
机器学习笔记之优化算法——收敛速度的简单认识
引言
本节对收敛速度简单介绍。
收敛速度的判别标准
我们之前几节介绍了线搜索方法
(
Line Search Method
)
( ext{Line Search Method})
(Line Search Method),并从方向角度、步长角度描述了先搜索方法的迭代优化过程。关于针对目标函数
f
(
X
)
f(mathcal X)
f(X)优化的终极目标:
min
X
∈
R
n
f
(
X
)
mathop{min}limits_{mathcal X in mathbb R^n} f(mathcal X)
X∈Rnminf(X),我们希望通过一系列数值解
{
x
k
}
k
=
0
∞
{x_k}_{k=0}^{infty}
{xk}k=0∞,使其对应的目标函数结果
{
f
(
x
k
)
}
k
=
0
∞
{f(x_k)}_{k=0}^{infty}
{f(xk)}k=0∞收敛到最优值
f
∗
f^*
f∗:
也可以等价写作:
{
x
k
}
k
=
0
∞
⇒
x
∗
;
f
(
x
∗
)
=
f
∗
{x_k}_{k=0}^{infty} Rightarrow x^*;f(x^*) = f^*
{xk}k=0∞⇒x∗;f(x∗)=f∗。其中
x
∗
x^*
x∗则表示迭代产生的最优数值解:
x
∗
=
arg
min
X
∈
R
n
f
(
X
)
x^* = mathop{argmin}limits_{mathcal X in mathbb R^n} f(mathcal X)
x∗=X∈Rnargminf(X)
{
f
(
x
k
)
}
k
=
0
∞
⇒
f
∗
{f(x_k)}_{k=0}^{infty} Rightarrow f^*
{f(xk)}k=0∞⇒f∗
本节将介绍两种关于收敛速度的判别标准: Q mathcal Q Q-收敛速度与 R mathcal R R-收敛速度。
Q mathcal Q Q-收敛速度
其中 Q mathcal Q Q-收敛速度中的 Q mathcal Q Q是指: Quotient ext{Quotient} Quotient,也就是除法中的商。该方式主要围绕迭代过程中数值解 x k , x k + 1 x_k,x_{k+1} xk,xk+1与最优解 x ∗ x^* x∗之间差异性的商值对收敛速度进行描述:
由于x k , x k + 1 , x ∗ x_k,x_{k+1},x^* xk,xk+1,x∗可能是∈ R n in mathbb R^n ∈Rn的向量,因此关于差异性的描述使用范数进行表示。而这个范数也可以理解为:数值解与最优解之间的距离,是一个正值。
lim k ⇒ ∞ ∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ mathop{lim}limits_{k Rightarrow infty} frac{||x_{k+1} - x^*||}{||x_k - x^*||} k⇒∞lim∣∣xk−x∗∣∣∣∣xk+1−x∗∣∣
在判断是否为 Q mathcal Q Q-收敛时,我们事先假定:
-
k
k
k充分大——这意味着
x
k
,
x
k
+
1
x_k,x_{k+1}
xk,xk+1都经过充分迭代产生的数值解,因而它们均无限趋近于
x
∗
x^*
x∗。也就是说:无论
∣
∣
x
k
+
1
−
x
∗
∣
∣
||x_{k+1} - x^*||
∣∣xk+1−x∗∣∣还是
∣
∣
x
k
−
x
∗
∣
∣
||x_{k} - x^*||
∣∣xk−x∗∣∣,它们都可视作无穷小量:
{ lim k ⇒ ∞ ∣ ∣ x k + 1 − x ∗ ∣ ∣ = 0 lim k ⇒ ∞ ∣ ∣ x k − x ∗ ∣ ∣ = 0⎩ ⎨ ⎧k⇒∞lim∣∣xk+1−x∗∣∣=0k⇒∞lim∣∣xk−x∗∣∣=0{ lim k ⇒ ∞ | | x k + 1 − x ∗ | | = 0 lim k ⇒ ∞ | | x k − x ∗ | | = 0 -
x
k
x_k
xk与
f
(
x
k
)
f(x_k)
f(xk)同理——这个意思并不是说
x
k
x_k
xk与
f
(
x
k
)
f(x_k)
f(xk)可以进行相互替换,而是说在
Q
mathcal Q
Q-收敛中,
f
(
x
k
)
f(x_k)
f(xk)与·
x
k
x_k
xk一样存在相同形式的定义:
这两个定义在Q mathcal Q Q-收敛中没有区别,针对具体情况都可以进行使用。
lim k ⇒ ∞ ∣ ∣ f ( x k + 1 ) − f ∗ ∣ ∣ ∣ ∣ f ( x k ) − f ∗ ∣ ∣ mathop{lim}limits_{k Rightarrow infty} frac{|| f(x_{k+1}) - f^*||}{||f(x_k) - f^*||} k⇒∞lim∣∣f(xk)−f∗∣∣∣∣f(xk+1)−f∗∣∣
我们根据收敛速度的强度由低到高介绍 4 4 4种 Q mathcal Q Q-收敛:
-
Q mathcal Q Q-次线性收敛 ( Q-SubLinear Convergence ) ( ext{Q-SubLinear Convergence}) (Q-SubLinear Convergence),其定义用数学符号表示为:
lim k ⇒ ∞ ∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ = 1 mathop{lim}limits_{k Rightarrow infty} frac{||x_{k+1} - x^*||}{||x_k - x^*||} = 1 k⇒∞lim∣∣xk−x∗∣∣∣∣xk+1−x∗∣∣=1 -
Q mathcal Q Q-线性收敛 ( Q-Linear Convergence ) ( ext{Q-Linear Convergence}) (Q-Linear Convergence)。对应数学符号表示为:
∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ ≤ a ∈ ( 0 , 1 ) frac{||x_{k+1} - x^*||}{||x_k - x^*||} leq a in (0,1) ∣∣xk−x∗∣∣∣∣xk+1−x∗∣∣≤a∈(0,1)
我们发现,与 Q mathcal Q Q-次线性收敛不同的是,它并没有加极限符号。并且:差异性的比值被 ( 0 , 1 ) (0,1) (0,1)范围内的常数 a a a限制着。例如:目标函数值集合 { f ( x k ) } k = 0 ∞ {f(x_k)}_{k=0}^{infty} {f(xk)}k=0∞服从函数 G ( k ) = 2 − k mathcal G(k) = 2^{-k} G(k)=2−k。其定义域内对应的函数图像表示如下:
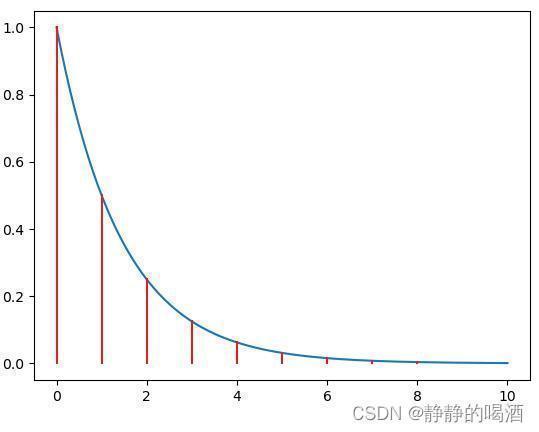
可以发现:随着 k ⇒ ∞ k Rightarrow infty k⇒∞,可以得到最优解 f ∗ = 0 f^* = 0 f∗=0,而对应的 ∣ ∣ f ( x k + 1 ) − f ∗ ∣ ∣ ∣ ∣ f ( x k ) − f ∗ ∣ ∣∣∣f(xk)−f∗∣∣∣∣f(xk+1)−f∗∣∣在图像中可表示为相邻红色直线之间的比值。这个比值的计算结果为:| | f ( x k + 1 ) − f ∗ | | | | f ( x k ) − f ∗ | |
∣ ∣ f ( x k + 1 ) − f ∗ ∣ ∣ ∣ ∣ f ( x k ) − f ∗ ∣ ∣ = 2 − ( k + 1 ) − 0 2 − k − 0 = 1 2 frac{||f(x_{k+1}) - f^*||}{||f(x_k) - f^*||} = frac{2^{-(k+1)} - 0}{2^{-k} - 0} = frac{1}{2} ∣∣f(xk)−f∗∣∣∣∣f(xk+1)−f∗∣∣=2−k−02−(k+1)−0=21
因此,由 G ( k ) mathcal G(k) G(k)表示的 { f ( x k ) } k = 0 ∞ {f(x_k)}_{k=0}^{infty} {f(xk)}k=0∞是 a = 1 2a=21的 Q mathcal Q Q-线性收敛。a = 1 2
此处所谓线性是指:将 { f ( x k ) } k = 0 ∞ {f(x_k)}_{k=0}^{infty} {f(xk)}k=0∞视作为误差序列。也就是说:随着迭代次数 k k k的增加,误差信息 G ( k ) mathcal G(k) G(k)越来越小,最终减少到 0 0 0。对误差取对数操作后,其结果 log G ( k ) log mathcal G(k) logG(k)与 k k k之间呈线性关系:
这里关于log log log取底数为2 2 2。
log G ( k ) = log 2 2 − k = − k log mathcal G(k) = log_2 2^{-k} =-k logG(k)=log22−k=−k
当 a a a取到极限 1 1 1时, Q mathcal Q Q-线性收敛会退化至 Q mathcal Q Q-次线性收敛;相反,当 a a a取到极限 0 0 0时, Q mathcal Q Q-线性收敛会进化至 Q mathcal Q Q-超线性收敛。反过来说:- 为什么被称作
Q
mathcal Q
Q-次线性收敛是因为:相比
Q
mathcal Q
Q-线性收敛中相邻迭代产生的差异性比值能够明显地用
a
∈
(
0
,
1
)
a in (0,1)
a∈(0,1)描述出来;而
Q
mathcal Q
Q-次线性收敛中相邻迭代产生的差异性几乎完全相同,它们之间的差距可以忽略不计。从而才有:
很明显,相比Q mathcal Q Q-次线性收敛,Q mathcal Q Q-线性收敛的差异性更明显,收敛的速度更快。
lim k ⇒ ∞ ∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ = 1 mathop{lim}limits_{k Rightarrow infty} frac{||x_{k+1} - x^*||}{||x_k - x^*||} = 1 k⇒∞lim∣∣xk−x∗∣∣∣∣xk+1−x∗∣∣=1
例如: G ( k ) = 1 kG(k)=k1就是一个明显的 Q mathcal Q Q-次线性收敛。其对应函数图像表示如下:G ( k ) = 1 k
很明显,相比上述的G ( k ) = 2 − k mathcal G(k)=2^{-k} G(k)=2−k,随着迭代次数k k k的增加,相邻红色线比值的变化并不非常明显。
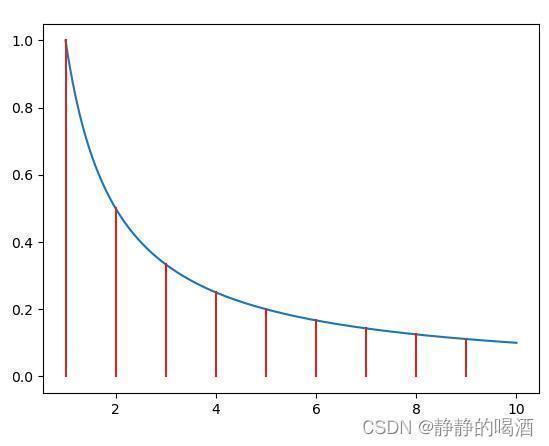
其次通过计算比值也能观察到类似的效果:
很明显,当充分迭代之后,此时k k k已经充分大,而k k + 1k+1kk k + 1 这样的收敛效果完全可以忽略不计。
lim k ⇒ ∞ ∣ ∣ f ( x k + 1 ) − f ∗ ∣ ∣ ∣ ∣ f ( x k ) − f ∗ ∣ ∣ = lim k ⇒ ∞ 1 k + 1 − 0 1 k − 0 = lim k ⇒ ∞ k k + 1 = 1 mathop{lim}limits_{k Rightarrow infty}frac{||f(x_{k+1}) - f^*||}{||f(x_k) - f^*||} = mathop{lim}limits_{k Rightarrow infty}frac{frac{1}{k+1} - 0}{frac{1}{k} - 0} = mathop{lim}limits_{k Rightarrow infty}frac{k}{k+1} = 1 k⇒∞lim∣∣f(xk)−f∗∣∣∣∣f(xk+1)−f∗∣∣=k⇒∞limk1−0k+11−0=k⇒∞limk+1k=1
- 为什么被称作
Q
mathcal Q
Q-次线性收敛是因为:相比
Q
mathcal Q
Q-线性收敛中相邻迭代产生的差异性比值能够明显地用
a
∈
(
0
,
1
)
a in (0,1)
a∈(0,1)描述出来;而
Q
mathcal Q
Q-次线性收敛中相邻迭代产生的差异性几乎完全相同,它们之间的差距可以忽略不计。从而才有:
-
与 Q mathcal Q Q-次线性收敛相反, Q mathcal Q Q-超线性收敛 ( Q-Superlinear Convergence ) ( ext{Q-Superlinear Convergence}) (Q-Superlinear Convergence)的定义用数学符号表示为:
这意味着相邻迭代次数之间差异性极大,使得x k + 1 x_{k+1} xk+1对应的差异性结果与x k x_k xk的差异性结果相比小到可以忽略不计,这里不再过多赘述。
lim k ⇒ ∞ ∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ = 0 mathop{lim}limits_{k Rightarrow infty} frac{||x_{k+1} - x^*||}{||x_k - x^*||} = 0 k⇒∞lim∣∣xk−x∗∣∣∣∣xk+1−x∗∣∣=0 -
Q mathcal Q Q-二次收敛 ( Q-Quadratic Convergence ) ( ext{Q-Quadratic Convergence}) (Q-Quadratic Convergence)的定义用数学符号表示为:
同理,如Q mathcal Q Q-三次收敛 ( Cubic Convergence ) ( ext{Cubic Convergence}) (Cubic Convergence)等等,仅与分母中的指数项相关。相比于线性收敛中a ∈ ( 0 , 1 ) a in (0, 1) a∈(0,1),我们在Q mathcal Q Q-二次收敛中不会更多计较a a a的范围,因为无穷小量的级别就可以说明其收敛速度。
∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ 2 ≤ a ∈ ( 0 , + ∞ ) frac{||x_{k+1} - x^*||}{||x_k - x^*||^2} leq a in (0,+infty) ∣∣xk−x∗∣∣2∣∣xk+1−x∗∣∣≤a∈(0,+∞)
与 Q mathcal Q Q-线性收敛的定义类似,也同样没有极限符号。由于 ∣ ∣ x k − x ∗ ∣ ∣ ||x_k - x^*|| ∣∣xk−x∗∣∣自身就是一个无穷小量,那么它的平方结果可理解为一个更高级别的无穷小量,反过来说明:如果 x k + 1 x_{k+1} xk+1差异性所描述的无穷小量与 x k x_k xk差异性的平方所描述的无穷小量是一个级别的话,那么它的收敛速度已经超越了线性范畴。
例如: G ( k ) = 2 − 2 k mathcal G(k) = 2^{-2^{k}} G(k)=2−2k就是明显的 Q mathcal Q Q-二次收敛。其对应的函数图像表示如下:
很明显,相比上面的收敛,它的收敛速度更快了,这里不再过多赘述。
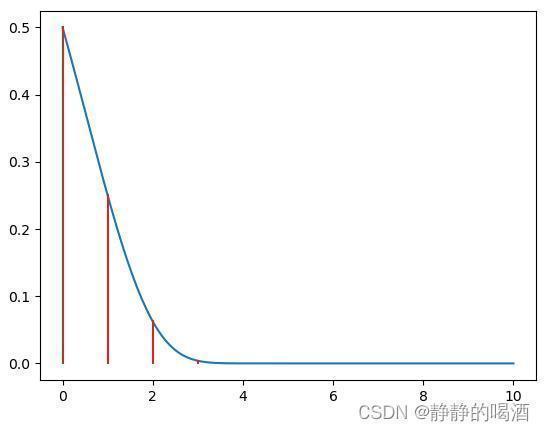
对应比值的计算结果是:
G ( k + 1 ) − 0 [ G ( k ) ] 2 = 2 − 2 k + 1 [ 2 − 2 k ] 2 = 1 ∈ ( 0 , + ∞ )[G(k)]2G(k+1)−0=[2−2k]22−2k+1=1∈(0,+∞)G ( k + 1 ) − 0 [ G ( k ) ] 2 = 2 − 2 k + 1 [ 2 − 2 k ] 2 = 1 ∈ ( 0 , + ∞ )
R mathcal R R-收敛速度
其中 R mathcal R R-收敛速度中的 R mathcal R R是指: Root ext{Root} Root。关于假设条件与 Q mathcal Q Q-收敛速度相同,这里不再赘述:
- k k k充分大;
- x k x_k xk与 f ( x k ) f(x_k) f(xk)共用相同概念。
关于
R
mathcal R
R-收敛速度定义的数学符号表示如下:
∣
∣
x
k
−
x
∗
∣
∣
≤
t
k
||x_k - x^*|| leq t_k
∣∣xk−x∗∣∣≤tk
其中
∣
∣
x
k
−
x
∗
∣
∣
||x_k - x^*||
∣∣xk−x∗∣∣依然是数值解与最优解之间的差异性信息(距离范数);该结果被另外一个序列
{
t
k
}
k
=
0
∞
{t_k}_{k=0}^{infty}
{tk}k=0∞限制住:
- 如果 t k t_k tk是 Q mathcal Q Q-次线性/线性/超线性/二次收敛;
- 并且
lim
k
⇒
∞
t
k
=
0
mathop{lim}limits_{k Rightarrow infty} t_k = 0
k⇒∞limtk=0;
这说明{ t k } k = 0 ∞ {t_k}_{k=0}^{infty} {tk}k=0∞是一个误差序列而不是数值解序列。上面的函数例子中,我们使用这些函数描述的是数值解序列 { x k } k = 0 ∞ {x_k}_{k=0}^{infty} {xk}k=0∞或者 { f ( x k ) } k = 0 ∞ {f(x_k)}_{k=0}^{infty} {f(xk)}k=0∞,但这里示例函数G ( k ) mathcal G(k) G(k)最终都会收敛到0 0 0,因而也可以将其视作误差序列。
则称
x
k
x_k
xk是
R
mathcal R
R-次线性/线性/超线性/二次收敛。
可以看出:
Q
mathcal Q
Q与
R
mathcal R
R的区别在于:
关于差异性的描述:Q ⇒ ∣ ∣ x k + 1 − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ p ( p = 1 , 2 , 3 , ⋯ )Q⇒∣∣xk−x∗∣∣p∣∣xk+1−x∗∣∣(p=1,2,3,⋯)Q ⇒ | | x k + 1 − x ∗ | | | | x k − x ∗ | | p ( p = 1 , 2 , 3 , ⋯ ) 与R ⇒ ∣ ∣ x k − x ∗ ∣ ∣ mathcal R Rightarrow ||x_k - x^*|| R⇒∣∣xk−x∗∣∣相比于Q mathcal Q Q中使用具体值(0、1)或者范围 ( 0 , 1 ) ; ( 0 , + ∞ ) (0,1);(0,+infty) (0,1);(0,+∞), R mathcal R R则使用误差序列 { t k } k = 0 ∞ {t_k}_{k=0}^{infty} {tk}k=0∞,并且每一个迭代步骤k = 0 , 1 , 2 , ⋯ k=0,1,2,cdots k=0,1,2,⋯均被对应{ t k } k = 0 ∞ {t_k}_{k=0}^{infty} {tk}k=0∞中的t 0 , t 1 , t 2 , ⋯ t_0,t_1,t_2,cdots t0,t1,t2,⋯限制住。
之所以会定义
R
mathcal R
R-收敛速度,原因在于:一些情况下,
Q
mathcal Q
Q-收敛速度不容易求解,如果找到一组合适的
{
t
k
}
k
=
0
∞
{t_k}_{k=0}^{infty}
{tk}k=0∞,可以根据
t
k
t_k
tk的收敛速度,从而对
x
k
x_k
xk的收敛速度进行表达。例如:
∣
∣
f
(
x
k
)
−
f
∗
∣
∣
≤
G
(
k
)
=
1
k
||f(x_k) - f^*|| leq mathcal G(k) = frac{1}{k}
∣∣f(xk)−f∗∣∣≤G(k)=k1
我们已经知道:满足
G
(
k
)
mathcal G(k)
G(k)的误差序列是
Q
mathcal Q
Q-次线性收敛,因而可以判断
{
f
(
x
k
)
}
k
=
0
∞
{f(x_k)}_{k=0}^{infty}
{f(xk)}k=0∞是
R
−
mathcal R-
R−次线性收敛。
关于算法复杂度与收敛速度
在真实情况下,我们不能任由算法无限迭代下去,即
k
k
k不能无限大。因而我们会设置一些判断条件。例如:
这里
ϵ
epsilon
ϵ表示描述限制条件的超参数。达到该条件,即可停止算法。
∣
∣
f
(
x
k
)
−
f
∗
∣
∣
≤
ϵ
||f(x_k) - f^*|| leq epsilon
∣∣f(xk)−f∗∣∣≤ϵ
- 如果依然以
Q
mathcal Q
Q-次线性收敛
1
k
k1为例,需要满足:
1 k
∣ ∣ f ( x k ) − f ∗ ∣ ∣ ≤ G ( k ) = 1 k ≤ ϵ ⇒ k ≥ 1 ϵ ||f(x_k) - f^*|| leq mathcal G(k) =frac{1}{k} leq epsilon Rightarrow k geq frac{1}{epsilon} ∣∣f(xk)−f∗∣∣≤G(k)=k1≤ϵ⇒k≥ϵ1
可以看出:当 ϵ epsilon ϵ越小时,迭代的次数 k k k越大。 - 如果以
Q
mathcal Q
Q-线性收敛
2
−
k
2^{-k}
2−k为例,需要满足:
2 − k ≤ ϵ ⇒ k ≥ log 2 1 ϵ 2^{-k} leq epsilon Rightarrow k geq log_2 frac{1}{epsilon} 2−k≤ϵ⇒k≥log2ϵ1
可以观察到:在
ϵ
epsilon
ϵ很小的情况下,关于
1
ϵ
随着
1
ϵ
的增加,
Q
mathcal Q
Q-次线性收敛(蓝色直线)与
Q
mathcal Q
Q-线性收敛(橙色曲线)对应的函数结果相比,其对应函数值的增速明显更高,而更高意味着更多的迭代步骤。
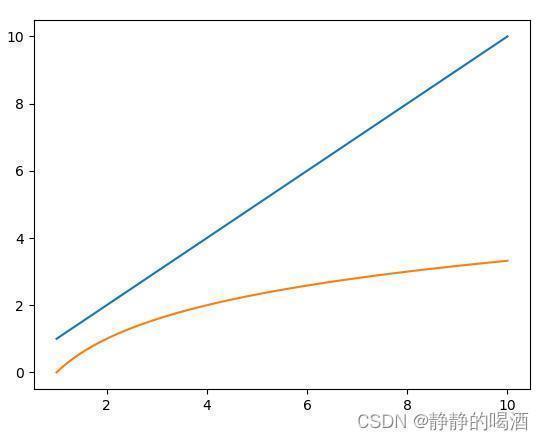
因此,一般情况下,使用更高强度的收敛速度,那么他的迭代步骤就会减小,从而降低算法复杂度。
相关参考:
【优化算法】收敛速度简介
优化里的Q-linear Convergence和R-linear convergence是什么意思?
评论记录:
回复评论: