
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。
巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清楚缓存,那么可以使用unpersist()方法。
Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
直接上示例:
接下来,通过实例展示未使用RDD持久化运行情况:
- package cn.spark.study.core1;
-
- import org.apache.spark.SparkConf;
- import org.apache.spark.api.java.JavaRDD;
- import org.apache.spark.api.java.JavaSparkContext;
-
- public class Persist {
-
- public static String m_FilePath = "C://Users//Leizuquan//Desktop//spark_thinkpad//spark code//spark-test-file//";
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- SparkConf conf = new SparkConf()
- .setAppName("Persist")
- .setMaster("local");
-
- // cache()或者persist()的使用,是有规则的
- // 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
- // 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
- // 而且,会报错,大量的文件会丢失
- JavaSparkContext sc = new JavaSparkContext(conf);
- JavaRDD
linesRDD = sc.textFile(m_FilePath + "Persist.txt"); -
- long startTime = System.currentTimeMillis();
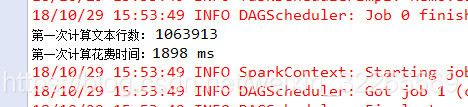
- long count = linesRDD.count();
- System.out.println("第一次计算文本行数: " + count);
- long endTime = System.currentTimeMillis();
- long spendTime = endTime - startTime;
- System.out.println("第一次计算花费时间:" + spendTime + " ms");
-
-
- startTime = System.currentTimeMillis();
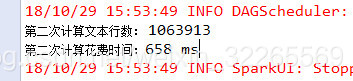
- count = linesRDD.count();
- System.out.println("第二次计算文本行数: " + count);
- endTime = System.currentTimeMillis();
- spendTime = endTime - startTime;
- System.out.println("第二次计算花费时间:" + spendTime + " ms");
-
-
- sc.close();
- }
-
- }

未使用RDD持久化运行结果:
接下来,通过实例展示RDD持久化带来的性能优化(textFile等创建了一个RDD之后,直接连续调用cache()):
- package cn.spark.study.core1;
-
- import org.apache.spark.SparkConf;
- import org.apache.spark.api.java.JavaRDD;
- import org.apache.spark.api.java.JavaSparkContext;
-
- public class Persist {
-
- public static String m_FilePath = "C://Users//Leizuquan//Desktop//spark_thinkpad//spark code//spark-test-file//";
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- SparkConf conf = new SparkConf()
- .setAppName("Persist")
- .setMaster("local");
-
- // cache()或者persist()的使用,是有规则的
- // 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
- // 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
- // 而且,会报错,大量的文件会丢失
- JavaSparkContext sc = new JavaSparkContext(conf);
- JavaRDD
linesRDD = sc.textFile(m_FilePath + "Persist.txt").cache(); -
- long startTime = System.currentTimeMillis();
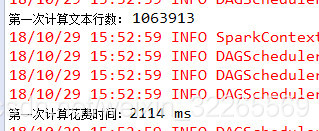
- long count = linesRDD.count();
- System.out.println("第一次计算文本行数: " + count);
- long endTime = System.currentTimeMillis();
- long spendTime = endTime - startTime;
- System.out.println("第一次计算花费时间:" + spendTime + " ms");
-
-
- startTime = System.currentTimeMillis();
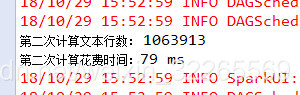
- count = linesRDD.count();
- System.out.println("第二次计算文本行数: " + count);
- endTime = System.currentTimeMillis();
- spendTime = endTime - startTime;
- System.out.println("第二次计算花费时间:" + spendTime + " ms");
-
-
- sc.close();
- }
-
- }
使用RDD持久化运行结果:
总结:
RDD持久化能够给应用程序带来数倍的性能提升。
文章最后,给大家推荐一些受欢迎的技术博客链接:
- Hadoop相关技术博客链接
- Spark 核心技术链接
- JAVA相关的深度技术博客链接
- 超全干货--Flink思维导图,花了3周左右编写、校对
- 深入JAVA 的JVM核心原理解决线上各种故障【附案例】
- 请谈谈你对volatile的理解?--最近小李子与面试官的一场“硬核较量”
- 聊聊RPC通信,经常被问到的一道面试题。源码+笔记,包懂
欢迎扫描下方的二维码或 搜索 公众号“10点进修”,我们会有更多、且及时的资料推送给您,欢迎多多交流!
![]()

评论记录:
回复评论: