
前言
List、Set、HashMap作为Java中常用的集合,需要深入认识其原理和特性。
本篇博客介绍常见的关于Java中Set集合的面试问题,结合源码分析题目背后的知识点。
关于List的博客文章如下:
关于的Set的博客文章如下:
关于HaseMap的博客文章如下:
- Java进阶(HashMap)——面试时HashMap常见问题解读 & 结合源码分析
- Java进阶(ConcurrentHashMap)——面试时ConcurrentHashMap常见问题解读 & 结合源码分析 & 多线程CAS比较并交换 初识
其他相关的Set的文章如下:
引出
1.特点:无序,去重,非线程安全;
2.底层:HashMap的Key值实现的;
3.map.put方法,静态常量PRESENT,新值替换旧值;
4.map.remove key方法,如果KEY不存在时,则返回的是null,如果KEY存在时,返回的就是e.value,即PRESENT,返回true成功,返回false不成功;
5.去重原理:先判断hash值,再通过==或者equals判断,整体如果返回true,则为重复元素;
6.无序的则采用HashSet ,有序的则采用TreeSet;
7.线程安全的set:Collections.synchronizedSet(new HashSet<>());
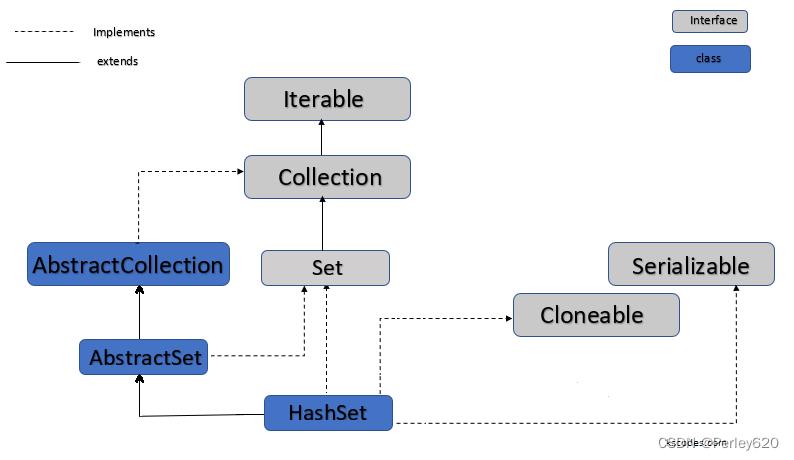
1. 描述一下HashSet的底层原理?
- HashSet的特点:无序,去重,非线程安全;
- HashSet 底层是用HashMap的Key值实现的,也有上面的3大特征;
构造方法
无参和代参构造方法都会初始化这个HashMap
无参的构造方法,调用了HashMap方法
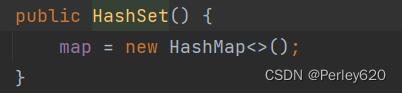
有参的构造方法也是,调用了HashMap方法


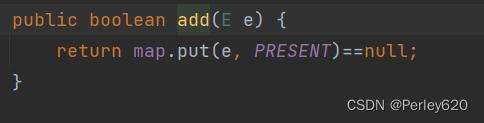
add方法

add方法中可以看出调用HashMap的put方法,key为放入元素,值为常量PRESENT

2. map.put方法,静态常量PRESENT
既然hashset基于hashmap实现,你说一下 hashset的add方法中,为什么要在map.put的val上放上一个Object类型的静态常量PRESENT?
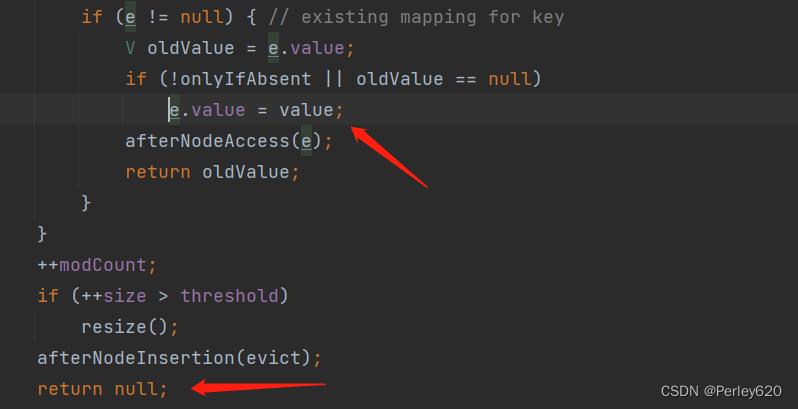
HashSet底层调用了map的put方法,传入了存储的对象和PRESENT常量,那我们进入put方法继续查看

put方法内调用了putVal方法,PRESENT常量为形参value,继续进入查看
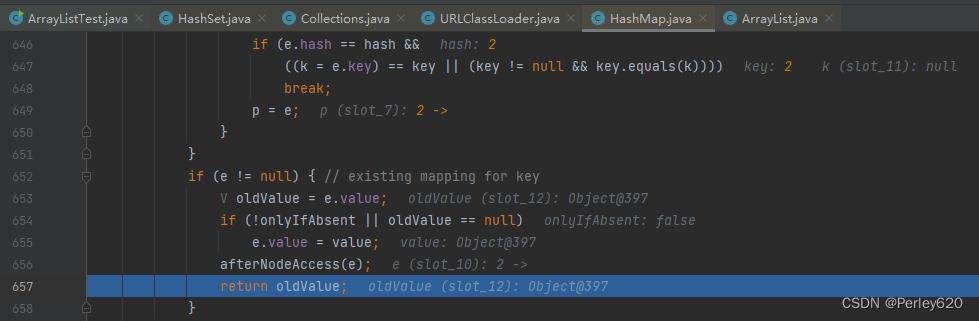
if (e != null) { // existing mapping for key
//把旧数据存储到oldValue
V oldValue = e.value;
//如果说存储的位置上已经有元素了
if (!onlyIfAbsent || oldValue == null)
//新元素会替代旧元素 新KEY替代KEY
e.value = value;
afterNodeAccess(e);
//返回旧元素数据
return oldValue;
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
//如果说上面的if结构没有执行,那么就说明这个位置上没有元素,则新增成功,返回null
return null;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
public boolean add(E e) {
//上面的方法返回值决定了HashSet的add方法到底返回true还是false
return map.put(e, PRESENT)==null;
}
- 1
- 2
- 3
- 4
- 此方法内部明确箭头标处的原理,value就是PRESENT,如果进入这个if结构,则说明这个位置上已经存在该key,则会用value替换之前的旧值,然后返回旧值oldValue,否则会返回null;
- 至此,我们可以看出此方法的返回值是PRESENT或者是null,如果为PRESENT则说明KEY已存在,则add方法就会返回false(此处元素put还是成功的,只是新值替换旧值),返回null则add返回true,此KEY不存在,代表存储新的KEY-VALUE;
3. map.remove key方法,PRESENT进行比较
既然hashset基于hashmap实现,你说一下 hashset的remove方法中,为什么要在map.remove key 完了之后要和PRESENT进行一个等值比较呢?
- 从HashMap的remove方法中可以看出,方法返回的是e.value或者null,与add方法中的原理一起联想,则会明白,如果KEY不存在时,则返回的是null,如果KEY存在时,返回的就是e.value,即PRESENT;
- 所以在HashSet在判断此返回值==PRESENT,如果相等则返回true,说明此KEY是存在的,删除成功返回true,如果返回值是null,那么null=PRESENT则返回的肯定是false,那么代表此KEY不存在,删除自然不成功,返回false;
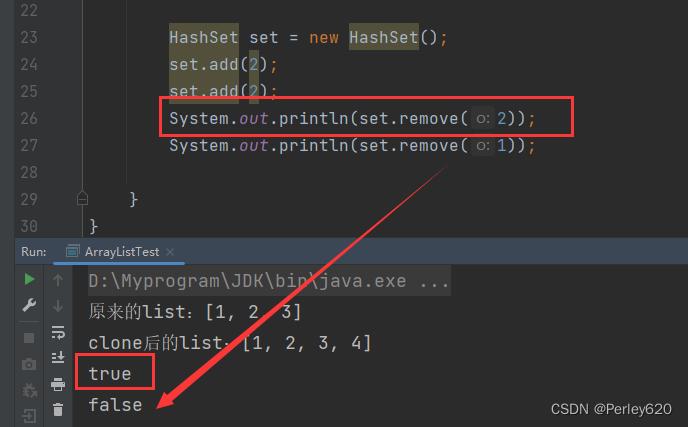
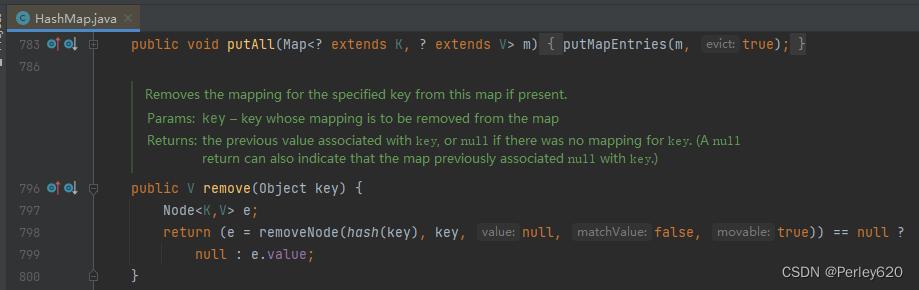
public V remove(Object key) {
Node<K,V> e;
//判断了一下,如果removeNode删除得到的是null,说明此KEY不存在,方法返回null
return (e = removeNode(hash(key), key, null, false, true)) == null ?
//否则返回e.value 就是 PRESENT
null : e.value;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
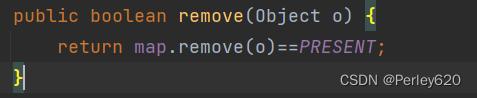
public boolean remove(Object o) {
//因为HashMap删除成功返回的是PRESENT , ==PRESENT 则结果为true 代表删除成功
//否则返回的是null , 返回false 删除失败
return map.remove(o)==PRESENT;
}
- 1
- 2
- 3
- 4
- 5
4. HashSet的去重原理?
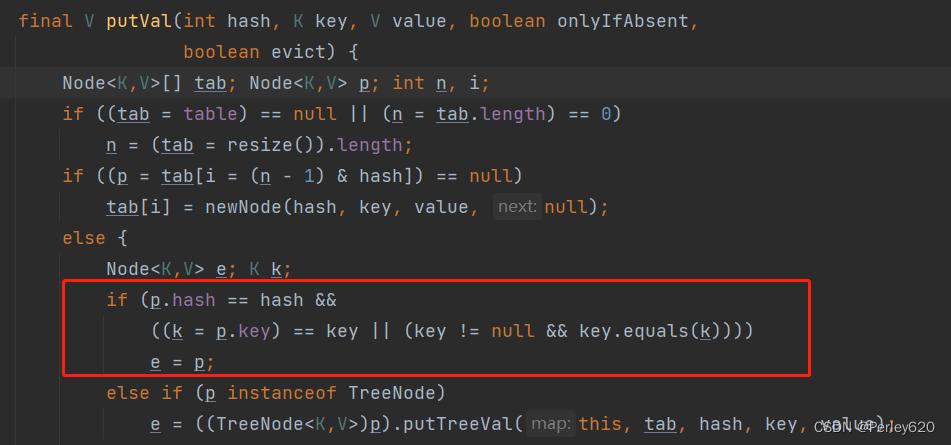
- HashMap中putVal方法中有这么一段代码判断,去重原理在于hashcode的判断和equals方法的判断
- 先判断hash值,再通过==或者equals判断,整体如果返回true,则为重复元素
5. 如何选择HashSet 或 TreeSet?
无序的则采用HashSet ,有序的则采用TreeSet
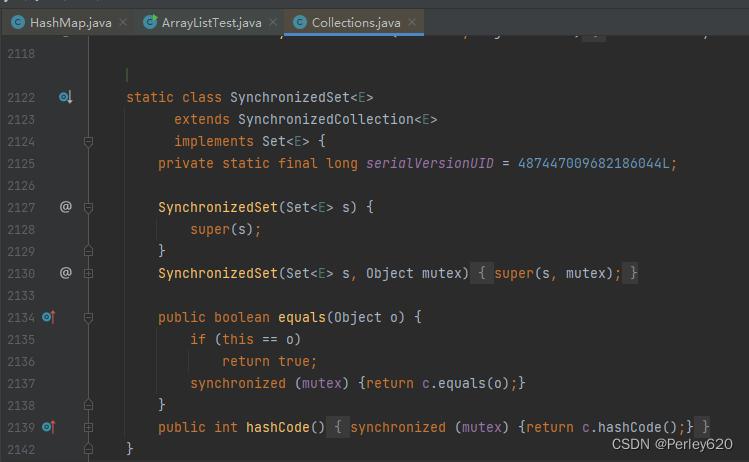
6. 如何得到一个线程安全的Set集合?
Set datas = Collections.synchronizedSet(new HashSet<>());
总结
1.特点:无序,去重,非线程安全;
2.底层:HashMap的Key值实现的;
3.map.put方法,静态常量PRESENT,新值替换旧值;
4.map.remove key方法,如果KEY不存在时,则返回的是null,如果KEY存在时,返回的就是e.value,即PRESENT,返回true成功,返回false不成功;
5.去重原理:先判断hash值,再通过==或者equals判断,整体如果返回true,则为重复元素;
6.无序的则采用HashSet ,有序的则采用TreeSet;
7.线程安全的set:Collections.synchronizedSet(new HashSet<>());
一、性能影响因素分析
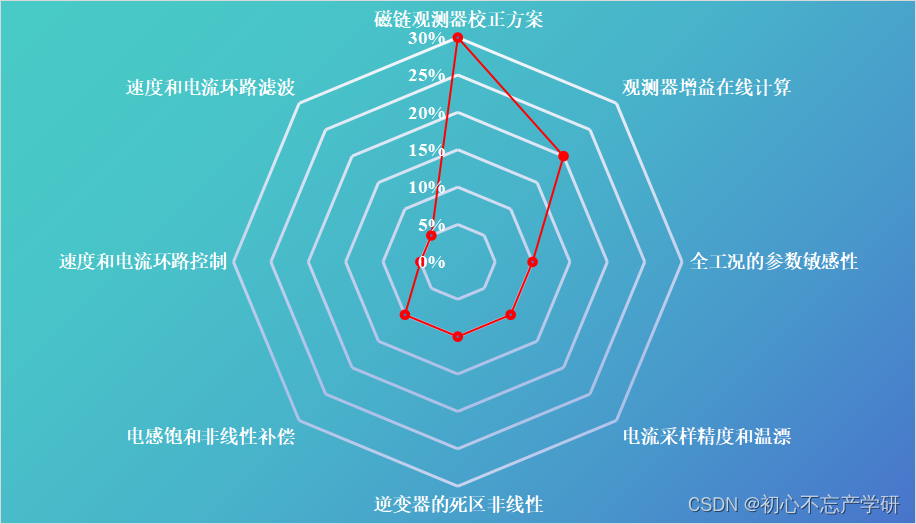
2024年通过阅读大量Sensorless Control为主题的文献以及王老师、诸老师等教授的Sensorless Control书籍总结了无位置传感器电机控制(Sensorless Control)性能影响因素分析如下图所示:
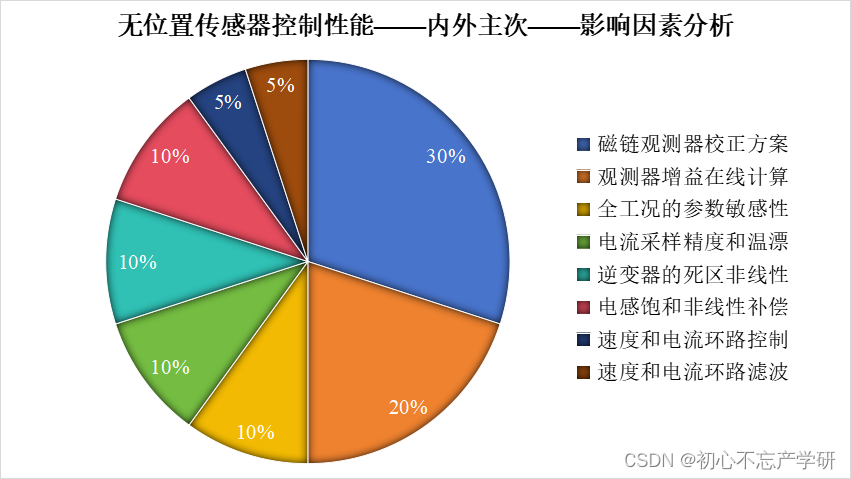
将上图进行雷达图排列重新绘图如下,可清楚看到该类电机控制方法中各个影响因素的具体占比:
二、影响因素详细解析
在此也同时对大家提问的问题进行统一回复:
问题1:如何在仿真和实验中验证无位置传感器控制方法的对测量噪声以及误差的鲁棒性?
回答1:像当初开发扩展卡尔曼滤波算法一样,可以在测量反馈通道人为添加直流偏置和随机噪声来验证无位置传感器控制方法的对测量噪声以及误差的鲁棒性;同时为了验证采样和发波延时的影响,也可以在仿真中前项控制通道增加控制延迟和非线性死区来逼近实际控制对象模型。
问题2:无位置传感器控制方法为什么会出现电机反转现象呢?
回答2:积分初值决定了无位置传感器控制方法中观测器的初始状态,首先需要电机初始状态正确,电机初始位置正确,就能实现零速带载直接启动(仿真中即使是此时满足了这些前置的条件,带载启动仍然会出现反转的现象,是由于观测器收敛过程的影响,一方面可以想办法加快观测器的收敛速度,另一方面从速度环积分初值入手来减弱该反转现象),一旦有一丁点速度,观测器就立刻收敛,即在从0速开始加速的时候收敛,对于反电势类的观测器和磁链类的观测器亦然。然而在实际应用中经常会采用parking和I/F来拖到电机启动,当前没有初始位置检测,parking可能会反转,IF低速带载需要做负载自适应,像V/F一样,功角自平衡带不同大小负载。
问题3:无位置传感器控制方法的电机位置角度估计误差的来源是什么?
回答3:常见的方式为直接反正切求角度或者是锁相环或者是龙伯格观测器(负载扰动观测器之类的),其角度估计误差来源于逆变器死区非线性和电机参数失配,电机反电势谐波、槽谐波先不考虑,其可能需要ESO或者PR等手段来抑制位置误差中的谐波。此处需要注意的是,多个参数同时不准的参数敏感性分析。仿真分析不同参数不准时,具体表现是怎样的,抓主要矛盾,比如转子磁链观测器,R不准导致转子磁链αβ不平衡,L不准导致转子磁链αβ畸变等。若没有输出电压采样,则需要注意电压重构的准确性,注意电流环的限幅值,调制波的限幅(注意过调制的影响)。因为电压重构 需要注意 ACR饱和时 电压重构 和 实际输出电压的误差,实际还需要考虑 死区时间 造成的误差,尤其对于零低速运行工况 。仿真中 观测器 对 实际输出电压 和 重构电压 的反应不同,重构电压的使用 需要 添加速度反馈滤波(因为其与实际电压的不同,相当于引入了高频电压误差,导致了PLL类的输出速度出现高频震荡),而速度反馈滤波的加入 需要 重新整定 ASR参数(因为反馈延时的增加)。
问题4:无位置传感器控制方法中的校正项是越多越好吗?
回答4:凡是多加一项校正 就 多了这一项校正的 优缺点,优点要尽量大于缺点。此时涉及观测器的增益设计 是 在表达 我要更依赖模型,还是要更依赖测量。多个参数如果同时变化呢?多个初始值如果同时不准呢?评估要更加具体和实际以及不同工况条件,高低速,负载大小,还要大电流饱和(极限转矩),磁饱和 在仿真中 如何考量?(数值电机模型,导入电机磁链MAP图)。自适应滤波器在仿真中 如何 设置(部分方案本身 就是 频率自适应带通滤波器,包括扰动观测器的等效数学表达式也是 自适应带通滤波器 或者 自适应陷波器),磁链观测器,PI校正方法,随运行频率计算PI参数(PI参数较弱,仍然解决不了磁链初值问题),HPF亦然,正在准备试一试陷波器,定子电阻问题,±30%;定子电感问题,±50%,或者离线辨识饱和曲线;永磁的磁链初值问题(同步磁阻除外,它先预励磁),±30%,和定子电阻一样,主要考虑热的影响。注意PLL输出转速的LPF对整个系统的参数敏感性也有影响(首先其降低了速度环带宽,限制了PLL里输出的噪声)SPM,IPM(凸极比较小),IPM-辅磁(凸极比较大),SRM极对数较多,凸极比较大。
问题5:无位置传感器控制方法的开发过程注意事项是什么?
回答5:磁链观测器两个层面:1.磁链观测精度,参数敏感性,观测稳定性(校正环节);2.对各类应用和各种电机的覆盖面,覆盖80%的电机;算法复杂度评估;列出1.0 基础算法框架;2.0 为滞后开发(兼容专用和通用);3.0 (基础稳定之后,作特殊的应用拓展)。先搞定连续域稳定性,再搞离散域稳定性(考虑离散误差,以及各种离散方式优缺点)。先搞定独立环路稳定性,再搞定串并联环路稳定性,最后再搞控制器+观测器系统稳定性(系统各个环节对整个系统的影响)。统计每一篇文献 带给你什么思路?把文字题目,创新点,统计出来以及文章中的一些小点,对比点,分析点,延伸文献和溯源引用文献。文献注意名字,注意课题组,注意裙带关系,注意同行工程师动向和其对电机控制的理解深度和广度。有源磁链,扩展磁链,等效磁链,线性磁链,非线性磁链校正,注意相关方法的联系,稳定性证明综述,注意各类方法的假设和前提条件。磁链初值正确,位置开环,速度闭环,电流闭环,启动都没有反转(坐标变换的位置是给定的,该方法假设了磁链观测器的全局稳定性,且收敛速度较快,至少比速度环带宽要快)注意 磁链观测器,如果磁链幅值的初值正确的话,HPF的存在反而带来不好的影响(启动带来振荡)。观测器设计,稳定性分析(收敛区域和收敛速度,计算和设计可调参数),参数敏感性分析(同时也影响着其稳定性,收敛区域,收敛速度),参数和测量(相位和幅值)两个方面失配问题。特殊或极限运行工况的稳定性分析(过调制,弱磁,极低速,低载波比,电机易于磁饱和)。全局观,FOC,填补细节问题,适应更多电机。三相不平衡检测,转子偏心检测,联轴器(轴向和径向)轴偏移。初始位置为0时,β轴磁链初值是 -磁链幅值,初始位置是其他角度时,初值是变化的。注意坐标系 直轴的空间位置定义。注意影响低速的到底是什么?定子电阻?磁链初值?死区非线性?带通的本质,在接近零频也会蜕变成高通滤波器。所有的算法模块 加 具体的产品和应用,不以产品和应用出发的算法没有实际意义。以未来市场需求为基础,多参考国外的一些资料,他们积累了大量的工程经验和产品化经验,能在更多的细节上给予产品可靠性。尽量从不同的角度来加深对控制的理解。滤波器的设计还是逃脱不了低频收敛速度。弄清楚应用场合 才能对算法模块的参数接口做更合理,更灵活的开放同时对算法进行更好地专用性封装;另一方面算法本身鲁棒性的接口参数调节在于 事先对算法设计过程中 预留一些接口应对极端工况,以提升算法的适应性和抗扰性,增加算法的灵活度。先保证收敛,文献阅读收敛,工作量收敛,思维收敛。发散只是一时的胡思乱想。问题的解决还是在于收敛域一个点,集中精力 聚焦一个点。
问题6:无位置传感器控制方法的参数鲁棒性如何提高?
回答6:注意不同的电机参数,其各个参数在模型中的占比发生变化后,参数适应范围也会不同,比如IPM,永磁体磁链过小对定子电阻更敏感,更容易发散?凸极比也影响对定子电阻敏感性?只要有源转子磁链幅值正确,定子电阻辨识还是有妙用的(但是对于凸极比较大电机反而其自身振荡了,其有源转子磁链幅值与凸极比和直轴电流相关)相当于IPM也和SRM一样,需要预励磁。定子磁场定向?(对于凸极比较大的电机?为啥呢?包括同步磁阻电机?)大一统 归 大一统,具体的某一类型的电机,还是得具体问题具体分析。对于SPM整个方案,还需要更细化的验证,比如低速发电和电动切换,减速发电,极低速(校正PI也要适应极低速)以及中高速转子磁链幅值的辨识 可行性和适应性。这样理解即可,所有控制,观测,辨识模块间的各自的带宽响应 距离 越近,则互相耦合越严重,难以系统性分析。层里和环路 解耦。控制带宽。观测带宽(包含估计转速反馈滤波)。辨识带宽。当前思路的定子电阻辨识 带宽较低,而逆变桥非线性电压误差项是快速变化的,因此暂时无法通过定子电阻辨识PI跟踪该非线性电压误差。注意凡是会导致有源转子磁链波动的 因素(直流偏置,突加载等),都可能导致基于磁链幅值的定子电阻辨识发散,定子电阻辨识PI尽量弱,这样就最大程度减小与校正PI的干涉。如果有特殊需求且允许以下手段,可运行在一定速度之上等定子电阻收敛后跑极低速。但是当同时存在定子电阻失配和直流偏置(测量电流)时上述特殊手段仍然很难有所作为。带重载减速(一定减速时间内),减速不一定处于发电工况(此时电磁力矩小于负载力矩即可)。温敏参数(定子电阻和永磁体磁链),变化缓慢,变化范围可预估。电流敏感参数(逆变器非线性,直交轴电感),变化较快,变化范围可能较大(不同电机不一致),难以在线估计(估计带宽要求过高)。为啥无感容易低速不行呢?初始位置,初始磁链,定子电阻,逆变器非线性,饱和电感曲线。
评论记录:
回复评论: