
前言:
前文提到,当我们遇到一个比较复杂的问题时,通常会将其分解为多个比较简单的等价子问题,分别求得等价子问题的解就可以得到原复杂问题的解。分解复杂问题通常也有两个思考维度:一个是从空间上将原大规模问题分割为多个相互独立且结构相似的小规模等价子问题,再将多个小规模子问题的解合并为原问题的解,这就是分治算法;另一个是从时序上将原多阶段决策复杂问题拆解为多个前后相继的单阶段决策子问题,从初始状态开始按照DFS 顺序依次求得每个单阶段决策子问题的解,所有满足约束条件的决策路径就构成了原问题的解,这就是回溯算法。
分治算法将大规模问题分割为多个小规模子问题的过程,实际上也大幅降低了其时间复杂度,比如排序算法从插入排序时间复杂度O(n2) 降低到归并排序时间复杂度O(n*logn)。而且分治算法分割出的小规模子问题是相互独立的,这就方便使用并行计算,进一步提高效率。
回溯算法将多阶段决策问题拆解为多个单阶段决策子问题,虽然可以按照DFS 规律无遗漏的穷举所有可能的解,但是该算法的时间复杂度太高,比如全排列的时间复杂度为O(nn)、全组合的时间复杂度为O(2n),而且多个单阶段决策子问题是有前后相继关系的,并不方便直接使用并行计算提高效率。如果不能降低回溯算法的时间复杂度,该算法就不适合用来处理大规模数据,适用场景或范围比较受限,有没有什么办法降低回溯算法的时间复杂度呢?
要想降低回溯算法的时间复杂度,让计算机少做无用功,就需要提供更多的信息。从信息论的角度,提供越多的信息,信息熵越低,不确定性越小,计算机求解去消除不确定性需要做的工作就越少。所以,要想提高回溯算法的时间复杂度,就需要找到更多的信息提前消除更多的不确定性(也可以理解为提前大幅剪枝)。当然,也不是多阶段决策问题都能找到更多更有效的信息,比如全排列中的N 皇后问题就很难再降低其时间复杂度。
我们在解决现实问题时,通常并不需要求出所有可能的解,而是更关注最优解。从前篇博文介绍的决策树可以看出,若只求最优解,可能只需要遍历其中的某一条或某几条决策路径,这将大幅降低多阶段决策问题的时间复杂度。理想情况下,如果每个阶段选择局部最优解(只跟当前状态有关),最后可以得到全局最优解(也即符合贪心选择性),只需要遍历多阶段决策树的其中一条选择路径(从初始根结点到某个最优解叶子结点),时间复杂度降低到O(n),这就是贪心算法。但现实中符合这类情况的问题并不多,通常当前阶段的局部最优解简单串联并不能得到全局最优解,我们该如何高效求解这类比较普遍的多阶段决策最优解问题呢?
一、从回溯剪枝到动态规划
如何求解最优解问题呢?如果你学过线性代数,很自然会想到线性规划(在线性约束条件形成的可行域内,找到线性目标函数的最优值),它可以用来解决现实中很多资源受限情况下进行最优化配置的问题。线性规划是运筹学的一个分支,我们关注的多阶段决策最优解问题在运筹学中也有研究,那就是动态规划(主要求解以时间划分阶段的动态过程的决策最优化问题)。
动态规划中的动态强调将原多阶段决策问题按时间划分为一系列前后相继的单阶段决策问题,这一点跟回溯算法划分阶段是类似的,也与线性规划这类与时间无关的静态规划形成对比(可将线性规划人为引入时间因素划分阶段,然后使用动态规划方法求解)。动态规划相比回溯算法高效求解最优决策序列的关键是,找到跟最优决策相关的最少路径(也即最优子结构),剪除跟最优决策无关的路径(通常还需要避免重叠子问题的重复求解),大幅提高计算效率。
动态规划中有一类比较简单且经典的问题 — 背包问题,下面以完全背包问题中的零钱兑换问题为例,看看回溯算法、贪心算法、动态规划算法求解该问题的思路有何区别?
[Leetcode - 322] 零钱兑换:给定不同面额的硬币 coins(可以认为每种硬币的数量是无限的,也即完全背包问题)和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
1.1 回溯剪枝求解零钱兑换问题
零钱兑换问题实际上是一个组合总和问题,不同面额的硬币coins 实际上就是构成组合的无重复数字序列(每种面额数量不限),目标总和为amount,可以使用前文介绍的回溯算法求解组合总和问题的思路穷举所有满足约束条件的组合。最后,在满足目标总和为amount 的所有组合中,找到元素个数最少的组合(也即硬币个数最少)即可得到答案。按照上述逻辑,使用组合总和思路编写零钱兑换问题的实现代码如下:
#include
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
组合总和的时间复杂度在前文已经分析过了,由于组合总和实际上是遍历全组合,全组合的时间复杂度为O(2N),空间复杂度为O(N),其中N 为构成组合的元素个数。在本例中,N 就是硬币数量,但本题硬币数量不确定(同一面额硬币数量不限),约束硬币总数量的条件是目标总和 S(也即amount,下文为表述方便简称为S)和n 种不同面额(c1、c2…cn),可以得到硬币数量最多为S 除以最小面额,硬币面额为常数,则平均硬币数量可以表示为S/n,用S/n 替换上面的N,得到时间复杂度O(2S/n) 和空间复杂度O(S/n)。
使用回溯算法求解零钱兑换问题的复杂度比较高,我们在leetcode 上提交代码测试结果如下:
Time Limit Exceeded
57/182 cases passed (N/A)
…
看来本题不能简单使用回溯算法穷举所有的组合,需要找到更高效的解法。
1.2 贪心算法求解零钱兑换问题
零钱兑换问题是要求得满足目标和的最少硬币数量,实际上是一个最优解问题。回溯算法复杂度高的原因是穷举了所有可能的组合,要想降低复杂度,可以只沿着某个最优决策路径遍历。
在零钱兑换问题中,使用最少硬币数量的组合总和问题,实际上就是达到目标总和需要的最少阶段数(每个阶段选择一枚硬币)。我们容易想到,要想使用最少的硬币数量达到目标总和,优先选择面额最大的硬币能更快接近目标总和,这正是贪心算法的思想。
贪心算法假设每个阶段选择最优决策(也即最快逼近目标的选择分支),最后可以得到全局最优解(也即符合贪心选择性)。比如硬币面额有{1,2,5} 三种,目标总和为11,按照贪心算法我们先选择最大面额5,剩余目标总和为6, 继续选择最大面额5,剩余目标总和1,此时继续选择最大面额将超出目标总和,选择次大面额也超出目标总和,直到选择面额1 正好符合目标总和,于是找零面额分别为{5,5,1}。
我们按照贪心算法的思路编写求解零钱兑换问题的实现代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
上述算法的时间复杂度为O(n),空间复杂度为O(1),其中n 为硬币的面额数量。贪心算法的效率还是很高的,但是能解决我们的问题吗?我们将代码提交到leetcode 测试结果如下:
Wrong Answer
46/182 cases passed (N/A)
Testcase
[186,419,83,408]
6249
Answer
-1
Expected Answer
20
第46 个case Fail 了,我们按照贪心算法的思路手动验证下6249 - 14 * 419 - 2 * 186 = 11,最小面额83 大于11,所以按照贪心算法的思路确实无法得到满足目标总和的组合。也可以举个更简单的例子,硬币面额{1,5,11},目标总和15,按照贪心算法的思路,计算过程15 - 11 - 4 * 1 = 0,最少硬币数为 1 + 4 = 5 个,但我们可以找到更少的硬币组合 5 * 3 = 15,也即使用3 枚五元的硬币即可,可见贪心算法的适用场景有限。
使用贪心算法需要事前证明这个多阶段决策问题确实符合贪心选择性(也即每次选择最快逼近目标值的决策分支,最后可以得到全局最优解),如果在不满足贪心选择性的场合使用了贪心算法,将可能得不到解或者得到的不是最优解(如果不要求最优解,倒也可以使用贪心算法高效获得一个近似次优解)。
我国的币值{1,5,10,20,50,100} 和美元币值{0.01,0.05,0.1,0.25,0.5,1,2,5,10,20,50,100} 经证明都是符合贪心选择性的,可以使用贪心算法快速求解相应的零钱兑换问题,但其它币值是否符合贪心选择性就要在使用前证明下了。
1.3 动态规划求解零钱兑换问题
求解零钱兑换问题,回溯算法效率太低,贪心算法适用范围受限,该如何求解呢?前面也提到运筹学中的一个分支 — 动态规划,是求解多阶段决策最优解的一种策略,我们尝试使用动态规划算法来解决该问题。
动态规划求解多阶段决策最优解问题,首先需要找到最优子结构(也即可以通过子问题的最优解推导出原问题的最优解),这有点像博文递归与递推中介绍的抢数字游戏面试题,通过递归这种逆向思维比较好分析。
我们求解线性规划问题需要先找到约束条件和目标函数,求解动态规划问题也类似。零钱兑换中的目标函数假设为f(S) ,表示目标总和为S 时需要的最少硬币数量,假设最后选择的硬币面值为ci,则从前一阶段推进到下一阶段的递推公式为f(S) = f(S - ci) + 1, 但我们不知道最后一枚硬币的确切面值ci,只知道它是所有可供选择面值之一。假设硬币面额分别为{c[0],c[1],…, c[n-1]},那么目标函数从前一状态往下一阶段推进决策的递推公式为f(S) = min{f(S - c[0]), f(S - c[1]),…, f(S - c[n-1])} + 1,也即前一阶段所有可选分支中的最小值加一。这个递推公式在动态规划中就叫做状态转移方程,动态规划中的每次决策可选择的分支即为一个状态,每个决策过程即为一个阶段,状态转移方程指的是从前一个状态推进决策到下一个状态,实际上就是递归中的递推公式。
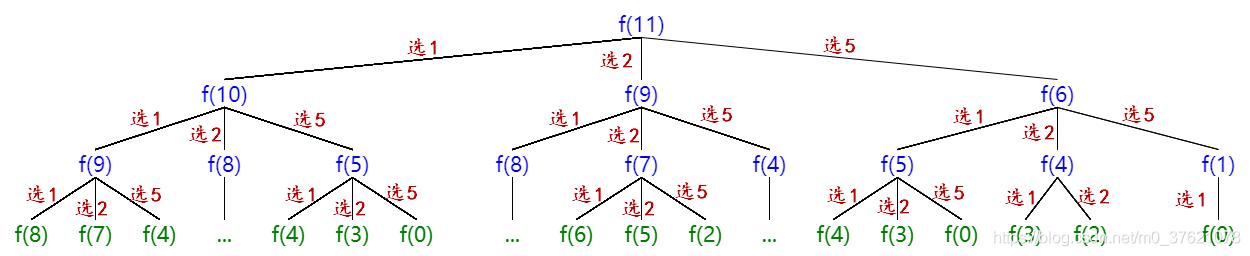
举个例子,假如硬币面额{1,2,5},目标总和11,需要最少的硬币数f(11) = min{f(11 - 1), f(11 - 2), f(11 - 5)} + 1,也即f(11) 的值是f(10)、f(9)、f(6) 这三个值中的最小值加一。除了目标函数f(S) 和递推公式或状态转移方程,还需要边界约束条件,我们的目标是正好凑够目标总和S,从后往前逆向递归到f(0) 即为边界约束条件,要想凑够0 元不需要任何硬币,所以f(0) = 0。零钱兑换问题就转换为到达f(0) 的最短路径(也即需要选择硬币的次数或阶段最少),该例中做选择的递归决策树如下:
递归中的边界约束条件和递推公式共同构成了动态规划中的状态转移方程,整理上面分析的零钱兑换问题中的状态转移方程如下:
f
(
S
)
=
{
−
1
,
S
<
0
0
,
S
=
0
m
i
n
{
f
(
S
−
c
[
0
]
)
,
f
(
S
−
c
[
1
]
)
,
⋯
,
f
(
S
−
c
[
n
−
1
]
)
}
+
1
,
S
≥
c
[
i
]
f(S)= {−1,S<00,S=0min{f(S−c[0]),f(S−c[1]),⋯,f(S−c[n−1])}+1,S≥c[i]
按照上面的状态转移方程编写零钱兑换问题的求解代码如下:
int dp_coins(vector<int>& coins, int amount)
{
// 边界约束条件,对应状态转移方程中的前两种情况
if(amount < 0)
return -1;
else if(amount == 0)
return 0;
else{ // 状态转移方程中的第三种情况,也即递推公式,minCoins为当前阶段的最少硬币数,相当于f(amount)
int minCoins = INT_MAX;
for (int i = 0; i < coins.size(); i++) {
if(amount - coins[i] >= 0){
// prevMin 相当于f(amount - coins[i]),对每个分支求 minCoins = min(minCoins, prevMin + 1),相当于minCoins = min{amount - coins[0],...,amount - coins[i],...,amount - coins[coins.size() - 1] } + 1,其中amount >= coins[i]
int prevMin = dp_coins(coins, amount - coins[i]);
if(prevMin >= 0)
minCoins = min(minCoins, prevMin + 1);
}
}
return minCoins == INT_MAX ? -1 : minCoins;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
上面的代码相比回溯算法看起来并没有明显降低时间复杂度,我们可以在leetcode 上提交代码测试结果如下:
Time Limit Exceeded
15/182 cases passed (N/A)
跟我们预想的一致,效率还不如回溯算法呢,问题出在哪呢?再看上面的递归决策树,发现有很多重复求解子问题的过程(也即重叠子问题),重复求解自然降低了效率,该如何避免呢?回顾博文递归中解决斐波那契数列重叠子问题的方案,我们可以添加备忘录解决,将上面的函数添加备忘录后的代码如下:
int dp_memo_coins(vector<int>& coins, int amount, vector<int>& memo)
{
if(amount < 0)
return -1;
else if(amount == 0)
return 0;
// 如果备忘录中已有子问题的解,则直接查表返回解
if(memo[amount] != INT_MAX)
return memo[amount];
else{ // 若备忘录中没有子问题的解,则求得解后将其保存到备忘录中
int minCoins = INT_MAX;
for (int i = 0; i < coins.size(); i++) {
if(amount - coins[i] >= 0){
int prevMin = dp_memo_coins(coins, amount - coins[i], memo);
if(prevMin >= 0)
minCoins = min(minCoins, prevMin + 1);
}
}
memo[amount] = minCoins < INT_MAX ? minCoins : -1;
return memo[amount];
}
}
int main(void)
{
......
vector<int> memo(amount + 1, INT_MAX);
int minCoins = dp_memo_coins(coins, amount, memo);
......
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
使用备忘录处理重叠子问题后的动态规划算法时间复杂度是多少呢?假设目标总和S,硬币面值有n 种,备忘录一共有S + 1 个子问题的解需要计算,时间复杂度为O(S),每个子问题需要遍历n 个选择分支并从中找到最小值,所以求解每个子问题的时间复杂度为O(n),动态规划总的时间复杂度为O(n*S),空间复杂度主要是备忘录开销为O(S)。
从时间复杂度上看,动态规划比回溯算法高效得多,虽然执行效率还比不上贪心算法,但适用范围比贪心算法更广,因此也更实用。我们将带备忘录的动态规划代码提交到leetcode 测试结果如下:
Accepted
182/182 cases passed (100 ms)
Your runtime beats 84.76 % of cpp submissions
Your memory usage beats 80.9 % of cpp submissions (13.9 MB)
我们的代码通过了所以的测试case,并且执行时间和空间也都超过了80% 的提交,效率还不错。
博文递归设计递推实现中介绍了函数的递归解法都可以转换为迭代解法。对于动态规划来说,递归解法可以称为状态转移方程法,迭代解法可以称为状态转移表法,迭代解法实际上就是按照递推公式或状态转移方程从初始条件f(0) = 0 出发往后遍历填充备忘录或者状态转移表的过程。按照这个思路,将动态规划的递归解法改写为迭代解法的代码如下:
int dp_iter_coins(vector<int>& coins, int amount)
{
if(amount < 0 || (coins.empty() && amount > 0))
return -1;
if(amount == 0)
return 0;
// 递归解法中的备忘录,也可称为状态转移表,长度为amount + 1,初始值为大于amount 的值,递归解法备忘录初始化为INT_MAX,这里初始化为amount + 1 效果一样
vector<int> dp_table(amount + 1, amount + 1);
dp_table[0] = 0; // 边界约束条件,也即f(0) = 0
// 按照递推公式或者状态转移方程从前往后依次填表
for(int s = 1; s <= amount; s++){
// 相当于dp_table[s] = min{dp_table[s - coins[0]],...,dp_table[s - coins[i]],...,dp_table[s - coins[coins.size()-1]] } + 1,其中s >= coins[i]
for (int i = 0; i < coins.size(); i++)
if(s - coins[i] >= 0)
dp_table[s] = min(dp_table[s], dp_table[s - coins[i]] + 1);
}
return dp_table[amount] > amount ? -1 : dp_table[amount];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
迭代解法或者状态转移表法的时间复杂度与空间复杂度和递归解法一致,在实际执行中,迭代解法相当于递归的后半部分,省去了大量中间状态入栈与出栈的操作,节省了系统栈的空间占用,执行效率比递归解法略高。由于动态规划问题一般都具有重叠子问题,所以通常使用迭代解法或者状态转移表法求解,分析问题找寻递推公式或状态转移方程的过程使用递归逆向思维更简单些。
二、什么是动态规划?
前面使用动态规划高效解决了零钱兑换问题,也初步了解了动态规划的思想,这里再深入谈论下什么样的问题可以用动态规划解决?解决动态规划问题的一般思考过程是什么样的?分治、回溯、贪心、动态规划这几种算法思想有什么区别和联系?
2.1 怎样的问题可以使用动态规划求解?
前面已经谈到,动态规划是运筹学的一个分支,主要用来求解多阶段决策最优解问题:
- 动态:指的是原问题可以按时间划分(与时间相关的为动态,与时间无关的为静态)为一系列前后相继的决策阶段(每个决策阶段都对应着一组可供选择的状态);
- 规划:指的是寻找最优解的过程(比如线性规划),也即在多阶段决策问题中寻找一组最佳的决策序列,经过这组决策序列可以得到我们期望的全局最优解。
动态规划求解多阶段决策最优解问题通常具有以下三个特征:
- 最优子结构:指的是我们可以通过每个单阶段决策子问题的最优解推导出原问题的全局最优解,在多阶段决策最优解问题中可以通过前面阶段的状态推导出后面阶段的状态,实际上就是递归设计中的递推公式,也即动态规划中的状态转移方程;
- 无后效性:指的是某个阶段的状态一旦确定,就不受后面阶段的决策影响,也体现了多个决策阶段之间的时序单向性。因此,我们在推导后面阶段的状态时,只需要关心前面阶段的状态值,而不需要关心这个状态是怎么一步一步推导出来的;
- 重叠子问题:指的是不同的决策序列,到达某个阶段时,可能会产生重复的状态。计算机重复求解这些重复的状态会做很多无用功,我们可以使用备忘录记录这些状态值,当遇到重复的状态时直接查表获得状态值,大幅提高了计算效率。
2.2 求解动态规划问题的一般过程是怎样的?
我们知道了动态规划主要是求解多阶段决策最优解问题的,自然需要先判断原问题是否可以按时间划分为多个单阶段决策问题?比如上面的零钱兑换问题,要找零到目标金额,需要一枚硬币一枚硬币的选择,每次决策都有好几种面额的硬币可供选择,每次选择硬币就是一个单阶段决策问题,多次选择硬币凑够目标金额就是一个多阶段决策问题,要求解的是凑够目标金额需要的最少硬币数,说明这是一个多阶段决策最优解问题,可以使用动态规划求解。
动态规划求解首先要找到最优子结构并判断决策过程无后效性,实际上就是找到动态规划求解的状态转移方程或者递推公式。在递归设计中,我们通过逆向思维找到递推公式和边界约束条件;在动态规划中,由于要求最优解,我们还需要找到目标函数及其影响目标函数的状态变量。零钱兑换示例中,最优解是最少硬币数,影响最优解的状态变量分别是硬币面额种类coins 和目标金额S,因此目标函数可以表示为F(coins, S),其中coins 为每个阶段决策可供选择的分支选项,S 是经过一系列决策需要逼近或达到的目标。
有了最优解目标函数F(coins, S),接下来就可以找递推公式或状态转移方程了,这里有两种方法可供使用,一种是自顶向下的递归解法,一种是自底向上的递推解法。我们先看递归解法,也即先画出递归决策树,在递归决策树中coins 变量包含在每个决策分支中,因此最优解目标函数简写为F(S),画出递归决策树如下(假设coins = {1, 2, 5}, S = 11):
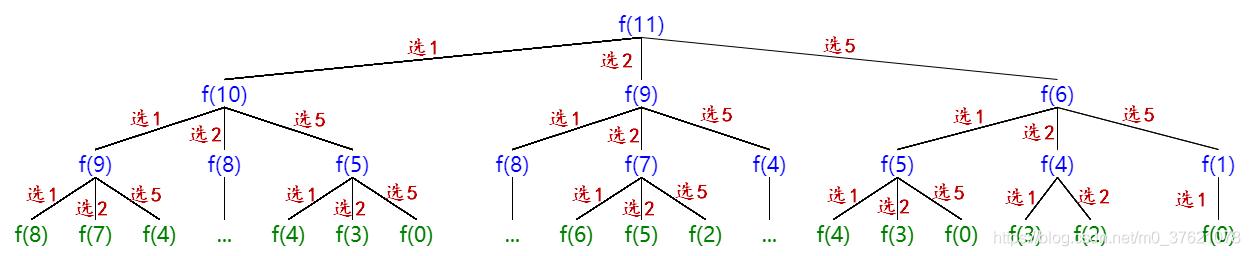
从递归决策树可以看出目标最优值F(S) 可以仅由前一阶段各状态决定,也即前一阶段各状态最小值加一,F(S) = min{F(S - c[0]), F(S - c[1]),…, F(S - c[n-1])} + 1,其中S >= c[i]。有了递推公式再找到边界约束条件,当目标金额为0 是不需要任何硬币,则有F(0) = 0,二者共同构成了状态转移方程如下:
f
(
S
)
=
{
−
1
,
S
<
0
0
,
S
=
0
m
i
n
{
f
(
S
−
c
[
0
]
)
,
f
(
S
−
c
[
1
]
)
,
⋯
,
f
(
S
−
c
[
n
−
1
]
)
}
+
1
,
S
≥
c
[
i
]
f(S)= {−1,S<00,S=0min{f(S−c[0]),f(S−c[1]),⋯,f(S−c[n−1])}+1,S≥c[i]
我们只需要将状态转移方程翻译为代码即可。由于从递归决策树上可以看到大量的重复子问题,所以需要使用备忘录解决重叠子问题重复计算的问题,也就完成了原问题的求解。
自底向上的递推解法是怎样分析的呢?我们依然从最优解目标函数F(coins, S) 着手,假设coins = {1, 2, 5},边界约束条件依然是F(0) = 0,从初始状态往后填写状态转移表的过程如下:
| S | F(S),其中coins = {1, 2, 5} |
|---|---|
| 0 | F(0) = 0 |
| 1 | F(1) = min{F(1-1)} + 1 = 0 + 1 = 1 |
| 2 | F(2) = min{F(2-1), F(2-2)} + 1 = 0 + 1 = 1 |
| 3 | F(3) = min{F(3-1), F(3-2)} + 1 = 1 + 1 = 2 |
| 4 | F(4) = min{F(4-1), F(4-2)} + 1 = 1 + 1 = 2 |
| 5 | F(5) = min{F(5-1), F(5-2), F(5-5)} + 1 = 0 + 1 = 1 |
| 6 | F(6) = min{F(6-1), F(6-2), F(6-5)} + 1 = 1 + 1 = 2 |
| 7 | F(7) = min{F(7-1), F(7-2), F(7-5)} + 1 = 1 + 1 = 2 |
| 8 | F(8) = min{F(8-1), F(8-2), F(8-5)} + 1 = 2 + 1 = 3 |
| 9 | F(9) = min{F(9-1), F(9-2), F(9-5)} + 1 = 2 + 1 = 3 |
| 10 | F(10) = min{F(10-1), F(10-2), F(10-5)} + 1 = 1 + 1 = 2 |
| 11 | F(11) = min{F(11-1), F(11-2), F(11-5)} + 1 = 2 + 1 = 3 |
将上面的填表过程翻译为代码即可解决零钱兑换问题,而且填写后面的表格时自动查询使用前面已填写表格的值,相当于已经避免了重叠子问题的重复计算,跟递归加备忘录的解法是等效的。
从上面递归解法和迭代解法的过程可以看出,求解动态规划问题主要分为以下几个步骤:
- 尝试将原问题按时序划分为一系列单阶段决策问题,并找到要求的最优解是什么?
- 假设一个最优解目标函数F(x),并找到影响最优解的状态变量。比如零钱兑换中的F(S, coins) 表示凑够目标S 需要的最少硬币数,其中coins 是每个阶段可供决策的状态或选项,S 是要凑够的目标金额;
- 根据最优解目标函数F(S, coins) ,尝试画出递归决策树,有哪些阶段以及每个阶段可供选择的状态分支有哪些,都比较直观清楚,回溯算法也常用递归决策树帮助分析问题;
- 根据递归决策树,使用逆向思维,思考是否可以从前一阶段推导到下一阶段,比如尝试从次末阶段推导到最末阶段,实际上就是找递推公式或者状态转移方程。比如零钱兑换中选择最后一枚硬币前的状态有F(S - c[0]), F(S - c[1]),…, F(S - c[n-1]) 这几个,选择最后一枚硬币后达到目标最优解F(S),很自然的想到前一阶段所有状态中的最小值加最后一枚硬币即可得到最优解,也就找到了递推公式F(S) = min{F(S - c[0]), F(S - c[1]),…, F(S - c[n-1])} + 1,其中S >= c[i]。找到了递归公式,再找到递归边界条件F(0) = 0,就构成了完整的状态转移方程;
- 从递归决策树发现很多重叠子问题,选择使用备忘录解决重叠子问题重复求解的问题,然后将状态转移方程翻译为代码即可;
- 如果想写成迭代递推的形式,可以按照状态转移方程的思路从初始条件开始往后逐项填写状态转移表。从目标值比较小的简单问题分析,比如coins = {1, 2, 3}、S = 6,也有助于启发我们找到递推公式或状态转移方程,这也是由个别示例推广到一般规律的方法。
2.3 分治、回溯、贪心、动规算法有哪些异同?
分治算法与回溯算法的异同在前篇博文已经介绍过了,回溯算法、贪心算法、动态规划之间的异同在前面求解零钱兑换问题时也有对比,这里简单总结下:
- 分治算法:在空间上将大规模问题分割为多个相互独立且结构相似的小规模子问题,这类问题规模小到一定程度可以直接求解,再将多个子问题的解合并为原问题的解。由此可见,分治算法很适合用来处理大规模问题,通过缩小规模大幅降低计算复杂度,因为分割出的子问题相互独立,也很适合使用并行计算,比如MapReduce;
- 回溯剪枝:在时序上将原问题划分为前后相继的一系列单阶段决策子问题,每个决策阶段都有一组可供选择的状态分支,时间上从初始状态到结束状态连续的一系列决策阶段构成一个决策序列,每个决策序列可以获得一个可行解,遍历所有决策序列可以穷举出所有可行解(通常使用DFS 遍历规律),比如排列组合问题;
分治算法和另外三种算法算是两个类别,分治算法主要从空间上将大规模问题分割为多个相互独立的小规模子问题,回溯剪枝、动态规划、贪心算法主要是解决多阶段决策问题,因此主要从时间上将多阶段决策问题划分为一系列前后相继的单阶段决策问题。
回溯算法和另外两种也可以再细分为两类,回溯算法通常穷举所有可行解,因此时间复杂度比较高阶,不适合处理大规模问题,而现实中通常只关心最优解,因此就细分出了多阶段决策最优解问题。回溯算法是穷举多阶段决策问题的所有可行解,动态规划和贪心算法是求解多阶段决策问题的最优解。理论上,动态规划和贪心算法可以求解的问题,回溯算法也都能求解,只是效率更低。
- 动态规划:将原问题按时间划分为一系列前后相继的单阶段决策最优解子问题(也即最优子结构),每个单阶段子问题的最优解可以由前面阶段的最优解推导出来,这就是动态规划的核心 – 状态转移方程(原意为描述前一阶段最优状态转移到下一阶段最优状态的方程,可以理解为递推公式加递归边界),由于后一阶段最优解通常与前一阶段多个状态相关,可能引起大量重叠子问题,需要使用备忘录或状态转移表解决重叠子问题重复求解问题;
- 贪心算法:实际上是动态规划问题的一种特殊情况,也是将原问题按时间划分为一系列前后相继的单阶段决策最优解子问题(也即最优子结构)。与动态规划不同的是,每个单阶段子问题的最优解不是由前面阶段的最优解推导来的,而是在每个阶段选择最快逼近目标值的状态分支,因此不存在状态转移方程(自然也不存在重叠子问题)。每个阶段都选择最快逼近目标值的状态分支,可以在整个决策序列获得全局最优解,这就是贪心选择性。如果经证明原问题符合贪心选择性,使用贪心算法可以获得更高的执行效率,比如Huffman 编码;反之,如果原问题不符合贪心选择性而错误使用贪心算法,可能求得错误的全局最优解。
在求解复杂问题时,根据信息论原理,问题中提供的信息越多,整个系统的信息熵越小,求解过程中的计算量越少。动态规划求解多阶段决策最优解,每个阶段子问题的最优解需要由前面阶段的最优解推导出来,而不能直接求得。贪心算法中,每个阶段子问题的最优解可以直接求得(也即选择最快逼近目标值的状态分支),计算效率自然比动态规划更高。但在使用贪心算法前,需要确保或证明原问题符合贪心选择性,否则可能求得不期望的错误结果。由此可见,预先需要提供的信息越多,解决方案的适用范围越窄,求解的计算效率越高;反之,预先需要提供的信息越少,解决方案的适用范围越广,求解的计算效率越低。
三、动态规划算法应用示例
3.1 如何实现拼写纠错功能?
前篇博文介绍了使用Trie 树可以实现搜索引擎、文本编辑等的关键词拼写提示功能,这样可以节省用户输入关键词的时间,也解决了关键词记忆不准确可能拼错的烦恼。如果我们一不小心输错单词了,搜索引擎也会非常智能的检测出拼写错误,并使用对应的正确单词进行搜索。搜索引擎和文本编辑器的拼写纠错功能是如何实现的呢?
检测出用户输入的单词不存在比较简单,前面提到的Trie 树就可以实现,但如何实现纠错功能,并给出可能正确的单词候选呢?用户可能输入的某个字符错误,那就需要列举出与用户输入单词相似度最高的候选单词,原问题就转换为如何量化并计算两个单词或字符串的相似度?
有一个非常著名的量化两个字符串相似度的方法 — 编辑距离(Edit Distance),指的是将一个字符串转换成另一个字符串需要的最少编辑操作次数(比如增加一个字符、删除一个字符、替换一个字符)。编辑距离越大,说明两个字符串的相似程度越小;反之,编辑距离越小说明两个字符串的相似程度越大。对于两个完全相同的字符串来说,编辑距离就是 0。
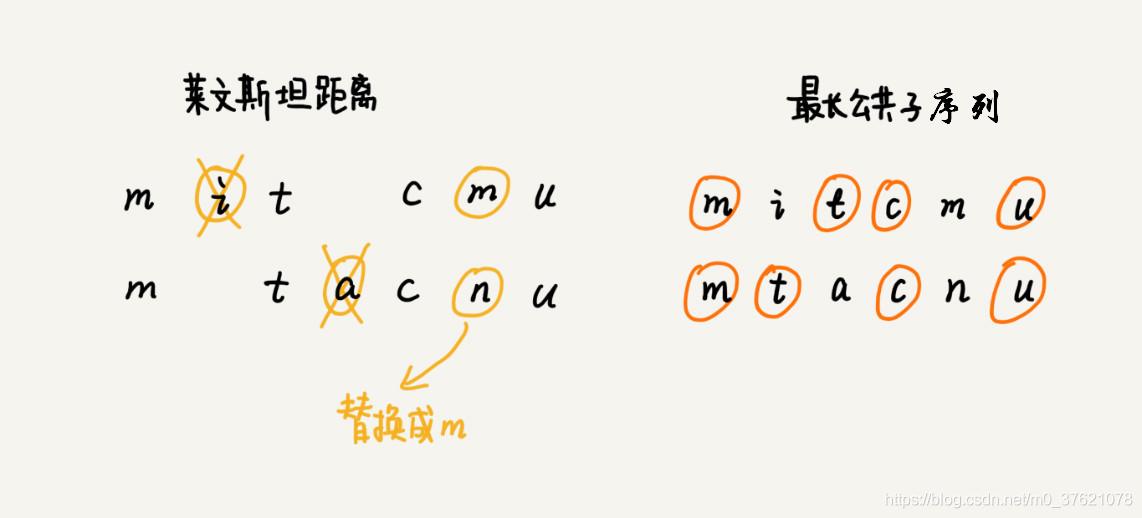
根据所包含的编辑操作种类的不同,编辑距离有多种不同的计算方式,比较著名的有莱文斯坦距离(Levenshtein distance)和最长公共子序列长度(Longest Common Subsequence length)。其中,莱文斯坦距离允许增加、删除、替换字符这三个编辑操作,最长公共子序列长度只允许增加、删除字符这两个编辑操作。而且,莱文斯坦距离和最长公共子序列长度,从两个截然相反的角度,分析字符串的相似程度。莱文斯坦距离的大小,表示两个字符串差异的大小;而最长公共子序列的大小,表示两个字符串相似程度的大小。举个例子,两个字符串 mitcmu 和 mtacnu 的莱文斯坦距离是 3,最长公共子序列长度是 4:
我们从leetcode 上选择一道题,看看如何使用动态规划求解两个字符串的编辑距离:
[Leetcode - 72] 编辑距离:给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:插入一个字符、删除一个字符、替换一个字符。
从题目描述,可以对一个单词进行插入、删除、替换三种操作,可以知道题目要我们求解的是莱文斯坦距离。
要计算两个字符串的编辑距离,需要逐字符比较,每个字符比较的过程可以看作一个阶段,每个阶段的比较都有相同和不同两种结果,字符相同则编辑距离不变,字符不同则编辑距离加一,求解目标是最少操作次数(也即编辑距离),因此该问题可以看作一个多阶段决策最优解问题。
逐字符比较两个字符串,影响最优解的状态变量有哪些呢?主要是两个字符串已比较的字符数,也即两个字符串的当前长度 i 和j,我们将两个字符串的编辑距离表示为最优解目标函数F(word1, i, word2, j),其中 word1 和word2 分别为要计算编辑距离的字符串,i 和j 分别为当前已比较的字符数,F(word1, word1.length(), word2, word2.length()) 则表示word1 和word2 的编辑距离。
有了最优解目标函数F(word1, i, word2, j),知道了影响目标解的状态变量 i 和j,每个阶段可供选择的状态有哪些呢?前面谈到每个阶段比较两个字符word1[i-1] 和word2[j-1],都有相同和不同两个结果,每个决策对状态变量i 和j 分别有什么影响呢?我们使用递归逆向思维,从后往前比较字符:
- 如果word1[i-1] == word2[j-1]:编辑距离不变,目标函数从F(i, j) 转移到F(i-1, j-1),继续比较word1[i-2] 与word2[j-2](由于i, j 定义的是字符数,因此下标为字符数减一);
- 如果word1[i-1] != word2[j-1]:编辑距离加一,但这里对不相等字符的处理分别有插入、删除、替换三种操作可供选择。word1 插入一个字符和word2 删除一个字符是等价的,目标函数均从F(i, j) 转移到F(i, j-1);word1 删除一个字符和word2 插入一个字符是等价的,目标函数均从F(i, j) 转移到F(i-1, j);word1 替换一个字符和word2 替换一个字符是等价的,目标函数均从F(i, j) 转移到F(i-1, j-1)。从三个分支中选择最优解,也即F(i, j) = min{F(i, j-1), F(i-1, j), F(i-1, j-1)} + 1, 这就是状态转移方程的一部分。
上面已经分析出了递推公式,边界约束条件是什么呢?假如word1 为空字符串(也即i = 0),编辑距离F(0, j) = j;假如word2 为空字符串(也即j = 0),编辑距离F(i, 0) = i。写出计算编辑距离问题的状态转移方程如下:
f
(
i
,
j
)
=
{
i
+
j
,
i
=
0
或
j
=
0
f
(
i
−
1
,
j
−
1
)
,
s
1
[
i
−
1
]
=
s
2
[
j
−
1
]
m
i
n
{
f
(
i
,
j
−
1
)
,
f
(
i
−
1
,
j
)
,
f
(
i
−
1
,
j
−
1
)
}
+
1
,
s
1
[
i
−
1
]
≠
s
2
[
j
−
1
]
f(i,j)= {i+j,i=0或j=0f(i−1,j−1),s1[i−1]=s2[j−1]min{f(i,j−1),f(i−1,j),f(i−1,j−1)}+1,s1[i−1]≠s2[j−1]
按照上面的分析逻辑,画出求解编辑距离的递归决策树如下:
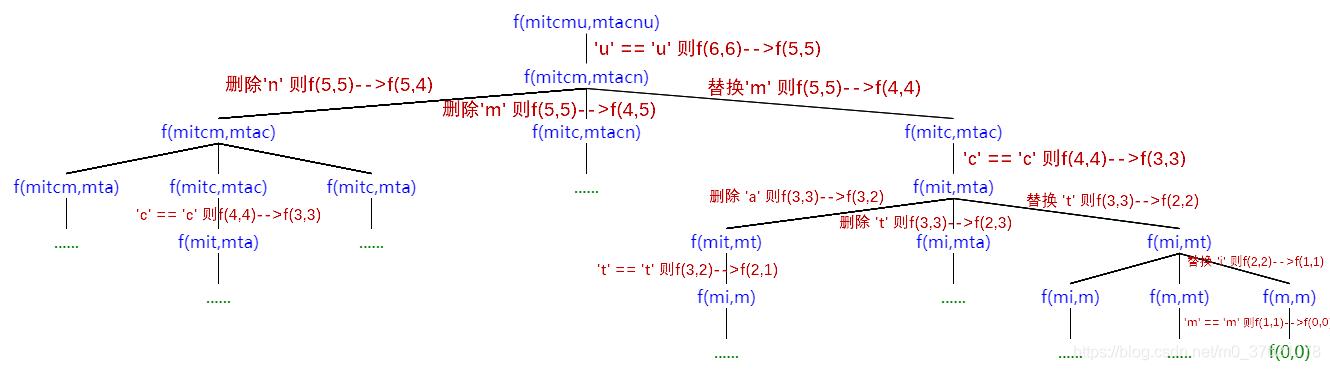
从上面的递归决策树也可以看出有不少重复的子问题,我们使用备忘录解决重叠子问题的重复计算问题,按照状态转移方程编写求解编辑距离的实现代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
求解编辑距离的时间复杂度是多少呢?单阶段决策子问题的数量与备忘录的大小一致,备忘录的大小为len1*len2,求解每个子问题最多计算3次,所以总的时间复杂度为O(len1 * len2),空间复杂度也即备忘录占用的空间大小,也为O(len1 * len2)。
我们向leetcode 提交代码,测试结果如下:
Accepted
1146/1146 cases passed (92 ms)
Your runtime beats 5.09 % of cpp submissions
Your memory usage beats 5 % of cpp submissions (79.5 MB)
通过了所有测试,说明我们的代码逻辑没问题,但时间效率和空间占用并不理想。我们知道迭代递推解法相比递归解法,虽然时间和空间复杂度一致,但减少了入栈出栈的开销,实际执行效率应该会比递归解法更高些,我们尝试将上面的递归代码修改为迭代递推的形式,将状态转移方程略作修改如下:
d
p
[
i
]
[
j
]
=
{
i
,
j
=
0
j
,
i
=
0
d
p
[
i
−
1
]
[
j
−
1
]
,
s
1
[
i
−
1
]
=
s
2
[
j
−
1
]
m
i
n
{
d
p
[
i
]
[
j
−
1
]
,
d
p
[
i
−
1
]
[
j
]
,
d
p
[
i
−
1
]
[
j
−
1
]
}
+
1
,
s
1
[
i
−
1
]
≠
s
2
[
j
−
1
]
dp[i][j]= {i,j=0j,i=0dp[i−1][j−1],s1[i−1]=s2[j−1]min{dp[i][j−1],dp[i−1][j],dp[i−1][j−1]}+1,s1[i−1]≠s2[j−1]
按照上述状态转移方程填写状态转移表,求解编辑距离的迭代递推实现代码如下:
int dp_iter(string word1, string word2)
{
int len1 = word1.length();
int len2 = word2.length();
// 创建状态转移表
int dp[len1 + 1][len2 + 1];
// 初始化状态转移表,也即其中一个字符串为空时的情况
for(int i = 0; i <= len1; ++i)
dp[i][0] = i;
for(int j = 0; j <= len2; ++j)
dp[0][j] = j;
// 按照状态转移方程从初始状态往后依次填表
for(int i = 1; i <= len1; ++i){
for(int j = 1; j <= len2; ++j){
if(word1[i-1] == word2[j-1]){
dp[i][j] = dp[i - 1][j - 1];
}else{
int ins = dp[i][j - 1] + 1;
int del = dp[i - 1][j] + 1;
int rep = dp[i - 1][j - 1] + 1;
dp[i][j] = min(rep, min(ins, del));
}
}
}
return dp[len1][len2];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
我们再次向leetcode 提交代码,测试结果如下:
Accepted
1146/1146 cases passed (4 ms)
Your runtime beats 99.74 % of cpp submissions
Your memory usage beats 95.26 % of cpp submissions (7 MB)
从递归解法和迭代递推解法的执行结果对比来看,迭代递推解法的实际执行效率更高。从填写状态转移表的代码也可以看出状态转移方程,可读性并没有降低太多,因此求解动态规划问题更常使用迭代递推解法(因整个过程主要是填写状态转移表,故也称为状态转移表法)。
有了高效求解两个字符串编辑距离的方法,当检测到用户输入的单词不存在时,就可以列举出与用户输入单词编辑距离最小的单词。通常与用户输入单词编辑距离最小的单词有多个,该按什么顺序排列呢?可以利用上下文信息以及键盘上字母间的距离等信息作为候选正确单词排序的依据。
编辑距离除了可以计算两个字符串之间的差异程度,还有哪些用途呢?两个字符串实际上是按照同一编码规则的两个序列,DNA 序列实际上是由A、G、C、T 四种碱基编码的序列,同样可以使用编辑距离来量化两个DNA 序列的差异程度,比如DNA 鉴定相似度多少就可以使用编辑距离来计算。
3.2 如何高效实现语音识别?
语音识别可以分为三步:第一步对声波进行信号处理,得到一些语音特征;第二步通过语音特征,识别出相应的音节;第三步是根据音节,合成出完整的语句。前两个阶段主要是信号处理、声学模型和语言模型匹配等,本文主要谈谈第三个阶段根据语音合成出完整的语句。为了简化问题,我们假设前两个阶段都完美识别。
语音识别中一个比较复杂的问题是一音多字,比如在汉语中平均一个读音可能对应十几个汉字,即便声调非常准确也平均对应六个汉字,这在语音识别上会带来指数级的计算复杂度。比如一个音对应6 个字,一个长度有20 个字组成的句子就能组合出620 种可能性,这个计算复杂度随音节个数增长的非常快,也即复杂度太高阶了,没办法处理大规模语音数据。如何大幅降低语音识别的复杂度,让其更实用呢?
语音实际上天然带有时间顺序,语音识别也是逐音节识别的,每个音节的识别可以看作一个阶段,每个音对应的多个单词或汉字就是每个阶段可供选择的状态分支,我们要找出最合理、最有可能的决策序列(也即音节合成出的完整语句),所以语音识别问题可以看作是一个多阶段决策最优解问题。
前面谈到语音识别因为一音多字问题导致指数级的复杂度,实际上使用的是回溯思想遍历了每一种可能的音节排列,多阶段决策最优解问题可以使用动态规划大幅降低求解复杂度。
在数字通信中,0 可能在传输中被误传输成了1,1 也可能被误传为0。在解码时,即便遇到1,也要考虑它有一个很小的可能性是0被传输错了产生的,这样一来,一个长度为n 的比特序列就会有2n 种可能,这类数字解码问题也可以看作是多阶段决策最优解问题。维特比为了解决这类通信传输中的纠错解码问题,发明了维特比算法,核心思想也正是动态规划,将指数级的时间复杂度降低为线性级时间复杂度(进制数为常数)。
语音识别问题实际上与通信传输中的数字解码问题很类似,一个句子由长度为n 的音节按时间顺序排列而成,每个音节对应k 种可能的字可以类比为k 进制比特流,假设k 为常数,语音识别问题使用维特比算法就可以将时间复杂度从O(kn) 降低到O(n),让语音识别真正实用并普及。除了通信解码和语音识别,还有机器翻译、基因测序等都用到了维特比算法,维特比也将这个算法做成芯片卖给其他通信公司,为他带来了丰厚的经济收益。
本文实现代码下载链接:https://github.com/StreamAI/ADT-and-Algorithm-in-C/tree/master/algorithm or https://github.com/StreamAI/Leetcode-CPP/tree/main/Dynamic_Programming
评论记录:
回复评论: