
http://blog.csdn.net/wxtsmart/article/details/2693329 由于原文的图片已经无法正常显示 这里处理一下
在多媒体会议中,音频互动是基本的要素之一,它是多媒体会议中最基本的要素.由于在分组网络中没有QoS,所以网络的拥塞导致了端到端通信的语音丢包和延时抖动等问题同时,多个端点同时相互发送数据更进一步增加了网络传输的负担,并且增加语音通信中数据收发的随机性和波动性.而语音互动的实时性要求远远高于多媒体会议中的其他要素,比如视频和数据.因为视频和数据在相对较长的时延内的抖动都是可以被用户接受的,而音频部分如果时间稍长,就会产生很明显的断续感,以致用户根本无法分辨语音所承载的语义从而严重影响沟通.为了解决这一问题,使用多点处理单元(MCU)对语音信号进行混音,则降低了网络传输的负担,对于每个端点的处理能力的需求也大大降低.但是在常见的处理算法中,一般会因为多路语音信号采样量化数据叠加后超出量化上限,而导致不得不采用饱和运算将其变更为量化上限,这样就引入了新的噪声.为确保混音输出音频流的波形尽量表现出各路输入音频流的波形包络,降低失真度,如何处理量化上限溢出是一个关键的问题. 在前一阵子的实践摸索中大致在这一方面有一些认识,也搜集整理了一些资料, 故在此将一些原先零散的碎片集中, 方便以后的查阅和进一步的探索.
[注:以下内容系资料整理集中, 参考了《视频会议中混音后溢出问题的研究及解决方法》·马旋王衡汪国平 董士海等]
参考链接
http://iyenn.com/index/link?url=http://www.doc88.com/p-70383188302.html
一、最简单的混音算法
现在一般的软件混音算法是对输入的音频数据进行线性叠加,即:

或者叠加以后再取平均值:
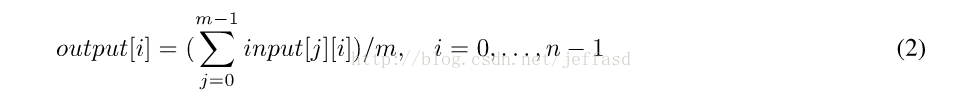
其中, m 为输入音频流的个数, n为一帧的样本数目, ·[i]为一帧中的第i个样本, ·[j]为第j个音频流, 所以, output[i]为混音后的一帧中第i个样本, input[j][i]为第j个输入音频流当前帧的第i 个样本(若经过编码则输入音频流应在混音前通过解码等还原成线性的PCM音频流).通常的语音数据为16 bit(或者更少,如8 bit),即可以用C语言中的short 类型表示,其取值范围是−32768≤采样值≤32767,可以预想到多个音频流直接线性叠加以后就有可能溢出,所以式(1)最后的结果可能会有溢出,产生噪音.
两个连续平滑的波形叠加, 其结果也应该是平滑的.所以产生噪音的地方就是由叠加溢出的地方引入的.我们需要采用滤波来处理这些溢出部分,改善由于溢出所造成的质量下降.为了解决溢出的问题,一个常用的方法就是使用更多的位数来表示音频数据的一个样本, 在混音完毕以后,再使用一些算法来降低其振幅,使其分布在16 bit所能表示的范围之内, 这种方法叫做归一化(Normalize).通常使用32 bit来表示线性叠加以后的数据, 也就是C语言中的int类型, 实现简单,运算也比较快,更能满足很多路音频同时进行混音的需要. 式(2)对叠加的和值作平均,解决了溢出的问题,但是混音以后的声音会总体衰减,特别是某一路音频流的能量与其他路音频流的能量反差很大的情况下,音量非常小,效果非常不理想. 进行滤波处理的另外一种常用方法就是“箝位”,当发生上溢时, 箝位以后的值为所能表示的最大值, 当发生下溢时,箝位后的值为所能表示的最小值,如式(3)所示:

其中, sample 为叠加以后的样本值, 为 32 bit, MAX 是最大输出值,这里为32767, MIN为最小输出值,为−32768. 现在很多现有的论文和系统都是采用箝位方法,因为实现简单, 快速, 效率很高.但是可以看出,这种箝位方法相当于在最大和最小的临界值处切强行切断波形,非常生硬,会造成较大的波形失真, 听觉上引起如嘈杂,出现突发刺耳的爆破音等.采用时域叠加作为基本的处理手段,由于数字音频信号存在量化上限和下限的问题,则因叠加运算肯定会造成结果溢出. 通常的处理手段是进行溢出检测,然后再进行饱和运算(如 4式的方法),
即超过上限的结果被置为上限值, 超过下限的值置为下限值.这种运算本身破坏了语音信号原有的时域特征,从而引入了噪声. 这就是出现爆破声和语音不连续现象的原因. 同时, 随着参与混音的人数增加,出现溢出的频率也不断上升,所以这类方法存在一个上限, 而且这个上限值很低, 实验证明,采用这种时域直接叠加的方式进行混音,一般不能突破 4 路输入音频流的限制, 否则将无法分辨语音流的内容了.
二、改进的混音算法
混音的时候, 还需要屏蔽某一路的本地音频数据,这样就不会听到本地的声音,只能听到其他 n − 1 路的声音, 也就是说,对于第 t路音频, 要发送给这个终端的混音后的数据如式(4):

以下提出的算法主要思想就是使用一个衰减因子, 对音频数据进行衰减, 衰减因子会随着数据而变化. 当溢出时,衰减因子比较小,使溢出的音频数据衰减以后处于临界值以内, 当没有溢出时, 衰减因子会慢慢增加, 尽量保持数据的平滑变化.而不是对于整帧使用同一个衰减因子来进行,这是不同于式(2)和式(3)的地方,既保证了整体的声强不至于衰减太快, 又保证了较小的失真度.
算法如下所述:
1. f 初始化为1.
2. 对于一帧中的样本按顺序处理:
(a) output[i] = mixing[i] × f.
(b) 如果output[i] > MAX,求得最大的 f0满足 output[i] × f0< MAX,然后 f = f0, output[i] = MAX.
(c) 如果output[i] < MIN,求得最大的 f0满足 output[i]×f0> MIN,然后 f = f0, output[i] = MIN.
3. 如果f < 1, 则f = f + STEPSIZE. 继续处理下一帧, 转2.
其中f 为衰减因子, f0为新的衰减因子; mixing[]为所有音频流的某一帧线性叠加值,实际实现的时候如式(4)所示; output[]为归一化以后的输出帧. MAX为正的最大值; MIN 为负的最大值. STEPSIZE 为f 变化的步长,通常取为 (1 − f)/16或者 (1 − f)/32.
SETPSIZE为f的变化步长,通常的取值为 (1-f)/VALUE 其中(1-f)为固定值 只是后面的VALUE值可以取 8, 16, 32, 64,128. SETPSIZE取值较大时,运算复杂度低,但语言平滑度不够细腻,STEPSIZE取值较小时,运算复杂度高,但语言平滑度比较细腻。
特别的, 就是在衰减以后的值溢出的情况下,求新的衰减因子 f0的方法不同,新的 f0需要满足 output[i] × f0< MAX或者 output[i] × f0> MIN,而不是直接使用mixing[i].也就是说,使用衰减以后的值output[i]来计算f0,而不是原始值mixing[i],这样将使得衰减因子的变化更为平滑.
用数学来表达, S 为溢出的一个样本值,在S × f仍然溢出的情况下, 可以比较一下计算出来的新衰减因子的大小:假设是上溢, forig是原始算法计算出的新的衰减因子,则f`orig<(MAX/S), 我们改进的算法得出的新衰减因子 f`new<(MAX/(S×f)),因为 S > (S × f),所以(MAX/S) <(MAX/(S×f)),那么 f`new很大程度上要大于f`orig.衰减因子大了(更接近1),相邻的数据变化不会特别大,所以跳跃的现象不会特别明显.
上述改进过的混音方案在实测中,与常规的混音算法(直接线性叠加的方式)比较,常规算法在混入 4路音频流的结果, 已经明显听到背景噪音,波形会突变失真,出现比较轻微的爆破音, 少量出现语音不可以辨认的情况;如果混入 5路或者 5 路以上的音频流,则输出的音频流质量已经不能从听觉上接受,语声模糊并且爆破音明显,噪音大, 难以辨别语音内容.采用衰减因子的方式进行调整以后,混入 4 路音频流从听觉上基本感觉不到背景噪音,混入 5路的情况下, 仍然能清晰辨别各路的语音内容,不出现爆破音;混入 6 路到 9路的情况下仍然能保证语音质量,不会发生突变的爆破音, 能够满足视频会议的要求.
从算法执行效率上看, 与常规的混音算法比较,其时间复杂度并没有增加而具有同等的时间复杂度,只是调和系数法在计算过程中叠加时需要进行一次额外的乘法运算(如上述算法描述的 2.a),并且发生溢出的情况下需要重新计算新的调和系数(整数除法运算),最后在算法的第三步需要进行一次加法运算(浮点数加法).因为涉及的数值不会很大,同时音频流的数据量较之视频等要小得很多,在视频会议的应用中, 采用调和系数方法进行混音完全在 MCU 承载的能力范围内, 实测与常规混音算法比较,格式为 linear PCM raw, 16 bit,单声道,采样率为8000 HZ,时间30秒, 帧长30毫秒的情况下,其差别不会超过 17ms ,并不会由此产生很大的延迟,其实时性仍然得到保证, 而从混音的质量来说较常规混音算法要好很多.[更详细的实测数据不做一一罗列]
评论记录:
回复评论: