
人类一向善于从大自然中寻找启发,并做出必要的改进来满足某种需要。而人类本身就有很多不可思议的事情,比如大脑。机器学习,学习学习,参考人类本身的学习就是对所见的事物一步一步的总结,一层一层的抽象,而大脑的神经-中枢-大脑的工作过程或许是一个不断迭代,不断抽象的过程,从原始的信号,做低级的抽象,逐渐向高级抽象迭代。
在感知机中,它采用了多个输入单元来抽象,但是学习能力非常有限,无法解决非线性可分的问题,虽然SVM延伸了核技术解决了这一点,但是实际上利用多层的感知机(Multi-layer Perception)也能完成,不过虽然是多层,其实是只有一层隐层节点的浅层模型。比如很多的分类,回归的学习方法都是浅层的算法,在于有限的样本和计算单元情况下对复杂的函数的表达能力有限,泛化能力不佳,计算量大。所以简单的多层网络的学习规则肯定是不够的,类比大脑产生更强大的算法是必要的。
正如一个感知机一样,它有多个输入,不过这些输入可以取0~1的任何值而不是仅仅0,1。改进原先的激活函数为Sigmoid函数:
σ
(
z
)
=
1
1
+
e
−
z
\sigma(z)=\frac{1}{1+e^{-z}}
σ(z)=1+e−z1
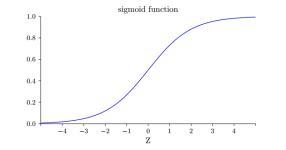
为什么用Sigmoid?
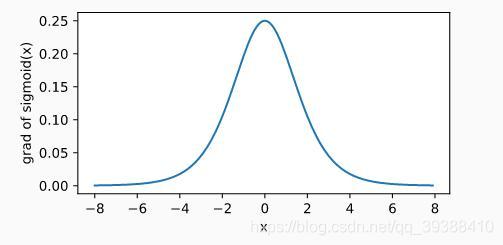
包括改进前的激活函数也是一样,都是引入非线性变换函数便于我们的“分类”。而且它的好处在于求导后的图像如下,
σ
′
(
x
)
=
σ
(
x
)
(
1
−
σ
(
x
)
)
\sigma'(x)=\sigma(x)(1-\sigma(x))
σ′(x)=σ(x)(1−σ(x)),当输入为 0 时,sigmoid 函数的导数达到最大值 0.25;当输入越偏离 0 时,sigmoid 函数的导数越接近 0,能过避免一些梯度的问题。其实使用不同的激活函数最大的变化只是求偏导时某些值的改变,事实证明这样做能够简化计算,至于其他的激活函数在文末会再次总结。
而正如模拟生物神经网络,当神经元“兴奋”时就会向其相连的神经元发送某些化学物质去改变相连神经元的电位,而且如果电位超过某个阈值(threshold),神经元将就会被激活。事实上,不考虑它是否真的模拟了生物神经网络,只需将一个神经网络视为包含了许多参数的数学模型,由若干个函数相互嵌套即可。采用Sigmoid做激活函数(activation function),可以构建一个多层感知机,由许多逻辑单元按照不同层级组织起来,每一层的输出变量都是下一层的输入变量。
- 实际上多层神经元是由多个线性存在级联产生的,由低级的特征逐步扩展至更抽象的描述,最终再得到想要的目标结果。
所以具体的计算过程如下:
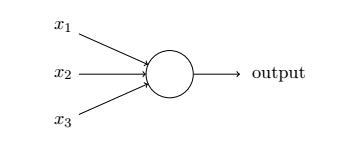
- 设x1,x2,x3是输入单元(input units),将原始数据输入给它们。a1,a2,a3是中间单元,负责处理数据,然后呈递到下一层,最后是输出单元,它负责计算h(x)。然后与感知机类似,可以算出
a
1
(
2
)
=
σ
(
w
11
(
1
)
x
1
+
w
12
(
1
)
x
2
+
w
13
(
1
)
x
3
+
b
1
(
1
)
)
a_1^{(2)}= \sigma(w_{11}^{(1)}x_1 + w_{12}^{(1)}x_2 + w_{13}^{(1)}x_3 + b_1^{(1)})
a1(2)=σ(w11(1)x1+w12(1)x2+w13(1)x3+b1(1))
a 2 ( 2 ) = σ ( w 21 ( 1 ) x 1 + w 22 ( 1 ) x 2 + w 23 ( 1 ) x 3 + b 2 ( 1 ) ) a_2^{(2)}= \sigma(w_{21}^{(1)}x_1 + w_{22}^{(1)}x_2 + w_{23}^{(1)}x_3 + b_2^{(1)}) a2(2)=σ(w21(1)x1+w22(1)x2+w23(1)x3+b2(1))
a 3 ( 2 ) = σ ( w 31 ( 1 ) x 1 + w 32 ( 1 ) x 2 + w 33 ( 1 ) x 3 + b 3 ( 1 ) ) a_3^{(2)}= \sigma(w_{31}^{(1)}x_1 + w_{32}^{(1)}x_2 + w_{33}^{(1)}x_3 + b_3^{(1)}) a3(2)=σ(w31(1)x1+w32(1)x2+w33(1)x3+b3(1)) - 计算结果做下一次的输入,然后可得:
h W , b ( x ) = σ ( w 11 ( 2 ) a 1 ( 2 ) + w 12 ( 2 ) a 2 ( 2 ) + w 13 ( 2 ) a 3 ( 2 ) + b 1 ( 2 ) ) h_{W,b}(x)= \sigma(w_{11}^{(2)}a_1^{(2)} + w_{12}^{(2)}a_2^{(2)} + w_{13}^{(2)}a_3^{(2)} + b_1^{(2)}) hW,b(x)=σ(w11(2)a1(2)+w12(2)a2(2)+w13(2)a3(2)+b1(2)) - 机器学习老套路,此时需要一个损失函数来微调,常见的均方误差: J ( W , b , x , y ) = 1 2 ∣ ∣ h W , b ( x ) − y ∣ ∣ 2 2 J(W,b,x,y) = \frac{1}{2}||h_{W,b}(x)-y||_2^2 J(W,b,x,y)=21∣∣hW,b(x)−y∣∣22
- 然后基于梯度下降策略,对参数们进行一层一层的误差逆传递(Error BackPropagation,BP)更新参数。
W l = W l − α ∑ i = 1 m δ i , l ( a i , l − 1 ) T W^l = W^l -\alpha \sum\limits_{i=1}^m \delta^{i,l}(a^{i, l-1})^T Wl=Wl−αi=1∑mδi,l(ai,l−1)T
b l = b l − α ∑ i = 1 m δ i , l b^l = b^l -\alpha \sum\limits_{i=1}^m \delta^{i,l} bl=bl−αi=1∑mδi,l
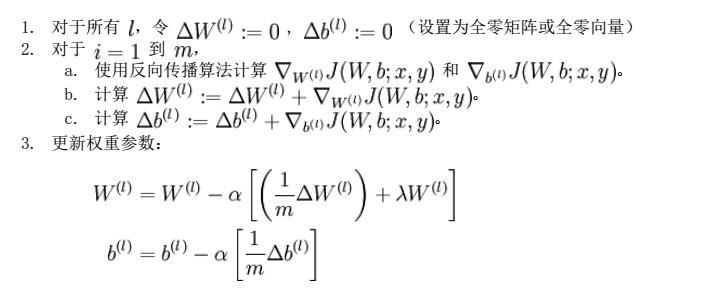
简单来说就是参数的随机初始化,利用正向传播计算所有的h(x),计算代价函数j,利用反向传播计算所有的偏导,利用数值检验来检验偏导,最后使用优化算法(梯度下降等)来最小化代价函数。
import random
import numpy as np
class Network(object):
def __init__(self, sizes):#sizes包含各层神经元的数量
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]#随机初始化
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):#梯度下降
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)#更新
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)#调用backprop
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x]
zs = []
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):#判别正确的数量
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
return (output_activations-y)
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):#导数
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
收敛速度太慢?损失函数改进
采用交叉熵:
J
(
W
,
b
,
a
,
y
)
=
−
y
∙
l
n
a
−
(
1
−
y
)
∙
l
n
(
1
−
a
)
J(W,b,a,y) = -y \bullet lna- (1-y) \bullet ln(1 -a)
J(W,b,a,y)=−y∙lna−(1−y)∙ln(1−a)
第一,它非负;第二结果越接近,交叉熵接近0。这两点将使收敛速度变快。
有关激活函数的真正力量!
除了归一化便于了计算的作用,它的真正力量其实是提供给了网络的非线性建模能力。如果没有激活函数,网络仅仅只能表示线性的关系,只有加入了激活函数的非线性特征才能使网络拥有非线性映射的学习能力。所以线性函数是绝对不能作为激活函数的!!
- 可微性。使用梯度时可微才方便处理。
- 单调性。保证变换后的网络还是凸函数。
- 输出范围。有限的范围会更稳定,训练会更加高效。
对神经元及其权重的理解
Hebb法则:突触连接强度的变化和两个相连神经元激活的相关性成比例。即如果两个神经元同时被激活,那么他们之间连接强度会变大,反正连接会减少甚至消失。这个法则也被称为长时效增强法则和神经可塑性。
分类问题如何解决?
Softmax激活函数:
a
i
L
=
e
z
i
L
∑
j
=
1
n
L
e
z
j
L
a_i^L = \frac{e^{z_i^L}}{\sum\limits_{j=1}^{n_L}e^{z_j^L}}
aiL=j=1∑nLezjLeziL
softmax函数能将输入值映射到(0,1),且所有输出值的累和为1,所以可以直接把它当概率,选取概率最大作最终结果。
继续加深神经网络效果怎么样?梯度问题
在BP算法中,使用了链式法则来求梯度,这样将会导致梯度问题。即激活函数饱和,每次输出的都是一堆小于1的激活数字连乘,那么网络越深,连乘越多,慢慢的导致梯度消失,反过来如果是大于1的数据,将导致梯度爆炸。
修正线性单元(Rectified Linear Unit,ReLU)激活函数:
ReLU
(
x
)
=
max
(
x
,
0
)
.
\text{ReLU}(x) = \max(x, 0).
ReLU(x)=max(x,0).
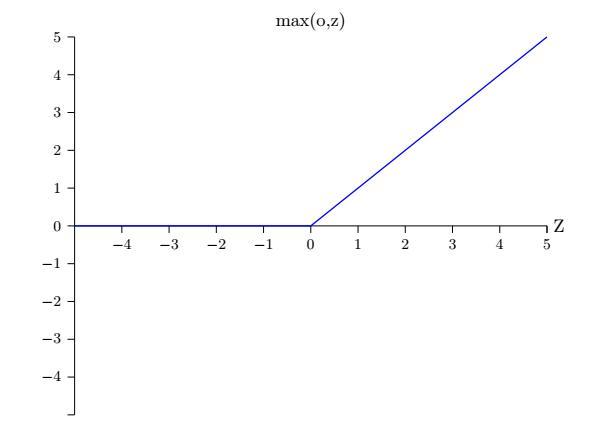
它在一定程度上能解决梯度消失,原因在于函数的右端的不会趋近于饱和。当值为负数时,ReLU 函数的导数为 0;当值为正数时,ReLU 函数的导数为 1,所以在求导时,很明显导数不为零,从而梯度不消失,不过对于小于0的左边即负数方向依然存在问题是不可导的(于是有了Leaky ReLU,pReLU等)。另外它不想Sigmoid等拥有一个确定的上界,再接受大数据时会不稳定,所以考虑给它一个上界的定义,ReLU6的经验函数就来了: m i n ( 6 , ∣ x ∣ + x 2 ) min(6,\frac {|x|+x}{2}) min(6,2∣x∣+x).使用BN进行归一化也能避免一些不足的问题。
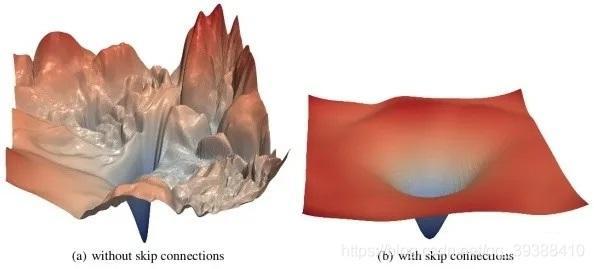
- 但其实损失函数只是一个缓刑作用,一旦模型深度增加这个问题依旧很棘手。直到2015何凯明大神的paper提出了残差网络,算是完成了对这个问题的阶段性解决,残差网络在cnn中有解释,只是在这里想说残差网络之所以好用除了它相比以为学习原数据的方法,它学习网络的残差十分有效,简化了学习的过程,使导数在求导的时候包含了恒等项,始终有值可以做传递。另外,在于它减轻了神经网络的退化。
- 网络退化:如果网络中的每个层只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分对不同的输入都是相同反应,此时整个权重矩阵的秩不高,而深度加深的连乘会使其更加的严重。
- 而残差网络可以打破神经网络的对称性、线性依赖等问题,解决退化问题,能够增加网络的泛化能力。
激活函数各优缺点
- Sigmoid:梯度消失;与原点不对称;计算exp时间长
- tanh:解决了对称问题,比Sigmoid快。仍然存在梯度消失
- ReLU:梯度消失没有完全解决;在负区间神经元为0,代表完全死亡不会复活。此时可以用leaky ReLU,ELU看看效果。
- Maxout:克服了ReLU缺点,提倡使用,但参数较多,本质上是在输出结果上又加了一层。( m a x ( w 1 T x + b 1 , w 2 T x + b 2 ) max(w^T_1x+b_1,w^T_2x+b_2) max(w1Tx+b1,w2Tx+b2))
- Gaussian Error Linerar Units(GELUS)。这种激活函数在BERT等目前最先进的nlp模型中用的很多,一般来说为了增加模型泛化能力,需要加入随机正则(例如等会要整理的dropout)+非线性激活,而GELU干了这两者。实现方式是在输入的x上乘一个正太分布随机mask,由于不容易直接计算,所以用下面的式子逼近来算: G E L U ( x ) = x P ( X < = x ) = x Φ ( x ) = 0.5 ( 1 + t a n h ( 2 π ( x + 0.044715 x 3 ) ) ) GELU(x)=xP(X<=x)=x\Phi(x)=0.5(1+tanh(\sqrt{\frac{2}{π}}(x+0.044715x^3))) GELU(x)=xP(X<=x)=xΦ(x)=0.5(1+tanh(π2(x+0.044715x3)))
def gelu(input_tensor):
cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(2.0)))
return input_tesnsor*cdf
- 1
- 2
- 3
选用避坑指南:除了gate等需要限制到0-1的场景,最好不要用Sigmoid,因为它到±4才有比较大的梯度,其他很接近0容易梯度消失。
网络的宽度对网络的影响怎么样?
宽度,即通道数量。网络加深的好处是使网络拥有逐级抽象的能力,而宽度是为了让网络学习到更加丰富的特征,比如不同方向、不同属性、不同纹理等,太窄的网络会使每一层的捕获的模式有限,不能够提取足够的信息。
深度和宽度谁更重要?
目前没有答案,两者都重要。但对于模型的研究与性能提升来说,模型对深度更加的敏感,效果往往是指数级,而宽度是多项式级别的提升,所以相对来说应该优先调整深度。
什么时候不适合用深度学习?
- 数据集太小,样本不足(深度学习在这里没有任何优势,提取特征非常容易过拟合,没有泛化能力)
- 数据集没有局部相关性(图像,语音,文字都是具有局部相关性的。深度学习对于有结构化特征的数据提取有很好的效果)
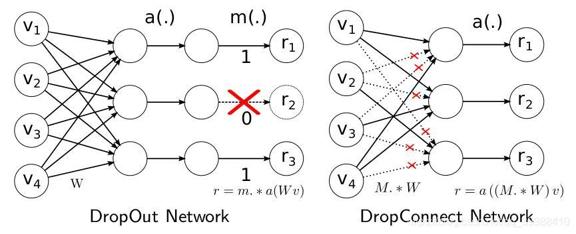
正则化问题–DropOut和DropConnect
除了用L1,L2这种正则化外,神经网络可以通过 dropout 来正则化,即在训练时随机去掉部分隐藏层的神经元。如下图:
随机dropout相当于训练了多个不同的神经网络,减弱了神经节点间的联合适应性,这样做能减轻过拟合,提升其泛化能力。
- 另外也可以把dropout看出一种ensemble的方法,每次都相当于从网络中找到了一个更简单的局部簇,使区分性变大,稀疏性变大了。
- 虽然在网络训练好后,测试阶段不会有dropout的操作,但是这将导致训练和测试的数据分布会不一样,这样训练会十分的不稳定,所以作为神经元失活的补偿,往往需要对权重除以(1-p)。(除以是为了将权重“放大”,即之间的差距会变得大一些,尽可能的拟合这种基于多次0-1的二阶分布,期望是1-p)
- 一般设置为0.5. 特别是小数据上0.5的dropout+sgd效果很不错。
而DropConnect与Dropout不同,它不是随机将隐含层节点的输出清0,而是将节点中的每个与其相连的输入权值以1-p的概率清0。(一个是输出,一个是输入)。在对DropConnect进行推理时,采用的是对每个输入(每个隐含层节点连接有多个输入)的权重进行高斯分布的采样,故不需要像Dropout一样补偿失活神经元。该高斯分布的均值与方差当然与前面的概率值p有关另外需要注意因为DropConnect只能用于全连接的网络层(和dropout一样),如果网络中用到了卷积,则用patch卷积时的隐层节点是不使用DropConnect的。
如何选择超参数?。
比如梯度下降的步率,批量数据的规模,周期和正则化的系数等等。
解决方案:可视化,不断尝试与调整以得到最好的结果。如从0.01、0.02、0.04、0.08、0.1、0.2、0.4、0.8这样的测试方式调参。(调参技术在一定程度上能够决定网络的性能优劣)
如何初始化权重?
这个问题实际上是非常重要的。设为0?网络不会有任何的作用。都设为相同的某一固定值?网络退化!(所有的中间结果都会一样)。太小:信号传递逐渐缩小难以产生作用,太大:信号传递逐渐放大导致发散和失效不。适当的权重会造成一定程度上的梯度消失和爆炸的问题,所以随机赋值的方法往往不适用。理想上我们需要每个层激活输出的平均值为0,平均标准差是1.
不过一般利用平均化的思想,w = np.random.randn(n) * sqrt(2.0/n)效果还不错,另外在ReLU中的赋值推荐(Bengio)往往是:
Var
(
W
)
=
2
n
in
+
n
out
\text{Var}(W) = \frac{2}{n_\text{in} + n_\text{out}}
Var(W)=nin+nout2
但是深度网络中Xavier初始化应用更多:
由于in和out的数量不同,所以简单来说就取了中间数。但在均匀分布时,有方差
Var
=
(
b
−
a
)
2
12
\text{Var}={(b-a)^2\over 12}
Var=12(b−a)2,可得
b
=
6
n
i
n
+
n
o
u
t
b={\sqrt{6}\over \sqrt{n_{in}+n_{out}}}
b=nin+nout6
那么就有了:
W
∼
U
[
−
6
n
j
+
n
j
+
1
,
6
n
j
+
n
j
+
1
]
W \sim U[-{\sqrt{6}\over \sqrt{n_j+n_{j+1}}},{\sqrt{6}\over \sqrt{n_j+n_{j+1}}}]
W∼U[−nj+nj+16,nj+nj+16]
即将一个层的权重设置为从一个有界的随机均匀分布中选择值,其中j是传入网络连接数量,也叫“扇入”,j+1是传出的数量,也叫“扇出”。它使得经过多层神经元后保持在合理的范围。
但是Xavier在百层nn或者30层cnn时,输出消失得很严重。所以特别是在CV领域,还是最好使用Kaiming/He初始化:
- 给某指定层权值矩阵创建一个张量,并从标准正太分布随机选择数字填充它
- 将每个随机数乘以 2 n \frac{\sqrt{2}}{\sqrt{n}} n2,n为扇入
- 偏置b初始化为0
不过现在的一些开源框架都会注意这些点,优化得…还可以。(一般选用tanh,Sigmoid用Xavier效果好,ReLU首选Kaiming/He初始化)
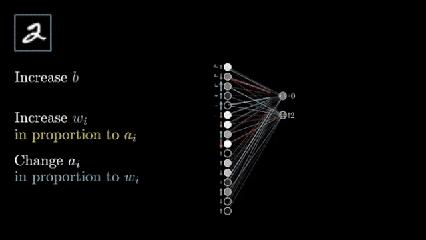
BP反向传播可视化
梯度下降算法优化
在线性回归等算法中,往往直接使用梯度下降,其实还有很多的优化梯度下降的方法。
- SGD。 损失函数凸时可收敛最优值,非凸时也可以收敛至局部最优点。但由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢。(但是这种随机性对缓解神经网络非凸有帮助)训练数较多时,需要较大内存。而且不能在线更新、增量学习,只有当其退化为GD,即每次只读入一个数据时可以增量,但显然GD容易陷入局部最优。 Θ = Θ − α ⋅ ▽ Θ J ( Θ ) Θ=Θ−α⋅▽ _Θ J(Θ) Θ=Θ−α⋅▽ΘJ(Θ)
- Mini-batch GD。 在SGD和GD间寻找一个平衡点,每次小批量小批量的进行训练,这样不仅计算效率高,而且收敛较为稳定,是目前的主流方法。但这个平衡点、学习率较难选择,如果学习率太小会导致收敛缓慢,而太块又会造成较大波动。 Θ = Θ − α ⋅ ▽ Θ J ( Θ ; x ( i : i + n ) , y ( i : i + n ) ) Θ=Θ−α⋅▽ Θ_J(Θ;x^{(i:i+n)} ,y^{(i:i+n)} ) Θ=Θ−α⋅▽ΘJ(Θ;x(i:i+n),y(i:i+n))
- Momentum。 克服SDG的更新方向完全依赖于当前batch计算出的梯度,借用了物理中的动量概念,模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。
v t = γ ⋅ v t − 1 + α ⋅ ▽ Θ J ( Θ ) v_t=γ⋅v _{t−1}+α⋅▽ _ΘJ(Θ) vt=γ⋅vt−1+α⋅▽ΘJ(Θ) Θ = Θ − v t \Theta = \Theta-v_{t} Θ=Θ−vt当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。简而言之就是跟着惯性,小球下山。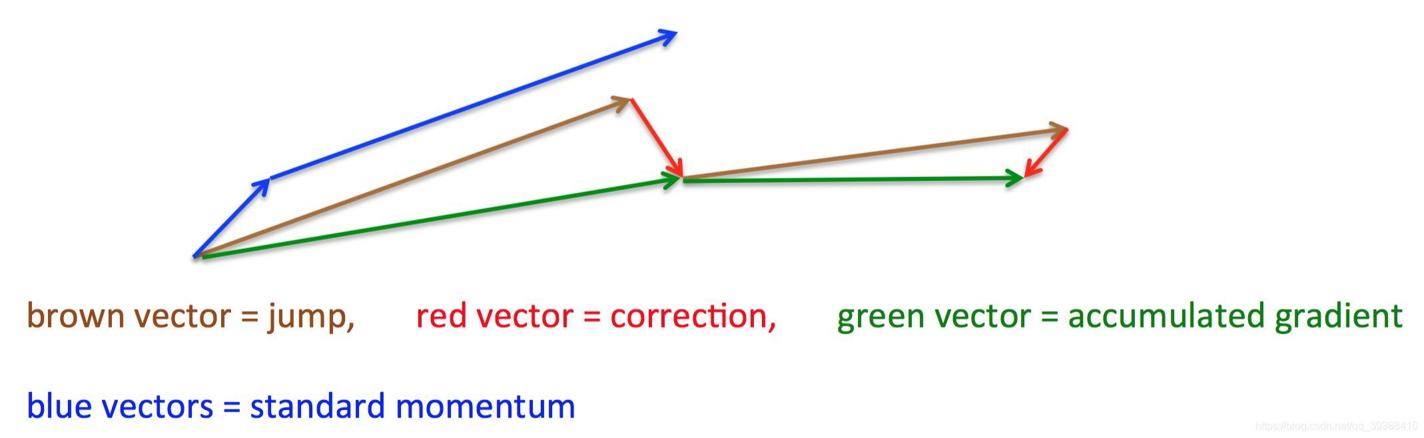
- Nesterov Momentum。 如上图,按照原来的更新方向更新一步(棕色线),然后在该位置计算梯度值(红色线),则在计算梯度时,不是在当前位置,而是未来的位置上,然后用这个梯度值修正最终的更新方向(绿色线),蓝色线是标准的momentum更新路径。 v t = γ ⋅ v t − 1 + α ⋅ ▽ Θ J ( Θ − γ v t − 1 ) v _t=γ⋅v _{t−1}+α⋅▽ _ΘJ(Θ−γv_{t−1}) vt=γ⋅vt−1+α⋅▽ΘJ(Θ−γvt−1) Θ = Θ − v t \Theta = \Theta-v_{t} Θ=Θ−vt对比 momentum 方法,如果只看 γ * v 项,那么当前的 θ经过 momentum 的作用会变成 θ-γ * v。因此可以把 θ-γ * v这个位置看做是当前优化的一个”展望”位置。所以,可以在 θ-γ * v(因为更新也是-γ * v,所以提前减掉,相当于是未来的值)对未来接下一的一步求导, 而不是原始的θ。相当于可以提前一步展望,预测是否会遇到上坡或下坡。
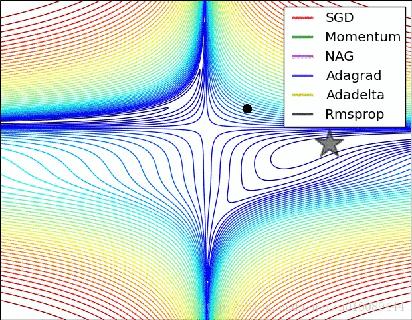
- Adagrad.。 为了克服每个参数需要的学习步长可能会不一样,故将除以一个对角矩阵G ,每个对角线位置为对应参数θ的从第1轮到第t轮梯度的平方和,即每个参数,随着其更新的总距离增多,其学习速率也随之变慢。 Θ t + 1 , i = Θ t , i − α ( G t , i i + ϵ ) ⋅ ▽ Θ J ( Θ i ) Θ _{t+1,i}=Θ _{t,i}− \frac{α}{(G _{t,ii}+ϵ)}⋅▽ _ΘJ(Θ _i) Θt+1,i=Θt,i−(Gt,ii+ϵ)α⋅▽ΘJ(Θi)可以看到,它对于出现频率较高的参数采用较小的α更新,频率低则是较大的更新,也意味着“二阶动量”开始占据领地。因此,Adagrad非常适合处理稀疏数据。且特别是它在分类问题上效果好。
- RMSprop。 Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应历史某个窗口的平均值,因此可缓解Adagrad算法学习率下降较快的问题。结合移动自回归来调整学习参数,是学习更稳健。 E [ g 2 ] t = 0.9 E [ g 2 ] t − 1 + 0.1 g t 2 E[g^2]_t=0.9E[g^2]_{t−1}+0.1g_t^2 E[g2]t=0.9E[g2]t−1+0.1gt2 Θ t + 1 = Θ t − α E [ g 2 ] t + ϵ ⋅ g t \Theta_{t+1} =\Theta_{t}- \frac{\alpha}{\sqrt{E[g^2]_t+\epsilon }}\cdot g_{t} Θt+1=Θt−E[g2]t+ϵα⋅gtHinton 建议设定 γ 为 0.9, 学习率 η 为 0.001。
- Adam。 同时结合动量和RMSprop的优化算法,同时结合一阶和二阶动量。从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t=β_1m_{t−1} +(1−β_1 )g_t mt=β1mt−1+(1−β1)gt v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t=\beta_2v_{t-1}+(1-\beta_2)g_t^2 vt=β2vt−1+(1−β2)gt2 m ^ t = m t 1 − β 1 t \hat{m}_t=\frac{m_t}{1-\beta_1^t} m^t=1−β1tmt v ^ t = v t 1 − β 2 t \hat{v}_t=\frac{v_t}{1-\beta_2^t} v^t=1−β2tvt Θ t + 1 = Θ t − α v ^ t + ϵ m ^ t \Theta_{t+1} =\Theta_{t}- \frac{\alpha}{\sqrt{\hat{v}_t }+\epsilon }\hat{m}_t Θt+1=Θt−v^t+ϵαm^tm,v 分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望的近似,而m^ 和 v^ 则是对m,v的校正,这样可以近似为对期望的无偏估计。 它既和RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的指数衰减平均值。建议的参数为: β1 = 0.9,β2 = 0.999,ϵ = 10e−8。且特别是它在生成问题上效果好。
选用指南:对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值。SGD通常训练时间更长,在好的初始化和学习率调度方案的情况下,结果更可靠。Adagrad非常适合数据出现频度不一样的模型,比如word2vec,你肯定希望出现非常少的词语权重更新非常大,让它们远离常规词,学习到向量空间中距离度量的意义,出现非常多的词(the,very,often)每次更新比较小。但如果在意更快的收敛,并且需要训练较深较复杂的网络时,请使用Adam大法。
调参指南:从1.0或者0.1的学习率开始,看一下验证集,cost没有下降就学习率减半。(很多论文都用这种方法)
深度学习中加速收敛/降低训练难度的方法?
- 瓶颈结构,残差结构
- 学习率,步长等超参
- 动量,优化方法,预训练
如果深度学习效果不好,应该怎么考虑?
- 模型是否合理?特别的,hidden size一般没有太大的影响,太少拟合不行太大训练比较慢,多试试找个适合的就行。
- 损失函数是否合理?
- 梯度更新是否正常。可以采用Gradient Check, g ( θ ) ≈ J ( θ + ϵ ) − J ( θ − ϵ ) 2 ϵ g(\theta)\approx \frac{J(\theta+\epsilon)-J(\theta-\epsilon)}{2\epsilon} g(θ)≈2ϵJ(θ+ϵ)−J(θ−ϵ),将 ϵ 设为一个很小的常量,比如 10−4 数量级。
- batch size是否合适?mini-batch好处主要有:可以用矩阵计算加速并行;引入的随机性可以避免困在局部最优值;并行化计算多个梯度等。但是如果size太大会很快平稳,太小会震荡。
- 学习率是否合适?学习率很重要,训练过程中,找到最大的,使模型error不会爆掉的lr,然后用稍微小一点的lr训练。
- 激活函数是否合理?学习率是否合理?优化方法是否合理?
- 是否过拟合?查看模型在验证集和测试集上的效果。
- 是否欠拟合?如果欠拟合了,请先让它过拟合!然后再正则就好。如L1,L2,early stop,Dropout等等。
- 还可以采取一些早停止,正则化,权重收缩,dropout等方法
- 最后,调整网络结构。。。重新开始吧!
Batch Normalization
Batch Normalization首先提出是由2015的Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift一文,从这个题目可以看到它的motivation是为了解决 Internal Covariate Shift。
- 内部协变转移(Internal Covariate Shift)是指神经网络在更新参数后各层输入的分布会发生变化,这使得后一层网络需要不停的适应这种分布变化,这便会降低网络的收敛速度。同时,这种变化的不断累积使模型容易陷入激活函数的饱和区,可能产生梯度消失/爆炸,从而给训练带来困难。所以在BN出现之前,较小的学习率和特定的权重初始化是必要的。
BN通过批归一化的操作,即对mini-batch的数据进行归一化为均值为 0、方差为 1 的正态分布,这就使得每一层神经网络的输入保持相同的分布,从而可以使用大学习率加速收敛,也不用特别设计权重初始化,Dropout,L2和weight decay也可以设置小甚至不用的。有放在激活函数前或者激活函数后两种方法,一般放在激活函数后比价常见。 x ′ ( k ) = x ( k ) − E [ x ( k ) ] V a r [ x ( k ) ] x^{'(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}} x′(k)=Var[x(k)]x(k)−E[x(k)]对mini-batch计算 的均值和方差就行了,其中k是特征的维度,即BN其实是对每个维度进行归一化的。
用的比较多的主要变体有:Batch Norm(BN)、Layer Norm(LN)、Instance Norm(IN)和 Group Norm(GN)。
- LN:在Transformer中就用到了,前面也提到过,BN主要受制有两点1.因为它是算当前 batch 的均值和方差,所以受制与batch size,但是size小了没意义,大了受硬件的影响(MoCo也主要是改进的这一点) 2.BN适合固定的网络如cnn,对于rnn的话由于句子长度不一样就不太好,所以那为什么不就直接对句子本身进行归一化呢?所以LN就是直接对样本本身进行归一化。
- IN:针对Channel的归一化,在处理图像时一般会有很多的通道,所以直接用每一个通道去计算均值和方差。
- GN:GN 主要是针对 batch 过小而导致统计值不准的缺点进行优化。即在这种情况下,把通道也拿来一起分组一起算,即分组数*通道数=特征数。
BN对应解决梯度问题性能优异,已经成为网络标配,但是在NIPS18’时被MIT打脸,文章自How Does Batch Normalization Help Optimization? 作者认为BN 优化训练的并不是因为缓解了 ICS(就算分布都归一化为0,1这些分布也不一定是相同的分布),而是和ResNet一样对目标函数空间增加了平滑约束loss landscape,从而使得利用更大的学习率获得更好的局部优解。
简单的NN应用:
import tensorflow as tf
#导入input_data用于自动下载和安装MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder("float", [None, 784])
#权重值W和偏置值b
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
#使用softmax
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder("float", [None,10])
#计算交叉墒
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
#梯度下降最小化交叉墒
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print (sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
再来一个多层神经网络
import tensorflow as tf
import numpy as np
def add_layer(inputs,in_size,out_size,n_layer,activation_function=None):
layer_name = "layer%s" % n_layer
with tf.name_scope(layer_name):
with tf.name_scope("Weights"):
Weights = tf.Variable(tf.random_normal([in_size,out_size]),name='W')
#概率分布的形式
tf.summary.histogram(layer_name+'/weights',Weights)
with tf.name_scope("biases"):
biases = tf.Variable(tf.zeros([1,out_size])+0.1,name='b')
tf.summary.histogram(layer_name + '/biases', biases)
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.add(tf.matmul(inputs,Weights),biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
x_data = np.linspace(-1,1,300)[:,np.newaxis]
noise = np.random.normal(0,0.05,x_data.shape).astype(np.float32)#加入噪音
y_data = np.square(x_data) - 0.5 + noise
#None表示给多少个sample都可以
with tf.name_scope("input"):
xs = tf.placeholder(tf.float32,[None,1],name='x_input')
ys = tf.placeholder(tf.float32,[None,1],name='y_input')
l1 = add_layer(xs,1,10,1,activation_function=tf.nn.relu)#第一层
prediction = add_layer(l1,10,1,2,activation_function=None)#第二层
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
tf.summary.scalar("loss",loss)
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('logs/',sess.graph)#记录并保存log便于显示
sess.run(init)
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i % 50 == 0:
result = sess.run(merged,feed_dict={xs:x_data,ys:y_data})
writer.add_summary(result,i)#写入log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
所生成的log文件是用于在tensorboard上进行显示。首先在logs上一层打开命令行,输入tensorboard --logdir logs回车(Tensorflow新一些的版本是自己配了tensorboard,如果没有也可以手动pip一个),然后打开Google浏览器或者火狐输入http://127.0.1.1:6006,或者一般回车后会有一个网址打开便可以使用了。可以看到我们建立了两层的网络,具体的输出和loss也都很方便。
一、下载Git
1、Git的下载地址
Git-2.47.1-64-bit
https://git-scm.com/downloads
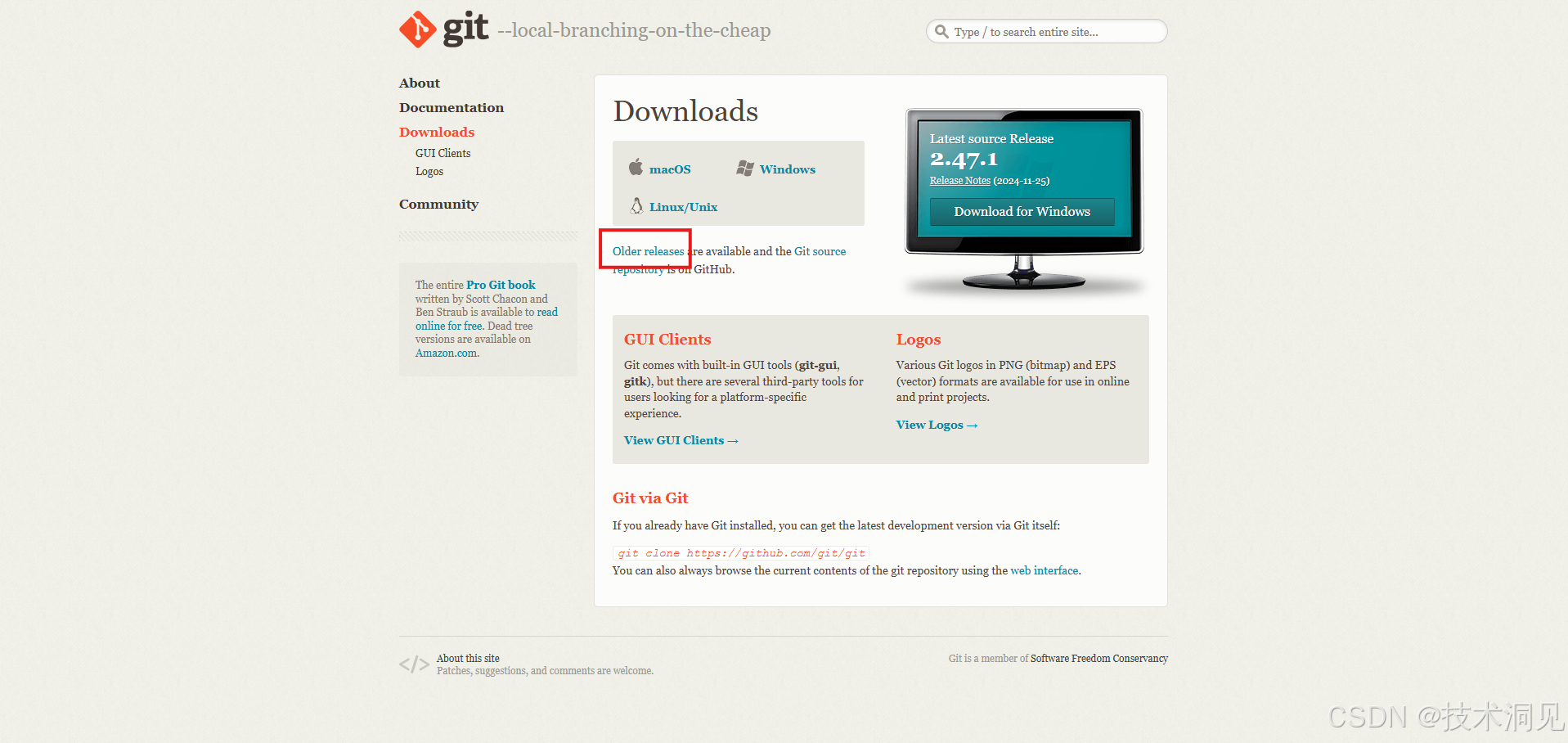
选择相应的操作系统下载,这里给出的是当前最新版本2.47.1,如需下载之前的版本,可在图片显示的红框内,点击Older releases即可。
PS:由于一些原因,Git安装包下载速度较慢,可以复制资源链接到迅雷等第三方下载工具下载或直接下载本文的资源即可
2、等待安装

找到下载的安装包双击进行安装。
二、Git的安装
1、阅读说明
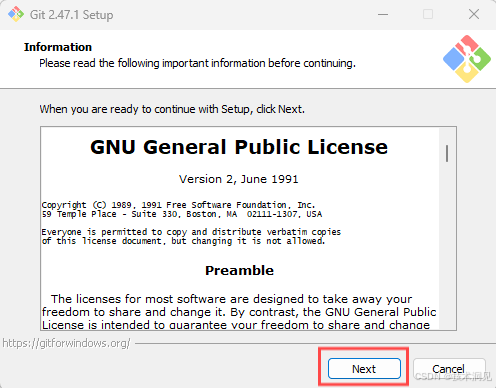
点击Next进行下一步。
2、选择安装路径
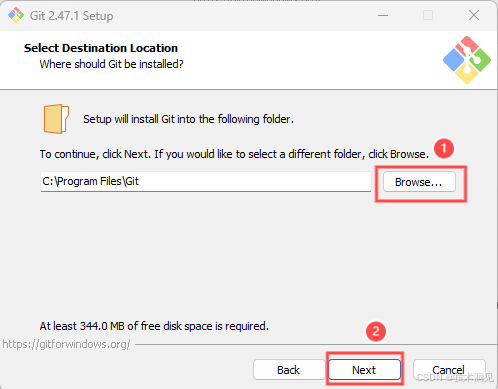
默认安装路径为C:\Program Files\Git,如需修改,点击①Browse选择文件夹,无需修改点击②Next进行下一步。
3、选择安装组件

①为在桌面上显示Git图标,可以勾选。其余默认选项不建议取消勾选,以免安装出现意外问题。如确认无误,点击②Next进行下一步。
4、在开始菜单中创建
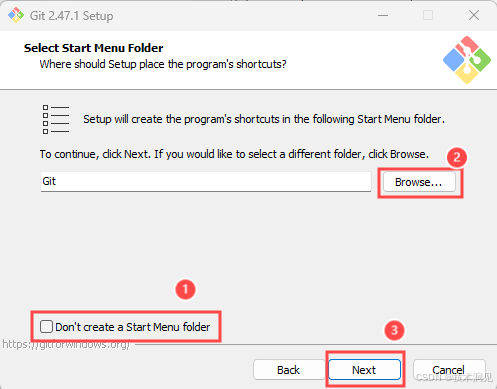
这一步是选择是否在开始菜单中添加Git选项,无需要添加,则勾选①选项;如选择其他文件夹,点击②Browse自行修改,无需修改点击③Next进行下一步操作。
5、选择Git默认编辑器
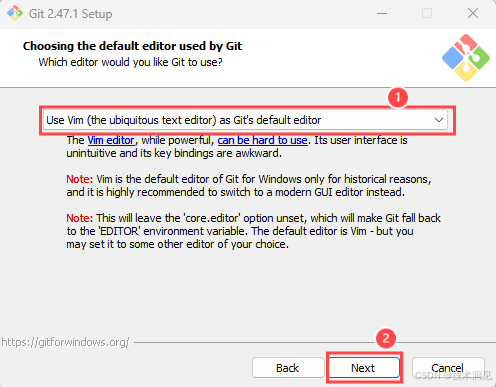
Git的默认编辑器为Vim,部分不熟悉Vim使用的童鞋可以点击①选择现代的GUI编辑器,如Notepad++等,无需修改点击②Next进行下一步。
6、选择仓库的初始分支
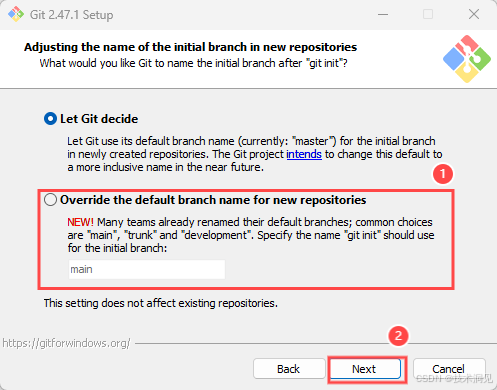
默认选项Let Git decide设置初始分支为master,如需修改,选择①Override the default branch name for new repositories单选按钮,并在main处修改分支名。点击Next。
7、选择PATH环境
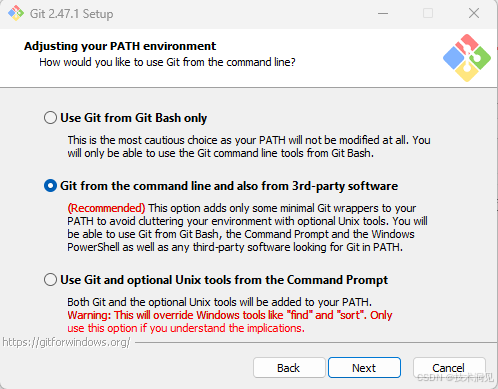
在这一界面,有三个可选选项:
(1)Use Git from Git Bash only
只能在Git Bash中使用Git,不能使用任何第三方工具。
(2)Git from the command line and also form 3rd-party software(默认推荐)
通过命令行及第三方工具使用Git。这一选项仅仅在PATH中添加了一些最小的Git wrapper,以避免使用可选的Unix工具造成环境混乱。能够从Git Bash、命令行、PowerShell以及在PATH中寻找Git的任何第三方软件中使用Git。这是推荐使用的方式!
(3)Use Git and optional Unix tools from the Command Prompt
通过命令行使用Git和可选的Unix工具,这有个警告:这将覆盖Windows工具,如“find 和sort ”。
8、选择ssh.exe
默认选项为使用Git自带的ssh.exe,也可以选择使用外部的OpenSSH。这里我们选择Use bundled OpenSSH
9、选择HTTP连接
默认为Use the OpenSSH library,使用OpenSSL库。点击Next。
10、配置行尾换行符
(1)Checkout Windows-style, commit Unix-style line endings
在检出(checkout)文本文件时,Git会将行尾符号 LF (Unix风格)自动转换为 CRLF (Windows风格)。而在提交(commit)文本文件时,Git会将行尾符号 CRLF 转换回 LF。这适用于跨平台项目,特别是在Windows环境下进行开发,并且希望在Windows上保留CRLF行尾符号的习惯。该选项需要将"core.autocrlf"设置为"true"。
(2)Checkout as-is, commit Unix-style line endings
检出文本文件时,Git不会执行任何行尾符号的转换,保持原样。但是在提交文本文件时,Git会将行尾符号 CRLF 转换为 LF。这适用于跨平台项目,特别是在Unix环境下进行开发,并且希望在提交时统一使用LF行尾符号。该选项需要将"core.autocrlf"设置为"input"。
(3)Checkout as-is, commit as-is
检出和提交文本文件时都不执行行尾符号的转换,保持原样。这个选项通常不推荐用于跨平台项目,因为不同操作系统使用不同的行尾符号(CRLF或LF)。如果项目中的文件包含不一致的行尾符号,可能会导致问题。该选项需要将"core.autocrlf"设置为"false"。
一般选择默认选项Checkout Windows-style, commit Unix-style line endings。
11、配置Git Bash使用的终端
(1)Use MinTTY
MinTTY具有可调整大小的窗口、非矩形选择以及Unicode字体的特性。它适用于与Win32控制台程序(如交互式Python或node.js)一起使用,并提供更好的兼容性和功能。在MinTTY环境下运行Windows控制台程序时,需要使用"winpty"来启动。
(2)Use Windows’ default console window
这个选项适用于与传统的Windows控制台程序一起使用,如交互式Python或node.js。然而,Windows默认控制台窗口的功能相对有限,默认的滚动回退(scroll-back)功能有限,需要配置Unicode字体才能正确显示非ASCII字符,并且在Windows 10之前,它的窗口大小不可自由调整,只允许矩形文本选择。
推荐使用默认的Use MinTTY。
12、创建git pull的默认行为
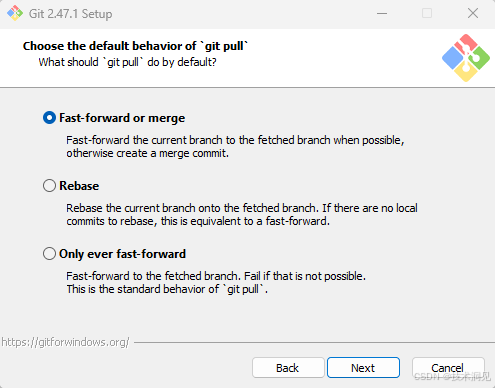
默认情况下,‘git pull’ 的行为取决于 git 配置中的 merge.default 参数。通常有以下三个选项可供选择:
Fast forward or merge: 这是’git pull’ 的标准行为:如果可能,将当前分支快进到被拉取的分支,否则创建一个合并提交。
Rebase: 将当前分支变基到被拉取的分支上。如果没有本地提交需要变基,则相当于快进操作。
Only ever fast-forward: 只进行快进操作,将当前分支快进到被拉取的分支。如果不可行,则操作失败。
默认情况下,大多数 git 库配置为执行 Fast forward or merge行为。这意味着在 ‘git pull’ 命令时,Git会尝试使用快进操作将当前分支更新到已拉取分支的最新状态。如果无法进行快进操作,例如存在冲突,Git将创建一个合并提交。
13、配置Git凭证
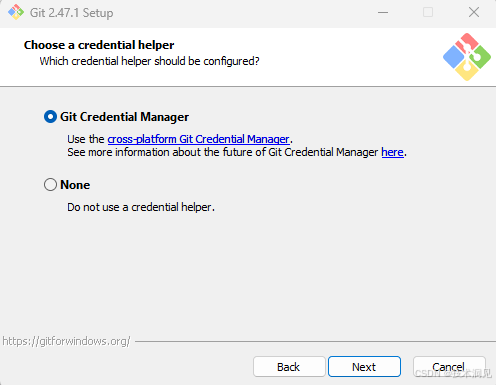
如果希望自动处理身份验证并避免频繁输入凭据,可以选择 Git Credential Manager。如果您更倾向于手动输入凭据或者使用其他凭据管理工具,则可以选择 None。这里我们选择Git Credential Manager。
14、配置额外选项
选择默认即可,点击Install进行安装。
15、等待安装完成
16、完成安装
点击Finish完成安装。
评论记录:
回复评论: