
window滑动窗口
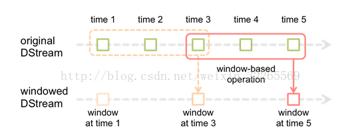
Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。比如下图中,就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。(Spark Streaming对滑动窗口的支持,是比Storm更加完善和强大的)
| Transform | 意义 |
| window | 对每个滑动窗口的数据执行自定义的计算 |
| countByWindow | 对每个滑动窗口的数据执行count操作 |
| reduceByWindow | 对每个滑动窗口的数据执行reduce操作 |
| reduceByKeyAndWindow | 对每个滑动窗口的数据执行reduceByKey操作 |
| countByValueAndWindow | 对每个滑动窗口的数据执行countByValue操作 |
案例:热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数
java版本:
- package cn.spark.study.streaming;
-
-
- import java.util.List;
-
-
- import org.apache.spark.SparkConf;
- import org.apache.spark.api.java.JavaPairRDD;
- import org.apache.spark.api.java.function.Function;
- import org.apache.spark.api.java.function.Function2;
- import org.apache.spark.api.java.function.PairFunction;
- import org.apache.spark.streaming.Durations;
- import org.apache.spark.streaming.api.java.JavaDStream;
- import org.apache.spark.streaming.api.java.JavaPairDStream;
- import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
- import org.apache.spark.streaming.api.java.JavaStreamingContext;
-
-
- import scala.Tuple2;
-
-
- /**
- * 基于滑动窗口的热点搜索词实时统计
- * @author Administrator
- *
- */
- public class WindowHotWord {
-
- public static void main(String[] args) {
- SparkConf conf = new SparkConf()
- .setMaster("local[2]")
- .setAppName("WindowHotWord");
- JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
-
- // 说明一下,这里的搜索日志的格式
- // leo hello
- // tom world
- JavaReceiverInputDStream
searchLogsDStream = jssc.socketTextStream("spark1", 9999); -
- // 将搜索日志给转换成,只有一个搜索词,即可
- JavaDStream
searchWordsDStream = searchLogsDStream.map(new Function() { -
-
- private static final long serialVersionUID = 1L;
-
-
- @Override
- public String call(String searchLog) throws Exception {
- return searchLog.split(" ")[1];
- }
-
- });
-
- // 将搜索词映射为(searchWord, 1)的tuple格式
- JavaPairDStream
searchWordPairDStream = searchWordsDStream.mapToPair( -
- new PairFunction
() { -
-
- private static final long serialVersionUID = 1L;
-
-
- @Override
- public Tuple2
call(String searchWord) - throws Exception {
- return new Tuple2
(searchWord, 1); - }
-
- });
-
- // 针对(searchWord, 1)的tuple格式的DStream,执行reduceByKeyAndWindow,滑动窗口操作
- // 第二个参数,是窗口长度,这里是60秒
- // 第三个参数,是滑动间隔,这里是10秒
- // 也就是说,每隔10秒钟,将最近60秒的数据,作为一个窗口,进行内部的RDD的聚合,然后统一对一个RDD进行后续
- // 计算
- // 所以说,这里的意思,就是,之前的searchWordPairDStream为止,其实,都是不会立即进行计算的
- // 而是只是放在那里
- // 然后,等待我们的滑动间隔到了以后,10秒钟到了,会将之前60秒的RDD,因为一个batch间隔是,5秒,所以之前
- // 60秒,就有12个RDD,给聚合起来,然后,统一执行redcueByKey操作
- // 所以这里的reduceByKeyAndWindow,是针对每个窗口执行计算的,而不是针对某个DStream中的RDD
- JavaPairDStream
searchWordCountsDStream = -
- searchWordPairDStream.reduceByKeyAndWindow(new Function2
() { -
-
- private static final long serialVersionUID = 1L;
-
-
- @Override
- public Integer call(Integer v1, Integer v2) throws Exception {
- return v1 + v2;
- }
-
- }, Durations.seconds(60), Durations.seconds(10));
-
- // 到这里为止,就已经可以做到,每隔10秒钟,出来,之前60秒的收集到的单词的统计次数
- // 执行transform操作,因为,一个窗口,就是一个60秒钟的数据,会变成一个RDD,然后,对这一个RDD
- // 根据每个搜索词出现的频率进行排序,然后获取排名前3的热点搜索词
- JavaPairDStream
finalDStream = searchWordCountsDStream.transformToPair( -
- new Function
, JavaPairRDD>() { -
-
- private static final long serialVersionUID = 1L;
-
-
- @Override
- public JavaPairRDD
call( - JavaPairRDD
searchWordCountsRDD) throws Exception { - // 执行搜索词和出现频率的反转
- JavaPairRDD
countSearchWordsRDD = searchWordCountsRDD - .mapToPair(new PairFunction
, Integer, String>() { -
-
- private static final long serialVersionUID = 1L;
-
-
- @Override
- public Tuple2
call( - Tuple2
tuple) - throws Exception {
- return new Tuple2
(tuple._2, tuple._1); - }
- });
-
- // 然后执行降序排序
- JavaPairRDD
sortedCountSearchWordsRDD = countSearchWordsRDD - .sortByKey(false);
-
- // 然后再次执行反转,变成(searchWord, count)的这种格式
- JavaPairRDD
sortedSearchWordCountsRDD = sortedCountSearchWordsRDD - .mapToPair(new PairFunction
, String, Integer>() { -
-
- private static final long serialVersionUID = 1L;
-
-
- @Override
- public Tuple2
call( - Tuple2
tuple) - throws Exception {
- return new Tuple2
(tuple._2, tuple._1); - }
-
- });
-
- // 然后用take(),获取排名前3的热点搜索词
- List
> hogSearchWordCounts = - sortedSearchWordCountsRDD.take(3);
- for(Tuple2
wordCount : hogSearchWordCounts) { - System.out.println(wordCount._1 + ": " + wordCount._2);
- }
-
- return searchWordCountsRDD;
- }
-
- });
-
- // 这个无关紧要,只是为了触发job的执行,所以必须有output操作
- finalDStream.print();
-
- jssc.start();
- jssc.awaitTermination();
- jssc.close();
- }
- }

scala版本:
package cn.spark.study.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
/**
* @author Administrator
*/
object WindowHotWord {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord")
val ssc = new StreamingContext(conf, Seconds(1))
val searchLogsDStream = ssc.socketTextStream("spark1", 9999)
val searchWordsDStream = searchLogsDStream.map { _.split(" ")(1) }
val searchWordPairsDStream = searchWordsDStream.map { searchWord => (searchWord, 1) }
val searchWordCountsDSteram = searchWordPairsDStream.reduceByKeyAndWindow(
(v1: Int, v2: Int) => v1 + v2,
Seconds(60),
Seconds(10))
val finalDStream = searchWordCountsDSteram.transform(searchWordCountsRDD => {
val countSearchWordsRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1))
val sortedCountSearchWordsRDD = countSearchWordsRDD.sortByKey(false)
val sortedSearchWordCountsRDD = sortedCountSearchWordsRDD.map(tuple => (tuple._1, tuple._2))
val top3SearchWordCounts = sortedSearchWordCountsRDD.take(3)
for(tuple <- top3SearchWordCounts) {
println(tuple)
}
searchWordCountsRDD
})
finalDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
运行步骤:
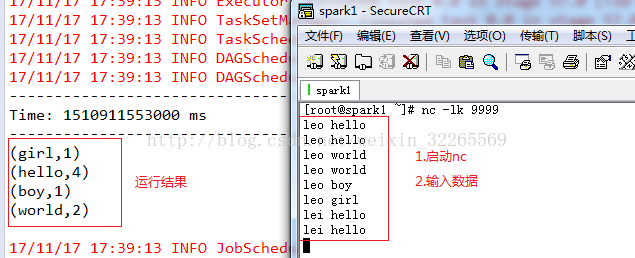
1.启动nc
nc -lk 9999
2.本地运行,直接在IDE中运行程序
运行结果:
文章最后,给大家推荐一些受欢迎的技术博客链接:
- Hadoop相关技术博客链接
- Spark 核心技术链接
- JAVA相关的深度技术博客链接
- 超全干货--Flink思维导图,花了3周左右编写、校对
- 深入JAVA 的JVM核心原理解决线上各种故障【附案例】
- 请谈谈你对volatile的理解?--最近小李子与面试官的一场“硬核较量”
- 聊聊RPC通信,经常被问到的一道面试题。源码+笔记,包懂
欢迎扫描下方的二维码或 搜索 公众号“10点进修”,我们会有更多、且及时的资料推送给您,欢迎多多交流!
![]()

评论记录:
回复评论: