
一、存储器寻址
我们使用C语言开发程序时经常涉及到存储空间的分配和释放,常用malloc/free两个函数完成相应的操作(C++语言则使用new/delete)。那么,我们分配和释放的到底是什么呢?有点计算机基础的应该知道,分配和释放的是运行内存(RAM:Random Access Memory)。计算机的主要作用是对输入数据进行处理和运算后输出,处理器主要完成数据的处理运算,但输入输出数据包括处理过程中的临时数据需要有一个空间去存放,这个临时存放数据供处理器和外设使用的地方就是内存,下面给出经典的冯诺依曼架构图:
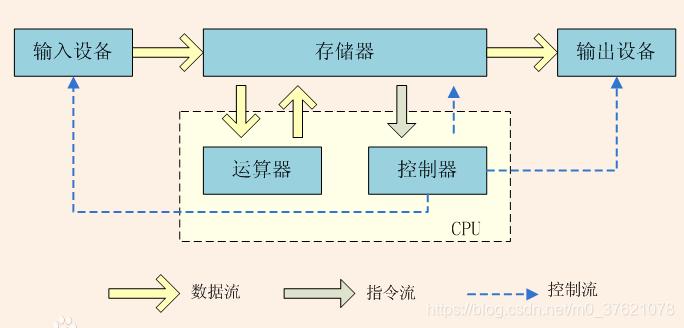
现在的计算机多采用哈弗架构,只是在冯诺依曼架构基础上进行了些改进,为了提高效率把存放程序(也即控制指令)和数据(也即操作数)的空间分开,同时把访问指令与访问数据的总线分开,使取指令和执行指令能够重叠(处理器的流水线)。
1.1 存储器分类
存储器又根据应用需求不同,被分成了两大类:RAM(Random Access Memory)与ROM(Read-Only Memory,可通过电压驱动读写操作),前者的特点是访问速度快,但数据断电就丢失,适合保存中间临时数据,后者的特点是访问速度慢,但数据断电后能长期保存,适合保存永久型数据。实际存储器类别分的更细,下面给出存储器的层次结构图供参考:
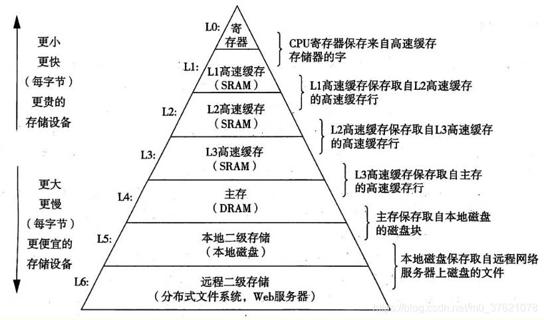
RAM又可分为两大类:一类是静态存储器SRAM,上面的寄存器和高速缓存SRAM都属于此类(主要位于处理器CPU或控制器MCU中),该类存储器主要由锁存器和触发器构成,基本单元是晶体管构成的门电路,访问速度快但成本较高;另一类是动态存储器DRAM,上面的主存DRAM属于此类(主要位于电脑或手机的内存中),该类存储器利用电容的电荷存储效应来存储数据,要定期刷新保证数据不丢失,速度慢但成本较低。
ROM最开始使用磁介质比如光盘/磁带等作为数据存储载体,但磁介质速度和存储密度满足不了特定使用场合的要求,所以身边以半导体电介质比如U盘/SSD固态硬盘等作为数据存储载体的设备越来越多。传统的电介质存储载体是EEPROM(Electrically Erasable Programmable Read-Only Memory),以字节为单位擦除数据,数据线与地址线分开,可以用地址线按字节随机寻址,但擦写速度慢且成本较高。
后来发展出了Flash EEPROM Memory,简称Flash,以块为单位(一般一个块为512字节)擦除数据,为了满足不同需求,又分出了两个类别:一类是NAND Flash(Not AND即与非),读写都是以块为单位,地址线与数据线复用,所以不支持地址线随机寻址,但擦写速度快、存储密度高且成本较低,我们常用的U盘/SSD固态硬盘等都属于此类;另一类是NOR Flash(Not OR即或非),读写都是以字节为单位,地址线与数据线分开,可以使用地址线按字节随机寻址,读取速度快但擦写速度较慢成本较高,跟EEPROM不同的是NOR按块擦除而EEPROM按字节擦除,因此NOR擦除速度比EEPROM更快,由于可以按字节随机寻址,保存在其中的程序可以直接执行,所以常用作程序存储器使用(大型系统因占用空间过大,所以一般只在程序存储器中保存引导启动代码,启动代码把系统代码载入内存后再执行)。
1.2 存储器寻址
一般像NAND Flash这种大容量的存储器由于不能通过地址线按字节进行随机寻址,所以并不直接与处理器通信,需要内存作为数据中转站间接与处理器进行数据交互,这类存储器由于距离处理器较远(不直接与处理器交互,由操作系统通过驱动程序间接管理),并不是操作系统内存管理的目标,所以本文主要介绍能通过地址线按字节进行随机寻址的存储器(比如程序存储器与数据存储器)。
处理器与内存之间有地址总线用于寻址,有数据总线用于传输数据,当然也有相应的控制线分辨读写操作,下面给出简单的关系图示如下:
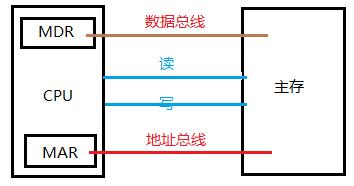
其中MDR(Memory Data Register)是主存数据寄存器,保存待处理的数据,MAR(Memory Address Register)是主存地址寄存器,用来保存源地址与目的地址,便于随机寻址。地址线用于从处理器经译码器到主存的寻址,信号是单向流动的;数据线用于处理器与主存间传输数据,数据需要双向流动,处理器与主存间还有读写控制线控制读写电路中的数据流向。
存储单元是以矩阵方式排列的,寻址时每个维度都有一个对应的地址译码器,就好比描述矩阵中的某一个元素,给定各个维度的编号就可以唯一确定该元素位置,所以一个存储单元的地址是由各个维度的编号组合而成的,下面给出一个二维存储单元的简单图示:
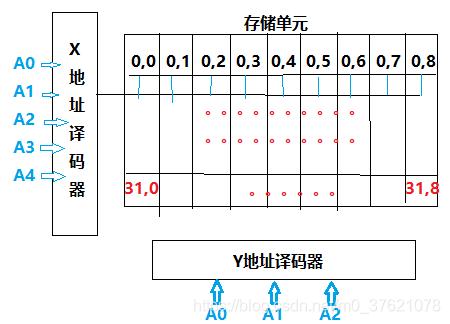
从上面的介绍可知,处理器对内存的访问主要包含三部分:要访问的存储单元的地址(保存在MAR寄存器中,由计算机汇编指令的操作数中指定)、要对该存储单元执行的访问类型(由程序指令指定,比如汇编语言中的操作码)、要与该存储单元交互的具体数据(保存在MDR寄存器中)。程序或指令的执行过程,主要也是处理器通过寻址从内存获取数据,经过运算处理后,再把结果放入内存相应地址的过程,所以操作系统对内存的管理,主要是通过对内存中地址或地址区间的管理实现的。
二、ARM内核存储器映射
在嵌入式领域ARM应用挺广泛,选择主要流行32位与64位,我们以相对简单的32位为例来介绍。既然对存储空间的访问受限于地址总线的位宽,所以32位处理器的最大寻址范围是4GB(2的32次方字节),下面以Cortex-M3为例给出其预定义的存储器映射图:
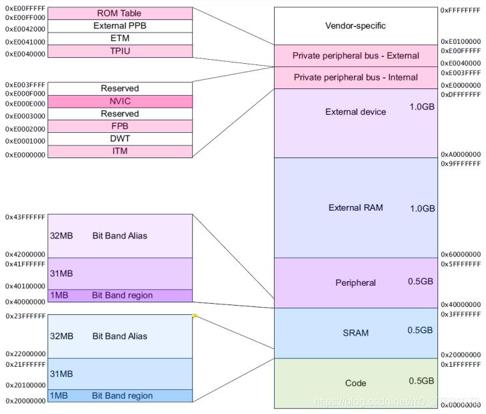
由上图可知,CM3对支持的4GB寻址空间的每个字节都进行了编号,每个字节都有一个独一无二的32位编号,对某个字节的操作只需要知道其所在的地址编号即可,当然也可以通过某一个连续地址段的起始编号和长度管理这一段连续的地址区间。
2.1 STM32存储器映射
上面CM3的存储器映射只是ARM预定义支持的,将4GB存储空间粗略分为六大块(Code/SRAM/Peripheral/External RAM/External Device/System Level),但在不同厂家生产的芯片中,对每块地址区间的利用率并不相同,比如CM3内核支持512MB的SRAM地址区间,但STM32可能只提供了其中的64KB,根据应用场景不同,可以选择不同大小存储空间的芯片型号,尽可能降低成本。下面先给出STM32的系统模块结构图,可以清晰了解CM3内核与STM32芯片之间的关系:
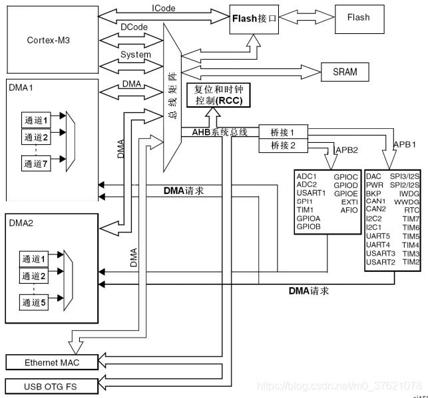
由上图可以看出,CM3只是处理器内核,跟内存和外设通过总线进行通信,总线主要分为指令总线、数据总线与系统总线,指令总线与数据总线共同负责对代码存储区的访问,系统总线用于访问内存和外设,上图中的Flash指的是NOR Flash或EEPROM程序存储器,SRAM指的就是我们上面所说的内存,连接在AHB总线上的外设对应Peripheral区间。下面给出STM32的内存映射图如下:
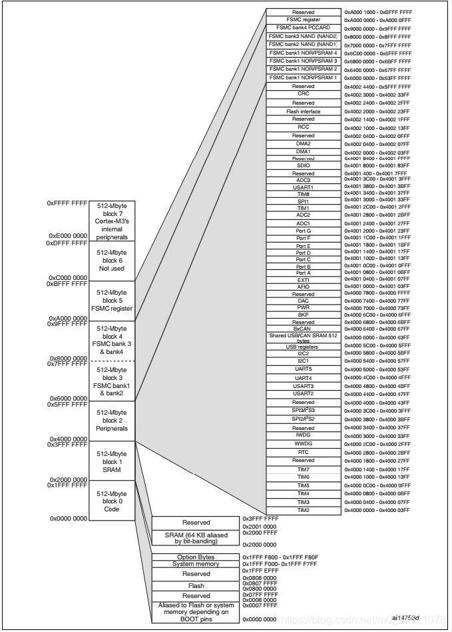
从上图可以看出,STM32上每个模块都映射到一段地址区间,方便处理器通过寻址访问该模块,比如对每个外设配置寄存器的访问,都是对其相应地址区间的读写访问。STM32除了片上支持的SRAM/Peripheral,还提供了可扩展性,主要通过FSMC(Flexible Static Memory Controller)对SRAM/Peripheral进行扩展,如果片上空间够用自然就不需要再扩展了。
下面给出STM32上主要的几个地址基点:
// Libraries\CMSIS\CM3\CoreSupport\core_cm3.h
/* Memory mapping of Cortex-M3 Hardware */
#define SCS_BASE (0xE000E000) /*!< System Control Space Base Address */
#define ITM_BASE (0xE0000000) /*!< ITM Base Address */
#define CoreDebug_BASE (0xE000EDF0) /*!< Core Debug Base Address */
#define SysTick_BASE (SCS_BASE + 0x0010) /*!< SysTick Base Address */
#define NVIC_BASE (SCS_BASE + 0x0100) /*!< NVIC Base Address */
#define SCB_BASE (SCS_BASE + 0x0D00) /*!< System Control Block Base Address */
/* Peripheral Memory mapping of STM32 Hardware */
#define FLASH_BASE ((uint32_t)0x08000000) /*!< FLASH base address in the alias region */
#define SRAM_BASE ((uint32_t)0x20000000) /*!< SRAM base address in the alias region */
#define PERIPH_BASE ((uint32_t)0x40000000) /*!< Peripheral base address in the alias region */
#define SRAM_BB_BASE ((uint32_t)0x22000000) /*!< SRAM base address in the bit-band region */
#define PERIPH_BB_BASE ((uint32_t)0x42000000) /*!< Peripheral base address in the bit-band region */
#define FSMC_R_BASE ((uint32_t)0xA0000000) /*!< FSMC registers base address */
/*!< Peripheral memory map */
#define APB1PERIPH_BASE PERIPH_BASE
#define APB2PERIPH_BASE (PERIPH_BASE + 0x10000)
#define AHBPERIPH_BASE (PERIPH_BASE + 0x20000)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
在前一篇文章介绍中断管理时谈到了NVIC、SCB、SYSTICK的相关寄存器配置,包括外设TIM、USART的配置,这些私有外设和片上外设寄存器对应的地址都是跟芯片相关的,想访问哪个寄存器就去访问其对应的地址编号,所以也不涉及内存的分配释放这类管理手段。除去私有外设与片上外设,比较重要的地址区间有两个:一个是Code区的Flash(程序存储器,存储程序代码,包括中断向量表)和System memory(存储系统引导启动BootLoader代码,一般单片机的代码量较少,Flash内能存放得下,所以不需要BootLoader代码,但对于占用空间较大的系统需要BootLoader),该区主要存储程序代码、初始化变量、中断向量表等跟系统启动运行相关的内容,处理器可以读取并执行,但运行期间不能写入或擦除,并不是操作系统存储管理的对象;另一个是SRAM区的SRAM地址区间(存储变量、堆栈等数据)是内存管理的主要对象,后面会针对SRAM地址区间详细讲解操作系统的内存管理。
2.2 STM32外设地址管理
前面谈中断管理时提到过私有外设与中断外设的配置,相关寄存器对应相应的地址,下面再以GPIO的配置为例,介绍下处理器是如何访问外设的,外设是如何在程序中被配置的。先看下GPIO对应的相关寄存器及其地址编号如下:
// Libraries\CMSIS\CM3\DeviceSupport\ST\STM32F10x\stm32f10x.h
#define PERIPH_BASE ((uint32_t)0x40000000) /*!< Peripheral base address in the alias region */
#define APB2PERIPH_BASE (PERIPH_BASE + 0x10000)
#define GPIOA_BASE (APB2PERIPH_BASE + 0x0800)
#define GPIOA ((GPIO_TypeDef *) GPIOA_BASE)
typedef struct
{
__IO uint32_t CRL;
__IO uint32_t CRH;
__IO uint32_t IDR;
__IO uint32_t ODR;
__IO uint32_t BSRR;
__IO uint32_t BRR;
__IO uint32_t LCKR;
} GPIO_TypeDef;
GPIOA->BSRR = 0x0001; //将PA.0引脚设置为输出高电平
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上面就可以直接通过结构体指针访问相关的寄存器,需要访问哪个寄存器就通过该结构体指针访问相应的成员变量,通过对该成员变量的读写访问实现对相应寄存器所在地址编号的读写访问。但这种位操作还是不够直观,ST官方也将其进一步封装了一些函数,使我们可以通过函数调用来操作寄存器,让程序开发更加直观方便。下面介绍进一步的封装方法:
// Libraries\STM32F10x_StdPeriph_Driver\inc\stm32f10x_gpio.h
#define GPIO_Pin_0 ((uint16_t)0x0001) /*!< Pin 0 selected */
#define GPIO_Pin_1 ((uint16_t)0x0002) /*!< Pin 1 selected */
#define GPIO_Pin_2 ((uint16_t)0x0004) /*!< Pin 2 selected */
#define GPIO_Pin_3 ((uint16_t)0x0008) /*!< Pin 3 selected */
#define GPIO_Pin_4 ((uint16_t)0x0010) /*!< Pin 4 selected */
#define GPIO_Pin_5 ((uint16_t)0x0020) /*!< Pin 5 selected */
#define GPIO_Pin_6 ((uint16_t)0x0040) /*!< Pin 6 selected */
#define GPIO_Pin_7 ((uint16_t)0x0080) /*!< Pin 7 selected */
#define GPIO_Pin_8 ((uint16_t)0x0100) /*!< Pin 8 selected */
#define GPIO_Pin_9 ((uint16_t)0x0200) /*!< Pin 9 selected */
#define GPIO_Pin_10 ((uint16_t)0x0400) /*!< Pin 10 selected */
#define GPIO_Pin_11 ((uint16_t)0x0800) /*!< Pin 11 selected */
#define GPIO_Pin_12 ((uint16_t)0x1000) /*!< Pin 12 selected */
#define GPIO_Pin_13 ((uint16_t)0x2000) /*!< Pin 13 selected */
#define GPIO_Pin_14 ((uint16_t)0x4000) /*!< Pin 14 selected */
#define GPIO_Pin_15 ((uint16_t)0x8000) /*!< Pin 15 selected */
#define GPIO_Pin_All ((uint16_t)0xFFFF) /*!< All pins selected */
#define IS_GPIO_PIN(PIN) ((((PIN) & (uint16_t)0x00) == 0x00) && ((PIN) != (uint16_t)0x00))
#define IS_GET_GPIO_PIN(PIN) (((PIN) == GPIO_Pin_0) || \
((PIN) == GPIO_Pin_1) || \
((PIN) == GPIO_Pin_2) || \
((PIN) == GPIO_Pin_3) || \
((PIN) == GPIO_Pin_4) || \
((PIN) == GPIO_Pin_5) || \
((PIN) == GPIO_Pin_6) || \
((PIN) == GPIO_Pin_7) || \
((PIN) == GPIO_Pin_8) || \
((PIN) == GPIO_Pin_9) || \
((PIN) == GPIO_Pin_10) || \
((PIN) == GPIO_Pin_11) || \
((PIN) == GPIO_Pin_12) || \
((PIN) == GPIO_Pin_13) || \
((PIN) == GPIO_Pin_14) || \
((PIN) == GPIO_Pin_15))
void GPIO_SetBits(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin)
{
/* Check the parameters */
assert_param(IS_GPIO_ALL_PERIPH(GPIOx));
assert_param(IS_GPIO_PIN(GPIO_Pin));
GPIOx->BSRR = GPIO_Pin;
}
GPIO_SetBits(GPIOA,GPIO_Pin_0); //将PA.0引脚设置为输出高电平
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
虽然增加了一些宏定义和函数代码,但让我们开发程序时更直观高效,不容易出错且方便调试和代码移植,所以也是值得的。对更复杂的寄存器组的操作,也有对应的数据结构和操作函数,原理跟上面差不多,就不过多介绍了,下面简单列举下对GPIO寄存器组初始化的部分代码:
// Libraries\STM32F10x_StdPeriph_Driver\inc\stm32f10x_gpio.h
typedef enum
{
GPIO_Speed_10MHz = 1,
GPIO_Speed_2MHz,
GPIO_Speed_50MHz
}GPIOSpeed_TypeDef;
#define IS_GPIO_SPEED(SPEED) (((SPEED) == GPIO_Speed_10MHz) || ((SPEED) == GPIO_Speed_2MHz) || \
((SPEED) == GPIO_Speed_50MHz))
typedef enum
{ GPIO_Mode_AIN = 0x0,
GPIO_Mode_IN_FLOATING = 0x04,
GPIO_Mode_IPD = 0x28,
GPIO_Mode_IPU = 0x48,
GPIO_Mode_Out_OD = 0x14,
GPIO_Mode_Out_PP = 0x10,
GPIO_Mode_AF_OD = 0x1C,
GPIO_Mode_AF_PP = 0x18
}GPIOMode_TypeDef;
#define IS_GPIO_MODE(MODE) (((MODE) == GPIO_Mode_AIN) || ((MODE) == GPIO_Mode_IN_FLOATING) || \
((MODE) == GPIO_Mode_IPD) || ((MODE) == GPIO_Mode_IPU) || \
((MODE) == GPIO_Mode_Out_OD) || ((MODE) == GPIO_Mode_Out_PP) || \
((MODE) == GPIO_Mode_AF_OD) || ((MODE) == GPIO_Mode_AF_PP))
typedef struct
{
uint16_t GPIO_Pin; /*!< Specifies the GPIO pins to be configured.
This parameter can be any value of @ref GPIO_pins_define */
GPIOSpeed_TypeDef GPIO_Speed; /*!< Specifies the speed for the selected pins.
This parameter can be a value of @ref GPIOSpeed_TypeDef */
GPIOMode_TypeDef GPIO_Mode; /*!< Specifies the operating mode for the selected pins.
This parameter can be a value of @ref GPIOMode_TypeDef */
}GPIO_InitTypeDef;
void GPIO_DeInit(GPIO_TypeDef* GPIOx);
void GPIO_AFIODeInit(void);
void GPIO_Init(GPIO_TypeDef* GPIOx, GPIO_InitTypeDef* GPIO_InitStruct);
void GPIO_StructInit(GPIO_InitTypeDef* GPIO_InitStruct);
uint8_t GPIO_ReadInputDataBit(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
uint16_t GPIO_ReadInputData(GPIO_TypeDef* GPIOx);
uint8_t GPIO_ReadOutputDataBit(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
uint16_t GPIO_ReadOutputData(GPIO_TypeDef* GPIOx);
void GPIO_SetBits(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
void GPIO_ResetBits(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
void GPIO_WriteBit(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin, BitAction BitVal);
void GPIO_Write(GPIO_TypeDef* GPIOx, uint16_t PortVal);
void GPIO_PinLockConfig(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
void GPIO_EventOutputConfig(uint8_t GPIO_PortSource, uint8_t GPIO_PinSource);
void GPIO_EventOutputCmd(FunctionalState NewState);
void GPIO_PinRemapConfig(uint32_t GPIO_Remap, FunctionalState NewState);
void GPIO_EXTILineConfig(uint8_t GPIO_PortSource, uint8_t GPIO_PinSource);
void GPIO_ETH_MediaInterfaceConfig(uint32_t GPIO_ETH_MediaInterface);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
我们只需要初始化相关的结构体变量,并把相应的结构体指针作为参数传入想要执行的操作函数,在操作函数内就会对相应的寄存器地址进行读写操作,完成对应外设的配置和访问。
三、UCOS物理内存管理
3.1 SRAM段内存地址划分
前面已经介绍了私有外设与片上外设甚至扩展外设的相关寄存器都有固定的地址区间,Code程序段是只读可执行的,保存执行代码和全局变量,下面重点介绍下SRAM内存段的地址空间划分,可以先参考下面的图示:
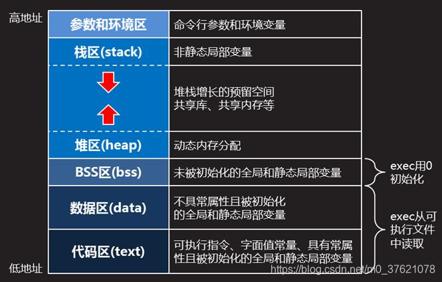
上图低地址的代码区在STM32中位于Code段Flash分区,并不是位于SRAM地址区间的。但对于大型系统如Linux,为了节约成本系统保存在了NAND Flash中(而非NOR Flash或EEPROM中),并不能从该存储区间直接执行(NAND Flash无法通过地址线按字节随机寻址),需要通过系统引导启动程序BootLoader先将系统代码从NAND Flash读入到内存中才能开始执行系统代码,对于这种情况,内存中就有一个代码区用来存放系统代码和中断向量表等信息了。
STM32程序启动后会有初始化堆栈的过程,把Code区Flash段保存的data数据区(在MDK中也叫RW_data区,全称ReadWrite data)与BSS区(Block Started by Symbol,在MDK中也叫ZI_data数据区,全称ZeroInitialie data)的内容初始化后放到SRAM区间起始地址处。
SRAM段各个区间的作用在上图已经清楚介绍了,其中栈区Stack主要保存非静态局部变量、函数参数或参数指针等数据,由SP指针管理,一般情况下不需要我们特别操心;堆区Heap是用于程序运行时进行动态内存分配和释放的区域,是内存管理的主要目标,C语言中的malloc/free函数分配和释放的内存都在Heap地址区间;数据区(data+BSS)主要保存我们开发程序时(程序运行前)分配的静态内存,比如静态变量与全局变量的初始化等。
额外介绍一点,Stack内存自高向低生长,Heap内存自低向高生长,中间有一个共享内存映射区,Stack和Heap各由一个指针(一般是SP指针与BRK指针)管理顶部地址,对于Heap区可能会出现最上面申请的地址还在使用但下面的地址已经释放的情况。因为Heap区只有一个指针管理,所以只能指向堆顶地址,更低地址区间调用free并非真的释放了(但可以再用于其他的分配申请),使用过程中容易导致Heap区没法相应较大内存区间的申请。为了解决该问题,malloc对于较大内存块的申请(一般为128KB),不在Heap区间分配,转到堆栈中间的共享内存映射区分配大块内存,由于可以对共享内存映射区的内存块进行更精细的管理(可能由一个数据结构管理),该区的每块内存都可以单独申请和释放。共享内存映射区一般在大型系统比如Linux上会常用到,对于STM32这种空间较小的芯片,一般也涉及不到共享内存映射区的分配与释放,动态内存分配和释放只关心Heap堆区就可以了。
3.2 UCOS内存管理
在嵌入式设备中,持续的调用malloc()和free()容易产生内存碎片,长时间的运行最终会导致内存消耗殆尽。UCOS提供了一套内存管理机制,在系统初始化的时候就分配好内存空间,将所有可用的空间组织成链表,需要申请内存的时候直接从链表中申请,释放内存的时候直接将内存归还到空余内存链表中即可。使用这种方法不仅避免了内存碎片的产生,而且使得在常数时间内分配内存空间成为可能。
在UCOS系统初始化时已分配内存空间,这段内存空间自然在SRAM数据区,包括前面介绍的任务控制块、事件控制块、定时器控制块等都是以静态方式分配的内存空间,部分代码参考如下:
// Micrium\Software\uCOS-II\Source\ucos_ii.h
OS_EXT OS_TCB OSTCBTbl[OS_MAX_TASKS + OS_N_SYS_TASKS]; /* Table of TCBs */
OS_EXT OS_TCB *OSTCBFreeList; /* Pointer to list of free TCBs */
OS_EXT OS_TCB *OSTCBPrioTbl[OS_LOWEST_PRIO + 1u]; /* Table of pointers to created TCBs */
OS_EXT OS_PRIO OSRdyTbl[OS_RDY_TBL_SIZE]; /* Table of tasks which are ready to run */
OS_EXT OS_EVENT *OSEventFreeList; /* Pointer to list of free EVENT control blocks */
OS_EXT OS_EVENT OSEventTbl[OS_MAX_EVENTS];/* Table of EVENT control blocks */
OS_EXT OS_TMR OSTmrTbl[OS_TMR_CFG_MAX]; /* Table containing pool of timers */
OS_EXT OS_TMR *OSTmrFreeList; /* Pointer to free list of timers */
OS_EXT OS_STK OSTmrTaskStk[OS_TASK_TMR_STK_SIZE];
OS_EXT OS_TMR_WHEEL OSTmrWheelTbl[OS_TMR_CFG_WHEEL_SIZE];
OS_EXT OS_MEM *OSMemFreeList; /* Pointer to free list of memory partitions */
OS_EXT OS_MEM OSMemTbl[OS_MAX_MEM_PART];/* Storage for memory partition manager */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
上面这些都是UCOS中定义的全局变量,定义时没有进行显式初始化,所以应该位于数据区的ZI_data区间,在系统启动时执行OSInit()函数,会将这些全局变量进行初始化。UCOS中也有一个数据结构用来进行内存管理,具体结构如下:
// Micrium\Software\uCOS-II\Source\ucos_ii.h
typedef struct os_mem { /* MEMORY CONTROL BLOCK */
void *OSMemAddr; /* Pointer to beginning of memory partition */
void *OSMemFreeList; /* Pointer to list of free memory blocks */
INT32U OSMemBlkSize; /* Size (in bytes) of each block of memory */
INT32U OSMemNBlks; /* Total number of blocks in this partition */
INT32U OSMemNFree; /* Number of memory blocks remaining in this partition */
#if OS_MEM_NAME_EN > 0u
INT8U *OSMemName; /* Memory partition name */
#endif
} OS_MEM;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
就像一个任务控制块管理一个任务,一个内存控制块管理一个内存分区,全局数组OSMemTbl[OS_MAX_MEM_PART]定义了一个UCOS管理的总内存区间(其中内存分区个数OS_MAX_MEM_PART是可以根据需求设定的),数组中每个元素的地址也即内存控制块的首地址,由一个内存控制块来管理全局数组OSMemTbl中的一个元素(也即一个内存分区)。在UCOS初始化时,UCOS管理的OS_MAX_MEM_PART个任务控制块以单链表的形式组织起来并初始化,链表头节点的地址就是*OSMemFreeList指针指向的地址,空闲链表的组织关系如下所示:
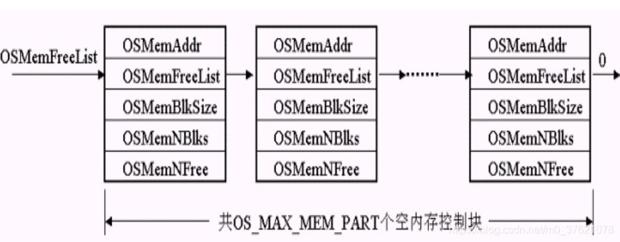
其中一个内存控制块管理的一个内存分区有OSMemNBlks个小的内存块,每个内存块大小为OSMemBlkSize个字节,*OSMemAddr指向这个内存分区的首地址,这些小的内存块在初始化一个内存分区时也被组织成一个单向链表了,表头指针为OS_MEM->OSMemFreeList,一个内存分区的管理结构如下:
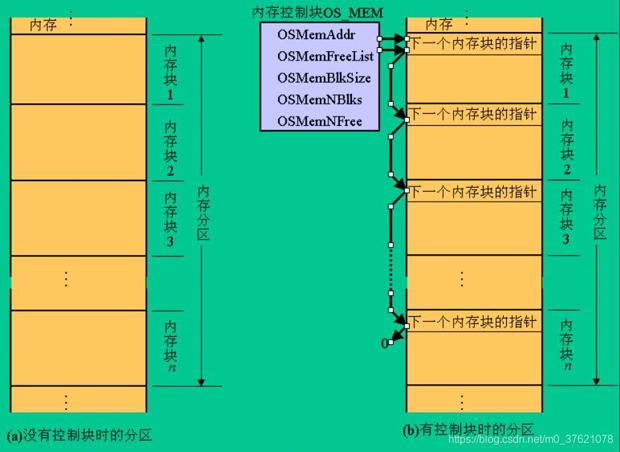
内存控制块又把一个内存分区更进一步划分为更小的内存块,初始化后的空闲内存分区被组织成一个单向链表,一个内存分区被初始化后的多个小内存块也被组织成了单向链表,所以UCOS对内存进行两级管理,有点类似于二维数组。内存控制块管理的一个内存分区中未被分配的空闲块都在以OSMemFreeList为头指针的链表内,每分配一个块,从空闲块链表中取出一个,每释放一个块则重新将其插入到空闲块链表中。
UCOS的内存管理实际上是对内存控制块的操纵,主要的操作函数如下表示:
| 操作函数 | 功能描述 |
|---|---|
| OS_MEM *OSMemCreate (void *addr, INT32U nblks, INT32U blksize, INT8U *perr) | 创建一个内存分区,即从空闲分区链表中获取一个内存控制块及一个内存分区,并初始化该内存控制块,将该内存分区划分为nblks个大小为blksize的内存块,并将这些内存块组织成一个空闲内存块链表,函数返回所创建内存分区的内存控制块地址; |
| void *OSMemGet (OS_MEM *pmem, INT8U *perr) | 从该内存分区获取一个内存块,若获取成功返回该内存块首地址,否则返回空指针; |
| INT8U OSMemPut (OS_MEM *pmem, void *pblk) | 向该内存分区释放一个内存块,并将该内存块插入到该内存分区对应的空闲内存块链表中; |
| INT8U OSMemQuery (OS_MEM *pmem, OS_MEM_DATA *p_mem_data) | 查询该内存控制块的信息,将该内存控制块的信息保存到p_mem_data中,其中OS_MEM_DATA是一个跟OS_MEM类似的结构体; |
| void OS_MemInit (void) | 初始化全局数组OSMemTbl[OS_MAX_MEM_PART]对应的所有内存分区,将这些内存分区组织成空闲内存分区链表,并将链表头地址赋值给全局指针变量OSMemFreeList; |
从UCOS内存分配可以看出,其内存管理还是比较简单粗糙的,把一整块内存区间用一个类似二维数组的两级链表进行管理,每个内存分区在创建时指定内存起始地址、内存块大小、内存块数量,相对有一定灵活性,对于内存空间非常有限的单片机系统来说,这种简单粗糙的内存管理方案倒也够用了。
四、内存保护MPU
从UCOS的内存管理方案可以看出,系统的可用内存区间都由一个全局数组分配,既然是全局变量,意味着UCOS上的所有任务都可以访问,虽然任务间通信主要靠访问共享内存区,但任务的部分私有数据还是不能被其他任务轻易访问到的,否则可能轻者造成数据泄露风险,重者导致该任务数据被篡改或破坏导致运算结果不正确甚至程序崩溃。所以我们需要对任务间的数据访问进行一些限制,以保护任务私有数据的安全性。
要保证不同任务间私有数据的安全,也即某任务所使用的内存区间不能轻易被其他的任务访问到,最简单的就是设置内存区间的访问权限。CM3提供了一个可选的存储器保护单元,配上它之后就可以对特权级访问和用户级访问施加不同的访问限制,MPU(Memory Protected Unit)在保护内存时是按区Region来管理内存的,它可以把某些内存区设置为只读,从而避免里面的内容意外被更改,还可以在多任务系统中把不同任务间的数据区隔离开(不同任务使用的内存区间可以配置不同的Region区域访问规则)。
MPU对内存区域进行分区管理,即分区设定访问权限和规则,图示如下:
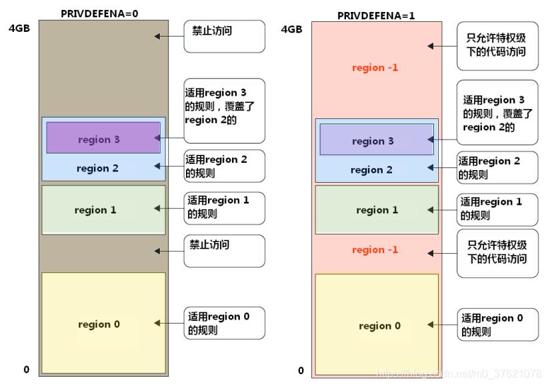
从上图可以看出,MPU是可以管理所有的4GB存储空间的,可以划分不同的Region内存区域,并为每个Region设置访问权限与规则,不同的Region允许相互重叠,重叠区域受多重访问规则的限制。上图中PRIVDEFENA是MPU控制寄存器MPUCR的一部分,置位表示特权级下打开背景Region,即为特权级打开缺省存储器映射,没有被其余Region覆盖到的内存区域只允许特权级下的代码访问。MPU其余相关的寄存器如下:
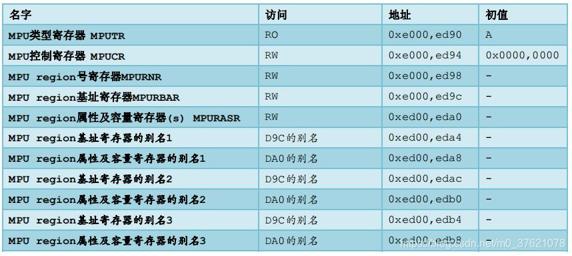
管理这些寄存器的数据结构及封装的操作函数如下:
// Libraries\CMSIS\CM3\CoreSupport\core_cm3.h
#define SCS_BASE (0xE000E000) /*!< System Control Space Base Address */
#define MPU_BASE (SCS_BASE + 0x0D90) /*!< Memory Protection Unit */
#define MPU ((MPU_Type*) MPU_BASE) /*!< Memory Protection Unit */
typedef struct
{
__I uint32_t TYPE; /*!< Offset: 0x00 MPU Type Register */
__IO uint32_t CTRL; /*!< Offset: 0x04 MPU Control Register */
__IO uint32_t RNR; /*!< Offset: 0x08 MPU Region RNRber Register */
__IO uint32_t RBAR; /*!< Offset: 0x0C MPU Region Base Address Register */
__IO uint32_t RASR; /*!< Offset: 0x10 MPU Region Attribute and Size Register */
__IO uint32_t RBAR_A1; /*!< Offset: 0x14 MPU Alias 1 Region Base Address Register */
__IO uint32_t RASR_A1; /*!< Offset: 0x18 MPU Alias 1 Region Attribute and Size Register */
__IO uint32_t RBAR_A2; /*!< Offset: 0x1C MPU Alias 2 Region Base Address Register */
__IO uint32_t RASR_A2; /*!< Offset: 0x20 MPU Alias 2 Region Attribute and Size Register */
__IO uint32_t RBAR_A3; /*!< Offset: 0x24 MPU Alias 3 Region Base Address Register */
__IO uint32_t RASR_A3; /*!< Offset: 0x28 MPU Alias 3 Region Attribute and Size Register */
} MPU_Type;
typedef struct
{
uint8_t Enable;
uint8_t Number;
uint32_t BaseAddress;
uint8_t Size;
uint8_t SubRegionDisable;
uint8_t TypeExtField;
uint8_t AccessPermission;
uint8_t DisableExec;
uint8_t IsShareable;
uint8_t IsCacheable;
uint8_t IsBufferable;
}MPU_Region_InitTypeDef;
void HAL_MPU_Disable(void);
void HAL_MPU_ConfigRegion(MPU_Region_InitTypeDef *MPU_Init);
void HAL_MPU_Enable(uint32_t MPU_Control);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
有了每个寄存器的对应地址,可以直接操作对应的寄存器,也可以使用更上层封装的结构体MPU_Region_InitTypeDef来配置相应的规则,最后通过调用ST提供的操作函数完成MPU的配置和使能。
五、虚拟内存管理
5.1 什么是虚拟内存
对于STM32这类存储空间有限的单片机平台使用类似UCOS这类实时操作系统提供的内存管理方案倒也够用了,使用MPU也能达到隔离内核与应用之间、不用任务之间数据区的目的,提高系统程序的可靠性与安全性。但对于像Linux这类复杂的操作系统,如果还使用这种简单的内存管理方案,很显然就不够用了,特别是剩余内存空间不足将无法运行新的任务。那么,Linux这类大型操作系统使用什么存储管理方案呢?
回想下前面介绍的多任务并行机制实现原理,把任务的调度交给任务调度器来管理,相当于在应用程序与底层硬件之间增加了一个任务调度层,使我们编写任务代码时不需要关心任务的调度,完全交给任务调度器自行处理,这也是操作系统的核心。类似的,我们能不能也在应用程序与物理内存之间增加一个中间管理层,用来管理物理内存地址的使用呢?中间管理层应该能屏蔽实际物理存储空间大小,使我们开发应用程序时,不用考虑所要使用的内存起始地址和实际可用的物理存储空间大小,向开发者抽象出一个统一的内存模型接口,这就能在很大程度上提高应用程序在不同实际内存大小的平台上运行的兼容性,且简化了应用程序的开发难度。
以经典操作系统Linux为例,这个用于管理物理存储空间的中间层是存在的,它向应用程序开发者提供统一的内存模型接口,就像前面介绍的ARM内核支持的存储器映射模型,实际可用的存储空间肯定是ARM支持存储空间的子集(实际更大的存储空间因超出ARM寻址范围而变得不可用),因这个统一的内存模型接口是抽象出来的,所以我们称这个抽象出来的内存地址为虚拟地址,这个中间管理层的任务就是把抽象的虚拟地址转换为实际存储器上的物理地址,并且尽可能降低因抽象导致的性能损失。
5.2 虚拟内存管理
虚拟地址到物理地址的转换需要硬件和软件同时提供支持,硬件指的是MMU内存管理单元,软件指的是页表管理相关的代码(Intel为了兼容旧程序,还引入了段式管理,由GDT全局段描述符表和LDT局部段描述符表,将内存空间分段管理,但因段式管理需要两次地址转换而降低了效率,Linux并未使用段式管理,且ARM并没有提供段寄存器,所以这里不再介绍段式管理)。下面先介绍硬件MMU的作用,其在处理器中的位置如下图所示:
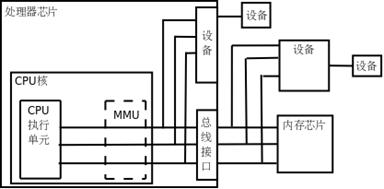
MMU是在处理器与内存或外设中间的一个模块,主要负责将指令中的虚拟地址转换为物理地址,再通过地址线到内存或外设中进行物理寻址,这个地址转换过程是靠MMU查询页表完成的,地址转换工作由硬件自动完成,但页表要由操作系统维护管理,也即在操作系统初始化、分配、释放内存时,都要及时更新维护页表,并把页表在物理内存中的位置告诉MMU,方便MMU的查表和地址转换工作正常进行。
前面介绍的ARM CM3内核并没有MMU模块,所以该处理器内核是不支持虚拟内存管理的,在更高级的ARM芯片比如A系列内核有MMU模块,可以支持虚拟内存管理。在ARM处理器平台上,MMU保存页表地址的寄存器为TTB(Translation Table Base),同时MMU内还有一个TLB(Translation Lookaside Buffers),保存最近用到的虚拟地址对应的物理地址,CPU指令中的虚拟地址传入MMU后,现在TLB中查询对应的物理地址,如果查不到则利用TTB到内存的页表中去查询对应的物理地址,TLB提高了地址转换的效率(寄存器或高速缓存的访问速度远高于内存)。
为了提高效率,页表的查询应尽量高效,目前的数据结构中可在常数时间查询到某元素的主要是数组和Hash映射,页表使用了数组结构来组织表项,而且为了提高效率,常采用多级页表,结构如下图示:
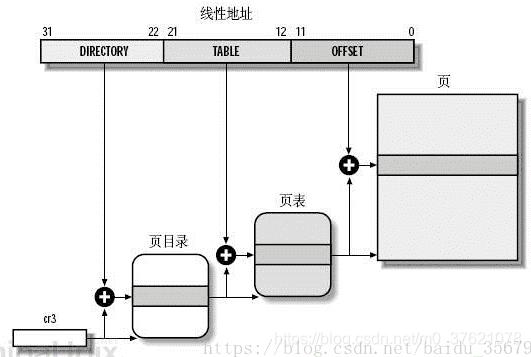
上面是两级页表,32位的虚拟地址(也叫线性地址,寻址范围4GB)由页目录、页表、页内偏移量三部分构成,页目录首地址存放在寄存器CR3内(x86平台MMU中保存页目录地址的寄存器,类似于ARM平台下的TTB寄存器),页目录共有2^10 = 1024个页表项,根据虚拟地址高10位查询到页目录中对应的页表项地址,再根据虚拟地址中间10位(同样1024个页项)查询到页表中对应的页地址,最后根据虚拟地址低12位(4096个地址)查询到对应的物理地址,完成从虚拟地址到物理地址的转换。
Linux为了保持移植性,将地址分成了五段,相当于四级页表,比上面复杂,但原理类似。Linux每个进程都有一个页目录,哪个进程运行时就将该进程对应的页目录地址存入MMU的TTB寄存器内,便于地址的转换。
由于不同进程的页目录不同,所以不同进程的虚拟地址是可以相同的,也即每个进程的虚拟地址都可以从零开始,利用整个4GB寻址空间(本文只介绍32位寻址平台,64位平台寻址空间肯定大得多,下面如无特殊说明都指的是32位寻址空间),就好像所有存储空间都由该进程独占一样。这就达到了我们上面说的,中间存储地址管理层面向开发者提供统一的内存映射模型,每个进程的虚拟地址区间都一样,程序开发者也就不用过多考虑实际存储空间的问题。这种方案同时也把不同进程的存储空间分隔开了,能有效保护内核与进程间的安全,防止内核或其他进程数据被别的进程意外更改。
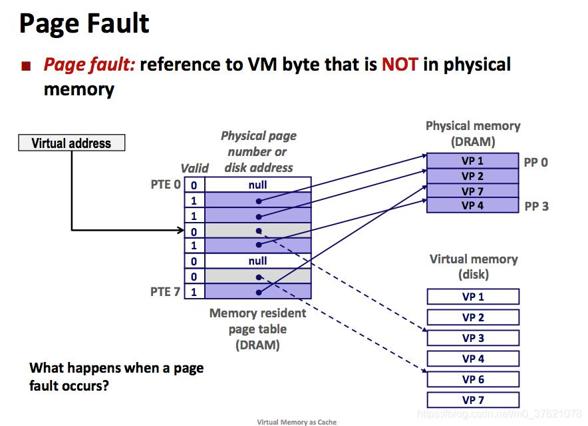
虽然每个进程都有4GB虚拟内存空间可用,但实际物理内存可能连4GB都不到,内存不够用怎么办呢?这是虚拟内存带来的另外一个好处,可以只把常用的数据放入内存,把不常有的数据放入硬盘,相当于扩展了内存空间。物理内存寻址时,要想运行程序,该程序的所有运行数据都是要放到内存中的,如果由于空间不够放不下,将导致该程序无法运行。但在虚拟内存寻址时,只把页目录表放到内存中,可以把要用的数据放到内存,而把暂时不用的数据放到硬盘上,等需要访问的数据不在内存中时会触发一个缺页异常,把需要的数据从硬盘中读入到内存中(硬盘读写速度较慢,在此期间可以先去执行其他任务,待数据读写完毕会以中断的形式通知系统继续执行),如果内存空间不足,则把内存中暂时不用的数据放入硬盘以释放内存空间供其它进程使用,这种借助硬盘扩展内存空间,大大提高内存使用效率的机制也是虚拟内存管理如此流行的一个重要原因。
虚拟地址查询页目录,如果在内存中查询不到,会触发一个页异常,在异常处理函数中将需要的页从硬盘中拷贝到内存中,如果内存上没有可用空间,则将一个暂时不用的页放入硬盘,整个过程如下图示:
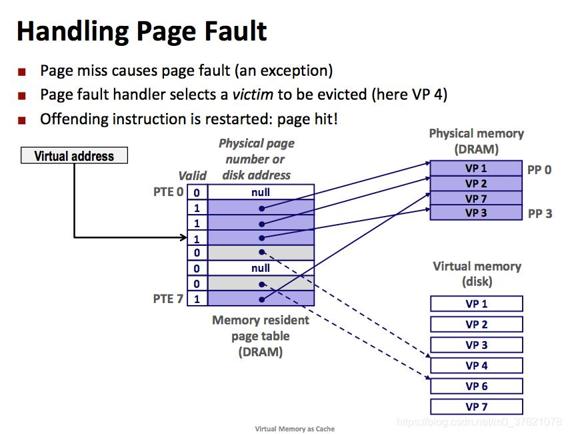
当然为了提高内存使用效率,不同进程可能会访问一些共同的数据,比如一些函数库,所以不同进程的虚拟地址有可能会访问到同一个物理地址,这个物理地址所在的页也叫共享页面。
5.3 Linux内存管理概览
虚拟内存与物理内存之间的映射关系也不是完全随意的,类似上面的ARM存储器映射结构,这里的虚拟内存与物理内存也是分区段的,大概的映射关系如下图示:
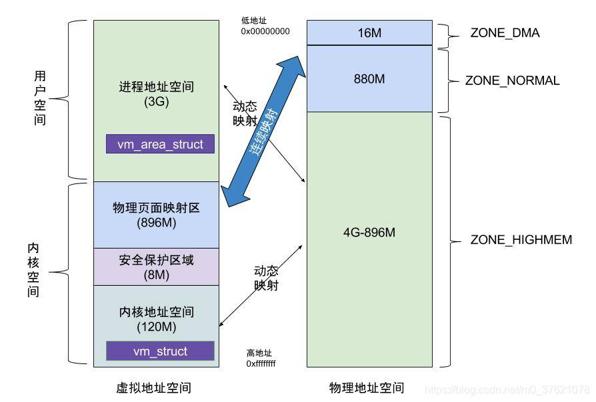
从上图看,物理地址空间中除了896M(ZONE_DMA + ZONE_NORMAL)的区域是绝对的物理连续,vm_struct是连续的虚拟内核空间,对应的物理页面可以不连续,地址范围(3G + 896M + 8M) ~ 4G;另外在虚拟用户空间中 vm_area_struct同样也是一块连续的虚拟进程空间,对应的物理页面同样可以不连续,地址空间范围0~3G。
下面以Linux为例,看看虚拟内存管理在整个操作系统管理中涉及到的数据结构及操作函数:
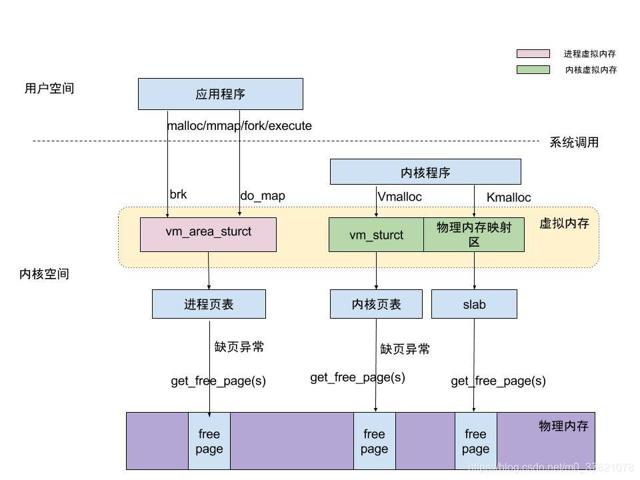
从上图可以看出,内核空间主要由vm_struct结构体管理内核页表,进程空间主要由vm_area_struct结构体管理进程页表。内核空间的分配主要由Kmalloc与Vmalloc两个操作函数完成,区别是前者分配的物理地址是连续的(物理内存映射区,比如硬件设备需要得到物理地址连续的内存),后者分配的虚拟地址是连续的但物理地址不一定连续。进程空间的分配,主要是调用系统API函数brk与do_map完成的,区别是前者分配小内存区间(一般小于128KB)在堆Heap上进行,后者分配大内存区间(一般大于128KB)在共享内存映射区(堆Heap与栈Stack之间)进行,这个在前面介绍过。
上图中除了进程页表和内核页表,还有一个Slab层,这个Slab层也可以申请物理页框,为什么又引入了一个Slab层呢?前面介绍的页表管理,在进行内存分配释放时都是以页为单位进行的,但是一个页面4KB,颗粒度比较大,如果我们需要3B的数据也分配一个页面显然太浪费了些,Linux就引入了一个Slab层用于管理小内存块的分配。Slab申请到大的物理页框(一个物理页框对应一个虚拟页面,大小也是4KB)后,将其分割为多个对象,使用类似UCOS内存管理中的空闲链表(一个Slab相当于一个UCOS中内存分区,一个对象相当于UCOS中一个内存块,不同的Slab可以有不同大小和个数的对象),将多个对象组织起来,分配时从空闲链表获取对象,释放时又归还给空闲链表。当对象拥有者释放一个对象后,Slab仅仅标记对象为空闲,当又有申请者申请相应大小的对象时,Slab会优先分配最近释放的对象,这样这个对象甚至有可能还在硬件高速缓存中,有点类似CPU高速缓存的做法,提高了系统的效率,从这个角度看,Slab也充当了高速缓存器的角色。
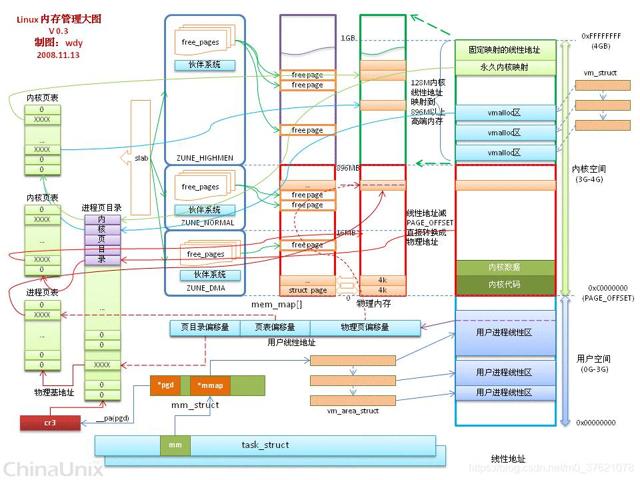
下面再给出Linux系统下进程虚拟地址(也即线性地址)转换为物理地址的过程图供参考(下图中的伙伴系统与Slab分配器都是用于解决内存碎片问题的):
评论记录:
回复评论: