
#Hive常见故障 #大数据 #生产环境真实案例 #Hive #离线数据库 #整理 #经验总结
说明:此篇总结hive常见故障案例处理方案 结合自身经历 总结不易 +关注 +收藏 欢迎留言
续写:Hive常见故障多案例FAQ宝典
【1】参数及配置类常见故障 详见(点击跳转):Hive常见故障多案例FAQ宝典 --项目总结(宝典一)
【2】任务运行类常见故障 详见(点击跳转): Hive常见故障多案例FAQ宝典 --项目总结(宝典一)
【3】SQL使用类常见故障 本章
目录
over(partition by orde by)使用同一字段,MapReduce任务运行慢
alter table drop partition删除大量分区慢、报错
SparkSQL没有group by的情况下使用having
insert into table values形式插入大量数据
SQL使用类常见故障 案例如下:
join中非常规join on写法导致任务运行慢
问题
两表join未写为标准的a join b on格式,使用a,b where a.*xx=b.xx*方式导致任务运行慢。
原因
该种SQL会造成笛卡尔积导致运行速度缓慢。针对该问题可以通过explain sql;打印执行计划,此时笛卡尔积的sql key为空,例如下图中keys0和1后无内容,代表没有key值:
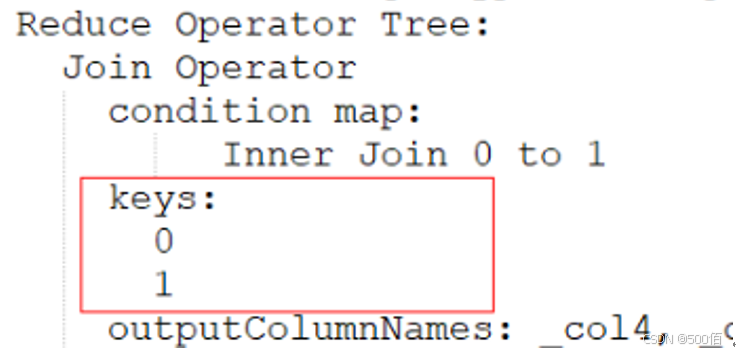
解决方法
修改为标准join on语法,例如:a join b on a.*xx=b.xx*,修改完可再次打印执行计划看“keys”处是否有值了,有值则修改成功。
视图中多表union all,视图外指定分区查询慢
问题
视图定义为多表union all时,表的分区数据类型不同时,在视图外指定分区条件查询很慢,出现全表扫描。
原因
视图定义为多表union all时,表的分区数据类型不同时(varchar类型长度不同也为类型不同),在视图外指定分区条件不会下推到视图的表里,而是全表扫描后再做过滤。是否是全表扫描可以使用explain sql;打印执行计划查看,可通过以下两点确认:
-
是否有分区筛选条件,有则为未下推,全表扫描。
-
统计信息很大时为未下推,全表扫描。
例如:
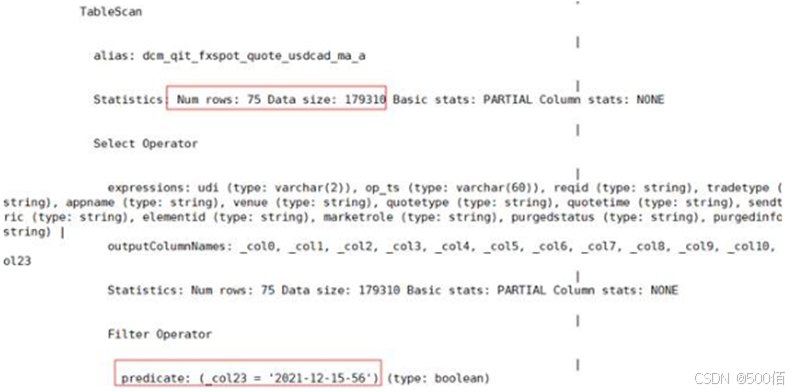
-
条件未下推,发生全表扫描执行计划:
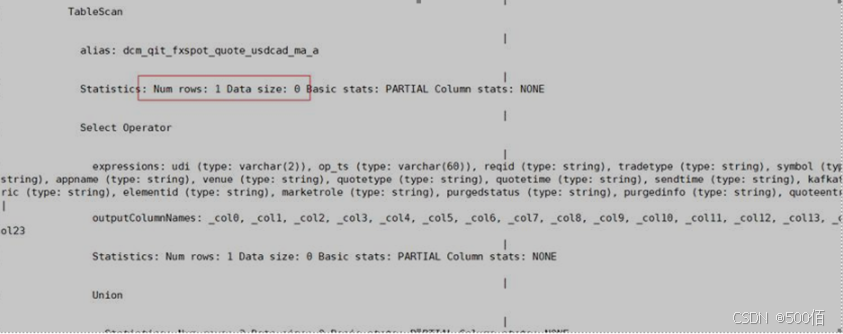
-
条件下推,未发生全表扫描的执行计划:
解决方法
-
在创建视图时指定好分。
-
视图中的表的分区字段类型相同。
over(partition by orde by)使用同一字段,MapReduce任务运行慢
问题
over(partition by order by)中partition by与order by后字段一样,MapReduce任务运行缓慢。
原因
该语法是按指定字段分区后按指定字段排序,partition by与order by字段一致时order by无意义。partition by order by为快速排序,在存在大量相同数据时,且partition by的分区多的情况下任务运行缓慢。
解决方法
-
修改partition by与order by为不同字段。
-
删除命令中的order by。
join on条件中使用or
问题
表关联中带有or条件例如“a join b on a.xx=b.xx or a.xx=b.xx”, 数据量大时启动的MapReduce任务缓慢。
原因
join on条件中带or,没有key会产生笛卡尔积,可以通过explain sql**;**查看执行计划key是否有值:
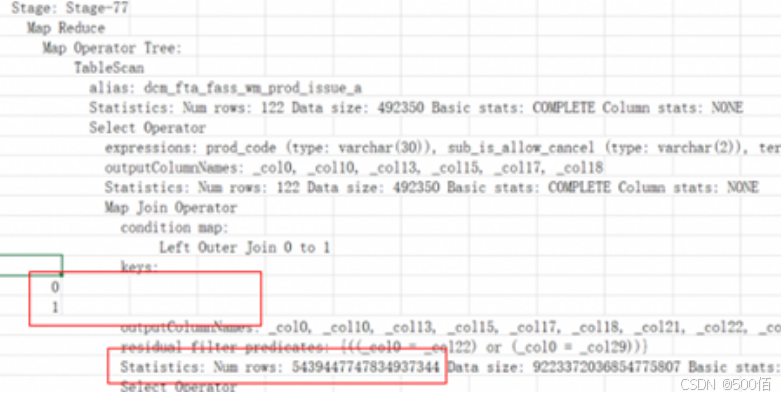
解决方法
删除命令中的or,使用union all方式拼接。
SQL扫描分区过多,元数据SQL拼接过长报错
问题
SQL扫描表分区过多,拼接的元数据SQL过长导致客户端返回或者HiveServer与MetaStore运行日志里出现如下报错:

原因
SQL扫描表分区过多。
解决方法
修改SQL,减少分区遍历量,当前可以正常遍历2000以下分区。
评论记录:
回复评论: