
机器学习笔记之优化算法——线搜索方法[方向角度]
引言
上一节对优化问题进行了简单描述,并从逻辑认知的角度介绍了线搜索方法与信赖域方法。本节将关注线搜索方法,并重点关注它的方向部分。
回顾:线搜索方法
线搜索方法是一种通过求解数值解来计算最优解的方法。其特点是:在数值解的迭代求解过程中,分为方向与步长分别执行,并且先定方向,后定步长。对应的数学符号表达如下:
x
k
+
1
=
x
k
+
α
k
⋅
P
k
x_{k+1} = x_k + alpha_k cdot mathcal P_k
xk+1=xk+αk⋅Pk
其中
α
k
alpha_k
αk表示步长,
P
k
mathcal P_k
Pk表示方向。并且步长的重要程度高于方向。
从方向角度观察线搜索方法
我们首先对优化问题(场景)进行一系列的假设以达到简化作用。
场景构建
假设1:目标函数结果的单调性
关于变量
X
mathcal X
X的目标函数
f
(
X
)
f(mathcal X)
f(X),我们最终目标是选择一个合适的
X
=
x
mathcal X = x
X=x,使得目标函数达到最值。这里以最小值为例,对应数学符号表示如下:
min
X
∈
R
n
f
(
X
)
mathop{min}limits_{mathcal X in mathbb R^n} f(mathcal X)
X∈Rnminf(X)
迭代之前,我们给定关于
X
mathcal X
X的初始化信息:
x
0
x_0
x0,并在迭代过程中通过策略得到一系列数值解:
{
x
k
}
k
=
1
∞
{x_k}_{k=1}^{infty}
{xk}k=1∞,它们对应的目标函数结果表示如下:
{
f
(
x
k
)
}
k
=
0
∞
{f(x_k)}_{k=0}^{infty}
{f(xk)}k=0∞
上一节介绍过,目标函数结果所描述的数列存在单调性,但这个单调性可能是不严格的:
- 如果数列满足严格的单调性,有:
f ( x k + 1 ) < f ( x k ) f ( x k ) , f ( x k + 1 ) ∈ { f ( x k ) } k = 0 ∞ f(x_{k+1}) < f(x_k) quad f(x_k),f(x_{k+1}) in {f(x_k)}_{k=0}^{infty} f(xk+1)<f(xk)f(xk),f(xk+1)∈{f(xk)}k=0∞ - 相反,如果数列的单调性不严格,有:
f ( x k + 1 ) < f ( x k − m ) f ( x k + 1 ) , f ( x k − m ) ∈ { f ( x k ) } k = 0 ∞ ; m ∈ [ 0 , k ] f(x_{k+1}) < f(x_{k-m}) quad f(x_{k+1}),f(x_{k-m}) in {f(x_k)}_{k=0}^{infty};m in [0,k] f(xk+1)<f(xk−m)f(xk+1),f(xk−m)∈{f(xk)}k=0∞;m∈[0,k]
也就是说,严格的单调性需要数列中的元素按照顺序严格递减;而不严格的单调性仅需要趋势递减即可,局部元素之间的大小关系并不是关注的重点。
在真实情况下,单调性的严格/不严格并不是绝对的。在迭代之前,初始化信息
x
0
x_0
x0一般是随机初始化,从而导致
x
0
x_0
x0到最优解
x
∗
x^*
x∗的距离是随机的。因此在迭代初期,我们通常会采用不严格的递减方式,随着数值解
x
k
x_k
xk逐步逼近最优解
x
∗
x^*
x∗,我们会调整参数
m
m
m,使其逐步地向严格的递减方式转化。
在方向角度观察线搜索方法之前,为简化运算,设定
{
f
(
x
k
)
}
k
=
0
∞
{f(x_k)}_{k=0}^{infty}
{f(xk)}k=0∞服从严格的单调性:
其中
N
N
N表示非负整数,描述数值解的编号。
∀
k
∈
N
⇒
f
(
x
k
+
1
)
<
f
(
x
k
)
forall k in N Rightarrow f(x_{k+1}) < f(x_k)
∀k∈N⇒f(xk+1)<f(xk)
假设2:屏蔽步长 α k alpha_k αk对线搜索方法过程的影响
上一节同样介绍了:线搜索方法对于步长的要求比较严格,较大或者较小的步长都会对线搜索方法产生负面影响。
不否认的是:较大的步长可能会影响方向,从而使线搜索方法失效;但较小的步长仅会使计算(迭代)代价提升,从而在真实情况中不太可用,但并不会使算法失效,也不会对其收敛性产生太大影响。
较小的步长仅仅使收敛速度慢了,而不是不收敛了。‘较大步长可能影响方向’示例见文章末尾。
由于这里仅讨论方向角度的线搜索方法,因此这里关于步长的假设是:在线搜索方法的迭代过程中,其步长
α
k
alpha_k
αk足够小,小到可以忽略不计。
由于‘步长’
α
k
alpha_k
αk的实际意义,因而它一定是一个正值。
假设3:限定向量 P k mathcal P_k Pk的大小
向量
P
k
mathcal P_k
Pk既包含大小,也包含方向。而观察方向角度的线搜索方法中,
P
k
mathcal P_k
Pk的大小同样不是我们关注的对象。因此我们需要将
P
k
mathcal P_k
Pk简化为单位向量。即:
∣
∣
P
k
∣
∣
=
1
k
=
1
,
2
,
3
,
⋯
||mathcal P_k|| = 1 quad k=1,2,3,cdots
∣∣Pk∣∣=1k=1,2,3,⋯
关于向量大小的约束我们早在支持向量机——模型构建思路中关于约束条件,消除等比例缩放对函数间隔
(
Functional Margin
)
( ext{Functional Margin})
(Functional Margin)的影响时使用的方法:
y
(
i
)
(
W
T
x
(
i
)
+
b
)
>
0
⇒
y
(
i
)
(
W
T
x
(
i
)
+
b
)
≥
1
y^{(i)} left(mathcal W^T x^{(i)} + b
ight) > 0 Rightarrow y^{(i)} left(mathcal W^T x^{(i)} + b
ight) geq 1
y(i)(WTx(i)+b)>0⇒y(i)(WTx(i)+b)≥1
实际上,假设
2
2
2与假设
3
3
3可以进行合并。当
P
k
mathcal P_k
Pk化简为相应的单位向量时,该向量一定与
P
k
mathcal P_k
Pk线性相关。化简后产生的标量系数可以与步长做乘法,从而被忽略掉。
下降方向的推导过程
基于上述假设,我们可以对数值解
x
k
+
1
x_{k+1}
xk+1对应的目标函数结果
f
(
x
k
+
1
)
f(x_{k+1})
f(xk+1)通过泰勒公式进行展开:
仅展开至
2
2
2阶。
f
(
x
k
+
1
)
=
f
(
x
k
+
α
k
⋅
P
k
)
=
f
(
x
k
)
+
1
1
!
[
∇
f
(
x
k
)
]
T
⋅
(
x
k
+
1
−
x
k
)
+
1
2
!
(
x
k
+
1
−
x
k
)
T
[
∇
2
f
(
x
k
)
]
(
x
k
+
1
−
x
k
)
将
x
k
+
1
−
x
k
=
α
k
P
k
x_{k+1} - x_k = alpha_k mathcal P_k
xk+1−xk=αkPk代入,化简有:
f
(
x
k
+
1
)
=
f
(
x
k
)
+
[
∇
f
(
x
k
)
]
T
⋅
α
k
P
k
+
1
2
(
α
k
P
k
)
T
[
∇
2
f
(
x
k
)
]
α
k
P
k
观察后一项:
1
2
(
α
k
P
k
)
T
[
∇
2
f
(
x
k
)
]
α
k
P
k
这里将
1
2
与标量
α
k
alpha_k
αk合并到一起),我们直接将其记作
O
(
∣
∣
α
k
P
k
∣
∣
)
mathcal O(||alpha_kmathcal P_k||)
O(∣∣αkPk∣∣)。又因为上述假设
2
2
2与假设
3
3
3的合并,这里直接将
O
(
∣
∣
α
k
P
k
∣
∣
)
mathcal O(||alpha_kmathcal P_k||)
O(∣∣αkPk∣∣)忽略掉,简化为如下形式:
这里的
O
(
∣
∣
α
k
P
k
∣
∣
)
mathcal O(||alpha_kmathcal P_k||)
O(∣∣αkPk∣∣)指与
α
k
P
k
alpha_kmathcal P_k
αkPk相关的复杂项。
f
(
x
k
+
1
)
=
f
(
x
k
)
+
[
∇
f
(
x
k
)
]
T
⋅
α
k
P
k
+
O
(
∣
∣
α
k
P
k
∣
∣
)
≈
f
(
x
k
)
+
[
∇
f
(
x
k
)
]
T
⋅
α
k
P
k
从而有:
f
(
x
k
+
1
)
−
f
(
x
k
)
≈
[
∇
f
(
x
k
)
]
T
⋅
α
k
P
k
f(x_{k+1}) - f(x_k) approx left[
abla f(x_k)
ight]^T cdot alpha_kmathcal P_k
f(xk+1)−f(xk)≈[∇f(xk)]T⋅αkPk
又因为假设
1
1
1:严格的单调性,因而有:
∀
k
∈
N
⇒
f
(
x
k
+
1
)
<
f
(
x
k
)
⇒
[
∇
f
(
x
k
)
]
T
⋅
α
k
P
k
<
0
forall k in N Rightarrow f(x_{k+1}) < f(x_k) Rightarrow left[
abla f(x_k)
ight]^T cdot alpha_kmathcal P_k < 0
∀k∈N⇒f(xk+1)<f(xk)⇒[∇f(xk)]T⋅αkPk<0
由于
α
k
alpha_k
αk自身是一个正值,因而可以不等号两侧同时除以
α
k
alpha_k
αk,不改变不等号的方向。因而有:
[
∇
f
(
x
k
)
]
T
⋅
P
k
<
0
left[
abla f(x_k)
ight]^T cdot mathcal P_k < 0
[∇f(xk)]T⋅Pk<0
可以观察:
∇
f
(
x
k
)
abla f(x_k)
∇f(xk)是数值解
x
k
x_k
xk对应的目标函数的梯度向量;而
P
k
mathcal P_k
Pk是数值解
x
k
x_k
xk在当前迭代步骤中更新的方向向量(单位向量)。根据上式,我们就可以反过来对
P
k
mathcal P_k
Pk的约束条件进行描述:
基于上述假设,如果存在这样的
P
k
mathcal P_k
Pk,使得
[
∇
f
(
x
k
)
]
T
⋅
P
k
<
0
并满足条件的 P k mathcal P_k Pk方向称作下降方向 ( Descent Direction ) ( ext{Descent Direction}) (Descent Direction)。
下降方向的几何意义
观察上面的公式:
[
∇
f
(
x
k
)
]
T
⋅
P
k
<
0
不等式左侧的本质上就是向量
∇
f
(
x
k
)
abla f(x_k)
∇f(xk)与向量
P
k
mathcal P_k
Pk之间的内积结果。将其继续展开:
∣
∣
∇
f
(
x
k
)
∣
∣
⋅
∣
∣
P
k
∣
∣
⋅
cos
θ
<
0
||
abla f(x_k)|| cdot ||mathcal P_k|| cdot cos heta <0
∣∣∇f(xk)∣∣⋅∣∣Pk∣∣⋅cosθ<0
其中
∣
∣
∇
f
(
x
k
)
∣
∣
,
∣
∣
P
k
∣
∣
=
1
||
abla f(x_k)||,||mathcal P_k||=1
∣∣∇f(xk)∣∣,∣∣Pk∣∣=1分别表示上述两向量的大小,均恒正;这意味着
cos
θ
<
0
cos heta < 0
cosθ<0,而
θ
heta
θ表示向量
∇
f
(
x
k
)
abla f(x_k)
∇f(xk)与向量
P
k
mathcal P_k
Pk之间的夹角。这意味着:向量
∇
f
(
x
k
)
abla f(x_k)
∇f(xk)与向量
P
k
mathcal P_k
Pk的夹角范围在
(
π
2
,
3
π
2
)
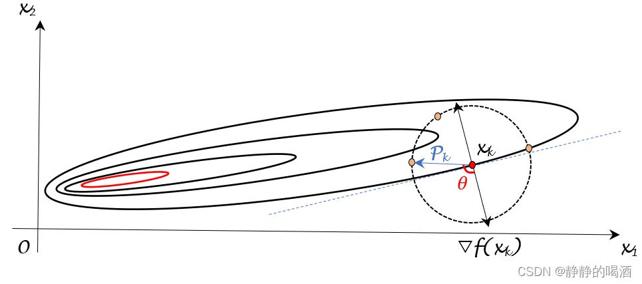
观察上述图像:
- 其中蓝色虚线表示 X mathcal X X变量空间中,过点 x k x_k xk与目标函数等高线的切线;
- 与蓝色虚线垂直,并向远离目标函数的黑色箭头是梯度方向 ∇ f ( x k ) abla f(x_k) ∇f(xk),与其相反的黑色箭头就是梯度的负方向。
- 以 x k x_k xk为圆心, 1 1 1为半径作圆(因为 P k mathcal P_k Pk是单位向量),在蓝色虚线上方并且落在圆上的点(橙色点)与 x k x_k xk相连接构成的向量就是 P k mathcal P_k Pk可能选择的向量。图中的红色弧线表示夹角。
在优化算法——无约束优化概述中提到线搜索方法方向中的与负梯度方向相关的方向就是与负梯度方向夹角在
(
−
π
2
,
π
2
)
与梯度方向的情况正好相反)。
继续观察上图,如果方向在蓝色虚线或者是蓝色虚线以下的范围内,那么更新后的梯度目标函数结果必然大于当前等高线的数值结果。可以想象一下:如果更新的P k mathcal P_k Pk方向与切线方向非常接近(例如图中最右侧的橙黄色点),如果稍微控制不好步长从而使步长过大,那么最终同样导致更新后的目标函数结果大于之前的结果,从而导致本次迭代无效。从侧面也能看出合理步长的重要性。
同理,如果
P
k
mathcal P_k
Pk方向恰好与
∇
f
(
x
k
)
abla f(x_k)
∇f(xk)之间的夹角为
π
pi
π(与
∇
f
(
x
k
)
abla f(x_k)
∇f(xk)方向完全相反),那么此时的
cos
θ
=
−
1
cos heta = -1
cosθ=−1,对应更新后的
f
(
x
k
+
1
)
f(x_{k+1})
f(xk+1)相比
f
(
x
k
)
f(x_k)
f(xk)减小的程度是最强烈的,也是当前迭代步骤最优的优化方向:
f
(
x
k
+
1
)
−
f
(
x
k
)
≈
α
k
⋅
∣
∣
∇
f
(
x
k
)
∣
∣
⋅
∣
∣
P
k
∣
∣
⋅
cos
θ
=
−
α
k
⋅
∣
∣
∇
f
(
x
k
)
∣
∣
⋅
1
⋅
(
−
1
)
=
−
α
k
⋅
∣
∣
∇
f
(
x
k
)
∣
∣
实际上,梯度下降法 ( Gradient Descent,GD ) ( ext{Gradient Descent,GD}) (Gradient Descent,GD),它每一次迭代(更新步骤)中总会选择最优的优化方向(与梯度方向相反的方向)作为下降方向,因为在当前迭代步骤中,该方向目标函数下降的效果最明显。因此梯度下降法也被称作最速下降法。
相关参考:
【优化算法】线搜索方法-方向
评论记录:
回复评论: