
引言
随着古茗的日益成长壮大,有了越来越多的伙伴加入。这其中不乏各方专业人人员、投资商、加盟商、供应商等等。这其中,为了保障双方合法权利,必然少不了合同的签订。而如果能够将合同生成 PDF 并预览的工作在线上完成,无疑将能够减少不少沟通和时间成本。
一般合同的展示信息,包含页眉,页脚以及合同本身的内容(比如各项条款及法规等)。合同会有多页,也就避免不了要对合同生成后的电子文档(如PDF文件等)内容进行分页处理。
今天我们就来聊聊如何生成将文档内容生成 PDF 文档并进行分页处理。
需求分析
对于文档内容生成 PDF 的场景,我们大致可以分为两大步:
- 将我们需要的文字、图片、表格等内容生成 PDF
- 对于内容较多的文档,可能还要考虑到对内容进行合理分页的问题,以让内容可以正常展示
以下,我们先从如何生成 PDF 开始着手。
PDF 生成
方案选择
目前主流的方案有两种:
- 仅使用 jspdf 自带 api
- 使用 html2canvas + jspdf
本文采用的是第二种方案,原因如下:
- 灵活性与兼容性
- 内容多样性:html2canvas能够将HTML元素(包括文本、图像、CSS样式等)渲染为Canvas图像,这意味着几乎任何类型的网页内容都可以被转换成图像。而jspdf虽然功能强大,但直接操作HTML元素的能力有限,特别是当内容包含复杂的CSS样式或动态生成的内容时。
- CSS样式支持:通过html2canvas,可以保留原HTML内容的CSS样式(尽管可能不是100%完美),这在生成PDF时非常重要,因为PDF文件通常需要保持与原网页相同的视觉效果。而jspdf在处理CSS样式时可能较为有限。
- 复杂布局的处理
- 页面布局:当需要生成的PDF文件包含复杂的页面布局(如多列布局、表格、图像等)时,直接使用jspdf可能难以实现精确的布局控制。而html2canvas可以先将HTML内容渲染为Canvas,然后再通过jspdf将Canvas图像添加到PDF中,从而更容易地控制页面布局。
- 分页处理:对于长内容,html2canvas + jspdf的方案可以更容易地实现分页处理。通过将HTML内容分割成多个Canvas图像,然后再将这些图像逐一添加到PDF的不同页面中,可以确保PDF文件的内容完整且易于阅读。
- 跨浏览器兼容性
- 浏览器兼容性:html2canvas 和 jspdf 都是 JavaScript 库,它们依赖于浏览器的 Canvas API 和JavaScript 环境。虽然jspdf本身具有较好的跨浏览器兼容性,但在处理复杂的HTML内容和CSS样式时,可能仍需要 html2canvas 来提供更广泛的浏览器支持。
- 性能考虑
- 渲染性能:对于包含大量DOM元素或复杂CSS样式的网页,直接使用jspdf进行PDF生成可能会非常耗时且资源密集。而html2canvas通过先将HTML内容渲染为Canvas图像,可以在一定程度上减轻浏览器的渲染负担,提高PDF生成的性能。
综上所述,使用html2canvas + jspdf的方案生成PDF文件具有更高的灵活性、更好的兼容性、更易于处理复杂布局、更好的跨浏览器支持以及更优的性能和用户体验。这些优势使得该方案成为前端生成 PDF 文件的较好选择。
其代码实现也较为简单,其主要代码实现如下:
声明 ref 方便拿到元素内容。
javascript 代码解读复制代码const contentRef = useRef(null);
...
...
"pdf-reviewer"> // PDF HTML 内容区块
...
将元素放入到 html2canvas 中,得到 canvas 数据。
javascript 代码解读复制代码import html2canvas from 'html2canvas';
const canvas = await html2canvas(element, { // element 即 contentRef.current
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度window.devicePixelRatio * 2
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
通过 jspdf 提供的 api 进行绘制
javascript 代码解读复制代码 const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation: 'p',
});
pdf.addImage(canvas, 'JPEG', x, y, width, height);
打开并预览 PDF 内容
javascript 代码解读复制代码const pdfBlob = pdf.output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
至此,我们完成了最简单的一步,将 PDF 成功生成了出来。但是在某些特定场景,竟然出现了内容截断。如下图:

从图中可以看到,在两页 PDF 的接缝处,文字内容被截断了。这确实是难以被接受的。
思考
为什么会出现截断呢?
原因就在于,html2canvas 帮我们生成了一整个 Canvas 图像,当我们将一整个图像放入 PDF 中时,PDF 会根据每个页面的高度直接将内容分割。
所以,我们需要想个办法,在 Canvas 图像放入 PDF 之前,将内容元素避开页面分割的地方(下称分页点)。
PDF 分页
方案选择
- 手动分页
- 顾名思义,该方案就是通过手动调整文档内容的样式,反复调整来让内容避开分页点。适合内容相对固定的文档,不会有动态变更的内容。优点是简单粗暴,所见即所得,不用考虑复杂场景。但缺点也显而易见,一旦有新的文档内容加入,又需要再去调整一遍样式,极其难以维护。
- 动态分页
- 根据 HTML 内容以及 PDF 页面尺寸,动态计算分页点的位置,使 HTML 的元素内容避开分页点。这样,无论多动态的内容,维护成本也几乎为0。
综上,本文将继续介绍第二种方案。
动态分页
在了解如何分页之前,我们需要知道 PDF 的生成流程以知晓高度和位置的计算逻辑。
PDF 生成流程
- 拿到整个 DOM 的根元素
- 使用 html2canvas,将整个元素转化为 canvas 数据,并得到总高度
- 计算页眉、页脚的高度
- 计算除去页眉、页脚以及内容与两者之间的间距后的每页内容的实际高度
- 遍历元素节点,通过以上计算所得的每页内容的实际高度以及总高度,计算得出总页数以及分页点位置(以下简称分页点),将分页点放入集合中记录
- 将分页点集合中的分页点依次取出,根据分页点的位置,截取 canvas 的数据内容,使用 pdf.addImage 将数据放入 pdf 文件中
- 添加页眉,页脚
纵观整体流程,将 HTML 内容转变成 PDF 的文件内容,其实本身是非常简单的,通过简单的 API 调用就可以完成。难点在于,如何将每页的内容合理分配且不产生截断。我们需要分为多种场景进行分别处理。
:::info
分页点
如以上生成流程中所说,我们可以通过每页内容的实际高度以及总高度,计算得出分页点。
当然,这只是最理想的情况:我们的文档内容恰巧都没有处在页面被分割的位置。
但是,当分割处有内容时该怎么办呢?
:::
此时,我们就需要一些特殊的处理:
普通元素
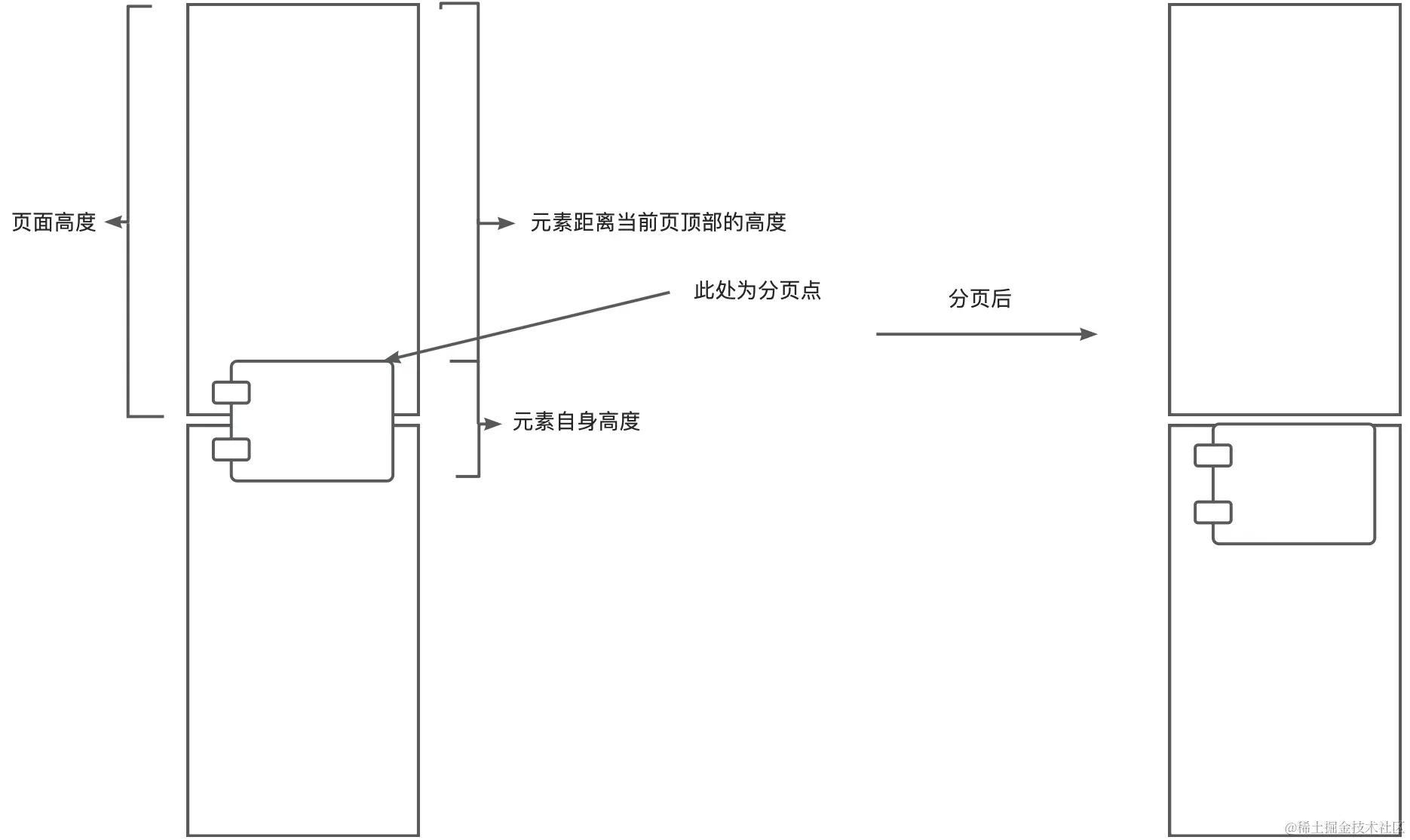
普通元素只需要考虑到是否到达了分页点,如果当前元素距离当前页顶部的高度加上元素自身的高度大于 PDF 一页内容的高度(页面高度), 则证明当前元素跨页,将当前元素顶部作为分页点位置。
表格
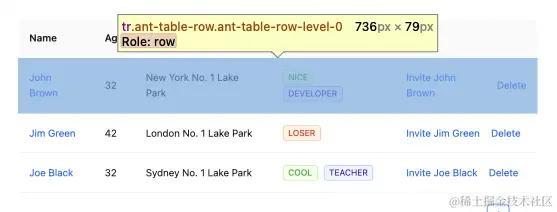
因为表格本身受到不同三方 UI 库的影响,表格行可能会有不同的 ClassName。
比如 antd 的表格行的 ClassName 就是 "ant-table-row"。
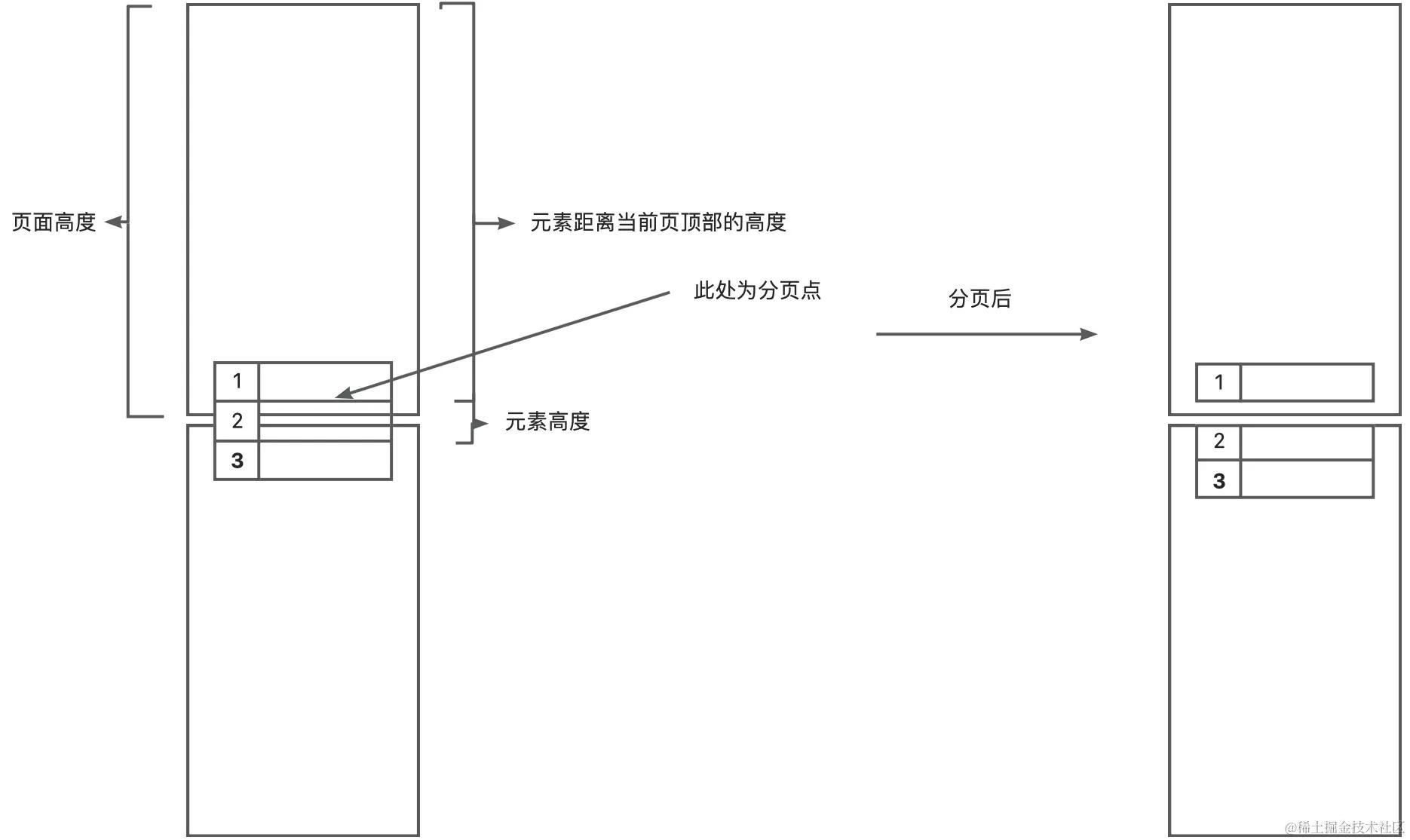
当我们遇到相应的 ClassName,则不再进行向下遍历。其实,其判断分页点条件与普通元素类似,只不过普通元素是以最小元素单位作来进行判断,表格是以表格行作为最小元素来进行判断,不再向下进行子元素遍历。
文字
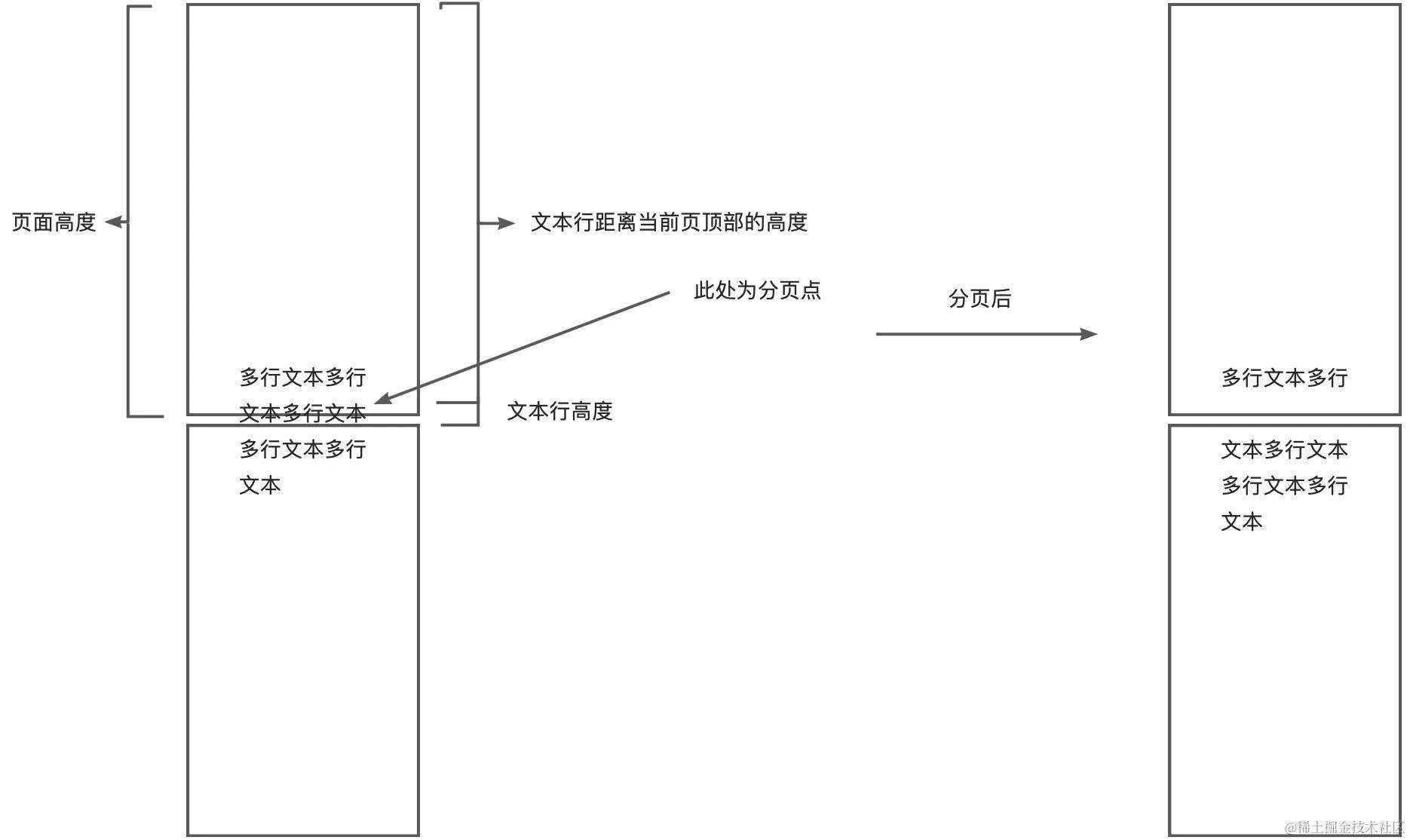
文字相较普通元素,则更深一层。复杂点在于,被截断的文字可能是多行文字的文本元素。
- 在遍历一个元素的子节点时,判断该子节点的 nodeType 是否为3,为3则为文本节点。
- 获取父节点的高度和顶部位置,以及行高
- 获取上一个分页点的位置(即当前页顶部位置)
- 计算当前元素顶部距离当前 PDF 页底部的高度 (上一个分页点的位置+页面高度-当前元素距离整个文档最顶部的高度)
- 计算当前被截断的文字行顶部位置(上一步骤得到的高度与行高求余)
- 计算分页点位置(上一个分页点的位置+页面高度-上一步骤得到的高度)
javascript 代码解读复制代码if (one.nodeType === 3) {
const { offsetHeight } = one.parentNode;
const offsetTop = getBaseElementTop(one.parentNode);
const top = Math.max(0, rate * offsetTop);
const lineHeightString = window.getComputedStyle(one.parentNode).lineHeight;
const lineHeightMatch = lineHeightString.match(/\d+(\.\d+)?/);
const lineHeightValue = lineHeightMatch ? parseFloat(lineHeightMatch[0]) : 0;
const lineHeight = lineHeightValue * rate;
const elementHeight = rate * offsetHeight;
const previousPoint = pages.length > 0 ? pages[pages.length - 1] : 0;
...
if (top + elementHeight - previousPoint > originalPageHeight) {
const currentRemainHeight = previousPoint + originalPageHeight - top; // 当前元素顶部距离当前 PDF 页底部的高度
const remainder = currentRemainHeight % lineHeight;
pages.push(previousPoint + originalPageHeight - remainder);
}
}
手动标记分页点位置
还有一些场景,我们希望直接另起一页。这种情况,可以直接指定一个 ClassName,放到想要分页位置的元素上面。当遍历时遇到此 ClassName,则直接将此元素顶部位置作为分页点位置。
注意事项
除以上提到的内容之外,我们可能还会遇到其他比较棘手的问题。
导出问题
在导出 PDF 并进行预览时,当 PDF 内容过大,可能会导致页面无法加载。此时,我们需要进行一层转换。
javascript 代码解读复制代码const pdfBlob = obj.getPDF().output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
javascript 代码解读复制代码const blob = dataURLtoBlob(obj.getPDF().output('datauristring'));
const pdfUrl = URL.createObjectURL(blob);
window.open(pdfUrl);
javascript 代码解读复制代码// 当 base64 过大时会导致页面无法加载,需要转化成 blob 格式
const dataURLtoBlob = (dataurl: any) => {
const arr = dataurl.split(',');
// 注意base64的最后面中括号和引号是不转译的
const _arr = arr[1].substring(0, arr[1].length - 2);
const mime = arr[0].match(/:(.*?);/)[1];
const bstr = atob(_arr);
let n = bstr.length;
const u8arr = new Uint8Array(n);
while (n--) {
u8arr[n] = bstr.charCodeAt(n);
}
return new Blob([u8arr], {
type: mime,
});
};
内容过长
在生成 PDF 时,可能会出现大量空白页的情况,这可能是触碰到了浏览器的限制。\ 在浏览器中,Canvas是存在尺寸限制的,主要原因是浏览器为了防止内存溢出和性能问题。不同浏览器对Canvas的最大尺寸有不同的限制:
- Chrome:最大尺寸为16384x16384像素。
- Firefox:最大尺寸约为11164x11164像素。
- Safari:在iOS 10及以下版本中,最大尺寸为4096x4096像素;而在HUAWEI NXT-TL00手机自带浏览器和UC浏览器中,最大尺寸为8192x8192像素。
- 搜狗浏览器:最大尺寸比16384x16384像素稍小一些。
- IE11 和 Edge 浏览器:没有明确的最大尺寸限制,但大尺寸 Canvas 会导致严重的内存消耗和性能问题。
对于这个问题,我们可以考虑将整个大的 Canvas 进行切割,再分段渲染到 PDF 文档上。
具体分割逻辑代码如下:
javascript 代码解读复制代码async function toCanvasAll(element, width) {
// canvas元素
const canvas = await html2canvas(element, {
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 高度转化为PDF的高度
const rate = width / canvasWidth;
const height = rate * canvasHeight;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
if (canvasData === 'data:,') {
const canvasDataArr = await toCanvasSplit(element, rate);
return { totalHeight: height, data: canvasDataArr.sort((a, b) => a.index - b.index) };
}
return {
totalHeight: height,
data: [{ width, height, index: 0, data: canvasData, start: 0, end: height }],
};
}
javascript 代码解读复制代码async function toCanvasSplit(element, rate, parts = 2) {
const yOffsets = distributeEvenlySimple(element.scrollHeight, parts);
let res;
try {
const arr = [];
for (let index = 0; index < yOffsets.length; index++) {
const previous = yOffsets[index - 1] || 0;
const canvas = await html2canvas(element, {
allowTaint: true,
scale: window.devicePixelRatio * 2,
useCORS: true,
// windowHeight: element.scrollHeight,
y: previous,
height: yOffsets[index] - previous,
});
const width = rate * canvas.width;
const height = rate * canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
if (canvasData === 'data:,') {
throw new Error('canvasData is empty');
}
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const start = arr[index - 1]?.end || 0;
arr.push({
width,
height,
index,
data: canvasData,
start,
end: start + height,
});
res = arr;
}
} catch (e) {
console.warn('error', e);
res = await toCanvasSplit(element, rate, parts + 1);
}
return res;
}
分段渲染时,后续分段的数据要考虑拿到到第一个数据渲染后的结束位置,进行拼接。
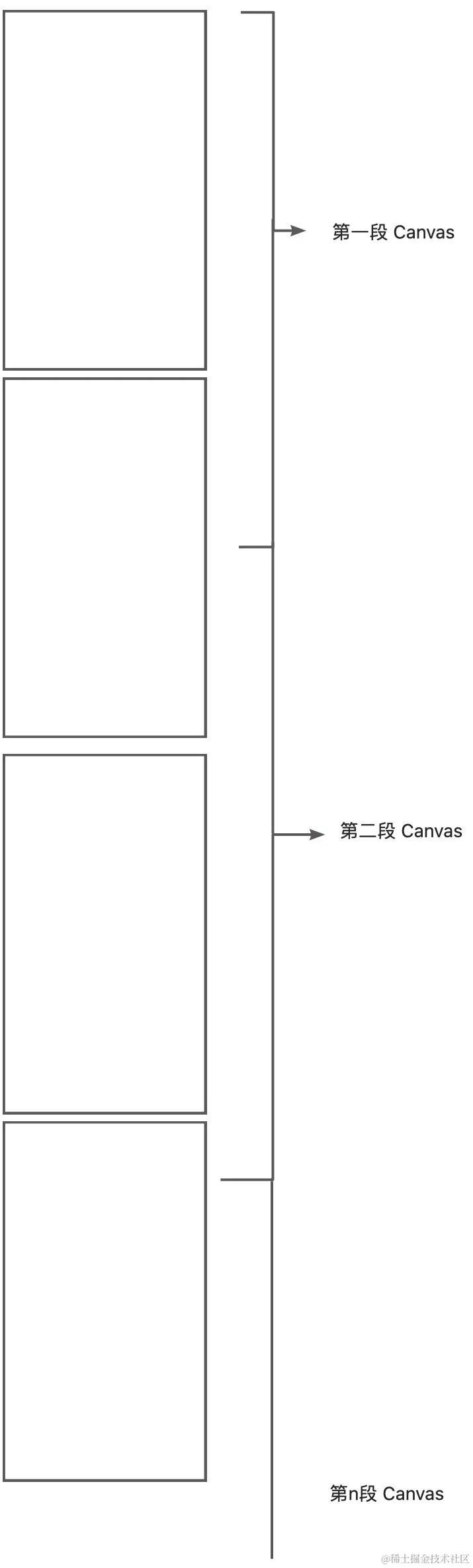
待优化问题
在开发过程中,还有两个问题稍微难解,等待后续完善。大家也可以讨论更好的解决方案。
- PDF 生成时间过长
- 其主要原因是因为页脚是动态多次渲染并生成的。因为 PDF 从 HTML 到 生成 Canvas 需要一定的耗时(几十到几百毫秒不等) ,而又因为页脚中有页码这种动态内容,所以并不能直接生成一次并复用。目前能想到的解决方案,是渲染包含所有页码的多个页脚,然后进行切割,并放入到 PDF 中,这样仅需生成一次。当然这只是一个想法,暂未得到实践。
- 生成时,将 HTML 元素隐藏
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
我目前采用的方案,是在生成前改变其可见性,使其不可见,生成中时改为可见,并使其透明度为0。因为 HTML 可见时,可能会对页面的样式(比如页面高度)产生影响,所以还要将其“浮在”父页面上(相对布局),在父页面上加上浮层,固定父页面使其不可滚动。
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
总结
以上,就是我对 HTML 生成 PDF 的探索。当然,在当下大家日益增长的业务中,我们可能会遇到更为复杂的场景,可能也会需要更为完善的方案来应对。大家可以多多发表真知灼见,共同学习,一起进步!
引言
随着古茗的日益成长壮大,有了越来越多的伙伴加入。这其中不乏各方专业人人员、投资商、加盟商、供应商等等。这其中,为了保障双方合法权利,必然少不了合同的签订。而如果能够将合同生成 PDF 并预览的工作在线上完成,无疑将能够减少不少沟通和时间成本。
一般合同的展示信息,包含页眉,页脚以及合同本身的内容(比如各项条款及法规等)。合同会有多页,也就避免不了要对合同生成后的电子文档(如PDF文件等)内容进行分页处理。
今天我们就来聊聊如何生成将文档内容生成 PDF 文档并进行分页处理。
需求分析
对于文档内容生成 PDF 的场景,我们大致可以分为两大步:
- 将我们需要的文字、图片、表格等内容生成 PDF
- 对于内容较多的文档,可能还要考虑到对内容进行合理分页的问题,以让内容可以正常展示
以下,我们先从如何生成 PDF 开始着手。
PDF 生成
方案选择
目前主流的方案有两种:
- 仅使用 jspdf 自带 api
- 使用 html2canvas + jspdf
本文采用的是第二种方案,原因如下:
- 灵活性与兼容性
- 内容多样性:html2canvas能够将HTML元素(包括文本、图像、CSS样式等)渲染为Canvas图像,这意味着几乎任何类型的网页内容都可以被转换成图像。而jspdf虽然功能强大,但直接操作HTML元素的能力有限,特别是当内容包含复杂的CSS样式或动态生成的内容时。
- CSS样式支持:通过html2canvas,可以保留原HTML内容的CSS样式(尽管可能不是100%完美),这在生成PDF时非常重要,因为PDF文件通常需要保持与原网页相同的视觉效果。而jspdf在处理CSS样式时可能较为有限。
- 复杂布局的处理
- 页面布局:当需要生成的PDF文件包含复杂的页面布局(如多列布局、表格、图像等)时,直接使用jspdf可能难以实现精确的布局控制。而html2canvas可以先将HTML内容渲染为Canvas,然后再通过jspdf将Canvas图像添加到PDF中,从而更容易地控制页面布局。
- 分页处理:对于长内容,html2canvas + jspdf的方案可以更容易地实现分页处理。通过将HTML内容分割成多个Canvas图像,然后再将这些图像逐一添加到PDF的不同页面中,可以确保PDF文件的内容完整且易于阅读。
- 跨浏览器兼容性
- 浏览器兼容性:html2canvas 和 jspdf 都是 JavaScript 库,它们依赖于浏览器的 Canvas API 和JavaScript 环境。虽然jspdf本身具有较好的跨浏览器兼容性,但在处理复杂的HTML内容和CSS样式时,可能仍需要 html2canvas 来提供更广泛的浏览器支持。
- 性能考虑
- 渲染性能:对于包含大量DOM元素或复杂CSS样式的网页,直接使用jspdf进行PDF生成可能会非常耗时且资源密集。而html2canvas通过先将HTML内容渲染为Canvas图像,可以在一定程度上减轻浏览器的渲染负担,提高PDF生成的性能。
综上所述,使用html2canvas + jspdf的方案生成PDF文件具有更高的灵活性、更好的兼容性、更易于处理复杂布局、更好的跨浏览器支持以及更优的性能和用户体验。这些优势使得该方案成为前端生成 PDF 文件的较好选择。
其代码实现也较为简单,其主要代码实现如下:
声明 ref 方便拿到元素内容。
javascript 代码解读复制代码const contentRef = useRef(null);
...
...
"pdf-reviewer"> // PDF HTML 内容区块
...
将元素放入到 html2canvas 中,得到 canvas 数据。
javascript 代码解读复制代码import html2canvas from 'html2canvas';
const canvas = await html2canvas(element, { // element 即 contentRef.current
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度window.devicePixelRatio * 2
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
通过 jspdf 提供的 api 进行绘制
javascript 代码解读复制代码 const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation: 'p',
});
pdf.addImage(canvas, 'JPEG', x, y, width, height);
打开并预览 PDF 内容
javascript 代码解读复制代码const pdfBlob = pdf.output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
至此,我们完成了最简单的一步,将 PDF 成功生成了出来。但是在某些特定场景,竟然出现了内容截断。如下图:
从图中可以看到,在两页 PDF 的接缝处,文字内容被截断了。这确实是难以被接受的。
思考
为什么会出现截断呢?
原因就在于,html2canvas 帮我们生成了一整个 Canvas 图像,当我们将一整个图像放入 PDF 中时,PDF 会根据每个页面的高度直接将内容分割。
所以,我们需要想个办法,在 Canvas 图像放入 PDF 之前,将内容元素避开页面分割的地方(下称分页点)。
PDF 分页
方案选择
- 手动分页
- 顾名思义,该方案就是通过手动调整文档内容的样式,反复调整来让内容避开分页点。适合内容相对固定的文档,不会有动态变更的内容。优点是简单粗暴,所见即所得,不用考虑复杂场景。但缺点也显而易见,一旦有新的文档内容加入,又需要再去调整一遍样式,极其难以维护。
- 动态分页
- 根据 HTML 内容以及 PDF 页面尺寸,动态计算分页点的位置,使 HTML 的元素内容避开分页点。这样,无论多动态的内容,维护成本也几乎为0。
综上,本文将继续介绍第二种方案。
动态分页
在了解如何分页之前,我们需要知道 PDF 的生成流程以知晓高度和位置的计算逻辑。
PDF 生成流程
- 拿到整个 DOM 的根元素
- 使用 html2canvas,将整个元素转化为 canvas 数据,并得到总高度
- 计算页眉、页脚的高度
- 计算除去页眉、页脚以及内容与两者之间的间距后的每页内容的实际高度
- 遍历元素节点,通过以上计算所得的每页内容的实际高度以及总高度,计算得出总页数以及分页点位置(以下简称分页点),将分页点放入集合中记录
- 将分页点集合中的分页点依次取出,根据分页点的位置,截取 canvas 的数据内容,使用 pdf.addImage 将数据放入 pdf 文件中
- 添加页眉,页脚
纵观整体流程,将 HTML 内容转变成 PDF 的文件内容,其实本身是非常简单的,通过简单的 API 调用就可以完成。难点在于,如何将每页的内容合理分配且不产生截断。我们需要分为多种场景进行分别处理。
:::info
分页点
如以上生成流程中所说,我们可以通过每页内容的实际高度以及总高度,计算得出分页点。
当然,这只是最理想的情况:我们的文档内容恰巧都没有处在页面被分割的位置。
但是,当分割处有内容时该怎么办呢?
:::
此时,我们就需要一些特殊的处理:
普通元素
普通元素只需要考虑到是否到达了分页点,如果当前元素距离当前页顶部的高度加上元素自身的高度大于 PDF 一页内容的高度(页面高度), 则证明当前元素跨页,将当前元素顶部作为分页点位置。
表格
因为表格本身受到不同三方 UI 库的影响,表格行可能会有不同的 ClassName。
比如 antd 的表格行的 ClassName 就是 "ant-table-row"。
当我们遇到相应的 ClassName,则不再进行向下遍历。其实,其判断分页点条件与普通元素类似,只不过普通元素是以最小元素单位作来进行判断,表格是以表格行作为最小元素来进行判断,不再向下进行子元素遍历。
文字
文字相较普通元素,则更深一层。复杂点在于,被截断的文字可能是多行文字的文本元素。
- 在遍历一个元素的子节点时,判断该子节点的 nodeType 是否为3,为3则为文本节点。
- 获取父节点的高度和顶部位置,以及行高
- 获取上一个分页点的位置(即当前页顶部位置)
- 计算当前元素顶部距离当前 PDF 页底部的高度 (上一个分页点的位置+页面高度-当前元素距离整个文档最顶部的高度)
- 计算当前被截断的文字行顶部位置(上一步骤得到的高度与行高求余)
- 计算分页点位置(上一个分页点的位置+页面高度-上一步骤得到的高度)
javascript 代码解读复制代码if (one.nodeType === 3) {
const { offsetHeight } = one.parentNode;
const offsetTop = getBaseElementTop(one.parentNode);
const top = Math.max(0, rate * offsetTop);
const lineHeightString = window.getComputedStyle(one.parentNode).lineHeight;
const lineHeightMatch = lineHeightString.match(/\d+(\.\d+)?/);
const lineHeightValue = lineHeightMatch ? parseFloat(lineHeightMatch[0]) : 0;
const lineHeight = lineHeightValue * rate;
const elementHeight = rate * offsetHeight;
const previousPoint = pages.length > 0 ? pages[pages.length - 1] : 0;
...
if (top + elementHeight - previousPoint > originalPageHeight) {
const currentRemainHeight = previousPoint + originalPageHeight - top; // 当前元素顶部距离当前 PDF 页底部的高度
const remainder = currentRemainHeight % lineHeight;
pages.push(previousPoint + originalPageHeight - remainder);
}
}
手动标记分页点位置
还有一些场景,我们希望直接另起一页。这种情况,可以直接指定一个 ClassName,放到想要分页位置的元素上面。当遍历时遇到此 ClassName,则直接将此元素顶部位置作为分页点位置。
注意事项
除以上提到的内容之外,我们可能还会遇到其他比较棘手的问题。
导出问题
在导出 PDF 并进行预览时,当 PDF 内容过大,可能会导致页面无法加载。此时,我们需要进行一层转换。
javascript 代码解读复制代码const pdfBlob = obj.getPDF().output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
javascript 代码解读复制代码const blob = dataURLtoBlob(obj.getPDF().output('datauristring'));
const pdfUrl = URL.createObjectURL(blob);
window.open(pdfUrl);
javascript 代码解读复制代码// 当 base64 过大时会导致页面无法加载,需要转化成 blob 格式
const dataURLtoBlob = (dataurl: any) => {
const arr = dataurl.split(',');
// 注意base64的最后面中括号和引号是不转译的
const _arr = arr[1].substring(0, arr[1].length - 2);
const mime = arr[0].match(/:(.*?);/)[1];
const bstr = atob(_arr);
let n = bstr.length;
const u8arr = new Uint8Array(n);
while (n--) {
u8arr[n] = bstr.charCodeAt(n);
}
return new Blob([u8arr], {
type: mime,
});
};
内容过长
在生成 PDF 时,可能会出现大量空白页的情况,这可能是触碰到了浏览器的限制。\ 在浏览器中,Canvas是存在尺寸限制的,主要原因是浏览器为了防止内存溢出和性能问题。不同浏览器对Canvas的最大尺寸有不同的限制:
- Chrome:最大尺寸为16384x16384像素。
- Firefox:最大尺寸约为11164x11164像素。
- Safari:在iOS 10及以下版本中,最大尺寸为4096x4096像素;而在HUAWEI NXT-TL00手机自带浏览器和UC浏览器中,最大尺寸为8192x8192像素。
- 搜狗浏览器:最大尺寸比16384x16384像素稍小一些。
- IE11 和 Edge 浏览器:没有明确的最大尺寸限制,但大尺寸 Canvas 会导致严重的内存消耗和性能问题。
对于这个问题,我们可以考虑将整个大的 Canvas 进行切割,再分段渲染到 PDF 文档上。
具体分割逻辑代码如下:
javascript 代码解读复制代码async function toCanvasAll(element, width) {
// canvas元素
const canvas = await html2canvas(element, {
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 高度转化为PDF的高度
const rate = width / canvasWidth;
const height = rate * canvasHeight;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
if (canvasData === 'data:,') {
const canvasDataArr = await toCanvasSplit(element, rate);
return { totalHeight: height, data: canvasDataArr.sort((a, b) => a.index - b.index) };
}
return {
totalHeight: height,
data: [{ width, height, index: 0, data: canvasData, start: 0, end: height }],
};
}
javascript 代码解读复制代码async function toCanvasSplit(element, rate, parts = 2) {
const yOffsets = distributeEvenlySimple(element.scrollHeight, parts);
let res;
try {
const arr = [];
for (let index = 0; index < yOffsets.length; index++) {
const previous = yOffsets[index - 1] || 0;
const canvas = await html2canvas(element, {
allowTaint: true,
scale: window.devicePixelRatio * 2,
useCORS: true,
// windowHeight: element.scrollHeight,
y: previous,
height: yOffsets[index] - previous,
});
const width = rate * canvas.width;
const height = rate * canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
if (canvasData === 'data:,') {
throw new Error('canvasData is empty');
}
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const start = arr[index - 1]?.end || 0;
arr.push({
width,
height,
index,
data: canvasData,
start,
end: start + height,
});
res = arr;
}
} catch (e) {
console.warn('error', e);
res = await toCanvasSplit(element, rate, parts + 1);
}
return res;
}
分段渲染时,后续分段的数据要考虑拿到到第一个数据渲染后的结束位置,进行拼接。
待优化问题
在开发过程中,还有两个问题稍微难解,等待后续完善。大家也可以讨论更好的解决方案。
- PDF 生成时间过长
- 其主要原因是因为页脚是动态多次渲染并生成的。因为 PDF 从 HTML 到 生成 Canvas 需要一定的耗时(几十到几百毫秒不等) ,而又因为页脚中有页码这种动态内容,所以并不能直接生成一次并复用。目前能想到的解决方案,是渲染包含所有页码的多个页脚,然后进行切割,并放入到 PDF 中,这样仅需生成一次。当然这只是一个想法,暂未得到实践。
- 生成时,将 HTML 元素隐藏
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
我目前采用的方案,是在生成前改变其可见性,使其不可见,生成中时改为可见,并使其透明度为0。因为 HTML 可见时,可能会对页面的样式(比如页面高度)产生影响,所以还要将其“浮在”父页面上(相对布局),在父页面上加上浮层,固定父页面使其不可滚动。
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
总结
以上,就是我对 HTML 生成 PDF 的探索。当然,在当下大家日益增长的业务中,我们可能会遇到更为复杂的场景,可能也会需要更为完善的方案来应对。大家可以多多发表真知灼见,共同学习,一起进步!
引言
随着古茗的日益成长壮大,有了越来越多的伙伴加入。这其中不乏各方专业人人员、投资商、加盟商、供应商等等。这其中,为了保障双方合法权利,必然少不了合同的签订。而如果能够将合同生成 PDF 并预览的工作在线上完成,无疑将能够减少不少沟通和时间成本。
一般合同的展示信息,包含页眉,页脚以及合同本身的内容(比如各项条款及法规等)。合同会有多页,也就避免不了要对合同生成后的电子文档(如PDF文件等)内容进行分页处理。
今天我们就来聊聊如何生成将文档内容生成 PDF 文档并进行分页处理。
需求分析
对于文档内容生成 PDF 的场景,我们大致可以分为两大步:
- 将我们需要的文字、图片、表格等内容生成 PDF
- 对于内容较多的文档,可能还要考虑到对内容进行合理分页的问题,以让内容可以正常展示
以下,我们先从如何生成 PDF 开始着手。
PDF 生成
方案选择
目前主流的方案有两种:
- 仅使用 jspdf 自带 api
- 使用 html2canvas + jspdf
本文采用的是第二种方案,原因如下:
- 灵活性与兼容性
- 内容多样性:html2canvas能够将HTML元素(包括文本、图像、CSS样式等)渲染为Canvas图像,这意味着几乎任何类型的网页内容都可以被转换成图像。而jspdf虽然功能强大,但直接操作HTML元素的能力有限,特别是当内容包含复杂的CSS样式或动态生成的内容时。
- CSS样式支持:通过html2canvas,可以保留原HTML内容的CSS样式(尽管可能不是100%完美),这在生成PDF时非常重要,因为PDF文件通常需要保持与原网页相同的视觉效果。而jspdf在处理CSS样式时可能较为有限。
- 复杂布局的处理
- 页面布局:当需要生成的PDF文件包含复杂的页面布局(如多列布局、表格、图像等)时,直接使用jspdf可能难以实现精确的布局控制。而html2canvas可以先将HTML内容渲染为Canvas,然后再通过jspdf将Canvas图像添加到PDF中,从而更容易地控制页面布局。
- 分页处理:对于长内容,html2canvas + jspdf的方案可以更容易地实现分页处理。通过将HTML内容分割成多个Canvas图像,然后再将这些图像逐一添加到PDF的不同页面中,可以确保PDF文件的内容完整且易于阅读。
- 跨浏览器兼容性
- 浏览器兼容性:html2canvas 和 jspdf 都是 JavaScript 库,它们依赖于浏览器的 Canvas API 和JavaScript 环境。虽然jspdf本身具有较好的跨浏览器兼容性,但在处理复杂的HTML内容和CSS样式时,可能仍需要 html2canvas 来提供更广泛的浏览器支持。
- 性能考虑
- 渲染性能:对于包含大量DOM元素或复杂CSS样式的网页,直接使用jspdf进行PDF生成可能会非常耗时且资源密集。而html2canvas通过先将HTML内容渲染为Canvas图像,可以在一定程度上减轻浏览器的渲染负担,提高PDF生成的性能。
综上所述,使用html2canvas + jspdf的方案生成PDF文件具有更高的灵活性、更好的兼容性、更易于处理复杂布局、更好的跨浏览器支持以及更优的性能和用户体验。这些优势使得该方案成为前端生成 PDF 文件的较好选择。
其代码实现也较为简单,其主要代码实现如下:
声明 ref 方便拿到元素内容。
javascript 代码解读复制代码const contentRef = useRef(null);
...
...
"pdf-reviewer"> // PDF HTML 内容区块
...
将元素放入到 html2canvas 中,得到 canvas 数据。
javascript 代码解读复制代码import html2canvas from 'html2canvas';
const canvas = await html2canvas(element, { // element 即 contentRef.current
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度window.devicePixelRatio * 2
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
通过 jspdf 提供的 api 进行绘制
javascript 代码解读复制代码 const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation: 'p',
});
pdf.addImage(canvas, 'JPEG', x, y, width, height);
打开并预览 PDF 内容
javascript 代码解读复制代码const pdfBlob = pdf.output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
至此,我们完成了最简单的一步,将 PDF 成功生成了出来。但是在某些特定场景,竟然出现了内容截断。如下图:
从图中可以看到,在两页 PDF 的接缝处,文字内容被截断了。这确实是难以被接受的。
思考
为什么会出现截断呢?
原因就在于,html2canvas 帮我们生成了一整个 Canvas 图像,当我们将一整个图像放入 PDF 中时,PDF 会根据每个页面的高度直接将内容分割。
所以,我们需要想个办法,在 Canvas 图像放入 PDF 之前,将内容元素避开页面分割的地方(下称分页点)。
PDF 分页
方案选择
- 手动分页
- 顾名思义,该方案就是通过手动调整文档内容的样式,反复调整来让内容避开分页点。适合内容相对固定的文档,不会有动态变更的内容。优点是简单粗暴,所见即所得,不用考虑复杂场景。但缺点也显而易见,一旦有新的文档内容加入,又需要再去调整一遍样式,极其难以维护。
- 动态分页
- 根据 HTML 内容以及 PDF 页面尺寸,动态计算分页点的位置,使 HTML 的元素内容避开分页点。这样,无论多动态的内容,维护成本也几乎为0。
综上,本文将继续介绍第二种方案。
动态分页
在了解如何分页之前,我们需要知道 PDF 的生成流程以知晓高度和位置的计算逻辑。
PDF 生成流程
- 拿到整个 DOM 的根元素
- 使用 html2canvas,将整个元素转化为 canvas 数据,并得到总高度
- 计算页眉、页脚的高度
- 计算除去页眉、页脚以及内容与两者之间的间距后的每页内容的实际高度
- 遍历元素节点,通过以上计算所得的每页内容的实际高度以及总高度,计算得出总页数以及分页点位置(以下简称分页点),将分页点放入集合中记录
- 将分页点集合中的分页点依次取出,根据分页点的位置,截取 canvas 的数据内容,使用 pdf.addImage 将数据放入 pdf 文件中
- 添加页眉,页脚
纵观整体流程,将 HTML 内容转变成 PDF 的文件内容,其实本身是非常简单的,通过简单的 API 调用就可以完成。难点在于,如何将每页的内容合理分配且不产生截断。我们需要分为多种场景进行分别处理。
:::info
分页点
如以上生成流程中所说,我们可以通过每页内容的实际高度以及总高度,计算得出分页点。
当然,这只是最理想的情况:我们的文档内容恰巧都没有处在页面被分割的位置。
但是,当分割处有内容时该怎么办呢?
:::
此时,我们就需要一些特殊的处理:
普通元素
普通元素只需要考虑到是否到达了分页点,如果当前元素距离当前页顶部的高度加上元素自身的高度大于 PDF 一页内容的高度(页面高度), 则证明当前元素跨页,将当前元素顶部作为分页点位置。
表格
因为表格本身受到不同三方 UI 库的影响,表格行可能会有不同的 ClassName。
比如 antd 的表格行的 ClassName 就是 "ant-table-row"。
当我们遇到相应的 ClassName,则不再进行向下遍历。其实,其判断分页点条件与普通元素类似,只不过普通元素是以最小元素单位作来进行判断,表格是以表格行作为最小元素来进行判断,不再向下进行子元素遍历。
文字
文字相较普通元素,则更深一层。复杂点在于,被截断的文字可能是多行文字的文本元素。
- 在遍历一个元素的子节点时,判断该子节点的 nodeType 是否为3,为3则为文本节点。
- 获取父节点的高度和顶部位置,以及行高
- 获取上一个分页点的位置(即当前页顶部位置)
- 计算当前元素顶部距离当前 PDF 页底部的高度 (上一个分页点的位置+页面高度-当前元素距离整个文档最顶部的高度)
- 计算当前被截断的文字行顶部位置(上一步骤得到的高度与行高求余)
- 计算分页点位置(上一个分页点的位置+页面高度-上一步骤得到的高度)
javascript 代码解读复制代码if (one.nodeType === 3) {
const { offsetHeight } = one.parentNode;
const offsetTop = getBaseElementTop(one.parentNode);
const top = Math.max(0, rate * offsetTop);
const lineHeightString = window.getComputedStyle(one.parentNode).lineHeight;
const lineHeightMatch = lineHeightString.match(/\d+(\.\d+)?/);
const lineHeightValue = lineHeightMatch ? parseFloat(lineHeightMatch[0]) : 0;
const lineHeight = lineHeightValue * rate;
const elementHeight = rate * offsetHeight;
const previousPoint = pages.length > 0 ? pages[pages.length - 1] : 0;
...
if (top + elementHeight - previousPoint > originalPageHeight) {
const currentRemainHeight = previousPoint + originalPageHeight - top; // 当前元素顶部距离当前 PDF 页底部的高度
const remainder = currentRemainHeight % lineHeight;
pages.push(previousPoint + originalPageHeight - remainder);
}
}
手动标记分页点位置
还有一些场景,我们希望直接另起一页。这种情况,可以直接指定一个 ClassName,放到想要分页位置的元素上面。当遍历时遇到此 ClassName,则直接将此元素顶部位置作为分页点位置。
注意事项
除以上提到的内容之外,我们可能还会遇到其他比较棘手的问题。
导出问题
在导出 PDF 并进行预览时,当 PDF 内容过大,可能会导致页面无法加载。此时,我们需要进行一层转换。
javascript 代码解读复制代码const pdfBlob = obj.getPDF().output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
javascript 代码解读复制代码const blob = dataURLtoBlob(obj.getPDF().output('datauristring'));
const pdfUrl = URL.createObjectURL(blob);
window.open(pdfUrl);
javascript 代码解读复制代码// 当 base64 过大时会导致页面无法加载,需要转化成 blob 格式
const dataURLtoBlob = (dataurl: any) => {
const arr = dataurl.split(',');
// 注意base64的最后面中括号和引号是不转译的
const _arr = arr[1].substring(0, arr[1].length - 2);
const mime = arr[0].match(/:(.*?);/)[1];
const bstr = atob(_arr);
let n = bstr.length;
const u8arr = new Uint8Array(n);
while (n--) {
u8arr[n] = bstr.charCodeAt(n);
}
return new Blob([u8arr], {
type: mime,
});
};
内容过长
在生成 PDF 时,可能会出现大量空白页的情况,这可能是触碰到了浏览器的限制。\ 在浏览器中,Canvas是存在尺寸限制的,主要原因是浏览器为了防止内存溢出和性能问题。不同浏览器对Canvas的最大尺寸有不同的限制:
- Chrome:最大尺寸为16384x16384像素。
- Firefox:最大尺寸约为11164x11164像素。
- Safari:在iOS 10及以下版本中,最大尺寸为4096x4096像素;而在HUAWEI NXT-TL00手机自带浏览器和UC浏览器中,最大尺寸为8192x8192像素。
- 搜狗浏览器:最大尺寸比16384x16384像素稍小一些。
- IE11 和 Edge 浏览器:没有明确的最大尺寸限制,但大尺寸 Canvas 会导致严重的内存消耗和性能问题。
对于这个问题,我们可以考虑将整个大的 Canvas 进行切割,再分段渲染到 PDF 文档上。
具体分割逻辑代码如下:
javascript 代码解读复制代码async function toCanvasAll(element, width) {
// canvas元素
const canvas = await html2canvas(element, {
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 高度转化为PDF的高度
const rate = width / canvasWidth;
const height = rate * canvasHeight;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
if (canvasData === 'data:,') {
const canvasDataArr = await toCanvasSplit(element, rate);
return { totalHeight: height, data: canvasDataArr.sort((a, b) => a.index - b.index) };
}
return {
totalHeight: height,
data: [{ width, height, index: 0, data: canvasData, start: 0, end: height }],
};
}
javascript 代码解读复制代码async function toCanvasSplit(element, rate, parts = 2) {
const yOffsets = distributeEvenlySimple(element.scrollHeight, parts);
let res;
try {
const arr = [];
for (let index = 0; index < yOffsets.length; index++) {
const previous = yOffsets[index - 1] || 0;
const canvas = await html2canvas(element, {
allowTaint: true,
scale: window.devicePixelRatio * 2,
useCORS: true,
// windowHeight: element.scrollHeight,
y: previous,
height: yOffsets[index] - previous,
});
const width = rate * canvas.width;
const height = rate * canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
if (canvasData === 'data:,') {
throw new Error('canvasData is empty');
}
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const start = arr[index - 1]?.end || 0;
arr.push({
width,
height,
index,
data: canvasData,
start,
end: start + height,
});
res = arr;
}
} catch (e) {
console.warn('error', e);
res = await toCanvasSplit(element, rate, parts + 1);
}
return res;
}
分段渲染时,后续分段的数据要考虑拿到到第一个数据渲染后的结束位置,进行拼接。
待优化问题
在开发过程中,还有两个问题稍微难解,等待后续完善。大家也可以讨论更好的解决方案。
- PDF 生成时间过长
- 其主要原因是因为页脚是动态多次渲染并生成的。因为 PDF 从 HTML 到 生成 Canvas 需要一定的耗时(几十到几百毫秒不等) ,而又因为页脚中有页码这种动态内容,所以并不能直接生成一次并复用。目前能想到的解决方案,是渲染包含所有页码的多个页脚,然后进行切割,并放入到 PDF 中,这样仅需生成一次。当然这只是一个想法,暂未得到实践。
- 生成时,将 HTML 元素隐藏
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
我目前采用的方案,是在生成前改变其可见性,使其不可见,生成中时改为可见,并使其透明度为0。因为 HTML 可见时,可能会对页面的样式(比如页面高度)产生影响,所以还要将其“浮在”父页面上(相对布局),在父页面上加上浮层,固定父页面使其不可滚动。
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
总结
以上,就是我对 HTML 生成 PDF 的探索。当然,在当下大家日益增长的业务中,我们可能会遇到更为复杂的场景,可能也会需要更为完善的方案来应对。大家可以多多发表真知灼见,共同学习,一起进步!
引言
随着古茗的日益成长壮大,有了越来越多的伙伴加入。这其中不乏各方专业人人员、投资商、加盟商、供应商等等。这其中,为了保障双方合法权利,必然少不了合同的签订。而如果能够将合同生成 PDF 并预览的工作在线上完成,无疑将能够减少不少沟通和时间成本。
一般合同的展示信息,包含页眉,页脚以及合同本身的内容(比如各项条款及法规等)。合同会有多页,也就避免不了要对合同生成后的电子文档(如PDF文件等)内容进行分页处理。
今天我们就来聊聊如何生成将文档内容生成 PDF 文档并进行分页处理。
需求分析
对于文档内容生成 PDF 的场景,我们大致可以分为两大步:
- 将我们需要的文字、图片、表格等内容生成 PDF
- 对于内容较多的文档,可能还要考虑到对内容进行合理分页的问题,以让内容可以正常展示
以下,我们先从如何生成 PDF 开始着手。
PDF 生成
方案选择
目前主流的方案有两种:
- 仅使用 jspdf 自带 api
- 使用 html2canvas + jspdf
本文采用的是第二种方案,原因如下:
- 灵活性与兼容性
- 内容多样性:html2canvas能够将HTML元素(包括文本、图像、CSS样式等)渲染为Canvas图像,这意味着几乎任何类型的网页内容都可以被转换成图像。而jspdf虽然功能强大,但直接操作HTML元素的能力有限,特别是当内容包含复杂的CSS样式或动态生成的内容时。
- CSS样式支持:通过html2canvas,可以保留原HTML内容的CSS样式(尽管可能不是100%完美),这在生成PDF时非常重要,因为PDF文件通常需要保持与原网页相同的视觉效果。而jspdf在处理CSS样式时可能较为有限。
- 复杂布局的处理
- 页面布局:当需要生成的PDF文件包含复杂的页面布局(如多列布局、表格、图像等)时,直接使用jspdf可能难以实现精确的布局控制。而html2canvas可以先将HTML内容渲染为Canvas,然后再通过jspdf将Canvas图像添加到PDF中,从而更容易地控制页面布局。
- 分页处理:对于长内容,html2canvas + jspdf的方案可以更容易地实现分页处理。通过将HTML内容分割成多个Canvas图像,然后再将这些图像逐一添加到PDF的不同页面中,可以确保PDF文件的内容完整且易于阅读。
- 跨浏览器兼容性
- 浏览器兼容性:html2canvas 和 jspdf 都是 JavaScript 库,它们依赖于浏览器的 Canvas API 和JavaScript 环境。虽然jspdf本身具有较好的跨浏览器兼容性,但在处理复杂的HTML内容和CSS样式时,可能仍需要 html2canvas 来提供更广泛的浏览器支持。
- 性能考虑
- 渲染性能:对于包含大量DOM元素或复杂CSS样式的网页,直接使用jspdf进行PDF生成可能会非常耗时且资源密集。而html2canvas通过先将HTML内容渲染为Canvas图像,可以在一定程度上减轻浏览器的渲染负担,提高PDF生成的性能。
综上所述,使用html2canvas + jspdf的方案生成PDF文件具有更高的灵活性、更好的兼容性、更易于处理复杂布局、更好的跨浏览器支持以及更优的性能和用户体验。这些优势使得该方案成为前端生成 PDF 文件的较好选择。
其代码实现也较为简单,其主要代码实现如下:
声明 ref 方便拿到元素内容。
javascript 代码解读复制代码const contentRef = useRef(null);
...
...
"pdf-reviewer"> // PDF HTML 内容区块
...
将元素放入到 html2canvas 中,得到 canvas 数据。
javascript 代码解读复制代码import html2canvas from 'html2canvas';
const canvas = await html2canvas(element, { // element 即 contentRef.current
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度window.devicePixelRatio * 2
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
通过 jspdf 提供的 api 进行绘制
javascript 代码解读复制代码 const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation: 'p',
});
pdf.addImage(canvas, 'JPEG', x, y, width, height);
打开并预览 PDF 内容
javascript 代码解读复制代码const pdfBlob = pdf.output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
至此,我们完成了最简单的一步,将 PDF 成功生成了出来。但是在某些特定场景,竟然出现了内容截断。如下图:
从图中可以看到,在两页 PDF 的接缝处,文字内容被截断了。这确实是难以被接受的。
思考
为什么会出现截断呢?
原因就在于,html2canvas 帮我们生成了一整个 Canvas 图像,当我们将一整个图像放入 PDF 中时,PDF 会根据每个页面的高度直接将内容分割。
所以,我们需要想个办法,在 Canvas 图像放入 PDF 之前,将内容元素避开页面分割的地方(下称分页点)。
PDF 分页
方案选择
- 手动分页
- 顾名思义,该方案就是通过手动调整文档内容的样式,反复调整来让内容避开分页点。适合内容相对固定的文档,不会有动态变更的内容。优点是简单粗暴,所见即所得,不用考虑复杂场景。但缺点也显而易见,一旦有新的文档内容加入,又需要再去调整一遍样式,极其难以维护。
- 动态分页
- 根据 HTML 内容以及 PDF 页面尺寸,动态计算分页点的位置,使 HTML 的元素内容避开分页点。这样,无论多动态的内容,维护成本也几乎为0。
综上,本文将继续介绍第二种方案。
动态分页
在了解如何分页之前,我们需要知道 PDF 的生成流程以知晓高度和位置的计算逻辑。
PDF 生成流程
- 拿到整个 DOM 的根元素
- 使用 html2canvas,将整个元素转化为 canvas 数据,并得到总高度
- 计算页眉、页脚的高度
- 计算除去页眉、页脚以及内容与两者之间的间距后的每页内容的实际高度
- 遍历元素节点,通过以上计算所得的每页内容的实际高度以及总高度,计算得出总页数以及分页点位置(以下简称分页点),将分页点放入集合中记录
- 将分页点集合中的分页点依次取出,根据分页点的位置,截取 canvas 的数据内容,使用 pdf.addImage 将数据放入 pdf 文件中
- 添加页眉,页脚
纵观整体流程,将 HTML 内容转变成 PDF 的文件内容,其实本身是非常简单的,通过简单的 API 调用就可以完成。难点在于,如何将每页的内容合理分配且不产生截断。我们需要分为多种场景进行分别处理。
:::info
分页点
如以上生成流程中所说,我们可以通过每页内容的实际高度以及总高度,计算得出分页点。
当然,这只是最理想的情况:我们的文档内容恰巧都没有处在页面被分割的位置。
但是,当分割处有内容时该怎么办呢?
:::
此时,我们就需要一些特殊的处理:
普通元素
普通元素只需要考虑到是否到达了分页点,如果当前元素距离当前页顶部的高度加上元素自身的高度大于 PDF 一页内容的高度(页面高度), 则证明当前元素跨页,将当前元素顶部作为分页点位置。
表格
因为表格本身受到不同三方 UI 库的影响,表格行可能会有不同的 ClassName。
比如 antd 的表格行的 ClassName 就是 "ant-table-row"。
当我们遇到相应的 ClassName,则不再进行向下遍历。其实,其判断分页点条件与普通元素类似,只不过普通元素是以最小元素单位作来进行判断,表格是以表格行作为最小元素来进行判断,不再向下进行子元素遍历。
文字
文字相较普通元素,则更深一层。复杂点在于,被截断的文字可能是多行文字的文本元素。
- 在遍历一个元素的子节点时,判断该子节点的 nodeType 是否为3,为3则为文本节点。
- 获取父节点的高度和顶部位置,以及行高
- 获取上一个分页点的位置(即当前页顶部位置)
- 计算当前元素顶部距离当前 PDF 页底部的高度 (上一个分页点的位置+页面高度-当前元素距离整个文档最顶部的高度)
- 计算当前被截断的文字行顶部位置(上一步骤得到的高度与行高求余)
- 计算分页点位置(上一个分页点的位置+页面高度-上一步骤得到的高度)
javascript 代码解读复制代码if (one.nodeType === 3) {
const { offsetHeight } = one.parentNode;
const offsetTop = getBaseElementTop(one.parentNode);
const top = Math.max(0, rate * offsetTop);
const lineHeightString = window.getComputedStyle(one.parentNode).lineHeight;
const lineHeightMatch = lineHeightString.match(/\d+(\.\d+)?/);
const lineHeightValue = lineHeightMatch ? parseFloat(lineHeightMatch[0]) : 0;
const lineHeight = lineHeightValue * rate;
const elementHeight = rate * offsetHeight;
const previousPoint = pages.length > 0 ? pages[pages.length - 1] : 0;
...
if (top + elementHeight - previousPoint > originalPageHeight) {
const currentRemainHeight = previousPoint + originalPageHeight - top; // 当前元素顶部距离当前 PDF 页底部的高度
const remainder = currentRemainHeight % lineHeight;
pages.push(previousPoint + originalPageHeight - remainder);
}
}
手动标记分页点位置
还有一些场景,我们希望直接另起一页。这种情况,可以直接指定一个 ClassName,放到想要分页位置的元素上面。当遍历时遇到此 ClassName,则直接将此元素顶部位置作为分页点位置。
注意事项
除以上提到的内容之外,我们可能还会遇到其他比较棘手的问题。
导出问题
在导出 PDF 并进行预览时,当 PDF 内容过大,可能会导致页面无法加载。此时,我们需要进行一层转换。
javascript 代码解读复制代码const pdfBlob = obj.getPDF().output('blob');
const pdfUrl = URL.createObjectURL(pdfBlob);
window.open(pdfUrl);
javascript 代码解读复制代码const blob = dataURLtoBlob(obj.getPDF().output('datauristring'));
const pdfUrl = URL.createObjectURL(blob);
window.open(pdfUrl);
javascript 代码解读复制代码// 当 base64 过大时会导致页面无法加载,需要转化成 blob 格式
const dataURLtoBlob = (dataurl: any) => {
const arr = dataurl.split(',');
// 注意base64的最后面中括号和引号是不转译的
const _arr = arr[1].substring(0, arr[1].length - 2);
const mime = arr[0].match(/:(.*?);/)[1];
const bstr = atob(_arr);
let n = bstr.length;
const u8arr = new Uint8Array(n);
while (n--) {
u8arr[n] = bstr.charCodeAt(n);
}
return new Blob([u8arr], {
type: mime,
});
};
内容过长
在生成 PDF 时,可能会出现大量空白页的情况,这可能是触碰到了浏览器的限制。\ 在浏览器中,Canvas是存在尺寸限制的,主要原因是浏览器为了防止内存溢出和性能问题。不同浏览器对Canvas的最大尺寸有不同的限制:
- Chrome:最大尺寸为16384x16384像素。
- Firefox:最大尺寸约为11164x11164像素。
- Safari:在iOS 10及以下版本中,最大尺寸为4096x4096像素;而在HUAWEI NXT-TL00手机自带浏览器和UC浏览器中,最大尺寸为8192x8192像素。
- 搜狗浏览器:最大尺寸比16384x16384像素稍小一些。
- IE11 和 Edge 浏览器:没有明确的最大尺寸限制,但大尺寸 Canvas 会导致严重的内存消耗和性能问题。
对于这个问题,我们可以考虑将整个大的 Canvas 进行切割,再分段渲染到 PDF 文档上。
具体分割逻辑代码如下:
javascript 代码解读复制代码async function toCanvasAll(element, width) {
// canvas元素
const canvas = await html2canvas(element, {
allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true, // 允许跨域
windowHeight: element.scrollHeight,
});
// 获取canvas转化后的宽度
const canvasWidth = canvas.width;
// 获取canvas转化后的高度
const canvasHeight = canvas.height;
// 高度转化为PDF的高度
const rate = width / canvasWidth;
const height = rate * canvasHeight;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvasWidth, canvasHeight);
if (canvasData === 'data:,') {
const canvasDataArr = await toCanvasSplit(element, rate);
return { totalHeight: height, data: canvasDataArr.sort((a, b) => a.index - b.index) };
}
return {
totalHeight: height,
data: [{ width, height, index: 0, data: canvasData, start: 0, end: height }],
};
}
javascript 代码解读复制代码async function toCanvasSplit(element, rate, parts = 2) {
const yOffsets = distributeEvenlySimple(element.scrollHeight, parts);
let res;
try {
const arr = [];
for (let index = 0; index < yOffsets.length; index++) {
const previous = yOffsets[index - 1] || 0;
const canvas = await html2canvas(element, {
allowTaint: true,
scale: window.devicePixelRatio * 2,
useCORS: true,
// windowHeight: element.scrollHeight,
y: previous,
height: yOffsets[index] - previous,
});
const width = rate * canvas.width;
const height = rate * canvas.height;
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
if (canvasData === 'data:,') {
throw new Error('canvasData is empty');
}
const context = canvas.getContext('2d');
context.clearRect(0, 0, canvas.width, canvas.height);
const start = arr[index - 1]?.end || 0;
arr.push({
width,
height,
index,
data: canvasData,
start,
end: start + height,
});
res = arr;
}
} catch (e) {
console.warn('error', e);
res = await toCanvasSplit(element, rate, parts + 1);
}
return res;
}
分段渲染时,后续分段的数据要考虑拿到到第一个数据渲染后的结束位置,进行拼接。
待优化问题
在开发过程中,还有两个问题稍微难解,等待后续完善。大家也可以讨论更好的解决方案。
- PDF 生成时间过长
- 其主要原因是因为页脚是动态多次渲染并生成的。因为 PDF 从 HTML 到 生成 Canvas 需要一定的耗时(几十到几百毫秒不等) ,而又因为页脚中有页码这种动态内容,所以并不能直接生成一次并复用。目前能想到的解决方案,是渲染包含所有页码的多个页脚,然后进行切割,并放入到 PDF 中,这样仅需生成一次。当然这只是一个想法,暂未得到实践。
- 生成时,将 HTML 元素隐藏
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
我目前采用的方案,是在生成前改变其可见性,使其不可见,生成中时改为可见,并使其透明度为0。因为 HTML 可见时,可能会对页面的样式(比如页面高度)产生影响,所以还要将其“浮在”父页面上(相对布局),在父页面上加上浮层,固定父页面使其不可滚动。
- 在使用 html2pdf 生成 PDF 时,可能会遇到需要先隐藏掉所有 HTML 元素的需求。但是直接改变其可见性,会导致无法渲染。其他文章中,有提到过改变整体 magin 为 -9999,将整体 HTML 内容移出视窗的方案,但这个方案可能会导致样式错乱进而导致分页失效的问题。
总结
以上,就是我对 HTML 生成 PDF 的探索。当然,在当下大家日益增长的业务中,我们可能会遇到更为复杂的场景,可能也会需要更为完善的方案来应对。大家可以多多发表真知灼见,共同学习,一起进步!
评论记录:
回复评论: