
写在前面:本文相关方法为作者独创,仅供参考学习爬虫技术使用,请勿用作它途,禁止转载!
一、 引言
在爬虫爬取网页时,有时候希望不同的时候能以不同公网地址去爬取相关的内容,去网上购买地址资源池是大部分人员的选择。老猿所在的环境有电信运输商部署的对外开放的WiFi,由于涉及对外开放支持不同用户接入,其分配的地址经过NAT地址转换,但其公网地址一定是一个地址池,对于需要公网地址池资源的人员来说,这就是一个免费的地址资源池。本节介绍的内容就是怎么借用这个地址资源池作为自己的地址池。
二、 要解决的问题
老猿仔细思考如何借用电信运营商提供给公众服务的WiFi,发现需要解决如下几个问题:
- Wi-Fi后面必须有个支持动态分配和映射的公网地址池,这个一般的公众服务Wi-Fi都是这样的,不存在问题;
- Wi-Fi最好支持账号、密码登录或自动登录功能,不能使用短信校验码登录,这个问题很关键,老猿所在区域的电信Wi-Fi需要使用手机+短信随机码方式登录,但登录一次后支持自动登录,即下次使用时无需再次认证,直接使用cookies信息自动登录;
- 需要能支持公网地址的动态分配,不能使用重复地址,这个一般公众服务的Wi-Fi都是动态分配地址,但有可能重复分配地址,需要爬虫应用读取公网地址判断是否重复;
- 确保所有爬虫应用访问数据都能从Wi-Fi连接出去,这个解决很简单,将其他网卡连接禁用就可以。
三、 实现方案关键点介绍
1、 要实现通过爬虫自动复位Wi-Fi连接并分配一个地址,需要通过对应操作系统命令去进行操作,老猿使用的windows7的操作系统,使用的命令是windows相关的命令,直接调用os模块的system指令执行命令;
2、 浏览器打开使用的是webbrowser模块;
3、 使用前必须公众WiFi支持登录一次后后续登录支持自动登录,否则老猿下面的代码不能直接使用,还需要自己增加登录相关处理;
4、 读取公网IP使用的是《第14.17节 爬虫实战3: request+BeautifulSoup实现自动获取本机上网公网地址》介绍的方法;
5、 dosomething()函数是各位自己应用的代码,需要自己处理。
四、 利用公众WiFi实现公网地址池的案例代码
大家在windows下把如下内容拷贝存入文件即可实现借用公众服务WiFi地址资源池的目的:
#代码中的:
#wifinet:为无线网卡的名字,各位需要替换为自己的无线网卡名
#wifiname:各位所使用公众WiFi的名字,各位需要替换为自己的公众WiFi名
#执行机器必须有Google浏览器,如果没有相关涉及浏览器的处理代码需要修改
from bs4 import BeautifulSoup
import urllib.request
import os
import webbrowser
import time
wifiname='wifi名' #存放wifi名
wifinet = 'MyWIFI' #存放无线网卡名
def isdupip(ipinfo):
#判断IP是否是原来已经分配过的IP
try: fp = open(r'c: emp
etip.log','r+')
except FileNotFoundError:
fp = open(r'c: emp
etip.log','w')
buff =''
else: buff = fp.read(None)
if buff.find(ipinfo)>=0:
print(f"本次的IP地址为以前分配过的重复公网IP地址:{ipinfo}")
fp.close()
return True
else:
fp.write(ipinfo+'
')
fp.close()
return False
def getip():
#获取本机公网IP地址
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36'}
cookie='BAIDUID=05715D2A65E185B06ECD6CB62056F630:FG=1; BIDUPSID=05715D2A65E185B06ECD6CB62056F630; PSTM=1563498219; BD_UPN=12314353; ispeed_lsm=2; MCITY=-%3A; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BD_HOME=1; H_PS_PSSID=1429_21095_29523_29519_29721_29568_29220_29072_29640; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; BD_CK_SAM=1; PSINO=7; ZD_ENTRY=baidu; sug=0; sugstore=1; ORIGIN=0; bdime=0; COOKIE_SESSION=15_0_9_9_18_35_0_4_9_5_0_0_69285_0_0_0_1567933423_0_1567941823%7C9%23278256_7_1564840597%7C2; H_PS_645EC=143a70YMQeyHbLrfwaFTZLdW6usn4%2FtO8C6yxMcDcF7RjvdnVWhYHMxScchloWr5ipmN; WWW_ST=1567941827974'
req = urllib.request.Request(url='https://www.baidu.com/s?ie=utf-8&mod=1&isbd=1&isid=05715D6F63032916&ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=baiduhome_pg&wd=IP&rsv_spt=1&oq=IP&rsv_pq=a0a4fcb40013a6aa&rsv_t=143a70YMQeyHbLrfwaFTZLdW6usn4%2FtO8C6yxMcDcF7RjvdnVWhYHMxScchloWr5ipmN&rqlang=cn&rsv_enter=0&rsv_dl=tb&inputT=4024&rsv_sug4=4105&bs=IP&rsv_sid=undefined&_ss=1&clist=&hsug=&f4s=1&csor=2&_cr1=28287',headers=header)
text = urllib.request.urlopen(req,timeout=5).read().decode()
soup = BeautifulSoup(text, 'lxml')
ipinfo=soup.select_one('table>tr>td span.c-gap-right').string[6:]
if not ipinfo:
print("访问百度获取公网IP地址失败")
return None
elif isdupip(ipinfo):return None
else:
print(f"本机公网地址为:{ipinfo}")
return ipinfo
def restartnet():
for i in range(1,5):
print(f"
第{i}次尝试重新打开网络......")
print(rf"释放wifi IP:ipconfig /release {wifinet}>C:TEMP
et.log")
os.system(rf'ipconfig /release {wifinet}>C:TEMP
et.log')
print(f"停止wifi连接:netsh interface set interface {wifinet} disable")
os.system(rf'netsh interface set interface {wifinet} disabled>C:TEMP
et.log')
print("尝试关闭谷歌浏览器... ")
os.system(r'taskkill /im chrome.exe >C:TEMP
et.log')
print(f"启用WiFi连接:netsh interface set interface {wifinet} enabled")
os.system(rf'netsh interface set interface {wifinet} enabled>C:TEMP
et.log')
time.sleep(10)
print("连接WiFi:netsh wlan connect name="+wifiname)
cmd=r'netsh wlan connect name='+wifiname+r'>C:TEMP
et.log'
print(cmd)
os.system(cmd)
time.sleep(10)
print(r"刷新WiFi地址")
os.system(rf'ipconfig /renew {wifinet}>C:TEMP
et.log')
time.sleep(5)
#启动浏览器访问网页,激活公众WiFi的自动登录功能
print("execute:尝试打开百度和sohu进行访问")
webbrowser.open('https://www.baidu.com/', new=0,autoraise=False)
time.sleep(5)
webbrowser.open('http://www.sohu.com', new=0,autoraise=False)
time.sleep(10)
print("execute:尝试打开CSDN进行访问")
webbrowser.open('https://blog.csdn.net', new=0,autoraise=False)
time.sleep(5)
webbrowser.open('http://iyenn.com/index/link?url=https://blog.csdn.net/LaoYuanPython', new=0,autoraise=False)
time.sleep(20)
try:
ipinfo = getip()
if not ipinfo:
print("尝试重新连接WiFi失败,错误原因可能是重复的IP地址或访问网络失败")
continue
except Exception as e:
print(f"访问网络出现异常,异常内容为:
{e}")
continue
else:return ipinfo
def dosomething():
print("******************请将自己要处理任务的代码放在dosomething函数中
")
time.sleep(5)
return
def main():
while restartnet(): dosomething()
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
注意,上述代码中的cookie内容请大家参考《第14.17节 爬虫实战3: request+BeautifulSoup实现自动获取本机上网公网地址》。
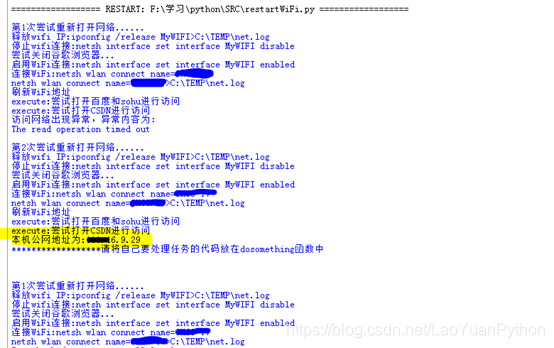
执行结果截图(涂抹部分为服务商wifi名字):
老猿Python,跟老猿学Python!
博客地址:http://iyenn.com/index/link?url=https://blog.csdn.net/LaoYuanPython
老猿Python博客文章目录:http://iyenn.com/rec/324322.html
请大家多多支持,点赞、评论和加关注!谢谢!

 微信公众号
微信公众号

评论记录:
回复评论: