
为了验证知识蒸馏在最新的yolo模型上是否有效,博主先调研了目标检测模型的分类、知识蒸馏的分类、最后调研了与yolo相关的知识蒸馏。当前并为发现yolov8以上模型在开源数据集上的知识蒸馏效果得到有效提升。同时,博主采用voc2012数据集,用yolov11 s模型蒸馏yolov11 n模型,同时对比了知识蒸馏与迁移学习。
基于以下实验,得出以下结论:
1、基于知识蒸馏得到学生模型没有经迁移学习后得到的模型精度高的现象,这表明只有在迁移学习与 直接训练 时精度相同,才优先考虑知识蒸馏;
2、发现可以发现未得到有效训练的模型,再次进行知识蒸馏时,可以有显著涨点。基于该经验,对于提到知识蒸馏大幅度提升模型效果,可能要论证一下原始的学生模型是否得到收敛。同时,要对比模型精度提升,是否由模型二次训练带来的迭代数变多导致的提升;
3、发现基于对coco预训练后的迁移权重,再次进行知识蒸馏时,可以发现基本上没有有效作用。这表明知识蒸馏中,来自其他数据集中学到的知识可能与教师模型中提供的知识高度贴合,导致知识蒸馏无效;
以上结论,对知识蒸馏的应用场景进行了制约,表明在常规数据集下,yolo模型进行知识蒸馏很难取得精度提升,除非是在专业数据集中,如sar数据、带雾数据集等。(可以在3.1中学术论文中的最后一篇论文中得到印证,非常规数据集,yolov5模型sar数据涨点)
同时,对开源项目或论文的调研,只发现了moblie-yolov5模型在voc数据集上得到有效涨点(2个点以上),对于yolov5、yolov8模型几乎没有涨点(可以在3.2中github与csdn检索结果中得到印证,同时结合3.1中论文二DAMO-YOLO,可以发现知识蒸馏不如模型结构优化有用)
1、目标检测模型
目标检测模型是计算机视觉领域中的一种重要技术模型,主要用于在图像或视频中定位和识别出感兴趣的目标物体。
1.1 模型分类
1.1.1 按检测阶段分类
单阶段检测模型: 在单次通过中执行对象检测,将目标检测任务视为一个回归问题,直接在特征图上预测目标的类别和位置,如YOLO、SSD等。这类模型优先考虑速度和效率,适合实时应用。
双阶段检测模型: 使用两步过程实现,进行区域建议,然后进行分类。先生成一系列候选区域(Region Proposals),再对这些候选区域进行分类和精确定位,如Faster R-CNN等。其专注于准确性,对复杂或密集的场景特别有益。
1.1.2 按是否使用锚点分类
基于锚点的检测器: 依赖于不同比例和长宽比的预定义边界框(锚点),这些边界框提供了强大的性能,但需要调整,如SSD、YOLOv8等。
无锚检测器: 直接预测对象位置,无需使用预定义的锚点,简化了架构,提高了跨不同数据集的适应性,如FCOS、CenterNet、YOLOX等。
1.1.3 按网络架构分类
基于CNN的检测器: 利用卷积层有效地捕获局部空间模式,是早期深度学习目标检测的主流架构,如R-CNN、Fast R-CNN、Faster R-CNN等。
基于Transformer的检测器: 利用自注意机制来捕捉图像中远处对象之间的全局上下文和关系,可以很好地扩展大型数据集,但计算成本更高,如DETR、DETR v2等。
1.1.4 按边界框类型分类
正框检测器:边界框与图像轴对齐,提供计算简单性,但难以处理旋转对象和密集场景。
旋转框检测器: 边界框旋转以适应对象的方向,从而提高了有角度对象的精度,但代价是增加了计算复杂性。
这两类目标检测器实质上没有区别,只是旋转框检测器多了个角度信息。一开始的旋转框检测器角度只是一个等价于类别的额外信息,如yolov5、ppyoloe的旋转框检测版本只是新增了一个角度输出。在角度表示上,可以基于分类也可以基于角度值回归实现。在yolov8的旋转框检测版本,实现了在标签分配中引入了角度信息,计算rotation_iou分配标签。
1.2 yolo系列模型
在2024年yolo系列模型如雨后春笋不断出新,提出了yolov9、yolov10、yolov11等模型。
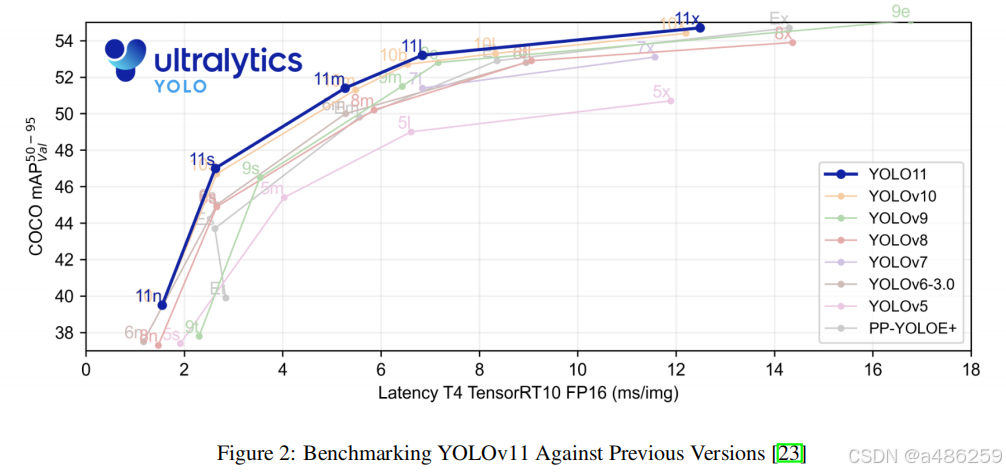
表1说明了YOLO模型从最初版本到最新版本的进展。每次迭代都在目标检测能力、计算效率和处理各种CV任务的多功能性方面带来了显著的改进。
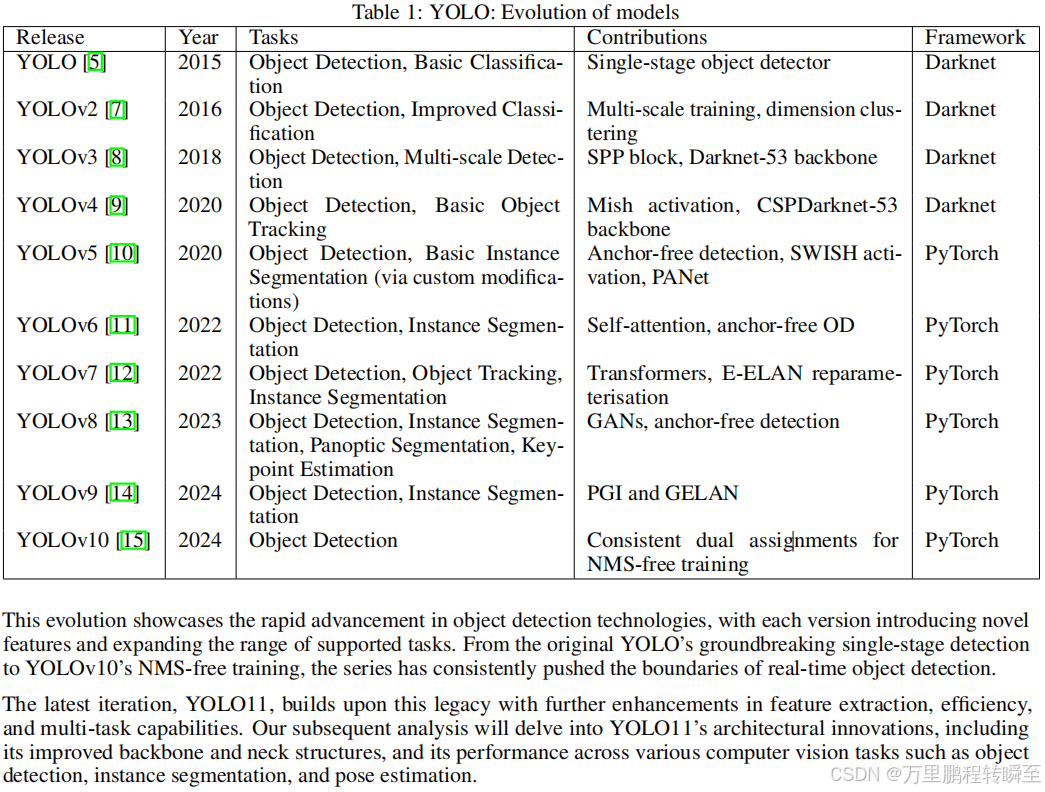
这种演变展示了目标检测技术的快速发展,每个版本都引入了新的特性,并扩大了所支持的任务的范围。从最初的YOLO开创性的单级检测到YOLOv10的无NMS训练,该系列不断突破了实时目标检测的边界。
1.3 ultralytics项目
ultralytics项目是yolov5、yolov8、yolov11的官方项目,其中包含了yolov3-yolo11等多个模型版本。与mmdetection、Paddledetection等项目相比,ultralytics项目在工程上的使用率更高,使用门槛更低。
ultralytics项目只支持部分一阶段目标检测器,而mmdetection、Paddledetection等项目则支持更多类型的目标检测器

1.4 目标检测模型的一般架构
目标检测模型通常由 骨干网络+ 颈部网络+检测头 三部分实现
1.4.1 骨干网络
骨干网络通常是一个深度卷积神经网络(CNN),如 VGG(Visual Geometry Group)、ResNet(Residual Network)等。其作用是提取图像的特征。以 ResNet 为例,它通过残差连接的方式,有效地解决了深层神经网络训练时的梯度消失问题,能够提取到图像中不同层次的特征,从低层次的边缘、纹理特征到高层次的语义特征。
例如,在一幅包含汽车的图像中,骨干网络可能先提取出车轮的圆形轮廓、车身的线条等低层次特征,然后逐步组合这些特征,形成如 “汽车” 这样的高层次语义特征。
1.4.2 颈部网络
颈部网络用于对骨干网络提取的特征进行进一步的融合和处理。它可以增强特征的表达能力,使得后续的检测头能够更好地利用这些特征。常见的颈部网络结构包括特征金字塔网络(FPN - Feature Pyramid Network)。
FPN 的特点是能够生成具有不同尺度的特征图,这对于检测不同大小的目标非常重要。在实际场景中,图像中的目标物体大小各异,比如一幅城市街道的图像,可能既有远处较小的交通标志,又有近处较大的汽车。FPN 可以为小目标提供高分辨率的特征图,为大目标提供低分辨率但语义信息更丰富的特征图,从而提高对不同大小目标的检测能力。
1.4.3 检测头
检测头是目标检测模型的最后一部分,它根据前面网络提供的特征来预测目标的位置和类别。检测头的输出通常包括目标物体的边界框(Bounding Box)坐标和类别概率。
例如,在一个行人检测任务中,检测头会输出每个行人目标的位置(以边界框的形式,如左上角和右下角的坐标)以及该目标是行人的概率。
2、知识蒸馏
知识蒸馏(Knowledge Distillation)是一种模型压缩技术,主要用于将复杂的、高精度的大型模型(称为教师模型)的知识迁移到相对简单的小型模型(称为学生模型)中。
2.1 知识蒸馏常规流程
2.1.1 教师模型训练
数据准备: 首先收集大量的训练数据,这些数据应与目标任务相关。例如,在图像分类任务中,需要收集各种类别的图像,并且对这些图像进行标注,标注内容为图像中物体的正确类别。对于自然语言处理任务,如情感分析,需要收集带有情感标签(如正面、负面、中性)的文本。
模型选择与训练: 选择一个合适的复杂模型作为教师模型,通常是深度神经网络,如大型的 Transformer 架构或者深度卷积神经网络(CNN)。这个模型具有较强的学习能力和较高的容量,可以很好地拟合训练数据。然后使用常规的训练方法,如最小化预测结果与真实标签之间的交叉熵损失来训练教师模型。例如,在训练一个用于文本分类的教师模型时,将文本输入模型,模型输出文本所属类别的概率,通过调整模型参数使这个概率分布与真实标签的差异最小化。
训练策略: 在训练过程中,可能会使用优化算法,如随机梯度下降(SGD)或其变种 Adagrad、Adadelta 等,同时还可能采用一些正则化方法,如 L1 和 L2 正则化、Dropout 等来防止过拟合。
2.1.2 软标签生成
数据输入教师模型: 将训练数据(可以是全部训练数据,也部分额外的数据)逐一向已经训练好的教师模型输入。例如,对于一个包含 1000 张图像的数据集,将这 1000 张图像一张一张地输入教师模型。
获取软标签: 教师模型对每个输入的数据输出类别概率分布,这个概率分布就是软标签。例如,在图像分类任务中,教师模型对一张图像输出的软标签可能是 [0.1(类别 1),0.7(类别 2),0.2(类别 3)],这表示教师模型认为这张图像有 10% 的可能性属于类别 1,70% 属于类别 2,20% 属于类别 3。这些软标签会和原始的硬标签(真实的类别标注)一起用于学生模型的训练。
2.1.3 学生模型训练
**模型选择:**选择一个相对简单的模型作为学生模型,可以使同架构的浅层模型,也可以是异架构的模型,如Transformer模型。例如,在图像分类任务中,学生模型可以是一个层数较少的卷积神经网络。
损失函数定义: 定义一个特殊的损失函数,它一般包含两部分。一部分是学生模型预测结果与硬标签之间的交叉熵损失,这部分保证学生模型能够正确分类。另一部分是学生模型预测结果与教师模型软标签之间的蒸馏损失,也通常用交叉熵来计算。这两部分损失通过加权相加的方式组合在一起,例如,假设交叉熵损失的权重为,蒸馏损失的权重为。
训练过程: 使用带有硬标签和软标签的数据来训练学生模型。将数据输入学生模型,学生模型输出预测的类别概率分布。然后根据定义好的损失函数计算损失值,通过优化算法(如 SGD)来调整学生模型的参数,使损失值最小化。在这个过程中,学生模型既学习硬标签以保证准确性,又学习软标签来获取教师模型的知识,如教师模型对不同类别判断的模式等。经过多轮训练,学生模型在验证集上的性能逐渐提升,最终得到一个经过知识蒸馏的学生模型。
2.2 知识蒸馏的分类
2.2.1 按知识传递形式分类
logits级别蒸馏: 使用教师模型的输出概率分布作为软标签来指导学生模型的训练,如使用softmax的输出替换onehot label。
特征级别蒸馏: 不仅使用最后一层的输出,还使用中间层的特征图来指导学生模型,如FitNets,进行学生模型与教师模型在特征层面的对齐
2.2.2 按学习方式分类
离线蒸馏: 教师模型和学生模型分别独立训练,学生模型只使用教师模型的输出作为标签进行训练。优点是灵活可控、易于操作、成本较低。
在线蒸馏: 教师模型和学生模型同时参与训练和参数更新。优点是能够满足多任务、多领域任务,能够实时调整教师模型的知识提炼过程,但缺点是计算量大、时间成本高。
自蒸馏: 模型自己作为自己的教师,通过多次迭代来提升性能,如Be Your Own Teacher。
多模型蒸馏: 在蒸馏过程中有多个模型参与,各自集成其他模型输出的知识后进行学习。可分为多教师模型和集成学习的多模型蒸馏方式。
3、yolo系列模型的知识蒸馏
3.1 学术论文
https://sc.panda985.com/scholar?q=yolo%20distill 基于谷歌学术镜像,以yolo distill为关键词进行检索。
基于以下检索,可以发现一共是有7篇与yolo相关的知识蒸馏论文。但整体过下来,只有最后一篇文章(2021年某竞赛对应的文章)提供了高参考价值。此外,2018年的一个yolov3蒸馏论文也提供了部分参考信息,但没有被检索到。
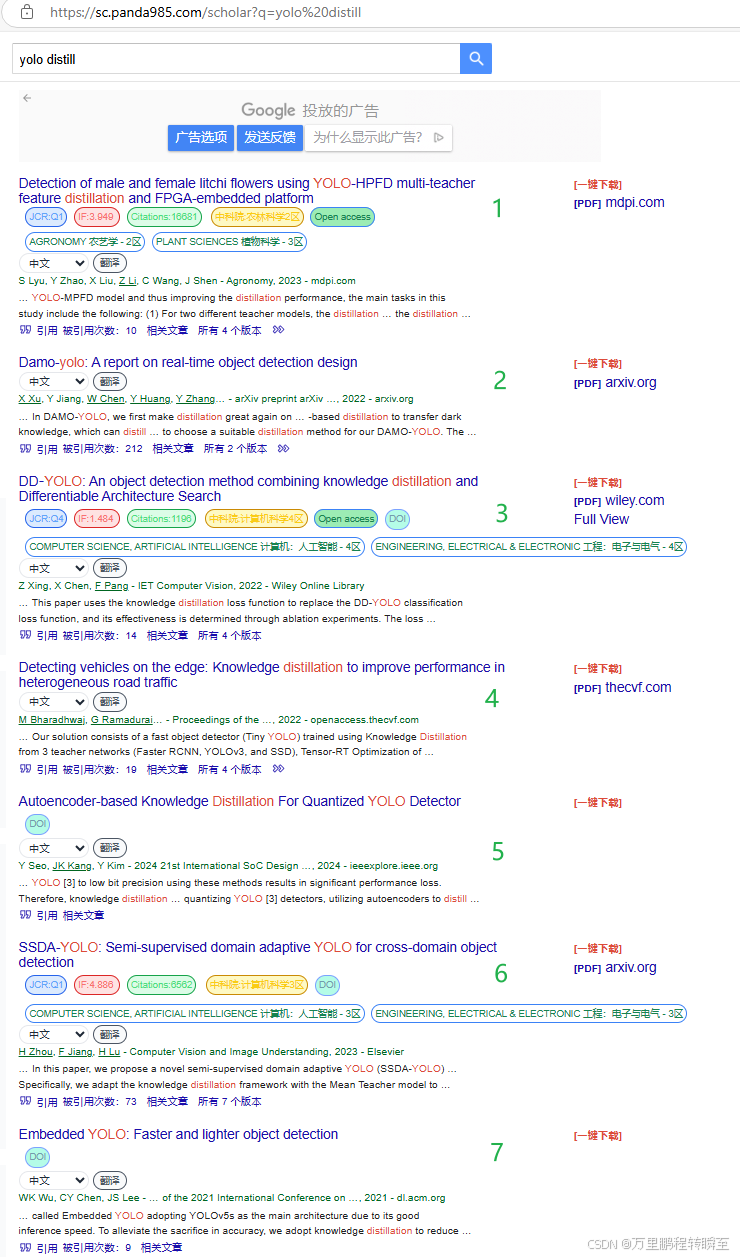
论文一 2023年
内容参考自Detection of Male and Female Litchi Flowers Using YOLO-HPFD Multi-Teacher Feature Distillation and FPGA-Embedded Platform
采用多教师预激活特征蒸馏(MPFD)技术,将YOLOv4和YOLOv5-l作为教师模型,将YOLOv4-Tiny作为学生模型,通过学习不同教师模型的中间特征知识,提高学生模型的在荔枝花检测方法检测性能。同时,采用了LogCosh-Squared函数作为蒸馏距离损失函数,采用边缘激活方法来改善教师模型传递给学生模型的特征。为了防止有效信息的丢失,还提出了采用卷积和组归一化(Conv-GN)结构进行学生模型的特征转换。
与未经过特征蒸馏的学生模型相比,经过MPFD特征蒸馏后的学生模型的mAP提高了4.42%,到94.21%;部署到FPGA嵌入式平台上的检测模型大小为5.91 MB,功耗仅为10 W,分别比服务器和PC平台上的检测模型低了73.85%和94.54%。
没有在公开数据集上进行实验,map高达94%,表明属于简单任务;在2023年没有采用YOLOv5-s做学生模型,可能表明直接蒸馏YOLOv5-s没有任何效果
论文二 2022年
内容参考自Damo-yolo: A report on real-time object detection design
-
本文提出了一种新的探测器DAMOYOLO,它在YOLO的基础上进行了扩展,并引入了更多的新技术,包括MAE-NAS主干、RepGFPN颈部、ZeroHead、aleigndota和蒸馏增强等。
-
DAMO-YOLO在公共COCO数据集上优于最先进的检测器(例如YOLO系列)。
3.DAMO-YOLO(微型/小型/中型)中提供了一套不同规模的模型,以支持不同的部署。代码和预训练模型在https://github.com/tinyvision/damoyolo上发布,支持ONNX和TensorRT。
与同时期的ppyole模型相比,DAMO-YOLO设计更为复杂,知识蒸馏只是论文中的常规操作,不是涨点关键,且性能提升并不显著
论文三 2022年
DD‐YOLO: An object detection method combining knowledge distillation and Differentiable Architecture Search
论文不可公开获取,分区为中科院四区,可信度不高
论文四 2022年
Detecting vehicles on the edge: Knowledge distillation to improve performance in heterogeneous road traffic
在过去几十年中,车辆数量的急剧增长需要显着改进的交通管理和规划。为了有效地管理流量,流量是一个基本参数。大多数方法在最先进的计算能力的假设下解决了车辆计数问题。随着最近经济高效的物联网 (IoT) 设备和边缘计算的增长,正在为此类设备定制多种机器学习模型。解决这些设备上的流量计数问题将使我们能够创建网络范围实时流量分析的实时仪表板。本文提出了一个 Detect-Track-Count (DTC) 框架,用于在边缘设备上有效地计算车辆数量。所提出的解决方案旨在使用集成知识蒸馏技术提高微型车辆检测模型的性能。在多个数据集上的实验结果表明,自定义知识蒸馏设置有助于更好地泛化微小目标检测器。
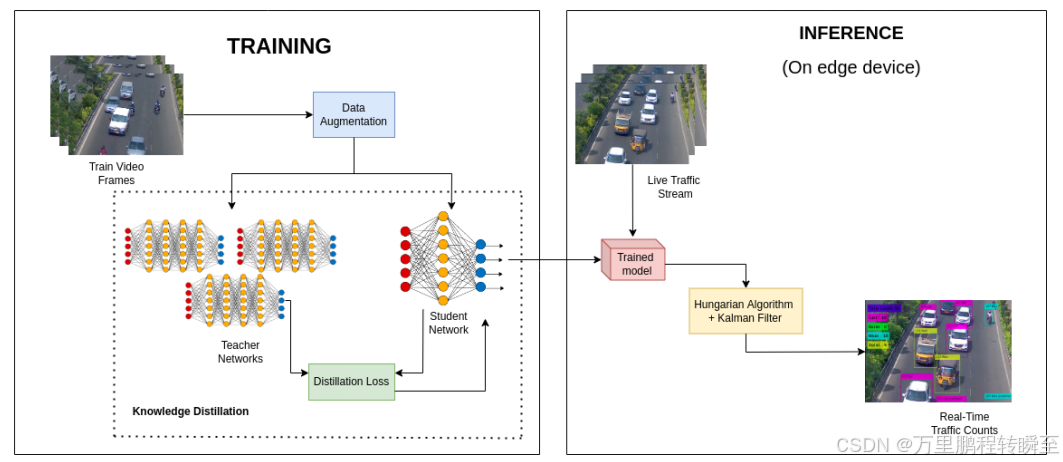
非coco数据集,voc数据集结果,参考价值不大
论文五 2024年
Autoencoder-based Knowledge Distillation For Quantized YOLO Detector
目标检测器如YOLO在量化到较低位精度时,性能往往会下降。为了缓解这个问题,研究人员探索了知识蒸馏(KD)方法与量化相结合。本文提出了一种使用自编码器对YOLO进行量化的新型KD方法。该方法涉及在全精度网络特征上训练一个自编码器,有效地将它们转移到量化网络中。将我们的方法应用于PASCAL VOC数据集上的YOLOv7-tiny,我们分别提高了LSQ和LLTQ方法的mAP(0.5:0.95) 0.6和0.9。与传统的KD方法相比,我们观察到mAP(0.5:0.95)提高了高达0.5。
针对yolov7模型进行蒸馏,在voc数据集上跑结果,理论上具备参考意义,但yolov7与yolov8相比,泛化能力存在显著差异,按这个策略蒸馏v7或许只是能让v7追平v8模型的泛化能力
论文六 2023年
SSDA-YOLO: Semi-supervised domain adaptive YOLO for cross-domain object detection
将知识蒸馏框架与MT模型相结合,帮助学生模型获得未标记目标领域的实例级特征,利用风格迁移转换在不同域交叉生成伪图像,弥补图像级差异。
论文特地在于实现跨域的知识蒸馏,一定程度上实现了教师模型的复用,在工程角度主要是节省了训练新教师模型的必要,价值不大
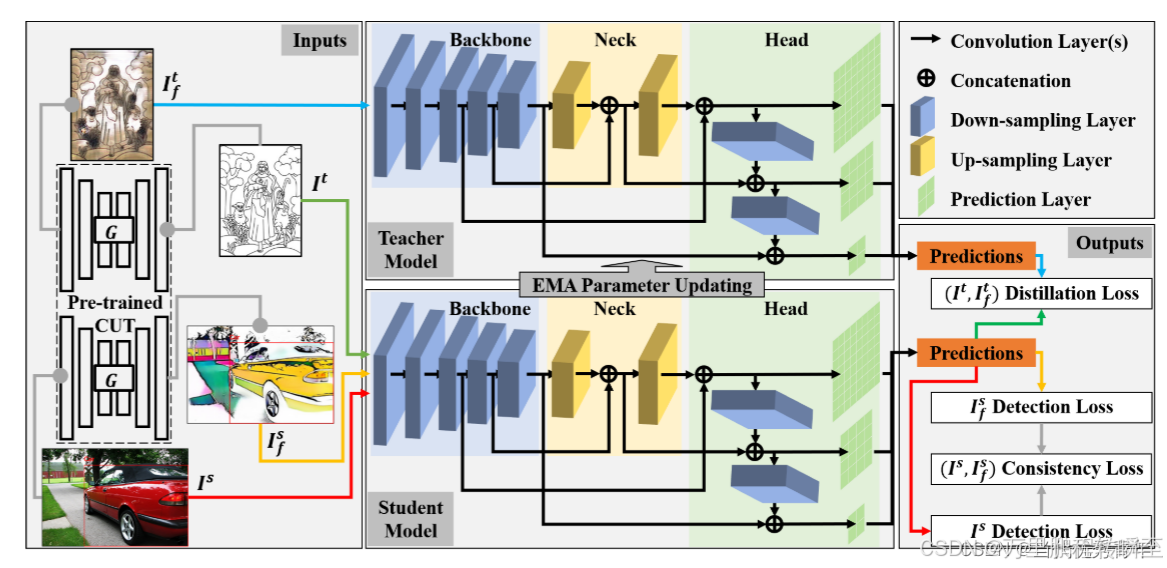
论文七 2021年
Embedded YOLO: Faster and lighter object detection
提出了DSC_CSP模块来替代YOLOv5s的中间层,以减少模型参数的数量。另一方面,为了避免因参数减少而导致性能下降,我们利用知识蒸馏来保持性能。为了充分利用数据增强提供的信息,我们提出了一种新方法,称为动态插值Mosaic,以改进原始的Mosaic方法。由于不同数据类型的样本数量严重不平衡,我们采用两阶段训练方案来克服数据不平衡问题。所提出的模型在ICMR2021大挑战PAIR竞赛(sar数据)中取得了最佳结果,mAP为0.59,模型大小为12MB,并且在联发科的Dimensity 1000平台上达到了41 FPS。
论文在比赛中验证了能力,此外暗含了模型参数量减少后拟合能力变差,需要更多的训练数据(故作者改进了Mosaic操作)
3.2 github开源状态
可以看到在github中搜索yolo+distill,主要是以yolov5为主的蒸馏,还有部分与yolov8相关的知识蒸馏。其中只有对moblibe-yolov5的蒸馏是有效的,对于其他更强模型的蒸馏都是无效的。
mobile-yolov5蒸馏
通过博主对第一个项目的探索,mobile-yolov5-pruning-distillation ,蒸馏moblibe-yolov5是确认有效的,map提升了3个点左右。
yolov5蒸馏
一共有两个项目:
https://github.com/YINYIPENG-EN/Knowledge_distillation_Pruning_Yolov5
https://github.com/Sharpiless/Yolov5-distillation-train-inference?tab=readme-ov-file
均没有分享蒸馏后模型的性能变化,预计是没有显著变化
yolov8蒸馏
https://github.com/huangzongmou/yolov8_Distillation
实现了2种蒸馏loss,可以看到并没有显著效果
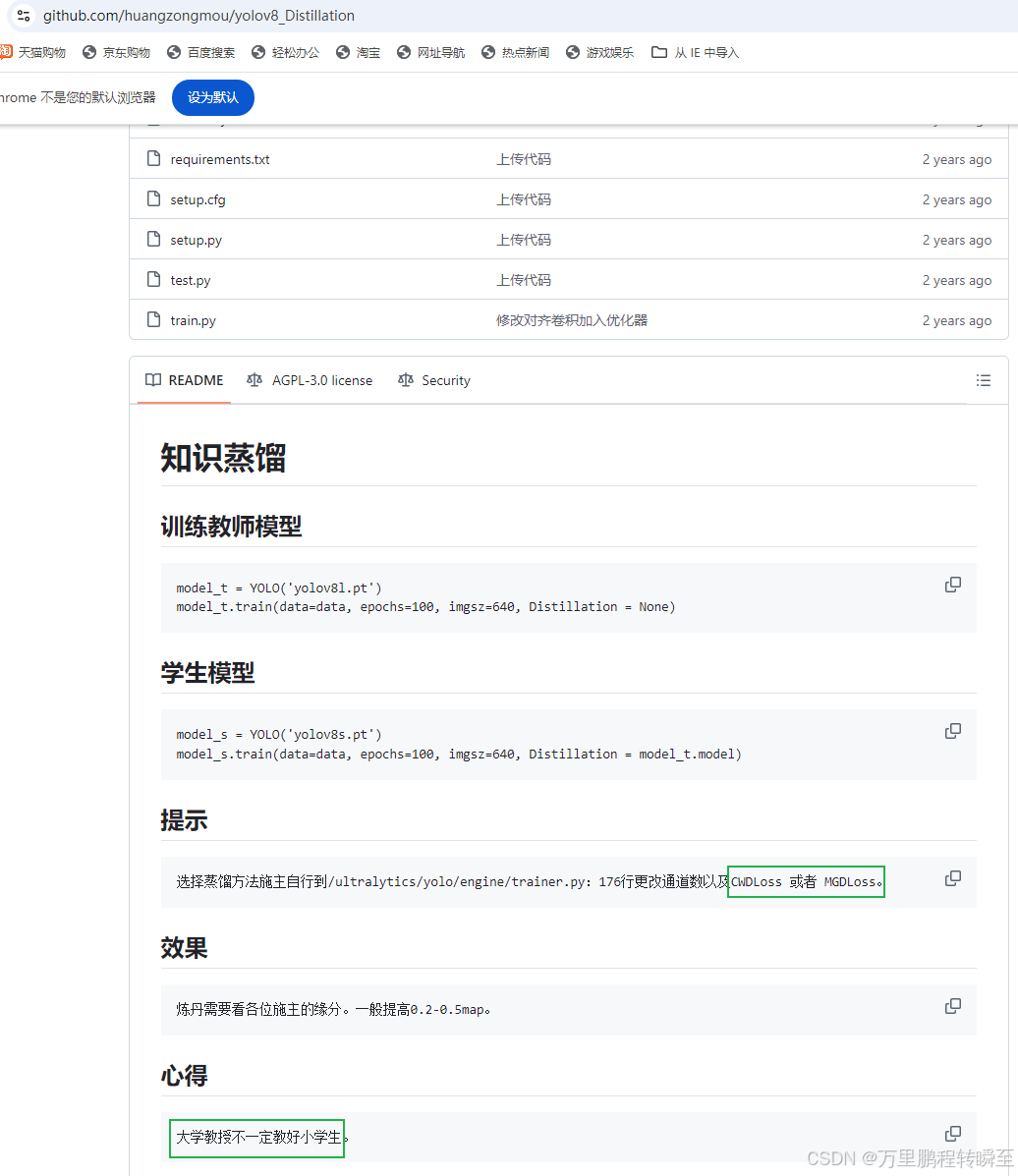
3.3 csdn开源
基于以下关键词在csdn进行检索,点击去后几乎没有任何一个博客明确指出在开源数据集上的精度变化。除了YOLOv8 知识蒸馏 | MGD 蒸馏 与 CWD 蒸馏 | 只涨精度不涨参数 !,但可以看到与github上开源的项目项目实现,与涨点量级基本上是一样的,非常轻微。

3.4 博主实操
为了验证知识蒸馏在yolov11模型上是否有效,博主采用voc2012数据集,用s模型蒸馏n模型,同时对比了知识蒸馏与迁移学习。基于以下实验,可以发现未得到有效训练的模型,再次进行知识蒸馏时,可以有显著涨点。同时,基于对coco预训练后的迁移权重,再次进行知识蒸馏时,可以发现基本上没有有效作用。
基于coco预训练模型,再训练voc2012数据集的教师模型,map为75.7
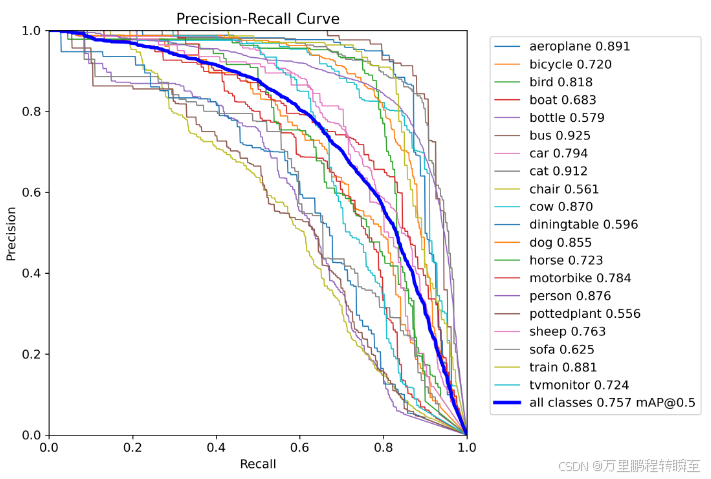
学生模型不使用coco数据初始化
直接训练的11n模型map为58.7
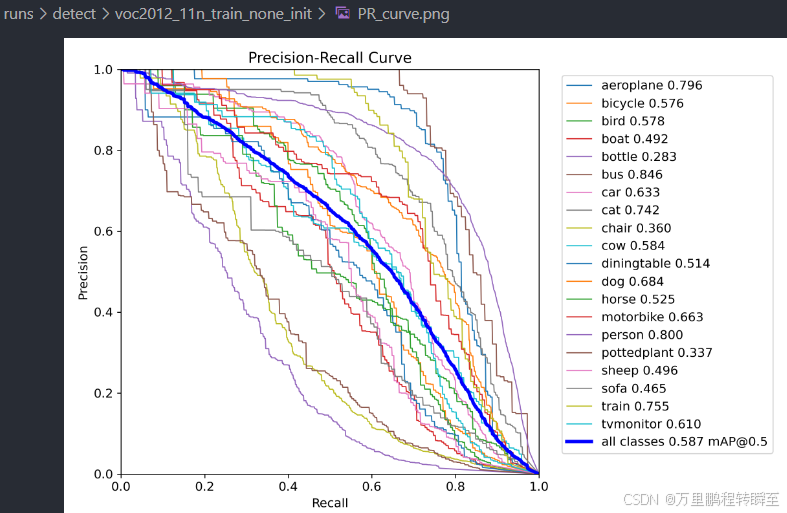
基于教师模型,按照论文Object detection at 200 Frames Per Second中方法,蒸馏学生模型后,map提升到63.6
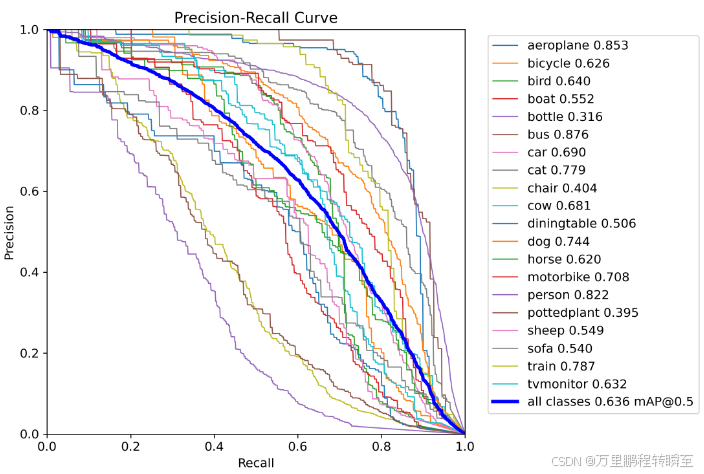
基于教师模型,按照论文Focal and Global Knowledge Distillation for Detectors中方法,蒸馏学生模型后,map提升到63.7
与58.7相比,可以发现未得到有效训练的模型,再次进行知识蒸馏时,可以有显著涨点。
与63.0相比,可以发现在模型充分训练后,再次进行知识蒸馏时,涨点是十分微弱的。
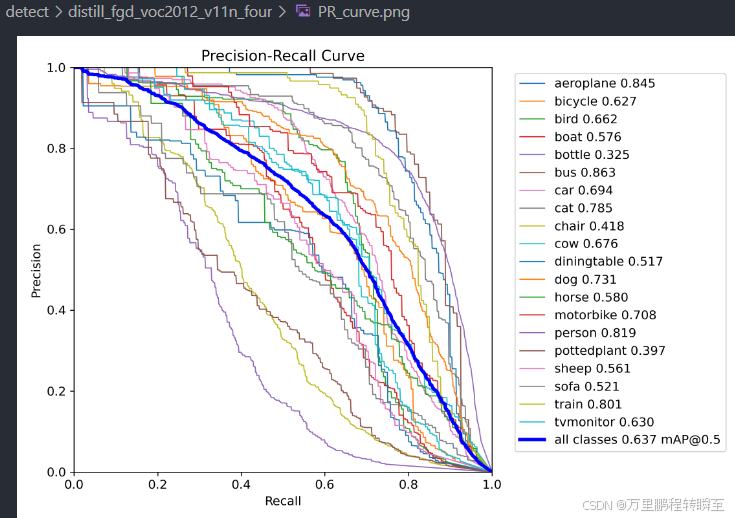
将map为58.7的11n模型,再次进行训练后,可以发现map提升到了63.0。
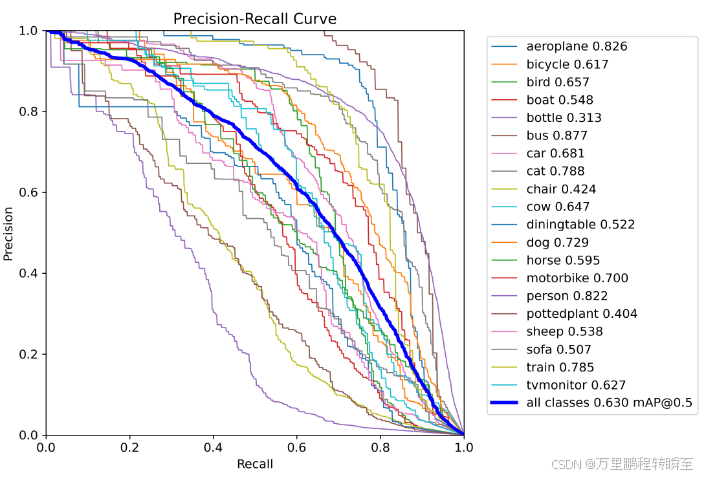
学生模型使用coco数据初始化
基于coco训练好的n模型,在voc2012数据集上map为71.3,比任何方法都要高
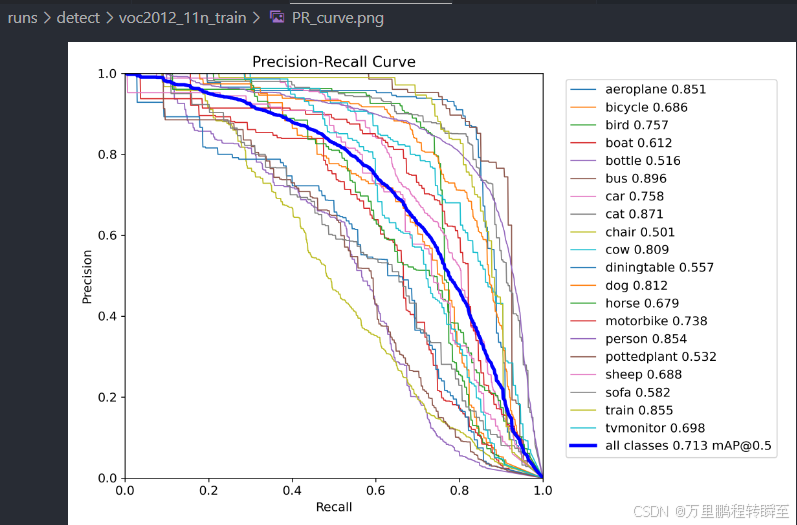
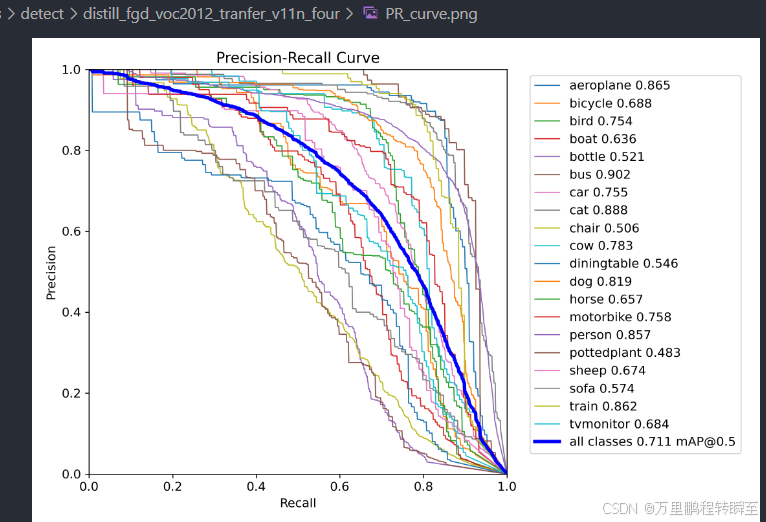
将coco迁移来的n模型,再使用fgd的方式进行蒸馏,可以发现map反而下降了0.2%
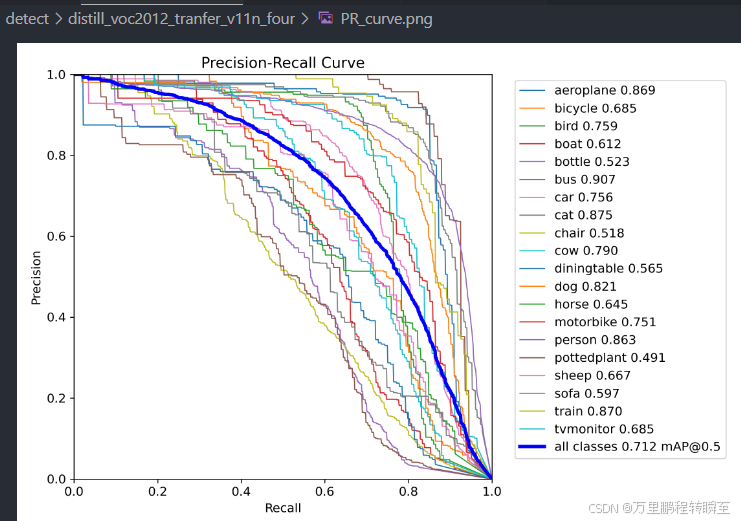
将coco迁移来的n模型,再使用Objectness scaled Distillation的方式进行蒸馏,可以发现map反而下降了0.1%
评论记录:
回复评论: