
机器学习笔记之前馈神经网络——M-P神经元模型与感知机的关系
引言
从本节开始,介绍反向传播算法( BackPropagation,BP ext{BackPropagation,BP} BackPropagation,BP),本节将介绍 M-P ext{M-P} M-P神经元模型与感知机算法的关系。
M-P ext{M-P} M-P神经元模型
本部分是针对前馈神经网络模型结构上的理论上的补充说明。详见《机器学习》(周志华著)P98。
M-P
ext{M-P}
M-P神经元模型由
1943
ext{1943}
1943年被提出,它是神经网络的基本组成单位:
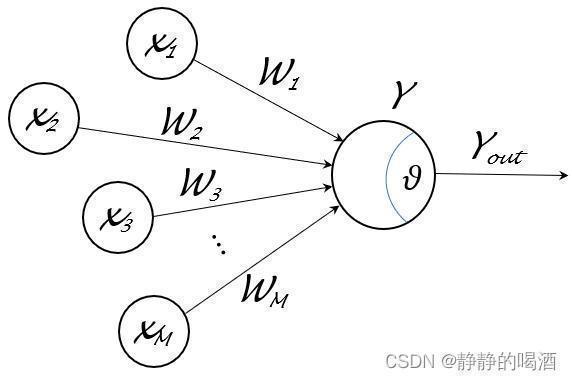
- 这里的 x m ( m = 1 , 2 , ⋯ , M ) x_m(m=1,2,cdots,mathcal M) xm(m=1,2,⋯,M)表示 M mathcal M M个其他神经元,如果是输入层,那么 x m x_m xm表示样本特征 X mathcal X X的随机变量集合;对应的 W m ( m = 1 , 2 , ⋯ , M ) mathcal W_m(m=1,2,cdots,mathcal M) Wm(m=1,2,⋯,M)表示各神经元向神经元 Y mathcal Y Y传递过程中对应的权重信息。
-
θ
heta
θ被称作阈值(
Threshold
ext{Threshold}
Threshold)。从逻辑意义的角度观察,它可以看作成一个触发器:一旦神经元
Y
mathcal Y
Y接收到的总输入值超过阈值
θ
heta
θ,那么神经元
Y
mathcal Y
Y就被激活,从而得到神经元
Y
mathcal Y
Y的输出结果
y
o
u
t
y_{out}
yout:
但从数学意义的角度观察,总输入值∑ m = 1 M W m x m sum_{m=1}^{mathcal M} mathcal W_mx_m ∑m=1MWmxm与阈值θ heta θ计算了它们之间的偏差∑ m = 1 M W m x m − θ sum_{m=1}^{mathcal M} mathcal W_mx_m - heta ∑m=1MWmxm−θ。也就是说,神经元Y mathcal Y Y总是会被激活的,只不过激活的效果视偏差结果而定。
y o u t = f ( ∑ m = 1 M W m x m − θ ) y_{out} = f left(sum_{m=1}^{mathcal M} mathcal W_m x_m - heta ight) yout=f(m=1∑MWmxm−θ)
其中
f
(
⋅
)
f(cdot)
f(⋅)表示激活函数(
Activation Function
ext{Activation Function}
Activation Function)。上式表示的具体流程为:
需要注意的点:
x
m
(
m
=
1
,
2
,
⋯
,
M
)
x_m(m=1,2,cdots,mathcal M)
xm(m=1,2,⋯,M)如果不是输出层的神经元,那么它们每个神经元也应存在对应的阈值,只不过上图没有将其画出而已。
- 神经元 Y mathcal Y Y将接收到其他 M mathcal M M个其他神经元 x x x的输入信号,并通过这些输入信号通过带权重 W mathcal W W的连接( Connection ext{Connection} Connection)向神经元 Y mathcal Y Y进行传递;
- 神经元 Y mathcal Y Y将接收到的总输入结果 ∑ m = 1 M W m x m sum_{m=1}^{mathcal M} mathcal W_m x_m ∑m=1MWmxm与神经元 Y mathcal Y Y的阈值 θ heta θ之间进行比较;
- 最终将比较结果 ∑ m = 1 M W m x m − θ sum_{m=1}^{mathcal M} mathcal W_mx_m - heta ∑m=1MWmxm−θ通过激活函数处理以产生神经元 Y mathcal Y Y的输出 y o u t y_{out} yout。
关于激活函数,理想状态下的激活函数就是指示函数自身:
当比较结果∑ m = 1 M W m x m − θ > 0 sum_{m=1}^{mathcal M} mathcal W_mx_m - heta>0 ∑m=1MWmxm−θ>0时,神经元Y mathcal Y Y必然以状态1 1 1的情况下被激活;相反,如果总输入结果< < <阈值时,神经元Y mathcal Y Y必然以和状态1 1 1相反的状态0 0 0情况下激活。之所以称之为‘理想状态’,是因为该函数的功能与上面描述的完全一致,没有出现流程错误的可能性。
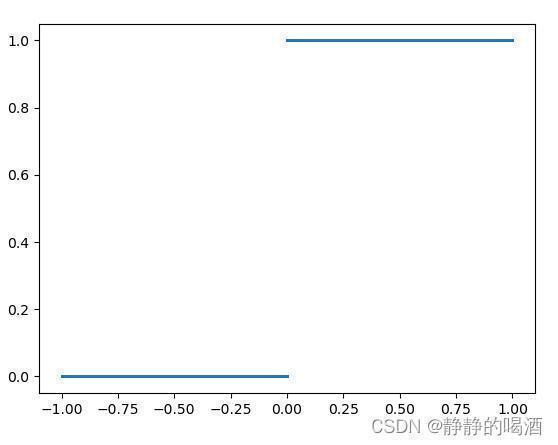
然而,指示函数自身并不是连续函数,着意味着该函数并非在其定义域内处处可导。如果针对损失函数求解连接权重 W m ( m = 1 , 2 , ⋯ , M ) mathcal W_m(m=1,2,cdots,mathcal M) Wm(m=1,2,⋯,M)的最优值,上述函数因无法求导而无法对权重信息进行更新,这并不是一个好的性质。
因此,实际上通常使用
Sigmoid
ext{Sigmoid}
Sigmoid函数作为激活函数。
Sigmoid
ext{Sigmoid}
Sigmoid函数图像表示如下:
关于
Sigmoid
ext{Sigmoid}
Sigmoid函数,不仅在‘激活函数’中提到过,在逻辑回归(
Logistic Regression
ext{Logistic Regression}
Logistic Regression),以及受限玻尔兹曼机(
Restricted Boltzmann Machine,RBM
ext{Restricted Boltzmann Machine,RBM}
Restricted Boltzmann Machine,RBM)——后验概率求解中都提到过相关性质。后续会专门写一篇关于
Sigmoid
ext{Sigmoid}
Sigmoid函数的总结。
标记-> 关键词:对数几率函数。
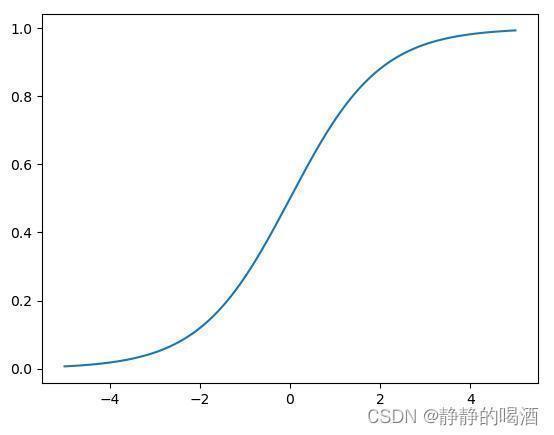
该函数的特点相比指示函数可在其定义域上处处连续、可导,这样在迭代求解连接权重时,能够对连接权重的最优方向进行计算;相反,依然从概率的角度观察,
Sigmoid
ext{Sigmoid}
Sigmoid激活函数并没有指示函数那样准确和果断:
- 当总输入结果超过阈值时,我们仅是分配一个 稍微高一点( > 0.5 >0.5 >0.5)的神经元激活状态。
- 相反,当总输入结果小于阈值时,依然存在一定神经元激活状态,只不过和指示函数相比,它们的区别可能小很多。
由于 Sigmoid ext{Sigmoid} Sigmoid函数能够把较大范围内变化的输入值压缩到 ( 0 , 1 ) (0,1) (0,1)范围的区间内,因而也称 Sigmoid ext{Sigmoid} Sigmoid函数为挤压函数 ( Squashing Function ) ( ext{Squashing Function}) (Squashing Function)。
而神经网络(
Neural Network
ext{Neural Network}
Neural Network)就是这些神经元模型按照一定的层次结构连接起来得到的模型结果。
‘按照一定层次结构’本质上是若干个
y
j
=
f
(
∑
m
=
1
M
W
m
x
m
−
θ
j
)
y_j = f left(sum_{m=1}^{mathcal M} mathcal W_mx_m - heta_j
ight)
yj=f(∑m=1MWmxm−θj)的嵌套结果。
M-P ext{M-P} M-P神经元模型与感知机算法
感知机算法的参数学习
既然知道了 M-P ext{M-P} M-P神经元模型对于任务的处理流程,下面通过感知机算法为例进行描述,它是如何实现这一过程的。
感知机算法( Perceptron ext{Perceptron} Perceptron)由两层神经元构成:
- 输入层:接收外界信号并将其传递给输出层;
- 输出层:该层由一个 M-P ext{M-P} M-P神经元组成,对输入层传递的信号进行计算,并根据计算结果对输入信号的性质进行判别。
感知机算法能够容易地实现与、或、非逻辑运算。关于 M-P ext{M-P} M-P神经元模型的计算流程: y = f ( ∑ m = 1 M W m x m − θ ) y = f left(sum_{m=1}^{mathcal M} mathcal W_mx_m - heta ight) y=f(∑m=1MWmxm−θ),假定激活函数 f ( ⋅ ) f(cdot) f(⋅)是指示函数,以逻辑与运算为例:
- 输入样本集合
D
AND
mathcal D_{ ext{AND}}
DAND:
D AND = { [ ( x 1 ( i ) , x 2 ( i ) ) , y ( i ) ] } i = 1 4 = { [ ( 1 , 1 ) , 1 ] , [ ( 1 , 0 ) , 0 ] , [ ( 0 , 1 ) , 0 ] , [ ( 0 , 0 ) , 0 ] } DAND={[(x(i)1,x(i)2),y(i)]}4i=1={[(1,1),1],[(1,0),0],[(0,1),0],[(0,0),0]}DAND={[(x1(i),x2(i)),y(i)]}i=14={[(1,1),1],[(1,0),0],[(0,1),0],[(0,0),0]}DAND={[(x(i)1,x(i)2),y(i)]}4i=1={[(1,1),1],[(1,0),0],[(0,1),0],[(0,0),0]} - 这里关于参数的学习过程暂时省略,先观察一个样本集合
D
AND
mathcal D_{ ext{AND}}
DAND学习正确的模型结果:
y = f ( 1 ⋅ x 1 + 1 ⋅ x 2 − 2 ) y = f left(1 cdot x_1 + 1 cdot x_2 - 2 ight) y=f(1⋅x1+1⋅x2−2)
可以发现,此时
D
AND
mathcal D_{ ext{AND}}
DAND中任意一个样本均可以通过该模型划分正确。其中
W
1
=
W
2
=
1
,
θ
=
2
mathcal W_1 = mathcal W_2 = 1, heta = 2
W1=W2=1,θ=2。继续从
M-P
ext{M-P}
M-P神经元模型的角度观察,激活函数
f
(
⋅
)
f(cdot)
f(⋅)内的项可表示为如下形式:
而公式中的
θ
=
x
3
heta = x_3
θ=x3被称作‘哑结点’
(
Dummy Node
)
( ext{Dummy Node})
(Dummy Node),其结果是某固定值,不发生变化。
1
⋅
x
1
+
1
⋅
x
2
−
2
⇒
W
1
⏟
=
1
⋅
x
1
+
W
2
⏟
=
1
⋅
x
2
+
W
3
⏟
=
2
⋅
x
3
⏟
θ
;
fixed;=-1
⇒
∑
m
=
1
3
W
m
⋅
x
m
1⋅x1+1⋅x2−2⇒W1⏟=1⋅x1+W2⏟=1⋅x2+W3⏟=2⋅x3⏟θ;fixed;=-1⇒3∑m=1Wm⋅xm
1⋅x1+1⋅x2−2⇒=1
W1⋅x1+=1
W2⋅x2+=2
W3⋅θ;fixed;=-1
x3⇒m=1∑3Wm⋅xm
这种操作意味着:阈值
θ
heta
θ我们不必计较它的数值具体是多少,我们仅需要将
W
3
mathcal W_3
W3学习正确,阈值自然迎刃而解。也就是说,权重参数和阈值的学习过程可统一为权重参数的学习。
感知机算法的参数调整
感知机算法对于权重参数的调整表示如下:
该部分是关于《机器学习》(周志华著)P99页中式5.1,式5.2的推导过程。
由于感知机算法策略的构建动机是错误驱动,我们将真实数据集
D
=
{
(
x
(
i
)
,
y
(
i
)
)
}
i
=
1
N
mathcal D = {(x^{(i)},y^{(i)})}_{i=1}^N
D={(x(i),y(i))}i=1N划分成两个部分:
- 被正确分类的样本集合:由于
f
(
⋅
)
f(cdot)
f(⋅)是指示函数,在定义域内,其函数结果非负,并且
y
(
i
)
y^{(i)}
y(i)与预测结果
W
T
x
(
i
)
mathcal W^Tx^{(i)}
WTx(i)之间同号。因而样本集合
D
True
mathcal D_{ ext{True}}
DTrue表示为:
D True = { ( x ( i ) , y ( i ) ) ∣ y ( i ) ( W T x ( i ) ) ≥ 0 } mathcal D_{ ext{True}} = left{(x^{(i)},y^{(i)}) mid y^{(i)} (mathcal W^Tx^{(i)}) geq 0 ight} DTrue={(x(i),y(i))∣y(i)(WTx(i))≥0} - 同理,被错误分类的样本集合
D
False
mathcal D_{ ext{False}}
DFalse:
D False = { ( x ( i ) , y ( i ) ) ∣ y ( i ) ( W T x ( i ) ) < 0 } mathcal D_{ ext{False}} = left{(x^{(i)},y^{(i)}) mid y^{(i)} (mathcal W^Tx^{(i)}) < 0 ight} DFalse={(x(i),y(i))∣y(i)(WTx(i))<0} - 并且有:
D = D True ∪ D False mathcal D = mathcal D_{ ext{True}} cup mathcal D_{ ext{False}} D=DTrue∪DFalse
分别观察两组集合:
-
首先观察分类正确的样本集合 D T r u e mathcal D_{True} DTrue:此时 y ( i ) = y ^ ( i ) y^{(i)} = hat y^{(i)} y(i)=y^(i),从权重学习的角度,我们希望集合 D True mathcal D_{ ext{True}} DTrue越接近 D mathcal D D越好,也就是说,在 D mathcal D D中,我们的 y ^ ( i ) ( W T x ( i ) ) hat y^{(i)} left(mathcal W^Tx^{(i)} ight) y^(i)(WTx(i))越大越好:
如果y ^ ( i ) ( W T x ( i ) ) hat y^{(i)} left(mathcal W^Tx^{(i)} ight) y^(i)(WTx(i))越大,越意味着‘有更多的样本被划分正确’,并将该逻辑应用在完整的数据集D mathcal D D中。
对应目标函数 L True ( W ) mathcal L_{ ext{True}}(mathcal W) LTrue(W)表示如下:
需要注意的点:该损失函数是基于y ( i ) = y ^ ( i ) y^{(i)} = hat y^{(i)} y(i)=y^(i)条件下实现的,并且y ^ ( i ) ( W T x ( i ) ) ≥ 0 hat y^{(i)} left(mathcal W^T x^{(i)} ight)geq0 y^(i)(WTx(i))≥0恒成立。因此一定求解的是最大值arg max mathop{argmax} argmax.
{ L True ( W ) = ∑ ( x ( i ) , y ( i ) ) ∈ D y ^ ( i ) ( W T x ( i ) ) arg max W L True ( W ) {LTrue(W)=∑(x(i),y(i))∈Dˆy(i)(WTx(i))argmaxWLTrue(W) ⎩ ⎨ ⎧LTrue(W)=∑(x(i),y(i))∈Dy^(i)(WTx(i))WargmaxLTrue(W)
对损失函数 L True ( W ) mathcal L_{ ext{True}}(mathcal W) LTrue(W)求解偏导:
∂ L True ( W ) ∂ W = ∇ W L True ( W ) = ∑ ( x ( i ) , y ( i ) ) ∈ D y ^ ( i ) x ( i ) frac{partial mathcal L_{ ext{True}}(mathcal W)}{partial mathcal W} = abla_{mathcal W} mathcal L_{ ext{True}}(mathcal W)=sum_{(x^{(i)},y^{(i)}) in mathcal D} hat y^{(i)}x^{(i)} ∂W∂LTrue(W)=∇WLTrue(W)=(x(i),y(i))∈D∑y^(i)x(i) -
同理,我们观察分类错误的样本集合 D False mathcal D_{ ext{False}} DFalse:由于 D False mathcal D_{ ext{False}} DFalse中 y ( i ) y^{(i)} y(i)与预测结果 W T x ( i ) mathcal W^Tx^{(i)} WTx(i)之间异号,因此该集合中的样本 y ( i ) ( W T x ( i ) ) ≤ 0 y^{(i)}left(mathcal W^Tx^{(i)} ight) leq 0 y(i)(WTx(i))≤0恒成立。从权重学习的角度观察, ∑ x ( i ) , y ( i ) ∈ D False y ( i ) ( W T x ( i ) ) sum_{x^{(i)},y^{(i)} in mathcal D_{ ext{False}}}y^{(i)}left(mathcal W^Tx^{(i)} ight) ∑x(i),y(i)∈DFalsey(i)(WTx(i))结果越大越好。
因为在小于 0 0 0的前提下,数值越大意味着错误分类的样本越少。并且我们希望将该逻辑应用在完整的数据集合 D mathcal D D中:
对应的目标函数 L False ( W ) mathcal L_{ ext{False}}(mathcal W) LFalse(W)表示如下:需要注意的点:该损失函数是基于y ^ ( i ) , y ( i ) hat y^{(i)},y^{(i)} y^(i),y(i)之间异号的条件下成立的,因而y ( i ) ( W T x ( i ) ) < 0 y^{(i)} left(mathcal W^Tx^{(i)} ight) < 0 y(i)(WTx(i))<0恒成立。为了和L True ( W ) mathcal L_{ ext{True}}(mathcal W) LTrue(W)同号,应将arg max W L False ( W ) mathop{argmax}limits_{mathcal W} mathcal L_{ ext{False}}(mathcal W) WargmaxLFalse(W)转化为相应的arg min W mathop{argmin}limits_{mathcal W} Wargmin形式。这里转化的核心原因:如果不转化,损失函数L False ( W ) mathcal L_{ ext{False}}(mathcal W) LFalse(W)没有下界;相反,如果转化了,L True ( W ) , L False ( W ) mathcal L_{ ext{True}}(mathcal W),mathcal L_{ ext{False}}(mathcal W) LTrue(W),LFalse(W)均恒正,并且均存在下界为0 0 0,这两个损失函数才能相加。
{ L False ( W ) = ∑ ( x ( i ) , y ( i ) ) ∈ D y ( i ) ( W T x ( i ) ) arg max W L False ( W ) ⇒ { L False ( W ) = − ∑ ( x ( i ) , y ( i ) ) ∈ D y ( i ) ( W T x ( i ) ) arg min W L False ( W ) {LFalse(W)=∑(x(i),y(i))∈Dy(i)(WTx(i))argmaxWLFalse(W)Rightarrow {LFalse(W)=−∑(x(i),y(i))∈Dy(i)(WTx(i))argminWLFalse(W)⎩ ⎨ ⎧LFalse(W)=∑(x(i),y(i))∈Dy(i)(WTx(i))WargmaxLFalse(W)⇒⎩ ⎨ ⎧LFalse(W)=−∑(x(i),y(i))∈Dy(i)(WTx(i))WargminLFalse(W)
对损失函数 L False ( W ) mathcal L_{ ext{False}}(mathcal W) LFalse(W)求解偏导:
∂ L False ( W ) ∂ W = ∇ W L False ( W ) = ∑ ( x ( i ) , y ( i ) ) ∈ D − y ( i ) x ( i ) frac{partial mathcal L_{ ext{False}}(mathcal W)}{partial mathcal W} = abla_{mathcal W} mathcal L_{ ext{False}}(mathcal W) = sum_{(x^{(i)},y^{(i)}) inmathcal D} -y^{(i)}x^{(i)} ∂W∂LFalse(W)=∇WLFalse(W)=(x(i),y(i))∈D∑−y(i)x(i)
至此,关于两个损失函数
L
True
(
W
)
,
L
False
(
W
)
mathcal L_{ ext{True}}(mathcal W),mathcal L_{ ext{False}}(mathcal W)
LTrue(W),LFalse(W)均恒正,并且下界均为
0
0
0,将两损失函数的梯度相加,有:
∇
W
L
(
W
)
=
∂
L
(
W
)
∂
W
=
∂
L
False
(
W
)
∂
W
+
∂
L
True
(
W
)
∂
W
=
∑
(
x
(
i
)
,
y
(
i
)
)
∈
D
(
y
^
(
i
)
−
y
(
i
)
)
x
(
i
)
∇WL(W)=∂L(W)∂W=∂LFalse(W)∂W+∂LTrue(W)∂W=∑(x(i),y(i))∈D(ˆy(i)−y(i))x(i)
∇WL(W)=∂W∂L(W)=∂W∂LFalse(W)+∂W∂LTrue(W)=(x(i),y(i))∈D∑(y^(i)−y(i))x(i)
最终,使用梯度下降法对模型参数进行迭代:
W
(
t
+
1
)
⇐
W
(
t
)
−
η
⋅
∇
W
L
(
W
)
=
W
(
t
)
+
η
∑
(
x
(
i
)
,
y
(
i
)
)
∈
D
(
y
(
i
)
−
y
^
(
i
)
)
x
(
i
)
W(t+1)⇐W(t)−η⋅∇WL(W)=W(t)+η∑(x(i),y(i))∈D(y(i)−ˆy(i))x(i)
W(t+1)⇐W(t)−η⋅∇WL(W)=W(t)+η(x(i),y(i))∈D∑(y(i)−y^(i))x(i)
观察这个关于
W
mathcal W
W的迭代公式,如果感知机对样本
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)},y^{(i)})
(x(i),y(i))预测正确,即
y
^
(
i
)
=
y
(
i
)
hat y^{(i)} = y^{(i)}
y^(i)=y(i),这意味着
W
(
t
+
1
)
=
W
(
t
)
mathcal W^{(t+1)} = mathcal W^{(t)}
W(t+1)=W(t),感知机模型的参数已经学习完成;否则继续根据误差的梯度对参数
W
mathcal W
W进行调整。
下一节将介绍反向传播算法( BackPropagation ext{BackPropagation} BackPropagation)。
相关参考:
机器学习(周志华著)
评论记录:
回复评论: