
目前市面上有 腾讯云长连接SDK、极光推送SDK、个推SDK 等SDK提供了长连接功能以及推送服务,可以帮助开发者实现消息推送、实时通讯等功能,对于长连接框架还不太熟悉的同学可以先查看上篇文章手把手教你搭建客户端长连接框架。
App在接入sdk时仅需关注业务通信协议,可能对底层协议设计不太清楚,本篇文章重点介绍通信协议的设计以及实现细节。
协议设计
一般底层通信协议格式会如下所示:
| 魔数 | type | 剩余长度 | 可变头部 | 业务数据 |
|---|
-
魔数:和服务器协商约定的消息起始数据,占用1字节
-
type: 消息类型,比如是connect,disconnect,普通消息等消息类型
-
剩余长度:整条消息剩余的长度。即 固定头部 + 可变头部 + 业务数据 长度。
-
可变头部:是指某些消息类型可能需要底层扩展一些字段传输,故设计到可变头部中来。比如消息id等信息。
-
业务数据:俗称有效负载,即真正的上层业务协议数据。
说明:
- 上述,魔数,type,剩余长度,属于固定头部信息,因为每条消息都会包含这3者信息。
- 这里魔数也可以考虑直接使用type 来表示。比如MQTT 框架中首字节中高4位就表示type, 低四位分别表示其他信息,并没有特殊的魔数概念。
- 设计剩余长度的好处是可以一次读取完整的消息信息。
读取数据
注意,这里读取数据的前提是先和服务器约定好上述协议,这样服务器下发数据后我们可以按照约定的协议来进行解析。接下来我们来看下如何具体解析对应的数据。
准备工作
在正式读取消息之前,有些准备工作需要先准备好(对byte多字节操作不感兴趣可以先跳过这部分)。
Stream操作类介绍
-
InputStream: 这是一个抽象类,buffer数据输入流(读入到内存),负责将数据从存储载体读取到内存。比如将接收到的服务器数据从Socket文件读取到内存。
-
OutputStream:这是一个抽象类,buffer数据输出流(从内存写入到OutputStream),负责将内存数据写入到具体的数据流中。
-
FilterInputStream:读取文件流。从一个文件中读取byte数据流。
-
DataInputStream:基于FilterInputStream 读取具体的 java data types 数据。比如将byte数据直接读取出 boolean,int,double等类型的数据。我们在将byte数据转为具体的消息对象时需要用到。
-
ByteArrayOutputStream:将内存数据逐个写入到一个连续的byte数组中,对byte数组进行了操作封装,这样我们可以很轻易的将整个消息全部读取到byte数组中。使用 ByteArrayOutputStream 还有一个好处,即可以节省内存,其内部可以自动适配内存增长,不用一次new 一大块内存供存储消息。
特殊byte封装和解析
-
多字节的int 封装(最多4字节)
-
多字节的int 解析
ini 代码解读复制代码//消息解析工具类
public class MessageParseUtil {
//将long型数据写到byte数组中
protected static byte[] encodeMBI(long number) {
int numBytes = 0;
long no = number;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
do {
byte digit = (byte) (no % 128);
no = no / 128;
if (no > 0) {
digit |= 0x80;
}
bos.write(digit);
numBytes++;
} while ((no > 0) && (numBytes < 4));
return bos.toByteArray();
}
//读取多个字节的int 值,因为消息长度不是固定的,所以可能同时多个字节都表示长度
protected static int readMBI(DataInputStream in) throws IOException {
byte digit;
long msgLength = 0;
int multiplier = 1;
int count = 0;
do {
digit = in.readByte();
count++;
msgLength += ((digit & 0x7F) * multiplier);
multiplier *= 128;
} while ((digit & 0x80) != 0);
return msgLength;
}
//将字符串写入到多字节中。
public static void encodeUTF8(DataOutputStream dos, String stringToEncode) throws Exception {
try {
byte[] encodedString = stringToEncode.getBytes("UTF-8");
byte byte1 = (byte) ((encodedString.length >>> 8) & 0xFF); //高位
byte byte2 = (byte) ((encodedString.length >>> 0) & 0xFF); //低位
dos.write(byte1);
dos.write(byte2);
dos.write(encodedString);
} catch (UnsupportedEncodingException ex) {
throw new MqttException(ex);
} catch (IOException ex) {
throw new MqttException(ex);
}
}
//将多字节byte数据解析成具体的String对象。
public static String decodeUTF8(DataInputStream input) throws IOException {
int encodedLength;
try {
encodedLength = input.readUnsignedShort();
byte[] encodedString = new byte[encodedLength];
input.readFully(encodedString);
return new String(encodedString, "UTF-8");
} catch (IOException ex) {
throw new Exception(ex);
}
}
}
多字节的int 封装
将一个较大的int值写入到byte数组中,这里设计的原理就是:每个字节的最高位表示下个字节是否仍为该int数据,若最高位为1,则表示下个byte 仍表示该int 值,若最高位为0,则表示这个byte 就是该int值的最后一个byte了。
具体封装流程如下
-
ByteArrayOutputStream bos = new ByteArrayOutputStream(); 先new 一个OutputStream 写入数据
-
byte digit = (byte) (no % 128); 因为一个byte是 8bits,即 11111111, 前面有说最高位表示下个字节是否仍表示该int值,不参与具体数值计算,所以一个byte 最大记录的数值就是 0111 1111 即 127,最小值为 1000 0000 即128, 表示0. 所以这里 no%128 就表示这个int值最低一个字节数据。举个例子,假设现在int 值为128,二进制是 10000000, 此时 128%128 = 0, 所以第一个字节表示的数据就为0。
-
no = no / 128; 所以此处 no/128 就表示一个字节是否能表示完整个int值,若大于0则表示一个字节不能存储下这个int值,则需要新增加byte 来存储该int值。同时将 no/128 赋值给no,即将int 值右移8位,将已经添加到byte数组中的数据清除掉。
-
if (no > 0) {digit |= 0x80;} 0x80就是128,即10000000 , 若这个byte 还存储不下这个int值,则将这个byte的最高位标记为1,表示下个字节仍表示这个int值的数据。 还是上面例子,int值为128,此时第一个字节的数据就是 1000 0000,表示0.
-
bos.write(digit); 将已经读出来的bite数据写入到Stream中。
-
while ((no > 0) && (numBytes < 4)); 只要no 大于0 ,并且在4个byte范围内,仍继续循环执行。
拿上面int值为128例子来说:
-
第一轮循环时,首个写入的byte数据为 1000 0000, 代表大小为0.
-
第二轮循环时,digit = 1%128 = 1. no = 1/128 = 0. 所以 第二个byte 的数据就为 0000 0001.
-
所以两轮循环下来,这个128 用byte 表示需要用2个字节,即 0000 0001 1000 0000 来表示。
经过上面分析,确认我们一个byte只能表示127 大小。超过127 就至少要2个byte 来表示
多字节的int 解析
前面讲了 int 转byte 数组存储,再来分析下byte数组数据怎么转为 int值。
解析步骤如下:
-
digit = in.readByte(); 读取第一个字节
-
count++; 记录使用了几个byte来存储数据
-
msgLength += ((digit & 0x7F) * multiplier); 0x7F即为 0111 1111, 即一个byte 的低7位,前面有讲到,每个byte仅低7位存储数据,最高位表示是否存储完成。 所以int值为128的例子中, 此处 digit & 0x7F 的值就为0.
-
multiplier *= 128; multiplier 表示这个字节的位置,即第一个字节本身的大小就表示实际大小,第二个字节的大小取数完后要将它移到对应的位置上。 乘以128 可以表示为往左移8位。
-
while ((digit & 0x80) != 0); 最高位不为0,则一直往下循环计算,直到最高位为0为止。
按照int值为128的例子来解析:
-
第一轮循环后 digit = 1000 0000, msgLength = 0, multiplier = 128
-
第二轮循环后 digit = 0000 0001, msgLength = 1 * 128 = 128
经过2轮遍历后就将128给解析出来了。
经过上述介绍后,我们用4个字节可以多大数据呢?我们按照最大值来计算,具体如下:
01111111 11111111 11111111 11111111
即,
第一个字节大小 127
第二个字节大小 127 * 128
第三个字节大小 127 * 128 * 128
第四个字节大小 127 * 128 * 128 * 128
所以 总大小为 127 + 16256 + 2080768 + 266338304 = 268435455(byte) = 262,143(kb)= 255(mb)
字符串多字节封装
封装字符串为多字节数据并不复杂。大致步骤如下:
-
读取字符串长度
-
将长度信息存储在2个byte中并写入到OutputStream中
-
将字符串也写入到OutputStream中
这里有一点需要注意,为什么写入字符串长度的时候,优先写入的高位字节,再写入的低位字节? 这是由于java系统中 DataInputStream 读取 readUnsignedShort() 数据时是指定的 "BIG_ENDIAN" 顺序来取数的,所以在写入的时候我们也要按照 "BIG_ENDIAN" 顺序来写入。
下面是DataInputStream#readUnsignedShort() 源码
java 代码解读复制代码
public final int readUnsignedShort() throws IOException {
// b/30268192
// Android-changed: Use read(byte[], int, int) instead of read().
readFully(readBuffer, 0, 2);
return Memory.peekShort(readBuffer, 0, ByteOrder.BIG_ENDIAN) & 0xffff;
}
BIG ENDIAN 和 LITTLE ENDIAN 小科普
BIG ENDIAN和LITTLE ENDIAN是用来描述多字节数据在内存中存储顺序的两种方式。
在计算机中,多字节数据(比如整数、浮点数)需要存储在内存中。例如,一个4字节的整数在内存中需要占用4个字节的空间。而对于多字节数据的存储顺序,就有两种方式:
BIG ENDIAN:最高有效字节存储在最低的内存地址,最低有效字节存储在最高的内存地址。类似于书写习惯,先写高位字节,后写低位字节。
LITTLE ENDIAN:最低有效字节存储在最低的内存地址,最高有效字节存储在最高的内存地址。与BIG ENDIAN相反,先写低位字节,后写高位字节。 举个例子,假设一个4字节的整数0x12345678,那么在内存中的存储顺序如下:
- BIG ENDIAN:0x12 0x34 0x56 0x78
- LITTLE ENDIAN:0x78 0x56 0x34 0x12
多字节字符串解析
将byte数组数据解析为字符串,这里分3步来完成
-
读取字符串长度,一般固定为2个字节。
-
读取字符串完整byte数据。
-
将byte数组数据转为UTF-8格式的字符串对象。
消息对象分类
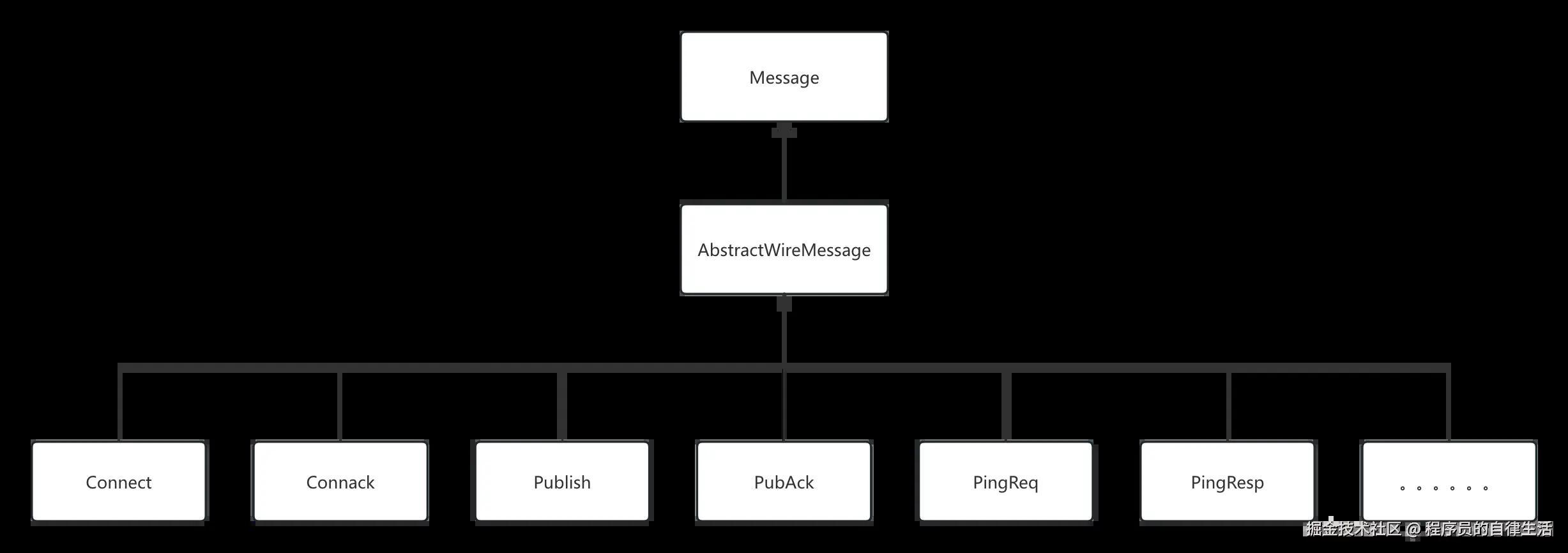
-
Message: 真实的业务消息基类。
-
AbstractWireMessage:基础连接消息,持有Message对象。
-
Connect: 建连消息
-
Connack:建连回执消息
-
Publish: 发送普通消息(一般由服务器发出)
-
PubAck:普通消息的回执消息(一般由客户端发出)
-
PingReq:心跳请求消息 (一般由客户端发出)
-
PingResp:心跳请求回执消息(一般由服务器发出)
WireMessage 子类还包括DisConnect,DisConnectAck 等一系列的消息。
note: 为什么要叫WireMessage?
WireMessage 翻译成中文就是连接消息。这种消息是框架内部定义的,是不需要对外开放的,它是正常消息的一个载体,只是因为其内部特殊的协议,所以会有这么一层封装,因为其作为 正常消息 和 底层框架的一个连接器,所以这里称其为WireMessage。
读取完整数据流
java 代码解读复制代码public class MyInputStream {
private static final int START_MAGIC = 0x22;
private DataInputStream mIn;
public MyInputStream(InputStream in) {
this.mIn = new DataInputStream(in);
}
public Message readMessage() throws IOException, Exception {
//将从socket读取到的信息全部存储在bytes数组中。
final ByteArrayOutputStream bais = new ByteArrayOutputStream();
//读取第一个字节,即我们的魔数,若首个字节不等于魔数,则需要停止长连接。
byte magic = mIn.readByte();
if (magic != START_MAGIC) {
throw new Exception("magic error");
}
//这里假设整个字节都是表示type。具体业务设计时该字节可以表示多个含义,协议设计时有说过。
byte type = mIn.readByte();
//判断type 是否有效,即和服务器约定的相关type类型
if (type无效) {
throw new Exception("type error");
}
//读取剩余长度
long remLen = MessageParseUtil.readMBI(in);
bais.write(magic);
bais.write(type);
bais.write(MessageParseUtil.encodeMBI(remLen));
//一条完整消息byte数组
byte[] packet = new byte[(int) (bais.size() + remLen)];
//读取剩余所有字节数据
mIn.readFully(packet, bais.size(), packet.length - bais.size());
//将已读的字节数据也copy到packet 中去。
byte[] header = bais.toByteArray();
System.arraycopy(header, 0, packet, 0, header.length);
//将读取到的bytes数组数据 解析为具体的消息对象。
Message message = Message.createMessage(packet);
return message;
}
}
具体流程如下,可以结合代码来看:
-
bais = new ByteArrayOutputStream(); 首先new 一个ByteArrayOutputStream,用于存储从Socket读取到的数据。
-
byte magic = mIn.readByte(); 从Socket 读取一个byte数据。
-
if (magic != START_MAGIC) 判断魔数是否正确,若不正确,则需要退出消息接收线程,并中断整个长连接,因为通道已经不安全了。
-
byte type = mIn.readByte(); 继续从Socket读取一个字节,表示消息类型
-
if (type无效) 判断type有效性,若type 非法,也需要中断长连接
-
long remLen = MessageParseUtil.readMBI(in); 读取剩余长度,具体解析过程前面有介绍
-
bais.write(magic); 将魔数写入到byte数组
-
bais.write(type); 将type也写入到byte数组
-
bais.write(MessageParseUtil.encodeMBI(remLen)); 将剩余长度也写入到byte数组,写入前我们按照规则将长度封装为byte数据了。
-
byte[] packet = new byte[(int) (bais.size() + remLen)]; 定义完整数据包byte数组,消息大小为 已经读取的长度 + 剩余长度
-
mIn.readFully(packet, bais.size(), packet.length - bais.size()); 将剩余长度写入到 packet 中,只是offset 偏移量为已读数据大小,即 bais.size()。
-
byte[] header = bais.toByteArray(); System.arraycopy(header, 0, packet, 0, header.length); 将已读数据放置到 packet 的头部,这样 packet 中就是完整的消息数据了。
-
Message message = Message.createMessage(packet); 将完整的消息byte数组 解析为具体类型的消息对象。
解析具体的消息对象
通过上面的步骤,我们得到了一条完整消息byte数组数据,现在我们需要进一步将byte数组数据解析为具体的上层消息对象,其中最核心的就是解析 头部 和 payload数据。
在读取可变头部和payload数据之前,我们先自定义一个 CountingInputStream 用于记录已经读取的字节数。比如前面有介绍我们的剩余长度字节数并不固定,此时若没有封装这个类,那我们将需要在每一个解析步骤中记录已经读取的字节数了,这个过程会相当复杂,并且该读取字节数功能会与具体协议字段完全耦合,导致协议解析代码臃肿。
CountingInputStream 具体实现如下,整体比较简单, 就是在read的时候 增加一个计数功能即可。
java 代码解读复制代码
//记录从InputStrean读取了多少字节数
public class CountingInputStream extends InputStream {
private InputStream mIn;
private int mCounter;
private int mMark;
public CountingInputStream(InputStream in) {
this.mIn = in;
this.mCounter = 0;
}
public int read() throws IOException {
int i = mIn.read();
if (i != -1) {
mCounter++;
}
return i;
}
public int getCounter() {
return mCounter;
}
@Override
public synchronized void mark(int readlimit) {
mIn.mark(readlimit);
mMark = mCounter;
}
@Override
public synchronized void reset() throws IOException {
if (!mIn.markSupported()) {
throw new IOException("Mark not supported");
}
if (mMark == -1) {
throw new IOException("Mark not set");
}
mIn.reset();
mCounter = mMark;
}
}
InputStream 的mark 和 reset 小介绍:
InputStream类是Java中用于字节输入流的抽象类,它的mark()方法和reset()方法用于在输入流中标记当前位置,并在需要时返回到该位置。
mark(int readlimit)方法用于在当前位置设置一个标记,readlimit参数指定了在调用reset()方法之前可以读取的最大字节数。如果在超过readlimit个字节之后调用reset()方法,则标记会失效,无法返回到标记位置。如果mark方法中传入的readlimit参数为-1,表示可以无限制地读取字节数,即在调用reset方法之前可以读取任意数量的字节。
reset()方法用于将输入流的位置重置到最后一次调用mark()方法时的位置。如果在调用mark()方法之后没有调用过read()方法,则reset()方法可能不会移动流的位置。
适用场景:尝试读取字节数据,不满足条件的话将读取位置恢复到之前的位置。
ini 代码解读复制代码
public class Message {
public static Message createMessage(byte[] bytes) {
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
return createMessage(bais);
}
private static Message createMessage(InputStream inputStream) throws Exception {
try {
//字节记数
CountingInputStream counter = new CountingInputStream(inputStream);
//java基础类型读取
DataInputStream in = new DataInputStream(counter);
int magic = in.readUnsignedByte();
int type = in.readUnsignedByte();
long remLen = MessageParseUtil.readMBI(in); //剩余长度
long remainder = remLen;
byte[] data = new byte[0];
if (remainder > 0) {
data = new byte[(int) remainder];
in.readFully(data, 0, data.length);
}
Message result;
if (type 是普通消息) {
result = CommonMessage(data);
} else if (type 是connect消息) {
} else if (type ......) {
}
//在次处穷举所有的type 类型,并在对应的分支下创建具体的消息类型实例对象
} catch (IOException e) {
}
}
}
此处我们再统一对完整的bytes数据进行处理,首先读取出固定头部,获取type信息,然后根据type 类型构建具体的消息对象,再在具体的消息对象中对具体的其他信息进行解析。大家可以看到这里对封装的概念用到了极致,一层紧扣一层,每个类和方法都符合单一职责设计原则(遇到好的符合设计原则的代码,不由得点赞一下)。
这里假设我们收到的普通消息是 CommonMessage ,我们再来具体看看我们是如何逐步解析的。
ini 代码解读复制代码
public class CommonMessage() {
private Message mMessage;
public CommonMessage(byte[] data) {
ByteArrayInputStream bais = new ByteArrayInputStream(data);
CountingInputStream counter = new CountingInputStream(bais);
DataInputStream dis = new DataInputStream(counter);
//可变头部部分
//数据是否已经加密处理,1个字节。
int flag = dis.readUnsignedByte();
mMessage.setEncrypted(flag == xxx);
//读取topicName 字符串
String topicName = MessageParseUtil.decodeUTF8(dis);
//读取消息id
String msgId = dis.readLong();
//标记当前位置
dis.mark(-1);
boolean isNeedDepressPayload = false;
//新扩展协议魔数
int newPro = dis.readUnsignedShort();
if (根据newPro判断是不是新协议) {
//读取标记位,4个字节
int headerUserSwitch = dis.readInt();
isNeedDepressPayload = 根据headerUserSwitch 标记位判断是否需要解压缩消息
if (根据headerUserSwitch 判断是否需要读取userid) {
//读取userid,4个字节。
int userId = dis.readInt();
}
else {
//老协议的话不存在 newPro 等内容,所以需要将InputStream 读取位置恢复到mark 时的位置
dis.reset();
}
//读取payload 数据
byte[] payload = new byte[data.length - counter.getCounter()];
dis.readFully(payload);
dis.close();
if (isNeedDepressPayload) {
payload = depressPayload(payload); //解压缩payload数据,这里就不细讲了。
}
mMessage.setPayload(payload);
}
}
上面举例了一个普通通知解析的案例(解释说明如何解析数据),具体流程如下:
-
int flag = dis.readUnsignedByte(); 读取一个字节,判断数据是否有加密。
-
String topicName = MessageParseUtil.decodeUTF8(dis); 读取topicName字符串。
-
String msgId = dis.readLong(); 读取消息id, 8字节。
-
dis.mark(-1); 标记当前位置。因为接下来的字段都是新扩展协议,若是老版本协议则还要恢复到当前读取位置。
-
int newPro = dis.readUnsignedShort(); 读取新协议魔数,占2个字节。
-
int headerUserSwitch = dis.readInt(); 读取新协议中的标记位,4个字节,可以支持32个标记位。
-
dis.reset(); 如果是老协议,则将位置恢复到mark时的位置(期间多读取了newPro 这两个字节)。
-
dis.readFully(payload); 将剩余数据全部读取到payload数据中, 因为payload 是业务数据,需要在上层通过相关协议来解析(比如pb格式,json格式等)。
至此我们将普通消息内容全部解析出来了。
总结
本篇文章重点从源码实现角度介绍了如何实现消息协议的解析,相信这些细节可以更好的辅助我们了解长连接框架。我们下篇文章接着讲长连接如何实现状态管理。
评论记录:
回复评论: