
前言
本文介绍6D位姿估计的方法FoundationPose,是CVPR 2024的满分论文,支持6D位姿估计和跟踪。
通过大规模的合成数据训练,具有强大的泛化能力,在测试新物体时,无需进行微调。
支持输入一些物体的RGBD图片,模型进行3D物体构建;生成多个假设的姿态,进行评分和排序得到最精准的姿态。
论文地址:FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
代码地址:https://github.com/NVlabs/FoundationPose

一、思路流程
FoundationPose的思路流程,如下图所示,看一下输入和输出:
- FoundationPose支持两种数据的输入,可以选择一些物体的RGBD图片,也可以直接输入物体的CAD模型。
- 其中,输入物体的RGBD图片,可以是4张、8张、16张等,模型会用基于SDF的NeRF构建物体的3D模型。
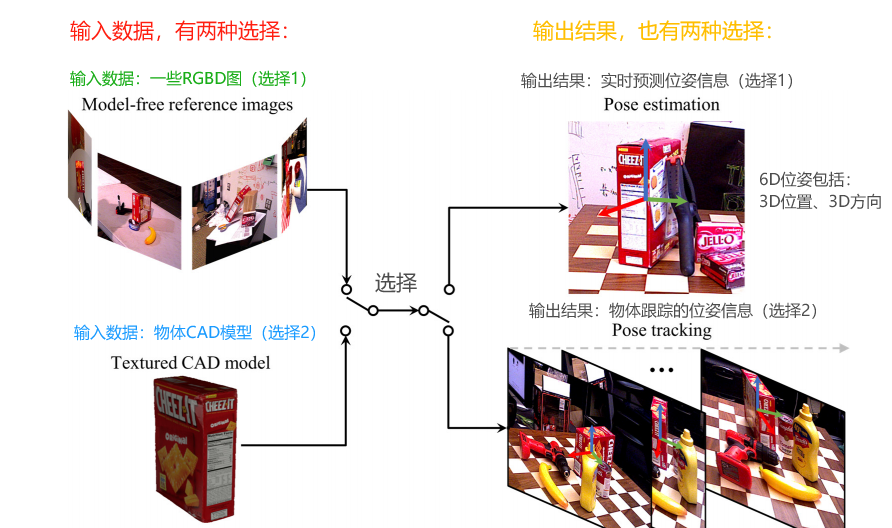
- 输出结果也有两种,一种是实时预测的位姿信息,另一种是使用跟踪算法计算出物体位姿信息。
- 看官方的demo代码,先对物体进行一次实时位姿预测,然后基础这个结果进行跟踪。
二、模型框架
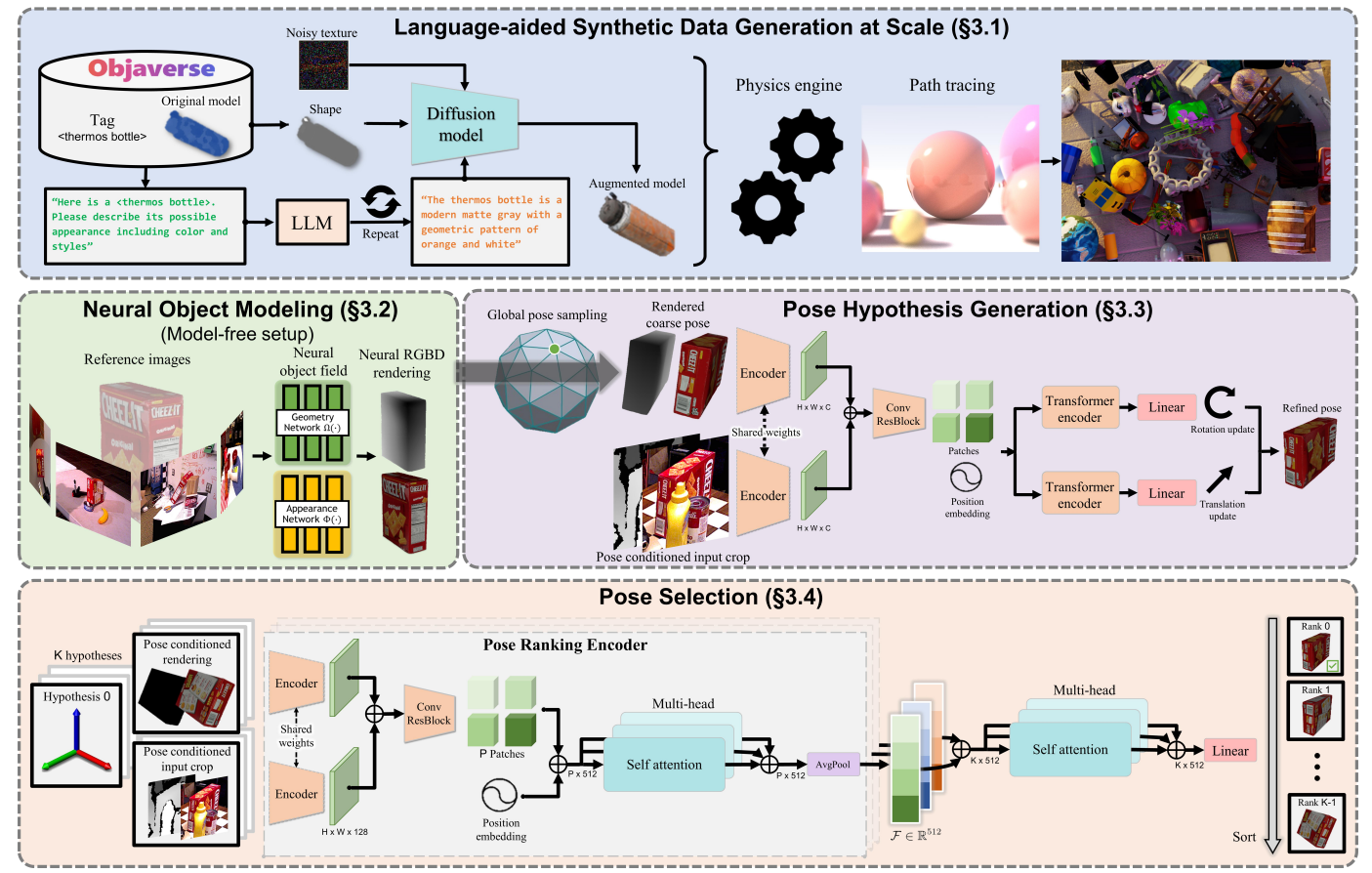
FoundationPose的模型框架,如下图所示:
- 基于大语言模型LLM和扩散模型,通过文字信息,引导生成指定的物体3D模型纹理和外观,生成大规模训练数据。
- 在没有物体的3D CAD模型的情况下,通过神经隐式场表示来进行高效的物体建模。
- 生成多个假设的姿态,主要有两步过程,生成初始姿态和姿态细化
- 最后选出最准确的姿态。
三、生成多个假设的姿态
姿态生成主要有两步过程,生成初始姿态和姿态细化,模型结构如下图所示:
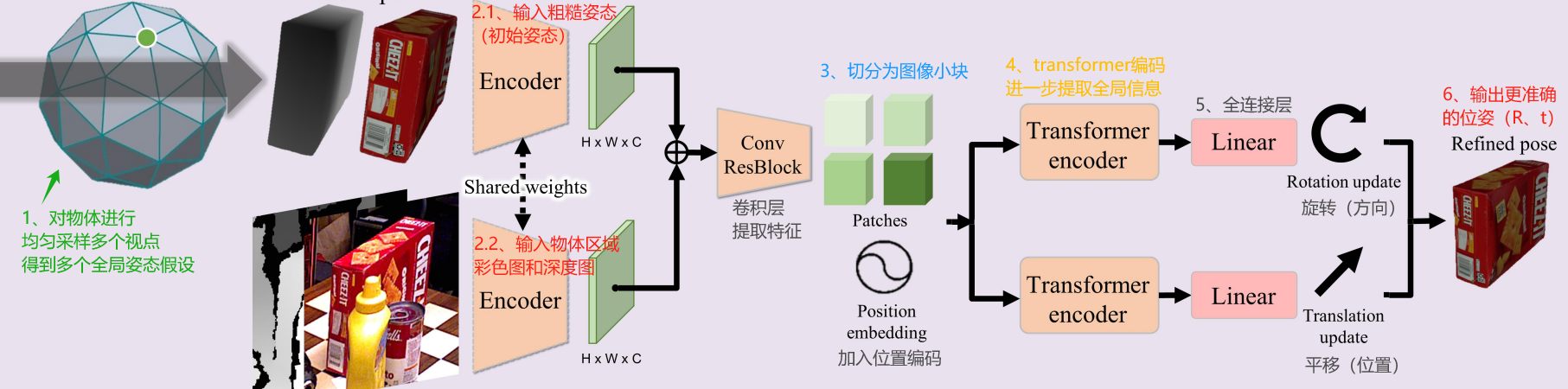
3.1、生成初始姿态
- RGBD图像: 使用RGBD图像来检测。
- 检测工具: 采用标准的对象检测方法(如Mask R-CNN或CNOS)来识别图像中的对象。
- 平移初始化: 物体在空间中的位置(平移),是根据物体边界框中的中位深度点确定的。中位深度点是在物体边界框内所有深度值的中值,它提供了一个相对准确的物体深度定位。
- 视点采样: 从一个以物体为中心的球形分布上均匀采样若干视点(Ns)。即:相机被置于球面上多个位置,每个位置都面向物体的中心,以捕捉从不同角度看物体的视图。
- 旋转初始化: 对象在空间中的方向(旋转),是通过在球面上均匀采样多个视点来初始化的,并对这些视点进行进一步的平面内离散旋转处理,从而创建多个全局姿态假设。
3.2、姿态细化
-
细化网络架构:接收物体的粗略姿态渲染的数据和相机观察到的剪裁物体区域作为输入。姿态细化网络的目标是输出一个改进的姿态估计,这一估计更准确地反映了物体的实际姿态。
-
姿态条件剪裁:从检测到的2D边界框中剪裁出物体图像,并根据物体的粗略姿态对剪裁范围进行调整。
-
多视角渲染:基于初步姿态,姿态细化网络围绕该姿态渲染物体的多个视图。这些视图帮助网络理解从不同角度看物体时的外观变化,从而更好地锚定最佳的姿态。
-
迭代优化:姿态细化可以通过多次迭代进行,每次使用前一次细化后的姿态作为新的输入。这个过程逐渐收敛于最佳姿态,通过不断反馈和调整来提高估计的准确性。
姿态细化通过多次迭代进行,姿态更新如下所示:
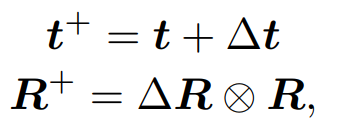
- 网络模型输出包括平移(Δt)和旋转(ΔR)的更新
- Δt 和 ΔR 分别表示在相机坐标系中物体平移和旋转的更新
姿态的损失函数,如下所示:
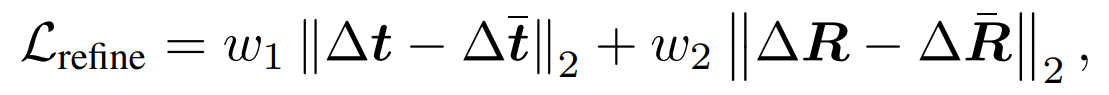
- 由两部分组成:平移的L2损失 和旋转的L2损失,其中
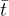 和
和 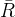 是真实的平移和旋转更新。
是真实的平移和旋转更新。 - 损失函数的权重 ?1 和 ?2被经验性地设置为1,以均衡平移和旋转更新的重要性。
四、姿态选择
上面生成了多个假设的姿态,现在需要选出最准确的。
模型结构如下所示:

分层比较策略:
- 这一策略首先对每一个细化后的姿态假设进行评分。
- 它使用两级比较方法来确定每个姿态的得分,进而选择得分最高的姿态作为最终结果。
第一级比较:
- 对于每一个姿态假设,网络渲染一个与之对应的图像,并将其与输入观察图像(已经经过姿态条件裁剪)进行比较。这个比较主要基于视觉内容的一致性。
- 使用姿态评分编码器提取特征,该编码器有与细化网络相同的特征提取架构。提取的特征经过拼接、标记化,并输入到多头自注意力模块,以便更好地利用全局图像内容进行比较。
- 通过平均池化输出一个特征嵌入 ?,这个嵌入描述了渲染图像与观察图像之间对齐的质量。
第二级比较:
- 为了更全面地评估各个姿态假设,网络将所有姿态的特征嵌入 ?进行比较。这是为了利用所有假设的全局上下文,而不是单独评估每个假设。
- 这一步通过多头自注意力机制实现,处理拼接后的所有特征嵌入。这样做可以让网络在做出最终选择时,考虑到所有候选姿态之间的相对差异。
五、6D位姿估计方法现状
基于CAD模型的物体位姿估计
- 基本假设:这种方法假定给定对象的CAD模型,这是其训练和测试的基础。
- 技术方法:通常通过直接回归或建立2D-3D对应关系后使用PnP算法(Perspective-n-Point)或最小二乘法拟合来求解姿态问题。
- 局限性:
- 严重依赖于精确的CAD模型。
- 不能推广到新类别的对象,只能处理训练时已知的特定实例。
- 类别级方法虽然放宽了对特定实例的依赖,但仍限于预定义的类别。
少次学习无模型物体位姿估计
- 核心优势:去除了对显式CAD模型的依赖,增强了对新对象的适应能力。
- 技术方法:
- 使用一组参考图像捕捉目标物体,而不依赖CAD模型。
- RLLG和NeRF-Pose等方法提出了不需要CAD模型的实例级训练,尤其是NeRF-Pose使用神经辐射场(neural radiance field)来提供半监督学习。
- 也可以通过构建在SDF(有符号距离函数)表示上的神经对象场,为RGB和深度渲染提供有效的桥梁,进一步提高效率和准确性。
现有方法的限制
- 实例级方法:这些方法依赖于特定实例的训练,通常需要一个CAD模型。它们不能直接应用于测试时见到的新物体。
- 类别级方法:虽然这些方法去除了实例特定的假设,但它们仅限于训练过的对象类别,并且获取类别级训练数据本身就是一个挑战。
- FoundationPose:提出了统一框架,能够同时处理基于模型的和非基于模型的,即使在没有CAD模型的情况下,也能通过少量的参考图像处理新对象。这种能力使其在实际应用中非常灵活和强大。
模型特点:
- 可以处理具有CAD模型的物体,也可以处理只有少量参考图像的物体。这种灵活性使其在实际应用中极为有用,尤其是在无法获取物体完整三维模型的情况下。
- 强大的泛化能力,这得益于大规模的合成数据训练。该训练过程中结合了大型语言模型(LLM)、基于transformer的新架构和对比学习方法。
- 其核心特点是在测试时对新物体,无需进行微调。这是通过使用神经隐式表示来高效地合成新视图实现的,尤其是在没有CAD模型可用的情况下。这种方法简化了从基于模型到非基于模型的迁移,因为下游的姿态估计模块在两种设置中都是相同的。
六、基于神经隐式场的物体建模
在没有物体的3D CAD模型的情况下,通过神经隐式场表示来进行高效的物体建模,原理类似于NeRF。
利用神经网络直接建模对象的几何和外观,能够在GPU上高效地进行计算。
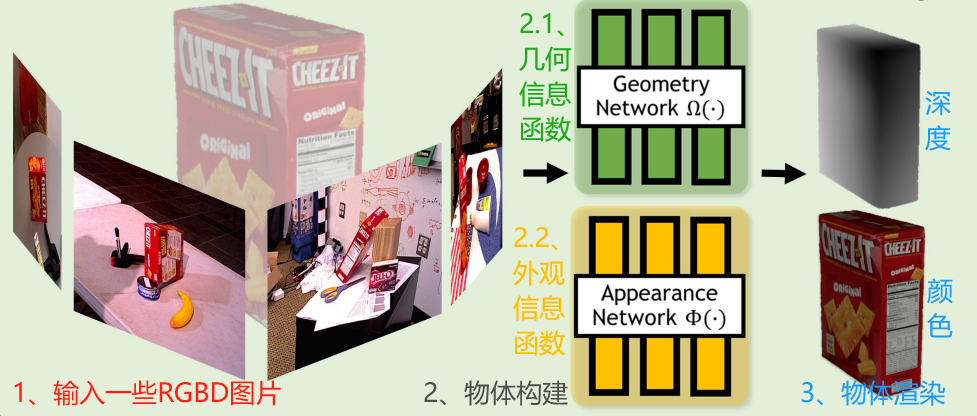
1、神经隐式场NeRF
FoundationPose的神经网络隐式场主要几何函数和外观函数表示:
-
几何函数Ω,它能将三维空间中的点转换为有符号距离值,这可以用于判定点在对象表面内部、外部或恰好在表面上。
-
外观函数Φ,它结合了几何信息、法线方向和观察方向来决定一个点的颜色,这对于渲染对象的外观至关重要。
特点:
- 这两个函数的组合使用,能够对物体进行建模;
- 通过有符号距离字段(SDF)来实现的,它定义了一个边界,边界内外的点分别表示对象的内部和外部。
- 这种方法提供了一种不需要手动设置密度阈值就能实现高质量深度渲染的方式,与传统的NeRF(神经辐射场)方法相比具有优势。
2、几何函数Ω
- 输入:三维点 x ∈ ℝ³: 这个输入是指在三维空间中的一个点的坐标,使用笛卡尔坐标系。
- 输出:有符号距离值 s ∈ ℝ: 输出是一个实数值,这个值表示输入点与某个表面的距离。
- 输出中的有符号距离的符号(正或负)表明点是在对象的外部还是内部。如果输出为零,则表示点恰好在对象的表面上。
有符号距离函数(SDF)是一个广泛使用的概念,在几何建模、物理模拟和计算机图形学中都有应用。
其主要原理包括:
-
隐式表面: 与显式表示(如多边形网格)不同,隐式表示通过一个数学函数定义了一个表面。这个函数给出了空间中任意点相对于表面的位置信息。
-
表面定义: 在有符号距离函数中,表面被定义为所有使得 Ω(x) = 0 的点 x 的集合。这意味着这些点恰好位于对象的表面上。
-
距离计算: 对于不在表面上的点,该函数计算出最近表面点的距离。如果点在表面内部,距离值为负;如果点在表面外部,距离值为正。
-
几何和拓扑灵活性: 有符号距离函数允许复杂的几何和拓扑结构的表示,因为它不依赖于点或多边形的显式连接。
-
效率: 在某些情况下,使用SDF可以更高效地进行几何操作,比如布尔运算、物体的融合与切割,因为它们可以通过简单的数学运算来实现。
-
渲染和物理模拟: 在渲染和物理模拟中,SDF可以用来快速判断光线与表面的相交,或者计算物理碰撞响应。
模型能够学习从三维空间到有符号距离的复杂映射,从而创建详细且真实的3D模型。
通过训练,网络可以学习到复杂对象的几何形状,并能够生成这些形状的精确隐式表面表示。
3、外观函数Φ
输入有三部分:
-
中间外观特征向量 f_Ω(x): 这是由几何函数 Ω 在点 x 的位置提供的信息,可能包含了关于该点在三维形状上位置的隐式几何描述。
-
法线 n ∈ ℝ³: 法线是一个从对象表面指出的单位向量,指明了在该点处表面的方向。法线信息对于确定光线如何与表面相互作用。
-
视角方向 d ∈ ℝ³: 视角方向是从观察者的视点到该点的方向向量。这个向量对于计算物体如何从特定角度被看到是必要的,因为物体的颜色和亮度可能会随观察角度的变化而变化。
输出:
- 颜色 c ∈ ℝ³: 输出是一个颜色向量,通常在RGB颜色空间中表示,表明了在给定几何形状、表面法线和观察方向下,该点应呈现的颜色。
外观函数的工作原理与现实世界中光与物体表面交互的物理原理密切相关。
其主要原理包括:
-
表面着色: 这涉及到计算光如何被表面吸收、散射和反射,以产生我们最终看到的颜色。着色通常依赖于材质属性(如粗糙度、金属感、透明度)以及法线和视角方向。
-
光线追踪: 在高级图形渲染中,光线追踪技术可以用来计算光如何在场景中传播,并与对象的表面相互作用,但这通常是计算密集型的。
-
BRDF: 双向反射分布函数(BRDF)描述了光如何在不同的角度从表面反射。它是影响材质外观的关键函数。
-
神经网络的角色: 在神经网络驱动的模型中,外观函数可能由一个深度学习模型实现,它可以学习从几何、法线和观察方向到颜色的映射。这种模型可以从大量的训练数据中学习到复杂的物体外观特性。
-
上下文感知: 神经网络可以理解和编码几何形状周围的上下文,这允许它在不同的光照和观察条件下产生逼真的颜色。
4、物体渲染
通过执行Marching Cubes算法来从SDF的零水平集提取纹理化网格,然后结合颜色投影;这只需要为每个物体对象执行一次。
给定一个物体对象的姿态,在推断阶段,可以根据光栅化过程渲染RGBD图像。
- 使用Marching Cubes算法,从SDF(Signed Distance Field,有符号距离场)的零水平集中提取带有纹理的网格。
- 这里的“零水平集”指的是那些有符号距离为零的点的集合,它们定义了物体对象的表面,对于几何函数的输出值。
渲染的公式如下所示,实现物体纹理提取和渲染。
首先,计算沿射线 ?通过体积的颜色?(?)
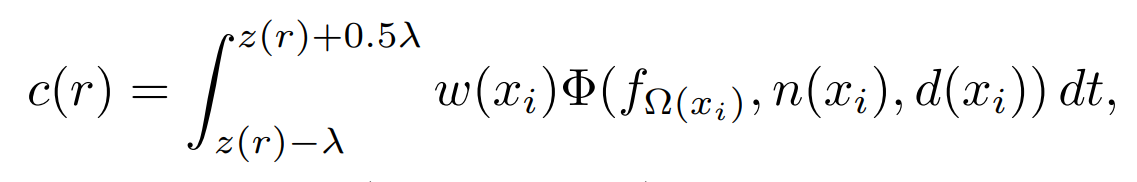
- 是一个积分表达式,通过积分权重函数?(??) 和外观函数Φ来计算颜色?(?)的过程。
- z(r) 是射线 ?从深度图像得到的深度值,代表射线与物体表面的交点深度。
- ?是截断距离,用于定义渲染的范围,这里体积渲染仅在表面附近的 ?范围内进行,以提高计算效率。
- ?(??)是一个基于点??的有符号距离 Ω(??)的概率密度函数,由下面公式定义,决定了该点对最终颜色的贡献大小。
然后,概率密度函数?(??)
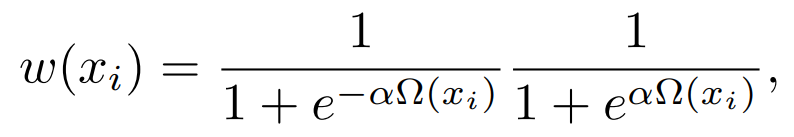
- α 调节函数的软性,使分布在物体表面附近有更高的概率峰值,这有助于聚焦在表面的纹理学习。
最后,颜色监督训练

- 在训练过程中,通过最小化预测颜色和实际颜色之间的差异来进行优化
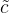 (r) 是射线 ?对应的真实颜色值,这样的监督确保学习的纹理能够反映实际的观察数据。
(r) 是射线 ?对应的真实颜色值,这样的监督确保学习的纹理能够反映实际的观察数据。
七、基于LLM合成大规模数据
数据多样性的重要性
- 问题识别:为了实现强大的泛化能力,需要大量多样化的对象和场景数据。然而,现实世界中获得这样的数据并注释准确的6D姿态是困难且成本高昂的。
- 解决方案:使用合成数据来补充现实数据的不足,合成数据可以在不受物理限制的情况下提供无限的多样性和配置。
技术栈:
- 3D模型数据库:如Objaverse和GSO,提供大规模的3D模型资源,增加训练数据的多样性。
- 大型语言模型(LLM):用于生成描述,帮助创建更真实的场景和对象交互,使生成的数据更接近自然语言描述的现实世界场景。
- 扩散模型:用于生成或改进对象的纹理和外观,使合成图像更加真实和具有吸引力。
基于大语言模型LLM和扩散模型,通过文字信息,引导生成指定的物体3D模型纹理和外观。
- 如下图所示,提供形状和外观的标签,进一步增强模型对各种对象特性的理解和学习。
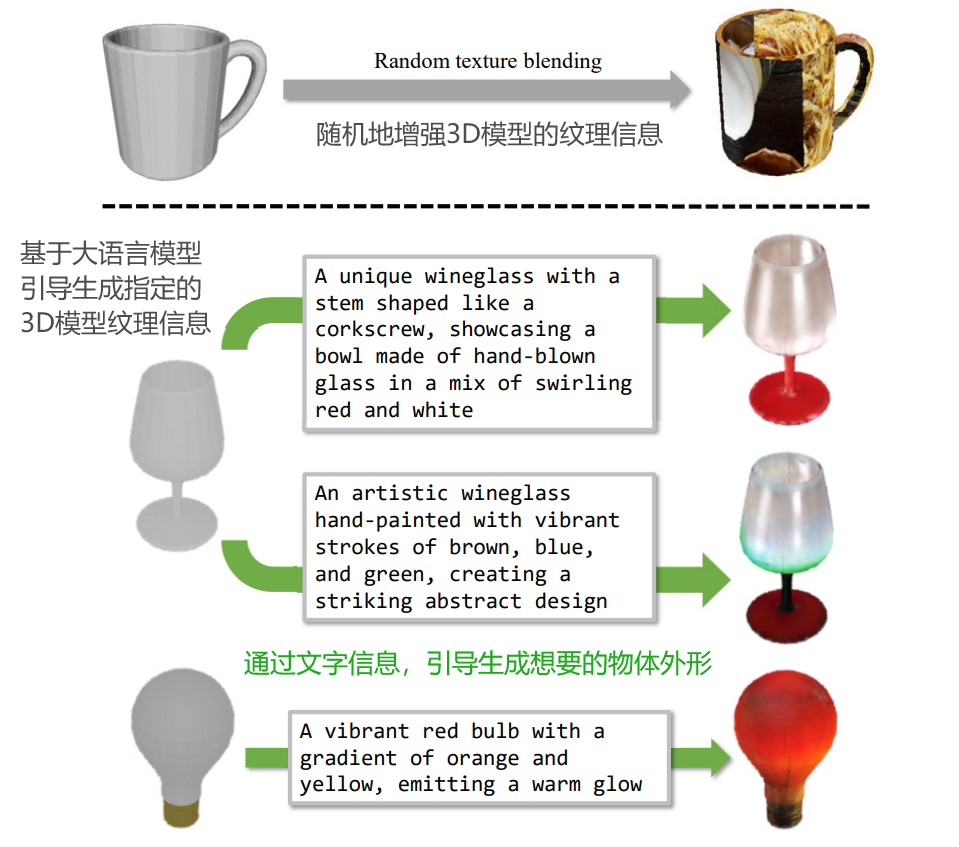
LLM辅助的纹理增强:
- 现有问题:以前的纹理增强方法,如FS6D,虽然通过从ImageNet或MS-COCO随机粘贴图像增强纹理,但这种方法往往因随机UV映射导致接缝明显,且整体场景的真实感不足。
- 新方法:利用LLM自动生成纹理描述,然后将这些描述提供给扩散模型生成更加真实和具有风格化的纹理。这不仅解决了接缝问题,而且提高了纹理的质量和多样性。
- 通过自动生成的纹理描述,整个纹理增强过程实现了全自动化,极大提高了处理的效率和规模。
- 使用NVIDIA Isaac Sim实现高保真的光追渲染,再结合物理和重力模拟,生成物理上可信的场景,随机设置对象的大小、材料、相机位置和光照条件。
总结:
- 通过大语言模型辅助的大规模数据生成,有效地解决了传统数据采集方法中的局限性。
- 通过结合最新的AI技术和大规模的3D数据库,显著提升了训练数据的质量和多样性。
- 这不仅有助于提高模型的泛化能力,还可以推动机器学习模型在更广泛的应用场景中的实用性和准确性。
八、模型效果
在LINEMOD数据集上,测试的无CDA模型位姿估计结果

- 使用ADD-0.1d评价指标
基于CAD模型的位姿估计结果,通过代表性BO数据集上的AR分数进行测量:
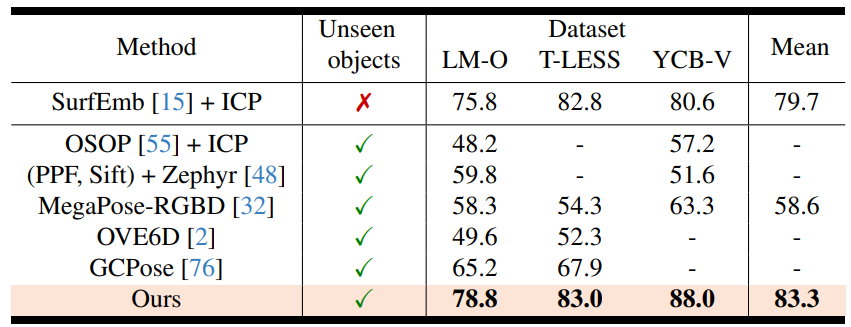
- 所有方法均使用 RGBD 模式
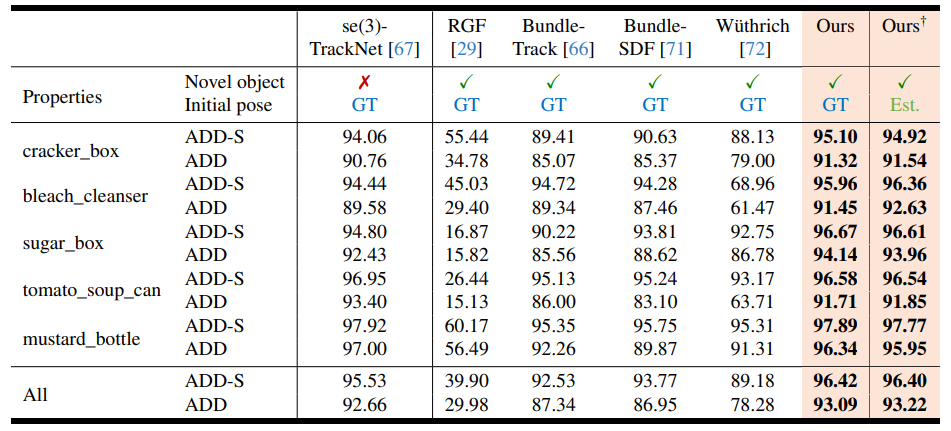
YCBInEOAT数据集上测试,RGBD方法的姿态跟踪结果:
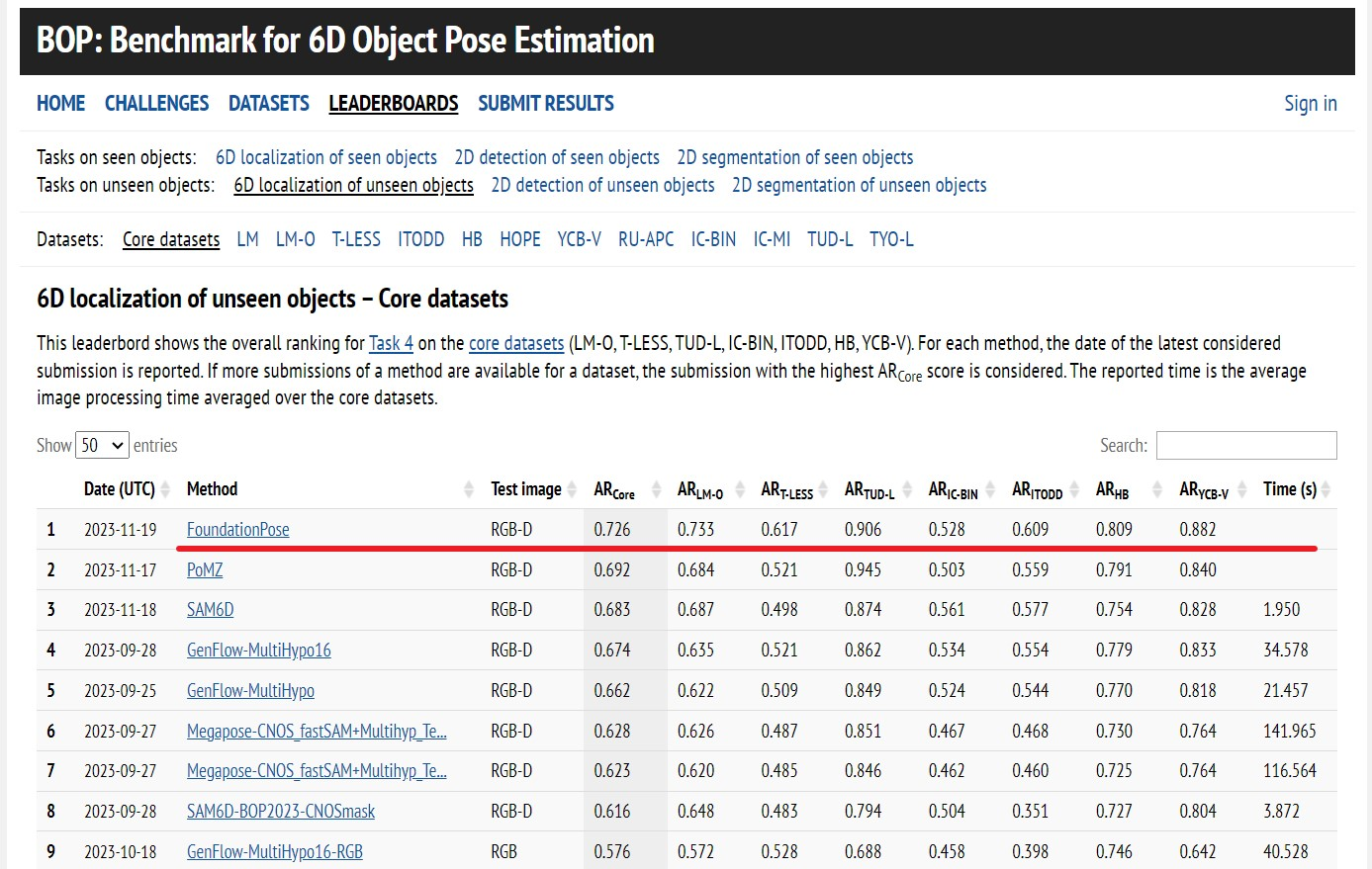
? 基于CAD模型为输入,新型物体姿态估计在全球 BOP 排行榜上排名第一(截至 2024/05)。
位姿估计+跟踪效果:




位姿估计效果:

代码运行参考:【6D位姿估计】FoundationPose 跑通demo 训练记录
分享完成~
本文先介绍到这里,后面会分享“6D位姿估计”的其它数据集、算法、代码、具体应用示例。
评论记录:
回复评论: