
一、TCP/IP分层思想
直接看理论书籍不够直观高效,这个系列依然主要从如何实现的角度介绍TCP/IP协议。就像前面介绍操作系统,主要从比较简单的UCOS源码介绍操作系统的实现,对RTOS的实现有了深入的了解,再去阅读Linux的源码会更容易理解。这里介绍的TCP/IP系列也从相对轻量的LwIP协议栈源码的实现来介绍TCP/IP协议的原理和应用,LwIP协议源码如下:http://git.savannah.gnu.org/cgit/lwip.git
这里选择相对简单的LwIP 1.4.1版本作为示例代码,下面先看下TCP/IP经典的分层模型:
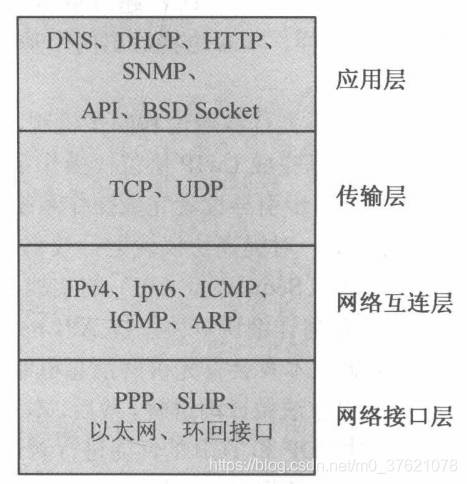
- 网络接口层:定义数据帧(对电信号0/1进行的特定分组)、确认主机的物理地址(MAC地址),通过传输介质在网络上传输数据帧。网络接口有不同的实现方式,比如可以通过有线或无线的方式收发数据帧,不同的实现方式意味着不同的帧结构、传输速率等。
- 网络层:定义网络地址(IP地址)、区分网段、对于子网内的数据包进行MAC寻址、对于不同子网的数据包进行路由,实现网络中主机到主机的通信。
- 传输层:定义端口(Port)、标识应用程序身份、实现端口到端口的通信,TCP协议可以保证数据传输的可靠性。
- 应用层:定义数据格式并按照对应的格式解读数据(下层传送过来的是字节流,不能很好的被程序识别)。应用层定义了各种各样的协议来规范数据格式,常见的有 HTTP、FTP、SMTP 等。
下面以访问一个网址为例,把每层模型的职责串联起来:
当你输入一个网址并按下回车键的时候,首先,应用层协议对该请求包做了格式定义;紧接着传输层协议加上了双方的端口号,确认了双方通信的应用程序;然后网络层协议加上了双方的IP地址,确认了双方的网络位置;最后网络接口层协议加上了双方的MAC地址,确认了双方的物理位置,同时将数据进行分组,形成数据帧,采用广播方式,通过传输介质发送给对方主机。而对于不同网段,该数据包首先会转发给网关路由器,经过多次转发后,最终被发送到目标主机。目标机接收到数据包后,采用对应的协议,对帧数据进行组装,然后再通过一层一层的协议进行解析,最终被应用层的协议解析并交给服务器处理。
LwIP协议栈实现的TCP/IP主要功能如下:
| 协议实现文件 | 功能描述 |
|---|---|
| .\src\netif\ppp | Point to Point Protocol,支持PPPoE(Point-to-Point Protocol Over Ethernet) ,比如宽带拨号上网就使用了PPPoE |
| slipif.c | Serial Line Internet Protocol,在串行链路上传输IP数据包 |
| ethernetif.c | Ethernet Protocol,通过以太网卡传输IP数据包,但移植时需要实现以太网卡驱动函数 |
| etharp.c | Address Resolution Protocol,实现主机以太网物理地址到IP地址的映射 |
| .\src\core\ip | 包括IPv4和IPv6,支持IP分片重组,支持多网络接口下数据报的转发;为数据包在网络主机间传输提供支持,是TCP/IP协议簇中最重要的协议 |
| autoip.c | IP地址自动配置,若主机从DHCP服务器获取IP地址失败,则可选择启用该功能来配置自身IP地址 |
| icmp.c | Internet Control Message Protocol,为IP数据包传递过程中的差错报告、差错纠正、目的可达性提供支持,常见的ping命令就属于该协议应用的一种 |
| igmp.c | Internet Group Management Protocol,为网络中的多播数据传输提供支持,主机加入某多播组后,可以接收该组的UDP多播数据包 |
| udp.c | User Datagram Protocol,无连接非可靠高速率的传输协议,本身不支持重传应答机制,但可以在上层实现简单的重传应答机制来保证一定的传输可靠性 |
| tcp.c | Transmission Control Protocol,面向连接的可靠的传输协议,支持TCP拥塞控制、RTT估计、快速恢复与重传等,保证传输的可靠势必会降低一定的传输速率 |
| .\src\core\snmp | Simple Network Management Protocol,基于UDP实现,为互联网上设备的管理提供了框架 |
| dhcp.c | Dynamic Host Configuration Protocol,可以从DHCP服务器处获得一个有效的IP地址,使计算机使用者不必为主机IP地址的分配而烦恼 |
| dns.c | Domain Name System,可以通过主机名从DNS服务器处获得与该主机名对应的IP地址,使计算机使用者访问某主机时只需记住该主机名,而不用记住该主机的IP地址 |
| raw.c | 为应用层提供了一种直接与IP数据包交互的方式,与UDP、TCP处于同一等级,类似于Socket编程中原始套接字的概念 |
| .\src\api | 提供了Sequential API与BSD Socket API两种上层接口,这两种API实现原理都是通过引进邮箱和信号量等通信与同步机制,实现对内核中Raw/Callback API函数的封装与调用,要使用这两套API需要底层操作系统的支持 |
二、网络数据包管理
TCP/IP是一种数据通信机制,协议栈的实现本质上就是对数据包进行处理。例如,底层网络接口层判断收到的数据包类型,提取数据包中的数据字段,记录主机物理地址信息;IP层根据数据包中的IP地址实现数据的存储、转发,根据数据包编号实现数据包的重装,提取数据包中关于传输层的信息,向上层递交数据包并记录递交结果;TCP层使用数据包中的信息更新TCP状态机,并向应用程序递交数据等。上述所有过程都与数据包操作密切相关,因此,数据包管理是整个协议栈中很重要的部分。
在标准TCP/IP协议结构中,各层都被描述为一个独立的模块形式,每层负责完成一个独立的通信问题,因为每层协议相互独立,它们都可以被单独实现,只要保证它们之间的接口不变就可以了。但如果按照这种严格的分层模式来实现TCP/IP协议,会使数据包在各层间的递交变得非常慢,因涉及到一系列的内存拷贝问题,使系统总体性能受到影响。考虑到嵌入式系统资源受限的特点,LwIP内部并没有采用完整的分层结构,它会假设各层间的部分数据结构和实现原理在其他层可见,在数据包递交过程中,各层协议可以直接对数据包中属于其他层协议的字段进行操作,这就避免了数据包在各层间拷贝时的时间开销与内存开销。
下面展示下数据包在各层间传递时的封包与拆包过程:
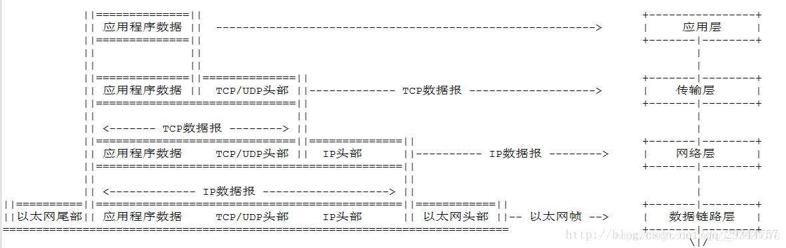
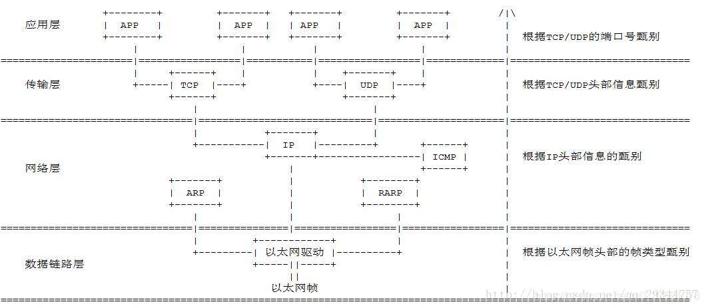
数据包传递到协议栈某层时,或添加或甄别该层的数据报头信息,应用程序数据及各层协议数据报头都是数据包的一部分。数据包就像协议栈的血液,在各层间存储并传输各种类型的数据。
2.1 数据包的描述
数据包管理机构采用数据结构pbuf来描述协议栈中使用的数据包,这个结构同BSD中的mbuf结构类似。在LwIP中,文件pbuf.h和pbuf.c实现了协议栈数据包管理相关的所有数据结构及函数,结构pbuf的定义如下:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\pbuf.h
struct pbuf {
/** next pbuf in singly linked pbuf chain */
struct pbuf *next;
/** pointer to the actual data in the buffer */
void *payload;
/**
* total length of this buffer and all next buffers in chain
* belonging to the same packet.
*
* For non-queue packet chains this is the invariant:
* p->tot_len == p->len + (p->next? p->next->tot_len: 0)
*/
u16_t tot_len;
/** length of this buffer */
u16_t len;
/** pbuf_type as u8_t instead of enum to save space */
u8_t /*pbuf_type*/ type;
/** misc flags */
u8_t flags;
/**
* the reference count always equals the number of pointers
* that refer to this pbuf. This can be pointers from an application,
* the stack itself, or pbuf->next pointers from a chain.
*/
u16_t ref;
};
typedef enum {
PBUF_RAM, /* pbuf data is stored in RAM */
PBUF_ROM, /* pbuf data is stored in ROM */
PBUF_REF, /* pbuf comes from the pbuf pool */
PBUF_POOL /* pbuf payload refers to RAM */
} pbuf_type;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
从上面的pbuf_type可以看出,pbuf有四种类型:PBUF_RAM、PBUF_POOL、PBUF_ROM与PBUF_REF,下面先看看四者的主要区别:
- PBUF_RAM类型:通过内存堆分配得到,该类型pbuf在协议栈中最常用,协议栈的待发送数据和应用程序的待发送数据一般都采用这种形式的pbuf;
- PBUF_POOL类型:通过内存池分配得到,该类型pbuf可以在极短时间内得到分配(内存池的优点),在网卡接收数据包时常使用这种方式包装数据;
- PBUF_ROM类型:在内存池中分配一个pbuf结构但不申请数据区空间,payload指向ROM空间内的某段数据,在发送某些静态数据时常采用该类型pbuf;
- PBUF_REF类型:在内存池中分配一个pbuf结构但不申请数据区空间,payload指向RAM空间内的某段数据,在发送某些静态数据时常采用该类型pbuf。
下面先看PBUF_RAM类型的pbuf结构图示:
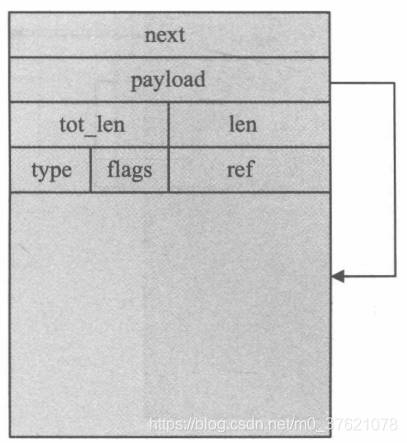
payload指针指向该pbuf所记录的数据区域,但从上图可以看出payload并不是直接指向整个数据区的起始处,而是间隔了一定区域,这段间隔的数据区域offset用来存储数据包的各种首部字段,比如TCP报文首部、IP首部、以太网帧首部等。源码中申请PBUF_RAM类型的pbuf代码如下:
p = (struct pbuf*)mem_malloc(LWIP_MEM_ALIGN_SIZE(SIZEOF_STRUCT_PBUF + offset) + LWIP_MEM_ALIGN_SIZE(length));
//调用内存堆分配函数,SIZEOF_STRUCT_PBUF为pbuf结构大小,offset为各首部字段大小,length为数据存储空间大小
- 1
- 2
接下来看PBUF_POOL类型的pbuf结构图示:
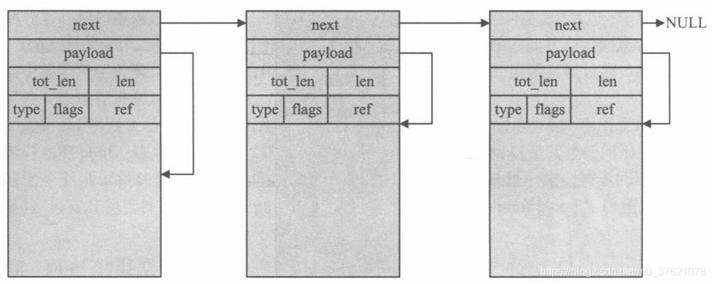
pbuf通过next构成单向链表,只有第一个pbuf的payload有一个offset用于保存各首部字段。前面说PBUF_POOL得益于内存池分配的优点,分配速度很快,主要是由于内存池每个存储单位都是固定长度且使用前已经过初始化,常用的内存池类型有两种:MEMP_PBUF与MEMP_PBUF_POOL,前者专门用来存放pbuf结构体(下面将要介绍的PBUF_ROM与PBUF_REF类型pbuf的分配便使用此类型),后者MEMP_PBUF_POOL的空间不仅包含了pbuf结构,还包含了LwIP认为协议栈中可能使用的最大TCP数据包空间(所有各层首部字段和 + 最大TCP数据段),默认长度为590字节(14 + 20 + 20 + 536),这个长度小于某些大的以太网数据包(比如大的ping包,长度可以达到MTU也即1500字节),此时可能需要多个MEMP_PBUF_POOL空间才能放得下这么大的数据包。源码中申请PBUF_POOL类型的pbuf代码如下:
p = memp_malloc(MEMP_PBUF_POOL); //调用内存池分配函数,分配MEMP_PBUF_POOL大小的空间
- 1
最后看PBUF_ROM与PBUF_REF类型的pbuf结构图示:
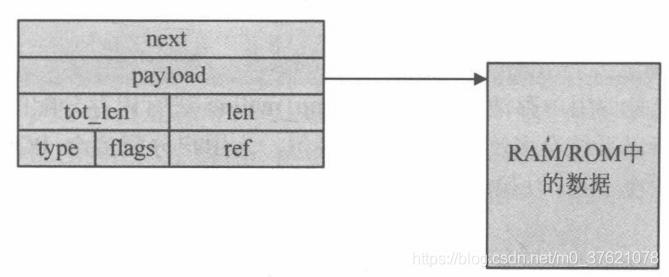
PBUF_ROM与PBUF_REF类型的pbuf基本相同,它们申请的都是内存池中一个MEMP_PBUF类型的POOL,而不申请数据区空间,二者的区别在于前者payload指向ROM空间内的某段数据,而后者指向RAM空间内的某段数据。源码中申请PBUF_ROM或PBUF_REF类型的pbuf代码如下:
p = memp_malloc(MEMP_PBUF); //调用内存池分配函数,分配MEMP_PBUF大小的空间
- 1
对于一个数据包,它可以使用上述任意的pbuf类型来描述,还可能一大串不同类型的pbuf连在一起,共同保存一个数据包的数据。
2.2 数据包的操作
前面描述了数据包pbuf的结构与类型,也简单介绍了数据包的分配,四种类型的数据包的分配都是通过调用内存堆或内存池分配函数实现的。一个数据包可能由多个pbuf链接而成,每个pbuf是一段连续的内存空间,对内存空间的操作最基础的就是分配和释放,下面先介绍数据包申请与释放函数。
struct pbuf *pbuf_alloc(pbuf_layer l, u16_t length, pbuf_type type); //pbuf分配函数
u8_t pbuf_free(struct pbuf *p); //pbuf释放函数
- 1
- 2
数据包分配函数有三个参数:pbuf_layer指定该pbuf数据所处的协议层级,分配函数根据该值在pbuf数据区预留出首部空间offset;length表示需要申请的数据区长度;pbuf_type指出需要申请的pbuf类型。其中pbuf_type一共有四种类型,前面已经介绍过了,下面介绍下pbuf_layer:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\pbuf.h
#define ETH_PAD_SIZE 0
#define PBUF_LINK_HLEN (14 + ETH_PAD_SIZE)
#define PBUF_TRANSPORT_HLEN 20 //TCP报文首部长度
#define PBUF_IP_HLEN 20 //IP数据报首部长度
typedef enum {
PBUF_TRANSPORT, //传输层,预留PBUF_LINK_HLEN + PBUF_IP_HLEN + PBUF_TRANSPORT_HLEN
PBUF_IP, //网络层,预留PBUF_LINK_HLEN + PBUF_IP_HLEN
PBUF_LINK, //链路层,预留PBUF_LINK_HLEN
PBUF_RAW //原始层,不预留任何空间
} pbuf_layer;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下面给出数据包申请函数的源码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\pbuf.c
struct pbuf *pbuf_alloc(pbuf_layer layer, u16_t length, pbuf_type type)
{
struct pbuf *p, *q, *r;
u16_t offset;
s32_t rem_len; /* remaining length */
/* determine header offset */
switch (layer) {
case PBUF_TRANSPORT:
/* add room for transport (often TCP) layer header */
offset = PBUF_LINK_HLEN + PBUF_IP_HLEN + PBUF_TRANSPORT_HLEN;
break;
case PBUF_IP:
/* add room for IP layer header */
offset = PBUF_LINK_HLEN + PBUF_IP_HLEN;
break;
case PBUF_LINK:
/* add room for link layer header */
offset = PBUF_LINK_HLEN;
break;
case PBUF_RAW:
offset = 0;
break;
default:
return NULL;
}
switch (type) {
case PBUF_POOL:
/* allocate head of pbuf chain into p */
p = (struct pbuf *)memp_malloc(MEMP_PBUF_POOL);
if (p == NULL) {
PBUF_POOL_IS_EMPTY();
return NULL;
}
p->type = type;
p->next = NULL;
/* make the payload pointer point 'offset' bytes into pbuf data memory */
p->payload = LWIP_MEM_ALIGN((void *)((u8_t *)p + (SIZEOF_STRUCT_PBUF + offset)));
/* the total length of the pbuf chain is the requested size */
p->tot_len = length;
/* set the length of the first pbuf in the chain */
p->len = LWIP_MIN(length, PBUF_POOL_BUFSIZE_ALIGNED - LWIP_MEM_ALIGN_SIZE(offset));
/* set reference count (needed here in case we fail) */
p->ref = 1;
/* now allocate the tail of the pbuf chain */
/* remember first pbuf for linkage in next iteration */
r = p;
/* remaining length to be allocated */
rem_len = length - p->len;
/* any remaining pbufs to be allocated? */
while (rem_len > 0) {
q = (struct pbuf *)memp_malloc(MEMP_PBUF_POOL);
if (q == NULL) {
PBUF_POOL_IS_EMPTY();
/* free chain so far allocated */
pbuf_free(p);
/* bail out unsuccesfully */
return NULL;
}
q->type = type;
q->flags = 0;
q->next = NULL;
/* make previous pbuf point to this pbuf */
r->next = q;
/* set total length of this pbuf and next in chain */
q->tot_len = (u16_t)rem_len;
/* this pbuf length is pool size, unless smaller sized tail */
q->len = LWIP_MIN((u16_t)rem_len, PBUF_POOL_BUFSIZE_ALIGNED);
q->payload = (void *)((u8_t *)q + SIZEOF_STRUCT_PBUF);
q->ref = 1;
/* calculate remaining length to be allocated */
rem_len -= q->len;
/* remember this pbuf for linkage in next iteration */
r = q;
}
/* end of chain */
/*r->next = NULL;*/
break;
case PBUF_RAM:
/* If pbuf is to be allocated in RAM, allocate memory for it. */
p = (struct pbuf*)mem_malloc(LWIP_MEM_ALIGN_SIZE(SIZEOF_STRUCT_PBUF + offset) + LWIP_MEM_ALIGN_SIZE(length));
if (p == NULL) {
return NULL;
}
/* Set up internal structure of the pbuf. */
p->payload = LWIP_MEM_ALIGN((void *)((u8_t *)p + SIZEOF_STRUCT_PBUF + offset));
p->len = p->tot_len = length;
p->next = NULL;
p->type = type;
break;
/* pbuf references existing (non-volatile static constant) ROM payload? */
case PBUF_ROM:
/* pbuf references existing (externally allocated) RAM payload? */
case PBUF_REF:
/* only allocate memory for the pbuf structure */
p = (struct pbuf *)memp_malloc(MEMP_PBUF);
if (p == NULL) {
return NULL;
}
/* caller must set this field properly, afterwards */
p->payload = NULL;
p->len = p->tot_len = length;
p->next = NULL;
p->type = type;
break;
default:
return NULL;
}
/* set reference count */
p->ref = 1;
/* set flags */
p->flags = 0;
return p;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
数据包的申请还是比较复杂的,主要是需要考虑的情况比较多,逻辑倒没那么复杂,这里就不详细阐述了。数据包释放函数需要注意pbuf结构有一个成员变量ref,当pbuf被创建时ref初始值为1,代表被引用一次,每增加一次对该pbuf的引用则ref相应增加1;相应的每释放一次pbuf,则其ref值减1,只有当pbuf的ref值减为0时,该pbuf才被删除。数据包释放函数的源码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\pbuf.c
u8_t pbuf_free(struct pbuf *p)
{
u16_t type;
struct pbuf *q;
u8_t count;
if (p == NULL) {
return 0;
}
count = 0;
/* de-allocate all consecutive pbufs from the head of the chain that
* obtain a zero reference count after decrementing*/
while (p != NULL) {
u16_t ref;
SYS_ARCH_DECL_PROTECT(old_level);
/* Since decrementing ref cannot be guaranteed to be a single machine operation
* we must protect it. We put the new ref into a local variable to prevent
* further protection. */
SYS_ARCH_PROTECT(old_level);
/* decrease reference count (number of pointers to pbuf) */
ref = --(p->ref);
SYS_ARCH_UNPROTECT(old_level);
/* this pbuf is no longer referenced to? */
if (ref == 0) {
/* remember next pbuf in chain for next iteration */
q = p->next;
type = p->type;
/* is this a pbuf from the pool? */
if (type == PBUF_POOL) {
memp_free(MEMP_PBUF_POOL, p);
/* is this a ROM or RAM referencing pbuf? */
} else if (type == PBUF_ROM || type == PBUF_REF) {
memp_free(MEMP_PBUF, p);
/* type == PBUF_RAM */
} else {
mem_free(p);
}
count++;
/* proceed to next pbuf */
p = q;
/* p->ref > 0, this pbuf is still referenced to */
/* (and so the remaining pbufs in chain as well) */
} else {
/* stop walking through the chain */
p = NULL;
}
}
/* return number of de-allocated pbufs */
return count;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
其他比较重要的数据包操作函数如下:
| 操作函数 | 功能描述 |
|---|---|
| void pbuf_realloc(struct pbuf *p, u16_t size) | 在相应pbuf链表尾部释放一定的空间,将数据包pbuf 中的数据长度减少为size; |
| u8_t pbuf_header(struct pbuf *p, s16_t header_size) | 调整pbuf的payload指针(向前或向后移动header_size 字节),使payload指针指向数据区前特定协议层的 首部字段,为各层对数据包首部字段的操作提供方便; |
| void pbuf_ref(struct pbuf *p) | 增加该pbuf的引用计数 |
| u8_t pbuf_clen(struct pbuf *p) | 获取该数据包链表中pbuf的个数 |
| void pbuf_cat(struct pbuf *head, struct pbuf *tail) | 将tai指向的pbuf连接到head指向的pbuf后面,但不 增加tail所指向pbuf的引用计数; |
| void pbuf_chain(struct pbuf *head, struct pbuf *tail) | 将tai指向的pbuf链接到head指向的pbuf后面,并增加 tail所指向pbuf的引用计数; |
| struct pbuf *pbuf_dechain(struct pbuf *p) | 从pbuf链表中解除链表首节点的链接,返回剩余链表 首节点或NULL; |
| err_t pbuf_copy(struct pbuf *p_to, struct pbuf *p_from) | 将一个任何类型的pbuf_from中的数据拷贝到一个 PBUF_RAM类型的pbuf_to中; |
| err_t pbuf_take(struct pbuf *buf, const void *dataptr, u16_t len) | 将dataptr开始长度为len的数据拷贝到pbuf的数据区域 |
三、协议栈内存管理
3.1 动态内存池管理
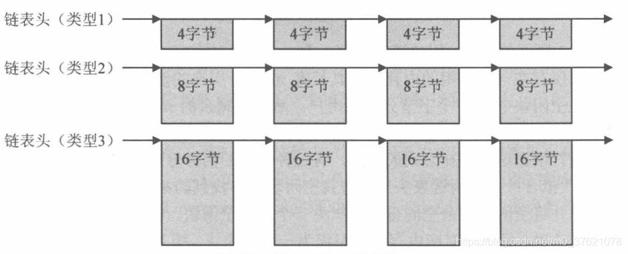
在之前介绍操作系统存储管理时谈到UCOS使用两级内存管理,分别是内存分区与内存块,每创建一个内存分区,都有特定数量相同大小的内存块构成链表供申请和释放。这是一种比较简单高效的内存管理方法,在LwIP中实现了类似的内存分配策略,称之为动态内存池分配,不过内存池在初始化时会将可能用到的不同类型的内存分区全部初始化。由于每种类型的内存块大小相同,分配释放时不需要查找,直接取出或插入链表首部即可,所以前面说这种方式分配内存所需的时间很短,效率也很高。该内存分配方式可以称为固定长度内存分配,内存块的链接关系如下图示:
3.1.1 动态内存池的描述
动态内存池POOL有多种类型,每种类型的单个POOL大小与POOL个数通常并不相同,因此要描述各种类型的POOL需要多个数据结构,在LwIP中与动态内存池管理相关的数据结构如下:
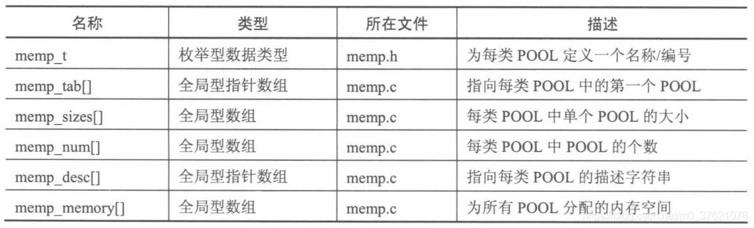
上表中的memp_t为系统定义一个枚举型数据类型,主要为系统将用到的各种类型的POOL取一个直观好记的名字,作为动态内存池函数申请空间的依据,下面先看下memp_t类型的定义:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\memp.h
/* Create the list of all memory pools managed by memp. MEMP_MAX represents a NULL pool at the end */
typedef enum {
#define LWIP_MEMPOOL(name,num,size,desc) MEMP_##name,
#include "lwip/memp_std.h"
MEMP_MAX
} memp_t;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
memp_t类型的定义比较难懂,这里简单解释下,#define宏定义告诉编译器遇到LWIP_MEMPOOL(name,num,size,desc)这个宏就把它用MEMP_##name代替,其中”##“在C语言中是连接符,用于连接两个Token。#include包含头文件"lwip/memp_std.h",结合上面的宏定义,就是把该头文件里的宏LWIP_MEMPOOL(name,num,size,desc)替换为MEMP_##name。MEMP_MAX并不表示任何类型的POOL,在这里表示memp_t枚举类型中元素的总个数。先看一下"lwip/memp_std.h"头文件的部分代码:
// rt-thread\components\net\lwip-1.4.1\src\include\lwip\memp_std.h
/*
* A list of internal pools used by LWIP.
*
* LWIP_MEMPOOL(pool_name, number_elements, element_size, pool_description)
* creates a pool name MEMP_pool_name. description is used in stats.c
*/
#if LWIP_RAW
LWIP_MEMPOOL(RAW_PCB, MEMP_NUM_RAW_PCB, sizeof(struct raw_pcb), "RAW_PCB")
#endif /* LWIP_RAW */
#if LWIP_UDP
LWIP_MEMPOOL(UDP_PCB, MEMP_NUM_UDP_PCB, sizeof(struct udp_pcb), "UDP_PCB")
#endif /* LWIP_UDP */
#if LWIP_TCP
LWIP_MEMPOOL(TCP_PCB, MEMP_NUM_TCP_PCB, sizeof(struct tcp_pcb), "TCP_PCB")
LWIP_MEMPOOL(TCP_PCB_LISTEN, MEMP_NUM_TCP_PCB_LISTEN, sizeof(struct tcp_pcb_listen), "TCP_PCB_LISTEN")
LWIP_MEMPOOL(TCP_SEG, MEMP_NUM_TCP_SEG, sizeof(struct tcp_seg), "TCP_SEG")
#endif /* LWIP_TCP */
#if IP_REASSEMBLY
LWIP_MEMPOOL(REASSDATA, MEMP_NUM_REASSDATA, sizeof(struct ip_reassdata), "REASSDATA")
#endif /* IP_REASSEMBLY */
#if IP_FRAG && !IP_FRAG_USES_STATIC_BUF && !LWIP_NETIF_TX_SINGLE_PBUF
LWIP_MEMPOOL(FRAG_PBUF, MEMP_NUM_FRAG_PBUF, sizeof(struct pbuf_custom_ref),"FRAG_PBUF")
#endif /* IP_FRAG && !IP_FRAG_USES_STATIC_BUF && !LWIP_NETIF_TX_SINGLE_PBUF */
#if LWIP_NETCONN
LWIP_MEMPOOL(NETBUF, MEMP_NUM_NETBUF, sizeof(struct netbuf), "NETBUF")
LWIP_MEMPOOL(NETCONN, MEMP_NUM_NETCONN, sizeof(struct netconn), "NETCONN")
#endif /* LWIP_NETCONN */
......
#undef LWIP_MEMPOOL
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
从上面的代码看,宏定义都是以条件编译方式定义的,也即编译时是否定义这个宏,看LwIP内核配置方式(在lwipopts.h与opt.h文件中)。下面按默认配置,假如系统配置了该条件编译选项,替换后的memp_t类型定义如下:
/* Create the list of all memory pools managed by memp. MEMP_MAX represents a NULL pool at the end */
typedef enum {
MEMP_RAW_PCB,
MEMP_UDP_PCB,
MEMP_TCP_PCB,
MEMP_TCP_PCB_LISTEN,
MEMP_TCP_SEG,
...
MEMP_MAX
} memp_t;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其余的几个数据结构的定义跟memp_t有点类似,由于"lwip/memp_std.h"头文件最开头并没有#ifndef、#define、#endif这类条件编译语句,所以该头文件是可以多次编译的,该头文件最后还有#undef语句撤销宏定义,以便后续重新定义该宏的功能。下面给出与动态内存池POOL管理相关的其余数据结构的定义如下:
// rt-thread\components\net\lwip-1.4.1\src\core\memp.c
/** This array holds the first free element of each pool.
* Elements form a linked list. */
struct memp {
struct memp *next;
};
static struct memp *memp_tab[MEMP_MAX];
/** This array holds the element sizes of each pool. */
const u16_t memp_sizes[MEMP_MAX] = {
#define LWIP_MEMPOOL(name,num,size,desc) LWIP_MEM_ALIGN_SIZE(size),
#include "lwip/memp_std.h"
};
/** This array holds the number of elements in each pool. */
static const u16_t memp_num[MEMP_MAX] = {
#define LWIP_MEMPOOL(name,num,size,desc) (num),
#include "lwip/memp_std.h"
};
/** This array holds a textual description of each pool. */
static const char *memp_desc[MEMP_MAX] = {
#define LWIP_MEMPOOL(name,num,size,desc) (desc),
#include "lwip/memp_std.h"
};
/** This is the actual memory used by the pools (all pools in one big block). */
static u8_t memp_memory[MEM_ALIGNMENT - 1
#define LWIP_MEMPOOL(name,num,size,desc) + ( (num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size) ) )
#include "lwip/memp_std.h"
];
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这几个数据结构定义的展开跟枚举类型memp_t的展开类似,这里就不一一展开了,前四个全局数组(*memp_tab[]、memp_sizes[]、memp_num[]、*memp_desc[])的索引都是枚举类型memp_t,根据枚举类型值查询相应类型POOL的链表头节点指针、单个POOL大小、该类型POOL个数、该类型POOL描述字符串等信息。最后的全局数组memp_memory[]则是为所有类型POOL分配的内存空间,其中宏MEMP_ALIGN_SIZE将size的值向上取整,MEMP_SIZE为每个POOL头不预留空间(LwIP默认设置其值为0),MEM_ALIGNMENT - 1也是考虑到系统内存对齐的问题。从这里可以看出,动态内存池POOL的分配跟UCOS内存管理有点类似,都是通过定义全局数组分配内存空间,而不使用堆Heap空间。
3.1.2 动态内存池的操作
与动态内存池管理相关的系统函数有三个:内存池初始化函数memp_init,在内核初始化时该函数必须被调用已完成内存池的建立;内存池分配函数memp_malloc通常被内核调用,以实现内核中固定长度数据结构空间的申请;内存池释放函数memp_free。内存池初始化函数代码与初始化后的空间分布如下:
// rt-thread\components\net\lwip-1.4.1\src\core\memp.c
/**
* Initialize this module.
*
* Carves out memp_memory into linked lists for each pool-type.
*/
void memp_init(void)
{
struct memp *memp;
u16_t i, j;
memp = (struct memp *)LWIP_MEM_ALIGN(memp_memory);
/* for every pool: */
for (i = 0; i < MEMP_MAX; ++i) {
memp_tab[i] = NULL;
/* create a linked list of memp elements */
for (j = 0; j < memp_num[i]; ++j) {
memp->next = memp_tab[i];
memp_tab[i] = memp;
memp = (struct memp *)(void *)((u8_t *)memp + MEMP_SIZE + memp_sizes[i]);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
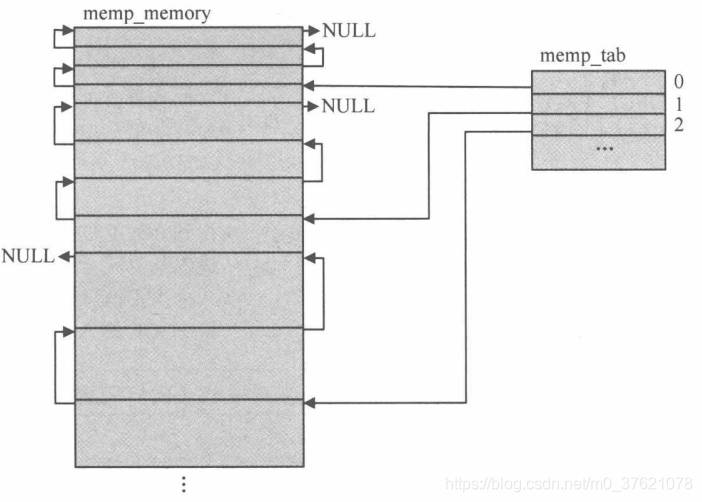
在系统初始化时,函数memp_init是必须被调用的,否则内存池空间将无效,当这个空间建立起来后,内存池空间的分配和释放就简单了,实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\memp.c
/**
* Get an element from a specific pool.
* @param type the pool to get an element from
* the debug version has two more parameters:
* @param file file name calling this function
* @param line number of line where this function is called
* @return a pointer to the allocated memory or a NULL pointer on error
*/
void *memp_malloc(memp_t type)
{
struct memp *memp;
SYS_ARCH_DECL_PROTECT(old_level);
SYS_ARCH_PROTECT(old_level);
memp = memp_tab[type];
if (memp != NULL) {
memp_tab[type] = memp->next;
MEMP_STATS_INC_USED(used, type);
memp = (struct memp*)(void *)((u8_t*)memp + MEMP_SIZE);
} else {
MEMP_STATS_INC(err, type);
}
SYS_ARCH_UNPROTECT(old_level);
return memp;
}
/**
* Put an element back into its pool.
* @param type the pool where to put mem
* @param mem the memp element to free
*/
void memp_free(memp_t type, void *mem)
{
struct memp *memp;
SYS_ARCH_DECL_PROTECT(old_level);
if (mem == NULL) {
return;
}
memp = (struct memp *)(void *)((u8_t*)mem - MEMP_SIZE);
SYS_ARCH_PROTECT(old_level);
MEMP_STATS_DEC(used, type);
memp->next = memp_tab[type];
memp_tab[type] = memp;
SYS_ARCH_UNPROTECT(old_level);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
使用内存池分配内存的优点在于速度快、效率高,不会产生内存碎片。但其缺点在于只能分配某个固定大小的内存空间,系统必须事先知道用户的需求,即用户需要些什么类型的POOL以及每种类型POOL的个数,然后依照这个需求为用户在内存池中事先建立起内存池空间。这种分配方式只要在内核固定数据结构空间分配时被使用,如果用户对内核结构有足够的了解,就能灵活配置各个POOL的数量,达到优化系统性能的目的。
3.2 动态内存堆管理
既然分配固定长度内存空间需要事先知道用户需求,很多时候我们并没法预见所需要的内存空间长度,比如用户待发送的数据长度,这时候就需要系统能分配可变长度内存空间。在使用标准C语言库时,经常见到malloc和free这两个内存管理函数,其内存分配的本质就是在事先准备好的一大块内存堆(可以理解为一个很大的数组)中分配合适的空间,然后将该空间起始地址返回给调用者,内核必须采用自己独有的一套数据结构来描述、记录哪些空间范围已经被分配(可以称为占用块)、哪些未用(可以称为空闲块)。
在LwIP中也实现了类似C语言库中malloc/free的内存分配策略,称之为动态内存堆分配。系统刚开始时,整个内存空间就是一个大的空闲块,随着内存分配和回收的进行,内存块的大小、数量也随着系统的运行而改变,某时刻内存中空闲块的链接关系如下:

若链表中存在多个空闲块,下次内存分配时选择哪个空闲块呢?常见的选择方式有如下三种:首次拟合(从空闲链表头开始查找空闲块,将找到的第一个长度符合要求的空闲块分配给用户,并将该空闲块剩余空间重新组织为一个小的空闲块插入到链表中)、最佳拟合(从空闲链表中查找长度与需求最接近的空闲块分配给用户,为避免每次遍历整个链表,系统将各空闲块按从小到大顺序组织起来)、最差拟合(从最大空闲块中划分需求长度的内存空间给用户,为避免每次遍历整个链表,系统将各空闲块按从大到小顺序组织起来)。一般来说,最佳拟合适用于用户请求大小范围较广的系统;最差拟合适用于用户请求大小范围较窄的系统;首次拟合则介于两者之间。最佳拟合与最差拟合需要维护空闲块大小的有序性,时间效率也会差一些,所以LwIP中实现的动态内存堆分配采用的是首次拟合方式。
3.2.1 动态内存堆的描述
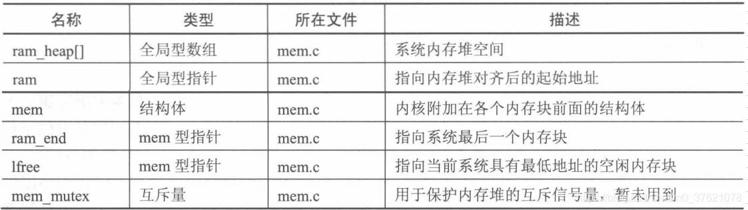
为了防止内存堆被不断细分为很小的内存块,用户申请的内存块大小具有最小限制,即请求的大小不能小于MIN_SIZE(通常被定义为12字节),否则系统自动将请求大小设置为MIN_SIZE。动态内存堆分配的优点是内存浪费小、比较简单、适用于小内存管理,缺点是如果频繁的动态分配和释放可能造成严重的内存碎片。由于内存堆分配需要查找链表,所以时间效率比动态内存池分配要低一些。在LwIP中与动态内存池管理相关的数据结构如下:
下面给出各数据类型的实现代码:
// rt-thread\components\net\lwip-1.4.1\src\core\mem.c
/** the heap. we need one struct mem at the end and some room for alignment */
u8_t ram_heap[MEM_SIZE_ALIGNED + (2*SIZEOF_STRUCT_MEM) + MEM_ALIGNMENT];
/**
* The heap is made up as a list of structs of this type.
* This does not have to be aligned since for getting its size,
* we only use the macro SIZEOF_STRUCT_MEM, which automatically alignes.
*/
struct mem {
/** index (-> ram[next]) of the next struct */
mem_size_t next;
/** index (-> ram[prev]) of the previous struct */
mem_size_t prev;
/** 1: this area is used; 0: this area is unused */
u8_t used;
};
/* MEM_SIZE would have to be aligned, but using 64000 here instead of
* 65535 leaves some room for alignment...
*/
#if MEM_SIZE > 64000L
typedef u32_t mem_size_t;
#define MEM_SIZE_F U32_F
#else
typedef u16_t mem_size_t;
#define MEM_SIZE_F U16_F
#endif /* MEM_SIZE > 64000 */
/** pointer to the heap (ram_heap): for alignment, ram is now a pointer instead of an array */
static u8_t *ram;
/** the last entry, always unused! */
static struct mem *ram_end;
/** pointer to the lowest free block, this is used for faster search */
static struct mem *lfree;
/** concurrent access protection */
#if !NO_SYS
static sys_mutex_t mem_mutex;
#endif
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
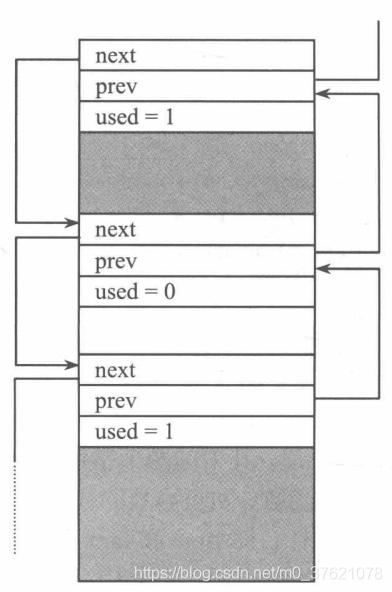
其中全局数组ram_heap[]与内存池中的memp_memory[]类似,内存堆的内存空间也是通过定义全局数组分配的,而不是在堆Heap中分配的。其中MEM_SIZE_ALIGNED是内存堆大小MEM_SIZE(在lwipopts.h中定义)进行内存对齐后的值,SIZEOF_STRUCT_MEM是结构体mem进行内存对齐后的大小,MEM_ALIGNMENT是为了后续的内存对齐而附加进去的字节。内存堆管理模块靠每个内存块顶部放置的一个结构体mem来保存内存块分配信息,该结构体由两个指针(将各内存块组织成双向链表,指针实际保存的是目的地址相对内存堆空间起始地址的偏移量)和一个标志(该内存块是否已被分配)构成。内存堆的组织结构如下图示:
3.2.2 动态内存堆的操作
与内存堆管理相关的函数主要有三个:内存堆初始化函数mem_init,在内核初始化时该函数必须被调用以完成内存堆的初始化;内存堆分配函数mem_malloc;内存堆释放函数mem_free。此外,还有个函数同内存堆的节点合并功能密切相关,即plug_holes。内存堆的初始化代码及初始化后的空间分布如下:
// rt-thread\components\net\lwip-1.4.1\src\core\mem.c
/**
* Zero the heap and initialize start, end and lowest-free
*/
void mem_init(void)
{
struct mem *mem;
/* align the heap */
ram = (u8_t *)LWIP_MEM_ALIGN(LWIP_RAM_HEAP_POINTER);
/* initialize the start of the heap */
mem = (struct mem *)(void *)ram;
mem->next = MEM_SIZE_ALIGNED;
mem->prev = 0;
mem->used = 0;
/* initialize the end of the heap */
ram_end = (struct mem *)(void *)&ram[MEM_SIZE_ALIGNED];
ram_end->used = 1;
ram_end->next = MEM_SIZE_ALIGNED;
ram_end->prev = MEM_SIZE_ALIGNED;
/* initialize the lowest-free pointer to the start of the heap */
lfree = (struct mem *)(void *)ram;
MEM_STATS_AVAIL(avail, MEM_SIZE_ALIGNED);
if(sys_mutex_new(&mem_mutex) != ERR_OK) {
LWIP_ASSERT("failed to create mem_mutex", 0);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
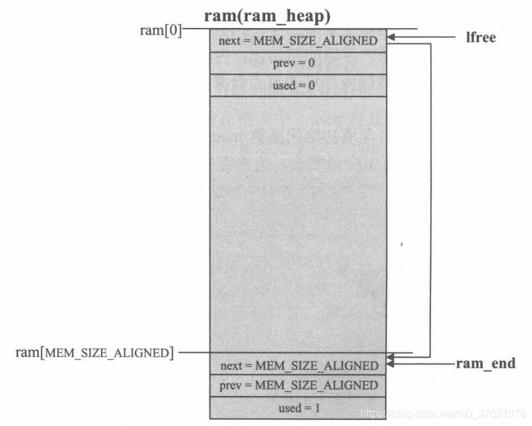
经过初始化后,整个内存堆区域划分为两个内存块:第一块包含了所有可用内存空间;第二块不包含任何可用内存空间,只有一个单独的mem结构体且被标记为已用,其中的两个指针next与prev也都指向自身,该内存块的作用主要在于方便内存分配与回收函数的代码编写。在内存堆初始化时,还初始化了两个指针lfree和ram_end,前者指向当前系统中地址最低的可用内存块,后者指向系统中最后一个内存块。
内存堆分配函数根据首次拟合的原则,根据用户所申请空间大小搜索所有未被使用的内存块,用于内存块管理的结构体mem是内存分配函数附加上去的,不包含在用户的申请大小内。内存堆是全局变量,内存的申请、释放操作都要做线程安全保护。内存堆分配函数的实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\mem.c
/**
* Adam's mem_malloc() plus solution for bug #17922
* Allocate a block of memory with a minimum of 'size' bytes.
* @param size is the minimum size of the requested block in bytes.
* @return pointer to allocated memory or NULL if no free memory was found.
* Note that the returned value will always be aligned (as defined by MEM_ALIGNMENT).
*/
void *mem_malloc(mem_size_t size)
{
mem_size_t ptr, ptr2;
struct mem *mem, *mem2;
LWIP_MEM_ALLOC_DECL_PROTECT();
if (size == 0) {
return NULL;
}
/* Expand the size of the allocated memory region so that we can
adjust for alignment. */
size = LWIP_MEM_ALIGN_SIZE(size);
if(size < MIN_SIZE_ALIGNED) {
/* every data block must be at least MIN_SIZE_ALIGNED long */
size = MIN_SIZE_ALIGNED;
}
if (size > MEM_SIZE_ALIGNED) {
return NULL;
}
/* protect the heap from concurrent access */
sys_mutex_lock(&mem_mutex);
LWIP_MEM_ALLOC_PROTECT();
/* Scan through the heap searching for a free block that is big enough,
* beginning with the lowest free block.*/
for (ptr = (mem_size_t)((u8_t *)lfree - ram); ptr < MEM_SIZE_ALIGNED - size;
ptr = ((struct mem *)(void *)&ram[ptr])->next) {
mem = (struct mem *)(void *)&ram[ptr];
if ((!mem->used) &&
(mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size) {
/* mem is not used and at least perfect fit is possible:
* mem->next - (ptr + SIZEOF_STRUCT_MEM) gives us the 'user data size' of mem */
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >= (size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED)) {
/* (in addition to the above, we test if another struct mem (SIZEOF_STRUCT_MEM) containing
* at least MIN_SIZE_ALIGNED of data also fits in the 'user data space' of 'mem')
* -> split large block, create empty remainder,
* remainder must be large enough to contain MIN_SIZE_ALIGNED data: if
* mem->next - (ptr + (2*SIZEOF_STRUCT_MEM)) == size,
* struct mem would fit in but no data between mem2 and mem2->next
* @todo we could leave out MIN_SIZE_ALIGNED. We would create an empty
* region that couldn't hold data, but when mem->next gets freed,
* the 2 regions would be combined, resulting in more free memory
*/
ptr2 = ptr + SIZEOF_STRUCT_MEM + size;
/* create mem2 struct */
mem2 = (struct mem *)(void *)&ram[ptr2];
mem2->used = 0;
mem2->next = mem->next;
mem2->prev = ptr;
/* and insert it between mem and mem->next */
mem->next = ptr2;
mem->used = 1;
if (mem2->next != MEM_SIZE_ALIGNED) {
((struct mem *)(void *)&ram[mem2->next])->prev = ptr2;
}
MEM_STATS_INC_USED(used, (size + SIZEOF_STRUCT_MEM));
} else {
/* (a mem2 struct does no fit into the user data space of mem and mem->next will always
* be used at this point: if not we have 2 unused structs in a row, plug_holes should have
* take care of this).
* -> near fit or excact fit: do not split, no mem2 creation
* also can't move mem->next directly behind mem, since mem->next
* will always be used at this point!
*/
mem->used = 1;
MEM_STATS_INC_USED(used, mem->next - (mem_size_t)((u8_t *)mem - ram));
}
if (mem == lfree) {
/* Find next free block after mem and update lowest free pointer */
while (lfree->used && lfree != ram_end) {
lfree = (struct mem *)(void *)&ram[lfree->next];
}
}
LWIP_MEM_ALLOC_UNPROTECT();
sys_mutex_unlock(&mem_mutex);
return (u8_t *)mem + SIZEOF_STRUCT_MEM;
}
}
MEM_STATS_INC(err);
LWIP_MEM_ALLOC_UNPROTECT();
sys_mutex_unlock(&mem_mutex);
return NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
在内存块释放时,内存堆管理模块根据用户提供的释放地址寻找到结构体mem,然后利用这个结构体来实现内存块的释放、合并等操作,内存块被回收后,其使用标志used清零。为防止内存碎片产生,上下相邻的内存块的使用标志都会被检查,如果任何一个还未被使用,则当前内存块将于它们进行合并操作。内存块释放与合并的实现代码如下:
// rt-thread\components\net\lwip-1.4.1\src\core\mem.c
/**
* Put a struct mem back on the heap
* @param rmem is the data portion of a struct mem as returned by a previous
* call to mem_malloc()
*/
void mem_free(void *rmem)
{
struct mem *mem;
LWIP_MEM_FREE_DECL_PROTECT();
if (rmem == NULL) {
return;
}
if ((u8_t *)rmem < (u8_t *)ram || (u8_t *)rmem >= (u8_t *)ram_end) {
SYS_ARCH_DECL_PROTECT(lev);
/* protect mem stats from concurrent access */
SYS_ARCH_PROTECT(lev);
MEM_STATS_INC(illegal);
SYS_ARCH_UNPROTECT(lev);
return;
}
/* protect the heap from concurrent access */
LWIP_MEM_FREE_PROTECT();
/* Get the corresponding struct mem ... */
mem = (struct mem *)(void *)((u8_t *)rmem - SIZEOF_STRUCT_MEM);
/* ... which has to be in a used state and is now unused. */
mem->used = 0;
if (mem < lfree) {
/* the newly freed struct is now the lowest */
lfree = mem;
}
MEM_STATS_DEC_USED(used, mem->next - (mem_size_t)(((u8_t *)mem - ram)));
/* finally, see if prev or next are free also */
plug_holes(mem);
LWIP_MEM_FREE_UNPROTECT();
}
/**
* "Plug holes" by combining adjacent empty struct mems.
* After this function is through, there should not exist
* one empty struct mem pointing to another empty struct mem.
* @param mem this points to a struct mem which just has been freed
* @internal this function is only called by mem_free() and mem_trim()
* This assumes access to the heap is protected by the calling function
* already.
*/
static void plug_holes(struct mem *mem)
{
struct mem *nmem;
struct mem *pmem;
/* plug hole forward */
nmem = (struct mem *)(void *)&ram[mem->next];
if (mem != nmem && nmem->used == 0 && (u8_t *)nmem != (u8_t *)ram_end) {
/* if mem->next is unused and not end of ram, combine mem and mem->next */
if (lfree == nmem) {
lfree = mem;
}
mem->next = nmem->next;
((struct mem *)(void *)&ram[nmem->next])->prev = (mem_size_t)((u8_t *)mem - ram);
}
/* plug hole backward */
pmem = (struct mem *)(void *)&ram[mem->prev];
if (pmem != mem && pmem->used == 0) {
/* if mem->prev is unused, combine mem and mem->prev */
if (lfree == mem) {
lfree = pmem;
}
pmem->next = mem->next;
((struct mem *)(void *)&ram[mem->next])->prev = (mem_size_t)((u8_t *)pmem - ram);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
内存堆管理还有两个操作函数,其功能描述如下:
| 操作函数 | 功能描述 |
|---|---|
| void *mem_calloc(mem_size_t count, mem_size_t size) | 用于申请指定大小(count*size)且初始值全为0的内存空间 |
| void *mem_trim(void *rmem, mem_size_t newsize) | 用于将一个内存区域重分配,该函数只能减少而不能增加 已分配区域的空间大小 |
评论记录:
回复评论: