
前言
计算机的两大核心任务是数值计算和字符处理,分别对应数学语言和自然语言,各种计算机编程语言也分别为数值计算和字符处理提供了丰富的库函数。前篇博文从字符编码和字符类型开始,介绍了C 语言常用的字符串和字符数组操作函数,C++ 由于兼容C 语言的设计,也完全支持前文介绍的字符类型识别、字母大小写转换、数值格式与字符串格式间的相互转换、字符串或字符数组的比较、拼接、复制替换、查找匹配、分割获取子串等操作。
但以字符数组的形式操作字符串也存在一些局限,比如为字符串申请的数组长度都是定长的,如果要拼接或者扩充字符串,可能原来的数组空间不够用,需要开发者重新申请更大的空间以容纳更多的字符,而且还容易发生数组访问越界的问题。回想下前面介绍过的C++ STL(Standard Template Library),不管是vector、deque、list、forward_list 这些线性的序列式容器(包括为应对特殊需求,基于这些序列式容器实现的stack、queue、priority_queue等),还是set、map、unordered_set、unordered_map 这些有序或无序的关联式容器,都支持自动变长特性,而且提供了丰富的操作函数,方便我们直接处理和操作STL 内的元素,我们能否借助C++ STL 容器来处理字符串呢?
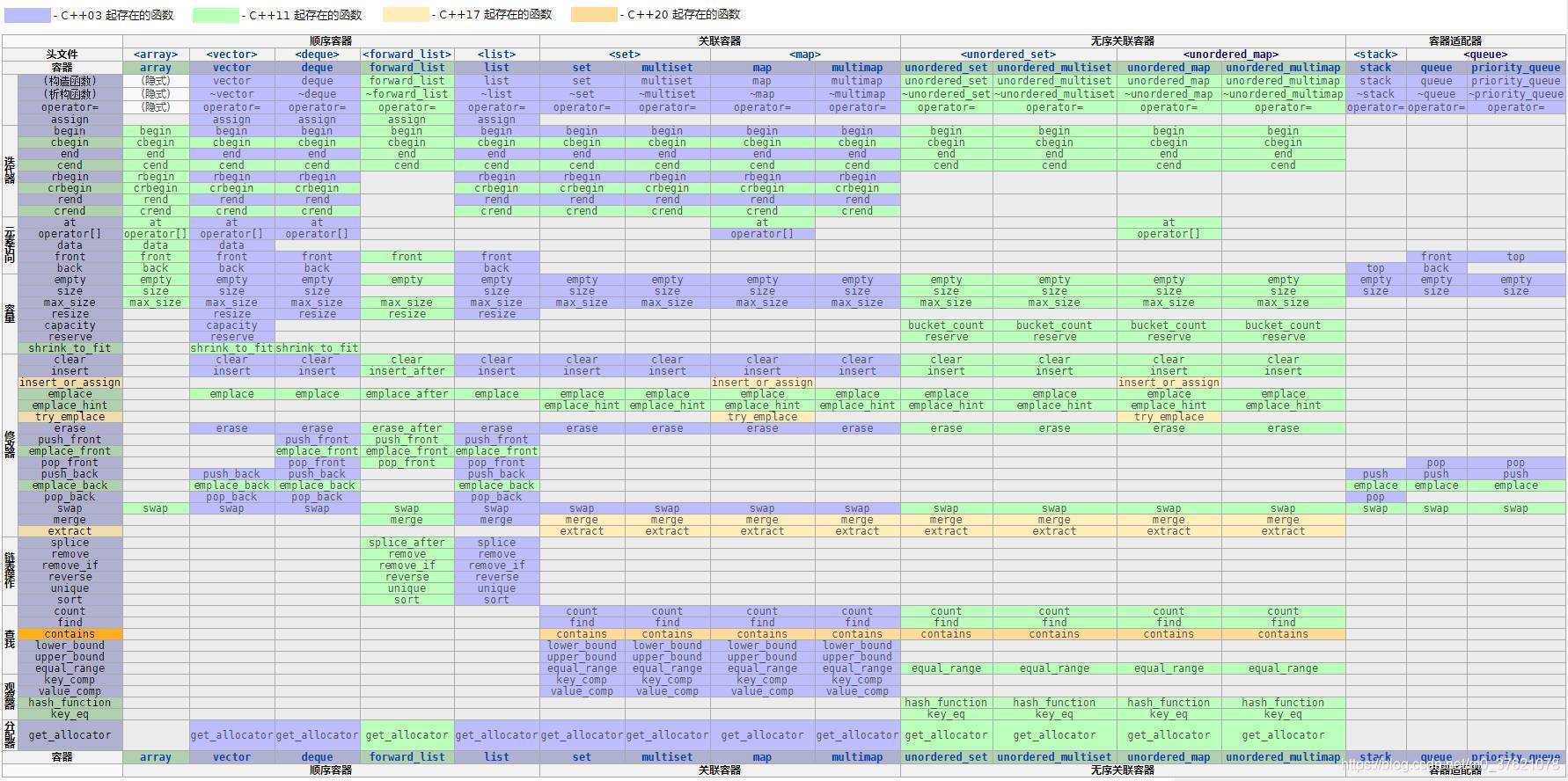
最适合用来处理字符信息的容器是vector,既支持变长特性,又支持随机访问,也能高效的顺序遍历容器内各字符。但vector
- Vector
:首要目标是处理和操作容器内的元素,而非容器整体,因此实现时通常会考虑“容器元素的操作行为”的最优化。 - String class:主要是把整个字符串视为整体来处理和操作,因此实现时通常会考虑“整个字符串的赋值和传递”的最优化。
不同的设计目标往往导致完全不同的实现手法,比如String 为了提高字符串的赋值和传递效率,通常采用reference 语义,而Vector
String 支持vector 提供的大部分操作,同时还新增了一些字符串处理的操作,而且string 和vector
C++ 相比C 语言增强的部分除了面向对象编程方法外(C 语言也可以实现面向对象的特征,可参考博文:C语言对象化模型),另一个就是泛型编程(C 语言也支持有限的泛型编程,可参考博文:qsort与bsearch 比较函数),STL 正是泛型编程的绝佳实现。String 则是已经限定了操作处理的数据类型为字符类型,而且C++ 已经为其预设了数据类型,我们使用string 时并不需要再声明数据类型,因此string 并不算STL 容器,但string 可以作为任何一种STL 容器的元素被STL 操作处理。
一、C++ String支持的字符操作
String 跟vector 类似,也支持动态调整大小,在初始化字符串时会多申请一部分空间(我测试初始化一个空字符串,查询其容量为15),为以后的变长预留位置。当预留空间用完之后,若要继续插入字符元素就需要再找一块儿更大的连续地址空间(一般为原地址空间的两倍大小),将原地址空间的数据搬移到新的地址空间(字符串需要经常顺序遍历各字符,连续地址空间可以保证遍历效率),继续支持变长特性,这个操作称为变长数组的扩容。由于扩容后,原数据元素搬移导致地址变更,对这些元素的地址引用操作比如引用、指针、迭代器等都将失去作用,且扩容操作比较耗时。要想缓解扩容导致的问题,可以在创建变长数组时,根据我们的需求预留足够的空间(string 提供了reserve 函数预留一定空间),但预留太多空间会导致空间浪费,这个取舍需要平衡。
C++11 string 和vector 的类模板定义对比如下(第一个参数charT 为字符类型;带默认值的第二个参数Traits 指定字符类型上操作的特性类,规定如何复制、比较、查找、转换字符等;带默认值的第三个参数Allocator 定义了string class 所采取的内存模型):
// 
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
从上面的类模板定义可以看出,vector 使用时需要声明模板数据类型T,string 则是已经被声明了模板数据类型char,使用时不需要再额外声明数据类型,如果想使用宽字符类型,直接使用wstring、u16string、u32string 即可。本文主要介绍最常用的string 类型,其支持的常用操作如下:

String class 提供的上述字符串操作函数,其中很多往往具有数个重载版本,不同重载版本支持的参数类型要求不同,下面给出不同操作函数支持的实参类型:
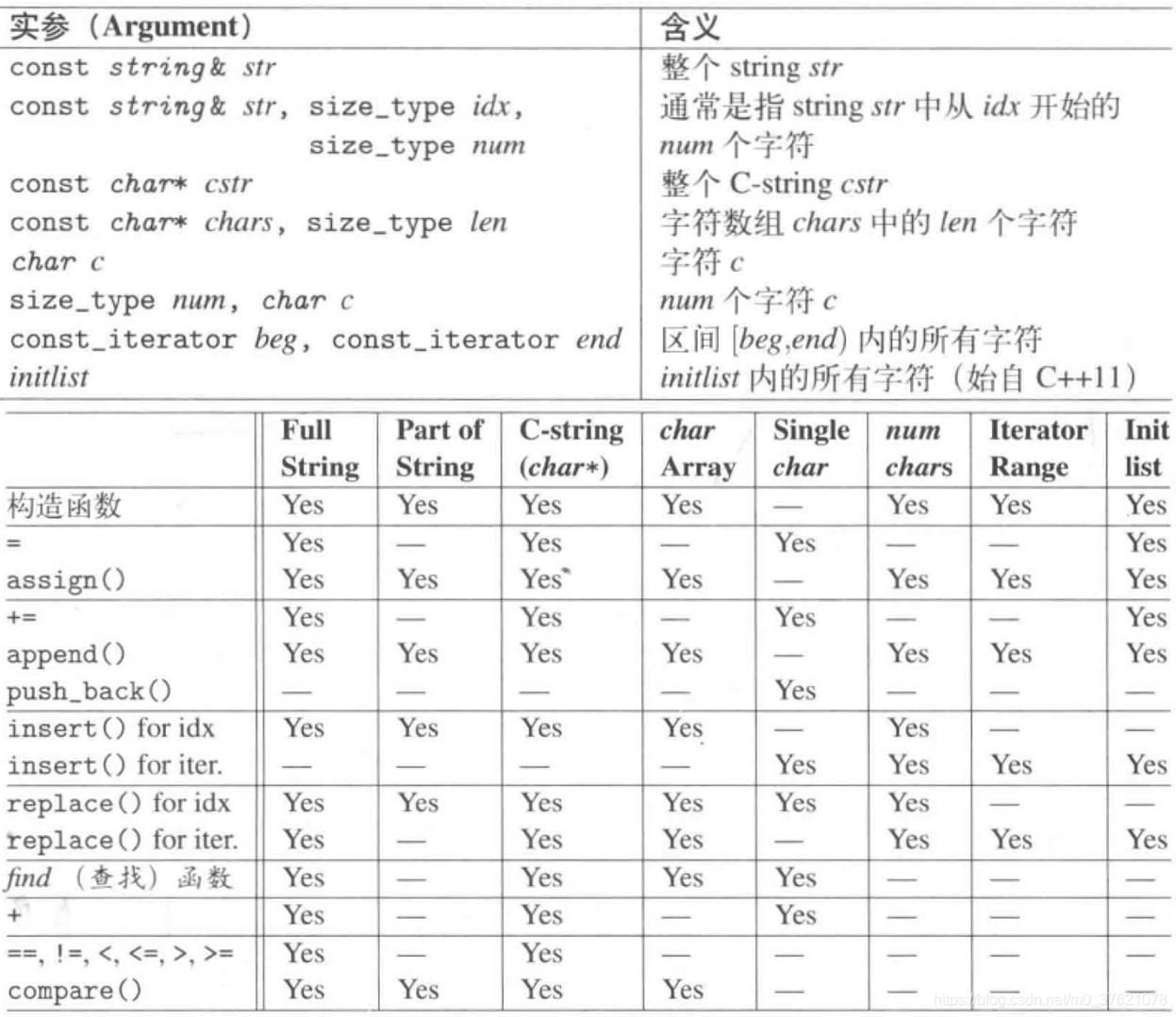
为方便和vector
1.1 构造析构与赋值操作(创建、复制、销毁)
String class 支持的构造与析构函数如下:
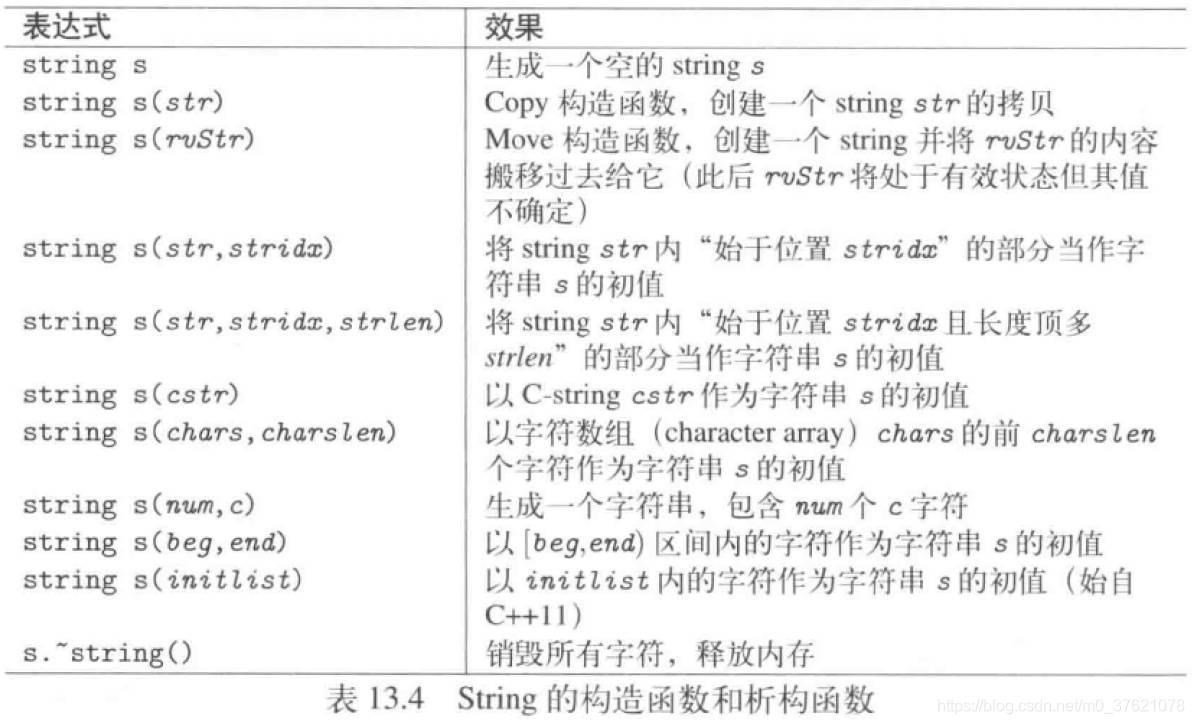
String 构造函数允许以整个字符串、字符串的一部分、整个C-string(也即带空终止符的字符数组)、字符数组中的部分字符、多个字符、迭代器区间内的字符、初始化列表等形式来初始化一个字符串,但不能以单个字符初始化一个字符串,比如下面这样:
#include- 1
- 2
- 3
- 4
String class 支持的赋值操作如下:
| 表达式 | 效果 |
|---|---|
| s = str s.assign(str) | 将字符串str 的全部元素以copy assignment 方式赋值给字符串s |
| s = rvStr s.assign(rvStr) | 将字符串rvalue rvStr 的所有元素以move assignment 方式搬移给字符串s |
| s.assign(str, stridx, strnum) | 将str 内从索引stridx 开始最多strnum 个字符赋值给字符串s |
| s = cstr s.assign(cstr) | 将C-string cstr 的内容赋值给字符串s,不包括’\0’ |
| s.assign(chars, charslen) | 将字符数组chars 内的charslen 个字符赋值给字符串s |
| s = c | 将单个字符c 赋值给字符串s |
| s.assign(num, c) | 将num 个字符c 赋值给字符串s |
| s.assign(beg, end) | 将迭代器[beg, end) 区间内的所有字符赋值给字符串s |
| s = initlist s.assign(initlist) | 将初值列表initlist 内的所有字符赋值给字符串s |
| s.swap(str) swap(s, str) | 用来交互字符串s 和str 的内容,具有常量复杂度,可使用该操作更快的实现string object 间的赋值 |
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
上例中的std::string::npos 被定义为-1,也可表示size_t 无符号类型的最大值,这里取后一种意思表示取最多size_t 能表示的最大值个字符,也即一直取到字符串的末尾。在后面将要介绍的字符串查找操作中,可使用std::string::npos 取前一种意思,表示没有找到期望的内容。
static const size_type npos = -1;
- 1
1.2 元素访问与容量操作
String class支持的容量操作如下:
| 表达式 | 效果 |
|---|---|
| s.empty() | 返回字符串s是否为空,等价于s.size() == 0 但可能更快 |
| s.size() s.length() | 返回字符串s 的现有字符数,两个函数等效 |
| s.max_size() | 返回字符串s 最多能够包含的字符数,返回值一般是索引类型的最大值减1 |
| s.capacity() | 返回字符串s 扩容或重新分配内存之前,所能包含的最大字符数 |
| s.reserve() s.reserve(size_t num) | 为字符串s 保留至少能容纳num 个字符的内存空间,若未指定num 或num < s.size()则相当于s.shrink_to_fit() |
| s.shrink_to_fit() | 降低字符串s 的内存占用以符合当前字符数,是一个“非强制性合身缩减”请求,相当于s.reserve() |
| s.resize(size_t num) s.resize(size_t num, char c) | 将字符串s 的字符数重新调整为num,若num != s.size() 则在字符串尾部添加或删除足够字符(若字符串增加则以字符c 为初值,若未指定c 则以’\0’为初值),若num == string::npos 或num > s.max_size()则抛出length_error异常 |
String class支持的元素访问操作如下:
| 表达式 | 效果 |
|---|---|
| s[size_t idx] | 返回字符串s 索引 idx 所指的字符(不检查索引是否有效,若idx 超出范围则可能访问非法内存) |
| s.at(size_t idx) | 返回字符串s 索引 idx 所指的字符(如果idx 超出范围,系统会抛出out_of_range异常) |
| s.front() | 返回字符串s 的第一个元素,相当于s[0],若字符串s 为空则返回值为’\0’ |
| s.back() | 返回字符串s 的最后一个元素,相当于s[s.length()-1],若字符串s 为空则会导致不明确的行为 |
#include- 1
- 2
- 3
- 4
- 5
1.3 比较操作与C-string 产生
String object 转换为C-string 的操作:
String class 并不同于C 语言中的字符串,C 语言中的字符串实际上是带空终止符的字符数组,在C++ 中为了跟string class 区分,将C 语言风格的字符串称为C-string。String class 中的字符串对象和C-string 中的字符数组类型并不一致,二者不能混用,string class 可通过构造或赋值操作将C-string 转换为string object,但如果我想将string object 转换为C-string 可以吗?C++ 为此提供了如下两个操作函数,便于将string object 转换为C-string:
| 表达式 | 效果 |
|---|---|
| s.data() s.c_str() | 从C++11 起两个函数是等价的,都是将string object 的内容以C-string 形式(字符数组尾部自动添加‘\0’)返回,但返回类型为const char*,调用者不能修改、释放、删除该返回值 |
| s.copy(char* buf, size_t num) s.copy(char* buf, size_t num, size_t idx) | 将string object 内从索引 idx 开始最多num 个字符复制到字符数组buf 中(若无索引参数idx 相当于idx == 0),返回被复制的字符数(应确保buf 有足够内存且idx 不超范围),但不自动添加‘\0’,因此复制后的buf 可能不是有效的C-string |
值得一提的是,空终止符’\0’ 只是C-string 的结束标识,在string 中并不具有特殊意义,也即在string 中字符’\0’ 和其它字符的地位完全相同,string 中自有成员变量来统计当前字符数量,因此并不需要结束标识。
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
String class 支持的比较操作:
C++ 为string class 重载了关系运算符,让两个string object 或C-string 之间可以直接使用关系运算符比较大小,实际上就是按字典序逐个比较两个字符串中的字符。除了关系运算符,C++ 还为string class 提供了compare 成员函数(vector 未提供该操作函数),功能更强大,还可以只比较两个字符串中的部分字符,建议优先使用compare 操作函数,string class 提供的比较操作如下:
| 表达式 | 效果 |
|---|---|
| ==,!=, <, <=, >, >= | 按字典序进行比较两个字符串,关系运算符任一端可以是string object 也可以是C-string(两种字符串可相互比较),返回布尔型的比较结果 |
| s.compare(str) s.compare(cstr) | 将字符串s 的所有字符和string object str 或C-string cstr 的所有字符相比较,若s == str/cstr 则返回0,若s < str/cstr 则返回负值,若s > str/cstr 则返回正值(一般按字典序比较,下面的返回值规则与此一致) |
| s.compare(size_t idx, size_t len, str) s.compare(size_t idx, size_t len, cstr) | 将字符串s 从索引 idx 开始的最多len 个字符和string object str 或C-string cstr 的所有字符相比较,返回值规则同上 |
| s.compare(size_t idx, size_t len, str, size_t stridx, size_t strlen) | 将字符串s 从索引 idx 开始的最多len 个字符和string object str 从索引 stridx 开始的最多strlen 个字符相比较,返回值规则同上 |
| s.compare(size_t idx, size_t len, chars, size_t charslen) | 将字符串s 从索引 idx 开始的最多len 个字符和字符数组chars 内的前charslen 个字符相比较,返回值规则同上 |
#include- 1
- 2
- 3
- 4
- 5
1.4 迭代器与修改操作(新增、清除、替换)
String 是字符的有序集合,C++ 标准库为string 提供了random-access iterator 让你可以像使用STL 容器那样遍历string 内的所有字符,它支持随机访问,且可被任何一个STL 算法接受,但如果string 因扩容发生内存地址空间重分配 iterator 也会失效。String 支持的迭代器类型及其相关操作如下:

上表不仅给出了string class 支持的迭代器类型,还给出了其支持的新增、清除、替换操作中跟迭代器相关的重载函数,其中s.append() 和s.replace() 是string class 独有的操作,vector 并不支持这两个操作。除了上述跟迭代器相关的操作,String 支持的其它新增、擦除、替换等修改操作如下:
| 表达式 | 效果 |
|---|---|
| s += str s.append(str) | 将string object str 添加到字符串s 的尾部 |
| s += cstr s.append(cstr) | 将C-string cstr 添加到字符串s 的尾部 |
| s.append(str, size_t stridx, size_t strnum) | 将string object str 内从索引 stridx 开始的strnum 个字符添加到字符串s 的尾部 |
| s.append(chars, size_t charslen) | 将字符数字chars 内的前charslen 个字符添加到字符串s 的尾部 |
| s.append(size_t num, c) | 将num 个字符c 添加到字符串s 的尾部 |
| s += c s.push_back( c ) | 将单个字符c 添加到字符串s 的尾部 |
| s += initlist s.append(initlist) | 将初值列表initlist 内的所有字符添加到字符串s 的尾部 |
| s.insert(size_t idx, str) s.insert(size_t idx, cstr) | 将string object str 或C-string cstr 插入到字符串s 内,从索引 idx 处开始安插新增字符 |
| s.insert(size_t idx, str, size_t stridx, size_t strnum) | 将string object str 内从索引 stridx 开始的strnum 个字符插入到字符串s 内,从索引 idx 处开始安插新增字符 |
| s.insert(size_t idx, chars, size_t charslen) | 将字符数组chars 内的前charslen 个字符插入到字符串s 内,从索引 idx 处开始安插新增字符 |
| s.insert(size_t idx, size_t num, c) | 将num 个字符c 插入到字符串s 内,从索引 idx 处开始安插新增字符 |
| s.clear() s.erase() | 删除字符串s 内的所有字符,调用后s 为空 |
| s.erase(size_t idx) s.erase(size_t idx, size_t len) | 删除字符串s 内从索引 idx 开始的最多len 个字符 |
| s.pop_back() | 删除字符串s 的最后一个字符 |
| s.replace(size_t idx, size_t len, str) s.replace(size_t idx, size_t len, cstr) | 将字符串s 内从索引 idx 开始的最长为len 的字符替换为string object str 或C-string cstr 内的所有字符 |
| s.replace(size_t idx, size_t len, str, size_t stridx, size_t strnum) | 将字符串s 内从索引 idx 开始的最长为len 的字符替换为string object str 内从索引 stridx 开始的最长为strnum 的所有字符 |
| s.replace(size_t idx, size_t len, chars, size_t charslen) | 将字符串s 内从索引 idx 开始的最长为len 的字符替换为字符数组chars 内的前charslen 个字符 |
| s.replace(size_t idx, size_t len, size_t num, c) | 将字符串s 内从索引 idx 开始的最长为len 的字符替换为num 个字符c |
| s.substr() s.substr(size_t idx) s.substr(size_t idx, size_t len)> | 返回字符串s 中从索引 idx 开始的最多len 个字符组成的substring,若无len 参数则将余下的所有字符当作substring 返回,若无idx 和len 参数则返回string 的拷贝 |
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.5 数值转换操作
C 语言提高了数值格式与字符串格式之间相互转换的库函数,C++ 自然也提供了相应的数值转换操作,不仅提供了将string object 字符串转换为数值格式的操作函数,还提供了将数值格式转换为string object 字符串的操作函数,string class 支持的数值转换操作如下:
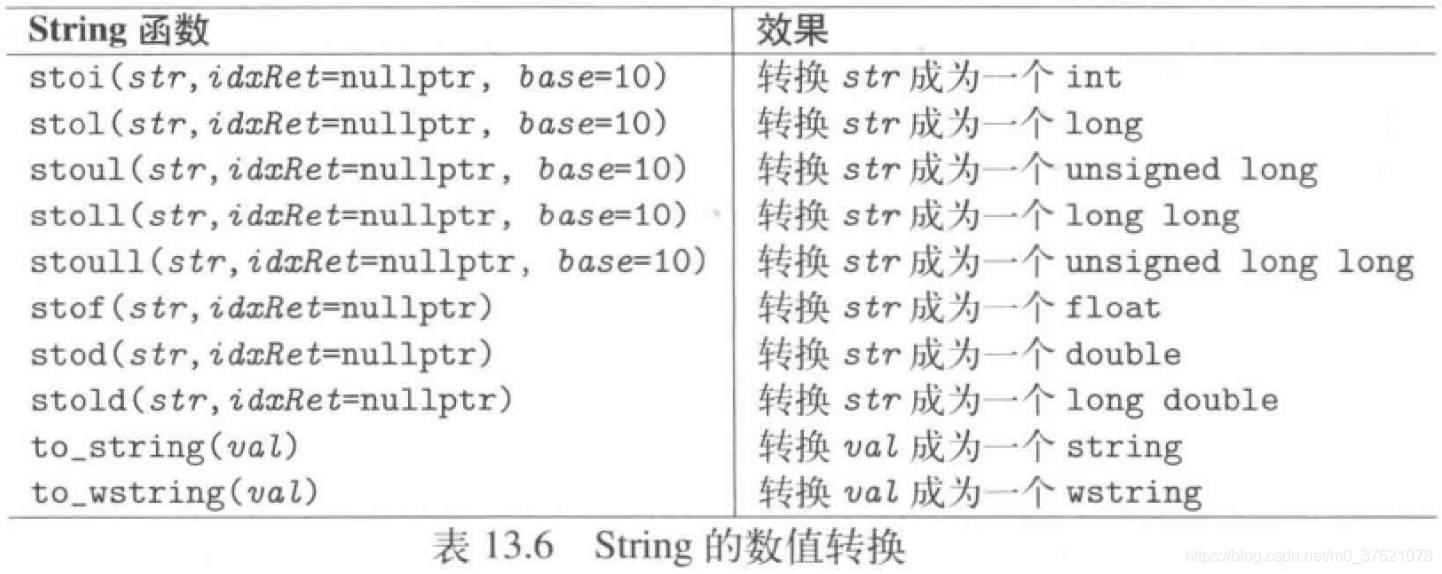
String class 提供的数值转换操作后两个参数给了默认值,若默认参数符合需求调用这些参数只传入一个参数即可,第二个默认参数空指针nullptr,需要注意的是这里不能像C 语言那样传入NULL,因为在C++ 中NULL 相当于整数0,而非空指针(C语言中NULL表示空指针),C++ 中使用nullptr 表示空指针(C++ 中0 也可以表示空指针,但若遇到重载函数NULL 按整数类型处理,nullptr 按指针类型处理)。
#ifdef __cplusplus
#define NULL 0 // 若判断为c++ 类型则将NULL定义为整数0
#else
#define NULL ((void *)0) // 若判断为c++ 类型则将NULL定义为void类型的指针
#endif
- 1
- 2
- 3
- 4
- 5
1.6 查找与匹配操作
字符串处理相比数值计算更常用的是字符查找和匹配操作,string class 自然会提供不少用于查找匹配字符或子字符串的操作函数,跟字符查找匹配相关的操作主要有如下三类:
- 使用成员函数:可以调用string class 成员函数正向或反向查找匹配单一字符、子字符串或字符数组的字符索引,还可以查找第一个或最后一个属于或不属于某单个字符、子字符串或字符数组的字符索引:

- 使用STL 算法:可以使用STL 算法查找搜索单个字符或指定字符序列第一次或最后一次出现的位置,STL 算法传参和返回值主要是迭代器类型,string class 完全支持随机访问迭代器:
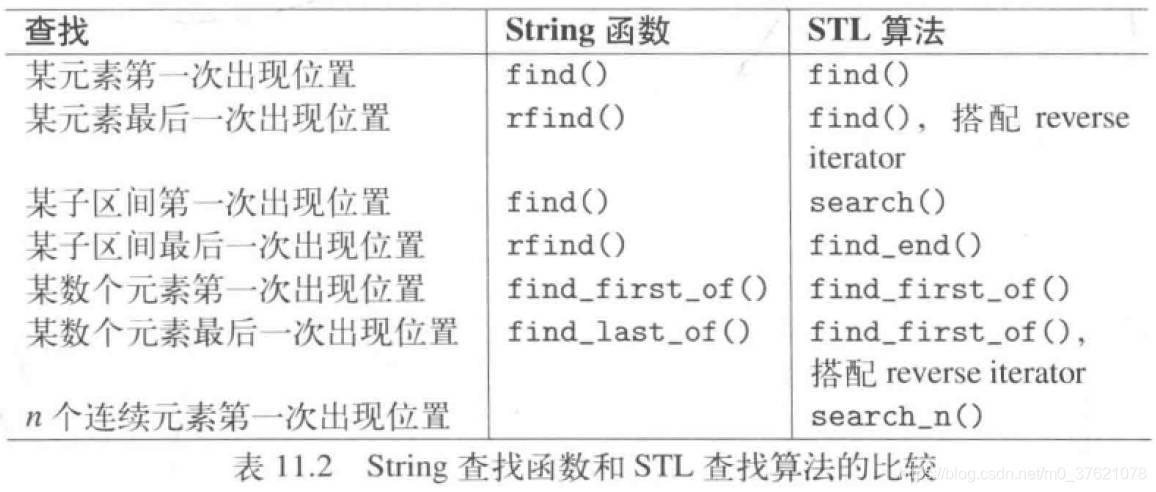
- 使用regex 正则程序库:可以使用regex 正则表达式程序库查找匹配更复杂的字符序列样式:

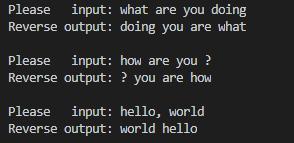
下面给出一个字符查找匹配的示例程序,功能是从输出的一行英文句子中,提取单词并将其原地反向打印出来:
#include- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
程序输出:
二、C++ Regex 支持的正则匹配操作
前文介绍字符串查找匹配时,提到了C++ 提供三种跟字符查找匹配相关的操作函数库,除了前文介绍的string class 成员函数和STL 查找算法外,另一个就是使用regex 正则表达式程序库实现更复杂的字符序列样式查找和匹配。
正则表达式(regular expression)的强大之处在于,它允许你使用通配符(wildcard)和模式(pattern)来查找匹配和替换string 中的字符,你可以使用正则表达式完成以下操作:
- Match:将整个字符序列拿来匹配某个正则表达式。
- Search:查找与某个正则表达式匹配的pattern(也即部分字符序列)。
- Replace:将与正则表达式匹配的第一个(或后续所有)子序列替换掉。
2.1 正则表达式文法
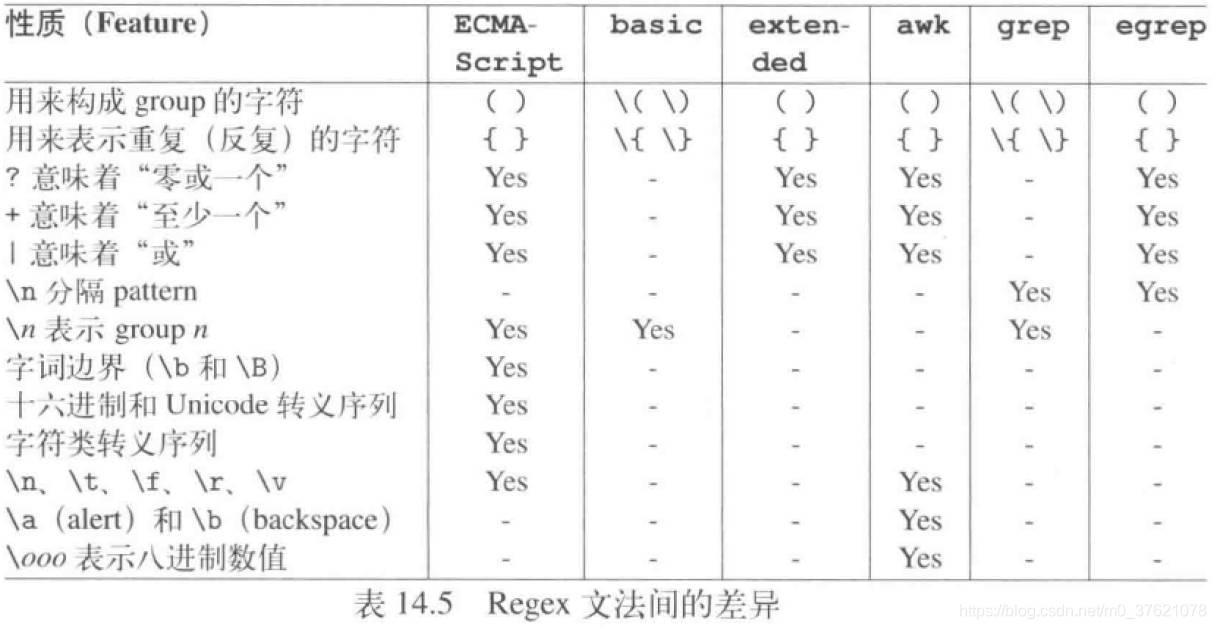
在介绍Regex 正则匹配程序库之前,先介绍点正则文法,regex 程序库的默认文法是“经改造的ECMAScript” 文法,它比其它文法的威力强大很多,下表列出了最重要的特殊表达式以及它们的意义:
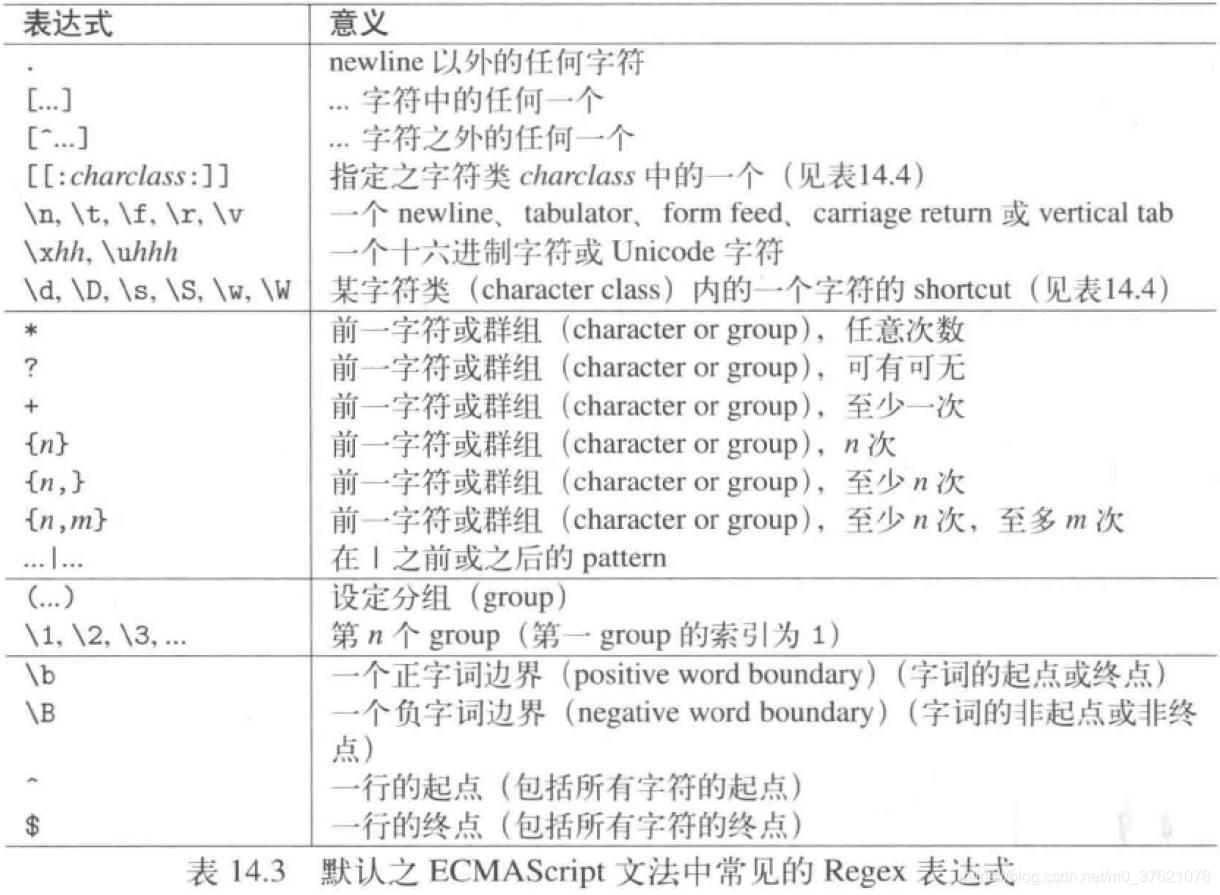
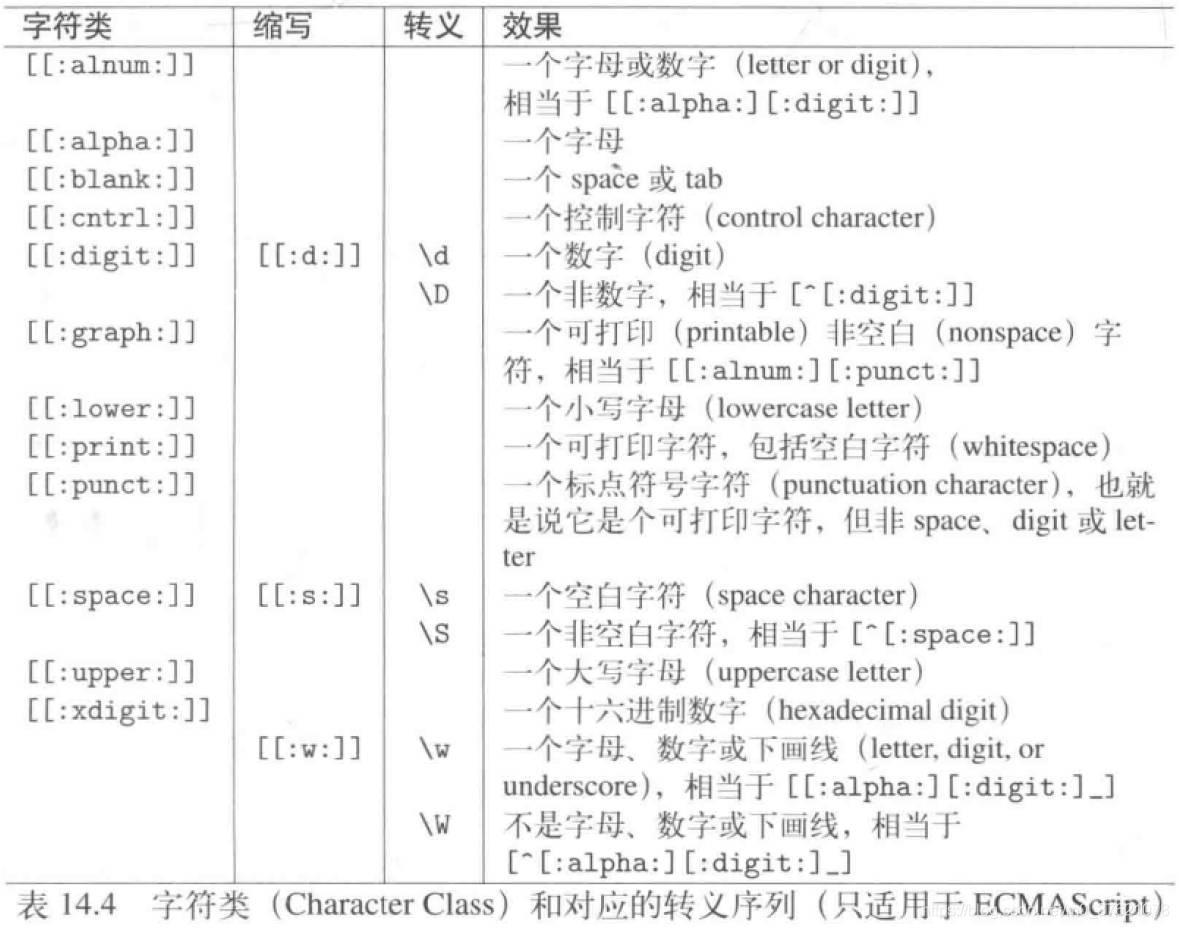
上表在中括号表达式[…]内,可以指明任何字符组合(包括特殊字符)、字符区间(比如[0-9a-z])以及字符类(比如[[:digit:]])。若出现前导符^(也即 [^…])表示要取整个表达式的补集,表示“除… 之外的任何字符”。下表列出了正则表达式中可能的字符类(character class):
#include- 1
- 2
- 3
- 4
除了默认的ECMAScript 文法,C++ 标准库还支持其它五种文法,其中basic 和extended 分别是POSIX 的基础和扩展正则文法,awk、grep、egrep 是UNIX 工具awk、grep、egrep 的正则文法,这三个命令在linux 系统shell 中也很常用,如果熟悉linux 系统应该也用过其中的某几个命令。这六种正则文法的主要差异对比如下:
2.2 Regex 支持的匹配与查找操作
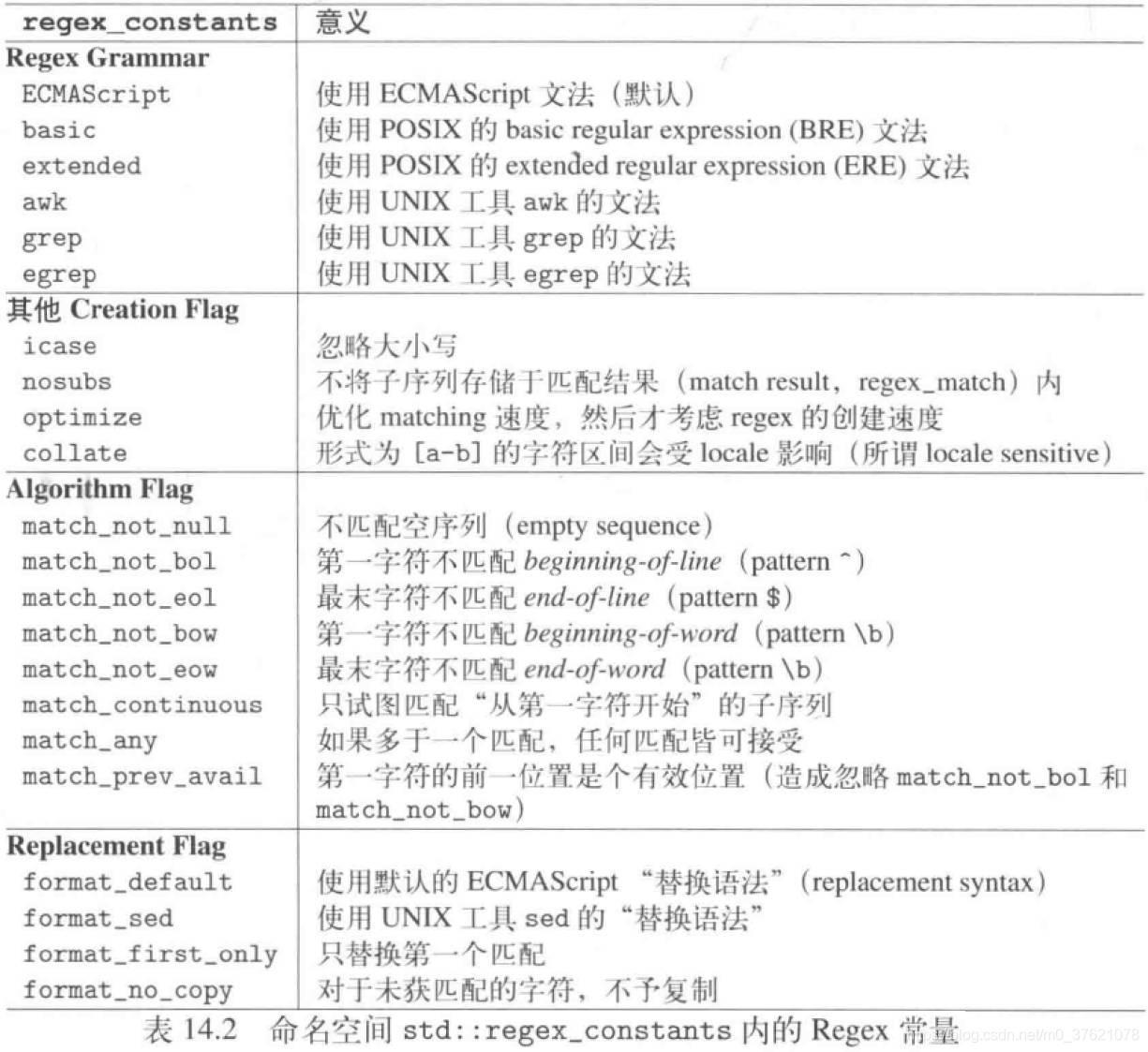
了解了regex 支持的正则表达式文法,接下来看怎么使用regex 提供的操作函数实现更复杂的字符序列查找匹配操作,regex class支持的操作函数如下:
上表中的regex 参数实际就是正则表达式,其中的flags 参数是用来影响regex 接口行为的一些regex_constants,regex class 提供的操作函数中一般都为flags 参数提供了默认值,如果调用者有特殊需求(比如选择其它的正则文法),也可以重设flags 参数值,regex library 提供的regex_constants 如下表示:
下面给出一个regex 整体匹配和部分匹配的示例程序,同时介绍了匹配结果对象std::match_results 的使用:
#includethe value ."); // 要查找匹配的数据1
regex reg1("<(.*)>(.*)"); // 定义正则表达式1,最后的转义字符\\1 实际上是'\1',表示跟第一组相同
bool found = regex_match(data1, reg1); // 正则匹配整个字符序列
cout << "regex_match result: " << (found ? "found" : "not found") << endl;
regex reg2(".*<(.*)>(.*).*"); // 定义正则表达式2
found = regex_match(data1, reg2); // 正则匹配整个字符序列
cout << "regex_match result: " << (found ? "found" : "not found") << endl;
found = regex_search(data1, reg1); // 正则查找部分字符序列
cout << "regex_search result: " << (found ? "found" : "not found") << endl;
cout << endl;
smatch mres; // 保存匹配的返回结果,若匹配结果为string object 则使用smatch 类型(wstring 对应wsmatch)
//若匹配结果为C-string 则使用cmatch 类型(wchar_t 对应wcmatch)
found = regex_search(data1, mres, reg1); // 保存模式匹配结果的正则查找
if(found == true) {
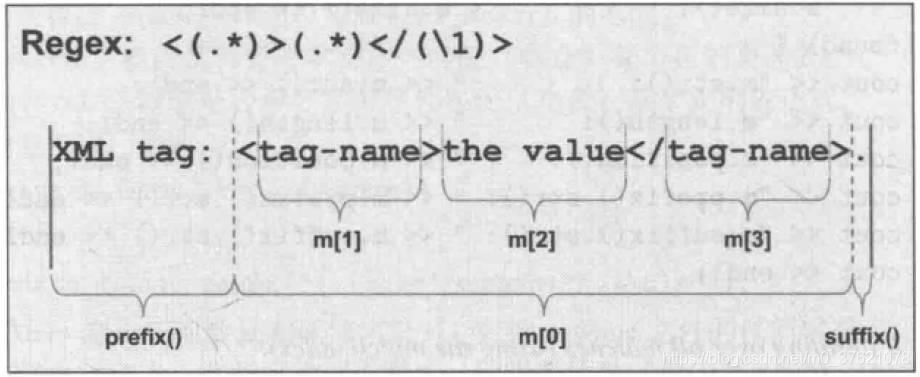
cout << "mres.size(): " << mres.size() << endl; // 匹配对象的个数,如下图所示data1 共有4 个匹配对象mres[0] ~ mres[3]
cout << "mres.str(): " << mres.str() << endl; // 打印整个匹配结果的字符序列,可使用str(n) 获得对应部分的匹配字符序列,n 对应下图中0 ~ 3
cout << "mres.length(): " << mres.length() << endl; // 打印整个匹配结果的字符数,可使用length(n) 获得对应部分的字符数量,n 对应下图中0 ~ 3
cout << "mres.position(): " << mres.position() << endl; // 打印整个匹配结果的起始位置,可使用position(n) 获得对应部分的匹配字符位置,n 对应下图中0 ~ 3
cout << "mres.prefix().str(): " << mres.prefix().str() << endl; // 表示第一个匹配合格的字符前方的所有字符
cout << "mres.suffix().str(): " << mres.suffix().str() << endl; // 表示最后一个匹配合格的字符后方的所有字符
cout << endl;
}
string data2 = "\n"
"Nico \n"
"Joson \n"
"\n"; // 要查找匹配的数据2
auto pos = data2.cbegin(); // 保存要查找数据的起始位置
while (regex_search(pos, data2.cend(), mres, reg1)) {
cout << "match result: " << mres.str() << endl; // 打印匹配结果
cout << "tag-name: " << mres.str(1) << endl; // 打印匹配结果的第一组,也即下图中的m[1]
cout << "the value: " << mres.str(2) << endl; // 打印匹配结果的第二组,也即下图中的m[2]
pos = mres.suffix().first; // 将查找数据的起始位置设置为该匹配结果的下一个字符
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
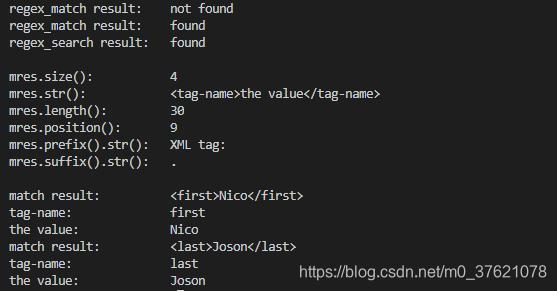
程序输出:
2.3 Regex 支持的替换与分割操作
Regex class 支持的替换操作:

与regex_match 和regex_search 返回bool 类型不同的是,regex_replace 返回替换后的字符串结果strRes,当然也支持将替换后的字符串保存到一个字符串变量中,但需要传入该变量的迭代器形式outPos。参数repl 全称replacement,实际上是一个字符串(可以是string class 或C-string 形式),用于表示要将匹配结果替换成的形式。
下面给出一个regex 替换匹配部分的示例程序:
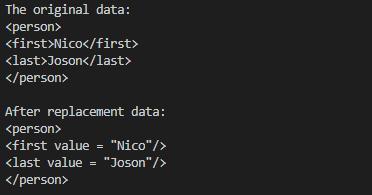
#include\n"
"Nico \n"
"Joson \n"
"\n"; // 要查找匹配的数据1
cout << "The original data:" << endl << data1 << endl;
regex reg1("<(.*)>(.*)"); // 定义正则表达式1,最后的转义字符\\1 实际上是'\1',表示跟第一组相同
string repl1 = R"(<$1 value = "$2"/>)"; // 要将匹配结果替换成的字符串形式,R 表示raw string 可省略转义字符
// $1 和$2 表示匹配的子表达式,同上图中的m[1] 和m[2](也即tag-name 和the value)
string res1 = regex_replace(data1, reg1, repl1); // 将匹配结果替换为repl1 的形式
cout << "After replacement data:" << endl << res1 << endl;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
程序输出:
Regex class 支持的分割操作:
Regex class 除了提供match、search、replace 三个主要操作外,还提供了字符串分割操作,不过对字符串的切分并不是通过额外的操作函数完成的,而是借助regex_token_iterator。Regex class 切分字符串的原理是使用分隔符作为匹配序列,不像前面那样重点关注匹配内容,而是重点关注匹配子序列之间的内容,匹配子序列实际就是分隔符,分隔符之间的内容就是一个个token,从而达到语汇切分的效果。
下面给出一个使用regex_token_iterator 来切分字符串提取token 或感兴趣的特定子序列的示例程序:
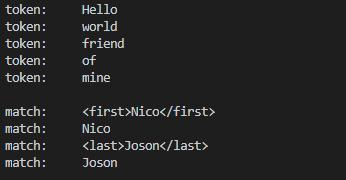
#include\n"
"Nico \n"
"Joson \n"
"\n"; // 要查找匹配的数据2
regex reg1("<(.*)>(.*)"); // 定义正则表达式1
sregex_token_iterator pos2(data2.cbegin(), data2.cend(), reg1, {0, 2}); // 最后一个参数{0,2}表示对整个匹配序列和第2个匹配子序列感兴趣,也即m[0]和m[2]
for (; pos2 != end; ++pos2)
cout << "match: " << pos2->str() << endl; // 输出感兴趣的匹配结果
cout << endl;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
程序输出:
本文示例代码下载地址:https://github.com/StreamAI/ADT-and-Algorithm-in-C/tree/master/string
评论记录:
回复评论: