
当我们遇到某个需要解决的新问题时,如果没有明确的思路,有一个比较笨的着手点,就是穷举法,尝试遍历所有可能的解,然后选择我们需要的解。要实现无遗漏的完全穷举,也需要按照一定的规律遍历可能解的集合,我们应遵循怎样的规律来保证无遗漏的完全穷举所有可能的解呢?
一、穷举法与遍历规律
穷举所有可能的解比较抽象,穷举实际上就是遍历,我们考虑遍历一组数据中的所有元素更直观些。我们把一个数据结构中的尾结点或叶子结点看作一个问题的解,把该数据结构中的首结点或根结点看作一个问题的初始条件,把中间结点看作问题求解的中间状态或中间结果。穷举所有可能的解,实际上就是从初始条件也即首结点或根结点出发,遍历所有能达到尾结点或者叶子结点的路径,遍历所有路径自然也遍历了所有元素。
对于线性表结构,不管是数组还是链表,一般都是从头开始顺序遍历所有元素,从首结点到尾结点的路径只有一条,比如求n 的阶乘问题。对于更复杂的树结构,遍历方法就不止一种了。以简单的二叉树为例,前序、中序、后序遍历比较类似,都是先从根结点一直找到左叶子结点,然后回退一步往右找其它的叶子结点;层序遍历跟前者不一样,都是先从上往下从左往右逐层遍历,最后才遍历到叶子结点,两种遍历方法如下图示:
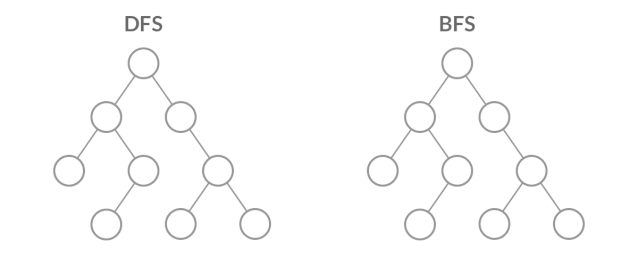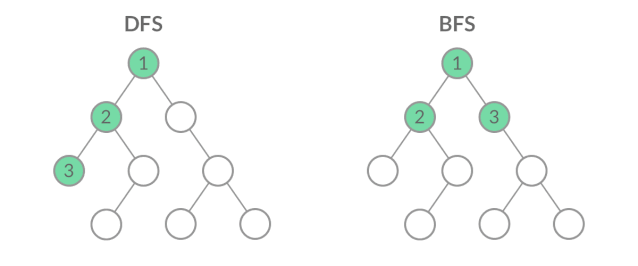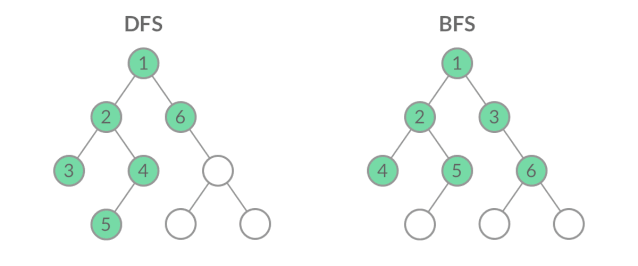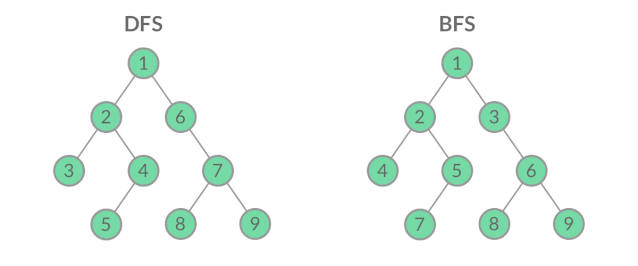
假如把根结点看作初始条件,叶子结点看作该问题的所有可能的解。上图左边的二叉树遍历方式优先从根结点选择一条路径遍历到左叶子结点,也即先找到一个可能的解,然后回退找其它可能的解,直到最后穷举出所有可能的解。上图右边的二叉树遍历方式优先从根结点遍历到所有可能的下一个中间状态,直到最后才遍历到所有可能的解。前者优先增加深度,先找到一个可能的解,因此也叫深度优先搜索DFS(Deep First Search);后者优先扩展广度,不放过任何一种求解路径,最后才推进到可能的解,因此也叫广度优先搜索BFS(Breath First Search)。
DFS与BFS 都可以穷举所有可能的解,但二者的侧重点有何不同呢?
- DFS(Deep First Search):不管刚开始有几种可能的求解路径,先选择一条路径获得一个可能的解,如果只是要找某问题的其中一个可能解,很显然DFS 更高效。
- BFS(Breath First Search):先不着急求解,重点看有几种可能的求解路径,然后分别沿所有可能路径往可能解的方向推进,逐阶段逐过程一步步推进,很显然路径最短或步骤最少的解会最先被找到,如果只是找步骤最少的解,则BFS 更高效。
如果要穷举所有可能的解,DFS 与BFS 都需要遍历所有结点,二者效率有区别吗?DFS 在找到某个解后,在原求解路径上回退然后搜索其它可能的解,回退的中间结果因为解已经求出而不再需要保存了,也即当前只需要保存已经找到的解和当前求解路径上的中间结果。BFS 是最后才找到可能解的,整个遍历过程不回退,在找到可能解之前需要保留所有的中间结果,因此占用的存储资源比DFS 更大。因此,如果要穷举所有可能的解,DFS 需要保存的中间结果更少,更节省存储资源。
本文的关注点是如何高效穷举所有可能的解,所以主要介绍DFS 深度优先遍历方式。我们把根结点看作初始状态,叶子结点看作结束状态,中间结点看作求解的中间状态,从初始状态到可能解的结束状态加上从初始状态递推到结束状态途径的中间状态,共同构成了一个求解路径。每个求解路径都是从初始状态开始,按照求解的递推公式逐层接近可能解的结束状态,因此比较适合使用递归调用来求解(当然也可以使用栈模拟递归,或者将其改为迭代形式,不过递归更直观易读)。比如二叉树和多叉树的遍历函数:
// 二叉树的遍历
void binaryTraverse(pTreeNode T)
{
// 递归遍历的结束条件,若T->LeftChild 为空说明结点 T 向左遍历到达终点,开始往右遍历;若T->RightChild 为空说明结点 T 向右遍历到达终点,返回上一个结点继续往右遍历
if (T == NULL)
return;
// 前序遍历在此处输出当前结点 T
binaryTraverse(T->LeftChild);
// 中序遍历在此处输出当前结点 T
binaryTraverse(T->RightChild);
// 后序遍历在此处输出当前结点 T
}
// 多叉树的遍历
void treeTraverse(pTreeNode T)
{
// 递归遍历的结束条件,若结点T 为空,则其父结点在该方向上到达终点,继续往右遍历或者返回上一个结点后往右遍历
if (T == NULL)
return;
// 每个结点逐个遍历其所有子节点
for(pTreeNode pChild : T->child) {
// 前序遍历在此处输出当前结点 T
treeTraverse(pChild);
// 后序遍历在此处输出当前结点 T
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
树结构的遍历是按照特定规律遍历完所有的结点,并非每个叶子结点都是一个可能的解,而是完全遍历后才是唯一解,但我们可以借鉴树结构的深度优先遍历规律来穷举所有可能的解。我们把多叉树的每个结点看作一个状态,每个结点的多个子结点看作一个选择,使用一个参数来保存当前从初始状态到结束状态的可能解路径,到达叶子结点时判断可能解路径是否满足要求,若满足要求就保存到可能解的集合中,若不满足要求则回退到上一个状态(也即该叶子结点的父结点)继续往右遍历其它可能解路径,伪代码如下:
// DFS 遍历所有可能的解
void backTracking(vector<typename>& slects, vector<typename>& path, vector<vector<typename>>& results)
{
// 递归遍历的结束条件,若满足结束条件则将可能的解放入解的集合,返回到上一个状态继续往右遍历
if (isValid(path) == true) {
results.push_back(path);
return;
}
// 每个结点状态逐个遍历可能的选择分支
for(typename option : slects) {
// 跳过一些不符合要求的选择分支,以提高效率(也即回溯剪枝中的剪枝思想)
if(isChoise(option) == false) continue;
// 将当前选择的结点 option 添加到当前求解路径 path 中
path.push_back(option);
// 按照求解的递推公式,沿着求解路径向可能解的状态靠近
backTracking(slects, path, results);
// 将当前选择的结点 option 从当前求解路径 path 中移除,继续尝试新的选择分支
path.pop_back();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这种从初始条件按照递推公式沿选择路径遍历到可能解的过程跟树结构深度优先遍历过程很类似,都是优先沿着可选分支靠左的路径往下推进到结束状态。由于沿当前求解路径推进到结束状态后,需要回退到上一个选择结点,以便选择其它的分支,同时要将末端的结点从求解路径中移除。整个求解过程都是按照树结构的DFS 遍历路径进行选择、回退和判断,因此这种求解方法也被称为回溯思想,强调了选择递推之后的回退撤销过程。
在选择后续分支路径时,有些分支明显不符合求解要求,可以提前跳过这些选择分支,相当于在树结构的剪去一些枝杈,因此也被称为剪枝过程,剪枝可以提高程序的执行效率,跟前面的回溯思想结合起来,就是回溯剪枝算法。
回溯思想与前面介绍的分治思想在解决问题时的思路有很大区别,二者的不同主要如下:
- 分治思想:在空间上将大规模问题分割为多个相互独立且结构相似的小规模子问题,这类问题规模小到一定程度可以直接求解,再将多个子问题的解合并为原问题的解。由此可见,分治算法很适合用来处理大规模问题,通过缩小规模大幅降低计算复杂度,因为分割出的子问题相互独立,也很适合使用并行计算,比如MapReduce;
- 回溯思想:在时序上将原问题拆解为前后相继的多选择分支多阶段子问题(最后阶段也有多个可行解),从初始状态按照DFS 规律向最后阶段的可行解状态逐阶段求解,到达一个可行解状态再回退到上一阶段继续沿其它的求解分支获得其它可行解,满足约束条件的所有可行解集合构成一个解空间,比如排列组合问题就很适合使用回溯思想解决。
二、排列问题
从 n 个不同的元素中取出 m(1 ≤ m ≤ n)个不同的元素,按照一定的顺序排成一列,这个过程就叫排列(Permutation),当 m=n 时称为全排列(All Permutation)。如果选择出的这 m 个元素可以有重复的,这样的排列是为重复排列(Permutation with Repetition),否则就是不重复排列(Permutation without Repetition)。
2.1 全排列问题
从n 个不同的元素中取出m 个不同的元素构成的不重复排列个数为 A n m = n ! ( n − m ) ! A_n^m = \frac{n!}{(n-m)!} Anm=(n−m)!n!,n 个元素构成的不重复全排列个数为 A n n = n ! A_n^n = n! Ann=n! 个。我们怎么获得这些排列呢?
容易想到的一个思路是,n 个元素设置n 个格子,从第一个格子开始往后逐个放置元素,当n 个格子都放进元素后就构成一个排列。往格子里放元素的过程是分阶段的,每个阶段放哪个元素也是有多个选择的,这个过程比较符合前面介绍的多叉树DFS 遍历,可以使用n 层的多叉树来表示往格子里放元素构成排列的过程。
举个简单的例子,数字序列{1, 2, 3} 的全排列可以使用四层多叉树表示,根结点初始状态格子无元素,第一个格子放哪个元素有三个选择分支,第一阶段就有三种放置一个元素的状态,第二个格子放哪个元素剩下两个选择分支,第二阶段分别有两种放置两个元素的状态,最后一个格子只剩一个选择分支,最后阶段就得到了所有的全排列。这个过程可以表示成下图所示的多叉树(按照多叉树DFS 回溯遍历规律就可以找到所有的排列):
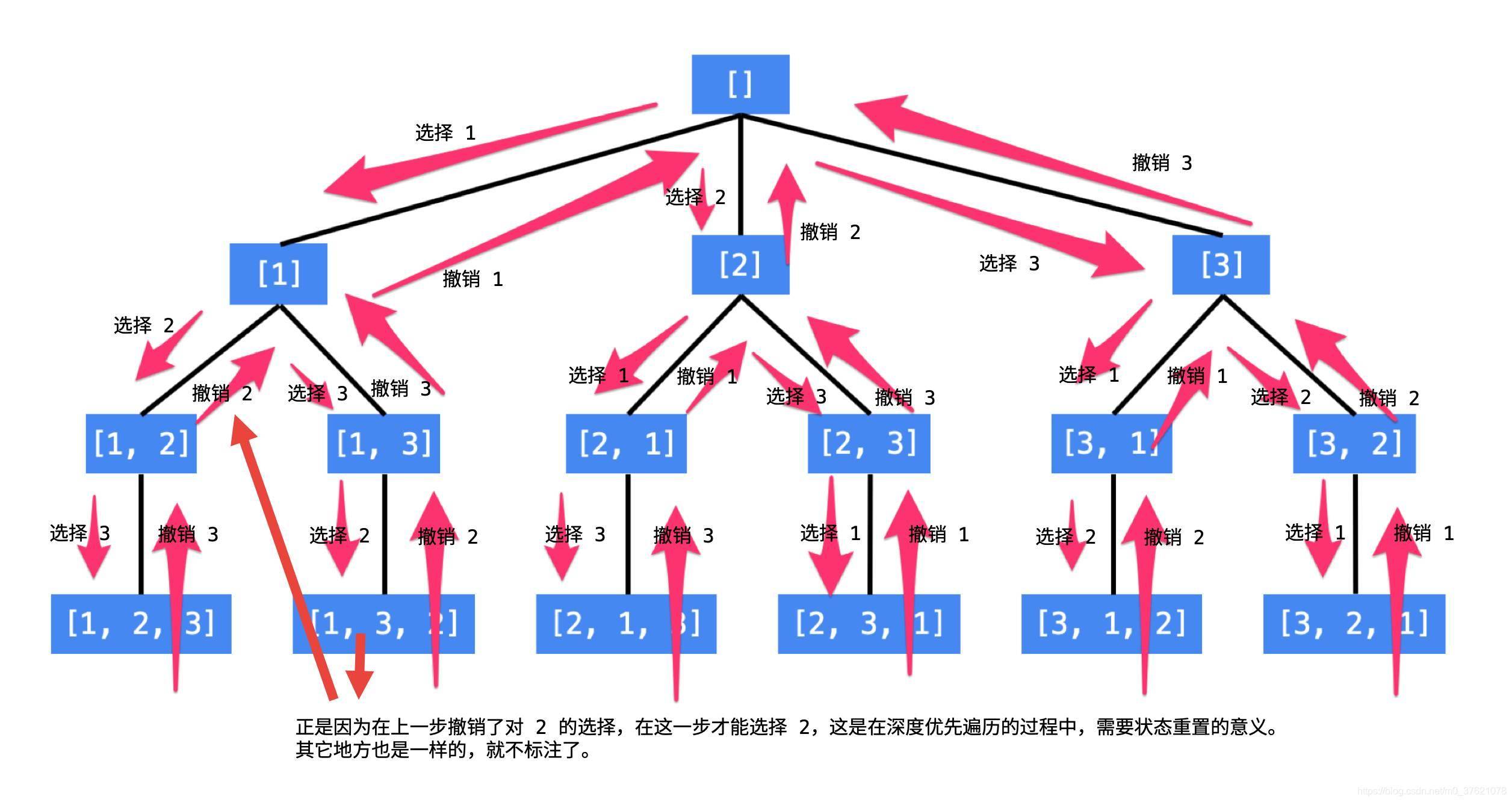
这个多叉树跟决策树比较像,求解排列问题的重点是分支选择(也即做决策),决策树的每一层即为一个阶段,每个阶段选择一个元素,当选择够m 个元素即构成一个排列,回溯到上一层继续选择其它分支,直到DFS 遍历完整个决策树就获得了所有排列构成的解空间。要获得一个排列,我们需要记录当前选择路径上已经选择的元素,往上层回溯时需要删除不在当前选择路径上的元素,还有一个重点是不能选择前面已经选择过的元素,我们可以使用一个变量标记已选择过的元素,后面只能选择未被标记过的元素,当然回溯时需要取消标记。
我们从leetcode 上选择一道题,看看全排列问题如何使用回溯算法解决:
[Leetcode - 46] 全排列:给定一个 没有重复 数字的序列,返回其所有可能的全排列。
按照前面介绍的回溯算法伪代码,实现无重复数字序列全排列的函数代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
这道题中的数字序列换成字符序列也是一样的解法,只改变元素类型就可以了。另一个限制条件是无重复元素序列的全排列,假如该序列包含重复元素会怎样呢?
[Leetcode - 47] 全排列 II:给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
我们很容易想到假如两个元素重复,这俩元素互换位置后的另一个排列与原排列相同,也即获得的全排列中有重复的排列。知道原因就很容易想到解决方案,一种简单的方案是最后将全排列的解空间进行去重处理,另一种是发现重复的排列提前进行剪枝处理,后一种方法需要先对元素序列排序,排序后相同元素就在一起了。举个简单的例子,数字序列{1,1,2} 包含重复元素1,全排列决策树如下(蓝色部分为选择路径path,绿色部分为访问标记数组used):
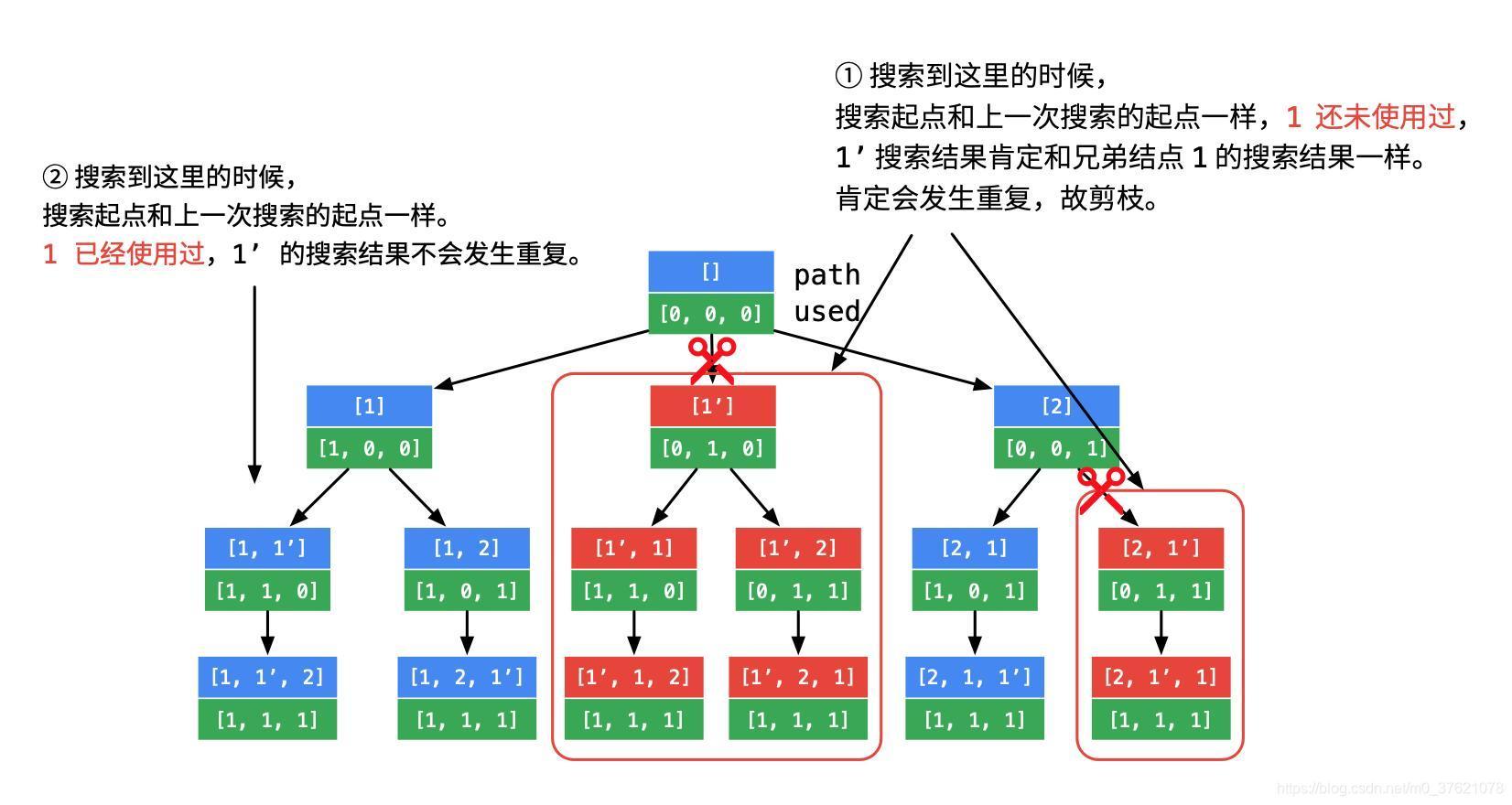
从上图可以看出,要正确剪除重复排列的分支,只判断当前选择与前一个选择元素相同(也即nums[i] == nums[i-1])是不够的,还需要同时确定前一个选择元素处于未被标记状态(也即 visited[i-1] == false)。根据上述思路,编写求解包含重复元素数字序列的不重复全排列代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
N 个元素全排列算法的时间复杂度是多少呢?不考虑剪枝的情况下,for 循环内的递归函数共调用 n 次,每次递归调用都会执行n 次元素选择与撤销操作(每次选择path新增一个元素,当path元素达到n 个时返回),所以最坏时间复杂度为O(nn)。考虑剪枝的情况不太好直接分析,我们换个角度从数学上分析全排列的时间复杂度,n 个元素共n 个格子,第一个格子内放置哪个元素有n 种选择,第二个格子有n-1 种选择,依此类推,最后一个格子只剩一种选择,n 个元素全排列的最好时间复杂度为O(n!),如果算上每个排列拷贝到解空间中的时间O(n),总的时间复杂度就是O(n*n!)。
N 个元素全排列的空间复杂度是多少呢?存储当前路径和标记已选择元素的空间复杂度均为O(n),如果不考虑保存所有全排列集合占用的存储空间,其空间复杂度为O(n)。如果考虑存储所有全排列集合占用的存储空间,其空间复杂度为O(n*n!)(一共有 A n n A_n^n Ann = n! 个排列,每个排列有n 个元素)。由此可见,全排列算法的时间复杂度和空间复杂度都挺高阶的,不适合用来处理大规模数据。
2.2 N 皇后问题
N 皇后问题中比较知名的是八皇后问题,是19世纪的一位国际象棋棋手贝瑟尔提出的一道智力题,讲的是在8×8格的国际象棋上摆放8个皇后,使其不会互相攻击(也即任意两个皇后都不能处于同一行、同一列或同一斜线上),问有多少种摆法,怎么摆?
在国际象棋中,皇后可以吃掉同一行、同一列和同一斜线上的棋子。因此,任意两个皇后都不能处于同一行、同一列或同一斜线上。下图分别给出一种正确的摆法(左图)和错误的摆法(右图)作为示例:
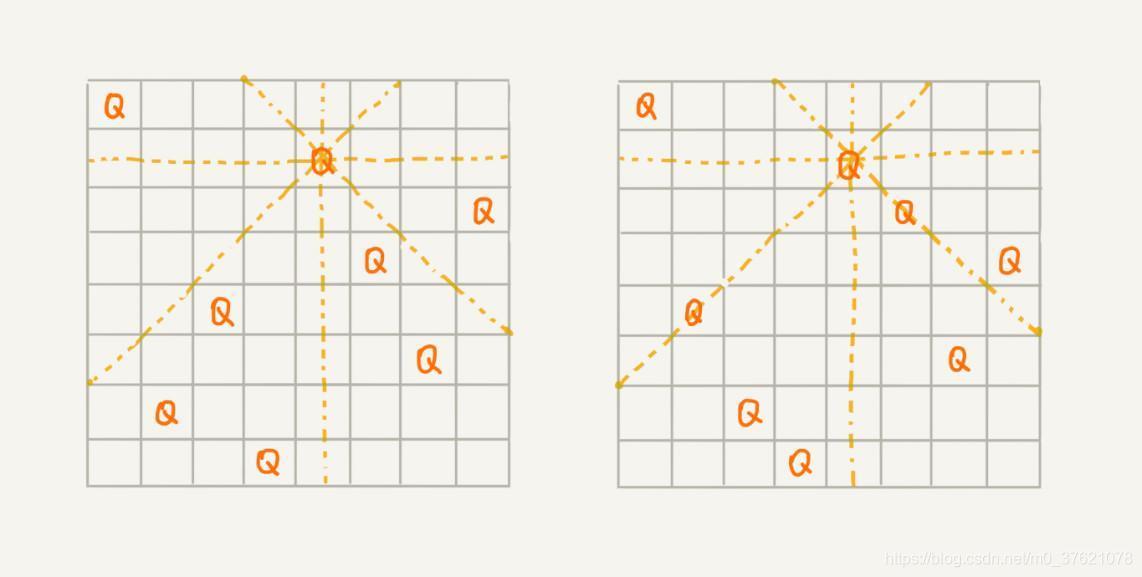
在没有计算机之前,要找到所有可能的摆法是很难的,读者有兴趣可以尝试下。大数学家高斯穷其一生只找到了76 种摆法,今天用计算机只需要几毫秒就可以找到全部92 种摆法。我们如何找到正确的摆法呢?
我们以比较简单的四皇后问题为例,要获得一个正确的摆法,一般会先在第一行摆一个棋子,一共有四列所以第一行有四个选择分支,第二行剪除掉皇后会相互攻击的摆法,分别只剩下一到两种选择分支,第三行剪除掉会相互攻击的摆法,分别只剩下一种选择分支,最后一行剪除掉会相互攻击的摆法,剩下的都是正确的摆法。这个过程可以表示成下图所示的四层多叉树(按照多叉树DFS 回溯遍历规律就可以找到所有的摆法):
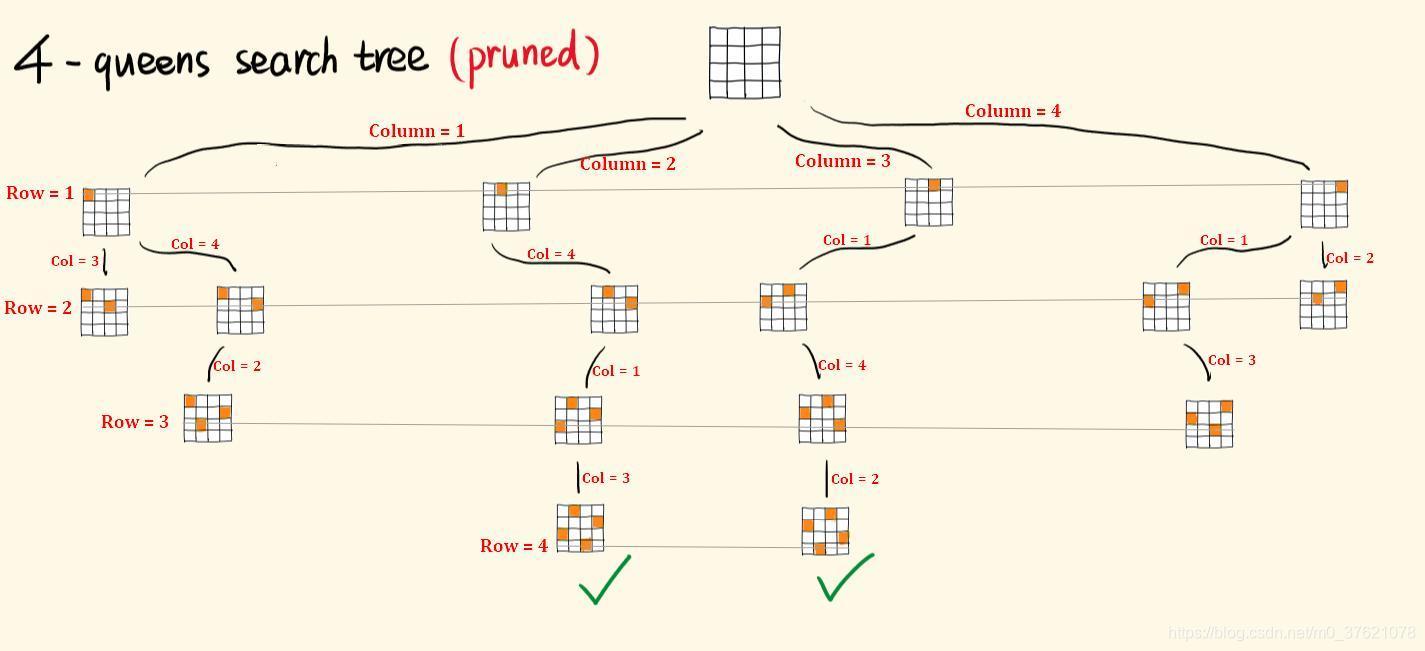
上面这个四层多叉树也算是决策树,求解N 皇后问题摆法的重点也是分支选择,棋盘上每一行即为一个阶段,每个阶段从N 行中选择一个位置摆放皇后,当N 行都摆放上皇后时即可获得一种摆法。N 皇后问题与全排列问题不同的是,全排列问题是往一个一维数组中填入元素,每个排列即为一个一维数组,N 皇后问题是往一个二维数组中放置皇后,每种摆法即为一个二维数组。
N 皇后问题的难点是判断某位置摆放皇后是否会跟之前已经摆放的皇后相互攻击,保证该位置与先前已摆放皇后位置不在同一行、不在同一列、不在同一斜线上。全排列问题向上一阶段回溯时,将一维数组当前格子里的元素移除,然后更换另一个可选元素放入当前格子中;N 皇后问题向上一阶段回溯时,将二维数组当前行里的皇后移除,然后更换另一列不会使皇后互相攻击的位置放置皇后,逻辑上是类似的。
[Leetcode - 51] N 皇后问题: 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击(任何两个皇后都不能处于同一条横行、纵列或斜线上)。
给你一个整数 n(1 <= n <= 9),返回所有不同的 n 皇后问题 的解决方案。每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
按照上面的分析逻辑,编写N 皇后所有正确摆法的实现代码如下:
#include,n+1 为第几种摆法
for(int n = 0; n < results.size(); ++n){
cout << n + 1 << ":" << endl;
for(const auto& str : results[n])
cout << str << endl;
cout << endl;
}
}
int main(void)
{
int n = 8;
vector<vector<string>> results;
vector<string> board(n, string(n, '.'));
backTracking(board, 0, results);
printQueue(results);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
N 皇后问题的时间复杂度是多少呢?分析方法跟全排列问题一样,不考虑剪枝的情况下,最坏时间复杂度为O(nn),考虑剪枝的情况会不会降低时间复杂度呢?理论上,全排列问题往一维数组放置元素的选择个数依次为n、n-1、…、1,N 皇后问题往二维数组每行放置皇后的选择个数也为n、n-1、…、1,所以时间复杂度也为O(n!)。但N 皇后问题在剪枝过程中判断(row, col) 位置是否满足要求的时间复杂度也为O(n)(如果能降低函数isValid 的时间复杂度则会提高整个算法效率),所以剪枝并没有明显降低时间复杂度,N 皇后问题的时间复杂度依然为O(nn)。
N 皇后问题的空间复杂度是多少呢?分析方法也可以类比全排列问题,不考虑存储所有正确摆法的空间,只剩下存储当前摆放皇后位置的二维棋盘,其空间复杂度为O(n2),若考虑存储所有正确摆法的空间,假设正确的摆法m = f(n),则其空间复杂度为O(m*n2)。N 皇后问题的时间复杂度和空间复杂度也是挺高阶的,也难怪高斯穷其一生都都没有找到八皇后问题的全部摆法。
三、组合问题
组合可以说是排列的兄弟,二者的主要区别是,组合不考虑每个元素出现的顺序。从定义上来说,组合是从n 个不同元素中取出 m(1 ≤ m ≤ n)个不同的元素。对于所有 m 取值的组合之全集合,我们可以叫作全组合(All Combination),例如对于集合{1, 2, 3}而言,全组合就是{空集, {1}, {2}, {3}, {1, 2}, {1,3} {2, 3}, {1, 2, 3}}。
3.1 N选k 组合问题
从n 个不同元素中取出m(1 ≤ m ≤ n)个不同元素的组合数量为 C n m = n ! m ! ( n − m ) ! C_n^m = \frac{n!}{m!(n-m)!} Cnm=m!(n−m)!n!,n 个元素构成的全组合数量为 C n 0 + C n 1 + … + C n n = 2 n C_n^0+C_n^1+\ldots +C_n^n = 2^n Cn0+Cn1+…+Cnn=2n。我们怎么获得这些组合呢?
从n 个不同元素中取出m 个不同元素构成的组合,实际上就是使用n 个不同元素填充一个长度为m 的一维数组。往数组中填充元素的过程是分阶段的,每个阶段放置哪个元素也是有多个选择的,这个过程也比较符合前面介绍的多叉树DFS 遍历,也可以用n 层的多叉树来表示往格子里放元素构成组合的过程。但组合与排列不同,不需要考虑每个元素出现的顺序,表示组合的多叉树与表示排列的多叉树有何不同呢?
举个简单的例子,从数字序列{1, 2, 3, 4} 中选出两个数字的组合可以使用三层多叉树表示,根结点初始状态格子无元素,第一个格子放哪个元素有四个选择分支,第一阶段就有四种放置一个元素的状态,第二个格子放哪个元素分别有几个选择分支呢?对于排列而言,第二个格子可以选择除前一阶段选择元素外的剩余三个元素,但这会带来重复的组合,怎么去除重复组合也即顺序颠倒的分支呢?
重复组合的原因是,选择1 的分支后续会选择2,选择2 的分支也会回头选择1。我们可以想到避免这种情况的方法,让选择2 的分支只能向后选择3 或4,而不能向前再选择1,也即每个阶段可以选择的分支只能是上一阶段所选元素后面的那些元素。上例第二个格子可以选择的分支数量跟第一个格子选择的元素直接相关,第一个格子选择的元素在数字序列中越靠前,第二个格子的选择分支越多,反之越少。这个过程可以表示成下图所示的多叉树(按照多叉树DFS 回溯遍历规律就可以找到所有满足条件的组合):
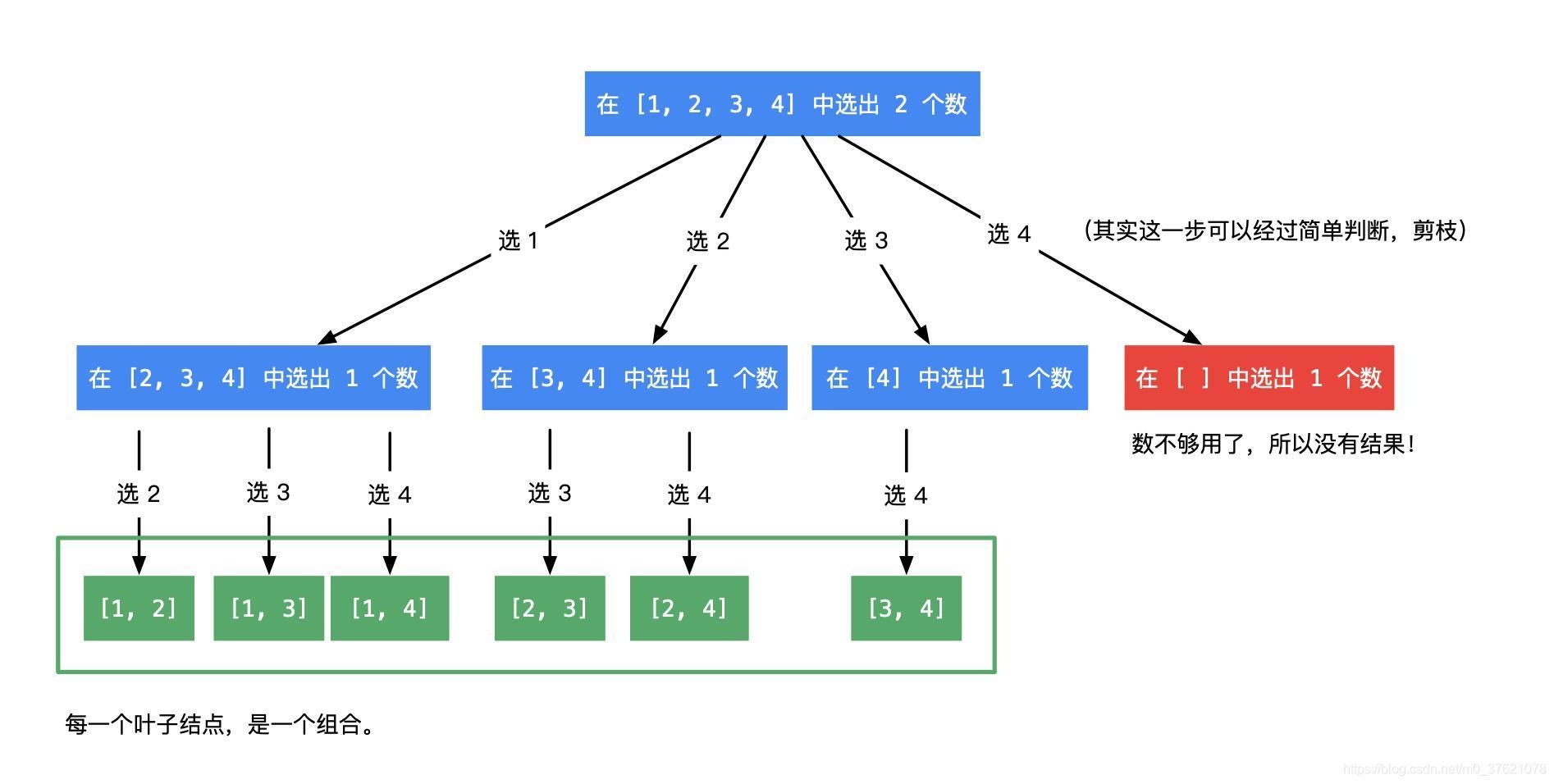
求解组合问题的重点也是分支选择, 与排列不同的是,每个阶段只能选择前一阶段已选元素后面的元素,也即只向后选择。回溯过程跟排列一样,当选择够m 个元素即构成一个组合,回溯到上一层继续选择其它分支,直到DFS 遍历完整个组合决策树就获得了所有满足要求的组合。
我们从leetcode 上选择一道题,看看组合问题如何使用回溯算法解决:
[Leetcode-77] 组合: 给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
按照前面介绍的回溯算法伪代码,获得数字序列组合的函数代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
从n 个不同元素中取出k 个元素构成组合的时间复杂度是多少呢?递归代码不太好直接分析,我们从组合的数学定义上分析,从n个不同元素中取出k 个元素构成的组合数量为 C n k = n ! k ! ( n − k ) ! C_n^k = \frac{n!}{k!(n-k)!} Cnk=k!(n−k)!n!,因此上述算法的时间复杂度为O( C n k C_n^k Cnk),如果考虑将每个组合拷贝到解空间的时间,则总的时间复杂度为O( k ∗ C n k k*C_n^k k∗Cnk)。 C n k C_n^k Cnk算法的空间复杂度也比较好分析,保存当前组合路径的空间复杂度为O(k),保存全部组合解数组的空间复杂度为O( k ∗ C n k k*C_n^k k∗Cnk),组合算法的时间和空间复杂度比排列算法更低阶些。
3.2 全组合问题(子集问题)
假如我想获得n 个不同元素的全组合,该如何求解呢?从前面求解
C
n
k
C_n^k
Cnk的组合数可知,组合的元素个数k 对应组合决策树中的第几阶段或第几层,上例中k = 2 也即只筛选出两个元素构成的组合,也即组合决策树第三层的所有元素。N 个不同元素的全组合数量为
C
n
0
+
C
n
1
+
…
+
C
n
n
=
2
n
C_n^0+C_n^1+\ldots +C_n^n = 2^n
Cn0+Cn1+…+Cnn=2n,也即遍历整个组合决策树的所有元素。举个简单的例子,数字序列{1,2,3} 的全组合就是其组合决策树从根结点到叶子结点的所有元素,如下图所示:
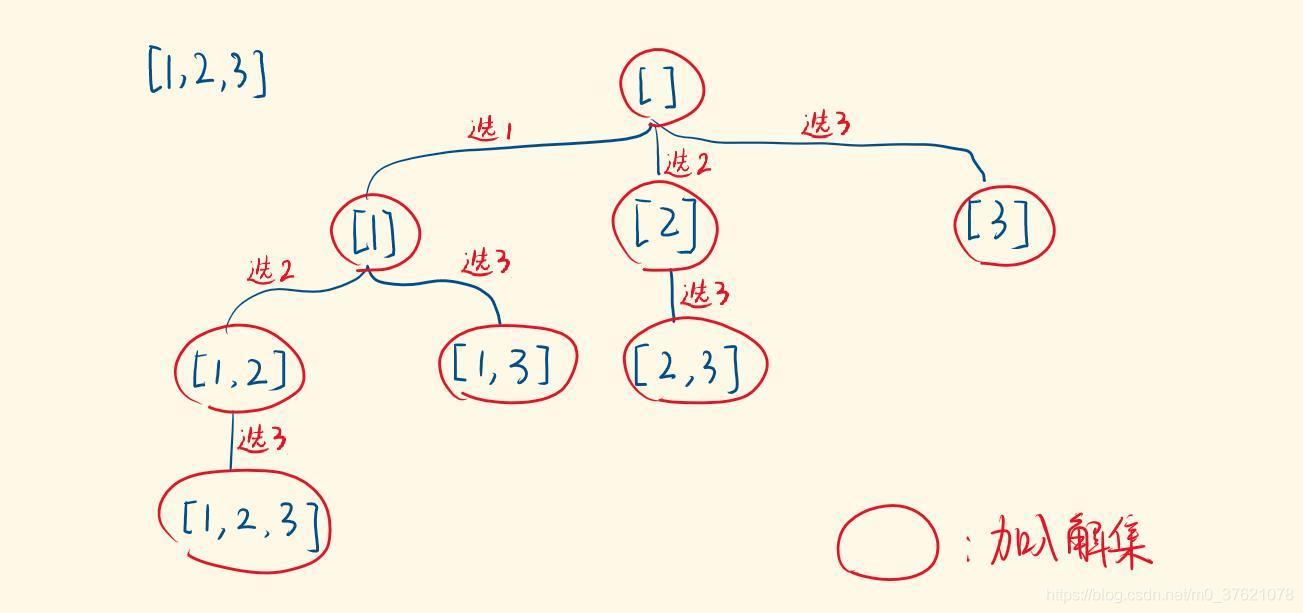
从leetcode 上选择一道题,看看全组合问题(子集问题)如何使用回溯算法解决:
[Leetcode-78] 子集:给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(解集不能包含重复的子集)。
按照上面对全组合的分析,只需要略微修改下 C n k C_n^k Cnk组合问题的代码即可:
void backTracking(vector<int>& nums, int index, vector<vector<int>>& results)
{
static vector<int> path;
// 递归遍历所有结点,并将每个结点构成的组合放入解空间
results.push_back(path);
// 每个结点状态逐个遍历可能的选择分支,变量 i 初始值为index,且在每次递归增加 1,保证只选择后续分支
for(int i = index; i < nums.size(); ++i){
path.push_back(nums[i]);
backTracking(nums, i + 1, results);
path.pop_back();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这道题中的数字序列换成字符序列也是一样的解法,只改变元素类型就可以了。另一个限制条件是无重复元素序列的全组合,假如该序列包含重复元素会怎样呢?
[Leetcode-90] 子集 II:给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(解集不能包含重复的子集)。
重复组合的去重比排列更简单些,不涉及访问标记数组,但一样要先对数字序列进行排序处理,以便让重复元素相互邻接。举个例子,数字序列{1,2,2} 的组合决策树,要正确剪除重复组合的分支,只判断当前选择与前一个选择元素相同(也即nums[i] == nums[i-1])是不够的,还需要确定当前选择元素不是该阶段的第一个选择分支(也即 i > index)。根据上述思路,编写求解包含重复元素数字序列的不重复全组合代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
n 个元素全组合算法的时间复杂度是多少呢?我们依然从全组合的数学定义分析,n 个不同元素构成的全组合数量为 C n 0 + C n 1 + … + C n n = 2 n C_n^0+C_n^1+\ldots +C_n^n = 2^n Cn0+Cn1+…+Cnn=2n,所以该算法的时间复杂度为O(2n),如果考虑将当前组合拷贝到解空间的平均时间O(n/2),则其总的时间复杂度为O(n*2n)。该算法的空间复杂度分析也类似,保存当前组合的平均空间复杂度为O(n),保存全组合解空间的空间复杂度为O(n * 2n),全组合算法的时间和空间复杂度也挺高阶的。
我们看到n 个不同元素的全组合数量2n 会想到什么呢?全组合跟计算机布尔代数 0-1 有怎样的关系呢?N 个布尔代数 0-1 可表示的种类数也是2n ,布尔代数0-1 通常用来表示真假,放到组合问题上,可以用来表示选择或不选择某个元素,就跟排列问题中的访问标记变量类似,我们是不是可以依次选择或不选择这n 个不同元素来表示全组合决策树呢?二者的全组合数量是一致的,使用前面介绍的多叉树和这里谈的0-1 二叉树表示同一个数字序列的全组合应该是等价的。依然使用数字序列{1,2,3} 举例,依次选择和不选择该数字序列中的某个元素,构成的二叉决策树如下:
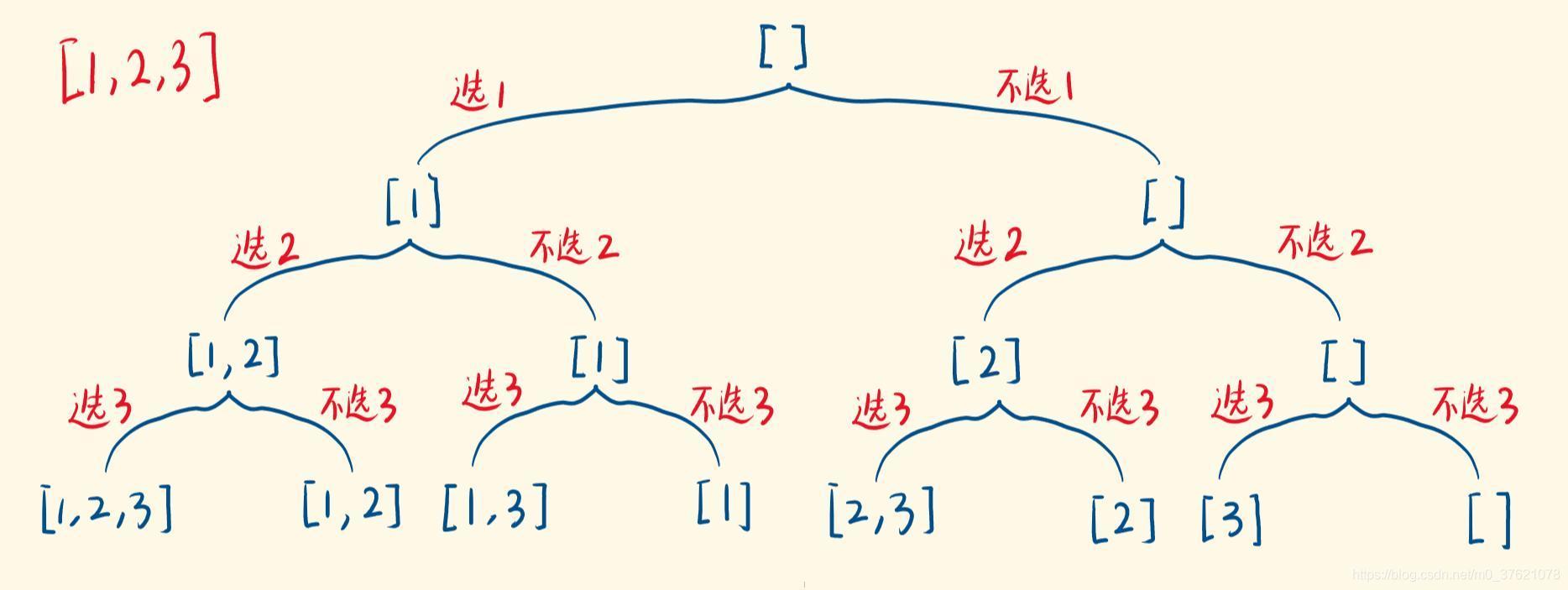
使用0-1(选择-不选择)数字序列中的某元素构成的二叉决策树跟前面介绍的多叉决策树是等价的,不同之处在于,前面介绍的多叉决策树所有结点都是全组合之一,这里的二叉决策树只有叶子结点是全组合成员。考虑到二叉树比多叉树更简单直观,且所有的解都在叶子结点(跟前面介绍的排列问题一致),后续我们使用这种二叉决策树来处理全组合问题。
使用二叉决策树解决Leetcode-78 子集问题的代码如下:
void backTracking(vector<int>& nums, int index, vector<vector<int>>& results)
{
// 使用static 变量只在第一次定义并初始化,后续递归调用不会再重新定义或初始化,用于记录选择路径
static vector<int> path;
// 递归遍历的结束条件,若递归到叶子结点则将该组合放入解空间并返回
if(index == nums.size()){
results.push_back(path);
return;
}
// 选择当前元素nums[index]
path.push_back(nums[index]);
backTracking(nums, index + 1, results);
path.pop_back();
// 不选择当前元素nums[index]
backTracking(nums, index + 1, results);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
使用二叉决策树可以解决Leetcode-90 子集 II 问题吗?解决该问题的关键是剪除重复的组合分支,由于二叉决策树的有效组合都在叶子结点,跟前面介绍的排列类似,可以借鉴排列问题解决重复元素的方案,使用二叉决策树解决子集 II 问题的代码如下:
void backTracking(vector<int>& nums, int index, vector<vector<int>>& results)
{
// 使用static 变量只在第一次定义并初始化,后续递归调用不会再重新定义或初始化,用于记录选择路径
static vector<int> path;
static vector<bool> visited(nums.size(), false);
// 递归遍历的结束条件,若递归到叶子结点则将该组合放入解空间并返回
if(index == nums.size()){
results.push_back(path);
return;
}
// 选择当前元素nums[index],剪除重复组合的选择分支,注意括号里面的条件取反(前面的逻辑非!)
if(!(index > 0 && nums[index] == nums[index - 1] && visited[index-1] == false)){
path.push_back(nums[index]);
visited[index] = true;
backTracking(nums, index + 1, results);
path.pop_back();
visited[index] = false;
}
// 不选择当前元素nums[index]
backTracking(nums, index + 1, results);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.3 组合总和问题
组合问题中,求解 C n k C_n^k Cnk的所有组合貌似应用场景没那么多,不像排列问题可以应用于暴力破解密码、解数独、正则表达式匹配等场景。实际上,组合问题中有一类比较常用,那就是组合总和问题。组合总和问题实际上就是求解所有元素总和满足某个约束条件的组合,实际上就是在全组合中筛选出组合元素总和满足给定约束条件(比如组合中元素相加值等于目标值的组合)的组合。 C n k C_n^k Cnk组合问题是从全组合中筛选元素个数为k 的组合,组合总和问题是从全组合中筛选出元素总和为target 的组合。从leetcode 上选择一道题,看看组合总和问题如何使用回溯算法解决:
[Leetcode - 39] 组合总和:给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。candidates 中的数字可以无限制重复被选取,所有数字(包括 target)都是正整数,解集不能包含重复的组合。
了解了全组合问题的求解,再看这道题也就不难了。一个容易想到的思路是先找到无重复元素数组 candidates 的全组合,然后从全组合中找出数字和为target 的组合。既然是采用递归回溯方法,我们也从目标出发反向思考,假如选择元素candidates[index],目标组合中剩余元素目标和更新为target - candidates[index],直到目标和target 正好减到0 即获得一组满足要求的组合。按照这个思路,编写求解无重复数字序列组合总和问题的代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
上面这个组合总和问题给定的数字序列是无重复元素的,且每个元素可以无限制重复使用,这类问题在现实中也有不少应用,比如钱币找零问题就可以转换为组合总和问题,假设要找零target 为99,可用零钱币值为{1,2,5,10},每张币值不限制使用次数,可以使用这个组合总和问题找到所有满足条件的找零方案,如果想要找到零钱数最少的方案,只需要在所有找零方案中遍历找到元素个数最少的组合即可。
现实中还有一类组合总和问题,给定的数字序列可能包含重复元素,但每个元素只能使用一次,比如0-1 背包问题,待装入背包的物品有限,选择将哪些物品装入背包正好将背包装满,这里的目标总和为背包容量target,数字序列为每个物品的体积。由于数学问题更具有普适性,不同的现实问题可以转换为相同的数学问题,这里依然使用一道数学问题展示这类组合问题的解法。
[Leetcode - 40] 组合总和 II :给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。candidates 中的每个数字在每个组合中只能使用一次,所有数字(包括目标数)都是正整数,解集不能包含重复的组合。
数字序列candidate 中每个元素只能使用一次比较好处理,只需要将第一种组合总和问题中若选择元素candidates[index] 将索引index 加一即可。由于数字序列中可能有重复的元素,怎么去除重复的组合呢?参照Leetcode-90 子集 II 问题中剪除重复组合的方案,编写求解可能包含重复元素数字序列的组合总和问题的代码如下:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
组合总和问题的时间复杂度是怎样的呢?从算法思路就可以知道,组合总和问题也是要遍历全组合的,所以时间复杂度跟前面介绍的子集问题一样,也是O(2n),如果考虑将当前组合拷贝到解空间的时间,假设满足总和条件的组合数为k(每个组合平均长度为n/2),则总的时间复杂度为O(2n + k*n)。
组合总和问题的空间复杂度是多少呢?该问题的分析也跟全组合类似,只考虑保存当前组合及其元素标记的变量,空间复杂度为O(n),如果要考虑保存全部满足条件的组合,假设满足总和条件的组合数为k(每个组合平均长度为n/2),则总的时间复杂度为O(k*n),其中k 的值跟全组合数量2n 和目标和target 有关。
四、回溯算法应用示例
4.1 如何实现拼写提示功能?
我们在编辑文档、写代码、搜索关键词时,编辑工具通常会基于我们输入的字母前缀列举出可能的完整单词,这些工具是如何实现单词拼写提示功能的呢?
单词拼写提示功能主要就是根据用户已经输入的前缀查字典,把前缀匹配的单词按某种规则(比如使用频率)列举出来即可。所以,原问题就转换为如何基于前缀实现高效查字典的功能?
基于前缀查字典实际上分为两步:第一是前缀逐字符匹配;第二是列举所有与前缀匹配的单词。基于前缀逐字母匹配可以看作是一个多阶段匹配问题,我们可以尝试使用多叉树来存储字典集合,这就是字典树或者Trie 树,由于查询Trie 树是基于前缀匹配的,因此也称为前缀树。Trie 树的根结点不存储字符,构造Trie 树时将每个单词插入到多叉树中,尽可能使用更多的公共前缀,查询Trie 树时从根结点逐层匹配前缀字符。
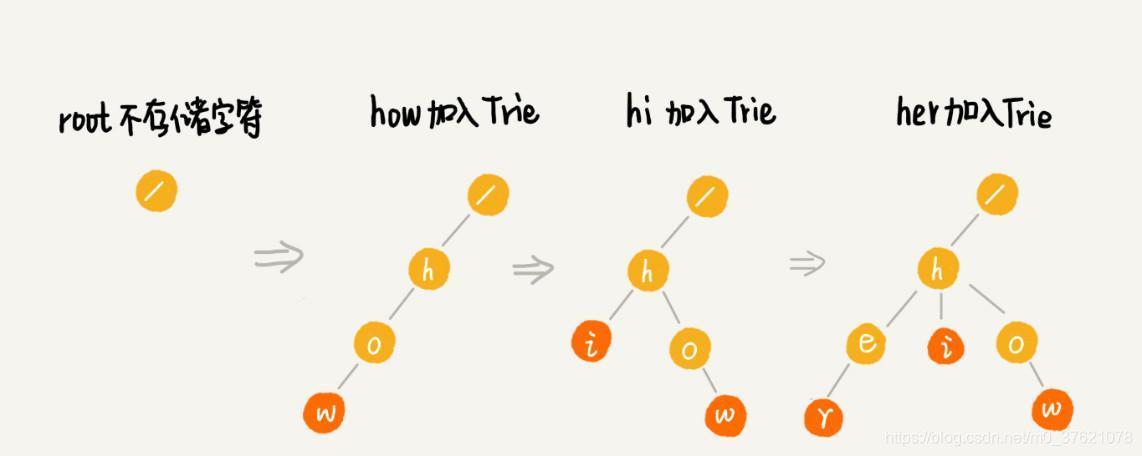
基于Trie 树查字典的过程符合DFS 规律,单词拼写提示的第一阶段前缀匹配实际上就是按DFS 顺序查字典,单词拼写提示的第二阶段实际上就是将匹配前缀的最后一个字符后面的所有分支列举出来,穷举所有与前缀匹配的后续分支或单词的过程,可以使用回溯算法实现。
本文实现代码下载链接:https://github.com/StreamAI/ADT-and-Algorithm-in-C/tree/master/algorithm or https://github.com/StreamAI/Leetcode-CPP/tree/main/Backtracking_DFS
评论记录:
回复评论: