program.cs文件中,我们会创建一个服务集合,并注册所需的依赖项:
csharp 代码解读复制代码using System;
using Avalonia;
using Microsoft.Extensions.DependencyInjection;
namespace AvaloniaWithDependencyInjection
{
internal sealed class Program
{
public static IServiceProvider? ServiceProvider { get; private set; }
[STAThread]
public static void Main(string[] args)
{
var services = new ServiceCollection();
services.AddViews()
.AddViewModels()
.AddServices();
ServiceProvider = services.BuildServiceProvider();
BuildAvaloniaApp().StartWithClassicDesktopLifetime(args);
}
public static AppBuilder BuildAvaloniaApp()
=> AppBuilder.Configure()
.UsePlatformDetect()
.WithInterFont()
.LogToTrace();
}
}
代码解释
-
Main 方法:
var services = new ServiceCollection();:创建一个服务集合。services.AddViews().AddViewModels().AddServices();:注册视图、视图模型和其他服务。ServiceProvider = services.BuildServiceProvider();:构建服务提供者。BuildAvaloniaApp().StartWithClassicDesktopLifetime(args);:配置并启动Avalonia应用程序。
-
BuildAvaloniaApp 方法:
AppBuilder.Configure:配置应用程序。() UsePlatformDetect():自动检测平台。WithInterFont():使用Inter字体。LogToTrace():将日志记录到跟踪。
内部实现
步骤详解
-
创建应用程序类:
- 继承自
Application。 - 重写
Initialize方法,加载XAML资源。 - 重写
OnFrameworkInitializationCompleted方法,配置主窗口和依赖注入。
- 继承自
-
配置依赖注入:
- 创建服务集合。
- 注册所需的视图、视图模型和其他服务。
- 构建服务提供者。
- 启动Avalonia应用程序。
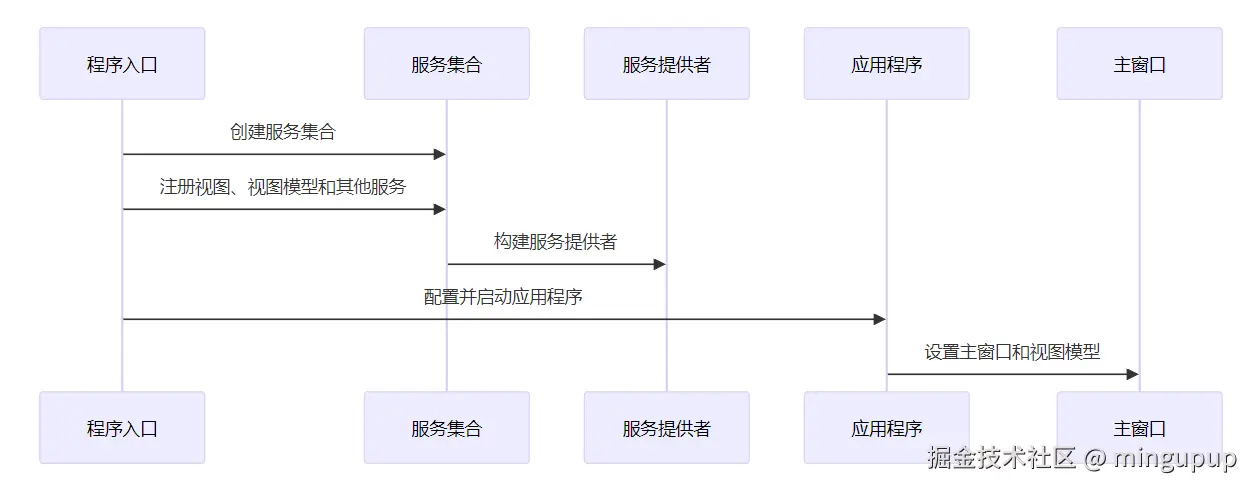
序列图
结论
通过本章,我们学习了如何配置和启动Avalonia应用程序。我们介绍了应用程序类的创建和依赖注入的配置。希望你现在已经能够理解这些基本概念,并能够自己动手配置一个简单Avalonia应用程序。
接下来,我们将深入学习依赖注入的更多内容。请继续阅读:依赖注入。
Chapter 2: 依赖注入
从上一章过渡
在上一章 主应用程序配置 中,我们学习了如何配置和启动一个Avalonia应用程序。我们介绍了应用程序类的创建和依赖注入的基本概念。在这一章中,我们将深入探讨依赖注入(Dependency Injection, 简称DI)这一重要的设计模式。通过理解依赖注入,你将能够更灵活地管理和使用应用程序中的各个组件。
依赖注入的基本概念
为什么使用依赖注入?
假设你正在开发一个应用程序,其中包含多个组件,例如视图(View)、视图模型(ViewModel)和服务(Service)。每个组件都可能需要依赖其他组件来完成特定的功能。例如,一个视图模型可能会依赖一个服务来获取数据。如果没有依赖注入,每个组件都需要自己创建或查找依赖,这样会导致代码耦合度高,难以测试和维护。
依赖注入通过将依赖关系从组件内部移到外部来解决这个问题。就像在一个团队中,领导分配任务,而不是每个成员自己找任务。这种方式使得组件更加独立和模块化,更容易测试和维护。
依赖注入的关键概念
-
依赖(Dependency) :
- 一个组件需要使用的其他组件。例如,视图模型可能需要一个服务来获取数据。
-
注入(Injection) :
- 通过构造函数、属性或方法将依赖传递给组件的过程。这种方式使得组件不需要自己创建或查找依赖。
-
依赖注入容器(Dependency Injection Container) :
- 管理和提供依赖的工具。在Avalonia中,我们使用
Microsoft.Extensions.DependencyInjection来创建和管理依赖注入容器。
- 管理和提供依赖的工具。在Avalonia中,我们使用
如何使用依赖注入
一个简单的例子
假设我们有一个视图模型 MainWindowViewModel,它需要使用一个服务 DataService 来获取数据。我们可以通过依赖注入来实现这一点。
定义服务
首先,我们定义一个服务 DataService:
csharp 代码解读复制代码namespace AvaloniaWithDependencyInjection.Services
{
public interface IDataService
{
string GetData();
}
public class DataService : IDataService
{
public string GetData()
{
return "Hello, World!";
}
}
}
注册服务
接下来,我们需要在依赖注入容器中注册这个服务。我们已经在 Program.cs 文件中完成了这一部分:
scss 代码解读复制代码public static AppBuilder BuildAvaloniaApp()
=> AppBuilder.Configure()
.UsePlatformDetect()
.WithInterFont()
.LogToTrace();
[STAThread]
public static void Main(string[] args)
{
var services = new ServiceCollection();
services.AddViews()
.AddViewModels()
.AddServices();
ServiceProvider = services.BuildServiceProvider();
BuildAvaloniaApp().StartWithClassicDesktopLifetime(args);
}
在 ServiceCollectionExtensions.cs 文件中,我们注册了所有的视图、视图模型和服务:
swift 代码解读复制代码public static class ServiceCollectionExtensions
{
public static IServiceCollection AddViews(this IServiceCollection services)
{
services.AddSingleton<MainWindow>();
services.AddSingleton<Page1View>();
services.AddSingleton<Page2View>();
return services;
}
public static IServiceCollection AddViewModels(this IServiceCollection services)
{
services.AddSingleton<MainWindowViewModel>();
services.AddSingleton<Page1ViewModel>();
services.AddSingleton<Page2ViewModel>();
return services;
}
public static IServiceCollection AddServices(this IServiceCollection services)
{
services.AddSingleton<IDataService, DataService>();
return services;
}
}
注入依赖
现在,我们可以在 MainWindowViewModel 中注入 DataService:
csharp 代码解读复制代码namespace AvaloniaWithDependencyInjection.ViewModels
{
public class MainWindowViewModel
{
private readonly IDataService _dataService;
public string Data { get; private set; }
public MainWindowViewModel(IDataService dataService)
{
_dataService = dataService;
Data = _dataService.GetData();
}
}
}
代码解释
-
定义服务:
DataService实现了IDataService接口,并提供了GetData方法。
-
注册服务:
- 在
ServiceCollectionExtensions中,我们通过AddServices方法注册了DataService。
- 在
-
注入依赖:
- 在
MainWindowViewModel中,我们通过构造函数注入了IDataService,并在构造函数中调用了GetData方法。
- 在
运行结果
当应用程序启动时,依赖注入容器会自动创建 DataService 实例,并将其传递给 MainWindowViewModel 的构造函数。MainWindowViewModel 会调用 GetData 方法,并将返回的数据赋值给 Data 属性。最终,Data 属性的值会显示在主窗口中。
内部实现
依赖注入容器的工作原理
-
创建服务集合:
- 在
Program.cs中,我们创建了一个ServiceCollection实例。
- 在
-
注册依赖:
- 通过
AddViews、AddViewModels和AddServices方法,我们注册了所有的视图、视图模型和服务。
- 通过
-
构建服务提供者:
- 使用
services.BuildServiceProvider()方法,我们构建了一个IServiceProvider实例。
- 使用
-
获取服务:
- 在
App.axaml.cs文件中,我们通过Program.ServiceProvider.GetRequiredService和() Program.ServiceProvider.GetRequiredService方法从服务提供者中获取主窗口和主窗口视图模型。()
- 在
序列图
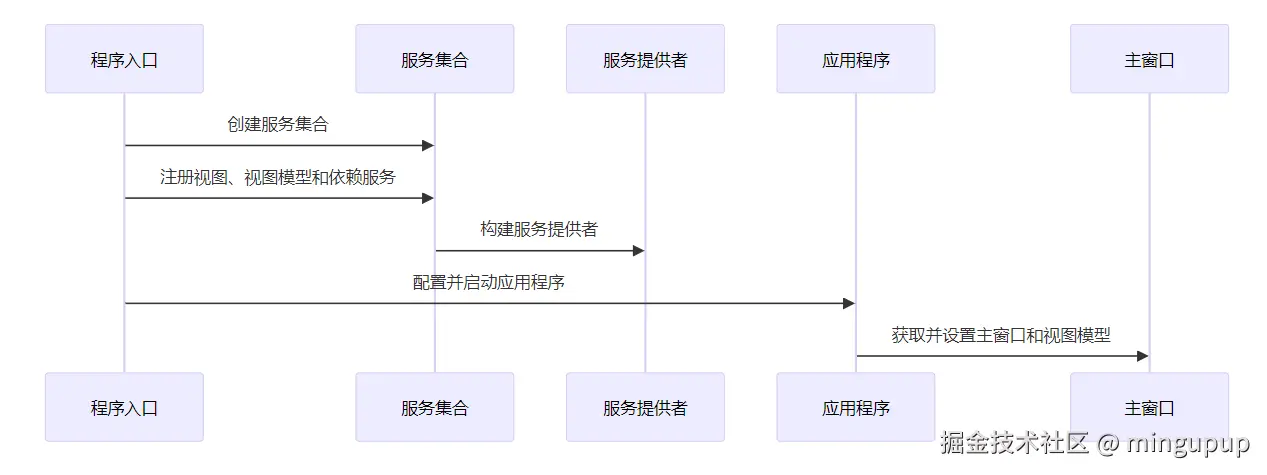
结论
通过本章,我们深入探讨了依赖注入的基本概念和使用方法。我们学习了如何通过依赖注入来管理和使用应用程序中的各个组件,使得代码更加模块化和易于测试。希望你现在能够理解依赖注入的重要性和使用方法。
接下来,我们将学习 应用程序生命周期 的相关内容。请继续阅读,了解应用程序的各个生命周期阶段。
最后
多的就不放了,感兴趣的朋友可以去GitHub上看完整的,让我惊讶的地方是感觉gemini-2.5-pro-exp-03-25的图画的很不错,在教程中多放点这种图,会让读者更加清晰易懂。
评论记录:
回复评论: