
学习笔记 | 主成分分析[PCA]及其若干应用
概要: 前段时间学习了一些矩阵分解算法,包括主成分分析(Principal Component Analysis, PCA)、独立成分分析(Independent Component Analysis, ICA)、非负矩阵分解(Non-negative Matrix Factorization, NMF)等。接下来我将用三五篇博客的篇幅简要介绍这些方法,以及他们的若干项应用。这篇博客先介绍主成分分析。
关键字: 矩阵分解; 主成分分析; PCA
1 背景说明
近来在学机器学习,果然是对数学要求很高。尤其是矩阵方面需要有丰富的知识储备,否则不论是算法还是代码都是很难看懂的,更别说作出什么东西来了。矩阵分解是矩阵分析中一个很重要的话题,以此为出发点可以发散出许许多多的算法,而且这些算法在实际工程项目中往往具有非常不错的效果和广阔的应用。主成分分析(PCA)在形式上可以归为矩阵分解问题一类,但实际上却是作为一种数据分析算法“闻名天下”的。顾名思义,PCA就是将一组数据的“主要成分”提取出来而忽略剩下的次要内容,达到数据降维的效果,以减少运算资源消耗或达成其他目的。从哲学上讲,这一想法体现了马克思主义哲学中唯物辩证法的核心——矛盾的观点,即抓主要矛盾。当我们用哲学的思想指导实践时,往往能对现实作出某称程度上的预判。因此,我们应当相信PCA算法存在的必然性和重要性,同时这也有助于我们更加迅速深入地了解PCA的本质和核心。
2 算法原理
2.1 PCA简介
大概主成分分析是最重要的降维方法之一。在数据压缩、消除冗余和数据噪音消除等领域都有广泛的应用,一般我们提到降维最容易想到的算法就是它。PCA试图用数据最主要的若干方面来代替原有的数据,这些最主要的方面首先需要保证蕴含了原始数据中的大量信息,其次需要保证相互之间不相关。因为相关代表了数据在某种程度上的“重叠”,也就相当于冗余性没有清除干净。现在,问题转变为什么样的特性能代表原始数据中的“信息”,怎样才能“最大程度地”保留信息。让我们先看图1。
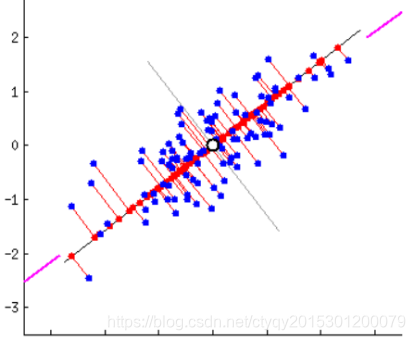 图1 数据投影(1)
图1 数据投影(1)
|
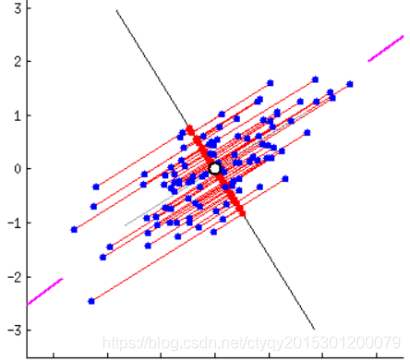 图1 数据投影(2)
图1 数据投影(2)
|
上面的截图来源于白马负金羁,实际上是个动图,我这里截图截成了静止的图像。上图都是将二维空间(平面)中的一群离散点投影到一维空间(直线)上去,那么应该怎样投才能使一维空间上保留尽可能多的原始信息?直观来看,显然是图1_(1)的效果比图1_(2)好,因为在(2)中点都纠集到了一团,很多点在直线上的投影重合了,这样最多只能保留一个点的信息,而图(1)中的投影相对更加离散。
说到离散,我就想到了西游记中的唐僧一别太宗十七载,去国离乡取西经的故事。明年,中外合拍的电影西游记即将正式开机,章老师将继续扮演美猴王孙悟空……咳咳,打住打住。说到离散,我就想起了数学上的方差概念,数据越离散保留的信息就越多,反之亦反。到这里,PCA的另一个指导思想就呼之欲出了:方差即信息。
2.2 基本原理
因为我比较懒,而且花时间抄书确实没有什么意思,所以公式什么的就不列举了。这里介绍几个把PCA的数学原理写得非常好的博客,水平比我不知道高到哪里去了,请大家移步观赏:
1. PCA的数学原理:从简单的2维数据开始讲起,深入浅出、娓娓道来,绝对是教材中的上品,零基础学生的福音;
2. Principal Component Analysis:PCA动图展示,支持用户交互,有时候不得不承认,人家老外做的东西就是比国内做得好,而且不止一点半点;
3. PCA(主成分分析):这是斯坦福机器学习课程(吴恩达授课)笔记系列的一部分,它最大的价值是针对成机器学习课程形成了一个完整的系列,参考价值很高;
4. 機器/統計學習:主成分分析:看上去应该是台湾人做的,示例详实、图文并茂,也很好;
5. 主成分分析(PCA)与Kernel PCA:我上文提到的白马负金羁的博客,公式不建议深究,KPCA也不完整,但是那张动图确实很好;
6. PCA主成分分析学习总结:这是知乎上的一篇学习总结,从基础知识入手,中规中矩,质量较高,而且这个知乎专栏的内容质量也较高。
部分是英文资料,部分资料需要翻墙,这也是没办法的事情。
2.3 形式化表达
将一个问题通过数学方法表达出来,就是形式化表达,这是求解问题的第一步。由于本人在CSDN上打公式不熟练,所以就用PPT代劳了,如图2所示。

这就是PCA的形式化表示,对于一个输入的
n
n
n行
m
m
m列矩阵,PCA的目标就是将它降至
k
k
k维,
k
<
n
k<n
k<n,输出
k
k
k行
m
m
m列矩阵,注意数据量
m
m
m是保持不变的。
3 算法步骤与代码
经过中间一系列计算步骤(这里不一一展现),最后得到了PCA算法的实现步骤如图3所示(仍然是PPT代劳):

有了步骤,接下来就只剩小学生都会做的编程了。
MATLAB代码如下:
function Res = myPCA(X,R,varargin)
%MYPCM - The Principal Component Analysis(PCA) function.
% To calculate the result after PCA, one kind of
% dimension-reduction technical of characteristics.
% Here are some useful reference material:
% https://www.jianshu.com/p/2fad63faa773
% http://blog.codinglabs.org/articles/pca-tutorial.html
%
% Res = myPCA(X,R)
% Res = myPCA(X,R,DIM)
%
% Input -
% X: a N*M matrix containing M datas with N dimensions;
% R: number of dimensions to be reduced to, normally, R N
error('Error! The 2nd parameter should be smaller than the col. of the 1st one.');
elseif R == N
warning('Warning! There is no dimension-reduction effect.');
end
if DIM == 2
X = X';
elseif DIM~=1 && DIM~=2
error('Error! Parameter DIM should be either 1 or 2.');
end
%% core algorithm
center = mean(X,2);
X = X - repmat(center,1,M); % zero_centered for each LINE/Field
C = X*(X')/M; % the Covariance matrix of X, C(N*N)
[eigenvector,eigenvalue] = eig(C);
[B,order] = sort(diag(eigenvalue),'descend');
% calculate contribution-rate matrix
contrb = zeros(R,2);
contrb(:,1) = B(1:R)/sum(B);
for i=1:R
contrb(i,2) = sum(contrb(1:i,1));
end
P = zeros(R,N);
% convert eigenvectors from columns to lines.
for i=1:R
P(i,:) = eigenvector(:,order(i))';
end
Y = P*X;
%% get result
Res.contrb = contrb;
Res.P = P;
Res.Y = Y;
Res.center = center;
end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
4 PCA实例与应用
接下来我将就上面的PCA算法做一些test code,来检测以下PCA的性能,顺便也能加深理解。
4.1 PCA的实质
我认为,PCA的实质是数据的整体旋转。
之前说到,PCA算法旨在寻找某些相互独立的方向,使得原始数据在这些方向上的投影尽可能离散。拆开来理解就是这么一回事:
1. 尽可能离散就是需要尽可能多地保留原始信息;
2. 寻找的方向要相互独立是为了避免保留下来的信息存在冗余;
3. “若干个”应当少于、最多等于原始数据维数,否则就不是降维了(注意,从数学上来讲是可以做到升维的,这个与Kernel Trick,即核方法有关,本系列的后续文章会介绍)。
还记得文章开头的那2张截图吗,原来的动图是一条轴线以数据质心为中心旋转,从旋转簇中选一条作为投影方向。从相对运动的角度来说,这等价于坐标轴不动,所有数据整体旋转,在不改变数据之间相对位置的情况下,使得自己方差最大的方向从大到小地对准坐标系中一组基底的方向。
相关的实验结果如图4所示:
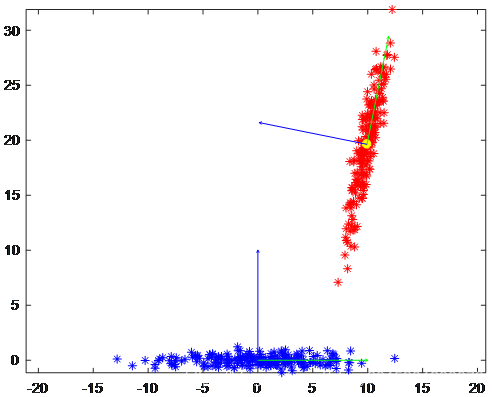 图4(1) 2维数据PCA变换前后
图4(1) 2维数据PCA变换前后
|
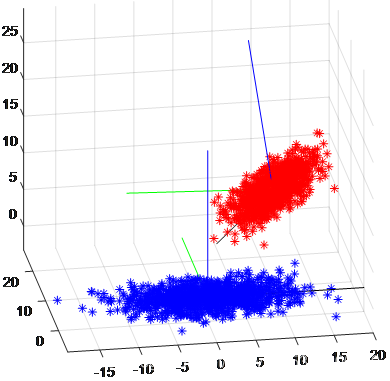 图4(2) 3维数据PCA变换前后
图4(2) 3维数据PCA变换前后
|
如上面两张图所示,红色为原数据,蓝色为PCA变换后没有降维的数据。图4(1)中方差由大到小的2个不相关轴分别是绿色和蓝色的,图4(2)中方差由大到小的3个不相关轴分别是黑色、绿色和蓝色的。可以看见变换后数据质心移到了原点,且根据数据离散程度分别与原坐标系的基底 i , j , k i,j,k i,j,k对齐,数据集的形态没有改变(数据点的相对位置不变)。在此基础上,如果要降维,自然是根据数据在各个轴上的方差值由小到大舍弃舍弃某一维即可。因此,不妨对PCA的原理做如下描述:
将数据整体旋转后,根据数据在各维度上投影的方差值由小到大地舍弃维度。
4.2 用PCA降维
这是PCA最直接的应用,降低了维度就可以减小运算数据量。
4.2.1 语音性别识别数据集
现在用PCA降低语音性别识别实验中所用数据集的维度,该数据集原来的数据维度为20,我在之前的博客中有相关说明。降维的效果如图5所示。
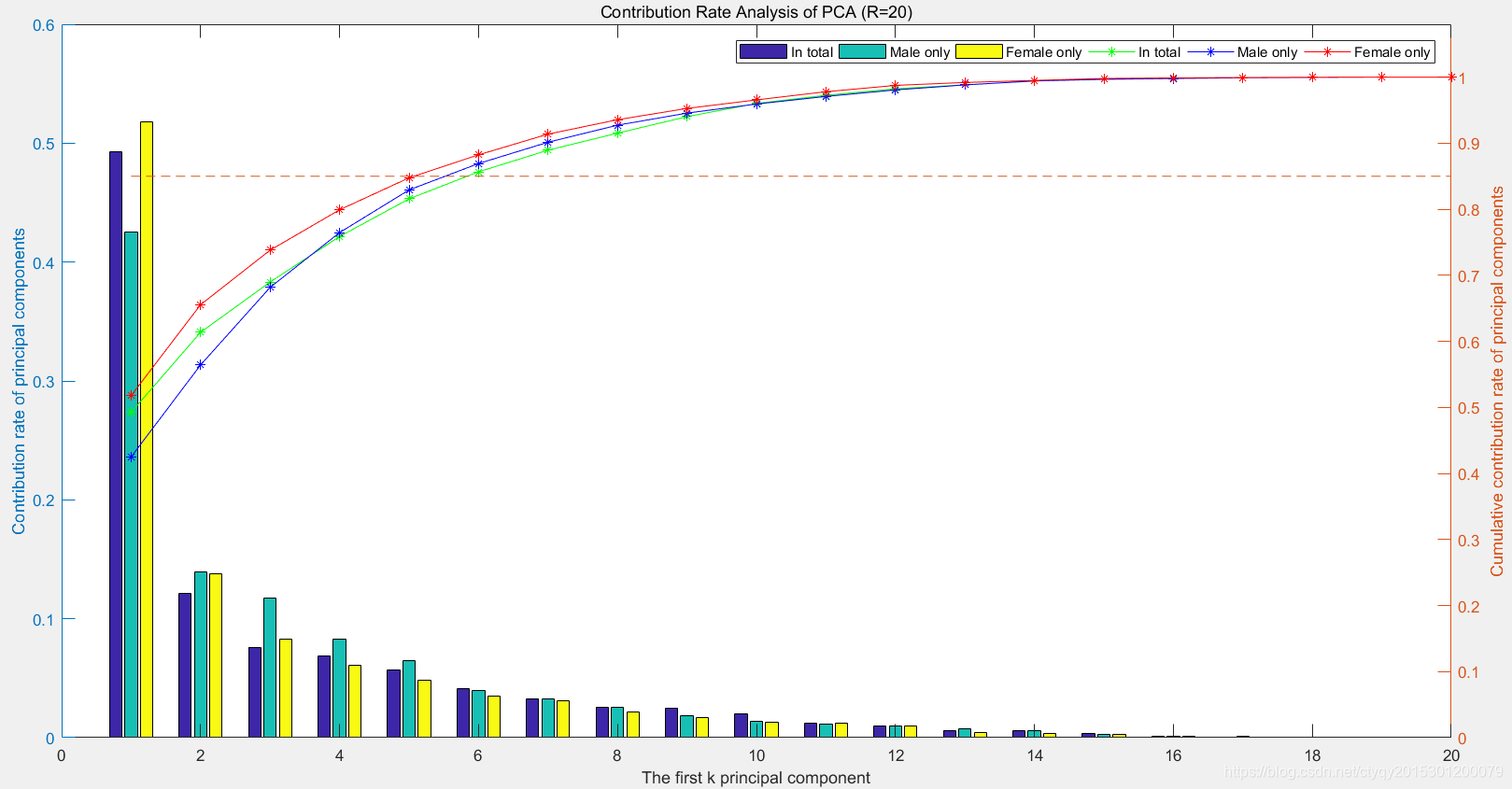
图中蓝、绿、黄三色分别代表总计、男性、女性,柱状图为各主成分的信息贡献率,折线图为前若干主成分的合计信息贡献率。可以发现主成分贡献率逐渐减小而越前面的主成分贡献率越大。一般而言我们需要保留原数据85%以上的信息,在本例中前5个主成分的累计贡献率就达到这一数据,因此理论上可以直接将20维数据降到5维,数据量减少75%而信息量只减少15%。
4.2.1 MNIST数据集
总计20维可能还太小,PCA的效果难以表现出来。现在对MNIST数据集分析,该数据集我也在之前的博客中谈到,每一个手写体数字是28*28的矩阵,共计784维。降维的效果如图6所示。
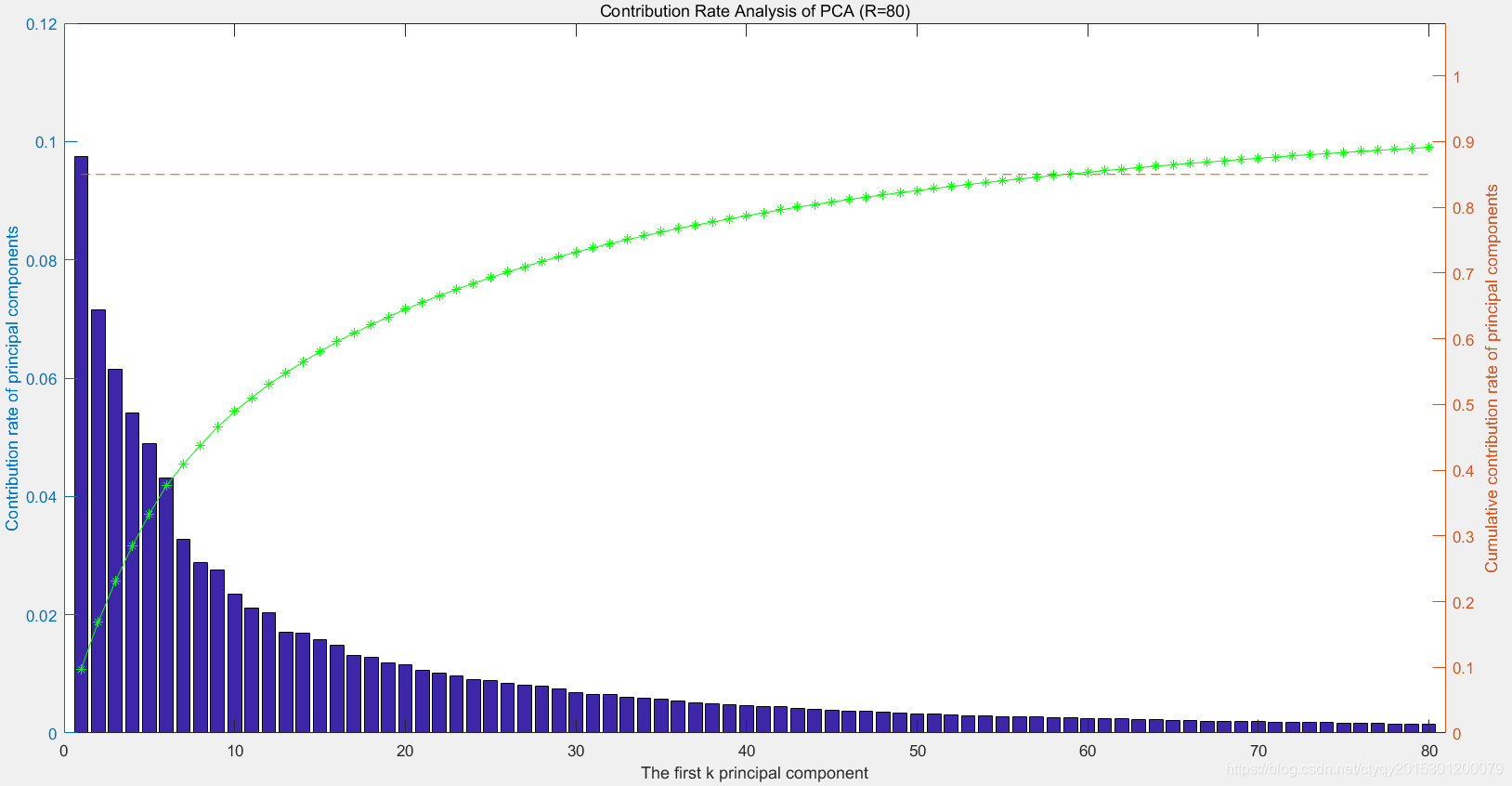
图中仅展现了前80维,因为后面的维度基本没有信息。在本例中约前60个主成分的累计贡献率就达到85%,因此理论上可以直接将784维数据降到60+维,数据量减少90%以上而信息量只减少15%。
4.3 用PCA做数据可视化
这一条相当于是4.2的特例,将高维数据降低到2维或是3维,放到坐标系中自然就可视了。图7所示是语音数据集的可视化。
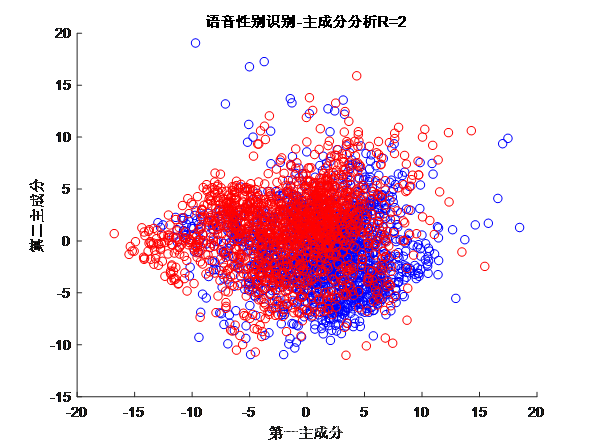 图7(1) PCA变换后为2维数据
图7(1) PCA变换后为2维数据
|
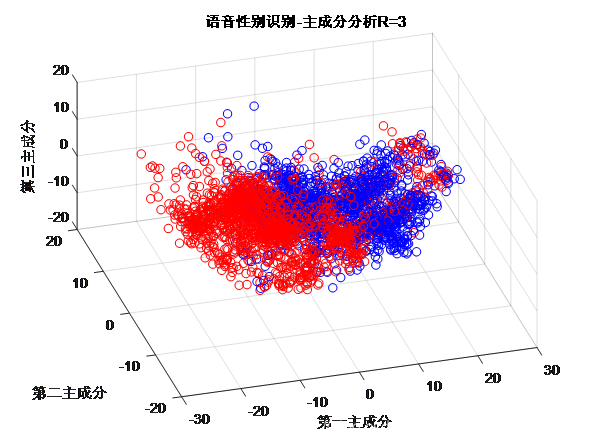 图7(2) PCA变换后为3维数据
图7(2) PCA变换后为3维数据
|
图7分别为原始数据(20维)被降维到2维和3维后的图像,蓝色是男性数据,红色是女性数据。另一方面,如果降维后两者区分较明显,通过这种方法就可以直接进行分类。
4.4 用PCA做图像压缩
用PCA做图像压缩的基本思路是图2所示的公式:
P k × n ⋅ X n × m = Y k × m P_{k \times n}\cdot X_{n \times m}=Y_{k \times m} Pk×n⋅Xn×m=Yk×m
PCA的思路是设矩阵 X n × m X_{n \times m} Xn×m表示一整一张 m m m行 n n n列的图像,通过矩阵 P k × n P_{k \times n} Pk×n将其降至 k k k维,得到 k k k行 m m m列矩阵 Y k × m Y_{k \times m} Yk×m。那么反过来,只要知道和 Y k × m Y_{k \times m} Yk×m和 P k × n P_{k \times n} Pk×n就能计算出矩阵 X n × m X_{n \times m} Xn×m,而矩阵 P k × n P_{k \times n} Pk×n和 Y k × m Y_{k \times m} Yk×m的数据量是可以小于矩阵 X n × m X_{n \times m} Xn×m的。因此,定义保留的数据量与原图像数据量之比为压缩率,则PCA做图像压缩的压缩率为:
ρ = k ( m + n ) m n \rho = \frac{k(m+n)}{mn} ρ=mnk(m+n)
在实际处理中,往往是将原图像无重叠拆分成 m m m个子图、每个子图拉成一长度为 n n n的列向量来拼成原矩阵 X n × m X_{n \times m} Xn×m的。现不妨设一图像长宽都是512像素,则有:
m n = 51 2 2 mn=512^2 mn=5122
因此,
ρ = k ( m + n ) m n ⩾ 2 k m n m n ⩾ 2 k m n = k 256 \rho = \frac{k(m+n)}{mn} \geqslant \frac{2k \sqrt{mn}}{mn} \geqslant \frac{2k}{\sqrt{mn}}=\frac{k}{256} ρ=mnk(m+n)⩾mn2kmn⩾mn2k=256k
若将这张图拆分为8*8的小图,那么 n = 64 , m = 4096 n=64,m=4096 n=64,m=4096,根据PCA原理,需满足 k ⩽ n k \leqslant n k⩽n,不妨令 k = 32 k=32 k=32,此时原图信息仍能保留绝大部分,而压缩率为50.78%,相当于数据量减少一半而信息几乎不丢失。图8所示为用PCA做图像压缩的效果,原图是经典的 l e n a lena lena图像,是512在*512的灰度图。

上面的图像压缩率是25.391%。
从压缩公式可知,要想进一步压缩,有2条途径可以走:要么减小 k k k,要么使得 m m m和 n n n数值尽可能接近,从而使柯西不等式尽可能接近等号的取值。而要在减小 k k k的同时不止于损失过多的数据,就需要 n n n尽可能小,结果就是 m m m和 n n n的数值差距越来越大,从而偏离柯西不等式的最小值,同时还需记得参与运算的都是整数,且要将图像完整分拆,这些都需要考虑。所以说这是一个 trade off 的过程,细节部分还需要具体问题具体分析。
另外,若不能将大图完整拆分,也可以考虑给大图补上白边,或是有重叠地拆分,或者所拆分得到的小图也不一定非得是正方形,等等方法都可以尝试。
5 小结
本文初步探讨了主成分分析算法(PCA)的原理以及若干应用,下面做一个小结。
PCA是一种著名的数据降维算法,它应用的条件是数据/特征之间具有明显的线性相关性,它的两个主要的指导思想是抓主要矛盾和方差即信息,它的基本应用是数据降维,以此为基础还有数据可视化、数据压缩存储、异常检测、特征匹配与距离计算等。从数学上理解,它是一种矩阵分解算法;从物理意义上理解,它是线性空间上的线性变换。
PCA的核心代码已经在文中给出,其他的都是一些测试代码,这里就不给出了。关于PCA,还有KPCA(Kernel PCA,核PCA)、MPCA(Multilinear PCA,多线性PCA)等变形,可以有效弥补标准PCA算法存在的某种缺陷,关于这些内容,我会在这个系列后面的文章中简要介绍。
评论记录:
回复评论: