
#详细的hive性能调优指导 #大数据 #离线数据库 #优化 #整理
整理耗时:3h
说明:此篇整理比较丰富 建议收藏学习
友情链接:Hive常见故障多案例维护宝典 --项目总结(宝典一)
目录
1.1 概述
1.1.1 模块架构模型
图1-1 Hive架构
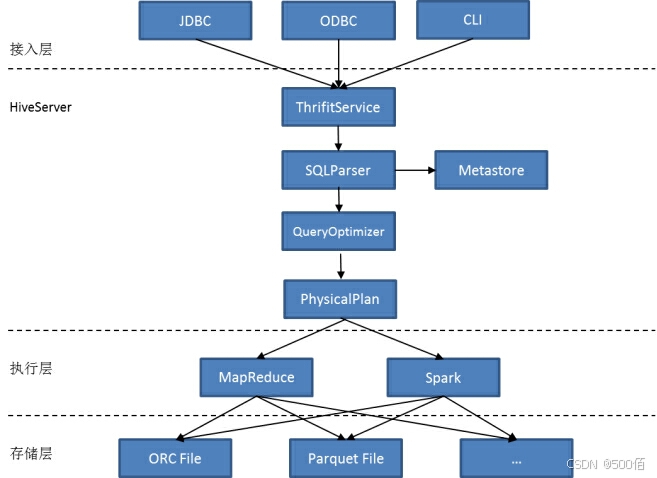
Hive提供了Hadoop的SQL能力,主要参考标准的SQL,Hive进行了部分的修改,形成了自己的特有的SQL语法HQL(Hive SQL),更加适合于Hadoop的分布式体系,该SQL目前是Hadoop体系的事实标准。
Hive的架构分为
接入层:体现为用户的接口,如JDBC,ODBC,CLI(command line interface)
HiveServer:Hive的主体部分,包括了词法解析,语法解析,逻辑优化和物理优化,HiveMetaStore。
执行层:主要有两个执行引擎,MapReduce和Spark。
存储层:目前Hive通过MapReduce/Spark访问HDFS可以支持多种存储格式,最主要的格式是ORC File和Parquet File。
用户输入HQL,Hive将HQL进行词法解析,语法解析,之后生成执行计划,并对执行计划进行优化,最后提交任务给YARN去执行。所以Hive的调优分为以下几个部分:
1. 接入层:主要包括用户的连接性能,如网络速度、认证、连接并发数。
2. HiveServer:以SQL的优化为主,执行计划是SQL优化的主要手段,通过接口查看Hive对整个SQL语句是如何进行任务的分解和编排,并结合MapReduce/Spark的执行情况针对性的进行任务的优化。
3. HiveMetaStore:因为Hive的MetaStore可能是外部的独立数据库,所以它的性能也会影响到整个HiveServer的性能,主要包括HiveMetaStore访问时间,访问次数,连接并发数。
4. MapReduce/Spark:以该组件进行执行时,MapReduce/Spark执行的情况直接引影响到Hive的性能,如每个任务的大小,任务与资源分配均匀度,任务拆分合理度等。
5.HDFS:最底层的IO读也是性能的关键,主要考虑的指标是读取和写入的性能,还包括块大小合理设置等。
其中MapReduce/Spark/HDFS组件有自己独立的调优文档,请参考对应组件的调优。本文档重点讨论上述的1,2,3部分的性能调优的内容,并结合MapReduce/Spark的进行调优说明。
2. 1性能衡量指标
2.1.1 衡量指标
衡量指标主要用于查看相应的指标来发现Hive服务或执行过程中的一些问题,尽快能定位Hive的性能问题。通常我们查看指标的顺序应该是通用指标,接入层指标,HiveMetaStore,HiveServer相关指标,其它相关组件的指标(如MapReduce/Spark/HDFS)。下面列举目前可查看到的相关指标信息:
1. 通用指标
主要是指通用的服务器的相关性能指标:CPU使用率,内存占用量,磁盘IO读写速度,使用Core数量等,通过这些指标可以衡量任务在该类型机器或该机器上的执行情况,观察集群各机器的通用指标,可以看到集群的负载是否均衡。
2. 接入层指标
Hive连接数,并行SQL数量,输入缓存值(或每批大小)。单HiveServer实例可以处理的最大并发数可以通过参数控制,默认是500,该参数主要受JVM内存和CPU的处理能力的限制。
3. HiveMetaStore
HiveMetaStore连接数,并行SQL数量,语句执行计划。
4. HiveServer
主要查看SQL语句的执行计划,进行SQL相关的调优,并结合MapReduce/Spark引擎的相关参数,主要是Job数量,Map数量,Reduce数量。
HiveServer编译生成MapReduce Task任务时对性能影响最大的两个因素是SQL语句涉及的表的分区数量和文件数量:
− 分区数量:单表的分区数量不能过多,分区信息是从HiveMetaStore读取,如果量太大,从HiveMetaStore的数据库读取分区信息比较慢。
− 文件数量:在生成MapReduce任务的时候,按读取文件大小进行分片,假设SQL语句涉及的表数据量达到100TB,一个文件128MB,一个块128MB,那么文件总数会达到10010241024/128=82万个文件,这么大量的文件,获取文件元数据信息需要时间,这些元数据读入内存,需要大量内存。
5. 通用测试标准
Hive性能上业界主要是拿TPC-DS来跟同类型的产品或者自己的老版本进行对比。标准测试仅做为性能测试的一些参考。
2.1.2 指标观测方法
1. 通用指标的观测
集群机器的CPU,内存,IO的使用情况可以通过FusionInsight Manager的主机管理界面查看到所有Host的资源使用情况。
2. 接入层指标的观测
FusionInsight Manger的服务->Hive服务状态页面可以查看到相关的HiveServer的连接数,HQL的执行成功的统计信息。
3. HiveMetaStore指标的观测
在FusionInsight Manager的服务->Hive服务状态页面,查看HiveMetaStore当前的请求连接数量以及关键API性能。
4. HiveServer相关指标的观测
这里主要以SQL调优为主,参考5.2.1 Hive的HQL调优。
3.1 集群服务部署规划
3.1.1 规格能力
HIVE当前支持的最大规格能力如下:
| 指标名 | 最大规格值 | 说明 |
|---|---|---|
| Max Files Per Table | 100万 | 单表最大文件数量 |
| Max Partitions Per Table | 1万 | 单表最大分区数量 |
| Total Tables | 1万 | 最大表数量 |
| Total Partitions | 300万 | 最大分区数量 |
| Max Sessions Per HiveServer | 500 | 单HiveServer最大并发数 |
上述规格参数仅作为参考,并不代表不能超过,但如果业务场景有超过这些规格,那么对性能影响比较大,需要在性能和业务能力上进行权衡。
3.2.1 环境要求
3.2.1.1 常见配置
服务器配置要求
常见推荐配置如下表
| 类型 | 节点数 | CPU | 内存 | 硬盘 | 网络 |
|---|---|---|---|---|---|
| HiveServer | 2 | 2u8 Cores | 128 GB | RAID1SAS≥600GB | 2*10Gb光口 |
| MetaStore | 2 | 2u8 Cores | 128 GB | RAID1SAS≥600GB | 2*10Gb光口 |
| WebHCat | 2 | 2u8 Cores | 128 GB | RAID1SAS≥600GB | 2*10Gb光口 |
4.1 典型业务的调优
Hive业务的业务主要以批量处理作业为主,同时也会做些交互式的查询。无论哪种情况调优的方法是类似的。
4.1.1 批处理业务
批处理主要特点是耗时时间长,消耗的资源比较多,主要的调优和设计推荐如下:
1. 尽量使用ORC File, 配上合适的压缩算法, 主要可选的压缩算法为Zlib和Snappy。其中Zlib压缩比高,但压缩解压时间比Snappy长,消耗资源比如Snappy多。Snappy平衡了的压缩比和压缩解压的性能。推荐使用Snappy。
2. 尽量使用Map Join减少Shuffle的次数,大幅提升性能
3. 不同SQL语句,完成同一个功能,生成Map Reduce的数量越少越好
4. Hive系统默认是典型的配置场景,结合业务实际情况,可以做一些参数的调整,如文件块的大小,Map个数与Reduce的个数,压缩算法等。
5. 合理的使用分区,分区数量不要太多,查询的SQL尽量指定具体的分区值;
具体请参考第5章节。
4.1.2 即席查询业务
即席查询业务当前主要是通过Hue或者JDBC,ODBC对接的工具,比如SAS,Cognos,Tableau进行交互查询,虽然这些工具可以通过标准接口对接Hive,但查询性能一般很难满足这类场景的需求,建议即席查询不使用Hive来操作。查询的性能主要通过对SQL的执行计划进行调优,请参考下文的HQL的调优细节。
5.1 二次开发业务应用指导
5.1.1 Hive的二次开发流程
通常数据进入Hadoop的处理流程大概如下:
1. 导入原始数据到HDFS:
原始业务的数据可能是在FTP服务器上,可能在本地磁盘上,可能在网络共享存储上, 可以通过Loader组件,HDFS API,HDFS 命令行工具将原始数据导入HDFS,或者通过Kafka,Flume等直接写入HDFS。
2. 格式转换(可选):
如果HDFS的数据格式不是列格式,建议通过Hive的SQL语句转换成列存储格式,如ORC格式,这样可以优化IO访问,合并小文件。
3. 针对性分析数据:
调用JDBC接口或者Beeline执行SQL语句对数据进行处理和转换,这里就是业务自己编写SQL语句,进行分析数据,生成结果。
4. 输出结果数据:
一般将结果数据导出到Relation Database,供其它的报表工具进一步使用,可以通过JDBC或直接从HDFS导出将数据转移到其它地方。
5.2.1 Hive的HQL调优
这一节讲解SQL语句优化,进行性能调优的开发人员,需要知道一些通常的原理,比如一个group by是一个MapReduce,一个join是一个MapReduce,一个order by是一个MapReduce。所以当一个SQL慢的时候,需要查看执行计划进行相应的调优。
5.2.2.1 HQL执行计划
Hive作为处理SQL的层,具体自己独特的SQL执行计划,查看SQL的执行计划能够快速了解SQL的执行过程,对于性能的调优会有很大的帮助。
Hive提供了Explain命令显示查询计划,语法如下:
EXPLAIN [EXTEENDED] query
EXPLAIN语句使用EXTENDED提供执行计划关于操作的的额外信息,如文件名。
EXPLAIN输出包括三个部分:
-
查询的抽象语法构
-
执行计划和计划的不同阶段之间的依赖关系
-
每个操作的描述,如FilterOperator,SelectOperator,FileSinkOperator
下面以例子的形式来看看Hive的执行计划的情况:
hive> explain select s.id, s.name from student s left outer join student_tmp st on s.name = st.name;
OK
ABSTRACT SYNTAX TREE: #抽象语法树
(TOK_QUERY (TOK_FROM (TOK_LEFTOUTERJOIN (TOK_TABREF (TOK_TABNAME student) s) (TOK_TABREF (TOK_TABNAME student_tmp) st) (= (. (TOK_TABLE_OR_COL s) name) (. (TOK_TABLE_OR_COL st) name)))) (TOK_INSERT (TOK_DESTINATION (TOK_DIR TOK_TMP_FILE)) (TOK_SELECT (TOK_SELEXPR (. (TOK_TABLE_OR_COL s) id)) (TOK_SELEXPR (. (TOK_TABLE_OR_COL s) name)))))
STAGE DEPENDENCIES: #依赖图
#这个sql将被分成两个阶段执行。基本上每个阶段会对应一个mapreduce job,Stage-0除外。因为Stage-0只是fetch结果集,不需要mapreduce job
Stage-1 is a root stage
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree: #map job开始
s
TableScan
alias: s #扫描表student
Reduce Output Operator #这里描述map的输出,也就是reduce的输入。比如key,partition,sort等信息。
key expressions: #reduce job的key
expr: name
type: string
sort order: + #这里表示按一个字段排序,如果是按两个字段排序,那么就会有两个+(++),更多以此类推
Map-reduce partition columns:
#partition的信息,由此也可以看出hive在join的时候会以join on后的列作为partition的列,以#保证具有相同此列的值的行被分到同一个reduce中去
expr: name
type: string
tag: 0 #用于标示这个扫描的结果,后面的join会用到它
value expressions: #表示select 后面的列
expr: id
type: int
expr: name
type: string
st
TableScan #开始扫描第二张表
alias: st
Reduce Output Operator
key expressions:
expr: name
type: string
sort order: +
Map-reduce partition columns:
expr: name
type: string
tag: 1
Reduce Operator Tree: #reduce job开始
Join Operator
condition map:
Left Outer Join0 to 1 #tag 0 out join tag 1
condition expressions: #这里也是描述select 后的列。这里我们的select后的列是 s.id 和 s.name, #所以0后面有两个字段, 1后面没有
0 {VALUE._col0} {VALUE._col2}
1
handleSkewJoin: false
outputColumnNames: _col0, _col2
Select Operator
expressions:
expr: _col0
type: int
expr: _col2
type: string
outputColumnNames: _col0, _col1
File Output Operator
compressed: false
GlobalTableId: 0
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Stage: Stage-0
Fetch Operator
limit: -1
Time taken: 0.216 seconds
5.2.2.2 除去多余的操作
操作场景
- CREATE TABLE clicks
- ( timestamp date,
- sessionID string,
- url string,
- source_ip string )
- STORED as ORC
- tblproperties (“orc.compress" = "SNAPPY");
-
- 比如上边这个表,如果要获取每一个sessionID最新的访问记录,可以这样写:
-
- SELECT clicks.*
- FROM clicks inner join ( select sessionID, max(timestamp) as max_ts
- from clicks
- group by sessionID) latest
- ON clicks.sessionID = latest.sessionID and clicks.timestamp = latest.max_ts;
语句解释:
查看执行计划会发现该语句会产生两个MapReduce,第一个MapReduce生成最新的sessionID信息表,第二MapReduce做一个Join,前面输出的结果与原表进行Join得到最后的结果。
再来看看下边的写法:
- SELECT *
- FROM ( SELECT *,
- RANK() over (partition by sessionID, order by timestamp desc) as rank
- FROM clicks
- ) ranked_clicks
- WHERE ranked_clicks.rank=1;
语句解释:
查看执行计划会发现只会有一个MapReduce,该语句将数据读出来对sesssionID进行分组并按时间进行倒序排序,最后过滤出排序后的第一条记录。
比较第一个语句和第二个语句,发现第二个语句减少了一次MapReduce操作,性能自然大幅提升。很明显第一个语句多余执行了一次Join操作,第二语句以分组排序替代了Join,除去了不必要的Join操作,带来了性能的提升。
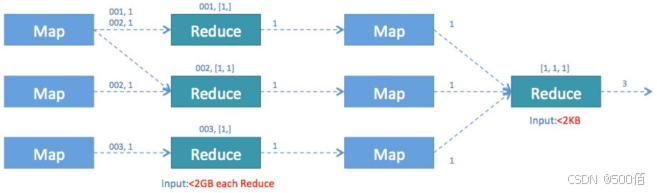
5.2.2.3 Distinct聚合优化
操作场景
SELECT COUNT( DISTINCT id ) FROM TABLE_NAME ;
优化前的问题:只有一个reduce处理全量数据,并发度不够,存在单点瓶颈。
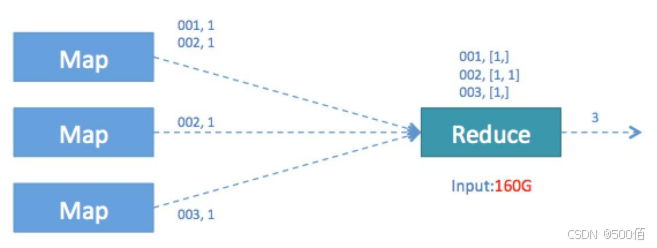
换种写法,reduce就会有多个,性能提升很多。
SELECT COUNT(*) FROM (SELECT DISTINCT id FROM TABLE_NAME ) t;
5.2.2.4 Order By
操作场景
默认情况下,Order By会生成一个Reduce进行全局排序,所以,一般要求Order By要加上Limit来使用,或者修改为Distribute By和Sort By 。
对于必须进行全量,全局排序的,可以考虑对数据进行抽样后,通过Distribute By和Sort By进行并行排序。
修改参数
| 参数名 | 描述 |
|---|---|
| hive.optimize.sampling.orderby | 默认是false |
| hive.optimize.sampling.orderby.number | 默认1000,抽取多少个样本 |
| hive.optimize.sampling.orderby.percent | 默认0.1,每条记录生成一个随机数,当随机数小于这个值时,选中该记录 |
5.2.2.5 Multi Insert
对于从同一份源表往不同的表中插数据,可以采用multi insert语法,减少job个数
- FROM (SELECT a.status, b.school, b.gender
- FROM status_updates a JOIN profiles b
-
-
- ON (a.userid = b.userid anda.ds='2009-03-20' )
- ) subq1
-
-
- INSERT OVERWRITE TABLE gender_summary PARTITION(ds='2009-03-20')
- SELECT subq1.gender, COUNT(1) GROUP BY subq1.gender
-
-
- INSERT OVERWRITE TABLE school_summary PARTITION(ds='2009-03-20')
- SELECT subq1.school, COUNT(1) GROUP BY subq1.school
上述查询语句使用了Multi-Insert特性连续insert了两张不同的表,减少了一轮MapReduce操作。
5.2.2.6 动态分区+distribute by
一般在从text转orc的时候,会用到动态分区,对于
- INSERT OVERWRITE TABLE T1 PARTITION(P1)
-
-
-
-
-
- SELECT C1,C2,P1FROM T2
最好对分区字段加上distribute by,否则最坏的情况就是,一个Task包含每个分区的数据,往每个分区插入数据,导致Task的内存溢出。
- INSERT OVERWRITE TABLE T1 PARTITION(P1)
-
-
-
- SELECT C1, C2, P1 FROM T2 DISTRIBUTE BY P1
6.1 性能调优常用方法
6.1.1 表模型优化
6.1.1.1 数据类型选择
操作场景
避免使用复杂的MAP,STRUCT等类型。
字段类型要精确,例如是INTEGER型的,不要定义成STRING。精确的类型可以让计算机CPU更快的处理。
6.1.1.2 表分区
操作场景
将数据分区,有助于减少查询时的数据量读取。例如按照天分区,那么按照时间跨度的查询,就可以通过排除掉一些分区,减少需要读取的文件数。
分区支持多层,即对多个字段分区,支持动态分区,使用动态分区请参考7.4.2.5 Multi Insert章节的注意事项;
单表的分区要尽量控制在1万以内,分区太多,会导致产生很多小文件,获取分区信息耗时等问题;
修改参数
| 参数名 | 优化描述 |
|---|---|
| hive.exec.dynamic.partition.mode | 默认值strict,修改值nonstrict; |
| hive.exec.max.dynamic.partitions | 默认值1000,最大动态partition的数量,可以根据分区的大小进行修改; |
| hive.exec.max.created.files | 默认值100000,一个MR job中最多可以创建文件的数量; |
6.2.1 文件格式
操作场景
表存储的文件格式有文本格式,有列存储类型的格式,对于Hive,建议使用列存储类型ORC File,虽然转化成ORC文件类型,需要多一些时间,但是,会让后边查询操作节省大量的时间。
修改参数
| 参数名 | 优化描述 |
|---|---|
| orc.compress | 默认值ZLIB |
6.3.1 小文件
操作场景
现在社区对于输入是小文件是没有自动合并功能,提供的合并命令,不够实用, 比如一个表有很多分区,需要对每个分区执行合并操作,我们暂时不建议用户用。
现在如果输入有小文件要合并,我们是建议用户先原始数据加载到hive表中,再启动一个MR从小文件临时表插入最终表,这个过程即解决小文件也解决文件存储格式(ORC + Snappy)。
对于输出,现在hive有参数控制多小的文件是小文件,对于输出的小文件是否要进行合并的参数,如下。
对于顺序执行的作业链,只有最后一张表的数据需要持久化,中间临时结果用完就删除的情况,可以在最后生成结果表之前开启下面参数,防止之前的作业也会生成合并任务使作业变慢。
修改参数
| 参数名 | 描述 |
|---|---|
| hive.merge.mapfiles | 默认为 True,是否合并 Map 输出文件 |
| hive.merge.mapredfiles | 默认为 False,是否合并 Reduce 输出文件 |
| hive.merge.size.per.task | 默认25610001000,合并后单个文件的大小 |
| hive.merge.smallfiles.avgsize | 默认16 * 1000 * 1000,文件平均大小小于该值时,认为需要合并 |
6.4.1 压缩格式
操作场景
通常来说压缩会对性能有提升,虽然消耗了一点CPU,但是节省了磁盘IO,节省了网络带宽。
对于ORC File文件,在定义表的时候,就指定了压缩类型。
对于中间结果,一般是Sequence File类型,因此可以指定中间文件的压缩类型和压缩算法;
修改参数
| 参数名 | 描述 |
|---|---|
| hive.exec.compress.output | 默认是false;对于文本文件格式,可以指定修改为true;orc文件类型不受此参数控制; |
| mapred.output.compression.codec | 默认是org.apache.hadoop.io.compress.DeflateCodec,建议改成org.apache.hadoop.io.compress.SnappyCodec |
| hive.exec.compress.intermediate | 中间结果是否进行压缩,默认是false |
| hive.intermediate.compression.codec | 默认为空,建议改成org.apache.hadoop.io.compress.SnappyCodec |
6.5.1 并行度控制
操作场景
SQL会转换成Map和Reduce,Map的数量由总数据量除以Map处理的数据量来定,Reduce的数量是总数据量除以Reduce处理的数量,不超过最大值。
修改参数
| 参数名 | 描述 |
|---|---|
| mapreduce.input.fileinputformat.split.maxsize | 默认256000000,map处理的最大数据量,一般不用改 |
| hive.exec.reducers.bytes.per.reducer | 默认256000000,reduce处理的最大数据量,一般不用改 |
| hive.exec.reducers.max | 默认999,对于集群比较大的情况,可以适当改大。 |
6.6.1Task内存
操作场景
默认情况下,每个Map和Reduce使用的最大内存都是4GB,堆内存是3GB。
原因如下: (说明格式:虽然分配了4G,但有时候任务实际可能只会到2G)
1. hive当前每个map处理的数据量是这个参数mapreduce.input.fileinputformat.split.maxsize控制的, 默认是256MB, 通常情况下,这个256MB是压缩文件,由于压缩文件压缩率不定,解压后数据量不同,对内存就会有不同的需求。
2. Hive有Mapjoin,Mapjoin是把小表加载到Map的内存中, 需要估计好加载后的内存,防止加载到内存过大导致内存溢出。
3. 数据可能有些微的倾斜情况,导致Reduce等处理的数据量变大,如果内存小会导致失败。
4. 对于大内存机器,可以尽量使用大的内存降低从内存刷磁盘的频率,这样可以减少IO。正确的做法应该是基于job的情况设置合适的内存,但是考虑到这样业务就需要花费更多的时间去调优, 因此配置成一个更大一点,更通用的值,保证job运行的稳定性。
修改参数
| 参数名 | 描述 |
|---|---|
| mapreduce.map.memory.mb | 默认4096,Map的YARN内存申请数量,单位MB |
| mapreduce.reduce.memory.mb | 默认4096,Reduce的YARN内存申请数量,单位mb |
| mapreduce.map.java.opts | 默认-Xmx2048M -Djava.net.preferIPv4Stack=true,Map的java堆大小 |
| mapreduce.reduce.java.opts | 默认-Xmx3276M -Djava.net.preferIPv4Stack=true,Reduce的java堆大小 |
| yarn.app.mapreduce.am.resource.mb | 默认1536,MapReduce引擎下,AM占用的YARN内存资源总数,必须不小于堆大小设置 |
| yarn.app.mapreduce.am.command-opts | 默认值-Xmx1024m -XX:CMSFullGCsBeforeCompaction=1 -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -verbose:gc任务task数很多时,比如task超过3万时,需要考虑增加AM的内存,以免AM由于内存不足拖慢整个任务,可以把Xmx改成3072m;MapReduce引擎下,AM 堆大小设置 |
7.1 其他性能调优常用方法
7.1.1 启用CBO
操作场景
Hive默认是逻辑优化器,在多表join的情况下可以考虑启用CBO(cost based optimization),hive将会根据已经收集好的表统计信息,自动选择代价较小的join顺序来执行。
CBO需要对表进行analysis,详细参考CPI文档。
修改参数
| *参数名* | *描述* |
|---|---|
| hive.cbo.enable | 默认是false,启用cbo需要修改成true; |
7.2.1 启用向量化
操作场景
现代CPU一般都支持SIMD(Single instruction, multiple data)等指令。通过向量化,可以使Hive利用现代CPU的这些高级特性,获得性能的提升
修改参数
| *参数名* | *描述* |
|---|---|
| hive.vectorized.execution.reduce.enabled | 默认是false,启用需要修改成true; |
最后
谢谢大家 整理较为详细 推荐收藏哟
@程序员500佰
评论记录:
回复评论: