
线性回归原理:
线性回归应该是机器学习最基本的问题了。它是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析,这种函数是一个或多个称为回归系数的模型参数的线性组合,只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。如果数据集中的变量存在线性关系,那么其就能拟合地非常好。
那么如何从一大堆数据里面求出回归方程呢?既然是求“线性回归”,那么我们期望得到:
h
w
(
x
1
,
x
2
,
.
.
.
x
n
)
=
w
0
+
w
1
x
1
+
.
.
.
+
w
n
x
n
h_w(x_1, x_2, ...x_n) = w_0 + w_{1}x_1 + ... + w_{n}x_{n}
hw(x1,x2,...xn)=w0+w1x1+...+wnxn也就是说我们知道了x,y,怎么找到这些w呢?一个常见的方法就是找出使误差最小的w,这里的误差是指预测y和真实y之间的差值,使用该误差的简单累加使得正差值和负差值相互抵消,所以我们一般采用均方误差做它的“代价函数”J:
J
(
w
0
,
w
1
.
.
.
,
w
n
)
=
1
2
∑
i
=
0
m
(
h
w
(
x
0
,
x
1
,
.
.
.
x
n
)
−
y
i
)
2
J(w_0, w_1..., w_n) = \frac{1}{2}\sum\limits_{i=0}^{m}(h_w(x_0, x_1, ...x_n) - y_i)^2
J(w0,w1...,wn)=21i=0∑m(hw(x0,x1,...xn)−yi)2矩阵写法为:
J
(
W
)
=
1
2
(
X
W
−
Y
)
T
(
X
W
−
Y
)
J(\mathbf{W}) = \frac{1}{2}(\mathbf{XW} - \mathbf{Y})^T(\mathbf{XW} - \mathbf{Y})
J(W)=21(XW−Y)T(XW−Y)
然后求导令其为零可解出即可,这就是最小二乘法。
W
=
(
X
T
X
)
−
1
X
T
Y
\mathbf{W} = (\mathbf{X^{T}X})^{-1}\mathbf{X^{T}Y}
W=(XTX)−1XTY
为什么损失函数前面乘了1/2?
为了在求导的时候,这个系数就不见了,从概率的角度解释有:
- 假设根据特征的预测结果与实际结果有误差E,那么预测结果wx和真实结果y满足下式:
y = W T X + E y=W^TX+E y=WTX+E
设误差E服从正态分布(根据中心极限定理,独立同分布的各变量微小且服从正太分布),那么可知x和y的条件概率:
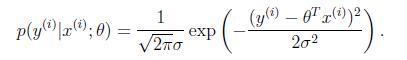
那么每预测一个值就会有一个误差,但概率认为是同一个。所以只需要对这个概率积做最大似然估计求参,求导可得原损失函数。
J
(
W
)
=
1
2
(
X
W
−
Y
)
T
(
X
W
−
Y
)
J(\mathbf{W}) = \frac{1}{2}(\mathbf{XW} - \mathbf{Y})^T(\mathbf{XW} - \mathbf{Y})
J(W)=21(XW−Y)T(XW−Y)
**补充:利用最小二乘法的矩阵解法对W求导,可得
X
T
(
X
W
−
Y
)
=
0
X^{T}(XW-Y)=0
XT(XW−Y)=0则要估计的参数
W
=
(
X
T
X
)
−
1
X
T
y
W=(X^TX)^{-1}X^Ty
W=(XTX)−1XTy
此处使用求导公式和链式法则。矩阵的求导一是默认为列向量,二是默认对矩阵所有求导,三是因为是矩阵,所以照搬代数里面的求导是不行的,往往不可乘或者不满足雅各比公式,所以多用转置来解决这种问题,于是就有:
∂
∂
X
(
X
T
X
)
=
2
X
\frac{\partial}{\partial\mathbf{X}}(\mathbf{X^TX}) =2\mathbf{X}
∂X∂(XTX)=2X
∂
∂
W
(
X
W
)
=
X
T
\frac{\partial}{\partial\mathbf W}(\mathbf{XW}) =\mathbf{X^T}
∂W∂(XW)=XT
∂
∂
W
(
W
T
X
)
=
X
\frac{\partial}{\partial\mathbf W}(\mathbf{W^TX}) =\mathbf{X}
∂W∂(WTX)=X
∂
∂
W
(
W
T
X
W
)
=
2
X
W
\frac{\partial}{\partial\mathbf W}(\mathbf{W^TXW}) =\mathbf{2XW}
∂W∂(WTXW)=2XW
算法实现:(Python):
def Regres(X,Y):
x = mat(X); y = mat(Y).T
if linalg.det(x.T*x) == 0.0:#判断行列式是否为0
print ("矩阵行列式为0,不可逆")
return 0
else return ((x.T*x).I * (x.T*y))#返回为已经求出的w,其中I为求逆操作
- 1
- 2
- 3
- 4
- 5
- 6
**注:上述函数中的X为便于之后矩阵的运算将偏置值b也纳入X的格式,即X=[[1.0,2.0],[1.0,3.0],[1.0,6.0]],前一个值恒为偏置值,后一个为x坐标。
矩阵不可逆怎么办?梯度下降法
刚刚推导过程的解可以直接用公式求解,一般这类解叫做解析解(analytical solution)。但是其他大多数算法,特别是深度学习模型往往并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值,这类解叫做数值解(numerical solution)。比如可以用随机梯度下降法来尽可能的线性 逼近,其求解迭代公式为:
W
=
W
−
α
X
T
(
X
W
−
Y
)
\mathbf{W}= \mathbf{W} - \alpha\mathbf{X}^T(\mathbf{XW} - \mathbf{Y})
W=W−αXT(XW−Y)线性逼近不能知道极值点在什么地方,但是能指引最小极值点的方向,便是“梯度”的含义,其中的
α
\alpha
α是梯度学习的学习率。更多的梯度下降问题在文末补充。
两者有什么区别?辨析梯度下降和正规方程(最小二乘)
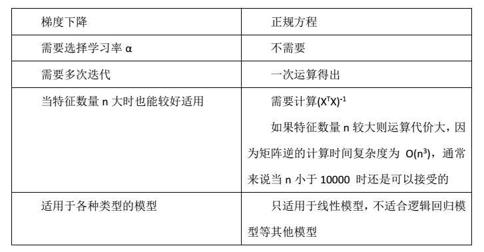
最小二乘法需要计算逆矩阵,然而它的逆矩阵可能不存在,无法求解,而此时梯度下降法仍然可以使用。不过如果你想,是可以通过去掉冗余特征使行列式不为0,然后使用的。
拟合结果不满意?欠拟合问题
线性回归很可能会出现欠拟合的现象,局部加权线性回归(Locally Weighted Linear Regression,LWLR),它是一个非参数模型,因为每次进行回归计算都要遍历训练集至少一次。该算法中给待预测点附近的 每一个点(即局部的含义) 都赋予了一点的权重,然后再进行一般的线性回归。参数W计算变为:
W
=
(
X
T
W
X
)
−
1
X
T
W
Y
\mathbf{W} = (\mathbf{X^{T}WX})^{-1}\mathbf{X^{T}WY}
W=(XTWX)−1XTWY
算法实现:(Python)
def lwlr(testPoint,xArr,yArr,k=1.0):#对某点赋予一个权重,k控制指数衰减速度
xMat = mat(xArr); yMat = mat(yArr).T
m = shape(xMat)[0]#得到矩阵阶数
weights = mat(eye((m)))#对角矩阵记录点间权值
for j in range(m):#更新点间权值
diffMat = testPoint - xMat[j,:]
weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2))#距离越远,权重越小(高斯核)
xTx = xMat.T * (weights * xMat)
if linalg.det(xTx) == 0.0:
print ("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T * (weights * yMat))#矩阵法计算w
return testPoint * ws#相乘以该点的返回预测值
def lwlrTest(testArr,xArr,yArr,k=1.0): #对每个点进行预测
m = shape(testArr)[0]
yHat = zeros(m)#初始化预测矩阵
for i in range(m):#调用lwlr函数遍历每一个点进行预测
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
return yHat

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
拟合效果不满意?过拟合问题
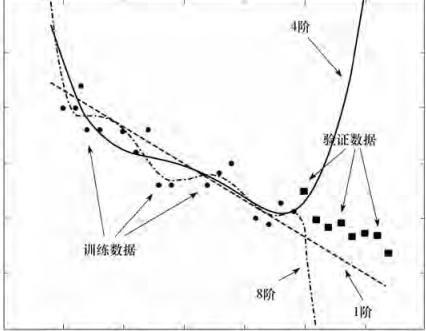
从上图可以看到不同阶数的选择导致拟合的程度的不同。过拟合则反映的是在学习训练中,对训练集达到非常高的逼近精度,但对非测试集的逼近误差随着训练次数而呈现先下降,后反而上升的奇异现象。
产生原因:迭代次数太多导致拟合了训练数据中的噪声,反而忽略了真实输入输出的关系。
解决方法:过拟合是机器学习所面临的关键障碍,不可避免,只能减少影响。
- 1.丢弃部分特征。(PCA等)
- 2.正则化(Regulation),保留特征,减少参数大小。(注意:0不会不参加任何一个正则化)
L1与L2正则化
正则化其实就是一种对过多回归系数采取惩罚以减少过拟合风险的技术。一般是在原损失函数上加上范数,一般有L0,L1,L2。L0相当于直接限制了参数个数,虽然直观但是不易求解。使用L1范数(也称曼哈顿距离或Taxicab范数,只允许在与空间轴平行行径的距离)又叫lasso回归,损失函数变为:
J
(
W
)
=
1
2
n
(
X
W
−
Y
)
T
(
X
W
−
Y
)
+
α
∣
∣
W
∣
∣
1
J(\mathbf{W}) = \frac{1}{2n}(\mathbf{XW} - \mathbf{Y})^T(\mathbf{XW} - \mathbf{Y}) + \alpha||W||_1
J(W)=2n1(XW−Y)T(XW−Y)+α∣∣W∣∣1
注意上式因为使用的是L1范数,所以得有样本数n。 α \alpha α用于调整惩罚力度,其选择很重要,下图可以看出W和 α \alpha α之间的“惩罚”关系:
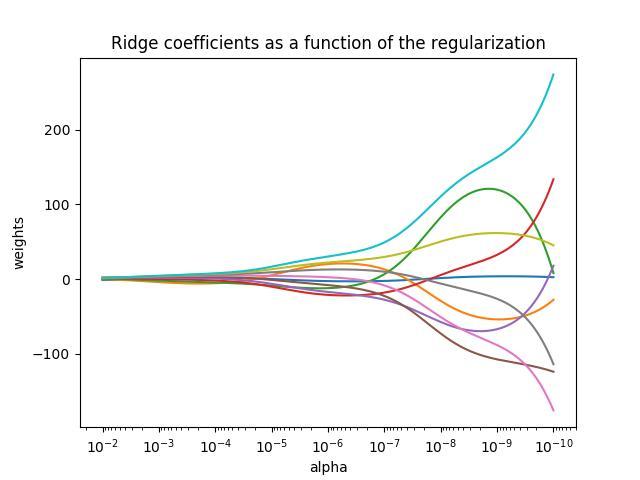
alpha越大时,权重接近0,也更接近于线性变换。
使用L2范数(也称欧几里德距离,是向量到原点的最短距离)又叫ridge回归,损失函数变为:
J
(
W
)
=
1
2
(
X
W
−
Y
)
T
(
X
W
−
Y
)
+
1
2
α
∣
∣
W
∣
∣
2
2
J(\mathbf{W}) = \frac{1}{2}(\mathbf{XW} - \mathbf{Y})^T(\mathbf{XW} - \mathbf{Y}) + \frac{1}{2}\alpha||W||_2^2
J(W)=21(XW−Y)T(XW−Y)+21α∣∣W∣∣22
此时的算法实现变为:(Python)
def ridgeRegres(Xt,Y,lam=0.2):
denom =X.T*X + eye(shape(X)[1])*lam
if linalg.det(denom) == 0.0:
print ("矩阵行列式为0,不可逆 ")
return
else return denom.I * (X.T*Yt)
- 1
- 2
- 3
- 4
- 5
- 6
L2的优点是可以限制|w|的大小,从而使模型更简单,更稳定,即使加入一些干扰样本也不会对模型产生较大的影响。而且还能解决非正定的问题,强制使XTX可逆有解。 θ = ( X X T + α I ) − 1 X Y \theta=(XX^T+\alpha I)^{-1}XY θ=(XXT+αI)−1XY
L1能使得一些特征的系数变小,甚至还是一些绝对值较小的系数直接变为0,产生稀疏解,起到特征选择的作用,增强模型的泛化能力。
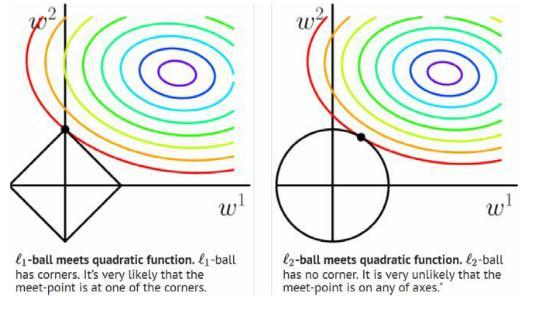
在上图中,两个坐标分别是要学习到的两个参数w1和w2。彩色线是损失函数J的等高线即损失值相等,方形和圆形就分别是L1和L2所产生的额外误差(约束空间),最后的目标要是两者最小,即要得到能使两者相加最小的点,也就是图中的黑色交点。在画等差图时,L1的的效果就很容易与坐标轴相交了,这就是会产生很多0,造成参数稀疏的原因,而且同时如果给一个微小的偏移,L2移动不会很大,而L1可能会移动到方形边上产生很多的交点,这也就是它不稳定的理由了。
l2倾向于w的分量取值更均衡,即非零分量个数尽量稠密,而l0和l1倾向w分量稀疏,即非零分量个数尽量少。所以从图可以看出L1的边缘比较尖锐,与目标函数的等高线相交时,交点会常在那些尖锐的地方,所以很多的参数就是0,即L1能产生稀疏解。所以在调参时如果我们主要的目的只是为了解决过拟合,一般选择L2正则化就够了。但是如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化。另外,如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。
L1正则化损失函数不可微,所以优化方法常用的有坐标轴下降法和最小角回归法。L2可微,所以和普通的求法一样。
前向逐步回归方法
但是它可能会出现处处可导但导数不连续的问题,所以要用前向逐步回归方法(forward stagewise regression)求解。前向逐步回归是一种贪心算法,一开始所有的权重都设为1,然后每一步所做的决策是对某个权重增加或减少一个很小的值。

算法实现(Python)
def regularize(X):#标准化
inMat = X.copy()
inMeans = mean(inMat,0)
inVar = var(inMat,0)
inMat = (inMat - inMeans)/inVar
return inMat
def rssError(yArr,yHatArr): #计算均方误差大小
return ((yArr-yHatArr)**2).sum()
def stageWise(xArr,yArr,eps=0.01,numIt=100):
xMat = mat(xArr); yMat=mat(yArr).T
yMean = mean(yMat,0)
yMat = yMat - yMean
xMat = regularize(xMat)
m,n=shape(xMat)
ws = zeros((n,1)); wsTest = ws.copy(); wsMax = ws.copy()
for i in range(numIt):
print (ws.T)
lowestError = inf;
for j in range(n):
for sign in [-1,1]:#增加或减少的影响
wsTest = ws.copy()
wsTest[j] += eps*sign
yTest = xMat*wsTest
rssE = rssError(yMat.A,yTest.A)
if rssE < lowestError:
lowestError = rssE
wsMax = wsTest
ws = wsMax.copy()
#returnMat[i,:]=ws.T
#return returnMat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
总结一下Regulation的作用:它的出现使函数在数值上更容易求解,在特征数目大时更稳定。通过调节 α \alpha α来调配,控制模型的复杂度减小,光滑性更好,复杂性越小且越光滑的目标函数泛化能力越强。系数越小,模型越简单,而泛化能力越强。
对比问题开头提出的两种方法,在单单需要减少过拟合时不建议用PCA,因为它的处理并不考虑任何与结果变量有关的信息,因此可能会丢掉重要的特征,而正则化处理会考虑到结果变量,不会丢失重要的数据。
LR应用:
sklearn里面的Diabetes数据集有442位病人的生理数据以及一年以后的病情发展情况。前十个数据分别表示年龄,性别,体质指数,血压和六种血清的化验数据。
[[ 0.03807591 0.05068012 0.06169621 …, -0.00259226 0.01990842
-0.01764613]
[-0.00188202 -0.04464164 -0.05147406 …, -0.03949338 -0.06832974
-0.09220405]
[ 0.08529891 0.05068012 0.04445121 …, -0.00259226 0.00286377
-0.02593034]
…,
[ 0.04170844 0.05068012 -0.01590626 …, -0.01107952 -0.04687948
0.01549073]
[-0.04547248 -0.04464164 0.03906215 …, 0.02655962 0.04452837
-0.02593034]
[-0.04547248 -0.04464164 -0.0730303 …, -0.03949338 -0.00421986
0.00306441]]
数据归一化处理过,不过这并不影响其代表的信息。
from sklearn import datasets
from sklearn import linear_model
linreg=linear_model.LinearRegression()
diabetes=datasets.load_diabetes()
x_train=diabetes.data[:-20]#前422位做训练集,剩余20做测试集
y_train=diabetes.target[:-20]
x_test=diabetes.data[-20:]
y_test=diabetes.target[-20:]
linreg.fit(x_train,y_train)
print(linreg.predict(x_test))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
[ 197.61846908 155.43979328 172.88665147 111.53537279 164.80054784
131.06954875 259.12237761 100.47935157 117.0601052 124.30503555
218.36632793 61.19831284 132.25046751 120.3332925 52.54458691
194.03798088 102.57139702 123.56604987 211.0346317 52.60335674]
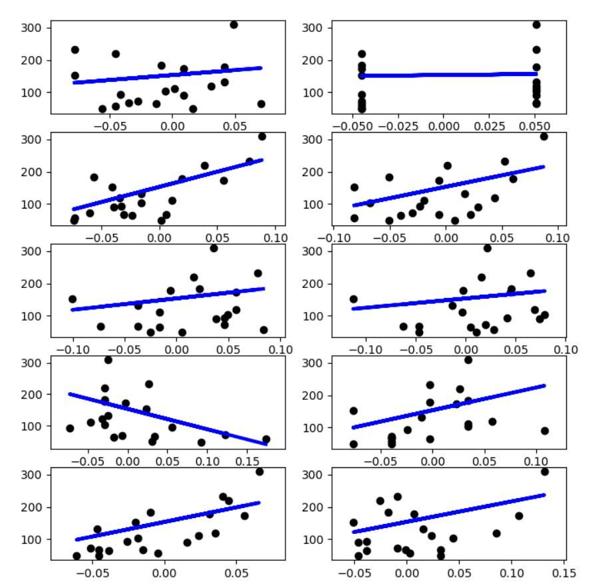
研究单个特征
from sklearn import datasets
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
linreg=linear_model.LinearRegression()
diabetes=datasets.load_diabetes()
x_train=diabetes.data[:-20]#前422位做训练集,剩余20做测试集
y_train=diabetes.target[:-20]
x_test=diabetes.data[-20:]
y_test=diabetes.target[-20:]
plt.figure(figsize=(8,12))
for f in range(0,10):
xi_test=x_test[:,f]
xi_train=x_train[:,f]
xi_test=xi_test[:,np.newaxis]
xi_train=xi_train[:,np.newaxis]
linreg.fit(xi_train,y_train)
y=linreg.predict(xi_test)
plt.subplot(5,2,f+1)
plt.scatter(xi_test,y_test,color='k')
plt.plot(xi_test,y,color='b',linewidth=3)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
用Tensorflow也可以做一个简单的:
import tensorflow as tf
import numpy as np
x_data=np.float32(np.random.rand(2,100))
y_data=np.dot([0.100,0.200],x_data)+0.300
b=tf.Variable(tf.zeros([1]))
w=tf.Variable(tf.random_uniform([1,2],-1.0,1.0))
y=tf.matmul(w,x_data)+b
loss=tf.reduce_mean(tf.square(y-y_data))
optimizer=tf.train.GradientDescentOptimizer(0.5)
train=optimizer.minimize(loss)
init=tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
for step in range(0,201):
sess.run(train)
if step %20==0:
print (step,sess.run(w),sess.run(b))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其他问题
-
1.普通最小二乘法( Ordinary Least Square,OLS)的回归,在实际运用中可能产生的异方差性(heteroscedasticity)。经典线性回归模型的一个重要假定是:总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差,所以OLS的结果会是线性、无偏、有效估计量。如果不满足,则称线性回归模型存在异方差性。即:
(1)单调递增型:随X的增大而增大,即在X与Y的散点图中,表现为随着X值的增大Y值的波动越来越大
(2)单调递减型:随X的增大而减小,即在X与Y的散点图中,表现为随着X值的增大Y值的波动越来越小
(3)复杂型:与X的变化呈复杂形式,即在X与Y的散点图中,表现为随着X值的增大Y值的波动复杂多变没有系统关系。
##此时需要及时检验数据,模型,否则最后的结果将不具有可信性!(常见在金融这种数据干扰源很多的场景)
##检测方法:图示,Park和Gleiser检验,Goldfeld-Quandt检验,White检验。 -
2.回归模型中的多重共线性问题。
即回归模型中使用两个或以上的自变量彼此相关时,则称回归模型中存在多重共线性(multicollinearity)。同样也需要诊断因子再做处理。如方差膨胀因子(Variance Inflation Factor,VIF),经验判断方法表明:当0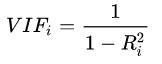
即变量 i 与其他变量间的关系。或者spearman和pearson相关性系数也可以。
from scipy.stats import pearsonr
from scipy.stats import spearman
pearson(X,Y)
spearman(X,Y)
- 1
- 2
- 3
- 4
- 5
- 3.线性回归要求因变量服从正态分布?
在使用线性回归拟合函数时,数据应符合或近似正态分布,否则拟合函数将不正确。原因在于已经提前假设了数据噪声是服从均值为0的正态分布,所以因变量也必须服从时,推导才会成立。
随机梯度下降
普通的梯度计算需要求所有样本的和函数,然后再确定一个梯度最小的方向,在样本量非常大的时候,梯度的计算会非常的耗时。而学习率的选择不恰当也会使梯度要么收敛太慢要么振动太大。

随机梯度法就是为了解决第一个问题;过大的计算量。
- 批梯度下降(GD):就是一般的梯度下降
- 随机梯度下降(SGD):每次只使用一个样本进行梯度的计算,可以减少计算,容易跳出局部最小点,在逐渐缩小学习率的情况下收敛速度也跟GD差不多。
- 小批量随机梯度下降(mini batch SGD):每次使用一批样本进行梯度下降,比SGD更稳定,而且可以利用现有的很多矩阵优化工具,在深度学习上这种方法用的很多。
- 所以更多的优化方法将在深度学习一篇进行整理,包括Momentum、Adagrad、RMSprop和Adam等。
为什么不用牛顿法
牛顿法是利用切线来确定下一次的位置,故也可称为“切线法”。与GD相比,牛顿法是二阶收敛,自然收敛快,而且同样是局部算法,牛顿法会更加的细致,不但考虑了方向还兼顾了移动的步长。
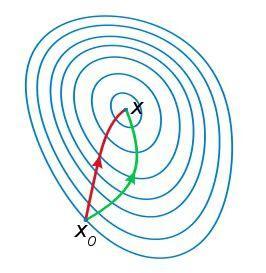
牛顿法要求计算二阶导数即Hessian matrix,在高维度下计算量非常大,而且在小批量训练时,牛顿法对二阶导的估计噪音太大。不过在目标函数非凸时,牛顿法更容易收敛到鞍点或者最大值点。参考wiki的解释是牛顿法是一个用二次曲面去拟合当前位置的局部曲面,相对来说二次曲面要比平面更好,下降路径也自然更好。如下图。
拟牛顿法
使用牛顿法需要的计算量较大,所以为了避免计算二阶矩阵。往往采用DFP算法,BFGS算法等拟牛顿法来求解。
共轭梯度
它介于GD和牛顿法之间,仅需要一阶导,但又克服了GD收敛慢的特点,存储量小,逐步收敛,稳定性高,不需要任何外来参数。是解决大型非线性最优化的最后算法之一,是最后。
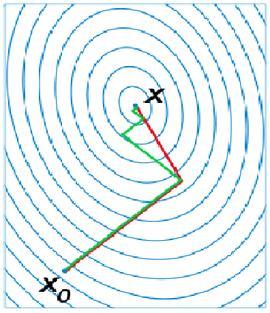
简单来说,它的每一个搜索方向是互相共轭的,而这些搜索方向d仅仅是负梯度方向与上一次迭代的搜索方向的组合,因此,存储量少,计算方便
题库来源:安全生产模拟考试一点通公众号小程序
2024年金属非金属矿山(地下矿山)安全管理人员证模拟考试题库及金属非金属矿山(地下矿山)安全管理人员理论考试试题是由安全生产模拟考试一点通提供,金属非金属矿山(地下矿山)安全管理人员证模拟考试题库是根据金属非金属矿山(地下矿山)安全管理人员最新版教材,金属非金属矿山(地下矿山)安全管理人员大纲整理而成(含2024年金属非金属矿山(地下矿山)安全管理人员证模拟考试题库及金属非金属矿山(地下矿山)安全管理人员理论考试试题参考答案和部分工种参考解析),掌握本资料和学校方法,考试容易。金属非金属矿山(地下矿山)安全管理人员考试技巧经过题库老师和金属非金属矿山(地下矿山)安全管理人员已考过学员的汇总,相对有效而可行的复习方式就是对金属非金属矿山(地下矿山)安全管理人员的试题攻克,进行多方面的试题训练。2024金属非金属矿山(地下矿山)安全管理人员证模拟考试题库及金属非金属矿山(地下矿山)安全管理人员理论考试试题个人、培训学校进行考试前有效训练,确保学员学习后能顺利通过考试。

1、【单选题】“三同时”是指安全设施与主体工程同时设计、同时施工、()。( B )
A、同时结算
B、同时投入生产和使用
C、同时检修
2、【单选题】《民用爆炸物品购买许可证》应当载明许可购买的品种、数量、购买单位以及()。( C )
A、销售单位
B、购买时间
C、有效期限
3、【单选题】下列不属于企业安全文化建设评价指标基础特征的是()。( C )
A、经营环境
B、企业形象特征
C、安全环境
4、【单选题】事故信息的发布应该及时迅捷准确,因此预案里应明确由()向新闻媒体通报信息。( C )
A、企业主要负责人
B、事故现场当事人
C、事故现场指挥部
5、【单选题】井下主要排水设备,至少应由同类型的()台泵组成。( B )
A、2
B、3
C、4
6、【单选题】井下停电时,应采取的措施有()。( C )
A、内燃设备正常作业
B、井下正常进行爆破作业
C、立即采取应急措施
7、【单选题】人工呼吸,每分钟约吹气()次。( A )
A、12至16
B、8至10
C、4至6
8、【单选题】依据《安全生产事故隐患排查治理暂行规定》,生产经营单位()对本单位事故隐患排查治理工作全面负责。( A )
A、主要负责人
B、安全部门负责人
C、技术负责人
9、【单选题】依据《安全生产法》的规定,生产经营单位与从业人员订立协议,免除或者减轻其对从业人员因生产安全事故伤亡依法应承担的责任的,该协议无效;对生产经营单位的()处二万元以上十万元以下的罚款。( A )
A、主要负责人、个人经营的投资人
B、直接责任人、相关负责人
C、主要负责人、直接责任人
10、【单选题】依据《消防法》的规定,消防工作贯彻()的方针,坚持专门机关与群众结合的原则,实行防火安全责任制。( A )
A、预防为主、防消结合
B、安全第一、预防为主
C、综合治理、群防群治
11、【单选题】依据《职业病防治法》,任何单位和个人不得生产、经营、()和使用国家明令禁止使用的可能产生职业病危害的设备或者材料。( C )
A、出口
B、储存
C、进口
12、【单选题】依照《民用爆炸物品管理条例》的规定,非爆破员()进行爆破作业。( B )
A、特殊情况下可以
B、禁止
C、一般不可以
13、【单选题】在交接班、人员上下井时间内,提升机操作应由()。( C )
A、提升机司机操作,安全员在场监督
B、副司机操作,正司机在场监督
C、正司机操作,副司机在场监督
14、【单选题】在地下矿山采用崩落法采矿时,为控制上部围岩突然大量冒落产生冲击气浪和泥石流危害,下列措施中最有效的是()。( C )
A、回采完毕,及时封闭本分段溜井口
B、上分段回采应超前于下分段
C、按照规定保留足够的覆盖岩层
15、【单选题】在处理冒顶片帮事故过程中,始终要有专人监测()情况,监测有害有毒气体浓度变化情况,发现异常,立即撤出救援人员。( B )
A、风向
B、地压活动
C、温度
16、【单选题】在潮湿含水的炮孔中,宜采用具有防水性能的()炸药。( C )
A、铵梯
B、铵油
C、乳化
17、【单选题】垂直深度超过50m的竖井用作人员出入口时,应采用()升降人员。( B )
A、吊桶
B、罐笼或电梯
C、箕斗
18、【单选题】孔隙度大的岩层其特征往往表现为()。( B )
A、坚硬
B、含水较多,加强防排水
C、稳固
19、【单选题】存在跑矿危险的场所是()。( B )
A、天井
B、溜井
C、斜斗
20、【单选题】安全生产管理涉及企业中的所有人员、设备设施、物料、环境、信息等各种管理对象,其管理的基本对象是()。( C )
A、重大危险源
B、事故隐患
C、企业员工
21、【单选题】安全生产责任追究是国家法律规定的一项法定制度,根据责任人员在事故中承担责任的不同,分为直接责任者、主要责任者和()。( C )
A、间接责任者
B、次要责任者
C、领导责任者
22、【单选题】安全评价中常用()和参照事故类别的方法进行分类。( C )
A、系统分析
B、导致事故的间接因素
C、导致事故的直接原因
23、【单选题】尾矿库安全监测,()与人工巡查和尾矿库安全检查相结合。( C )
A、无所谓
B、不应
C、应
24、【单选题】尾矿库库址离选矿厂要近,最好位于选厂的()方向。( B )
A、上游
B、下游
C、中游
25、【单选题】扑救天然气火灾,可选择水(水流切封)、干粉、卤代烷、蒸汽、( )、二氧化碳等灭火剂灭火。( B )
A、氧气
B、氮气
C、一氧化碳
26、【单选题】工会依法组织职工参加本单位()的民主管理和民主监督,维护职工在安全生产方面的合法权益。( C )
A、退休养老
B、企业领导选举
C、安全生产工作
27、【单选题】斜井施工时,下列安全设施中不需要的是()。( B )
A、井口设与卷扬机联动的阻车器,井颈及掘进工作面上方分别设保险杠
B、井口设栏杆
C、斜井内人行道一侧设躲避硐
28、【单选题】某企业在生产经营活动中发生了死亡2人的生产安全事故。按《生产安全事故报告和调查处理条例》的规定,该事故应在规定的时限内上报至()安全生产监督管理部门和负有安全生产监督管理职责的有关部门。( C )
A、国务院
B、省级人民政府
C、设区的市级人民政府
29、【单选题】某年4月27日夜班,井下巷道掘进施工单位在放当班第二次炮的时候,作业人员认为更深夜静、不会有人进入工作面,爆破员张某和工人孙某留下连线放炮,其余人员去推矿车。孙、张二人连好炮线没有进行站岗警戒就准备放炮,此时瓦检员陈某从联络巷进入迎头,刚走到离迎头17m处,孙、张二人便通电放炮,炸起的煤块飞起击中陈某脸部,造成轻伤。根据上述事实,在以下的选择项中,不是爆破作业的要求所规定的是()。( C )
A、进行爆破作业时,必须遵守爆破安全操作规程
B、爆破后,必须对现场进行检查,确认安全后发出解除警戒信号
C、进行爆破作业必须由安全管理人员负责指挥
30、【单选题】根据《国务院安委会办公室关于贯彻落实<国务院关于进一步加强企业安全生产工作的通知>精神进一步加强非煤矿山安全生产工作的实施意见》,非煤矿山企业要设立专门安全管理机构,配备专职安全管理人员,其中地下矿山专职安全管理人员不少于()人。( A )
A、3
B、5
C、7
31、【单选题】根据《安全生产法》,生产经营单位对重大危险源应(),进行定期检测、评估、监管,并制定应急预案。( C )
A、公告公示
B、设置标识
C、登记建档
32、【单选题】《中华人民共和国特种设备安全法》规定,特种设备使用单位应当按照安全技术规范的要求,在检验合格有效期届满前( )向特种设备检验机构提出定期检验要求。( A )
A、一个月
B、二个月
C、三个月
33、【单选题】根据《安全生产许可证条例》,企业取得安全生产许可证后,疏于安全生产管理,不再具备本条例规定的安全生产条件的,颁证机关应当()安全生产许可证。( A )
A、暂扣或吊销
B、撤销
C、收回
34、【单选题】根据《金属非金属地下矿山安全避险“六大系统”安装使用和监督检查暂行规定》,()不属于金属非金属地下矿山安全避险“六大系统”。( A )
A、通风系统
B、井下人员定位系统
C、紧急避险系统
35、【单选题】根据《非煤矿矿山企业安全生产许,安 全生产模拟考试一 点通,可证实施办法》,非煤矿矿山企业不包括()。( B )
A、金属非金属矿山企业及其尾矿库
B、矿山建设项目监理单位
C、地质勘探单位
36、【单选题】每个矿井至少应由两个独立的直达地面的安全出口,安全出口的间距应不小于()m。( B )
A、50
B、30
C、100
37、【单选题】民用爆炸物品使用单位申请购买民用爆炸物品的,应当向所在地()人民政府公安机关提出购买申请。( B )
A、乡镇
B、县级
C、县级以上
38、【单选题】没有防尘供水管路的采掘工作面()生产。( B )
A、必须
B、不得
C、可以
39、【单选题】特种设备使用单位应当在特种设备投入使用前或者投入使用后()日内,向负责特种设备安全监督管理的部门办理使用登记,取得使用登记证书。( C )
A、7
B、15
C、30
40、【单选题】生产经营单位将生产经营项目、场所、设备发包或者出租给不具备安全生产条件或者相应资质的单位或者个人,导致发生生产安全事故给他人造成损害的,其责任的规定是()。( B )
A、生产经营单位承担全部责任
B、生产经营单位与承包方(承租方)承担连带赔偿责任
C、承包方(或承租方)承担全部责任
41、【单选题】生产经营单位应当定期组织安全生产管理人员、()和其他相关人员排查本单位的事故隐患。对排查出的事故隐患,应当按照事故隐患的等级进行登记,建立事故隐患信息档案,并按照职责分工实施监控治理。( B )
A、安全总监
B、工程技术人员
C、主要负责人
42、【单选题】生产经营单位编制安全技术措施计划的主要目的是()。( A )
A、保证资金的有效投入
B、保证责任制的落实
C、保证计划的可靠性
43、【单选题】用人单位应当及时安排对疑似职业病人进行诊断,在疑似职业病病人诊断或医学观察期间,不得解除或者终止与其订立的劳动合同,在诊断和医学观察期间的费用由()承担。( A )
A、用人单位
B、个人
C、主管部门
44、【单选题】矿井(竖井、斜井、平硐等)井口的标高,应高于当地历史最高洪水位()m以上。( B )
A、0.5
B、1
C、2
45、【单选题】矿井通风系统的矿井总风量、矿井有效风量、矿井有效风量率、机站风量、机站风压等应每()测定一次,遇到矿井生产或通风系统重大改变时亦应进行测定。( C )
A、月
B、季度
C、年
46、【单选题】矿山企业中,()对本企业的安全生产工作负责。( B )
A、班组长
B、矿长
C、安全员
47、【单选题】矿山企业安全标准化系统运行绩效内部评定工作应至少每()年进行一次。( A )
A、一
B、半
C、三
48、【单选题】矿山开采对区域地质要求是()。( B )
A、区域地质构造特征
B、构造特征和矿床在区域构造中的位置等
C、矿床在区域构造单元中的位置
49、【单选题】经验算,余推力法安全系数大于1.00小于设计规范规定值的排土场是()。( A )
A、病级
B、危险级
C、正常级
50、【单选题】老窿水的特点是()。( B )
A、埋藏深水量大,水压高来势猛,涌水量稳定不易排干
B、短时涌水量大,来势猛,具有很大的破坏性,容易造成淹井,常伴随有毒有害气体
C、水压可以很高,但水量较小
51、【单选题】胸外心脏按压法是抢救()伤员的有效方法。( B )
A、休克
B、心脏骤停
C、呼吸停止
52、【单选题】装卸爆破器材时应设置警卫,禁止()。( A )
A、无关人员在场
B、小孩入内
C、妇女参加
53、【单选题】非煤矿山企业主要负责人或主管负责人、技术总负责人()至少组织一次全面的、以隐患排查为主要内容的安全检查。对查出的各类隐患要进行登记,并切实做到整改措施、责任、资金、时限和预案五落实。( C )
A、每年
B、每季度
C、每月
54、【判断题】事故隐患排除前或者排除过程中无法保证安全的,应当从危险区域内撤出作业人员,并疏散可能危及的其他人员,设置警戒标志,暂时停产停业或者停止使用。( √ )
55、【判断题】井下不得使用电炉烘烤,可以使用灯泡取暖。( × )
56、【判断题】井下火灾事故往往都是由于火烟窒息致人死亡,因此,井下火灾事故发'安 全 生产 模 拟考试一点通'生后应重点灭火。( × )
57、【判断题】井下电机车的制动方式有两种,即电气制动和机械制动。( √ )
58、【判断题】从业人员在任何情况下都必须听从指挥,否则将会受到相应的处罚。( × )
59、【判断题】企业事故发生后,事故现场有关人员应当立即向本单位负责人报告;单位负责人接到报告后,应当于2小时内向事故发生地县级以上人民政府安全生产监督管理部门和负有安全生产监督管理职责的有关部门报告。( × )
60、【判断题】企业各级行政正职一直到班长都是安全生产责任制的第一责任人。( √ )
61、【判断题】企业应急响应能·安 全生产模 拟考试一点通·力的体现,应包括应急救援过程中一系列需要明确并实施在应急救援过程中的核心功能和任务。这些核心功能具有独立性,相互之间不应有联系。( × )
62、【判断题】低压电动机的控制设备,应具备短路、过负荷、单相断线、漏电闭锁保护装置及远程控制装置。( √ )
63、【判断题】升降人员或升降人员和物料用的提升机钢丝绳,自悬挂之日起,每年检验一次。( × )
64、【判断题】取得安全生产许可证的非煤矿矿山企业提供虚假证明文件或采取其他欺骗手段,取得安全生产许可证的,依法吊销其安全生产许可证。( √ )
65、【判断题】因受自然地理条件等因素的影响,矿山开采活动的空间和场所处在不断变化的过程中,工作环境和安全状况非常复杂,有的甚至十分恶劣,安全生产受到很大威胁。( √ )
66、【判断题】在需要支护的井巷中施工,中途停止掘进时,支护也应停下来。( × )
67、【判断题】大块石爆破时,如果块度大可布置几个孔,但必须同段爆破。( √ )
68、【判断题】实践出真知。经多次总结爆破经验后,爆破安全警戒范围可适当减小。( × )
69、【判断题】尾矿库建设项目包括新建、改建、扩建、闭库以及在用尾矿库回采再利用和闭库后再利用的尾矿库建设工程。( √ )
70、【判断题】尾矿库的勘察、设计、安全评价、施工及施工监理等应当由具有相应资质的单位承担。( √ )
71、【判断题】应急救援预案的全面演练,是针对应急救援预案中全部或大部分应急响应功能,检验、评价应急组织应急运行能力的演练活动。( √ )
72、【判断题】应急预案管理应遵循“综合协调、分类管理、分级负责、属地为主”的原则。( √ )
73、【判断题】应急预案编制完成后,生产经营单位应在广泛征求意见的基础上,对应急预案进行评审。正确的评审程序是:批准印发、评审准备、组织评审、修订完善。( × )
74、【判断题】建设项目安全设施竣工或者试运行完成后,生产经营单位应当委托具有相应资质的安全评价机构对安全设施进行验收评价,并编制建设项目安全验收评价报告。( √ )
75、【判断题】我国非煤矿山开采技术相对落后,装备水平低。( √ )
76、【判断题】所有矿井采区避灾线路上匀应敷设压风管路,并设置供气阀门,间隔不大于200m。( √ )
77、【判断题】承包单位不得拒绝发包单位的任何指挥和作业。( × )
78、【判断题】排土,最新解 析,场上游要有截洪沟,下游有拦挡坝,并留排水孔,以防发生泥石流。( √ )
79、【判断题】民用爆炸物品生产企业应当建立健全产品检验制度,保证民用爆炸物品的质量符合相关标准。( √ )
80、【判断题】氡及其子体在衰变过程中放射出的α、β、γ三种射线对人体无危害。( × )
81、【判断题】水害严重的矿山企业,应成立防治水的专门机构,开展防治水方面的调查、监测和预测预报工作。( √ )
82、【判断题】特种设备的使用单位应根据特种设备的不同特性制定相应的事故应急措施和救援预案。( √ )
83、【判断题】用人单位对未进行离岗前职业健康检查的劳动者,可以解除或终止与其订立的劳动合同。( × )
84、【判断题】用人单位应当为职工参加工伤保险,由用人单位和职工按照国家规定共同缴纳工伤保险费。( × )
85、【判断题】由地面到井下中央变电所或主排水泵房的电源电缆,至少应敷设两条独立线路,并应引自地面主变电所的不同母线段。( √ )
86、【判断题】甲乙采石场均为开采石灰岩的个体工商户,两个采石场相邻,矿区边界相距40m。2007年7月3日9点,甲采石场到镇民用爆破器材管理站用。安全生产模拟 考试一 点通。现金购买了2t炸药和其他爆破器材,11点装药完毕,剩余48kg炸药和30m导爆管,此时,乙采石场安全管理员邢某来到甲采石场,说自己采石场今天有一个大块矿石需要二次爆破破碎,向甲采石场借了2kg炸药和15m导爆管,并签署了借条。甲采石场将剩余的炸药和爆破器材退回镇民爆站。下午2点,乙采石场爆破大块矿石,没有发出爆破信号,飞石击中了甲采石场正在排险作业的工人关某头部,当时关某没有戴安全帽,当场重伤昏迷,在送往医院的途中死亡。根据上述描述,请判断以下说法是否正确,造成该事故的直接原因是爆破作业没有发出信号,撤离人员,造成飞石伤人。( √ )
87、【判断题】矿井应建立机械通风系统,对于自然风压较大的矿井,当风量、风速和作业场所空气质量满足《金属非金属矿山安全规程》的相关规定时,可以不建立机械通风系统,用自然通风替代。( × )
88、【判断题】矿山企业是落实领导带班下井制度的责任主体,必须确保每个班次至少有1名领导在井下现场带班,并与工人同时下井、同时升井。( √ )
89、【判断题】矿山企业的主要负责人对落实领导带班下井制度全面负责。( √ )
90、【判断题】血液常规检查不正常者,可以从事放射性矿山的井下作业。( × )
91、【判断题】装药时炸药的压装密度越大,装药量就越多,爆炸威力就越大。( × )
92、【判断题】触电伤员脱离电源后,如果神志清醒的话,可以立即站立和走动。( × )
93、【判断题】设计主平硐和主要运输巷道的断面时,要考虑运输能力,通风的要求,不用考虑通过坑内大件的要求。( × )
94、【判断题】购买民用爆炸物品的单位,应当自民用爆炸物品买卖成交之日起5日内,将购买的品种、数量向所在地县级人民政府公安机关备案。( × )
95、【判断题】进入有毒有害气体场所进行救护的人员要佩戴过滤式自救器或采取有效的通风措施。( × )
96、【判断题】违反《特种设备安全法》,使用未经检验或者检验不合格的特种设备的,责令停止使用有关特种设备,处三万元以上三十万元以下罚款。( √ )
97、【判断题】违反劳动纪律、擅自开动机械设备、擅自更改拆除、毁坏、挪用安全装置和设备造成事故的人员负直接责任或主要责任。( √ )
98、【判断题】采用空场法开采矿体,地下将留下大量的采空区,采空区面积越大,形成的时间越长,围岩崩落的可能性越大。( √ )
99、【判断题】雷雨季节宜采用电雷管起爆法起爆。( × )
100、【判断题】非煤矿矿山企业应当对其向安全生产许可证颁发管理机关提交安全评价报告、检测检验结果负责。( × )
支持全国各地区精准金属非金属矿山(地下矿山)安全管理人员考试试题,支持安全资格证,特种作业操作证,职业技能鉴定等工种题库练习。
评论记录:
回复评论: