
输入DStream和Receiver详解(一)
输入DStream代表了来自数据源的输入数据流。在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),代表了从netcat(nc)服务接收到的数据流。除了文件数据流之外,所有的输入DStream都会绑定一个Receiver对象,该对象是一个关键的组件,用来从数据源接收数据,并将其存储在Spark的内存中,以供后续处理。
Spark Streaming提供了两种内置的数据源支持;
- 基础数据源:StreamingContext API中直接提供了对这些数据源的支持,比如文件、socket、Akka Actor等。
- 高级数据源:诸如Kafka、Flume、Kinesis、Twitter等数据源,通过第三方工具类提供支持。这些数据源的使用,需要引用其依赖。
- 自定义数据源:我们可以自己定义数据源,来决定如何接受和存储数据。
输入DStream和Receiver详解(二)
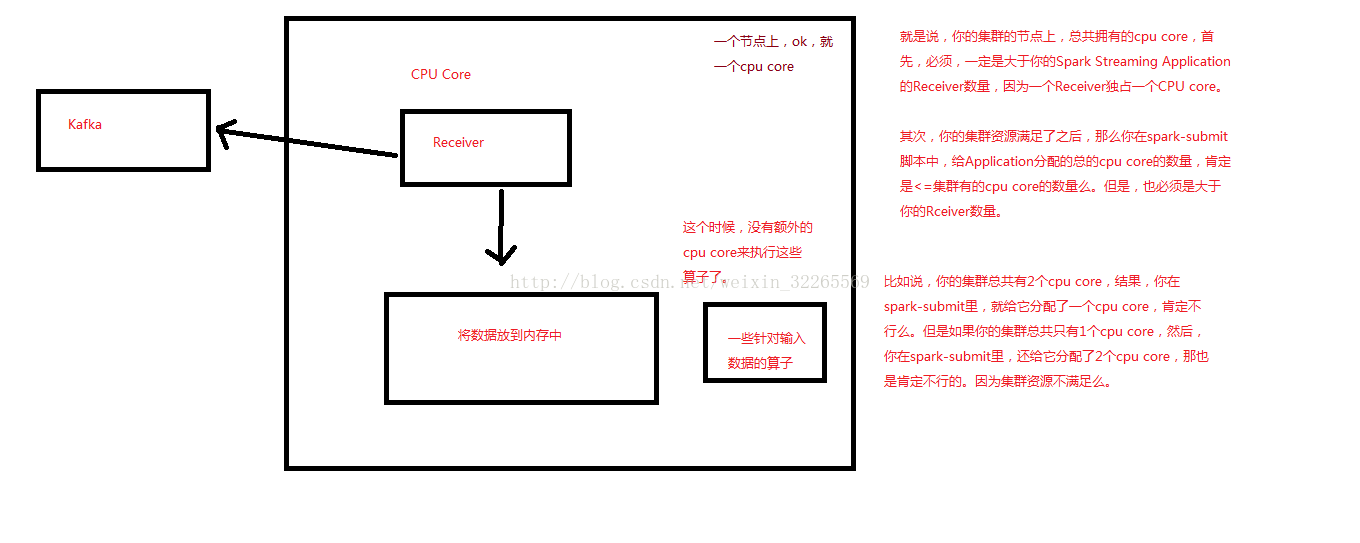
要注意的是,如果你想要在实时计算应用中并行接收多条数据流,可以创建多个输入DStream。这样就会创建多个Receiver,从而并行地接收多个数据流。但是要注意的是,一个Spark Streaming Application的Executor,是一个长时间运行的任务,因此,它会独占分配给Spark Streaming Application的cpu core。从而只要Spark Streaming运行起来以后,这个节点上的cpu core,就没法给其他应用使用了。
使用本地模式,运行程序时,绝对不能用local或者local[1],因为那样的话,只会给执行输入DStream的executor分配一个线程。而Spark Streaming底层的原理是,至少要有两条线程,一条线程用来分配给Receiver接收数据,一条线程用来处理接收到的数据。因此必须使用local[n],n>=2的模式。
如果不设置Master,也就是直接将Spark Streaming应用提交到集群上运行,那么首先,必须要求集群节点上,有>1个cpu core,其次,给Spark Streaming的每个executor分配的core,必须>1,这样,才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一条处理数据。否则的话,只会接收数据,不会处理数据。
因此,基于此,特此声明,我们本系列课程所有的练习,都是基于local[2]的本地模式,因为我们的虚拟机上都只有一个1个cpu core。但是大家在实际企业工作中,机器肯定是不只一个cpu core的,现在都至少4核了。到时记得给每个executor的cpu core,设置为超过1个即可。
文章最后,给大家推荐一些受欢迎的技术博客链接:
- Hadoop相关技术博客链接
- Spark 核心技术链接
- JAVA相关的深度技术博客链接
- 超全干货--Flink思维导图,花了3周左右编写、校对
- 深入JAVA 的JVM核心原理解决线上各种故障【附案例】
- 请谈谈你对volatile的理解?--最近小李子与面试官的一场“硬核较量”
- 聊聊RPC通信,经常被问到的一道面试题。源码+笔记,包懂
欢迎扫描下方的二维码或 搜索 公众号“10点进修”,我们会有更多、且及时的资料推送给您,欢迎多多交流!
![]()

评论记录:
回复评论: