
☞ ░ 老猿Python博文目录:http://iyenn.com/rec/324322.html ░

一、引言
最近看到好几篇类似“n行Python代码…”的博文,看起来还挺不错,简洁、实用,传播了知识、带来了阅读量,撩动了老猿的心,决定跟风一把,推一个“n行Python代码系列”文章。
今天写个分离博文中的程序代码的极简实现。后续更多“n行Python代码系列”文章请参考免费专栏《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_10858655.html n行Python代码系列》。
在爬取编程类博文时,博文中的程序代码有时出于需要分离出来,如提取博文中的程序保存、或者分析博文内容(如用BeatifulSoap的find查找特定文字或tag标记)时需要剔除博文中的程序代码(特别博文内容中的程序本身就是HTML代码或爬虫程序)以防止干扰到分析。
二、案例说明
2.1、处理博文案例
下面这篇博文截图是老猿CSDN的一个爬虫测试用博文:
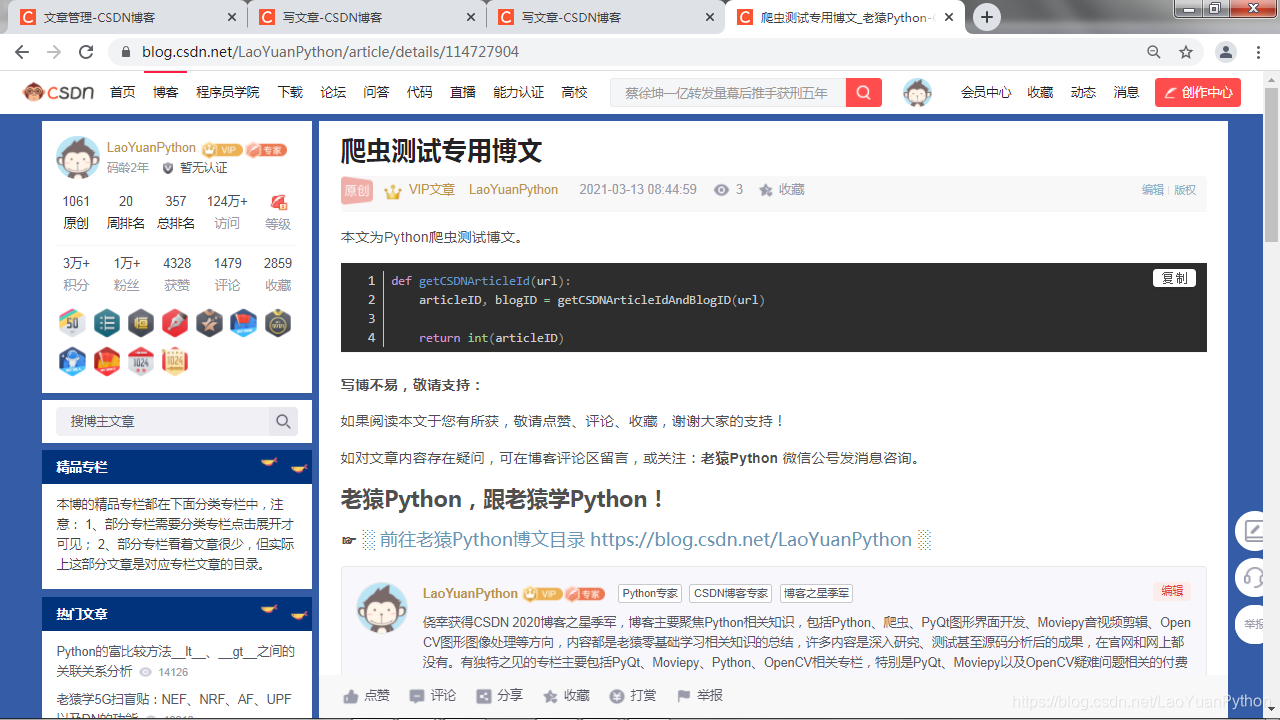
该博文内容很简单,几行文字加三行代码,其中代码部分用到了单独的格式控制,这个控制格式是现在markdown等主流编辑器都支持的。
获取该博文的HTML内容后,文章主体对应的HTML内容如下:
<div id="article_content" class="article_content clearfix">
<link rel="stylesheet" href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/editerView/ck_htmledit_views-b5506197d8.css">
<div id="content_views" class="markdown_views prism-tomorrow-night-eighties">
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<p>本文为Python爬虫测试博文。</p>
<pre><code class="prism language-python"><span class="token keyword">def</span> <span class="token function">getCSDNArticleId</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span>
articleID<span class="token punctuation">,</span> blogID <span class="token operator">= getCSDNArticleIdAndBlogID(url)
<span class="token keyword">return</span> <span class="token builtin">int</span><span class="token punctuation">(</span>articleID<span class="token punctuation">)</span>
</code></pre>
<h6><a id="_10"></a>写博不易,敬请支持:
<p>如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
<p>如对文章内容存在疑问,可在博客评论区留言,或关注:老猿Python 微信公号发消息咨询。
<h2><a id="PythonPython_16"></a>老猿Python,跟老猿学Python!
<h4><a id="__Python_httpsblogcsdnnetLaoYuanPythonhttpsblogcsdnnetLaoYuanPythonarticledetails98245036__17"></a>☞ ░ <a href="http://iyenn.com/rec/324322.html">前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython</a> ░</h4>
</div>
<link href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/editerView/markdown_views-d7a94ec6ab.css" rel="stylesheet">
<link href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/style-a0c38f4093.css" rel="stylesheet">
</div>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
可以看出,程序代码在code标签范围内。
2.2、实现功能说明
要实现程序代码的分离,首先要将code标签的内容提取出来,然后从整体HTML文本中删除,这样才既获得了程序代码,又不影响后续分析。
三、分离博文程序代码的实现
>>> from bs4 import BeautifulSoup
>>> text = """
本文为Python爬虫测试博文。
def getCSDNArticleId(url):
articleID, blogID = getCSDNArticleIdAndBlogID(url)
return int(articleID)
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
如对文章内容存在疑问,可在博客评论区留言,或关注:老猿Python 微信公号发消息咨询。
老猿Python,跟老猿学Python!
☞ ░ 前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython ░
"""
>>> soup = BeautifulSoup(text,'lxml')
>>> code = soup.code.extract()
>>> code
<code class="prism language-python"><span class="token keyword">def</span> <span class="token function">getCSDNArticleId</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span>
articleID<span class="token punctuation">,</span> blogID <span class="token operator">=</span> getCSDNArticleIdAndBlogID<span class="token punctuation">(</span>url<span class="token punctuation">)</span>
<span class="token keyword">return</span> <span class="token builtin">int</span><span class="token punctuation">(</span>articleID<span class="token punctuation">)</span>
</code>
>>> code.text
'def getCSDNArticleId(url):
articleID, blogID = getCSDNArticleIdAndBlogID(url)
return int(articleID)
'
>>> soup
<html><body><article class="baidu_pl">
<div class="article_content clearfix" id="article_content">
<link href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/editerView/ck_htmledit_views-b5506197d8.css" rel="stylesheet"/>
<div class="markdown_views prism-tomorrow-night-eighties" id="content_views">
<svg style="display: none;" xmlns="http://www.w3.org/2000/svg">
<path d="M5,0 0,2.5 5,5z" id="raphael-marker-block" stroke-linecap="round" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<p>本文为Python爬虫测试博文。</p>
<pre></pre>
<h6><a id="_10"></a>写博不易,敬请支持:</h6>
<p>如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!</p>
<p>如对文章内容存在疑问,可在博客评论区留言,或关注:<strong>老猿Python</strong> 微信公号发消息咨询。</p>
<h2><a id="PythonPython_16"></a>老猿Python,跟老猿学Python!</h2>
<h4><a id="__Python_httpsblogcsdnnetLaoYuanPythonhttpsblogcsdnnetLaoYuanPythonarticledetails98245036__17"></a>☞ ░ <a href="http://iyenn.com/rec/324322.html">前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython</a> ░</h4>
</div>
<link href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/editerView/markdown_views-d7a94ec6ab.css" rel="stylesheet"/>
<link href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/style-a0c38f4093.css" rel="stylesheet"/>
</div></article></body></html>
>>> soup.text
'
本文为Python爬虫测试博文。
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
如对文章内容存在疑问,可在博客评论区留言,或关注:老猿Python 微信公号发消息咨询。
老猿Python,跟老猿学Python!
☞ ░ 前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython ░
'
>>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
可以看到,通过调用code = soup.code.extract()后,原来的soup对象中的HTML报文内容中已经去除了程序代码相关的内容,这些内容被保存到了code对象中。
如果去除输出数据的代码,则代码精简如下四行代码:
>>> from bs4 import BeautifulSoup
>>> text = """
本文为Python爬虫测试博文。
def getCSDNArticleId(url):
articleID, blogID = getCSDNArticleIdAndBlogID(url)
return int(articleID)
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
如对文章内容存在疑问,可在博客评论区留言,或关注:老猿Python 微信公号发消息咨询。
老猿Python,跟老猿学Python!
☞ ░ 前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython ░
"""
>>> soup = BeautifulSoup(text,'lxml')
>>> code = soup.code.extract()
>>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
四、BeautifulSoup相关知识
4.1、简介
BeautifulSoup是bs4模块的类,它是一个高效的网页解析库,是用于解析、遍历、维护网页“标签树”的功能库,可以从 HTML 或 XML 文件中提取数据。BeautifulSoup对象对应一个HTML/XML文档的全部内容。
beautifulsoup支持不同的解析器,比如,对HTML解析,对XML解析,对HTML5解析。一般情况下,我们用的比较多的是 lxml 解析器。
lxml是一款XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据,它可以被BeautifulSoup用于解析HTML文本,当然BeautifulSoup自己也默认带有解析器,也可以支持一些其他解析器。
当前最新的 Beautiful Soup 版本为4.9.3,Beautiful Soup 3 当前已停止维护。
4.2、安装
在操作系统命令行方式执行安装bs4模块和lxml解析器模块的命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
- 1
- 2
4.3、加载BeautifulSoup所在模块
因为BeautifulSoup是bs4模块提供的一个类,一般导入时使用:
from bs4 import BeautifulSoup
- 1
4.4、定义BeautifulSoup实例对象
4.4.1、构造方法
__init__(self,markup="", features=None, builder=None,
parse_only=None, from_encoding=None, exclude_encodings=None,
element_classes=None, **kwargs)
- 1
- 2
- 3
- 4
4.4.2、参数解析
BeautifulSoup类的构造方法提供7个参数(不含self)并支持通过kwargs扩展更多动态参数,主要参数说明如下:
- markup:包含了HTML报文内容的字符文本或文件对象,即要解析的html文本字符串或使用open函数打开的html文件
- features:要使用的解析器特性,可以是特定解析器的名称(“lxml”、 “lxml-xml”、“html.parser”,或“html5lib”,其中html.parser是Python标准库中的HTML解析器),也可以是要使用的标记类型(“html”、“html5”、“xml”)。建议使用特定的解析器,这样Beautiful Soup就可以跨平台和虚拟环境提供相同的结果。如果我们不安装第三方的解析器,则 Python 会使用 Python默认的标准库内置解析器html.parser,官方推荐使用lxml 解析器,因为lxml 解析器更加强大,支持xml解析,速度更快
- builder:要代替features参数的TreeBuilder子类,就是自定义解析结构,只有在实现了自定义TreeBuilder的情况下才需要使用它
- parse_only:一个SoupStrainer,只考虑文档中与SoupStrainer匹配的部分。这在解析文档的某个部分时非常有用,否则该部分将太大而无法放入内存,这个参数只有特定情况下才需要使用
- rom_encoding:表示要分析的标记内容的编码。如果Beautiful Soup错误地猜测了文档的编码,可以通过此参数设置指定
- exclude_encodings:表示不是标记内容对应文档编码类型的字符串列表。如果不知道文档的具体编码,但知道BeautifulSoup肯定不是某几个编码,则使用此参数传递这些要排除的编码格式
- element_classes:一个将BeautifulSoup类如Tag、NavigableString映射到开发者在构建解析树时实例化的其他类,这对于将Tag或NavigableString子类化以修改默认行为非常有用
- kwargs:为了后向兼容支持一些关键字参数的处理,这些参数通常用于BS3,在BS4中将被忽略
4.5、BeautifulSoup提取报文中的标签信息
上述案例中使用了soup.code来提取程序代码,结合前面的报文介绍code是html标签,因此BeautifulSoup对象可以直接使用“BeautifulSoup对象.标签名”方式来提取HTML文本中第一个符合条件的标签内容,这样可以非常方便的查找标签信息,不过一定要注意是第一个,如果是所有相同标签都需要提取出来,则需要使用更复杂的select方法或find_all方法。
4.6、extract函数
调用语法:extract(self, _self_index=None)
语法说明:
extract函数实际上是一个方法,将方法调用者对象对应的HTML标签信息从整个BeautifulSoup对象中取出来,实际上就是将调用对象对应标签的HTML内容从BeautifulSoup对象对应HTML中取出来。
参数_self_index参数用于指出调用者对象在其父标签中的精确位置,是为了避免逐一查找优化性能的,可以不传值。
另外BeautifulSoup还提供了一个decompose方法,该方法与extract的区别就是直接删除对应对象数据而不是取出来返回。
五、小结
本文介绍了使用Python BeautifulSoup模块快速分离HTML报文中的程序代码的方法和案例,通过BeautifulSoup模块可简单快速完成从HTML文本中分离程序代码,实现程序代码和分析主体的分离,方便后续程序的分析。
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
更多关于BeautifulSoup的介绍请参考:
《Python爬虫入门专栏 http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_10762553.html》。
关于老猿的付费专栏
- 付费专栏《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_9607725.html 使用PyQt开发图形界面Python应用》专门介绍基于Python的PyQt图形界面开发基础教程,对应文章目录为《 http://iyenn.com/rec/324324.html 使用PyQt开发图形界面Python应用专栏目录》;
- 付费专栏《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_10232926.html moviepy音视频开发专栏 )详细介绍moviepy音视频剪辑合成处理的类相关方法及使用相关方法进行相关剪辑合成场景的处理,对应文章目录为《http://iyenn.com/rec/324326.html moviepy音视频开发专栏文章目录》;
- 付费专栏《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_10581071.html OpenCV-Python初学者疑难问题集》为《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的伴生专栏,是笔者对OpenCV-Python图形图像处理学习中遇到的一些问题个人感悟的整合,相关资料基本上都是老猿反复研究的成果,有助于OpenCV-Python初学者比较深入地理解OpenCV,对应文章目录为《http://iyenn.com/rec/324329.html OpenCV-Python初学者疑难问题集专栏目录 》
- 付费专栏《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_10762553.html Python爬虫入门 》站在一个互联网前端开发小白的角度介绍爬虫开发应知应会内容,包括爬虫入门的基础知识,以及爬取CSDN文章信息、博主信息、给文章点赞、评论等实战内容。
前两个专栏都适合有一定Python基础但无相关知识的小白读者学习,第三个专栏请大家结合《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的学习使用。
对于缺乏Python基础的同仁,可以通过老猿的免费专栏《http://iyenn.com/index/link?url=https://blog.csdn.net/laoyuanpython/category_9831699.html 专栏:Python基础教程目录)从零开始学习Python。
如果有兴趣也愿意支持老猿的读者,欢迎购买付费专栏。
如果对文章内容存在疑问,可以在博客评论区留言,或关注:老猿Python 微信公号发消息咨询。


跟老猿学Python!
☞ ░ 前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython ░

 微信公众号
微信公众号

评论记录:
回复评论: