
本文重点介绍 Spark 中 【mapToPair】和【flatMapToPair】的区别,请继续看到尾部,后续有示例说明,会理解更加清晰。
函数原型
1.JavaPairRDD
此函数会对一个RDD中的每个元素调用f函数,其中原来RDD中的每一个元素都是T类型的,调用f函数后会进行一定的操作把每个元素都转换成一个
2.JavaPairRDD
此函数对对一个RDD中的每个元素(每个元素都是T类型的)调用f函数,通过f函数可以将每个元素转换为
使用说明
在使用时mapToPair会将一个长度为N的、每个元素都是T类型的对象,转换成另一个长度为N的、每个元素都是
大白话说明
spark 分析的数据是基于一行行,类似于数据库的一条条记录那样。所以,我们可以理解为:
- map 是一条记录变一条记录的转换操作;适用于数据格式转换
- flatMap 是一条记录变多条记录的转换操作;适用于数据格式拆分同时进行数据转换
话不多说,直接上示例代码,如下:
JAVA 版本:
- package com.java.spark_core.transform;
-
- import org.apache.log4j.Level;
- import org.apache.log4j.Logger;
- import org.apache.spark.SparkConf;
- import org.apache.spark.api.java.JavaRDD;
- import org.apache.spark.api.java.JavaSparkContext;
-
- import java.util.Arrays;
-
-
- public class Java_Spark02_Oper1_mapVsflatmap {
- public static void main(String[] args) {
- Logger.getLogger("org").setLevel(Level.WARN);
- // var config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
- SparkConf config = new SparkConf().setMaster("local[*]").setAppName("map");
-
- // 创建 Spark上下文对象
- // var sc: SparkContext = new SparkContext(config)
- JavaSparkContext sc = new JavaSparkContext(config);
-
-
- JavaRDD
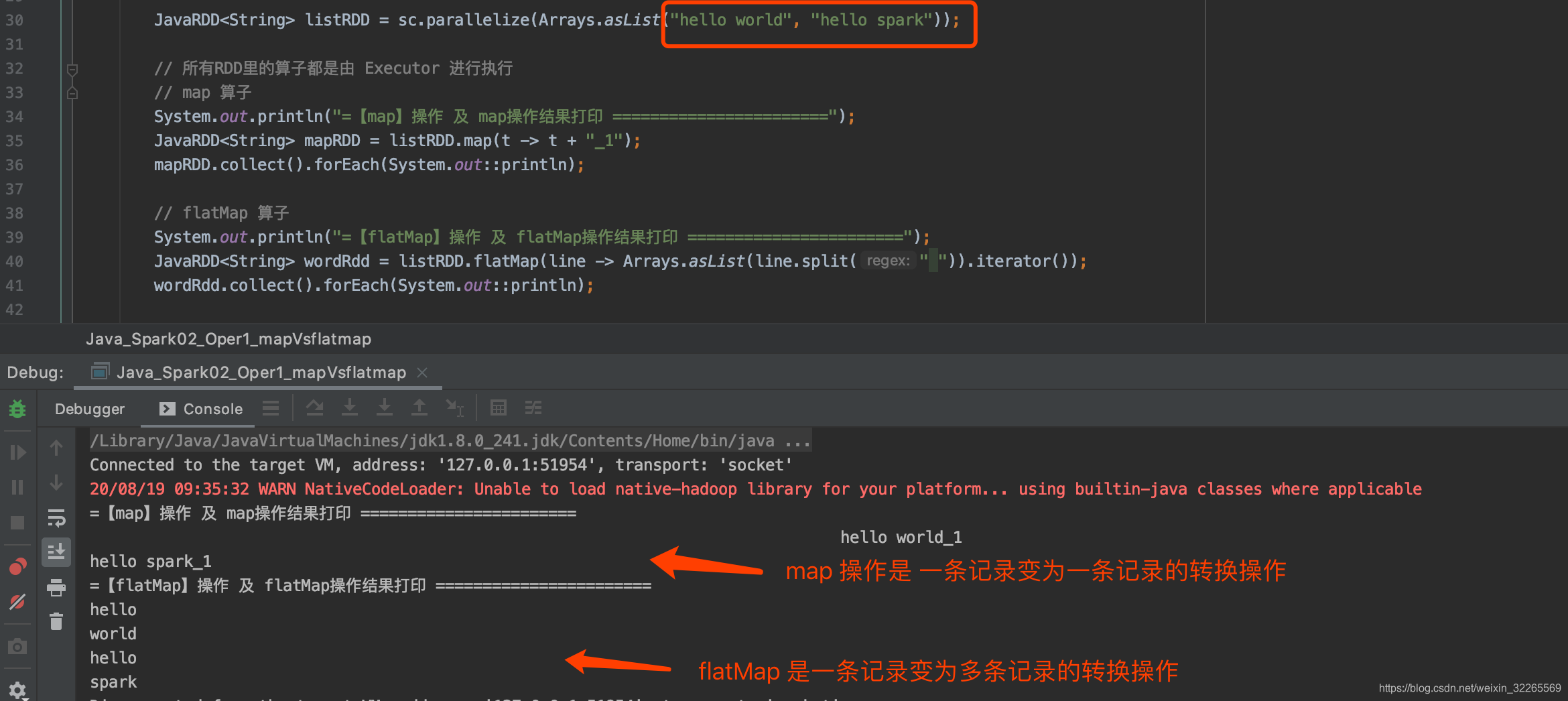
listRDD = sc.parallelize(Arrays.asList("hello world", "hello spark")); -
- // 所有RDD里的算子都是由 Executor 进行执行
- // map 算子
- System.out.println("=【map】操作 及 map操作结果打印 =======================");
- JavaRDD
mapRDD = listRDD.map(t -> t + "_1"); - mapRDD.collect().forEach(System.out::println);
-
- // flatMap 算子
- System.out.println("=【flatMap】操作 及 flatMap操作结果打印 =======================");
- JavaRDD
wordRdd = listRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator()); - wordRdd.collect().forEach(System.out::println);
-
- sc.close();
- }
- }

Scala 版本:
- package com.scala.spark_core.transform
-
- import org.apache.log4j.{Level, Logger}
- import org.apache.spark.rdd.RDD
- import org.apache.spark.{SparkConf, SparkContext}
-
-
- object Spark02_Oper1_mapVsflatmap {
-
- def main(args: Array[String]): Unit = {
- Logger.getLogger("org").setLevel(Level.WARN)
- var config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("map")
-
- // 创建Spark上下文对象
- var sc: SparkContext = new SparkContext(config)
-
- // map算子
- var listRDD: RDD[String] = sc.makeRDD(Array("hello world", "hello spark"))
-
- // 所有RDD里的算子都是由 Executor 进行执行
- // map 算子
- System.out.println("=【map】操作 及 map操作结果打印 =======================")
- val mapRDD: RDD[String] = listRDD.map(_ + "_1")
- mapRDD.collect().foreach(println)
-
- // flatMap 算子
- System.out.println("=【flatMap】操作 及 flatMap操作结果打印 =======================")
- val wordRDD: RDD[String] = listRDD.flatMap(_.split(" "))
- wordRDD.collect().foreach(println)
- }
- }
示例代码运行结果截图如下:
文章最后,给大家推荐一些受欢迎的技术博客链接:
- Hadoop相关技术博客链接
- Spark 核心技术链接
- JAVA相关的深度技术博客链接
- 超全干货--Flink思维导图,花了3周左右编写、校对
- 深入JAVA 的JVM核心原理解决线上各种故障【附案例】
- 请谈谈你对volatile的理解?--最近小李子与面试官的一场“硬核较量”
- 聊聊RPC通信,经常被问到的一道面试题。源码+笔记,包懂
欢迎扫描下方的二维码或 搜索 公众号“10点进修”,我们会有更多、且及时的资料推送给您,欢迎多多交流!
![]()

评论记录:
回复评论: